23 paź 2025·5 min
Filtrowanie po stronie serwera vs klienta: lista kontrolna
Lista kontrolna: kiedy wybrać filtrowanie po stronie serwera lub klienta na podstawie rozmiaru danych, opóźnień, uprawnień i cache'owania — bez wycieków UI i lagów.
Lista kontrolna: kiedy wybrać filtrowanie po stronie serwera lub klienta na podstawie rozmiaru danych, opóźnień, uprawnień i cache'owania — bez wycieków UI i lagów.
Filtrowanie w UI to więcej niż pojedyncze pole wyszukiwania. Zwykle obejmuje kilka powiązanych działań, które zmieniają to, co użytkownik widzi: wyszukiwanie tekstowe (imię, e‑mail, ID zamówienia), facety (status, właściciel, zakres dat, tagi) oraz sortowanie (najpierw najnowsze, najwyższa wartość, ostatnia aktywność).
Kluczowe pytanie nie brzmi, która technika jest „lepsza”. Chodzi o to, gdzie znajduje się pełny zbiór danych i kto ma do niego dostęp. Jeśli przeglądarka otrzyma rekordy, których użytkownik nie powinien widzieć, UI może ujawnić wrażliwe dane, nawet jeśli je wizualnie ukryjesz.
Większość debat o filtrowaniu po stronie serwera vs klienta to reakcje na dwie porażki, które użytkownicy od razu zauważają:
Pojawia się trzeci problem, który generuje mnóstwo zgłoszeń błędów: niespójne wyniki. Jeśli niektóre filtry działają po stronie klienta, a inne po stronie serwera, użytkownicy widzą liczby, strony i sumy, które się nie zgadzają. To szybko podważa zaufanie, szczególnie przy listach z paginacją.
Praktyczny domyślny wybór jest prosty: jeśli użytkownik nie powinien mieć dostępu do całego zbioru danych, filtruj na serwerze. Jeśli ma dostęp i zestaw danych jest na tyle mały, że można go szybko załadować, filtrowanie po stronie klienta jest dopuszczalne.
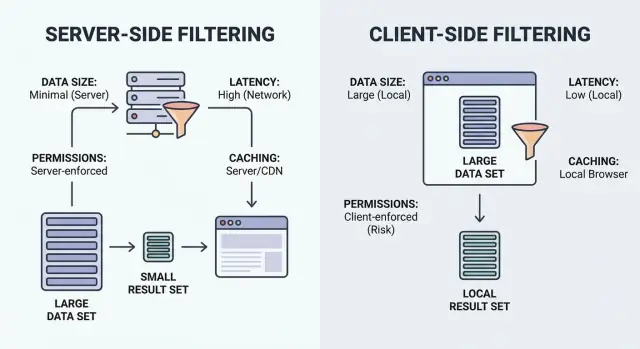
Filtrowanie to po prostu „pokaż elementy, które pasują”. Kluczowe pytanie brzmi: gdzie odbywa się dopasowanie — w przeglądarce użytkownika (klient) czy na backendzie (serwer).
Filtrowanie po stronie klienta działa w przeglądarce. Aplikacja pobiera zestaw rekordów (zwykle JSON), a następnie stosuje filtry lokalnie. Może to działać natychmiast po załadowaniu danych, ale sprawdza się tylko wtedy, gdy zbiór danych jest na tyle mały, że można go wysłać i na tyle bezpieczny, by go ujawnić.
Filtrowanie po stronie serwera odbywa się na backendzie. Przeglądarka wysyła wartości filtrów (np. status=open, owner=me, createdAfter=Jan 1), a serwer zwraca tylko pasujące wyniki. W praktyce to zwykle endpoint API, który przyjmuje filtry, buduje zapytanie do bazy i zwraca paginowaną listę plus sumy.
Prosty model mentalny:
Hybrydowe rozwiązania są powszechne. Dobrym wzorcem jest wymuszanie „dużych” filtrów na serwerze (uprawnienia, właściciel, zakres dat, wyszukiwanie), a następnie używanie małych, wyłącznie UI‑owych przełączników lokalnie (ukryj archiwalne, szybkie tagi, widoczność kolumn) bez dodatkowego żądania.
Sortowanie, paginacja i wyszukiwanie zwykle należą do tej samej decyzji. Wpływają na rozmiar payloadu, odczucie użytkownika i to, jakie dane ujawniasz.
