08 wrz 2025·8 min
Dlaczego natywne frameworki wciąż mają znaczenie dla aplikacji o wysokiej wydajności
Natywne frameworki nadal mają przewagę przy niskich opóźnieniach, płynnym UI, oszczędności baterii i głębokim dostępie do sprzętu. Dowiedz się, kiedy natywne rozwiązania przewyższają cross-platform.
Co naprawdę znaczy „performance-critical"
„Performance-critical" to nie tylko „miło byłoby, gdyby było szybciej”. To oznacza, że doświadczenie się rozpada, gdy aplikacja jest nawet odrobinę wolna, niestabilna lub opóźniona. Użytkownicy nie tylko zauważają lag — tracą zaufanie, przegapiają chwilę lub popełniają błędy.
Codzienne przykłady, gdzie wydajność jest produktem
Kilka powszechnych typów aplikacji pokazuje to najlepiej:
- Aparat i wideo: Naciskasz migawkę i oczekujesz natychmiastowego zarejestrowania. Opóźnienia potrafią przegapić moment. Przycięcia w podglądzie, wolne ostrzenie czy utracone klatki sprawiają, że aplikacja wydaje się zawodna.
- Mapy i nawigacja: Niebieska kropka musi poruszać się płynnie, przeliczenia trasy powinny być niemal natychmiastowe, a UI musi pozostać responsywny podczas równoległego działania GPS, ładowania danych i renderowania.
- Trading i finanse: Aktualizacja notowań z opóźnieniem, przycisk rejestrujący dotyk później albo zamrożony ekran w czasie zmienności rynkowej mogą bezpośrednio wpływać na wyniki.
- Gry: Utrata klatek i opóźnienie wejścia nie tylko „źle się odczuwają” — zmieniają rozgrywkę. Stabilne tempo klatek jest równie ważne jak surowe FPS.
We wszystkich tych przypadkach wydajność nie jest ukrytą metryką — jest widoczna, odczuwalna i oceniana w ciągu sekund.
Co oznaczają „natywne frameworki" (bez marketingowego żargonu)
Mówiąc natywne frameworki, mamy na myśli budowanie przy użyciu narzędzi pierwszej klasy dla każdej platformy:
- iOS: Swift/Objective‑C z iOS SDK (np. UIKit lub SwiftUI oraz frameworki systemowe)
- Android: Kotlin/Java z SDK Androida (np. Jetpack, Views/Compose oraz API platformy)
Natywność nie oznacza automatycznie „lepszego inżynieringu”. Oznacza, że aplikacja mówi bezpośrednio językiem platformy — co ma znaczenie, gdy mocno obciążasz urządzenie.
Nie jesteśmy przeciwko cross-platform — chodzi o dopasowanie
Frameworki cross-platform mogą być świetnym wyborem w wielu produktach, szczególnie gdy liczy się szybkość tworzenia i udostępnianie kodu bardziej niż wyciskanie każdej milisekundy.
Ten artykuł nie twierdzi, że „natywne zawsze”. Twierdzi, że gdy aplikacja jest naprawdę krytyczna pod względem wydajności, natywne frameworki często eliminują całe kategorie narzutów i ograniczeń.
Wymiary, które zwykle decydują
Oceniamy potrzeby krytyczności wydajności przez kilka praktycznych wymiarów:
- Opóźnienie (latency): reakcja na dotyk, pisanie, interakcje w czasie rzeczywistym, synchronizacja audio/wideo
- Renderowanie: płynne przewijanie, animacje, tempo klatek, UI napędzany przez GPU
- Bateria i ciepło: efektywność podczas długich sesji
- Dostęp do sprzętu/OS: pipeline aparatu, czujniki, Bluetooth, wykonywanie w tle, on-device ML
To obszary, gdzie użytkownicy czują różnicę — i gdzie natywne frameworki zazwyczaj błyszczą.
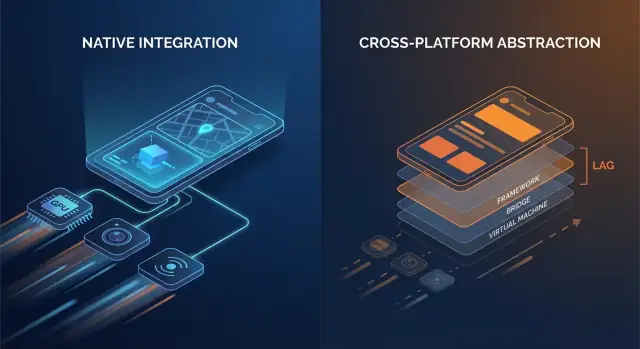
Natywne vs cross-platform: gdzie widać narzut
Frameworki cross-platform mogą wydawać się „wystarczająco bliskie” natywnym, gdy budujesz typowe ekrany, formularze i przepływy sieciowe. Różnica zwykle pojawia się, gdy aplikacja jest wrażliwa na małe opóźnienia, potrzebuje stabilnego tempa klatek lub musi długo mocno obciążać urządzenie.
