Dlaczego doświadczenie deweloperskie ma znaczenie, gdy baza kodu rośnie
Baza kodu rzadko zwalnia dlatego, że inżynierowie nagle zapomnieli programować. Zwalnia, bo rośnie koszt dowiedzenia się: zrozumienia nieznanych modułów, wprowadzenia bezpiecznej zmiany i udowodnienia, że nic nie zostało zepsute.
W miarę rozwoju projektu „po prostu wyszukaj i edytuj” przestaje działać. Płacisz za każdy brakujący wskazówkę: niejasne API, niespójne wzorce, słabe autouzupełnianie, wolne kompilacje i mało pomocne błędy. Wynik to nie tylko wolniejsze dostarczanie — to ostrożniejsze dostarczanie. Zespoły unikają refaktoryzacji, odkładają porządki i dostarczają mniejsze, bezpieczniejsze zmiany, które nie przesuwają produktu do przodu.
Dlaczego Anders Hejlsberg ma tu znaczenie
Anders Hejlsberg to kluczowa postać stojąca za C# i TypeScript — dwoma językami, które traktują doświadczenie deweloperskie (DX) jako funkcję pierwszorzędną. To ważne, bo język to nie tylko składnia i zachowanie w czasie wykonywania; to także ekosystem narzędzi: edytory, narzędzia do refaktoryzacji, nawigacja i jakość informacji zwrotnej podczas pisania kodu.
Ten artykuł patrzy na TypeScript i C# przez praktyczną soczewkę: jakie wybory projektowe pomagają zespołom poruszać się szybciej w miarę rozrostu systemów i zespołów.
Co naprawdę znaczy „skalowanie”
Gdy mówimy, że baza kodu się „skalowała”, zwykle mamy na myśli kilka równoległych presji:
- Wielkość zespołu: więcej współautorów, więcej stylów, większa potrzeba koordynacji.
- Rozmiar kodu: więcej modułów, więcej zależności, więcej „nieznanych” obszarów.
- Tempo zmian: częstsze wydania i równoległe strumienie prac.
Silne narzędzia zmniejszają podatek tworzony przez te presje. Pomagają inżynierom szybko odpowiedzieć na typowe pytania: „Gdzie to jest używane?”, „Czego oczekuje ta funkcja?”, „Co się zmieni, jeśli zmienię nazwę?” i „Czy to bezpieczne do opublikowania?” To właśnie doświadczenie deweloperskie — i często różnica między dużą bazą kodu, która ewoluuje, a taką, która skamieniała.
Wpływ Andersa Hejlsberga: praktyczna perspektywa
Wpływ Hejlsberga najlepiej widać nie jako zbiór cytatów czy kamieni milowych, lecz jako spójną filozofię produktową, która przejawia się w głównych narzędziach deweloperskich: przyspieszać codzienne zadania, sprawiać, że błędy są widoczne wcześnie i uczynić zmiany na dużą skalę bezpieczniejszymi.
Ta część nie jest biografią. To praktyczna perspektywa do zrozumienia, jak projekt języka i otaczający go ekosystem narzędzi mogą kształtować codzienną kulturę inżynieryjną. Gdy zespoły mówią o „dobrym DX”, często mają na myśli rzeczy celowo zaprojektowane w systemach jak C# i TypeScript: przewidywalne autouzupełnianie, rozsądne domyślne ustawienia, refaktoryzacje, którym można zaufać, oraz błędy, które wskazują rozwiązanie zamiast jedynie odrzucać kod.
Jak „wpływ” wygląda w kulturze narzędziowej
Wpływ obserwuje się w oczekiwaniach, jakie deweloperzy przynoszą do języków i edytorów:
- Edytory powinny rozumieć kod, nie tylko go kolorować.
- Nawigacja, zmiana nazwy i "znajdź odniesienia" powinny działać w całym repozytorium.
- Typy (tam, gdzie występują) powinny poprawiać produktywność, a nie ją hamować.
- Narzędzia powinny być na tyle szybkie, by używać ich ciągle, nie tylko przed wydaniem.
Efekty te dają się zmierzyć w praktyce: mniej błędów wykonywania, pewniejsze refaktoryzacje i krótszy czas potrzebny, by „odzyskać orientację” w kodzie przy dołączaniu do zespołu.
