08 cze 2025·8 min
Jak gwarancje ACID kształtują niezawodne systemy transakcyjne
Dowiedz się, jak gwarancje ACID wpływają na projekt baz danych i zachowanie aplikacji. Poznaj atomicity, consistency, isolation, durability, kompromisy i przykłady.
Dowiedz się, jak gwarancje ACID wpływają na projekt baz danych i zachowanie aplikacji. Poznaj atomicity, consistency, isolation, durability, kompromisy i przykłady.
Gdy płacisz za zakupy, rezerwujesz lot lub przesuwasz pieniądze między kontami, oczekujesz jednoznacznego wyniku: albo się udało, albo nie. Bazy danych dążą do tej samej pewności — nawet gdy wielu użytkowników korzysta z systemu jednocześnie, serwery padają lub sieć ma przestoje.
Transakcja to pojedyncza jednostka pracy, którą baza traktuje jak jeden „pakiet”. Może obejmować kilka kroków — zmniejszenie zapasów, utworzenie zamówienia, obciążenie karty i zapis paragonu — ale ma zachowywać się jak jedna spójna operacja.
Jeśli którykolwiek krok zawiedzie, system powinien przewinąć zmiany do bezpiecznego punktu, zamiast zostawiać pół‑ukończony bałagan.
Częściowe aktualizacje to nie tylko błędy techniczne; zmieniają się w zgłoszenia do obsługi i ryzyko finansowe. Na przykład:
Takie błędy są trudne do debugowania, bo wszystko wygląda „w miarę poprawnie”, a jednak liczby nie sumują się.
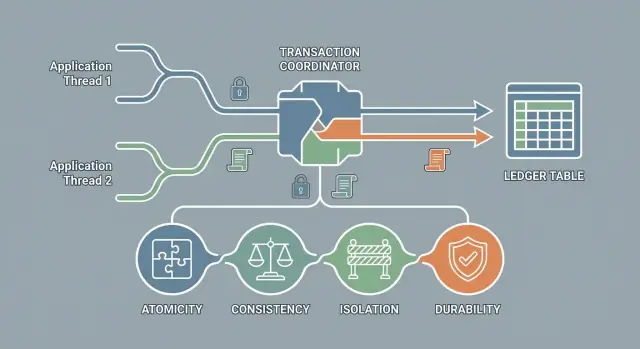
ACID to skrót od czterech gwarancji, które wiele baz danych może zapewnić dla transakcji:
To nie jest marka bazy danych ani pojedyncza opcja do przełączania; to obietnica dotycząca zachowania systemu.
Silniejsze gwarancje zwykle oznaczają, że baza musi wykonać więcej pracy: dodatkowa koordynacja, czekanie na blokady, śledzenie wersji i zapisywanie do dzienników. To może zmniejszyć przepustowość lub zwiększyć opóźnienia przy dużym obciążeniu. Celem nie jest „maksymalne ACID zawsze”, lecz wybór poziomu gwarancji dopasowanego do realnego ryzyka biznesowego.
Atomicity oznacza, że transakcja jest traktowana jako pojedyncza jednostka pracy: albo zakończy się w całości, albo nie będzie miała żadnego efektu. Nigdy nie zobaczysz „połowicznej aktualizacji” w bazie.
Wyobraź sobie przesunięcie 50 USD z konta Alicji na konto Boba. W praktyce to zwykle co najmniej dwie zmiany:
Dzięki atomicity te dwie zmiany albo udają się razem, albo obie są odrzucane. To zapobiega koszmarowi, w którym Alicja zostaje obciążona, a Bob nie otrzymuje środków (lub odwrotnie).
Bazy danych dają transakcjom dwa wyjścia:
Przydatny model mentalny to „roboczy szkic vs. opublikowane”. Podczas działania transakcji zmiany są prowizoryczne. Dopiero commit je publikuje.
Atomicity ma znaczenie, bo awarie są normalne:
Jeśli któreś z tych zdarzeń nastąpi przed ukończeniem commitu, atomicity zapewnia, że baza może cofnąć zmiany, aby częściowa praca nie przeszła do realnych sald.
