23 gru 2025·8 min
Ekrany panelu admina: 12 niezbędnych widoków dla ops i supportu
Praktyczna lista 12 ekranów panelu admina, które obsługują większość potrzeb supportu i ops, oraz prosta metoda priorytetyzacji tego, co zbudować najpierw.
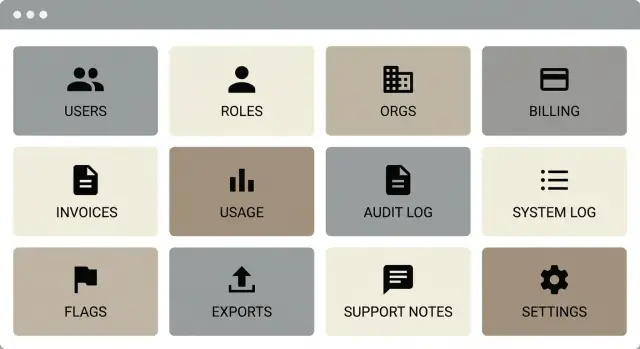
Praktyczna lista 12 ekranów panelu admina, które obsługują większość potrzeb supportu i ops, oraz prosta metoda priorytetyzacji tego, co zbudować najpierw.
Panel administracyjny, który „pokrywa 80% operacji”, to nie ten z największą liczbą ustawień. To taki, który pozwala zespołowi rozwiązać najczęstsze zgłoszenia supportu i operacji w kilka minut, bez angażowania inżyniera do pojedynczej ręcznej naprawy.
Zmiana polega na oddzieleniu funkcji produktowych od narzędzi wsparcia. Funkcje produktowe pomagają użytkownikom końcowym wykonywać pracę. Narzędzia wsparcia pomagają zespołowi wewnętrznemu odpowiedzieć na pytania: „Co się stało? Kto to zrobił? Co możemy bezpiecznie zmienić?”. Wiele zespołów wypuszcza mnóstwo kontrolek skierowanych do użytkownika końcowego, a potem odkrywa, że support nadal nie widzi podstaw, jak właściciel, stan płatności, ostatnie błędy czy przejrzysta historia zmian.
Różne zespoły używają panelu admina do różnych celów. Support musi odblokowywać użytkowników i wykonywać bezpieczne zmiany. Finanse potrzebują widoku billingowego, faktur, zwrotów i informacji podatkowych. Ops potrzebuje zdrowia organizacji, trendów użycia, kontroli ryzyka i eksportów. Inżynieria potrzebuje breadcrumbs do debugowania, jak logi i śladu audytu (nie pełnej obserwowalności).
Aby zdecydować, co stanowi te 80%, użyj oceny częstotliwości kontra wpływ. Częstotliwość to jak często pojawia się zapytanie. Wpływ to jak bolesne jest, gdy nie możesz go szybko rozwiązać (utrata przychodu, ryzyko churn, ryzyko zgodności).
Prosta metoda:
Jeśli użytkownik mówi: „Zostałem obciążony, ale nie mam dostępu do Pro”, najlepsza lista kontrolna panelu admina to ta, która prowadzi support od wyszukania użytkownika przez status subskrypcji i fakturę aż do akcji, z audytowalnym śladem dla każdej zmiany.
Panel administracyjny zarabia na siebie, gdy pomaga zamykać zgłoszenia szybko i bezpiecznie. Najłatwiejszy sposób wybrać właściwe ekrany to zacząć od realiów supportu, a nie od tego, co wydaje się „kompletne”.
Najpierw zapisz 20 najczęstszych pytań, które już dostajesz (lub spodziewasz się otrzymać w pierwszych 90 dniach). Użyj skrzynki odbiorczej, logów czatu i notatek o zwrotach. Jeśli budujesz coś takiego jak Koder.ai, przykłady to: „Dlaczego nie mogę się zalogować?” „Kto zmienił to ustawienie?” „Dlaczego zostałem obciążony dwa razy?” „Czy możecie wyeksportować moje dane?” „Czy aplikacja jest niedostępna dla wszystkich?”
Następnie pogrupuj te pytania w kilka tematów: dostęp (użytkownicy, organizacje, role), pieniądze (billing, faktury, użycie), dane (eksporty, usunięcia, retencja) oraz incydenty (audyt, logi, status).
Potem przekształć każdy temat w jeden ekran plus 2–3 bezpieczne akcje, które rozwiązują większość zgłoszeń. „Bezpieczne” oznacza odwracalne, zapisane i trudne do nadużycia. Przykłady: ponów zaproszenie, zresetuj MFA, ponów płatność, wygeneruj eksport ponownie, cofnij zmianę konfiguracji.