Dodatkowe warstwy, które się sumują
Kod natywny zazwyczaj komunikuje się bezpośrednio z API systemu. Wiele stosów cross-platform dodaje jedną lub więcej warstw tłumaczących między logiką aplikacji a tym, co ostatecznie renderuje telefon.
Typowe punkty narzutu to:
- Wywołania przez mostek i przełączanie kontekstu: jeśli warstwa UI i logika aplikacji żyją w różnych runtime’ach (np. runtime zarządzany lub silnik skryptowy plus natywny), każda interakcja może wymagać przeskoku przez granicę.
- Serializacja i kopiowanie: dane przekazywane przez granice mogą wymagać konwersji (payloady podobne do JSON, mapy typowane, bufory bajtowe). Ta konwersja pojawia się w „gorących ścieżkach” jak przewijanie czy pisanie.
- Dodatkowe hierarchie widoków: niektóre frameworki tworzą własne drzewo UI, a potem mapują je na natywne widoki (lub renderują na canvasie). Rekonsyliacja i layout mogą być droższe niż bezpośrednia aktualizacja natywnego widoku.
Żaden z tych kosztów nie jest ogromny sam w sobie. Problemem jest powtarzalność: mogą występować przy każdym geście, każdym ticku animacji i każdym elemencie listy.
Czas startu i „jank” w czasie działania
Narzut to nie tylko surowa prędkość; to też kiedy praca występuje.
- Czas uruchamiania może się wydłużyć, gdy aplikacja musi zainicjalizować dodatkowy runtime, załadować zbundlowane zasoby, rozgrzać silnik UI lub odbudować stan przed pierwszym interaktywnym ekranem.
- Jank w czasie działania często wynika z nieprzewidywalnych pauz: garbage collection, przeciążenie mostka, kosztowne porównania/diffy lub długa operacja blokująca główny wątek dokładnie wtedy, gdy UI musi wygenerować kolejną klatkę.
Aplikacje natywne też mogą napotkać te problemy — ale jest mniej ruchomych części, a więc mniej miejsc, gdzie mogą ukryć się niespodzianki.
Prosty model myślowy
Pomyśl: mniej warstw = mniej niespodzianek. Każda dodana warstwa może być dobrze zaprojektowana, ale nadal wprowadza więcej złożoności harmonogramowania, większą presję pamięciową i więcej pracy translacyjnej.
Kiedy narzut jest akceptowalny — a kiedy nie
Dla wielu aplikacji narzut jest akceptowalny, a zysk produktywności realny. Ale dla aplikacji krytycznych pod względem wydajności — szybkie feedy, ciężkie animacje, współpraca w czasie rzeczywistym, przetwarzanie audio/wideo czy cokolwiek wrażliwego na opóźnienia — te „małe” koszty szybko stają się widoczne dla użytkownika.
Płynność UI: klatki, jank i natywne ścieżki renderowania
Płynne UI to nie tylko „miły dodatek” — to bezpośredni sygnał jakości. Na ekranie 60 Hz aplikacja ma około 16,7 ms na przygotowanie każdej klatki. Na urządzeniach 120 Hz budżet spada do 8,3 ms. Gdy nie trafisz w ten limit, użytkownik widzi przycięcia (jank): przewijanie, które „zacina się”, przejścia, które klatkowią, albo gest, który wydaje się opóźniony względem palca.
Dlaczego przegapione klatki tak łatwo zauważyć
Ludzie nie liczą klatek świadomie, ale zauważają niekonsekwencję. Pojedyncza utracona klatka przy wolnym zaniku może być tolerowalna; kilka utraconych klatek podczas szybkiego przewijania jest natychmiast oczywiste. Ekrany o wysokiej częstotliwości odświeżania podnoszą też oczekiwania — gdy użytkownicy doświadczą płynności 120 Hz, niespójne renderowanie wydaje się gorsze niż na 60 Hz.
Główny wątek to zwykły wąskie gardło
Większość frameworków UI nadal polega na głównym/wątku UI do koordynacji wejścia, layoutu i rysowania. Jank pojawia się, gdy ten wątek wykonuje zbyt dużo pracy w jednej klatce:
- Ciężkie przebiegi layoutu: złożone hierarchie widoków, zagnieżdżone kontenery lub częste ponowne układy wywoływane przez zmieniające się ograniczenia/rozmiary.
- Kosztowne animacje: animowanie właściwości, które wymuszają relayout lub ponowne rasteryzowanie zamiast pozwolić GPU obsłużyć transformacje.
- Synchroniczna praca w callbackach UI: parsowanie JSON, formatowanie dużych bloków tekstu lub wykonywanie logiki biznesowej podczas przewijania/gestów.