Dlaczego porównanie C# i TypeScript ma sens
C# i TypeScript działają w różnych środowiskach i służą różnym odbiorcom: C# bywa używany na serwerze i w aplikacjach korporacyjnych, podczas gdy TypeScript celuje w ekosystem JavaScript. Mimo to łączy je podobny cel DX: pomagać deweloperom poruszać się szybko, zmniejszając koszt zmian.
Porównanie ich jest przydatne, bo oddziela zasady od platformy. Gdy podobne pomysły sprawdzają się w dwóch bardzo różnych środowiskach uruchomieniowych — statyczny język na zarządzanym runtime (C#) i warstwa typów nad JavaScript (TypeScript) — oznacza to, że zwycięstwo nie jest przypadkowe. To wynik świadomych decyzji projektowych faworyzujących sprzężenie zwrotne, jasność i utrzymywalność w skali.
Typy statyczne jako mechanizm skalowania (nie tylko preferencja)
Typowanie statyczne często bywa przedstawiane jako kwestia gustu: „lubię typy” kontra „wolę elastyczność”. W dużych bazach kodu chodzi mniej o preferencję, a bardziej o ekonomię. Typy utrzymują codzienną pracę przewidywalną, gdy więcej osób dotyka więcej plików częściej.
Co daje silne typowanie na co dzień
Silny system typów nadaje nazwy i kształty obietnicom programu: czego funkcja oczekuje, co zwraca i jakie stany są dozwolone. To zamienia wiedzę implicytną (w czyjejś głowie lub w dokumentacji) w coś, co kompilator i narzędzia mogą egzekwować.
W praktyce oznacza to mniej rozmów „Czekaj, czy to może być null?”, wyraźniejsze autouzupełnianie, bezpieczniejszą nawigację po nieznanych modułach i szybsze przeglądy kodu, bo intencja jest zakodowana w API.
Sprawdzenia w czasie kompilacji kontra błędy w czasie wykonywania
Sprawdzenia w czasie kompilacji zawodzą wcześnie, często zanim kod zostanie zmergowany. Jeśli przekażesz argument o złym typie, zapomnisz wymaganego pola albo źle użyjesz wartości zwracanej, kompilator od razu to wychwyci.
Błędy w czasie wykonywania pojawiają się później — może w QA, może w produkcji — gdy konkretny przebieg kodu wykona się na rzeczywistych danych. Takie błędy są zwykle droższe: trudniejsze do odtworzenia, przerywają użytkownikom działanie i generują pracę reaktywną.
Typy statyczne nie eliminują wszystkich błędów czasu wykonywania, ale usuwają dużą klasę błędów „to nie powinno się skompilować”.
Błędy skalowania, które typy pomagają zapobiegać
W miarę wzrostu zespołów typowe punkty awarii to:
- Niejasne kontrakty: moduły nie mówią, co gwarantują, więc użycie dryfuje.
- Niebezpieczne refaktoryzacje: zmiany nazw i sygnatur pomijają miejsca wywołań.
- Ukryte sprzężenia: niezwiązane części zależą od tej samej luźno zdefiniowanej struktury.
Typy działają jak wspólna mapa. Gdy zmieniasz kontrakt, otrzymujesz konkretną listę miejsc wymagających aktualizacji.
Kompromisy (realne, ale możliwe do opanowania)
Typowanie ma koszty: krzywą uczenia się, dodatkowe adnotacje (zwłaszcza na granicach) i sporadyczne tarcia, gdy system typów nie potrafi ładnie wyrazić tego, co chcesz. Kluczowe jest strategiczne użycie typów — najintensywniej tam, gdzie są publiczne API i struktury współdzielone — aby uzyskać korzyści skalowania bez zamieniania rozwoju w biurokrację.
Pętla informacji zwrotnej to mały cykl, który powtarzasz cały dzień: edytuj → sprawdź → napraw. Zmieniasz linię, narzędzia natychmiast to weryfikują i poprawiasz, zanim utracisz kontekst.
Wolne sprzężenie: kiedy błędy podróżują daleko
W wolnej pętli „sprawdź” oznacza głównie uruchomienie aplikacji i poleganie na testach ręcznych (albo czekanie na CI). To opóźnienie zamienia drobne błędy w poszukiwania:
- Wysyłasz kod.