Atomicity chroni stan bazy, ale aplikacja nadal musi radzić sobie z niepewnością — szczególnie gdy utrata sieci sprawia, że nie wiadomo, czy commit nastąpił.
Dwa praktyczne uzupełnienia:
Razem: atomowe transakcje i idempotentne powtórzenia pomagają uniknąć zarówno częściowych aktualizacji, jak i przypadkowych podwójnych obciążeń.
W ACID „consistency” nie oznacza „dane wyglądają rozsądnie” ani „wszystkie repliki się zgadzają”. Oznacza to, że każda transakcja musi przenieść bazę ze stanu ważnego do innego stanu ważnego — zgodnie z regułami, które definiujesz.
Baza danych może utrzymywać spójność tylko względem jawnych ograniczeń, triggerów i inwariantów, które opisują, co znaczy „prawidłowe” dla twojego systemu. ACID nie wymyśla tych reguł; egzekwuje je podczas transakcji.
Typowe przykłady:
order.customer_id musi wskazywać na istniejącego klienta.Jeśli te reguły są zdefiniowane, baza odrzuci każdą transakcję, która by je złamała — nie skończysz z „półpoprawnymi” danymi.
Walidacja po stronie aplikacji jest ważna, ale sama w sobie nie wystarcza.
Klasyczny błąd to sprawdzać w aplikacji, czy e‑mail jest wolny, a potem wstawić wiersz. Przy współbieżności dwa żądania mogą przejść sprawdzenie jednocześnie. To ograniczenie unikalności w bazie zapewnia, że tylko jedno wstawienie powiedzie się.
Jeśli zakodujesz „saldo nie może być ujemne” jako ograniczenie (lub zapewnisz jego egzekwowanie w jednej transakcji), każdy transfer, który spowodowałby debet poniżej zera, musi się nie powieść w całości. Jeśli nigdzie nie zapiszesz tej reguły, ACID nie ochroni jej — bo nie ma czego egzekwować.
Consistency to w skrócie jawność: zdefiniuj reguły, a transakcje zadbają o to, by nigdy ich nie złamać.
Isolation zapewnia, że transakcje nie depczą po sobie. Gdy jedna transakcja trwa, inne nie powinny widzieć pół‑ukończonej pracy ani przypadkowo jej nadpisywać. Cel jest prosty: każda transakcja powinna zachowywać się tak, jakby wykonywała się samodzielnie, nawet gdy wielu użytkowników działa jednocześnie.
Systemy produkcyjne są zajęte: klienci składają zamówienia, agenci aktualizują profile, zadania w tle uzgadniają płatności — wszystko jednocześnie. Te akcje nachodzą się w czasie i często operują na tych samych wierszach (saldo konta, liczba zapasów, dostępność terminu).
Bez izolacji czas wykonywania staje się częścią logiki biznesowej. Aktualizacja „odejmij zapas” może rywalizować z innym checkoutem, a raport może czytać dane w trakcie zmiany i pokazać liczby, które nigdy nie istniały w stabilnym stanie.
Pełna izolacja „jakbyś był sam” może być kosztowna. Zwiększa oczekiwanie (blokady), może powodować powtórzenia transakcji i spadek przepustowości. Wielu workflowom nie potrzeba najsurowszej ochrony — odczyty raportów z wczoraj np. tolerują drobne niespójności.
Dlatego bazy oferują konfigurowalne poziomy izolacji: wybierasz, ile ryzyka współbieżności akceptujesz, w zamian za lepszą wydajność i mniej konfliktów.
Przy zbyt słabej izolacji napotkasz klasyczne anomalie:
Zrozumienie tych trybów błędnych pomaga dobrać poziom izolacji pasujący do obietnic twojego produktu.
Izolacja decyduje, co inne transakcje mogą „zobaczyć”, gdy twoja nadal działa. Gdy izolacja jest za słaba, pojawiają się anomalie — zachowania technicznie możliwe, ale zaskakujące dla użytkowników.
Dirty read zdarza się, gdy odczytujesz dane napisane przez inną transakcję, która jeszcze nie zatwierdziła swoich zmian.
