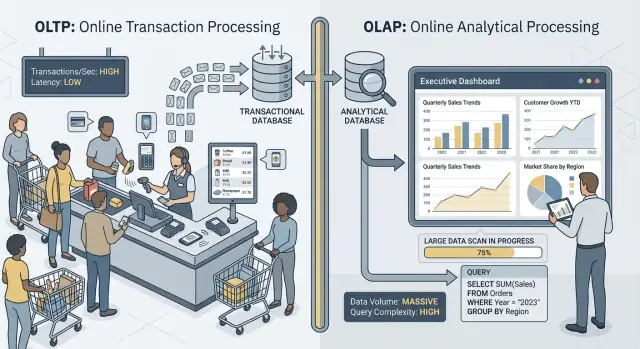
OLTP vs OLAP: czym są (bez żargonu)
Kiedy mówimy „OLTP” i „OLAP”, chodzi o dwa bardzo różne sposoby używania bazy danych.
OLTP: baza, która napędza biznes
OLTP (Online Transaction Processing) to obciążenie obsługujące codzienne działania, które muszą być szybkie i poprawne za każdym razem. Pomyśl: „zapisz tę zmianę teraz”.
Typowe zadania OLTP to tworzenie zamówienia, aktualizacja stanu magazynowego, zapis płatności czy zmiana adresu klienta. Operacje są zwykle małe (kilka wierszy), częste i muszą odpowiadać w milisekundach, bo ktoś — użytkownik lub system — czeka.
OLAP: baza, która wyjaśnia biznes
OLAP (Online Analytical Processing) to obciążenie służące do zrozumienia, co się stało i dlaczego. Pomyśl: „przeskanuj dużo danych i podsumuj je”.
Typowe zadania OLAP to panele administracyjne, raporty trendów, analiza kohort, prognozowanie i pytania typu „jak zmieniły się przychody według regionu i kategorii produktu w ciągu ostatnich 18 miesięcy?”. Zapytania te często czytają wiele wierszy, wykonują ciężkie agregacje i mogą trwać sekundy (lub minuty) bez bycia „niepoprawnymi”.
Te same dane, inne cele — i inne potrzeby
Główna idea jest prosta: OLTP optymalizuje szybkie, spójne zapisy i małe odczyty, podczas gdy OLAP optymalizuje duże odczyty i złożone obliczenia. Ponieważ cele są różne, najlepsze ustawienia bazy, indeksy, układ przechowywania i sposób skalowania często też będą inne.
Warto też zwrócić uwagę na słowo: rzadko, nie nigdy. Małe zespoły mogą przez jakiś czas dzielić jedną bazę, szczególnie przy niewielkich wolumenach danych i dyscyplinie zapytań. W dalszych częściach opisano, co psuje się najpierw, typowe wzorce separacji i jak bezpiecznie przenieść raportowanie poza produkcję.
Krótkie przykłady
- Checkout (OLTP): klient klika „Zapłać”, a aplikacja zapisuje zamówienie, status płatności i aktualizacje magazynu.
- Panel raportowy (OLAP): manager otwiera panel agregujący tysiące (lub miliony) zamówień, by pokazać konwersję, średnią wartość zamówienia i trendy tygodniowe.
Inne cele, inne metryki sukcesu
OLTP i OLAP mogą oba „używać SQL”, ale są zoptymalizowane do różnych zadań — i to widać po tym, co każde z nich uznaje za sukces.
OLTP: szybkość, współbieżność i poprawność
Systemy OLTP napędzają codzienne operacje: ścieżki zakupowe, aktualizacje kont, rezerwacje, narzędzia wsparcia. Priorytety są jasne:
- Szybkie czasy odpowiedzi dla małych odczytów/zapisów (milisekundy)
- Wiele współbieżnych użytkowników bez spowolnień
- Poprawność i spójność, bo błędny stan konta lub zdublowane zamówienie to realny problem biznesowy
Sukces mierzy się często metrykami opóźnień jak p95/p99, wskaźnikiem błędów i zachowaniem systemu przy dużej współbieżności.
