14 maj 2025·8 min
Intel, dominacja x86 i dlaczego zmiany platform są tak trudne
Jasna historia, jak x86 Intela zbudował dekady kompatybilności, dlaczego ekosystemy się blokują i dlaczego zmiana platformy jest tak trudna dla branży.
Jasna historia, jak x86 Intela zbudował dekady kompatybilności, dlaczego ekosystemy się blokują i dlaczego zmiana platformy jest tak trudna dla branży.
Kiedy ludzie mówią „x86”, zwykle mają na myśli rodzinę instrukcji procesora, która zaczęła się od układu Intel 8086 i rozwijała przez dekady. Te instrukcje to podstawowe „czasowniki”, które rozumie procesor — dodawanie, porównywanie, przenoszenie danych i tak dalej. Ten zestaw instrukcji nazywa się ISA (instruction set architecture). Możesz myśleć o ISA jak o „języku”, którym oprogramowanie musi w końcu mówić, żeby działać na danym typie CPU.
x86: Najpowszechniejsza ISA używana w komputerach osobistych przez większość ostatnich ~40 lat, implementowana głównie przez Intel, a także AMD.
Wsteczna kompatybilność: Możliwość, by nowsze komputery dalej uruchamiały starsze programy (czasem sprzed dziesięcioleci) bez konieczności dużych przeróbek. Nie jest perfekcyjna w każdym przypadku, ale to przewidywalna obietnica świata PC: „Twoje rzeczy powinny nadal działać.”
„Dominacja” tutaj to nie tylko chwalenie się wydajnością. To praktyczna, kumulatywna przewaga w kilku wymiarach:
To połączenie warstw sprawia, że każda z nich wzmacnia pozostałe. Więcej maszyn zachęca do tworzenia więcej oprogramowania; więcej oprogramowania zachęca do kupowania większej liczby maszyn.
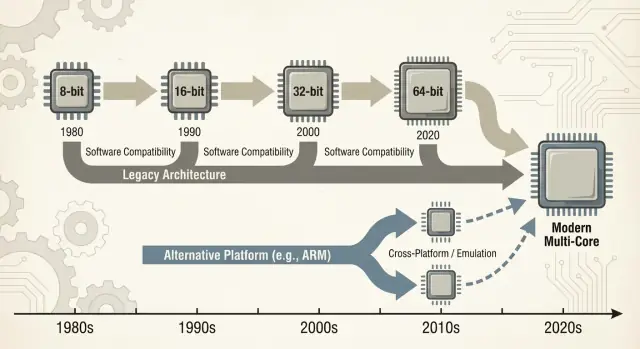
Przejście z dominującej ISA nie jest jak wymiana jednego komponentu na inny. Może to zepsuć — albo przynajmniej skomplikować — aplikacje, sterowniki (dla drukarek, GPU, urządzeń audio, wyspecjalizowanych peryferiów), łańcuchy narzędzi deweloperskich, a nawet codzienne nawyki (obrazy systemów, skrypty IT, agenty bezpieczeństwa, pipeliny wdrożeniowe). Wiele z tych zależności pozostaje niewidocznych, dopóki coś nie zawiedzie.
Ten wpis koncentruje się głównie na PC i serwerach, gdzie x86 przez długi czas był domyślny. Odwołamy się też do niedawnych zmian — zwłaszcza przejść na ARM — ponieważ dają one współczesne, łatwe do porównania lekcje o tym, co idzie gładko, co nie, i dlaczego „wystarczy przebudować” rzadko jest całą prawdą.
Wczesny rynek PC nie zaczął się od wielkiego planu architektonicznego — zaczął się od praktycznych ograniczeń. Firmy chciały maszyn tanich, dostępnych w dużej liczbie i łatwych w serwisowaniu. To pchnęło dostawców ku CPU i częściom, które można było pozyskać niezawodnie, sparować ze standardowymi peryferiami i składać w systemy bez specjalnego inżynieringu.
Pierwotny projekt IBM PC silnie opierał się na gotowych komponentach i relatywnie niedrogim procesorze klasy Intel 8088. Ten wybór miał znaczenie, bo sprawił, że „PC” mniej przypominał jedyny produkt, a bardziej przepis: rodzina CPU, zestaw slotów rozszerzeń, podejście do klawiatury/ekranu i stos oprogramowania, który dało się odtworzyć.