- Testy zawodzą później (albo, co gorsza, użytkownicy to zgłaszają).
- Ktoś musi odtworzyć intencję, odtworzyć problem i szybko załatać.
Im większa przerwa między edycją a odkryciem, tym droższa każda naprawa.
Szybkie sprzężenie: edytor + kompilator jako współpracownik
Nowoczesne języki i ich narzędzia skracają pętlę do sekund. W TypeScript i C# edytor może oznaczać problemy podczas pisania, często z proponowaną poprawką.
Konkretnie, przykłady wykrywane wcześnie:
- Brakujące pole: odwołujesz się do
user.address.zip, ale address nie jest gwarantowane.
- Zły typ parametru: przekazujesz string, gdzie oczekiwane jest liczba (lub określone enum).
- Kod nieosiągalny:
return sprawia, że reszta funkcji nigdy się nie wykona.
To nie są „pułapki” — to typowe potknięcia, które szybkie narzędzia zamieniają w błyskawiczne poprawki.
Dlaczego to ważniejsze w zespołach
Szybkie sprzężenie zmniejsza koszty koordynacji. Gdy kompilator i usługa językowa wykrywają niezgodności natychmiast, mniej problemów przedostaje się do przeglądu kodu, QA czy pracy innych zespołów. To oznacza mniej pytań „co tu miałeś na myśli?”, mniej złamanych buildów i mniej niespodzianek typu „ktoś zmienił typ i moja funkcja eksplodowała”.
W skali szybkość to nie tylko wydajność runtime — to jak szybko deweloper może być pewny, że jego zmiana jest poprawna.
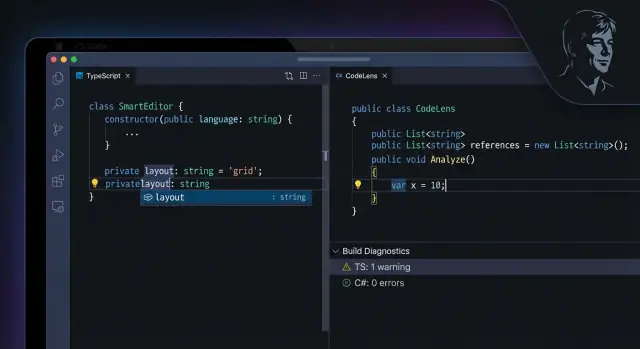
Narzędzia, które czują się natywne: usługi językowe i integracja IDE
„Usługi językowe” to prosta nazwa na zestaw funkcji edytora, które czynią kod łatwym do przeszukiwania i bezpiecznym do zmiany. Pomyśl o autouzupełnianiu rozumiejącym projekt, „przejdź do definicji” skaczącym do właściwego pliku, zmianie nazwy aktualizującej wszystkie użycia i diagnostykach podkreślających problemy zanim cokolwiek uruchomisz.
TypeScript: kompilator jako asystent zawsze włączony
Doświadczenie edytora w TypeScript działa, ponieważ kompilator TypeScript to nie tylko narzędzie do produkcji JavaScript — napędza też TypeScript Language Service, silnik stojący za większością funkcji IDE.
Gdy otwierasz projekt TS w VS Code (lub innym edytorze obsługującym ten protokół), usługa językowa czyta tsconfig, śledzi importy, buduje model programu i ciągle odpowiada na pytania typu:
- Jaki typ ma teraz ta wartość?
- Które przeciążenie jest wywoływane?
- Gdzie ten symbol jest zdefiniowany w całym workspace?
Dlatego TypeScript może oferować dokładne autouzupełnianie, bezpieczne zmiany nazw, przejścia do definicji, „znajdź wszystkie odniesienia”, szybkie poprawki i błędy inline podczas pisania. W dużych repozytoriach z dużą ilością JavaScriptu to ciasne sprzężenie jest przewagą skalowania: inżynierowie mogą edytować nieznane moduły i od razu otrzymać wskazówki, co może się zepsuć.