OLAP: skanowanie, agregowanie i elastyczność
Systemy OLAP odpowiadają na pytania typu „Co zmieniło się w tym kwartale?” lub „Który segment zwiększył churn po zmianie cen?”. Zapytania te często:
- Skanują duże ilości danych po wielu wierszach
- Wykonują agregacje (SUM, COUNT, percentyle) i złączenia
- Często się zmieniają, gdy analitycy eksplorują i doprecyzowują pytania
Sukces tutaj to raczej przepustowość zapytań, czas do insightu i możliwość uruchamiania złożonych zapytań bez ręcznego tuningu każdego raportu.
Dlaczego „jeden system do wszystkiego” tworzy kompromisy
Gdy zmuszasz jedną bazę do obsługi obu obciążeń, oczekujesz od niej jednocześnie świetnej obsługi małych, częstych transakcji i dużych, eksploracyjnych skanów. Rezultat zwykle to kompromis: OLTP dostaje nieprzewidywalne opóźnienia, OLAP jest ograniczany, by chronić produkcję, a zespoły zaczynają się spierać, które zapytania są „dozwolone”. Osobne cele zasługują na osobne metryki sukcesu — i zwykle na osobne systemy.
Konflikt o zasoby: kiedy analityka „zabiera” transakcje
Gdy OLTP (transakcje aplikacji) i OLAP (raportowanie i analizy) działają w tej samej bazie, walczą o te same ograniczone zasoby. Efektem nie jest tylko „wolniejsze raportowanie”. Często to wolniejsze finalizacje zamówień, zablokowane logowania i nieprzewidywalne problemy aplikacji.
CPU i pamięć: długie zapytania kontra krótkie
Zapytania analityczne są długotrwałe i zasobożerne: złączenia dużych tabel, agregacje, sortowanie i grupowanie. Mogą zawłaszczyć rdzenie CPU i pamięć potrzebną do hash joinów czy buforów sortowania.
Tymczasem zapytania transakcyjne są zwykle krótkie i wrażliwe na opóźnienia. Jeśli CPU jest zajęty lub presja pamięci wymusza częste wyrzucanie danych, drobne zapytania zaczynają czekać za dużymi — nawet jeśli każde z nich potrzebuje tylko kilku milisekund pracy.
Dysk I/O: duże skany kontra wiele małych odczytów/zapisów
Analityka często powoduje skany tabel i sekwencyjne odczyty wielu stron. OLTP robi odwrotnie: wiele małych, losowych odczytów oraz stałe zapisy do indeksów i logów.
Połączenie tych wzorców zmusza podsystem magazynu do żonglowania niekompatybilnymi dostępami. Cache, które pomagały OLTP, mogą zostać „wymyte” przez skany analityczne, a opóźnienia zapisu rosną, gdy dysk jest zajęty strumieniowaniem danych dla raportów.
Presja na pule połączeń i kolejkowanie
Kilku analityków uruchamiających szerokie zapytania może zablokować połączenia na kilka minut. Jeśli aplikacja używa puli o stałym rozmiarze, żądania ustawiają się w kolejce, czekając na wolne połączenie. To kolejkowanie może sprawić, że system wydaje się zepsuty: średnie opóźnienie może wyglądać akceptowalnie, ale ogony (p95/p99) stają się bolesne.
Co użytkownicy naprawdę zauważają
Na zewnątrz objawia się to timeoutami, wolniejszymi flowami płatności, opóźnionymi wynikami wyszukiwania i ogólnie zawodną pracą — często „tylko podczas raportów” albo „tylko pod koniec miesiąca”. Zespół aplikacji widzi błędy; analitycy widzą wolne zapytania; prawdziwy problem to współdzielona konkurencja o zasoby.
Układ danych i potrzeby indeksowania idą w przeciwnych kierunkach
OLTP i OLAP nie tylko „używają bazy inaczej” — preferują przeciwne projekty fizyczne. Gdy próbujesz zaspokoić obie potrzeby w jednym miejscu, zwykle kończysz kompromisem, który jest kosztowny i nadal niedostateczny.