Kiedy IBM PC udowodnił istnienie popytu, rynek rozszerzył się przez klonowanie. Firmy takie jak Compaq pokazały, że można zbudować kompatybilne maszyny, które uruchamiają to samo oprogramowanie — i sprzedawać je w innych przedziałach cenowych.
Równie ważna była produkcja z drugiego źródła: wielu dostawców mogło dostarczać kompatybilne procesory lub komponenty. Dla kupujących zmniejszało to ryzyko uzależnienia od jednego producenta. Dla OEM‑ów zwiększało podaż i konkurencję, co przyspieszyło adopcję.
W takim środowisku kompatybilność stała się cechą, którą ludzie rozumieli i cenili. Kupujący nie musieli wiedzieć, czym jest ISA; wystarczyło, że Lotus 1‑2‑3 (a później aplikacje Windows) będą działać.
Dostępność oprogramowania szybko przekształciła się w prostą heurystykę zakupową: jeśli działa te same programy co na innych PC, to bezpieczny wybór.
Konwencje sprzętowe i firmware wykonały dużo niewidocznej pracy. Wspólne magistrale i podejścia do rozszerzeń — wraz z oczekiwaniami dotyczącymi BIOS/firmware i wspólnych zachowań systemu — ułatwiały producentom sprzętu i deweloperom celowanie w „PC” jako stabilną platformę.
Ta stabilność pomogła utrwalić x86 jako domyślną podstawę pod rosnący ekosystem.
x86 nie wygrał jedynie dzięki częstotliwościom taktowania czy sprytnym układom. Wygrał, ponieważ oprogramowanie podążyło za użytkownikami, a użytkownicy za oprogramowaniem — ekonomiczny „efekt sieciowy”, który kumuluje się w czasie.
Gdy platforma zyskuje wczesną przewagę, deweloperzy widzą większą publiczność i jaśniejszą ścieżkę do przychodów. To generuje więcej aplikacji, lepsze wsparcie i więcej dodatków stron trzecich. Te ulepszenia czynią platformę jeszcze atrakcyjniejszą dla kolejnej fali nabywców.
Powtarzaj tę pętlę przez lata, a „domyślna” platforma staje się trudna do wypchnięcia — nawet jeśli alternatywy są technicznie atrakcyjne.
To dlatego przejścia platformowe to nie tylko budowa CPU. To odtworzenie całego ekosystemu: aplikacji, instalatorów, kanałów aktualizacji, peryferiów, procesów IT i zbiorowej wiedzy milionów użytkowników.
Firmy często utrzymują krytyczne aplikacje przez długi czas: bazy danych na zamówienie, wewnętrzne narzędzia, dodatki ERP, oprogramowanie specyficzne dla branży i makra workflow, których nikt nie chce ruszać, bo „po prostu działają”. Stabilny cel x86 oznaczał:
Nawet jeśli nowa platforma obiecywała niższe koszty lub lepszą wydajność, ryzyko przerwania procesu generującego przychody często przeważało korzyści.
Deweloperzy rzadko optymalizują pod „najlepszą” platformę w oderwaniu. Optymalizują pod platformę, która minimalizuje koszty wsparcia i maksymalizuje zasięg.
Jeśli 90% twoich klientów to x86 Windows, tam testujesz najpierw, tam wydajesz najpierw i tam najszybciej poprawiasz błędy. Wsparcie kolejnej architektury oznacza dodatkowe pipeline’y budowania, więcej matryc QA, więcej debugowania „u mnie działa” i więcej skryptów wsparcia.
W efekcie powstaje samowzmacniająca luka: wiodąca platforma dostaje lepsze oprogramowanie, szybciej.
Wyobraź sobie małą firmę. Ich pakiet księgowy działa tylko na x86, zintegrowany z dekadą szablonów i wtyczką do płac. Polegają też na konkretnej drukarce etykiet i skanerze dokumentów z kapryśnymi sterownikami.
Teraz zaproponuj zmianę platformy. Nawet jeśli główne aplikacje istnieją, ważne są elementy peryferyjne: sterownik drukarki, narzędzie do skanera, wtyczka do PDF, moduł importu bankowego. Te „nudne” zależności stają się must‑have — i gdy ich brakuje lub są niestabilne, cała migracja ugrzęźnie.