Zacznij od najpraktyczniejszego pytania: ile danych wysłałbyś do przeglądarki, gdyby filtrowanie odbywało się po stronie klienta? Jeśli szczera odpowiedź to „więcej niż kilka ekranów”, zapłacisz za to w czasie pobierania, zużyciu pamięci i wolniejszych interakcjach.
Nie potrzebujesz perfekcyjnych szacunków. Wystarczy rząd wielkości: ile wierszy użytkownik może zobaczyć i jaki jest średni rozmiar wiersza? Lista 500 elementów z kilkoma krótkimi polami to co innego niż 50 000 elementów, gdzie każdy wiersz zawiera długie notatki, bogaty tekst lub zagnieżdżone obiekty.
Szerokie rekordy to cichy zabójca payloadów. Tabela może wyglądać na małą pod względem liczby wierszy, ale być ciężka, jeśli każdy wiersz zawiera wiele pól, duże ciągi tekstowe lub połączone dane (kontakt + firma + ostatnia aktywność + pełny adres + tagi). Nawet jeśli pokazujesz tylko trzy kolumny, zespoły często wysyłają „wszystko, na wszelki wypadek” i payload puchnie.
Pomyśl też o wzroście. Zbiór danych, który jest w porządku dziś, może stać się uciążliwy po kilku miesiącach. Jeśli dane szybko rosną, traktuj filtrowanie po stronie klienta jako krótkoterminowe obejście, a nie domyślne rozwiązanie.
Zasady praktyczne:
Ten ostatni punkt ma znaczenie nie tylko dla wydajności. Pytanie „Czy możemy wysłać cały zbiór danych do przeglądarki?” jest także pytaniem bezpieczeństwa. Jeśli odpowiedź nie jest zdecydanym „tak”, nie wysyłaj tego.
Wybory dotyczące filtrowania często zawodzą na odczuciu, nie na poprawności. Użytkownicy nie mierzą milisekund. Zauważają przerwy, migotanie i wyniki, które skaczą podczas pisania.
Czas może ginąć w różnych miejscach:
Zdefiniuj, co oznacza „wystarczająco szybko” dla tego ekranu. Widok listy może wymagać responsywnego pisania i płynnego przewijania, podczas gdy strona raportu może tolerować krótkie oczekiwanie o ile pierwszy wynik pojawi się szybko.
Nie oceniaj tylko po biurowym Wi‑Fi. Przy wolnych połączeniach filtrowanie po stronie klienta może działać świetnie po pierwszym ładowaniu, ale ten pierwszy załadunek może być wolny. Filtrowanie po stronie serwera trzyma payloady małe, ale może wydawać się powolne, jeśli wyzwalasz żądanie przy każdym naciśnięciu klawisza.
Projektuj z myślą o ludzkim wprowadzaniu. Debouncuj żądania podczas pisania. Dla dużych zestawów wyników stosuj ładowanie progresywne, aby strona pokazywała coś szybko i pozostała płynna podczas przewijania.
To uprawnienia powinny decydować o podejściu do filtrowania bardziej niż szybkość. Jeśli przeglądarka kiedykolwiek otrzyma dane, których użytkownik nie powinien widzieć, już masz problem, nawet jeśli je ukryjesz za nieaktywnym przyciskiem lub złożoną kolumną.
Zacznij od wymienienia, co jest wrażliwe na tym ekranie. Niektóre pola są oczywiste (e‑maile, telefony, adresy). Inne łatwo przeoczyć: notatki wewnętrzne, koszt lub marża, specjalne zasady cenowe, oceny ryzyka, flagi moderacji.
Wielką pułapką jest „filtrujemy po stronie klienta, ale pokazujemy tylko dozwolone wiersze”. To wciąż oznacza, że pełny zbiór danych został pobrany. Każdy może sprawdzić odpowiedź sieciową, otworzyć dev tools lub zapisać payload. Ukrywanie kolumn w UI to nie kontrola dostępu.
Filtrowanie po stronie serwera jest bezpieczniejszym domyślnym wyborem, gdy autoryzacja różni się w zależności od użytkownika, szczególnie gdy różni użytkownicy widzą różne wiersze lub pola.
Szybki check:
Jeśli na którekolwiek pytanie odpowiesz „tak”, trzymaj filtrowanie i wybór pól po stronie serwera. Wysyłaj tylko to, co użytkownik ma prawo zobaczyć, i stosuj te same reguły do wyszukiwania, sortowania, paginacji i eksportu.