OLTP: zoptymalizowany pod szybkie wybory selektywne
Obciążenie transakcyjne dominuje krótkimi zapytaniami, które dotykają niewielkiego fragmentu danych: pobierz jedno zamówienie, zaktualizuj wiersz magazynu, wypisz ostatnie 20 zdarzeń dla jednego użytkownika.
To kieruje schemat OLTP w stronę przechowywania wierszowego i indeksów wspierających wyszukiwania punktowe i małe skany zakresowe (często na kluczach podstawowych, kluczach obcych i kilku wartościowych indeksach pomocniczych). Celem jest przewidywalne, niskie opóźnienie — szczególnie dla zapisów.
OLAP: zoptymalizowany pod skanowanie, grupowanie i podsumowania
Obciążenie analityczne często potrzebuje przeczytać wiele wierszy i tylko kilka kolumn: „przychody według tygodnia i regionu”, „konwersja według kampanii”, „top produkt według marży”.
Systemy OLAP korzystają z przechowywania kolumnowego (czytasz tylko potrzebne kolumny), partycjonowania (szybkie odrzucanie starych lub nieistotnych danych) i wstępnych agregacji (materializowane widoki, rollupy, tabele podsumowań), by raporty nie liczyły stale tych samych sum.
Dlaczego „indeksuj wszystko” się nie sprawdza
Reakcją bywa dodawanie indeksów, aż każdy dashboard będzie szybki. Ale każdy indeks zwiększa koszty zapisów: insert/update/delete musi utrzymywać więcej struktur. Zwiększa też koszty przechowywania i spowalnia zadania konserwacyjne jak vacuum, reindex czy backup.
Planery zapytań i dryf statystyk (prosto)
Bazy wybierają plany zapytań na podstawie statystyk — oszacowań, ile wierszy pasuje do filtra, jak selektywny jest indeks i jak rozkładają się dane. OLTP zmienia dane ciągle. Gdy rozkłady się przesuwają, statystyki mogą dryfować, a planner może wybrać plan świetny dla wczoraj, ale wolny dla dzisiaj.
Gdy dorzucisz ciężkie zapytania OLAP skanujące i łączące duże tabele, zmienność rośnie: „najlepszy plan” staje się trudniejszy do przewidzenia, a strojenie pod jedno obciążenie często szkodzi drugiemu.
Blokady, MVCC i efekt uboczny konserwacji
Nawet jeśli twoja baza „wspiera współbieżność”, mieszanie ciężkiego raportowania z żywymi transakcjami tworzy subtelne spowolnienia, które trudno przewidzieć — i jeszcze trudniej wytłumaczyć klientowi patrzącemu na kręcące się kółko w checkout.
Długie zapytania dalej powodują problemy z blokadami
Zapytania w stylu OLAP często skanują wiele wierszy, łączą tabele i trwają sekundy lub minuty. W tym czasie mogą trzymać blokady (np. na obiektach schematu lub gdy sortują/agregują do tymczasowych struktur) i często pośrednio zwiększają konkurencję o blokady, utrzymując wiele wierszy „w grze”.
Nawet przy MVCC (multi-version concurrency control) baza musi śledzić wiele wersji tego samego wiersza, żeby czytelnicy i zapisy nie blokowali się nawzajem. To pomaga, ale nie eliminuje konkurencji — zwłaszcza gdy zapytania dotykają „gorących” tabel, które transakcje aktualizują non stop.
MVCC ma ukryty koszt: sprzątanie staje się trudniejsze
MVCC oznacza, że stare wersje wierszy pozostają dopóki baza nie może ich bezpiecznie usunąć. Długotrwały raport może utrzymać stary snapshot otwarty, co zapobiega usuwaniu starych wersji.
To wpływa na:
- Vacuum/garbage collection: sprzątanie nie może szybko usuwać martwych tupli/wersji.
- Bloat/fragmentację: magazyn rośnie, indeksy tracą efektywność, a cache staje się mniej użyteczny.
- Nacisk na kompakcję: niektóre silniki wykonują cięższą pracę w tle, co zabiera I/O i CPU transakcjom.