To koło zamachowe w działaniu: zwycięska platforma akumuluje długi ogon kompatybilności, na którym wszyscy cicho polegają.
Wsteczna kompatybilność nie była tylko miłym dodatkiem x86 — stała się świadomą strategią produktową. Intel utrzymywał ISA x86 na tyle stabilne, by oprogramowanie napisane lata wcześniej nadal działało, zmieniając przy tym niemal wszystko pod spodem.
Kluczowa różnica to co pozostało kompatybilne. ISA definiuje instrukcje, na których polega oprogramowanie; mikroarchitektura to sposób, w jaki chip je wykonuje.
Intel mógł przejść od prostszych pipeline’ów do wykonania poza kolejnością, dodać większe cache, poprawić predykcję skoków czy wprowadzić nowe procesy technologiczne — bez proszenia deweloperów o przepisanie aplikacji.
Ta stabilność stworzyła potężne oczekiwanie: nowe PC powinny uruchamiać stare programy od pierwszego dnia.
x86 kumulował nowe możliwości warstwowo. Rozszerzenia zestawu instrukcji jak MMX, SSE, AVX i późniejsze były addytywne: stare binarki nadal działały, a nowsze aplikacje mogły wykrywać i używać nowych instrukcji, gdy były dostępne.
Nawet poważne przejścia łagodzono mechanizmami kompatybilności:
Minus to złożoność. Wspieranie dziesiątek lat zachowań oznacza więcej trybów CPU, więcej przypadków brzegowych i większy nakład walidacji. Każda nowa generacja musi udowodnić, że nadal uruchamia aplikacje, sterowniki i instalatory z poprzednich lat.
Z czasem „nie łamać istniejących aplikacji” przestaje być wskazówką i staje się strategicznym ograniczeniem: chroni zainstalowaną bazę, ale też utrudnia radykalne zmiany platformy — nowe ISA, nowe projekty systemowe, nowe założenia.
„Wintel” to nie tylko chwytliwe określenie Windows i procesorów Intel. Opisywało samowzmacniającą pętlę, w której każda część branży PC korzystała na trzymaniu się tego samego domyślnego celu: Windows na x86.
Dla większości producentów oprogramowania praktyczne pytanie nie brzmiało „jaka architektura jest najlepsza?”, lecz „gdzie są klienci i jak będą wyglądać połączenia do supportu?”
Komputery Windows były szeroko rozproszone w domach, biurach i szkołach, i opierały się głównie na x86. Wydawanie na tę kombinację maksymalizowało zasięg przy minimalizacji niespodzianek.
Gdy krytyczna masa aplikacji założyła Windows + x86, nowi nabywcy mieli kolejny powód, by to wybrać: ich niezbędne programy już tam działały. To z kolei czyniło platformę jeszcze atrakcyjniejszą dla kolejnych deweloperów.
Producenci PC odnoszą sukces, gdy mogą szybko budować wiele modeli, pozyskiwać komponenty od wielu dostawców i wysyłać maszyny, które „po prostu działają”. Wspólna baza Windows + x86 to upraszczała.
Firmy produkujące peryferia podążały za wolumenem. Jeśli większość kupujących używała Windows PC, drukarki, skanery, interfejsy audio, karty Wi‑Fi i inne urządzenia najpierw priorytetowo traktowały sterowniki dla Windows. Lepsza dostępność sterowników poprawiała doświadczenie Windows PC, co pomagało OEM‑om sprzedawać więcej jednostek i utrzymywać wysoki wolumen.
Zakupy korporacyjne i rządowe preferują przewidywalność: kompatybilność z istniejącym oprogramowaniem, zarządzalne koszty wsparcia, gwarancje producentów i sprawdzone narzędzia wdrożeniowe.
Nawet gdy alternatywy były atrakcyjne, najniższe ryzyko często wygrywało, bo zmniejszało szkolenia, unikało przypadków brzegowych i pasowało do ustalonych procesów IT.
W efekcie to nie była spiskowa gra, lecz zbieżność zachęt — każdy uczestnik wybierał drogę, która zmniejszała tarcie — tworząc impet, który utrudniał zmianę platformy.
„Przejście platformy” to nie tylko wymiana CPU. To pakiet zmian: ISA CPU, system operacyjny, kompilator/łańcuch narzędzi budujących aplikacje i stos sterowników, które sprawiają, że sprzęt działa. Zmiana któregokolwiek z tych elementów często narusza inne.