Frameworki natywne mają zwykle dobrze zoptymalizowane pipeline’y i jaśniejsze dobre praktyki dotyczące przenoszenia pracy z głównego wątku, minimalizowania invalidacji layoutu i używania animacji przyjaznych GPU.
Natywne komponenty kontra UI renderowany niestandardowo
Kluczowa różnica to ścieżka renderowania:
- Natywne komponenty platformy zwykle mapują się bezpośrednio do zoptymalizowanych widgetów OS i systemów kompozycji.
- Podejścia z niestandardowym renderowaniem (częste w stosach cross-platform) mogą dodawać osobne drzewo renderowania, dodatkowe przesyłanie tekstur lub dodatkową pracę przy rekonsyliacji. To może być w porządku — dopóki ekran nie stanie się ciężki animacjami lub listami i narzut nie zacznie konkurować o ciasny budżet klatki.
Gdzie to odczujesz: prawdziwe przykłady ekranów
Złożone listy to klasyczny test obciążeniowy: szybkie przewijanie + ładowanie obrazów + dynamiczne wysokości komórek może tworzyć churn layoutowy i presję pamięci/GC.
Przejścia mogą ujawnić nieefektywności pipeline’u: animacje elementów współdzielonych, rozmyte tła i nałożone cienie są wizualnie bogate, ale mogą skokowo podnieść koszt GPU i overdraw.
Ekrany oparte na gestach (przeciąganie, drag-to-reorder, swipe cards, scrubbery) są bezlitosne, ponieważ UI musi odpowiadać ciągle. Gdy klatki przychodzą późno, UI przestaje być „przypięty” do palca użytkownika — co jest dokładnie tym, czego aplikacje wysokowydajnościowe unikają.
Niskie opóźnienia: dotyk, pisanie, audio i UX w czasie rzeczywistym
Opóźnienie to czas między działaniem użytkownika a reakcją aplikacji. Nie ogólna „szybkość”, lecz przerwa, którą czujesz przy stuknięciu przycisku, wpisaniu znaku, przesunięciu suwaka, narysowaniu pociągnięcia lub zagraniu nuty.
Od wejścia do reakcji: kiedy „szybko” staje się „odczuwalnie dobrze"
Przydatne progi:
- 0–50 ms: wydaje się natychmiastowe. Stuki i pisanie są bezpośrednio połączone z palcem.
- 50–100 ms: zazwyczaj akceptowalne, ale zaczyna się odczuwalna „miękkość”, szczególnie przy przeciąganiu.
- 100–200 ms: zauważalne opóźnienie. Pisanie wydaje się opóźnione; rysowanie linii „goni” rysik.
- 200 ms+: frustrujące. Użytkownicy zwalniają, by skompensować opóźnienie.
Aplikacje krytyczne żyją i umierają przez te przerwy: komunikatory, narzędzia do notatek, trading, nawigacja, narzędzia kreatywne.
Pętle zdarzeń, planowanie i „przeskoki wątku”
Większość frameworków obsługuje wejście na jednym wątku, logikę aplikacji gdzie indziej, a potem prosi UI o aktualizację. Gdy ta ścieżka jest długa lub nieregularna, opóźnienia rosną.
Warstwy cross-platform mogą dodać dodatkowe kroki:
- Wejście przychodzi → tłumaczone na zdarzenia frameworku
- Logika działa w osobnym runtime’ie (z własną pętlą zdarzeń)
- Zmiany stanu są serializowane i odesłane z powrotem
- Aktualizacje UI są planowane później, czasem nie trafiając w następną klatkę
Każde przekazanie („przeskok wątku”) dodaje narzut i, co ważniejsze, jitter — czas odpowiedzi jest zmienny, co często odczuwane jest gorzej niż stałe opóźnienie.
Frameworki natywne mają zwykle krótszą, bardziej przewidywalną ścieżkę od dotyku → aktualizacja UI, bo lepiej pasują do schedulerów OS, systemu wejścia i pipeline’u renderowania.
UX w czasie rzeczywistym: audio, wideo i współpraca na żywo
Niektóre scenariusze mają twarde limity:
- Monitoring audio/instrumenty: round-trip latency często musi pozostać poniżej ~20 ms, by grać się naturalnie.
- Połączenia głosowe/wideo: możesz buforować, by ukryć sieciowe problemy, ale kontrolki UI (mute, głośnik, napisy) muszą reagować natychmiast.
- Współpraca na żywo (dokumenty, tablice): lokalne edycje muszą pojawiać się natychmiast, nawet jeśli synchronizacja zdalna trwa dłużej.
Implementacje native-first ułatwiają skrócenie „critical path” — priorytetyzując wejście i renderowanie nad pracą w tle — tak by interakcje w czasie rzeczywistym pozostały zwarte i wiarygodne.
Głębokie funkcje sprzętowe i OS: natywny jako pierwszy wybór
Weryfikuj UX przed optymalizacją
Szybko zbuduj kluczowe ścieżki, aby optymalizować tylko to, co naprawdę odczuwają użytkownicy.