Efekt to podwójny cios: raportowanie obciąża bazę i z czasem spowalnia system.
Poziomy izolacji zwiększają zmienność opóźnień
Narzędzia raportujące często żądają silniejszej izolacji (albo przez przypadek uruchamiają długą transakcję). Wyższa izolacja może zwiększyć oczekiwanie na blokady i ilość wersjonowania, które musi obsłużyć silnik. Ze strony OLTP widzisz to jako nieprzewidywalne skoki: większość zamówień zapisuje się szybko, a kilka nagle stoi.
Praktyczny przykład: raporty na koniec miesiąca spowalniają zamówienia
Na koniec miesiąca dział finansów uruchamia zapytanie „przychód według produktu” skanujące zamówienia i pozycje za cały miesiąc. Gdy ono trwa, nowe zapisy zamówień są nadal akceptowane, ale vacuum nie może odzyskać starych wersji i indeksy się zużywają. API zamówień zaczyna mieć sporadyczne timeouty — nie dlatego, że jest „wyłączone”, ale dlatego, że konkurencja i koszty sprzątania cicho przepychają opóźnienia poza akceptowalny limit.
Pikowość obciążeń i nieprzewidywalne opóźnienia
Pick a tier that fits
Try Koder.ai free, then move to Pro, Business, or Enterprise when you need more.
Systemy OLTP żyją i umierają dzięki przewidywalności. Checkout, ticket wsparcia czy aktualizacja salda nie są „w porządku na ogół” jeśli są szybkie tylko 95% czasu — użytkownicy zauważą wolne chwile. OLAP z kolei jest często wybuchowy: kilka ciężkich zapytań może przez godzinę milczeć, a potem nagle zażądać dużo CPU, pamięci i I/O.
Pikowanie zdarza się z normalnych powodów
Ruch analityczny ma tendencję do skumulowania się wokół rutyn:
- Poranne „standupowe” panele, gdy wiele osób odświeża te same wykresy
- Zaplanowane raporty uruchamiane na początku godziny
- Zamknięcia miesiąca i przeglądy kwartalne, które uruchamiają długie skany i złączenia
Tymczasem ruch OLTP jest zwykle bardziej równomierny. Gdy oba obciążenia współdzielą bazę, te analityczne piki przekładają się na nieprzewidywalne opóźnienia dla transakcji — timeouty, wolniejsze strony i ponowienia, które generują dodatkowe obciążenie.
Dlaczego limity i harmonogramy pomagają — ale nie rozwiązują problemu
Możesz zmniejszyć skutki takimi taktykami jak uruchamianie raportów nocą, ograniczanie współbieżności, egzekwowanie timeoutów zapytań czy ustawienie limitów kosztu zapytań. To dobre zabezpieczenia, zwłaszcza przy „raportowaniu na produkcji”.
Ale nie usuwają podstawowego napięcia: zapytania OLAP są projektowane, by wykorzystywać dużo zasobów do odpowiedzi na duże pytania, a OLTP potrzebuje małych, szybkich kawałków zasobów przez cały dzień. Gdy niespodziewane odświeżenie panelu, ad-hoc zapytanie lub backfill przeniknie ochronę, współdzielona baza znów jest narażona.
Problem „hałaśliwego sąsiada"
Na współdzielonej infrastrukturze jeden „hałaśliwy” użytkownik analityczny lub zadanie może zdominować cache, nasycić dysk lub obciążyć CPU — nie robiąc nic złego. OLTP staje się ofiarą uboczną, a najtrudniejsze jest to, że awarie wyglądają losowo: skoki opóźnień zamiast jasnych, powtarzalnych błędów.
Złożoność operacyjna: kopie zapasowe, bezpieczeństwo i planowanie pojemności
Mieszanie OLTP i OLAP nie tylko tworzy problemy z wydajnością — komplikuje też codzienne operacje. Baza staje się „pudełkiem na wszystko”, a każde zadanie operacyjne dziedziczy ryzyka obu obciążeń.