Scenariusz: Alex transferuje 500 USD z konta, saldo tymczasowo pokazuje 200 USD, a ty to odczytujesz zanim transfer później się cofnie.
Skutek dla użytkownika: klient widzi błędnie niskie saldo, reguła antyfraudowa może zadziałać fałszywie, albo agent wsparcia poda zły wynik.
Non-repeatable read oznacza, że czytasz ten sam wiersz dwukrotnie i otrzymujesz różne wartości, bo inna transakcja zatwierdziła zmianę między odczytami.
Scenariusz: Ładujesz sumę zamówienia (49,00 USD), odświeżasz i widzisz 54,00 USD, bo usunięto linię z rabatem.
Skutek: „Moja kwota zmieniła się w trakcie realizacji” — utrata zaufania, porzucenie koszyka.
Phantom read to non‑repeatable read, ale dla zestawu wierszy: drugie zapytanie zwraca więcej (lub mniej) wierszy, bo ktoś inny dodał lub usunął pasujące rekordy.
Scenariusz: Wyszukiwanie dostępności hotelowej pokazuje „3 pokoje”, potem przy próbie rezerwacji okazuje się, że już nie ma żadnego.
Skutek: próby podwójnej rezerwacji, niespójne ekrany dostępności, oversell.
Lost update występuje, gdy dwie transakcje odczytują tę samą wartość i obie zapisują aktualizacje, przy czym późniejszy zapis nadpisuje wcześniejszy.
Scenariusz: Dwóch administratorów edytuje cenę produktu. Obaj zaczynają od 10; jeden zapisuje 12, drugi zapisuje 11 jako ostatni.
Skutek: czyjaś zmiana znika; raporty i sumy są błędne.
Write skew zdarza się, gdy dwie transakcje każda wykonuje zmianę, która osobno jest poprawna, ale łącznie łamie regułę.
Scenariusz: Reguła „przynajmniej jeden lekarz na dyżurze”. Dwóch lekarzy niezależnie oznacza siebie jako nieobecnych, po sprawdzeniu, że drugi jest nadal na dyżurze.
Skutek: brak obsady mimo, że każda transakcja indywidualnie „przeszła”.
Silniejsza izolacja redukuje anomalie, ale zwiększa czekanie, powtórzenia i koszty przy dużej współbieżności. Wiele systemów wybiera słabszą izolację dla odczytów analitycznych, a silniejszą dla transferów pieniędzy, rezerwacji i innych krytycznych przepływów poprawności.
Izolacja dotyczy tego, co twoja transakcja może zobaczyć, gdy inne działają. Bazy udostępniają to jako poziomy izolacji: wyższe poziomy zmniejszają zaskakujące zachowania, ale mogą kosztować przepustowość lub zwiększać oczekiwanie.
Zespoły często wybierają Read Committed jako domyślne dla aplikacji użytkowych: dobra wydajność i brak dirty reads pokrywa większość oczekiwań.
Użyj Repeatable Read, gdy potrzebujesz stabilnych wyników wewnątrz transakcji (np. generowanie faktury) i możesz zaakceptować dodatkowy narzut.
Użyj Serializable, gdy poprawność jest ważniejsza niż współbieżność (np. aby nigdy nie sprzedać więcej niż masz), lub gdy trudno rozsądnie przewidzieć warunki wyścigów w kodzie aplikacji.
Read Uncommitted jest rzadki w systemach OLTP; czasem używa się go do monitoringu lub przybliżonych raportów, gdzie sporadyczne niepoprawne odczyty są akceptowalne.
Nazwy są zunifikowane, ale dokładne gwarancje różnią się w zależności od silnika bazy (a czasem od konfiguracji). Sprawdź dokumentację twojej bazy i przetestuj anomalie ważne dla twojego biznesu.
Durability oznacza, że gdy transakcja jest zatwierdzona, jej efekty powinny przetrwać awarię — utratę zasilania, restart procesu czy nagły reboot maszyny. Jeśli aplikacja mówi klientowi „płatność udana”, durability to zapewnienie, że baza nie „zapomni” o tym po kolejnej awarii.
