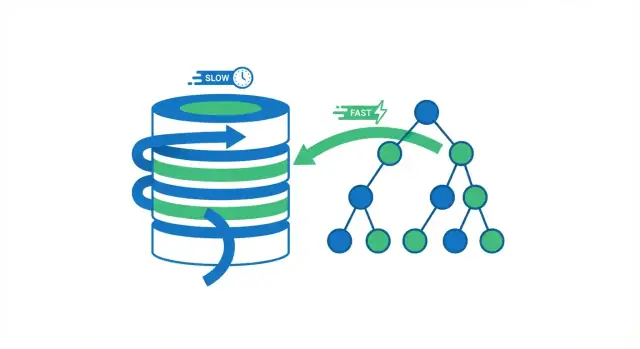
Co naprawdę robi indeks bazy danych
Indeks bazy danych to oddzielna struktura wyszukiwania, która pomaga bazie szybciej znaleźć wiersze. To nie jest druga kopia tabeli. Wyobraź sobie strony indeksu w książce: używasz indeksu, by przeskoczyć blisko właściwego miejsca, a potem czytasz konkretną stronę (wiersz), której potrzebujesz.
Bez indeksu baza zwykle ma tylko jedną bezpieczną opcję: przeglądać wiele wierszy, by sprawdzić, które pasują do zapytania. To może być w porządku, gdy tabela ma kilka tysięcy rekordów. Gdy tabela rośnie do milionów wierszy, „sprawdzanie większej liczby wierszy” oznacza więcej odczytów z dysku, większe obciążenie pamięci i CPU — więc to samo zapytanie, które kiedyś było natychmiastowe, zaczyna się ciągnąć.
Co zmienia indeks (a co nie)
Indeksy zmniejszają ilość danych, które baza musi sprawdzić, żeby odpowiedzieć na pytania typu „znajdź zamówienie o ID 123” lub „pobierz użytkowników z tym emailem”. Zamiast skanować wszystkiego, baza najpierw sięga do zwartej struktury, która szybko zawęża pole poszukiwań.
Ale indeksowanie to nie jest uniwersalny lek. Niektóre zapytania nadal muszą przetworzyć dużo wierszy (szerokie raporty, filtry o niskiej selektywności, ciężkie agregacje). Indeksy mają też realne koszty: dodatkową przestrzeń dyskową i wolniejsze zapisy, bo insert i update muszą też modyfikować indeks.
Czego nauczysz się z tego przewodnika
Zobaczysz:
- dlaczego unikanie pełnych skanów tabel to największy zysk prędkości
- jak powszechne struktury indeksów (np. B-tree) przyspieszają wyszukiwanie
- które zapytania zyskują najwięcej, a kiedy indeksy nie pomagają
- jak wybierać indeksy złożone/pokrywające i weryfikować je za pomocą planu EXPLAIN
- jak utrzymywać indeksy z czasem, żeby wydajność nie pogarszała się po cichu
Główny zysk prędkości: unikanie pełnych skanów tabel
Gdy baza wykonuje zapytanie, ma dwie szerokie opcje: przeskanować całą tabelę wiersz po wierszu albo od razu przeskoczyć do pasujących wierszy. Większość wygranych z indeksów polega na unikaniu niepotrzebnych odczytów.
Pełny skan tabeli vs. wyszukiwanie po indeksie
Pełny skan tabeli (full table scan) to dokładnie to, co nazwa sugeruje: baza odczytuje każdy wiersz, sprawdza, czy pasuje do warunku WHERE, i dopiero potem zwraca wyniki. To jest akceptowalne dla małych tabel, ale wraz ze wzrostem tabeli robi się wolniejsze w przewidywalny sposób — więcej wierszy to więcej pracy.
Dzięki indeksowi baza często może uniknąć odczytywania większości wierszy. Najpierw sprawdza indeks (zwarta struktura zaprojektowana do wyszukiwania), by znaleźć, gdzie znajdują się pasujące wiersze, a potem odczytuje tylko te konkretne wiersze.
Prosty przykład z analogią
Pomyśl o książce. Jeśli chcesz znaleźć każde miejsce, gdzie wspomniano „fotosynteza”, możesz przeczytać całą książkę od początku do końca (pełny skan). Albo możesz użyć indeksu, przeskoczyć do wymienionych stron i czytać tylko te fragmenty (wyszukiwanie po indeksie). Drugi sposób jest szybszy, bo omijasz prawie wszystkie strony.
Dlaczego mniej odczytów zwykle oznacza szybsze zapytania
Bazy spędzają dużo czasu czekając na odczyty — zwłaszcza gdy dane nie mieszczą się w pamięci. Zmniejszenie liczby wierszy (i stron), które trzeba dotknąć, zwykle redukuje:
- odczyty z dysku/SSD
- czas CPU potrzebny na ocenę filtrów
- obciążenie pamięci przez zbędne dane w cache
Kiedy zysk z prędkości jest widoczny
Indeksowanie pomaga najbardziej, gdy danych jest dużo, a wzorzec zapytań jest selektywny (np. pobieranie 20 pasujących wierszy z 10 milionów). Jeśli zapytanie i tak zwraca większość wierszy, albo tabela jest na tyle mała, że zmieści się w pamięci, pełny skan może być równie szybki — a czasem nawet szybszy.