Backupy, przywracanie i odzyskiwanie po awarii zwalniają
Tabele analityczne często rosną szeroko i szybko (więcej historii, kolumn, agregatów). Ten dodatkowy wolumen zmienia twoją strategię odzyskiwania.
Pełny backup trwa dłużej, zużywa więcej przestrzeni i zwiększa szansę na niezałapanie okna backupu. Przywracanie jest gorsze: przy szybkim odzysku przywracasz nie tylko dane transakcyjne potrzebne aplikacji, ale też duże zbiory analityczne, które nie są konieczne do podstawowego działania biznesu. Testy DR też trwają dłużej, więc wykonywane są rzadziej — dokładne przeciwieństwo tego, co chcesz.
Planowanie pojemności staje się wróżeniem z fusów
Wzrost transakcyjny jest zwykle przewidywalny: więcej klientów, więcej zamówień, więcej wierszy. Wzrost analityczny jest często nierównomierny: nowy panel, zmiana polityki retencji, albo jedna drużyna decyduje się przechować „jeszcze rok” surowych zdarzeń.
Gdy oba żyją razem, trudno odpowiedzieć na pytania:
- Czy rośniemy, bo produkt odnosi sukces, czy bo raporty przechowują więcej historii?
- Potrzebujemy szybszego storage dla transakcji, czy więcej taniego storage dla analityki?
Ta niepewność prowadzi do nadprowizjonowania (płacenia za zapas, którego nie potrzebujesz) lub niedoprowizjonowania (niespodziewane outage'y).
Zabezpieczenia trudniej egzekwować uczciwie
W współdzielonej bazie jedno „niewinne” zapytanie może stać się incydentem. W końcu dodasz zabezpieczenia takie jak timeouty, limity zapytań, harmonogramy czy zasady zarządzania obciążeniem. Pomagają, ale są kruche: aplikacja i analitycy konkurują teraz o te same limity, a zmiana polityki dla jednej grupy może zepsuć drugą.
Bezpieczeństwo i kontrola dostępu się komplikują
Aplikacje zazwyczaj potrzebują wąskich, precyzyjnych uprawnień. Analitycy często potrzebują szerokiego dostępu do odczytu, czasem w wielu tabelach, by eksplorować i weryfikować. Umieszczając oba w jednej bazie zwiększasz presję na nadawanie większych uprawnień „żeby raport działał”, powiększając ryzyko błędów i powiększając liczbę osób widzących wrażliwe dane.
Skalowanie i koszty: często płacisz dwa razy (albo gorzej)
Protect production from dashboards
Set a clear reporting boundary so dashboards do not slow checkouts.
Próba obsłużenia OLTP i OLAP w tej samej bazie często wygląda taniej — dopóki nie zaczniesz skalować. Problem to nie tylko wydajność. To, że każdy rodzaj obciążenia skaluje się inaczej, zmusza do drogich kompromisów.
Skalowanie OLTP jest napędzane zapisami (i bywa bolesne)
Systemy transakcyjne są ograniczone przez zapisy: wiele małych aktualizacji, surowe wymagania opóźnień i piki, które trzeba natychmiast obsłużyć. Skalowanie OLTP zwykle oznacza zwiększanie zasobów pionowo (mocniejsze CPU, szybsze dyski, więcej pamięci), bo obciążenia zapisów trudno rozproszyć.
Gdy osiągniesz limity pionowe, rozwiązania to sharding lub inne wzorce skalowania zapisów. To dodaje koszt inżynieryjny i często wymaga zmian w aplikacji.
Skalowanie OLAP jest napędzane obliczeniami (i często elastyczne)
Obciążenia analityczne skalują inaczej: długie skany, ciężkie agregacje i duża przepustowość odczytu. Systemy OLAP zwykle skalują, dodając rozproszone zasoby obliczeniowe, a wiele nowoczesnych rozwiązań oddziela compute od storage, więc możesz zwiększać moc zapytań bez duplikowania danych.
Jeśli OLAP dzieli bazę z OLTP, nie możesz skalować analityki niezależnie. Skalujesz całą bazę — nawet jeśli transakcje działają dobrze.