C#: kompilator + IDE działające jako jedna jednostka
C# bazuje na podobnej zasadzie, z wyjątkowo głęboką integracją IDE w popularnych przepływach pracy (szczególnie Visual Studio, a także VS Code przez language server). Platforma kompilatora wspiera bogatą analizę semantyczną, a warstwa IDE dodaje refaktoryzacje, akcje kodu, nawigację w całym projekcie i feedback na etapie budowy.
To ma znaczenie, gdy zespoły rosną: spędzasz mniej czasu „mentalnie kompilując” kod. Narzędzia mogą potwierdzić intencję — pokazać rzeczywisty symbol, który wywołujesz, oczekiwaną nullowalność, dotknięte miejsca wywołań i czy zmiana rozlewa się na inne projekty.
Dlaczego to skaluje poza wygodą
W małym projekcie narzędzia są miłe do posiadania. W dużym — to sposób, w jaki zespoły poruszają się bez strachu. Silne usługi językowe ułatwiają eksplorację nieznanego kodu, bezpieczniejsze zmiany i łatwiejsze przeglądy — bo te same fakty (typy, odniesienia, błędy) są widoczne dla wszystkich, nie tylko dla autora modułu.
Wsparcie refaktoryzacji: czynienie zmian tanimi i niezawodnymi
Udostępniaj pracę bez dodatkowego setupu
Udostępnij projekt bez dodatkowej konfiguracji, gdy będziesz gotowy.
Refaktoryzacja to nie jednorazowe „wiosenne porządki”. W dużych bazach kodu to codzienna praca: ciągłe przekształcanie kodu, by nowe funkcje nie stawały się miesiąc po miesiącu wolniejsze i bardziej ryzykowne.
Gdy język i narzędzia czynią refaktoryzację bezpieczną, zespoły mogą utrzymywać moduły małe, nazwy trafne i granice czytelne — bez planowania ryzykownych, wielotygodniowych przebudów.
Refaktoryzacje, których potrzebujesz na co dzień
Wsparcie IDE w TypeScript i C# skupia się zwykle na kilku silnie efektywnych ruchach:
- Bezpieczna zmiana nazwy dla zmiennych, metod, klas, plików i modułów
- Wyodrębnij metodę/funkcję by przekształcić długie bloki w czytelne, testowalne jednostki
- Przenieś symbol (np. klasę do innego pliku/przestrzeni nazw/modułu) przy automatycznym naprawianiu importów/usings
- Porządkuj importy/usings by zmniejszyć szum i uniknąć subtelnych konfliktów
To drobne operacje, ale w skali — różnica między „możemy to zmienić” a „nikt nie dotyka tego pliku”.
Dlaczego refaktoryzacja potrzebuje zrozumienia semantycznego (a nie wyszukiwania tekstu)
Wyszukiwanie tekstowe nie potrafi powiedzieć, czy dwa takie same słowa odnoszą się do tego samego symbolu. Prawdziwe narzędzia refaktoryzacyjne korzystają z modelu kompilatora — typów, zakresów, przeciążeń, rozwiązywania modułów — aby aktualizować znaczenie, nie tylko znaki.
To ten semantyczny model pozwala zmienić nazwę interfejsu bez dotykania literałów tekstowych albo przenieść metodę i automatycznie poprawić wszystkie importy i odniesienia.
Błędy, których dobre narzędzia pomagają unikać
Bez semantycznej refaktoryzacji zespoły rutynowo wypuszczają do produkcji łatwe do uniknięcia awarie:
- Połamane odniesienia po zmianach nazw lub przenosinach
- Pominięte miejsca wywołań ze względu na wzorce dynamiczne, przeciążenia lub zasłonięte nazwy
- Przypadkowe edycje komentarzy/łańcuchów zamiast kodu
- Półzaktualizowane API, gdzie niektóre pliki się kompilują, a inne cicho się rozjeżdżają
To moment, kiedy doświadczenie deweloperskie bezpośrednio przekłada się na przepustowość inżynieryjną: bezpieczniejsze zmiany oznaczają więcej zmian, wcześniej — i mniej strachu wpisanego w bazę kodu.