Wydajność to nie tylko szybkość CPU czy liczba klatek. Dla wielu aplikacji decydujące chwile dzieją się na obrzeżach — tam, gdzie kod dotyka aparatu, czujników, radio i usług systemowych. Te możliwości są projektowane i udostępniane najpierw jako natywne API, a ta rzeczywistość kształtuje, co jest wykonalne (i jak stabilne) w stosach cross-platform.
Dostęp do sprzętu rzadko bywa generyczny
Funkcje takie jak pipeline aparatu, AR, BLE, NFC i czujniki ruchu często wymagają ścisłej integracji ze specyficznymi frameworkami urządzenia. Owijki cross-platform mogą obsługiwać przypadki podstawowe, ale zaawansowane scenariusze zwykle odkrywają luki.
Przykłady, gdzie natywne API mają znaczenie:
- Zaawansowane sterowanie aparatem: ręczne ustawianie ostrości i ekspozycji, zapis RAW, wideo o wysokiej liczbie klatek, strojenie HDR, przełączanie multi-kamer (wide/tele), dane głębi i zachowanie w słabym świetle.
- Doświadczenia AR: możliwości ARKit/ARCore szybko ewoluują (occlusion, wykrywanie płaszczyzn, rekonstrukcja sceny).
- BLE i tryby w tle: skanowanie, zachowanie ponownego łączenia i „działa niezawodnie przy wyłączonym ekranie” często zależą od reguł wykonywania w tle platformy.
- NFC: dostęp do secure element, ograniczenia emulacji kart i zarządzanie sesjami czytnika są mocno specyficzne dla platformy.
- Dane zdrowotne: uprawnienia HealthKit/Google Fit, typy danych i dostarczanie w tle bywają niuansowe i wymagają natywnego podejścia.
Aktualizacje OS pojawiają się najpierw natywnie
Gdy iOS lub Android wprowadzają nowe funkcje, oficjalne API są dostępne natywnie od razu. Warstwy cross-platform mogą potrzebować tygodni (lub dłużej) na dodanie powiązań, aktualizację pluginów i rozpracowanie przypadków brzegowych.
To opóźnienie to nie tylko niedogodność — może stworzyć ryzyko niezawodności. Jeśli wrapper nie został zaktualizowany pod nową wersję systemu, możesz zobaczyć:
- przepływy uprawnień, które przestają działać,
- zadania w tle, które zostają ograniczone,
- crashy wywołane zaktualizowanymi zachowaniami systemu,
- regresje występujące tylko na niektórych modelach urządzeń.
Dla aplikacji krytycznych natywny stack zmniejsza problem „czekania na wrapper” i pozwala zespołom korzystać z nowych funkcji systemu od pierwszego dnia — często decydując, czy funkcja trafi do użytkowników w tym czy następnym kwartale.
Bateria, pamięć i ciepło: wydajność odczuwalna w czasie
Szybkość w krótkim demo to połowa historii. Wydajność, którą pamiętają użytkownicy, to ta, która utrzymuje się po 20 minutach używania — gdy telefon jest ciepły, bateria spada, a aplikacja kilkakrotnie była w tle.
Skąd naprawdę bierze się spadek baterii
Większość „tajemniczych” drenów baterii jest samospowodowana:
- Wake locki i wymykające się timery uniemożliwiają CPU przejście w sen, nawet gdy ekran jest wyłączony.
- Praca w tle, która nigdy nie przestaje (polling, częste sprawdzanie lokalizacji, powtarzające się próby sieciowe) sumuje się szybko.
- Nadmierne przerysowywanie — odbudowywanie UI lub renderowanie animacji częściej niż potrzeba — utrzymuje CPU/GPU w ruchu.
Frameworki natywne zwykle oferują jaśniejsze, bardziej przewidywalne narzędzia do planowania pracy (zadania w tle, job scheduling, odświeżanie zarządzane przez OS), dzięki czemu można wykonać mniej pracy ogółem — i w lepszych momentach.
Presja pamięci: ukryte źródło przycięć
Pamięć wpływa nie tylko na to, czy aplikacja padnie — wpływa też na płynność.
Wiele stosów cross-platform opiera się na runtime’ie zarządzanym z garbage collection (GC). Gdy pamięć narasta, GC może zatrzymać aplikację na chwilę, by posprzątać nieużywane obiekty. Nie musisz znać wnętrza działania, żeby to poczuć: sporadyczne mikro-zamrożenia podczas przewijania, pisania czy przejść.
Aplikacje natywne częściej korzystają z wzorców platformy (np. ARC na Apple), które rozkładają pracę porządkowania bardziej równomiernie. Efektem mogą być rzadsze „niespodziewane” pauzy — zwłaszcza w warunkach ograniczonej pamięci.