Ukryty rachunek: płacisz za zasoby klasy OLTP dla analityki
Aby utrzymać transakcje szybkie przy równoczesnym raportowaniu, zespoły nadprowizjonowują bazę produkcyjną: dodatkowe CPU, wysokiej klasy storage i większe instancje „na wszelki wypadek”. To znaczy, że płacisz ceny OLTP, by obsługiwać OLAP.
Separacja pozwala dobrać rozmiar do zadania: OLTP dla przewidywalnych, niskolatencyjnych zapisów, OLAP dla wybuchowych, ciężkich odczytów. Efekt często jest tańszy ogólnie — mimo że to „dwa systemy” — bo przestajesz kupować wysokiej klasy zasoby transakcyjne dla raportowania na produkcji.
Popularne architektury oddzielające OLTP i OLAP
Większość zespołów oddziela obciążenie transakcyjne (OLTP) od analitycznego (OLAP), dodając drugi system „zorientowany na odczyt”, zamiast zmuszać jedną bazę do obsługi obu.
Wzorzec 1: replika do odczytu dla raportowania
Częsty pierwszy krok to replika do odczytu (follower) bazy OLTP, na której uruchamia się narzędzia BI.
Zalety: minimalne zmiany w aplikacji, znajome SQL, szybkie do wdrożenia.
Wady: to wciąż ten sam silnik i schemat, więc ciężkie raporty mogą nasycić CPU/I/O repliki; niektóre raporty potrzebują funkcji niedostępnych na replikach; opóźnienie replikacji może oznaczać, że liczby są opóźnione o minuty lub więcej, co prowadzi do pytań „dlaczego nie zgadza się z produkcją?”.
Najlepsze dopasowanie: małe zespoły, umiarkowany wolumen danych, „prawie w czasie rzeczywistym” jest miłe, ale nie krytyczne, a zapytania raportujące są kontrolowane.
Wzorzec 2: dedykowana hurtownia danych / baza analityczna
Tutaj OLTP pozostaje zoptymalizowane pod zapisy i odczyty punktowe, a analityka przenosi się do hurtowni danych (albo kolumnowej bazy analitycznej) zaprojektowanej do skanów, kompresji i dużych agregacji.
Zalety: przewidywalna wydajność OLTP, szybsze panele, lepsza współbieżność dla analityków i jasne strojenie kosztów/wydajności.
Wady: teraz operujesz dodatkowym systemem i potrzebujesz modelu danych (często schemat gwiazdy), przyjaznego analityce.
Najlepsze dopasowanie: rosnące wolumeny danych, wielu interesariuszy, złożone raportowanie lub ścisłe wymagania dotyczące latencji OLTP.
Wzorzec 3: potok oparty na CDC do analityki
Zamiast okresowego ETL, przesyłasz zmiany używając CDC (change data capture) z logu OLTP do hurtowni (często w podejściu ELT).
Zalety: świeższe dane przy mniejszym obciążeniu OLTP, łatwiejsze przetwarzanie przyrostowe i lepsza audytowalność.
Wady: więcej ruchomych części i potrzeba ostrożnego obchodzenia się ze zmianami schematu.
Najlepsze dopasowanie: większe wolumeny, wysokie wymagania świeżości danych i zespoły gotowe na potoki danych.
Jak bezpiecznie przenosić dane z OLTP do OLAP
Przenoszenie danych z bazy transakcyjnej do analitycznej to mniej „kopiowanie tabel”, a bardziej budowanie niezawodnego, niskonakładowego potoku. Cel jest prosty: analityka dostaje to, czego potrzebuje, bez narażania ruchu produkcyjnego.
ETL vs ELT (po ludzku)
ETL (Extract, Transform, Load) oznacza, że czyścisz i przekształcasz dane przed wgraniem do hurtowni. Przydatne, gdy w hurtowni koszt obliczeń jest wysoki lub chcesz mieć ścisłą kontrolę nad tym, co przechowujesz.
ELT (Extract, Load, Transform) najpierw ładuje się surowe dane, a transformacje wykonuje się w hurtowni. Często szybciej do ustawienia i łatwiej ewoluować: możesz zachować historię źródła i zmieniać transformacje, gdy wymagania się zmienią.