Podejście TypeScript: stopniowe bezpieczeństwo dla świata JavaScript
TypeScript odniósł sukces głównie dlatego, że nie wymaga „zacząć od nowa”. Akceptuje, że większość realnych projektów zaczyna jako JavaScript — nieuporządkowany, szybki i już działający — i pozwala na nakładanie bezpieczeństwa bez blokowania tempa.
Typowanie strukturalne, inferencja i typowanie stopniowe (prosto)
TypeScript używa typowania strukturalnego, co znaczy, że zgodność opiera się na kształcie wartości (jej polach i metodach), a nie na nazwie deklarowanego typu. Jeśli obiekt ma { id: number }, zwykle można go użyć tam, gdzie oczekiwany jest ten kształt — nawet gdy pochodzi z innego modułu lub nie był jawnie zadeklarowany.
Silnie polega też na inferencji typów. Często masz sensowne typy bez pisania ich:
const user = { id: 1, name: "Ava" };
Wreszcie, TypeScript jest stopniowy: możesz mieszać kod typowany i nietypowany. Możesz adnotować najważniejsze granice najpierw (odpowiedzi API, narzędzia współdzielone, moduły domenowe), a resztę zostawić na później.
„Dodawanie typów w miarę pracy” czyni adopcję realistyczną
Ta inkrementalna ścieżka jest powodem, dla którego TypeScript pasuje do istniejących kodów JavaScript. Zespoły mogą migrować plik po pliku, akceptować trochę any na początku i mimo to uzyskać natychmiastowe korzyści: lepsze autouzupełnianie, bezpieczniejsze refaktoryzacje i jaśniejsze kontrakty funkcji.
Surowość to pokrętło, które zespoły mogą zwiększać z czasem
Większość organizacji zaczyna od umiarkowanych ustawień, a następnie stopniowo zaostrza reguły, włączając opcje jak strict, zaostrzając noImplicitAny czy poprawiając pokrycie strictNullChecks. Klucz to postęp bez paraliżu.
Krótkie ostrzeżenie: typy wyrażają intencję, nie prawdę
Typy modelują to, co oczekujesz, że się stanie; nie dowodzą zachowania w czasie wykonywania. Nadal potrzebujesz testów — szczególnie dla reguł biznesowych, integracyjnych i wszystkiego, co dotyczy I/O lub danych z zewnątrz.
Podejście C#: funkcje produktywności skalujące zespoły
Spraw, by postęp się opłacał
Zdobądź kredyty za tworzenie treści o Koder.ai lub polecanie innych twórców.
C# rozwijał się wokół prostego pomysłu: spraw, by „normalny” sposób pisania kodu był też najbezpieczniejszy i najbardziej czytelny. To ma znaczenie, gdy baza kodu przestaje być czymś, co jedna osoba może ogarnąć, a staje się współdzielonym systemem utrzymywanym przez wielu.
Czytelność i intencja jako domyślne
Nowoczesny C# stawia na składnię, która czyta się jak zamiary biznesowe, a nie mechanika. Małe cechy składają się na całość: czytelniejsze inicjalizacje obiektów, dopasowywanie wzorców (pattern matching) do obsługi określonych kształtów danych oraz wyrażenia switch redukujące zagnieżdżone if.
Gdy dziesiątki deweloperów dotykają tych samych plików, takie udogodnienia redukują potrzebę posiadania wiedzy plemiennej. Przeglądy kodu stają się mniej odszyfrowywania, a bardziej weryfikowania zachowania.
Bezpieczeństwo dopasowane do realnego kodu
Jedną z najbardziej praktycznych cech skalujących jest nullowalność. Zamiast traktować null jako ciągłe zaskoczenie, C# pozwala zespołom wyrażać intencję:
- „Ta wartość nigdy nie może być null” (konsumenci mogą na tym polegać)
- „To może być null” (wywołujący są zachęcani do obsługi)
To przesuwa wiele defektów z produkcji do czasu kompilacji i jest pomocne w dużych zespołach, gdzie API używają osoby, które ich nie pisały.
Ergonomia async/await: współbieżność skalowana dla ludzi
Wraz ze wzrostem systemów rośnie liczba wywołań sieciowych, operacji I/O i pracy w tle. async/await w C# sprawia, że kod asynchroniczny czyta się jak synchroniczny, co zmniejsza obciążenie poznawcze przy obsłudze współbieżności.