Przykład: w liście kontaktów CRM handlowcy widzą tylko swoje konta, menedżerowie widzą wszystkie w swoim zespole. Jeśli przeglądarka pobiera wszystkie kontakty i filtruje lokalnie, handlowiec i tak może odzyskać ukryte konta z odpowiedzi. Filtrowanie po stronie serwera zapobiega temu, nigdy nie wysyłając tych wierszy.
Cache może sprawić, że ekran będzie działał natychmiast. Może też pokazać nieprawdę. Kluczowe jest zdecydowanie, co można ponownie użyć, jak długo i jakie zdarzenia powinny to unieważnić.
Zacznij od wyboru jednostki cache. Cache całej listy jest prosty, ale zwykle marnuje pasmo i szybko się starzeje. Cache stron działa dobrze dla infinite scroll. Cache wyników zapytania (filtr + sort + wyszukiwanie) jest dokładny, ale może rosnąć szybko, jeśli użytkownicy testują wiele kombinacji.
Świeżość ma większe znaczenie w niektórych domenach niż w innych. Jeśli dane zmieniają się szybko (poziomy zapasów, salda, statusy dostaw), nawet 30‑sekundowy cache może mylić użytkowników. Jeśli dane zmieniają się wolno (archiwalne rekordy, dane referencyjne), dłuższe cachowanie zwykle jest w porządku.
Zaplanuj unieważnianie zanim zaczniesz pisać kod. Oprócz upływu czasu, zdecyduj, co powinno wymusić odświeżenie: tworzenia/edycje/usuwania, zmiany uprawnień, importy zbiorcze lub mergy, przejścia statusów, cofnij/rollback oraz zadania w tle, które aktualizują pola, po których użytkownicy filtrują.
Zdecyduj również, gdzie cache będzie żył. Pamięć przeglądarki przyspiesza nawigację wstecz/do przodu, ale może przeciekać dane między kontami, jeśli nie kluczuje się po użytkowniku i organizacji. Cache na backendzie jest bezpieczniejszy pod względem uprawnień i spójności, ale musi zawierać pełny podpis filtrów i tożsamość wywołującego, by wyniki się nie pomieszały.
Traktuj cel jako niepodlegający negocjacjom: ekran powinien być szybki bez wyciekania danych.
Większość zespołów wpada w te same wzorce: UI wygląda świetnie na demo, potem prawdziwe dane, prawdziwe uprawnienia i rzeczywiste prędkości sieci ujawniają pęknięcia.
Najpoważniejsza porażka to traktowanie filtrowania jako prezentacji. Jeśli przeglądarka otrzyma rekordy, których nie powinna mieć, już przegrałeś.
Dwa częste powody:
Przykład: praktykanci powinni widzieć tylko leady ze swojego regionu. Jeśli API zwraca wszystkie regiony, a dropdown filtruje w React, praktykant i tak może wydobyć całą listę.
Opóźnienia często wynikają z założeń:
Subtelny, ale bolesny problem to niespójne reguły. Jeśli serwer traktuje „rozpoczyna się od” inaczej niż UI, użytkownicy widzą liczby, które się nie zgadzają, lub przedmioty znikające po odświeżeniu.
Zrób ostatnie przejście z dwoma podejściami: ciekawy użytkownik i kiepska sieć.
Prosty test: utwórz ograniczony rekord i potwierdź, że nigdy nie pojawia się w payloadzie, sumach ani cache, nawet gdy filtrujesz szeroko lub czyścisz filtry.
Wyobraź sobie CRM z 200 000 kontaktów. Handlowcy widzą tylko swoje konta, menedżerowie widzą zespół, a admini wszystko. Ekran ma wyszukiwanie, filtry (status, właściciel, ostatnia aktywność) i sortowanie.
Filtrowanie po stronie klienta szybko zawodzi. Payload robi się ciężki, pierwszy załadunek zwalnia, a ryzyko wycieku danych jest wysokie. Nawet jeśli UI ukrywa wiersze, przeglądarka i tak otrzymała dane. Dodatkowo obciążasz urządzenie: duże tablice, ciężkie sortowania, częste uruchamianie filtrów, duże zużycie pamięci i awarie na starszych telefonach.
Bezpieczniejsze podejście to filtrowanie po stronie serwera z paginacją. Klient wysyła wybory filtrów i tekst wyszukiwania, a serwer zwraca tylko wiersze, które użytkownik może zobaczyć, już przefiltrowane i posortowane.