Stosuj tę samą soczewkę oceny dla każdego proponowanego ekranu:
Buduj najmniejszą wersję, która nadal rozwiązuje zgłoszenia end-to-end. Dobry test to, czy agent supportu poradzi sobie z realnym przypadkiem bez pytania inżyniera. Jeśli nie, zwykle brakuje jednego szczegółu (jak ostatnie logowanie, status płatności lub co się zmieniło, kiedy i przez kogo).
Te trzy ekrany wykonują większość codziennej pracy w panelu ops. Powinny szybko odpowiadać na dwa pytania: „Co się pali teraz?” i „Kogo to dotyczy?”.
Overview powinno być małym, niezawodnym pulsem. Skup się na dziś i ostatnich 24 godzinach: nowe rejestracje, aktywni użytkownicy, nieudane płatności i wszelkie skoki błędów. Dodaj krótki obszar alertów dla rzeczy, których support nie powinien przegapić, jak wyjątkowo wysokie nieudane logowania, błędy webhooków czy nagły wzrost zwrotów.
Dobra zasada: każda metryka na tej stronie powinna prowadzić do jednego jasnego następnego kliknięcia, zwykle do Users, Organizations lub Logs.
Ekran Users potrzebuje świetnego wyszukiwania. Support powinien znaleźć osoby po emailu, nazwisku, ID użytkownika i organizacji. Umieść status i sygnały zaufania na pierwszym planie: potwierdzony email lub telefon (jeśli zbierasz), ostatnie logowanie oraz czy konto jest aktywne, zawieszone lub zaproszone, ale nie dołączyło.
Trzymaj kluczowe akcje w jednym, spójnym miejscu i spraw, by były bezpieczne: dezaktywuj/reaktywuj, zresetuj dostęp (sesje, MFA lub hasło w zależności od produktu) oraz ponów zaproszenie. Dodaj pole notatek wewnętrznych dla kontekstu, np. „prośba o zmianę faktury z 9 stycznia”, aby zgłoszenia nie zaczynały się od zera.
Ten ekran powinien pokazywać członkostwo, aktualny plan, użycie vs limity oraz właściciela. Support często musi rozwiązać przypadki „zła osoba ma dostęp” i „osiągnęliśmy limit”, więc uwzględnij transfer własności oraz zarządzanie członkostwem.
Utrzymuj widoki szybkie dzięki filtrom, sortowaniu i zapisanym wyszukiwaniom jak „płatność nieudana”, „brak logowania w 30 dni” czy „przekroczono limit”. Powolne ekrany admina zamieniają proste zgłoszenia w długie sprawy.
Role i uprawnienia to miejsce, w którym support wygrywa lub traci czas. Jeśli ktoś mówi „Nie mogę zrobić X”, musisz odpowiedzieć w kilka minut. Traktuj ten ekran jako czytelny widok kontroli dostępu opartej na rolach, a nie narzędzie deweloperskie.
Zacznij od dwóch prostych tabel: role (co mogą robić) i osoby (kto ma jakie role). Najbardziej użytecznym detalem jest efektywne uprawnienie. Pokaż role użytkownika, wszelkie role na poziomie organizacji oraz nadpisania w jednym miejscu, ze streszczeniem w prostym języku, np. „Może zarządzać bilingiem: Tak.”
Edytor uprawnień musi być bezpieczny, bo zmiany ról mogą szybko psuć konta. Dodaj podgląd, który pokaże dokładnie, co się zmieni przed zapisaniem: które możliwości są dodawane lub usuwane i którzy użytkownicy będą wpływać.
By ułatwić supportowi, dodaj troubleshooter „Dlaczego nie mogą tego zrobić?”. Support wybiera akcję (np. „eksport danych” lub „zaproszenie użytkownika”), wybiera użytkownika, a ekran zwraca brakujące uprawnienie i gdzie powinno być nadane (rola vs polityka organizacji). To unika długiego ping-ponga i zmniejsza eskalacje.
Dla działań wysokiego ryzyka wymagaj dodatkowego potwierdzenia. Częste to: zmiana ról administratorów, przyznanie dostępu do bilingów lub wypłat, włączenie dostępu produkcyjnego lub uprawnień do deploymentu oraz wyłączenie kontroli bezpieczeństwa jak wymaganie MFA.