Zamiast przepychać callbacki w kodzie, zespoły mogą pisać przejrzyste przepływy — pobierz dane, waliduj, kontynuuj — podczas gdy runtime zarządza oczekiwaniem. Efekt: mniej błędów związanych z czasem i mniej niestandardowych konwencji, które nowi członkowie muszą poznawać.
Narzędzia, które pozostają użyteczne w dużych rozwiązaniach
Historia produktywności C# jest nierozerwalna z usługami językowymi i integracją IDE. W dużych rozwiązaniach mocne narzędzia zmieniają to, co jest wykonalne na co dzień:
- Szybka nawigacja między projektami (go to definition, find references)
- Analiza na poziomie rozwiązania, która wcześniej wychwytuje zmiany łamiące kompilację
- Bezpieczne, zautomatyzowane refaktoryzacje (rename, extract method, change signature)
To sprawia, że zespoły utrzymują impet. Gdy IDE może wiarygodnie odpowiedzieć "gdzie to jest używane?" i "co złamie ta zmiana?", deweloperzy wprowadzają ulepszenia proaktywnie, zamiast ich unikać.
Spójne „dno sukcesu”
Utrwalony wzorzec to konsystencja: powszechne zadania (obsługa null, async, refaktoryzacje) są wspierane zarówno przez język, jak i narzędzia. Takie połączenie zamienia dobre praktyki inżynieryjne w najprostszy sposób postępowania — dokładnie to, czego potrzebujesz przy skalowaniu bazy kodu i zespołu.
Diagnostyka i komunikaty o błędach, które uczą (a nie tylko blokują)
W małym projekcie nieostry komunikat o błędzie może wystarczyć. W skali diagnostyka staje się częścią systemu komunikacji zespołu. TypeScript i C# mają bias Hejlsberga ku komunikatom, które nie tylko zatrzymują — pokazują, jak pójść dalej.
Jak wyglądają „dobre” komunikaty błędów
Pomocne diagnostyki mają zwykle trzy cechy:
- Działające: sugerują następny krok ("Czy miałeś na myśli…", "Dodaj sprawdzenie null", "Konwertuj na async").
- Sprecyzowane: nazywają konkretny symbol, oczekiwany typ lub brakujący element, zamiast opisywać kategorię błędu.
- Lokalne: wskazują najmniejszy fragment kodu odpowiedzialny, aby można było naprawić to bez grzebania w niepowiązanych plikach.
To ważne, bo błędy czyta się często pod presją. Komunikat, który uczy, redukuje korespondencję i zamienia "zablokowany" czas w "czas nauki".
Ostrzeżenia kontra błędy: dlaczego ostrzeżenia chronią przyszłego ciebie
Błędy wymuszają poprawność teraz. Ostrzeżenia chronią długoterminowe zdrowie kodu: przestarzałe API, kod nieosiągalny, wątpliwe użycie null, implicit any i inne „działa dziś, może złamać się później” problemy.
Zespoły mogą traktować ostrzeżenia jako stopniowe zaostrzanie: zaczynaj przyjaźnie, potem zaostrzaj politykę i pilnuj, by liczba ostrzeżeń nie rosła.
Diagnostyka jako standardy zespołu — i paliwo onboardingowe
Spójne diagnostyki tworzą spójny kod. Zamiast polegać na wiedzy plemiennej ("tutaj tego nie robimy"), narzędzia wyjaśniają regułę w momencie, gdy ma to znaczenie.
To przewaga skalowania: nowi członkowie mogą naprawiać problemy, których nigdy wcześniej nie widzieli, ponieważ kompilator i IDE w praktyce dokumentują intencję — prosto na liście błędów.
Wydajność i przyrostowość: utrzymanie szybkości narzędzi w skali
Gdy baza kodu rośnie, wolne sprzężenie zwrotne staje się codziennym podatkiem. Rzadko pojawia się jako jeden „duży” problem; to śmierć przez tysiąc czeków: dłuższe buildy, wolniejsze testy i CI, które zamienia szybkie sprawdzenie w godzinne przerywanie kontekstu.
Ból skalowania, który można poczuć
Pojawiają się typowe symptomy:
- Czas kompilacji rośnie wraz z liczbą projektów, generowanego kodu i zależności.