Praktyczny wzorzec:
Małe wyjątki, gdzie filtrowanie klienta jest w porządku: drobne, statyczne dane. Dropdown „Status kontaktu” z 8 wartościami można załadować raz i filtrować lokalnie bez dużego ryzyka czy kosztu.
Zespoły rzadko płoną przez wybranie „złego” rozwiązania raz. Płoną przez podejmowanie różnych decyzji na każdym ekranie i potem naprawianie wycieków i wolnych stron pod presją.
Zapisz krótką notatkę decyzyjną dla każdego ekranu: rozmiar zbioru, koszt wysyłu, co oznacza „wystarczająco szybko”, które pola są wrażliwe i jak wyniki mają być cache'owane (albo że nie będą). Trzymaj backend i UI w zgodzie, by nie powstały „dwie prawdy” dla filtrowania.
Jeśli szybko budujesz ekrany w Koder.ai (koder.ai), warto zdecydować z góry, które filtry muszą być egzekwowane na backendzie (uprawnienia i dostęp na poziomie wierszy), a które drobne, wyłącznie UI‑owe przełączniki mogą pozostać w warstwie React. Ta jedna decyzja często zapobiega najdroższym przepisywaniom później.
Domyślnie wybieraj filtrowanie po stronie serwera, gdy użytkownicy mają różne uprawnienia, zbiór danych jest duży lub zależy Ci na spójnej paginacji i sumach. Filtrowanie po stronie klienta stosuj tylko wtedy, gdy cały zbiór danych jest mały, bezpieczny do ujawnienia i szybko się pobiera.
Ponieważ wszystko, co przeglądarka otrzyma, można przejrzeć. Nawet jeśli interfejs ukrywa wiersze lub kolumny, użytkownik może sprawdzić odpowiedź sieciową, pamięć podręczną lub obiekty w pamięci.
Zwykle dzieje się tak, gdy wysyłasz za dużo danych i następnie filtrujesz/sortujesz duże tablice przy każdym naciśnięciu klawisza, albo gdy wyzwalasz zapytanie do serwera przy każdym naciśnięciu bez debouncowania. Trzymaj payloady małe i unikaj ciężkiej pracy przy każdej zmianie wejścia.
Zachowaj jedno źródło prawdy dla „prawdziwych” filtrów: uprawnienia, wyszukiwanie, sortowanie i paginacja powinny być egzekwowane po stronie serwera razem. Ogranicz logikę po stronie klienta do drobnych przełączników UI, które nie zmieniają podstawowego zbioru danych.
Cache po stronie klienta może pokazywać nieaktualne lub błędne dane i może ujawniać dane między kontami, jeśli klucz cache nie uwzględnia tożsamości użytkownika. Cache po stronie serwera jest bezpieczniejszy dla uprawnień, ale musi zawierać pełny podpis zapytania (filtry) oraz tożsamość wywołującego, by wyniki się nie pomieszały.
Zadaj dwie pytania: ile wierszy użytkownik realnie może mieć i jak duży jest każdy wiersz w bajtach. Jeśli nie załadowałbyś tego komfortowo przez typowe mobilne łącze lub na starszym urządzeniu, przenieś filtrowanie na serwer i wprowadź paginację.
Po stronie serwera. Jeśli role, zespoły, regiony lub reguły własności zmieniają to, co ktoś może zobaczyć, serwer musi egzekwować dostęp do wierszy i pól. Klient powinien otrzymywać tylko te rekordy i pola, które użytkownik może zobaczyć.
Zdefiniuj kontrakt filtrów i sortowania najpierw: akceptowane pola filtrów, domyślne sortowanie, zasady paginacji oraz jak działa dopasowanie w wyszukiwarce (wielkość liter, znaki diakrytyczne, dopasowania częściowe). Następnie wdroż tę samą logikę konsekwentnie na backendzie i przetestuj, że sumy i strony się zgadzają.
Debouncuj wpisywanie, żeby nie wysyłać żądań przy każdym naciśnięciu, i trzymaj stare wyniki widoczne, dopóki nie nadejdą nowe, by ograniczyć migotanie. Używaj paginacji lub ładowania progresywnego, aby użytkownik zobaczył coś szybko bez blokowania się na ogromnej odpowiedzi.
Najpierw stosuj uprawnienia, potem filtry i sortowanie, i zwracaj tylko jedną stronę oraz liczbę wszystkich pasujących wierszy. Unikaj wysyłania „dodatkowych pól na wszelki wypadek” i upewnij się, że klucze cache zawierają user/org/role, aby przedstawiciel nie otrzymał danych menedżera.