W końcu, spraw, by zmiany uprawnień były audytowalne. Każda edycja powinna zapisać, kto zmienił, kogo to dotknęło, wartości przed/po i powód. Na platformie takiej jak Koder.ai ta historia pomaga supportowi wyjaśnić, dlaczego użytkownik nagle może lub nie może eksportować kodu źródłowego, deployować czy zarządzać domeną.
Billing to miejsce, gdzie gromadzą się zgłoszenia. Te ekrany powinny być przejrzyste, szybkie i trudne do pomylenia. Jeśli zrobisz tylko jedną rzecz dobrze, niech to będzie: „Jaki mają plan, ile zapłacili i dlaczego dostęp się zmienił?”.
Pokaż aktualny plan, datę odnowienia, status (aktywny, trial, past due, anulowany), liczbę miejsc oraz kto jest właścicielem rozliczeń. Umieść źródło prawdy na górze, a historię niżej (zmiany planu, zmiany miejsc). Trzymaj ryzykowne kontrolki (anuluj, zmień plan, wznowienie) oddzielone od widoku, z potwierdzeniem i wymaganym powodem.
Support potrzebuje prostej listy faktur z datami, kwotami, podatkami i statusem (opłacone, otwarte, nieudane, zwrócone). Uwzględnij próby płatności i powody niepowodzeń jak odrzucenie karty czy wymagane uwierzytelnienie. Paragony powinny być dostępne jednym kliknięciem z wiersza faktury, ale unikaj edycji tu, chyba że to naprawdę konieczne.
Jeśli pobierasz opłaty za użycie lub kredyty, pokaż licznik odpowiadający temu, co widzi klient. Uwzględnij użycie w bieżącym okresie, limity, nadwyżki i ewentualne caps. Dodaj krótkie „dlaczego zostali zablokowani”, aby support mógł to wyjaśnić prostym językiem.
Typowe akcje supportowe należą tu, ale trzymaj je kontrolowane: przyznanie jednorazowego kredytu (z wygaśnięciem i notatką wewnętrzną), przedłużenie trialu (z limitami), aktualizacja podatku lub adresu rozliczeniowego (śledzona), ponowienie płatności, lub dodanie miejsc bez zmiany planu.
Wizualnie odróżniaj pola tylko do odczytu od edytowalnych. Na przykład pokaż „Plan: Business (tylko do odczytu)” obok „Liczba miejsc (edytowalna)”, aby agent nie spowodował przypadkowej zmiany planu.
Gdy support mówi „coś się zmieniło”, te dwa ekrany kończą zgadywanie. Audit log mówi, kto co zrobił. System log mówi, co system zrobił (albo nie zrobił). Razem skracają follow-upy i pomagają dać jasne odpowiedzi szybko.
Audit log powinien odpowiadać na trzy pytania od razu: kto wykonał akcję, co zmienił i kiedy to miało miejsce. Jeśli zapisujesz też skąd (adres IP, urządzenie, przybliżona lokalizacja), możesz wykrywać podejrzane dostępy i wyjaśniać dziwne zachowania bez obwiniania użytkownika.
Filtry przyjazne supportowi zwykle obejmują: aktora (admin, agent supportu, użytkownik końcowy, klucz API), użytkownika i organizację, okno czasowe, typ akcji (logowanie, zmiana roli, zmiana bilingowa, eksport) oraz obiekt docelowy (konto, projekt, subskrypcja).
Każdy wiersz powinien być czytelny: nazwa akcji, podsumowanie przed/po i stabilne ID zdarzenia, którym można się podzielić z inżynierią.
System logs to miejsce, gdzie potwierdzasz „zawiodło” vs „zadziałało, ale było opóźnione”. Ten ekran powinien grupować błędy, ponowienia i zadania w tle oraz pokazywać, co się działo w tym samym czasie.
Pokaż zwarty zestaw pól, który przyspiesza debugowanie: znacznik czasu i poziom ważności, request ID i correlation ID, nazwa serwisu lub joba (API, worker, billing sync), komunikat błędu z krótkim stack trace (jeśli bezpieczne), liczba ponowień i status końcowy.
To redukuje dialogi. Support może odpowiedzieć: „Twój eksport rozpoczął się o 10:14, próbował dwukrotnie i nie powiódł się przez timeout. Uruchomiliśmy go ponownie i zakończył się o 10:19. Request ID: abc123.”
Flagi funkcji to jeden z najszybszych sposobów, w jaki support może pomóc klientowi bez czekania na release. W panelu admina powinny być nudne, jasne i bezpieczne.