- Czasy testów rosną, zwłaszcza gdy "uruchom wszystko" staje się domyślną praktyką.
- Opóźnienia CI powodują stos PR-ów, więcej konfliktów merge i przeglądów opartych na domysłach zamiast weryfikacji.
- Opóźnienie w edytorze (autouzupełnianie, przejdź do definicji, zmiana nazwy) sprawia, że deweloperzy omijają narzędzia zamiast z nich korzystać.
Dlaczego przyrostowość zmienia doświadczenie
Nowoczesne toolchainy językowe coraz częściej traktują "przepal wszystko" jako ostateczność. Kluczowa idea jest prosta: większość edycji dotyczy niewielkiego wycinka programu, więc narzędzia powinny ponownie wykorzystywać wcześniejszą pracę.
Kompilacja przyrostowa i cache zwykle opierają się na:
- Śledzeniu zależności: wiedzy, które pliki/moduły zależą od czego.
- Stabilnych wynikach pośrednich: przechowywaniu parsowanych drzew składni, informacji o typach lub skompilowanych artefaktów do ponownego użycia.
- Inteligentnym unieważnianiu: przeliczaniu tylko tego, co się zmieniło — i tego, co musi się zmienić z tego powodu.
To nie tylko szybsze buildy. To to, co pozwala usługom językowym pozostać responsywnymi podczas pisania, nawet w dużych repozytoriach.
Responsywność edytora jako wskaźnik jakości
Traktuj responsywność IDE jako metrykę produktu, nie miły dodatek. Jeśli rename, find references i diagnostyki trwają sekundy, ludzie przestają im ufać — i przestają refaktoryzować.
Praktyczne sposoby na utrzymanie szybkiego sprzężenia
Ustal jasne budżety (np. lokalny build poniżej X minut, kluczowe akcje edytora poniżej Y ms, CI poniżej Z minut). Mierz je ciągle.
Następnie działaj na podstawie liczb: podziel krytyczne ścieżki w CI, uruchamiaj najmniejszy zestaw testów potrzebny do weryfikacji zmiany i inwestuj w cache oraz przyrostowe przepływy pracy tam, gdzie się da. Cel jest prosty: spraw, by najszybsza ścieżka była domyślną ścieżką.
Projektowanie na zmianę: API, granice i utrzymywalność
Skróć drogę do produkcji
Wdrażaj i hostuj aplikację w trakcie iteracji, aby sprzężenie zwrotne było blisko zmiany.
Duże bazy kodu rzadko upadają przez jedną złą funkcję — zawodzą, gdy granice rozmywają się z czasem. Najłatwiejszy sposób utrzymania bezpieczeństwa zmian to traktować API (nawet wewnętrzne) jak produkt: małe, stabilne i celowe.
Jasne kontrakty (i dlaczego typy pomagają)
W TypeScript i C# typy zamieniają „jak to wywołać” w jawny kontrakt. Gdy biblioteka współdzielona eksponuje dobrze dobrane typy — wąskie wejścia, klarowne kształty zwracane, znaczące enumy — zmniejszasz liczbę "reguł ukrytych", które istnieją tylko w cudzej głowie.
Dla API wewnętrznych to ma jeszcze większe znaczenie: zespoły się przemieszczają, własność zmienia się, a biblioteka staje się zależnością, której nie da się „szybko przeczytać”. Silne typy utrudniają nadużycia i czynią refaktoryzacje bezpieczniejszymi, bo wywołania łamią się na etapie kompilacji zamiast w produkcji.
Kontrolowanie powierzchni przez granice
System utrzymywalny zwykle jest warstwowy:
- Publiczna powierzchnia vs. internals: eksportuj tylko to, co zamierzasz wspierać; trzymaj pomocnicze rzeczy prywatnie.
- Moduły/przestrzenie nazw: grupuj powiązane możliwości, by ułatwić odkrywanie i zmniejszyć przypadkowe sprzężenia.
- Kierunek zależności: kod wyższego poziomu zależy od prymitywów niższego poziomu, nie odwrotnie.
Chodzi mniej o "czystość architektury", a bardziej o to, by było oczywiste, gdzie powinny następować zmiany.