Większość relacyjnych baz osiąga durability dzięki write-ahead logging (WAL). Na wysokim poziomie baza zapisuje sekwencyjne „potwierdzenie” zmian do dziennika na dysku zanim uzna transakcję za zatwierdzoną. Jeśli baza ulegnie awarii, podczas startu może odtworzyć log, aby przywrócić zatwierdzone zmiany.
Aby czas odzyskiwania był rozsądny, bazy tworzą też checkpointy. Checkpoint to moment, w którym baza zapewnia, że wystarczająca część ostatnich zmian jest zapisana w głównych plikach danych, żeby odzyskiwanie nie musiało odtwarzać nieograniczonej historii z logu.
Durability nie jest jedynym włącznikiem; zależy od tego, jak agresywnie baza wymusza zapis na trwałe nośniki.
fsync) przed potwierdzeniem commitu. To bezpieczniejsze, ale może zwiększyć opóźnienie.Również sprzęt ma znaczenie: dyski SSD, kontrolery RAID z cachem zapisu czy wolumeny chmurowe różnie zachowują się przy awariach.
Kopie zapasowe i replikacja pomagają odzyskać lub zmniejszyć przestój, ale nie są tym samym co durability. Transakcja może być durable na primary, nawet jeśli nie dotarła jeszcze do repliki, a backupy zwykle są snapshotami punktowymi, a nie gwarancją commit‑po‑commicie.
Gdy BEGIN transakcji i później COMMIT, baza koordynuje wiele elementów: kto może czytać które wiersze, kto może je aktualizować i co się dzieje, gdy dwie osoby próbują zmienić ten sam rekord.
Kluczowy wybór „pod maską” to sposób obsługi konfliktów:
Wiele systemów miksuje oba podejścia zależnie od obciążenia i poziomu izolacji.
Nowoczesne bazy często używają MVCC (Multi-Version Concurrency Control): zamiast trzymać tylko jedną kopię wiersza, baza przechowuje wiele wersji.
To główny powód, dla którego niektóre bazy radzą sobie z wieloma odczytami i zapisami jednocześnie bez dużego blokowania — choć konflikty zapis‑zapis wciąż trzeba rozwiązać.
Blokady mogą prowadzić do deadlocków: Transakcja A czeka na blokadę trzymaną przez B, a B czeka na blokadę trzymaną przez A.
Bazy zwykle wykrywają taki cykl i przerywają jedną transakcję („ofiara deadlocku”), zwracając błąd, żeby aplikacja mogła spróbować ponownie.
Jeśli egzekwowanie ACID zaczyna przeszkadzać, często zobaczysz:
Te symptomy zwykle oznaczają, że warto przejrzeć rozmiar transakcji, indeksowanie lub strategię izolacji/blokad.
Gwarancje ACID to nie tylko teoria baz danych — wpływają na projektowanie API, zadań w tle i nawet przepływów UI. Podstawowy pomysł: zdecyduj, które kroki muszą się powieść razem, a potem opakuj tylko te kroki w transakcję.
Dobre API transakcyjne zwykle odpowiada jednej akcji biznesowej, nawet jeśli dotyczy wielu tabel. Na przykład operacja /checkout może: utworzyć zamówienie, zarezerwować zapas i zapisać intencję płatności. Te zapisy do bazy zazwyczaj powinny znaleźć się w jednej transakcji, żeby zatwierdzały się razem (albo były wspólnie wycofywane).
Powszechny wzorzec:
To zachowuje atomicity i consistency, a jednocześnie unika powolnych, kruchych transakcji.
Gdzie zamknąć transakcję zależy od tego, co znaczy „jedna jednostka pracy”:
ACID pomaga, ale aplikacja nadal musi poprawnie radzić sobie z awariami:
Unikaj długich transakcji, wywołań API zewnętrznych wewnątrz transakcji oraz czasu myślenia użytkownika w transakcji (np. „zablokuj wiersz koszyka, poproś użytkownika o potwierdzenie”). Zwiększają one zawartość i sprawiają, że konflikty izolacji są znacznie bardziej prawdopodobne.