Dobry widok flag wspiera przełączniki per-user i per-organization, plus staged rollouts (np. 5%, 25%, 100%). Potrzebuje też kontekstu, żeby nikt nie zgadywał, co flaga robi o 2 w nocy.
Trzymaj ekran mały, ale rygorystyczny. Każda flaga powinna mieć prosty opis efektu dla użytkownika, właściciela, datę przeglądu lub wygaśnięcia, reguły zakresu (user, org, środowisko) oraz historię zmian pokazującą kto ją przestawił i dlaczego.
Workflow supportu też ma znaczenie. Pozwól tymczasowe włączenie z krótką notatką (przykład: „Włącz dla Org 143 na 2 godziny, aby potwierdzić naprawę”). Po zakończeniu timer powinien automatycznie cofnąć zmianę i zostawić ślad w audycie.
Flagi służą eksperymentom i bezpiecznemu rolloutowi. Jeśli to długoterminowy wybór, którym klient spodziewa się zarządzać, zwykle powinno to być ustawienie. Sygnały: powtarzające się prośby w czasie onboardingu lub odnawiania, zmiany wpływające na billing/limity/zgodność, potrzeba etykiety UI i tekstu pomocy, albo trwała różnica domyślna między zespołami.
Przykład: jeśli klient Koder.ai zgłasza, że nowy krok builda psuje się tylko w ich workspace, support może tymczasowo włączyć flagę kompatybilności dla tej organizacji, potwierdzić przyczynę, a potem albo wypuścić poprawkę, albo przekształcić zachowanie w realne ustawienie.
Eksporty wyglądają nieszkodliwie, ale mogą stać się najprostszą drogą do wycieku danych. W większości paneli admina eksport jest jedną akcją, która może skopiować dużo wrażliwych informacji jednym kliknięciem.
Zacznij od małego zestawu wysokowartościowych eksportów: użytkownicy, organizacje, billing i faktury, użycie lub kredyty oraz aktywność (zdarzenia powiązane z użytkownikiem lub workspace). Jeśli produkt przechowuje treści generowane przez użytkowników, rozważ osobny eksport dla nich z ostrzejszymi uprawnieniami.
Daj supportowi kontrolę bez komplikowania UI eksportu. Solidny przepływ eksportu zawiera zakres dat, kilka kluczowych filtrów (status, plan, workspace) oraz opcjonalny wybór kolumn, by plik był czytelny. CSV dobrze działa do szybkiej pracy supportu; JSON lepiej do głębszej analizy.
Uczyń eksporty bezpiecznymi z założenia. Postaw eksporty za kontrolą dostępu opartą na rolach (nie tylko „admin”), maskuj sekrety domyślnie (klucze API, tokeny, pełne dane kart), maskuj PII gdzie to możliwe, uruchamiaj eksporty jako zadania w tle z jasnym statusem (queued, running, ready, failed), ustaw okno wygaśnięcia pobrania i limituj ogromne eksporty chyba że zatwierdzi wyższa rola.
Traktuj eksporty też jako zdarzenia audytowe. Zapisuj kto eksportował, co eksportował (typ, filtry, zakres dat, kolumny) i gdzie plik został dostarczony.
Przykład: klient kwestionuje obciążenie. Support eksportuje faktury i użycie za ostatnie 30 dni dla tej organizacji, z tylko potrzebnymi kolumnami (invoice id, amount, period, payment status). Audit log zapisuje szczegóły eksportu, a plik jest dostarczony po zakończeniu zadania, bez ujawniania danych metody płatności.
Dobry workspace supportu przestaje przepychać zgłoszenia między ludźmi. Powinien odpowiadać na jedno pytanie szybko: „Co się stało z tym klientem i co już próbowaliśmy?”.
Zacznij od osi czasu klienta, która miesza zdarzenia systemowe i kontekst ludzki. Notatki wewnętrzne (niewidoczne dla klienta), tagi (do routingu jak „billing”, „login”, „bug”) oraz feed aktywności zapobiegają powtarzaniu pracy. Każda akcja administracyjna powinna pojawić się w tej samej osi czasu z informacją kto to zrobił, kiedy i wartościami przed/po.