Ciepło i utrzymana wydajność
Ciepło to wydajność. W miarę jak urządzenia się nagrzewają, OS może ograniczać prędkości CPU/GPU, a FPS spada. To częste przy długotrwałych obciążeniach jak gry, nawigacja, przetwarzanie obrazu z aparatu czy realtime audio.
Kod natywny może być bardziej energooszczędny, bo może wykorzystywać sprzętowo przyspieszone, dostrojone przez OS API do ciężkich zadań — takie jak natywne pipeline’y odtwarzania wideo, efektywne próbkowanie czujników czy kodeki mediów — redukując marnotrawstwo pracy zamieniające się w ciepło.
Gdy „szybko” znaczy także „chłodno i stabilnie”, natywne frameworki często mają przewagę.
Profilowanie i debugowanie: zobacz prawdziwe wąskie gardła
Zarabiaj kredyty za swoje buildy
Podziel się tym, co zbudowałeś, i zdobądź kredyty do wykorzystania na Koder.ai.
Praca nad wydajnością udaje się lub nie na podstawie widoczności. Frameworki natywne zwykle dostarczają najgłębsze haki do systemu operacyjnego, runtime’u i pipeline’u renderowania — bo są tworzone przez tych samych dostawców, którzy definiują te warstwy.
Dlaczego narzędzia natywne widzą więcej
Aplikacje natywne mogą podłączyć profile do granic, gdzie pojawiają się opóźnienia: główny wątek, wątek renderujący, kompositor systemowy, stack audio czy subsystemy sieci i pamięci masowej. Gdy ścigasz jank, który zdarza się raz na 30 sekund, lub dren baterii pojawiający się tylko na niektórych urządzeniach, ślady „poniżej frameworku” często są jedyną drogą do definitywnej odpowiedzi.
Typowe natywne narzędzia (najczęściej używane)
Nie trzeba ich na pamięć znać, by z nich korzystać, ale warto wiedzieć, co jest dostępne:
- Xcode Instruments (Time Profiler, Allocations, Leaks, Core Animation, Energy Log)
- Debugger Xcode (inspekcja wątków, memory graph, symboliczne breakpointy)
- Android Studio Profiler (CPU, pamięć, sieć, energia)
- Perfetto / System Trace (śledzenie systemowe na Androidzie)
- Narzędzia GPU jak Metal tools w Xcode albo inspektory dostawców GPU (do diagnozy overdraw, kosztów shaderów, tempa klatek)
Narzędzia te odpowiadają na konkretne pytania: „Która funkcja jest gorąca?”, „Który obiekt nigdy nie jest zwalniany?”, „Która klatka przekroczyła deadline i dlaczego?”.
„Ostatnie 5%" bugów: zamrożenia, wycieki i utraty klatek
Najtrudniejsze problemy wydajnościowe często chowają się w przypadkach brzegowych: rzadki deadlock synchronizacji, wolne parsowanie JSON na głównym wątku, pojedynczy widok wywołujący kosztowny layout, albo wyciek pamięci widoczny dopiero po 20 minutach użycia.
Natywne profilowanie pozwala korelować symptomy (zawieszenie lub jank) z przyczynami (konkretne stosy wywołań, wzorce alokacji czy piki GPU) zamiast polegać na metodzie prób i błędów.
Szybsze poprawki dla problemów o dużym wpływie
Lepsza widoczność skraca czas naprawy, bo zamienia dyskusje w dowody. Zespoły mogą złapać ślad, udostępnić go i szybko dojść do przyczyny — często redukując dni spekulacji do konkretnej poprawki i mierzalnego wyniku przed/po.
Niezawodność na skalę: urządzenia, aktualizacje OS i przypadki brzegowe
Wysyłając aplikację do milionów telefonów, nie tylko wydajność zawodzi — zawodzi spójność. Ta sama aplikacja może zachowywać się inaczej na różnych wersjach OS, modyfikacjach OEM i sterownikach GPU. Niezawodność na skalę to utrzymanie przewidywalności, gdy ekosystem nią nie jest.
Dlaczego „ten sam Android/iOS” nie jest naprawdę taki sam
Na Androidzie nakładki OEM mogą zmieniać limity w tle, powiadomienia, wybór plików i zarządzanie energią. Dwa urządzenia z „tą samą” wersją Androida mogą się różnić, bo producenci dostarczają różne składniki systemowe i poprawki.
GPU dodają kolejną zmienną. Sterowniki dostawców (Adreno, Mali, PowerVR) mogą się różnić w precyzji shaderów, formatach tekstur i sposobach optymalizacji. Ścieżka renderowania, która wydaje się w porządku na jednym GPU, może pokazywać migotanie, banding lub rzadkie crashy na innym — zwłaszcza przy wideo, aparacie i grafice niestandardowej.
iOS jest bardziej zwarty, ale aktualizacje systemu też zmieniają zachowanie: przepływy uprawnień, quirki klawiatury/autouzupełniania, reguły sesji audio i polityki zadań w tle mogą się subtelnie różnić między wersjami.