Większość uszkodzeń nie jest dramatycznym „aplikacja się nie uruchamia”. To śmierć tysiąca drobnych problemów:
Nawet gdy rdzeń aplikacji ma nową wersję, jej otoczenie „klejące” może nie mieć.
Drukarki, skanery, drukarki etykiet, wyspecjalizowane karty PCIe/USB, urządzenia medyczne, sprzęt POS i dongle USB żyją i umierają przez sterowniki. Jeśli dostawca zniknął albo nie jest zainteresowany, może nie być sterownika dla nowego OS lub architektury.
W wielu firmach jedno urządzenie za 200 USD może zablokować floty komputerów po 2000 USD.
Największym blokującym elementem są często „małe” narzędzia wewnętrzne: niestandardowa baza Access, skoroszyt z makrami w Excelu, aplikacja VB z 2009 roku, niszowe narzędzie produkcyjne używane przez trzy osoby.
Nie są na mapie drogowej produktu, ale są krytyczne. Przejścia platformowe zawodzą, gdy ten długi ogon nie zostanie migrowany, przetestowany i przypisany komuś do opieki.
Przejście platformowe nie jest oceniane jedynie po benchmarkach. Ocenia się je po całkowitym rachunku — pieniądze, czas, ryzyko i utracony impet — który dla większości osób i organizacji jest wyższy, niż wygląda z zewnątrz.
Dla użytkowników koszty zmiany zaczynają się od oczywistych (nowy sprzęt, peryferia, gwarancje) i szybko przechodzą w bałagan: przeszkolenie, rekonfiguracja workflowów i ponowna walidacja narzędzi, z których korzystają na co dzień.
Nawet gdy aplikacja „działa”, szczegóły mogą się zmieniać: wtyczka nie ładuje się, brak sterownika drukarki, makro działa inaczej, system anty‑cheat gry zgłasza problem albo niszowy akcesorium przestaje działać. Każdy z tych problemów jest drobny; razem mogą wymazać wartość aktualizacji.
Dostawcy płacą za przejście platformy przez rozszerzającą się matrycę testów. To nie tylko „czy się uruchamia?”, ale:
Każda dodatkowa kombinacja dodaje czasu QA, więcej dokumentacji i więcej zgłoszeń do wsparcia. Przejście może przemienić przewidywalny cykl wydań w stały tryb reagowania na incydenty.
Deweloperzy ponoszą koszty portowania bibliotek, przepisywania kodu krytycznego dla wydajności (często ręcznie dopasowanego do ISA) i odbudowy testów automatycznych. Najtrudniejsze jest odzyskanie pewności: udowodnienie, że nowy build jest poprawny, wystarczająco szybki i stabilny w rzeczywistych obciążeniach.
Prace migracyjne konkurują bezpośrednio z nowymi funkcjami. Jeśli zespół spędza dwa kwartały, żeby rzeczy „znowu działały”, to dwa kwartały, których nie poświęcił na ulepszanie produktu.
Wiele organizacji przejdzie dopiero, gdy stara platforma zacznie ich blokować — albo gdy nowa będzie tak przekonująca, że usprawiedliwi ten kompromis.
Gdy pojawia się nowa architektura CPU, użytkownicy nie pytają o zestawy instrukcji — pytają, czy ich aplikacje nadal się otworzą. Dlatego „mosty” mają znaczenie: pozwalają nowym maszynom uruchamiać stare oprogramowanie wystarczająco długo, by ekosystem nadążył.
Emulacja naśladuje cały CPU w oprogramowaniu. To opcja najbardziej kompatybilna, ale zwykle najwolniejsza, bo każda instrukcja jest „odegrana” zamiast wykonywana bezpośrednio.
Tłumaczenie binarne (często dynamiczne) przepisuje fragmenty kodu x86 na natywne instrukcje nowego CPU w trakcie działania programu. Tak wiele współczesnych przejść dostarcza opowieść „dzień pierwszy”: zainstaluj swoje istniejące aplikacje, a warstwa kompatybilności cicho je przetłumaczy.
Wartość jest prosta: możesz kupić nowy sprzęt bez czekania, aż wszyscy dostawcy przebudują swoje programy.