Jeśli budujesz system transakcyjny szybko, największe ryzyko rzadko wynika z „nieznajomości ACID” — częściej z przypadkowego rozproszenia jednej akcji biznesowej na wiele endpointów, zadań czy tabel bez wyraźnej granicy transakcji.
Platformy takie jak Koder.ai mogą pomóc przyspieszyć pracę, jednocześnie projektując wokół ACID: opisz przepływ (np. „checkout z rezerwacją zapasów i intencją płatności”) w czacie planującym, wygeneruj UI w React i backend Go + PostgreSQL, i iteruj ze snapshotami/cofnięciami, jeśli schemat lub granice transakcji wymagają zmiany. Baza nadal egzekwuje gwarancje; wartość polega na szybszym przełożeniu poprawnego projektu na działającą implementację.
Pojedyncza baza zwykle dostarcza gwarancje ACID w ramach jednej granicy transakcji. Gdy rozprosisz pracę między wiele serwisów (i często wiele baz), utrzymanie tych samych gwarancji staje się trudniejsze — i droższe, gdy się o nie walczy.
Ścisła spójność oznacza, że każdy odczyt widzi „najświeższą zatwierdzoną prawdę”. Wysoka dostępność oznacza, że system nadal odpowiada, nawet gdy część jest wolna lub nieosiągalna.
W konfiguracji wieloserwisowej tymczasowy problem sieci może zmusić do decyzji: blokować lub odrzucać żądania, aż wszyscy uczestnicy się zgodzą (więcej spójności, mniej dostępności), albo zaakceptować krótkotrwałe niesynchroniczności (więcej dostępności, mniej spójności). Żadne z tych rozwiązań nie jest uniwersalnie „dobre” — zależy od tego, jakich błędów biznes może tolerować.
Transakcje rozproszone wymagają koordynacji między granicami, których w pełni nie kontrolujesz: opóźnienia sieci, powtórzenia, timouty, awarie serwisów i częściowe błędy.
Nawet gdy każdy serwis działa poprawnie, sieć może stworzyć dwuznaczność: czy serwis płatności zatwierdził, ale serwis zamówień nie otrzymał potwierdzenia? Aby to bezpiecznie rozwiązać, systemy używają protokołów koordynacyjnych (np. two‑phase commit), które bywają wolne, obniżają dostępność przy awariach i zwiększają złożoność operacyjną.
Sagi dzielą workflow na kroki, z których każdy zatwierdzany jest lokalnie. Jeśli późny krok zawiedzie, wcześniejsze są „odwracane” przez akcje kompensacyjne (np. zwrot płatności).
Outbox/inbox sprawiają, że publikowanie zdarzeń i ich konsumowanie jest niezawodne. Serwis zapisuje dane biznesowe i rekord „do opublikowania” w tej samej lokalnej transakcji (outbox). Konsumenci zapisują przetworzone identyfikatory wiadomości (inbox), by obsłużyć powtórzenia bez duplikowania efektów.
Eventual consistency akceptuje krótkie okienka różnic między serwisami, z jasnym planem pogodzenia danych.
Luzuj gwarancje, gdy:
Kontroluj ryzyko, definiując niezmienniki (co nigdy nie może być złamane), projektując idempotentne operacje, używając timeoutów i backoffów przy powtórzeniach oraz monitorując dryf (zawieszone sagi, powtarzane kompensacje, rosnące tabele outbox). Dla krytycznych inwariantów (np. „nigdy nie przekroczyć salda konta”) trzymaj je w obrębie jednego serwisu i jednej transakcji bazy, jeśli to możliwe.
Transakcja może być „poprawna” w teście jednostkowym, a i tak zawieść pod realnym obciążeniem, restartami i współbieżnością. Użyj tej listy kontrolnej, aby dopilnować, że gwarancje ACID odpowiadają zachowaniu twojego systemu w produkcji.
Zacznij od spisania, co musi zawsze być prawdą (twoje inwarianty danych). Przykłady: „saldo konta nigdy nie ujemne”, „suma zamówienia równa się sumie jego pozycji”, „zapasy nie mogą spaść poniżej zera”, „płatność powiązana z dokładnie jednym zamówieniem”. Traktuj je jako reguły produktu, nie jako bazy danych.