Dlaczego natywnie bywa bardziej przewidywalnie w przypadkach brzegowych
Platformy natywne expose’ują „prawdziwe” API pierwsze. Gdy OS się zmienia, natywne SDK i dokumentacja zwykle odzwierciedlają to natychmiast, a narzędzia platformy (Xcode/Android Studio, logi systemowe, symbole crashów) zgadzają się z tym, co działa na urządzeniu.
Stosy cross-platform dodają kolejną warstwę tłumaczącą: framework, jego runtime i wtyczki. Gdy pojawia się przypadek brzegowy, debugujesz zarówno swoją aplikację, jak i most.
Ryzyko zależności: aktualizacje, breaking changes i jakość wtyczek
Aktualizacje frameworków mogą wprowadzać zmiany w runtime’ie (wątki, renderowanie, obsługa tekstu, gesty), które zawiodą tylko na niektórych urządzeniach. Wtyczki bywają gorsze: jedne są cienkimi opakowaniami, inne osadzają ciężki natywny kod o niestabilnym utrzymaniu.
Lista kontrolna: weryfikacja bibliotek trzecich w krytycznych ścieżkach
- Utrzymanie: niedawne wydania, aktywne triage issue, jasna odpowiedzialność.
- Paralelność natywna: używa oficjalnych API platformy (nie prywatnych/hackowanych)
- Wydajność: benchmarki, unika dodatkowych kopii/alokacji, minimalne wywołania przez mostek
- Tryby awarii: łagodne fallbacky, timeouty i raportowanie błędów
- Kompatybilność: testy na wersjach OS, urządzeniach OEM i vendorach GPU
- Obserwowalność: logi, symbole crashów i powtarzalne przypadki testowe
- Bezpieczeństwo aktualizacji: dyscyplina semver, changelogi, notatki migracyjne
Na dużą skalę niezawodność rzadko dotyczy pojedynczego buga — to redukcja liczby warstw, gdzie mogą ukryć się niespodzianki.
Grafika, multimedia i ML: kiedy natywność to jasna przewaga
Stwórz backend Go + Postgres
Wygeneruj backend w Go + PostgreSQL z poziomu czatu i utrzymaj responsywność frontendu.
Niektóre obciążenia karzą nawet małe narzuty. Jeśli aplikacja potrzebuje utrzymania wysokiego FPS, intensywnej pracy GPU lub ścisłej kontroli nad dekodowaniem i buforami, natywne frameworki zwykle wygrywają, bo mogą korzystać z najszybszych ścieżek platformy bez pośredników.
Obciążenia, które wyraźnie faworyzują natywny stack
Natywność jest oczywistym wyborem dla scen 3D, doświadczeń AR, gier o wysokim FPS, edycji wideo i aplikacji skupionych na aparacie z filtrami w czasie rzeczywistym. Te przypadki nie są tylko „ciężkie obliczeniowo” — są ciężkie pipeline’owo: przesuwasz duże tekstury i klatki między CPU, GPU, kamerą i enkoderami dziesiątki razy na sekundę.
Dodatkowe kopie, spóźnione klatki lub niesynchroniczne synchronizacje objawiają się od razu jako utracone klatki, przegrzewanie lub opóźnione sterowanie.
Bezpośredni dostęp do API GPU, kodeków i akceleracji
Na iOS kod natywny może rozmawiać z Metal i systemowym stackiem mediów bez pośrednich warstw. Na Androidzie ma dostęp do Vulkan/OpenGL oraz kodeków i akceleracji sprzętowej przez NDK i API mediów.
To ma znaczenie, ponieważ wysyłanie komend GPU, kompilacja shaderów i zarządzanie teksturami są wrażliwe na to, jak aplikacja harmonogramuje pracę.
Pipeline renderowania i upload tekstur (wysoki poziom)
Typowy pipeline realtime to: przechwyć lub załaduj klatki → konwertuj formaty → upload tekstur → uruchom shadery GPU → kompozycja UI → prezentuj.
Kod natywny może zmniejszyć narzut, utrzymując dane w formatach przyjaznych GPU dłużej, grupując wywołania rysowania i unikając powtarzanych uploadów tekstur. Nawet jedna niepotrzebna konwersja (np. RGBA ↔ YUV) na klatkę może dodać wystarczający koszt, by zepsuć płynne odtwarzanie.
Inference ML: przepustowość, opóźnienie i energia
On-device ML często zależy od delegatów/ backendów (Neural Engine, GPU, DSP/NPU). Integracja natywna zwykle udostępnia je szybciej i z większą liczbą opcji strojenia — ważne, gdy zależy ci zarówno na latencji inference, jak i na baterii.
Strategia hybrydowa: natywne moduły dla hotspotów
Nie zawsze potrzebujesz w pełni natywnej aplikacji. Wiele zespołów trzyma UI cross-platform dla większości ekranów, a dodaje natywne moduły dla hotspotów: pipeline aparatu, niestandardowe renderery, silniki audio czy inference ML.