Warstwy kompatybilności działają najlepiej dla mainstreamowych, dobrze napisanych aplikacji — i zawodzą na obrzeżach:
Wsparcie sprzętowe często jest prawdziwym blokiem.
Wirtualizacja pomaga, gdy potrzebujesz całego legacy środowiska (konkretna wersja Windows, stary stos Java, aplikacja linii biznesowej). Operacyjnie jest czysta — snapshoty, izolacja, łatwy rollback — ale zależy od tego, co wirtualizujesz.
VM‑y tej samej architektury mogą być niemal natywne; VM‑y między architekturami zwykle cofają się do emulacji i zwalniają.
Most zwykle wystarcza dla aplikacji biurowych, przeglądarek i codziennej produktywności — tam „wystarczająco szybkie” wygrywa. Jest ryzykownie dla:
W praktyce mosty kupują czas — ale rzadko eliminują pracę migracyjną.
Argumenty o CPU często brzmią jak jeden wynik: „szybszy wygrywa”. W rzeczywistości platformy wygrywają, gdy dopasowują się do ograniczeń urządzeń i rzeczywistych obciążeń użytkowników.
x86 stał się domyślnym wyborem dla PC częściowo dlatego, że dawał silną szczytową wydajność przy zasilaniu sieciowym, a przemysł zbudował wszystko wokół tego założenia.
Kupujący desktopów i laptopów historycznie nagradzali responsywność: uruchamianie aplikacji, kompilacje, gry, ciężkie arkusze. To popycha producentów ku wysokim zegarom boost, szerokim rdzeniom i agresywnemu turbo — świetne, gdy można wydawać waty swobodnie.
Efektywność energetyczna to inna gra. Jeśli produkt ogranicza bateria, temperatura czy cienka obudowa, najlepszy CPU to ten, który wykonuje „wystarczająco” pracy na wat, konsekwentnie, bez dławiących throttlingów.
Efektywność to nie tylko oszczędność energii; to utrzymanie wydajności w granicach termicznych, by nie upadała po minucie.
Telefony i tablety żyją w ciasnych budżetach energetycznych i zawsze były wrażliwe na koszty przy ogromnych wolumenach. To środowisko premiowało projekty optymalizowane pod efektywność, zintegrowane komponenty i przewidywalne zachowania termiczne.
Stworzyło też ekosystem, w którym system operacyjny, aplikacje i krzem ewoluowały razem pod mobilne założenia.
W centrach danych wybór CPU rzadko jest czystą decyzją benchmarkową. Operatorzy dbają o funkcje niezawodności, długie okna wsparcia, stabilne firmware, monitoring i dojrzały ekosystem sterowników, hypervisorów i narzędzi zarządzania.
Nawet gdy nowa architektura wygląda atrakcyjnie pod kątem perf/watt, ryzyko operacyjnych niespodzianek może przewyższać korzyść.
Współczesne obciążenia serwerowe są zróżnicowane: serwowanie WWW premiuje wysoką przepustowość i efektywne skalowanie; bazy danych nagradzają przepustowość pamięci, spójność latencji i sprawdzone strojenie; AI przesuwa wartość ku akceleratorom i stosom oprogramowania.
W miarę zmiany miksu obciążeń, zwycięska platforma również może się zmienić — ale tylko wtedy, gdy otaczający ją ekosystem nadąży.
Nowa architektura CPU może być technicznie doskonała i nadal przegrać, jeśli narzędzia dnia codziennego nie ułatwią budowania, wysyłania i wspierania oprogramowania. Dla większości zespołów „platforma” to nie tylko zestaw instrukcji — to cały pipeline dostarczania.
Kompilatory, debugery, profile, podstawowe biblioteki cicho kształtują zachowania deweloperów. Jeśli najlepsze flagi kompilatora, stack trace czy narzędzia do sanitizacji pojawią się z opóźnieniem (lub będą działać inaczej), zespoły wstrzymają się z zakładaniem wydań na nich.
Nawet drobne braki mają znaczenie: brak biblioteki, niestabilny plugin debugera czy wolniejsze CI mogą przekształcić „możemy to portować” w „nie zrobimy tego w tym kwartale”. Gdy toolchain x86 jest domyślny w IDE, systemach budowania i CI, droga najmniejszego oporu ciągnie deweloperów z powrotem.