Trzymaj akcje bezpieczne i nudne. Daj supportowi narzędzia do odblokowywania użytkowników bez zamiany ich w deweloperów: zablokuj/odblokuj konto (z wymaganym powodem), unieważnij aktywne sesje (wymuś ponowne logowanie), ponów wysłanie weryfikacji lub reset hasła, uruchom zadanie „przelicz uprawnienia” lub „odśwież status subskrypcji”, albo dodaj tymczasową notatkę (np. „nie zwracać dopóki nie sprawdzono”).
Jeśli pozwalasz na „login jako użytkownik” lub jakikolwiek dostęp admins jako ten użytkownik, traktuj to jak operację uprzywilejowaną. Wymagaj wyraźnej zgody użytkownika, rejestruj ją i loguj pełne rozpoczęcie/zakończenie sesji w audycie.
Dodaj krótkie szablony przypominające supportowi, co zebrać przed eskalacją: dokładny komunikat błędu, znacznik czasu/strefa czasowa, dotknięte konto lub organizacja, wykonane kroki i jakie działania już wykonano w adminie.
Przykład: klient mówi, że został obciążony dwa razy. Support otwiera workspace, widzi notatkę, że wcześniej zrobiono reset sesji, sprawdza status bilingowy, następnie zapisuje nową notatkę z ID faktur, potwierdzeniem klienta i podjętą akcją zwrotu. Następny agent widzi to od razu i nie powtarza tych samych kroków.
Większość paneli admina zawodzi z nudnych powodów. Nie dlatego, że zespół przegapił jakąś fajną funkcję, ale dlatego, że podstawy sprawiają, że codzienna obsługa jest powolna, ryzykowna lub myląca.
Błędy, które najczęściej zamieniają ekrany admina w pożeracz czasu:
Prosty przykład: support musi pomóc klientowi, który nie może się zalogować po zmianie bilingowej. Bez wyszukiwania nie znajdą konta szybko. Bez audytu nie potwierdzą, co się zmieniło. Bez właściwej kontroli ról albo nie mogą tego naprawić, albo mają zbyt duże uprawnienia.
Jeśli budujesz na platformie takiej jak Koder.ai, traktuj bezpieczeństwo jako funkcję produktu: spraw, by najbezpieczniejsza ścieżka była najprostszą, a ryzykowna — wolna i głośna.
Zanim uznasz go za „gotowy”, zrób reality check. Najlepsze ekrany admina to te, których support może użyć pod presją, z małym kontekstem i bez obawy, że coś zepsuje.
Zacznij od prędkości. Jeśli agent supportu nie może znaleźć użytkownika w mniej niż 10 sekund (po emailu, ID lub org), zgłoszenia będą narastać. Umieść pole wyszukiwania widoczne na pierwszym widoku admina i pokaż pola, których support potrzebuje najbardziej: status, ostatnie logowanie, org, plan.
Następnie sprawdź, czy billing jest możliwy do odczytania jednym rzutem oka. Support powinien widzieć aktualny plan, status bilingowy, ostatni wynik płatności i datę następnego odnowienia na tej samej stronie co klient. Jeśli musi otworzyć trzy zakładki, popełniają się błędy.
Pre-release checklist:
Traktuj każdą ryzykowną akcję jak narzędzie: postaw ją za właściwymi uprawnieniami, dodaj jasny krok potwierdzenia i zaloguj ją. Jeśli budujesz te ekrany admina w narzędziu takim jak Koder.ai, wbuduj te checki w pierwszą wersję, żeby nie musieć dokładać bezpieczeństwa później.
Klient pisze: „Zmieniłem plan i teraz nie mogę się zalogować.” Tu dobre ekrany admina oszczędzają czas, bo support może podążać tą samą ścieżką za każdym razem i unikać zgadywania.
Zacznij od kontroli, które wyjaśniają większość blokad: tożsamość, członkostwo, stan bilingowy, potem uprawnienia. Częstą przyczyną jest użytkownik nadal aktywny, ale jego organizacja została przeniesiona na inny plan, płatność jest przeterminowana lub rola została zmieniona podczas upgrade'u.
Praktyczna kolejność do sprawdzenia:
Jeśli wszystko wygląda poprawnie, sprawdź feature flags. Flaga mogła włączyć nową metodę uwierzytelniania tylko dla niektórych organizacji lub wyłączyć stary login dla konkretnego poziomu planu. Logi plus stan flag zwykle powiedzą, czy to bug, czy konfiguracja.
Zanim zamkniesz zgłoszenie, napisz jasne notatki supportu, aby następny agent nie powtarzał kroków:
Eskaluj do inżynierii tylko wtedy, gdy dołączysz użyteczny kontekst: ID użytkownika, ID organizacji, znaczniki czasu, odpowiednie wpisy w audycie i stan flag w momencie awarii.