Praktyczna zasada: jeśli logika biznesowa często się zmienia, ELT zmniejsza prace do powtórzeń; jeśli wymagania governance wymagają jedynie kuratorowanych danych, ETL może lepiej pasować.
Podstawy CDC: jak przechwycić zmiany bez ciężkich zapytań
Change Data Capture (CDC) strumieniuje insert/update/delete z OLTP (często z logu bazy) do systemu analitycznego. Zamiast wielokrotnie skanować duże tabele, CDC przesyła tylko to, co się zmieniło.
Co to umożliwia:
- Prawie w czasie rzeczywistym raporty bez dużych odczytów na produkcji
- Odtwarzanie i backfille gdy trzeba odbudować tabele analityczne
- Śledzenie historii (kto co zmienił i kiedy), jeśli przechowujesz zdarzenia zmian
Świeżość danych: realtime vs near-real-time vs dzienne
Świeżość to decyzja biznesowa z kosztem technicznym.
- Realtime (sekundy): najlepsze dla paneli operacyjnych, ale najtrudniejsze do utrzymania; drobne problemy w potoku widać natychmiast.
- Near-real-time (minuty): popularny kompromis — wystarczający do podejmowania decyzji bez ekstremalnej złożoności.
- Codzienne batchy: najprostsze i najtańsze, dobre dla raportów finansowych, gdzie «wczoraj» jest akceptowalne.
Zdefiniuj jasne SLA (np. „dane są nie starsze niż 15 minut”), by interesariusze wiedzieli, co znaczy „świeże”.
Kontrole jakości danych, które zapobiegają cichym awariom
Potoki zwykle psują się cicho — dopóki ktoś nie zauważy rozbieżności. Dodaj lekkie kontrole dla:
- Zmian schematu: nowe kolumny, zmienione nazwy czy typy, które mogą spowodować utratę danych.
- Późno przychodzących zdarzeń: zamówienia lub płatności pojawiające się godzinami później; rozwiązuj to przez okno "lookback".
- Deduplication: retry i replay mogą podwajać zapisy; użyj stabilnych identyfikatorów i idempotentnych ładowań.
Te zabezpieczenia utrzymują OLAP wiarygodnym, a OLTP bezpiecznym.
Kiedy dzielenie jednej bazy może być akceptowalne
Generate tables and APIs
Describe orders, payments, and reports and let Koder.ai draft tables and APIs.
Trzymanie OLTP i OLAP razem nie jest automatycznie „złe”. Może to być rozsądny, tymczasowy wybór, gdy aplikacja jest mała, potrzeby raportowe wąskie, a ty wprowadzasz twarde granice, by analityka nie zaskakiwała klientów wolnymi checkoutami, nieudanymi płatnościami ani timeoutami.
Sytuacje, w których to działa
Małe aplikacje z lekką analityką i ścisłymi limitami zapytań często radzą sobie na jednej bazie — szczególnie na początku. Kluczem jest uczciwe określenie, co znaczy „lekka”: kilka paneli, umiarkowana liczba wierszy i jasne limity czasu i współbieżności.
Dla wąskiego zestawu cyklicznych raportów materializowane widoki lub tabele podsumowujące mogą zmniejszyć koszty analityki. Zamiast skanować surowe transakcje, wstępnie obliczasz dzienne sumy, top kategorie czy agregaty na poziomie klienta. Dzięki temu większość zapytań zostaje krótka i przewidywalna.
Jeśli użytkownicy biznesowi tolerują opóźnienia, okna raportowania poza szczytem pomagają. Planuj cięższe zadania w nocy lub w godzinach o niskim ruchu i rozważ dedykowaną rolę raportującą z węższymi uprawnieniami i limitami zasobów.
Zabezpieczenia, które warto dodać
- Ustaw timeouty zapytań i anuluj zapętlone zapytania.
- Ogranicz współbieżność dla użytkowników raportów.
- Monitoruj p95/p99 osobno dla kluczowych transakcji i czasów raportów.