Oprogramowanie trafia do użytkowników przez konwencje pakowania: instalatory, aktualizatory, repozytoria, sklepy z aplikacjami, kontenery i podpisane binaria. Zmiana platformy zadaje niewygodne pytania:
Jeśli dystrybucja robi się nieporęczna, koszty wsparcia rosną — i wielu dostawców tego unika.
Firmy kupują platformy, które mogą zarządzać na dużą skalę: imaging, rejestracja urządzeń, polityki, zabezpieczenia endpointów, agenty EDR, klienci VPN i raportowanie zgodności. Jeśli któreś z tych narzędzi opóźnia się na nowej architekturze, pilotaże zatrzymują się.
„Działa na mojej maszynie” jest bez znaczenia, jeśli IT nie może tego wdrożyć i zabezpieczyć.
Deweloperzy i IT zbieżają się na jednym praktycznym pytaniu: jak szybko możemy wysyłać i wspierać? Narzędzia i dystrybucja często odpowiadają na nie bardziej zdecydowanie niż surowe benchmarki.
Jednym praktycznym sposobem na zmniejszenie tarcia migracji jest skrócenie czasu od pomysłu do testowalnego buildu — szczególnie przy walidacji tej samej aplikacji w różnych środowiskach (x86 vs ARM, różne obrazy OS czy cele wdrożeniowe).
Platformy takie jak Koder.ai wpisują się w ten workflow, pozwalając zespołom generować i iterować rzeczywiste aplikacje przez interfejs czatu — często produkując frontend w React, backend w Go i bazy PostgreSQL (oraz Flutter dla mobilnych). Dla prac migracyjnych dwie funkcje są szczególnie istotne:
Ponieważ Koder.ai wspiera eksport źródła, może też służyć jako most między eksperymentem a konwencjonalnym procesem inżynieryjnym — przydatne, gdy trzeba działać szybko, ale zachować utrzymywalny kod we własnym repozytorium.
Wejście ARM do laptopów i desktopów to dobry test tego, jak trudne są naprawdę zmiany platform. Na papierze argument jest prosty: lepsza wydajność na wat, cichsze maszyny, dłuższy czas pracy na baterii.
W praktyce sukces zależy mniej od rdzenia CPU, a bardziej od wszystkiego wokół — aplikacji, sterowników, dystrybucji i tego, kto ma siłę, by skoordynować uczestników.
Przejście Apple z Intela na Apple Silicon powiodło się głównie dlatego, że Apple kontroluje cały stos: projekt sprzętu, firmware, system operacyjny, narzędzia deweloperskie i główny kanał dystrybucji aplikacji.
Ta kontrola pozwoliła firmie wykonać czyste przejście bez czekania, aż dziesiątki niezależnych partnerów poruszą się synchronicznie.
Umożliwiła też skoordynowany okres „mostowy”: deweloperzy otrzymali jasne cele, użytkownicy ścieżki kompatybilności, a Apple mogło naciskać kluczowych dostawców, by wypuścili natywne buildy. Nawet gdy niektóre aplikacje nie były natywne, UX często pozostał akceptowalny, bo plan przejścia był zaprojektowany jako produkt, a nie tylko wymiana procesora.
Windows na ARM pokazuje drugą stronę medalu. Microsoft nie kontroluje w pełni ekosystemu sprzętowego, a pecety z Windowsem silnie zależą od wyborów OEM i długiego ogona sterowników.
To tworzy typowe punkty awarii:
Niedawny postęp ARM potwierdza lekcję: kontrola większej części stosu przyspiesza i upraszcza przejścia.
Gdy polegasz na partnerach, potrzebujesz niezwykle silnej koordynacji, jasnych ścieżek aktualizacji i powodu, dla którego każdy uczestnik — producent chipów, OEM, deweloper i nabywca IT — ma priorytetowo traktować migrację jednocześnie.
Przejścia platformowe zawodzą z nudnych powodów: stara platforma nadal działa, wszyscy już w nią zainwestowali (pieniędzmi i nawykami), a „przypadki brzegowe” to miejsce, gdzie żyją realne biznesy.
Nowa platforma zwykle wygrywa, gdy układają się trzy rzeczy:
Po pierwsze, korzyść jest oczywista dla normalnych nabywców — nie tylko inżynierów: lepszy czas pracy na baterii, istotnie niższe koszty, nowe formy urządzeń lub krokowa poprawa wydajności dla typowych zadań.