Wersjonowanie, deprecjacje i nawyki zespołu
API ewoluują. Zaplanuj to:
- Wprowadzaj nowe punkty wejścia obok starych, oznaczając stare jako przestarzałe i ustalając datę usunięcia.
- Prowadź lekkie changelogi dla współdzielonych pakietów, by aktualizacje nie stawały się archeologią.
Wspieraj te nawyki automatyzacją: reguły lintujące blokujące importy wewnętrzne, checklisty code review dla zmian API i sprawdzenia CI wymuszające semver oraz zapobiegające przypadkowym eksportom publicznym. Gdy reguły są wykonalne, utrzymywalność przestaje być cnotą jednostki, a staje się gwarancją zespołu.
Praktyczne wskazówki dla skalowania dużych baz kodu
Duże bazy kodu nie upadają dlatego, że zespół „wybrał zły język”. Upadają, bo zmiana staje się ryzykowna i powolna. Praktyczny wzorzec stojący za TypeScript i C# jest prosty: typy + narzędzia + szybkie sprzężenia czynią codzienne zmiany bezpieczniejszymi.
Główne przesłanie
Typy statyczne są najbardziej wartościowe, gdy idą w parze z rozbudowanymi usługami językowymi (autouzupełnianie, nawigacja, szybkie poprawki) oraz ciasnymi pętlami informacji zwrotnej (błyskawiczne błędy, kompilacja przyrostowa). To połączenie zamienia refaktoryzację z wydarzenia stresującego w rutynową czynność.
Gdzie Koder.ai pasuje do tej historii DX
Nie każda korzyść ze skalowania pochodzi wyłącznie z języka — workflow też ma znaczenie. Platformy takie jak Koder.ai dążą do skrócenia pętli edytuj → sprawdź → napraw jeszcze bardziej, pozwalając zespołom budować aplikacje webowe, backendowe i mobilne za pomocą workflow opartego na czacie (React w webie, Go + PostgreSQL na backendzie, Flutter na mobile), zachowując jednocześnie wynik jako rzeczywisty, eksportowalny kod źródłowy.
W praktyce funkcje takie jak tryb planowania (by wyjaśnić intencję przed zmianami), migawki i rollback (by uczynić refaktoryzacje bezpieczniejszymi) oraz wbudowane wdrażanie/hosting z custom domains bezpośrednio wpisują się w temat tego artykułu: zmniejszać koszt zmiany i utrzymywać ciasne sprzężenie zwrotne w miarę rozrostu systemów.
Prosty plan adopcji (działający w realnym świecie)
-
Zacznij od zwycięstw narzędziowych. Ustandaryzuj konfigurację IDE, włącz spójne formatowanie, dodaj linting i spraw, by "go to definition" i zmiana nazwy działały niezawodnie w całym repozytorium.
-
Dodawaj bezpieczeństwo stopniowo. Włącz sprawdzanie typów tam, gdzie najbardziej to boli (moduły współdzielone, API, kod o dużej dynamice). Stopniowo przechodź do ostrzejszych ustawień zamiast próbować "przełączyć wszystko" w tydzień.
-
Refaktoruj z zabezpieczeniami. Gdy typy i narzędzia są zaufane, inwestuj w większe refaktoryzacje: wyodrębnianie modułów, wyjaśnianie granic, usuwanie martwego kodu. Niech kompilator i IDE wykonają ciężką pracę.
Znaki, że dobrze skalujesz
- Zmiany są przewidywalne: potrafisz oszacować wysiłek bez heroicznego debugowania.
- Regresje spadają, bo błędy łamiące wykrywane są wcześnie.
- Refaktoryzacje są pewne: rename/move/extract są nudne, a nie przerażające.
- Nowi członkowie zespołu szybciej stają się produktywni, bo baza kodu „tłumaczy się sama” poprzez typy i narzędzia.
Praktyczne następne kroki
Wybierz jedną nadchodzącą funkcję i potraktuj ją jako pilota: zaostrz typy w dotykanym obszarze, wymagaj zielonego buildu w CI i mierz lead time oraz wskaźnik błędów przed i po.
Jeśli chcesz więcej pomysłów, przejrzyj powiązane posty inżynieryjne w tekście "/blog".