To pozwala osiągnąć wydajność bliską natywnej tam, gdzie to konieczne, bez przepisywania wszystkiego.
Wybór właściwego podejścia: natywny, cross-platform czy hybryda
Wybór frameworka to mniej ideologia, a więcej dopasowania oczekiwań użytkownika do tego, co urządzenie musi robić. Jeśli Twoja aplikacja wydaje się natychmiastowa, pozostaje chłodna i działa płynnie pod obciążeniem, użytkownicy rzadko pytają, z czego jest zbudowana.
Praktyczna macierz decyzyjna
Zadaj sobie te pytania, by szybko zawęzić wybór:
- Oczekiwania użytkowników: Czy to aplikacja „użytkowa”, gdzie sporadyczne przycięcia są akceptowalne, czy doświadczenie, gdzie jank łamie zaufanie (bankowość, nawigacja, współpraca na żywo, narzędzia twórców)?
- Potrzeby sprzętowe: Czy potrzebujesz pipeline’u aparatu, peryferiów Bluetooth, czujników, przetwarzania w tle, niskolatencyjnego audio, AR lub ciężkiej pracy GPU? Im bliżej metalu, tym więcej zysku daje natywność.
- Harmonogram i tempo iteracji: Cross-platform może skrócić time-to-market dla prostszych UI i współdzielonych przepływów. Natywne może być szybsze do tuningu wydajności, bo pracujesz bezpośrednio z narzędziami i API platformy.
- Umiejętności zespołu i rekrutacja: Silny zespół iOS/Android szybciej wyda wysokiej jakości natywny kod. Mały zespół z doświadczeniem webowym może szybciej osiągnąć MVP z cross-platform — jeśli wymagania wydajnościowe są umiarkowane.
Jeśli prototypujesz wiele kierunków, warto najpierw zweryfikować przepływy produktu, zanim zainwestujesz w głęboką natywną optymalizację. Przykładowo, zespoły czasem używają Koder.ai do szybkiego postawienia działającej aplikacji webowej (React + Go + PostgreSQL) przez czat, testowania UX i modelu danych, a potem przechodzą do natywnej lub hybrydowej mobilnej budowy, gdy krytyczne ekrany są jasne.
Co naprawdę oznacza „hybryda" (i dlaczego często wygrywa)
Hybryda nie musi znaczyć „web wewnątrz aplikacji”. Dla produktów krytycznych pod względem wydajności hybryda często oznacza:
- Natywne jądro + współdzielona logika biznesowa: Sieciowanie, stan i logika domenowa są współdzielone, podczas gdy UI i części wrażliwe na wydajność pozostają natywne.
- Natywna powłoka + współdzielone UI tam, gdzie to bezpieczne: Używaj współdzielonego UI dla ekranów statycznych lub formularzy, a zachowaj widoki ciężkie animacjami lub realtime jako natywne.
To podejście ogranicza ryzyko: możesz zoptymalizować najgorętsze ścieżki bez przepisywania wszystkiego.
Najpierw mierz, potem decyduj
Zanim się zobowiążesz, zbuduj mały prototyp najtrudniejszego ekranu (np. live feed, timeline edytora, mapa + nakładki). Zmierz stabilność klatek, opóźnienia, pamięć i baterię podczas 10–15 minut sesji. Użyj tych danych — nie przypuszczeń — by zdecydować.
Jeśli korzystasz z narzędzia wspomaganego AI jak Koder.ai do wczesnych iteracji, traktuj je jako mnożnik prędkości do eksplorowania architektury i UX — nie jako zastępstwo dla profilowania na urządzeniach. Gdy celujesz w doświadczenie krytyczne pod względem wydajności, ta sama zasada: mierz na rzeczywistych urządzeniach, ustal budżety wydajności i trzymaj ścieżki krytyczne (renderowanie, wejście, media) jak najbliżej natywu, jak wymagania tego potrzebują.
Unikaj przedwczesnej optymalizacji
Zacznij od poprawności i obserwowalności aplikacji (podstawowe profilowanie, logowanie i budżety wydajności). Optymalizuj tylko wtedy, gdy wskażesz wąskie gardło odczuwalne dla użytkowników. To zapobiega spędzaniu tygodni na szlifowaniu milisekund w kodzie, który nie leży na krytycznej ścieżce.
Często zadawane pytania
Co w praktyce znaczy „performance-critical”?
Oznacza to, że doświadczenie użytkownika rozpada się, gdy aplikacja jest nawet nieznacznie wolna lub niestabilna. Małe opóźnienia mogą powodować utratę chwili (aparat), błędne decyzje (trading) lub utratę zaufania (nawigacja), ponieważ wydajność jest bezpośrednio widoczna w kluczowej interakcji.