Po drugie, istnieje wiarygodny plan kompatybilności: dobra emulacja/tłumaczenie, proste „uniwersalne” buildy i jasne ścieżki dla sterowników, peryferiów i narzędzi korporacyjnych.
Po trzecie, zachęty są zgrane w całym łańcuchu: dostawca OS, producent chipów, OEM‑y i deweloperzy widzą korzyści i mają powód, by priorytetowo traktować migrację.
Udane przejścia wyglądają mniej jak włączenie jednego przełącznika, a bardziej jak kontrolowane nakładanie się: rollouty fazowe (najpierw grupy pilotażowe), podwójne buildy (stare + nowe) i telemetria (wskaźniki awaryjności, wydajność, użycie funkcji) pozwalają złapać problemy wcześnie.
Równie ważne: publikowane okno wsparcia dla starej platformy, jasne wewnętrzne terminy i plan dla użytkowników „nieprzenoszalnych”.
x86 wciąż ma ogromny impet: dekady kompatybilności, utrwalone procesy korporacyjne i szerokie opcje sprzętowe.
Ale presja rośnie z powodu nowych potrzeb — efektywności energetycznej, głębszej integracji, obliczeń AI i prostszych flot urządzeń. Najtrudniejsze bitwy nie dotyczą surowej prędkości; dotyczą tego, jak sprawić, by zmiana była bezpieczna, przewidywalna i opłacalna.
x86 to architektura zestawu instrukcji procesora (ISA): zbiór instrukcji maszynowych, na których ostatecznie działa oprogramowanie.
„Dominacja” w tym wpisie oznacza skumulowaną przewagę wynikającą z wysokiej liczby wysyłek, największego katalogu oprogramowania i domyślnego postrzegania — nie tylko przewagi w syntetycznych testach wydajności.
ISA to „język”, który rozumie procesor.
Jeśli aplikacja jest skompilowana dla x86, uruchomi się natywnie na CPU x86. Jeśli przechodzisz na inną ISA (np. ARM), zwykle potrzebujesz natywnej rekompilacji lub polegasz na tłumaczeniu/emulacji, żeby uruchomić stary binarny plik.
Wsteczna kompatybilność pozwala nowszym maszynom uruchamiać starsze programy przy minimalnych zmianach.
W świecie PC to oczekiwanie produktowe: aktualizacje nie powinny zmuszać do przepisywania aplikacji, zastępowania procesów pracy ani porzucania „tego jednego” narzędzia legacy, które nadal jest potrzebne.
Mogą zmieniać się sposoby wykonania instrukcji (mikroarchitektura), podczas gdy same instrukcje (ISA) pozostają stabilne.
Dzięki temu widać duże zmiany w wydajności, pamięci podręcznej czy zużyciu energii bez łamania starych binarek.
Typowe punkty awarii to:
Często „główna aplikacja” działa, ale otaczające ją „spoiwo” już nie.
Bo zwykle to brakujący sterownik lub nieobsługiwane urządzenie peryferyjne blokuje migrację.
Warstwa kompatybilności może przetłumaczyć aplikację, ale nie „stworzy” stabilnego sterownika jądra dla niszowego skanera, urządzenia POS czy klucza USB, jeśli producent go nie wypuścił.
Baza zainstalowanych systemów napędza wysiłek programistów.
Jeśli większość klientów używa Windows x86, dostawcy priorytetowo traktują ten build, testy i wsparcie. Wsparcie kolejnej architektury oznacza dodatkowe buildy CI, matryce QA, dokumentację i obciążenie supportu, które zespoły często odkładają, dopóki popyt nie stanie się oczywisty.
Nie wystarczy.\n\nRekompilacja to tylko jedna część. Może być też konieczne:
Najtrudniejsze jest udowodnienie, że nowy build jest poprawny i możliwy do wsparcia w rzeczywistych warunkach.
Są mostami, a nie lekarstwem:
Kupują czas, aż ekosystem się dostosuje, ale sterowniki i komponenty niskiego poziomu pozostają twardymi ograniczeniami.
Użyj pilota opartego na checkliście:
Traktuj to jako kontrolowane wdrożenie z opcjami rollbacku, a nie jednorazową „wielką zmianę”.