Następnie zdecyduj, co musi być w jednej transakcji, a co można odłożyć.
Trzymaj transakcje małe: dotykaj mniej wierszy, wykonuj mniej pracy (bez wywołań zewnętrznych), commituj szybko.
Uczyń współbieżność pierwszoplanowym wymiarem testów.
Jeśli wspierasz powtórzenia, dodaj klucz idempotencyjny i test „żądanie powtórzone po sukcesie”.
Obserwuj wskaźniki, które pokażą, że gwarancje stają się kosztowne lub kruche:
Alertuj na trendy, nie tylko na skoki, i powiąż metryki z endpointami lub zadaniami, które je powodują.
Używaj najsłabszej izolacji, która nadal chroni twoje inwarianty; nie ustawiaj najwyższej domyślnie. Gdy potrzebujesz ścisłej poprawności dla małego krytycznego fragmentu (transfery pieniędzy, dekrementacja zapasu), zawęż transakcję tylko do tego fragmentu i trzymaj resztę poza nią.
ACID to zestaw gwarancji transakcyjnych, które pomagają bazom danych zachowywać przewidywalność przy awariach i współbieżności:
Transakcja to pojedyncza „jednostka pracy”, którą baza traktuje jako jeden pakiet. Nawet jeśli wykonuje wiele poleceń SQL (np. utworzenie zamówienia, zmniejszenie zapasu, zapis intencji płatności), ma tylko dwa wyniki:
Częściowe aktualizacje tworzą realne sprzeczności, które są kosztowne do naprawy, na przykład:
ACID (szczególnie atomicity + consistency) zapobiega pojawieniu się takich „półukończonych” stanów jako prawdy.
Atomicity gwarantuje, że baza nigdy nie ujawnia „półskończonej” transakcji. Jeśli coś zawiedzie przed commitem — awaria aplikacji, utrata sieci, restart DB — transakcja zostanie cofnięta, aby wcześniejsze kroki nie wyciekły do trwałego stanu.
W praktyce atomicity sprawia, że wielokrokowe zmiany (np. przelew aktualizujący dwa salda) są bezpieczne.
Nie zawsze wiadomo, czy commit się powiódł, gdy klient traci odpowiedź (np. timeout sieci tuż po commicie). Dlatego łączymy transakcje ACID z:
To zapobiega zarówno częściowym aktualizacjom, jak i przypadkowemu podwójnemu obciążeniu/zapisowi.
W ACID „consistency” oznacza, że baza przechodzi z jednego prawidłowego stanu do innego zgodnie z regułami, które sam zdefiniujesz — ograniczeniami, kluczami obcymi, unikalnością i checkami.
Jeśli nie zakodujesz reguły (np. „saldo nie może być ujemne”), ACID nie ochroni jej automatycznie. Baza potrzebuje jawnych inwariantów, aby móc je egzekwować.
Walidacja w aplikacji poprawia UX i może egzekwować złożone reguły, ale zawodzi przy współbieżności (dwa żądania mogą przejść sprawdzenie jednocześnie).
Ograniczenia bazy to ostateczna strażnica:
Używaj obu podejść: sprawdzaj wcześnie w aplikacji, wymuszaj jednoznacznie w bazie.
Izolacja kontroluje, co twoja transakcja może zobaczyć, gdy inne są w toku. Słaba izolacja może powodować anomalie, takie jak:
Poziomy izolacji pozwalają wymienić wydajność na ochronę przed tymi anomaliami.
Praktyczny punkt wyjścia to Read Committed w wielu aplikacjach OLTP — zapobiega dirty reads i ma dobrą wydajność. Podnoś poziom, gdy potrzebujesz:
Zawsze weryfikuj zachowanie w konkretnej silniku bazy danych, bo szczegóły się różnią.
Durability oznacza, że po potwierdzeniu commit zmiana przetrwa awarie. Zwykle realizuje się to przez write-ahead logging (WAL) i checkpointy.
Uważaj na ustawienia:
Kopie zapasowe i replikacja pomagają w odzyskiwaniu/dostępności, ale to nie to samo co gwarancja durability.