Wyraźne znaki ostrzegawcze, że pora podzielić
Gdy widzisz rosnące opóźnienia transakcyjne, powtarzające się incydenty w czasie uruchamiania raportów, wyczerpanie puli połączeń lub historie „jedno zapytanie zabiło produkcję”, przekroczyłeś bezpieczną strefę. Wtedy rozdzielenie baz (albo przynajmniej użycie replik) przestaje być optymalizacją a staje się podstawową higieną operacyjną.
Praktyczna lista kontrolna migracji: od współdzielonego do rozdzielonego
Przenoszenie analityki poza bazę produkcyjną to mniej „duży rewrite”, a bardziej uczynienie pracy widoczną, ustawienie celów i migracja krok po kroku.
1) Inwentaryzacja — co naprawdę się dzieje dziś
Zacznij od dowodów, nie założeń. Wyciągnij listę:
- Najważniejsze endpointy/ zapytania OLTP według częstotliwości i p95/p99 (checkout, login, create order itp.)
- Najważniejsze raporty/panele OLAP według czasu wykonania, objętości skanowanych danych i znaczenia biznesowego
Uwzględnij „ukrytą” analitykę: ad-hoc SQL z narzędzi BI, zaplanowane eksporty i pobrania CSV.
2) Zdefiniuj cele: SLO OLTP i świeżość analityki
Zapisz cele, które będziesz optymalizować:
- SLO OLTP: p95/p99 latencji, wskaźnik błędów i maksymalna przepustowość, której musisz sprostać
- Świeżość analityki: jak bardzo dane mogą być przeterminowane (5 minut, 1 godzina, następny dzień) oraz czas odbudowy, gdy potok padnie
To zapobiega dyskusjom typu „jest wolno” vs „jest OK” i pomaga dobrać architekturę.
3) Wybierz ścieżkę separacji
Wybierz najprostsze rozwiązanie spełniające cele:
- Replika do odczytu: najszybsze do wdrożenia dla read-heavy raportów, ale może cierpieć z powodu lag i stresu
- Hurtownia: najlepsza dla dużych skanów, wielu złączeń i długiej historii; zwykle właściwe miejsce dla BI
- Potok CDC (ETL/ELT): najlepszy gdy potrzebujesz świeżości bez uderzania w produkcję
4) Wdrażaj bezpiecznie (najpierw równolegle)
- Uzgodnij definicje (strefy czasowe, refundy, „aktywny użytkownik” itp.), by liczby się zgadzały.
- Uruchom stare i nowe panele równolegle przez pełny cykl biznesowy.
- Przełącz raport po raporcie, zaczynając od najbardziej problematycznych zapytań.
- Zablokuj bezpośredni "reporting on production", gdy interesariusze zaufają nowemu źródłu.
5) Dodaj zabezpieczenia, by nie cofnąć się w rozwoju
Monitoruj opóźnienie replik/potoku, czasy uruchamiania dashboardów i koszty hurtowni. Dodaj budżety zapytań (timeouty, limity współbieżności) i miej playbook incydentowy: co robić, gdy świeżość spadnie, obciążenie wzrośnie lub kluczowe metryki się rozjadą.
Uwaga praktyczna, jeśli budujesz aplikację
Jeśli jesteś we wczesnej fazie i szybko dostarczasz, największym ryzykiem jest przypadkowe wpisanie analityki w tę samą ścieżkę bazy danych co transakcje (np. zapytania panelowe, które cichcem stają się krytyczne produkcyjnie). Jednym ze sposobów uniknięcia tego jest zaprojektowanie separacji od początku — nawet jeśli zaczynasz od skromnej repliki — i wpisanie jej w checklistę architektoniczną.
Platformy takie jak Koder.ai mogą tu pomóc, bo pozwalają prototypować stronę OLTP (aplikacja React + serwisy Go + PostgreSQL) i zaplanować granicę raportowania/hurtowni w trybie planowania przed uruchomieniem. W miarę rozwoju produktu możesz eksportować kod źródłowy, ewoluować schemat i dodawać komponenty CDC/ELT bez utrwalania "reportingu na produkcji".