Dobre pierwsze wydanie to nie „wszystkie ekrany”. To najmniejszy zestaw, który pozwala supportowi odpowiadać na większość zgłoszeń bez pytania inżyniera. Wypuść, obserwuj, potem dodawaj tylko to, co zasłuży na miejsce.
Na v1 wybierz sześć ekranów, które odblokowują najczęstsze żądania: Overview (status + kluczowe liczniki), Users, Organizations, Roles i permissions (RBAC), Billing i Usage, oraz Logs (audit + system). Jeśli support może zidentyfikować klienta, potwierdzić dostęp, zrozumieć użycie i zobaczyć, co się zmieniło, pokryjesz zaskakująco dużą część codziennej pracy.
Po v1 wybieraj następne ekrany na podstawie zmierzonego wolumenu zgłoszeń. Zwykle oznacza to szczegóły faktur/płatności, eksporty danych, feature flags, workspace supportu (notatki i bezpieczne akcje) oraz wszelkie ustawienia specyficzne dla produktu, które generują zgłoszenia „zmień to za mnie”.
Mierz prostymi sygnałami i przeglądaj je tygodniowo: najczęstsze kategorie zgłoszeń, czas do pierwszej wartościowej odpowiedzi, czas do zamknięcia, jak często support eskaluje do inżynierii oraz które akcje admina są używane najczęściej.
Napisz krótkie runbooki admina dla 10 najważniejszych akcji (2–5 kroków każdy). Dołącz, jak wygląda „dobrze”, co może pójść źle i kiedy przerwać i eskalować.
Na koniec zaplanuj rollback i wersjonowanie zmian konfiguracji. Każdy przełącznik wpływający na klientów (uprawnienia, flagi, ustawienia billingowe) powinien mieć notatki zmian, kto to zmienił i sposób szybkiego odwrócenia.
Jeśli chcesz budować szybko, Koder.ai (koder.ai) jest jedną z opcji do generowania ekranów admina z czatu, potem iterowania w trybie planowania i snapshotów, żeby ryzykowne zmiany łatwiej cofnąć.
Celuj w najmniejszy zestaw ekranów, który pozwala supportowi rozwiązać większość zgłoszeń end-to-end bez angażowania inżyniera.
Praktyczne v1 zwykle obejmuje:
Wyciągnij ostatni miesiąc zgłoszeń (lub oczekiwane listy na pierwsze 90 dni) i oceniaj każde żądanie.
Proste podejście:
Projektuj każdy ekran wokół powtarzalnego przepływu supportu.
Dobry ekran pozwala agentowi:
Jeśli agent nadal musi pytać inżyniera o „jedną brakującą rzecz”, ekran nie jest jeszcze kompletny.
Zacznij od działającego wyszukiwania: email, ID użytkownika, imię i organizacja.
Następnie pokaż sygnały zaufania i status, które support potrzebuje najbardziej:
Utrzymaj akcje spójne i bezpieczne, np. , , , z obowiązkowym powodem i wpisem do audytu.
Pokaż to, czego support potrzebuje, by odpowiedzieć na pytania billingowe jednym rzutem oka:
Oddziel ryzykowne kontrolki (anuluj/zmień plan/wznów) od widoku z potwierdzeniem i wymaganym powodem.
Faktury powinny być zoptymalizowane pod szybkie odpowiedzi, nie edycję.
Zawierać powinny:
Jeśli dopuszczasz akcje, utrzymuj je wąskie (np. ponów płatność) i loguj każdą próbę.
Dopasuj miernik do tego, co widzi klient.
Przynajmniej pokaż:
Typowe kontrolowane akcje to , , czy , wszystkie z notatkami i logowaniem audytu.
Potrzebujesz obu, bo odpowiadają na różne pytania.
Razem pozwalają supportowi powiedzieć „co się stało” bez zgadywania i dają inżynierom stabilny request/event ID przy eskalacji.
Traktuj flagi jako kontrolowane narzędzie supportu.
Dobre domyślne ustawienia:
Jeśli flaga staje się stałym wyborem klienta, przenieś ją do normalnego ustawienia z UI i pomocą.
Eksporty to najprostszy sposób na wyciek danych, więc domyślnie rób je bezpiecznymi.
Zrób to tak:
Utrzymuj przepływ prosty: zakres dat, kilka filtrów i CSV/JSON zależnie od potrzeb.