Dlaczego natywne frameworki często wydają się szybsze niż rozwiązania cross-platform?
Ponieważ komunikują się bezpośrednio z API platformy i pipeline’em renderowania, bez dodatkowych warstw tłumaczących. To zwykle oznacza:
- niższe opóźnienie od dotyku do reakcji
- bardziej przewidywalne tempo klatek (mniej janku)
- lepszy dostęp do OS-owych ścieżek medialnych/GPU/sprzętu
- mniej niespodzianek wynikających z dodatkowych runtime’ów i mostów
Skąd zwykle bierze się narzut w rozwiązaniach cross-platform?
Typowe źródła to:
- Wywołania przez mostek / przełączanie kontekstu między runtime’ami
- Serializacja/kopiowanie danych podczas przekazywania
- Dodatkowe drzewa UI (reconciliation/diffing + praca przy layout)
- Zatrzymania runtime’u (np. garbage collection), które trafiają w zły moment
Pojedynczo to małe koszty, ale kumulują się, gdy występują przy każdej klatce czy geście.
Czym jest „jank” i dlaczego jest tak zauważalny na nowoczesnych telefonach?
Płynność polega na trafianiu w deadline klatki konsekwentnie. Przy 60 Hz masz ~16,7 ms na klatkę; przy 120 Hz ~8,3 ms. Gdy przegapisz, użytkownik widzi przycięcia podczas przewijania, animacji lub gestów—często bardziej zauważalne niż nieco wolniejsze ładowanie.
Dlaczego główny/wątek UI jest częstym wąskim gardłem?
Wąskie gardło bywa na głównym wątku/UI, bo to on koordynuje wejście, layout i rysowanie. Jank pojawia się, gdy robisz tam za dużo, np.:
- ciężkie przebiegi layoutu w złożonych hierarchiach
- kosztowne animacje wymuszające relayout lub re-rasteryzację
- synchroniczna praca w callbackach UI (parsowanie JSON, formatowanie, logika biznesowa)
Utrzymanie głównego wątku przewidywalnego to zwykle największy zysk w płynności.
Jak szybko aplikacja musi reagować, żeby wydawać się „natychmiastowa”?
Opóźnienie to odczuwana przerwa między akcją użytkownika a reakcją aplikacji. Przydatne progi:
- 0–50 ms: wydaje się natychmiastowe
- 50–100 ms: zwykle OK, ale „miękkie” przy przeciąganiu
- 100–200 ms: zauważalne opóźnienie
- 200 ms+: frustrujące
Aplikacje krytyczne optymalizują całą ścieżkę input → logika → render, aby odpowiedzi były szybkie i przewidywalne (mały jitter).
Dlaczego zaawansowane funkcje sprzętowe skłaniają zespoły ku natywności?
Wiele funkcji sprzętowych jest najpierw natywna i szybko się rozwija: zaawansowane sterowanie aparatem, AR, zachowanie BLE w tle, NFC i API zdrowotne. Wrappersy cross-platform mogą obsługiwać podstawy, ale zaawansowane lub brzegowe zachowania często wymagają bezpośrednich natywnych API, by były niezawodne i aktualne.
Jak aktualizacje systemu operacyjnego wpływają na niezawodność natywnego vs cross-platform?
Aktualizacje OS udostępniają API natywnie od razu, podczas gdy wiązania/wtyczki cross-platform mogą się opóźniać. To może powodować:
- opóźniony dostęp do nowych funkcji
- psujące się przepływy uprawnień/tryby w tle po zmianach systemu
- awarie lub regresje urządzeniowe do czasu aktualizacji wrappera
Natywność zmniejsza ryzyko „czekania na wrapper” dla krytycznych funkcji.
Dlaczego bateria, pamięć i ciepło mają znaczenie dla „prawdziwej” wydajności?
Utrzymanie wydajności w czasie to kwestia efektywności:
- Zużycie baterii: blokady budzenia, częste odpytywanie, nadmierne odświeżania
- Presja pamięci: może powodować zatrzymania i przycięcia (często gorzej przy GC)
- Ciepło / throttling: długie sesje obniżają zegary CPU/GPU i klatkarz
Natywne API zwykle pozwalają lepiej planować pracę i używać OS-owych, przyspieszonych ścieżek multimedialnych/graficznych, które zużywają mniej energii.
Czy można uzyskać wydajność bliską natywnej bez pełnego przejścia na natywność?
Tak. Wiele zespołów stosuje strategię hybrydową:
- używają cross-platform tam, gdzie ryzyko jest niskie (formy, ustawienia)
- implementują natywne moduły dla gorących punktów (pipeline aparatu, niestandardowy renderer, silnik audio, inference ML)
- prototypują najtrudniejszy ekran i mierzą stabilność klatek, opóźnienia, pamięć i baterię przed ostateczną decyzją
Dzięki temu inwestujesz w natywność tam, gdzie ma największe znaczenie, bez przepisywania całej aplikacji.