Jak struktury indeksów przyspieszają wyszukiwanie
Indeksy działają, bo organizują wartości tak, że baza może przeskoczyć blisko tego, czego szukasz, zamiast sprawdzać każdy wiersz.
Indeksy B-tree: podstawowy roboczy koń
Najpopularniejszą strukturą indeksu w bazach SQL jest B-tree (często zapisywane jako „B-tree” lub „B+tree”). Koncepcyjnie:
- wartości są posortowane
- indeks dzieli się na strony (kawałki), które wskazują na inne strony, aż do pasujących wierszy tabeli
Ponieważ jest posortowany, B-tree świetnie nadaje się zarówno do wyszukiwań po równości (WHERE email = ...) jak i zapytania zakresowych (WHERE created_at >= ... AND created_at < ...). Baza może przejść do właściwej okolicy wartości, a potem skanować kolejne pozycje w porządku.
Co znaczy „logarytmicznie” (bez matematyki)
Mówi się, że wyszukiwanie w B-tree jest „logarytmiczne”. W praktyce oznacza to: gdy tabela rośnie z tysięcy do milionów wierszy, liczba kroków potrzebnych do znalezienia wartości rośnie wolno, a nie proporcjonalnie.
Zamiast „dwa razy więcej danych = dwa razy więcej pracy”, to raczej „dużo więcej danych = tylko kilka dodatkowych kroków nawigacji”, bo baza podąża wskaźnikami przez niewielką liczbę poziomów drzewa.
Indeksy haszujące: szybkie dla dokładnych dopasowań (z ograniczeniami)
Niektóre silniki oferują również indeksy haszujące. Mogą być bardzo szybkie przy dokładnych porównaniach, bo wartość zamienia się w hash i używa do bezpośredniego odnalezienia wpisu.
Cena: indeksy haszujące zwykle nie pomagają przy zakresach ani skanach uporządkowanych, a dostępność i zachowanie różnią się w zależności od bazy.
Szczegóły silnika różnią się, idea pozostaje ta sama
PostgreSQL, MySQL/InnoDB, SQL Server i inne przechowują i używają indeksów nieco inaczej (rozmiary stron, klastrowanie, kolumny dołączone, widoczność). Ale główna koncepcja jest uniwersalna: indeksy tworzą zwartą, nawigowalną strukturę, która pozwala bazie znaleźć pasujące wiersze przy znacznie mniejszym nakładzie pracy niż skan całej tabeli.
Zapytania, które najbardziej zyskują na indeksach
Indeksy nie przyspieszają „SQL-a” w ogóle — przyspieszają konkretne wzorce dostępu. Gdy indeks pasuje do sposobu, w jaki zapytanie filtruje, łączy lub sortuje dane, baza może przeskoczyć prosto do istotnych wierszy zamiast czytać całą tabelę.
Najbardziej przyjazne zapytania dla indeksów
1) Filtry WHERE (szczególnie na selektywnych kolumnach)
Jeśli zapytanie często zawęża dużą tabelę do małego zbioru wierszy, indeks jest zwykle pierwszym miejscem, które warto sprawdzić. Klasyczny przykład to wyszukiwanie użytkownika po identyfikatorze.
Bez indeksu na users.email baza może być zmuszona do skanowania wszystkich wierszy:
SELECT * FROM users WHERE email = '[email protected]';
Z indeksem na email może szybko zlokalizować pasujący wiersz(y) i przestać szukać.
2) Klucze JOIN (klucze obce i klucze referencyjne)
JOINy to miejsce, gdzie „małe nieefektywności” zamieniają się w duże koszty. Jeśli łączysz orders.user_id z users.id, indeksowanie kolumn używanych w JOIN (zwykle orders.user_id oraz klucz główny users.id) pomaga bazie dopasowywać wiersze bez wielokrotnego skanowania.
3) ORDER BY (gdy chcesz już posortowane wyniki)
Sortowanie jest kosztowne, gdy baza musi zebrać dużo wierszy i posortować je po fakcie. Jeśli często uruchamiasz:
SELECT * FROM orders WHERE user_id = 42 ORDER BY created_at DESC;
indeks zgodny z user_id i kolumną sortującą może pozwolić silnikowi odczytać wiersze we właściwej kolejności zamiast sortować duży wynik pośredni.
4) GROUP BY (gdy grupowanie pokrywa się z indeksem)
Grupowanie może skorzystać, gdy baza może czytać dane w porządku grup. To nie jest gwarancja, ale jeśli często grupujesz po kolumnie używanej też do filtrowania (lub naturalnie sklastrowanej w indeksie), silnik może wykonać mniej pracy.
Filtry zakresowe: częste zwycięstwo B-tree
Indeksy B-tree są szczególnie dobre przy warunkach zakresowych — pomyśl o datach, cenach i zapytaniach typu „pomiędzy":
SELECT * FROM orders
WHERE created_at >= '2025-01-01' AND created_at < '2025-02-01';
Dla pulpitów nawigacyjnych, raportów i ekranów „ostatniej aktywności” ten wzorzec pojawia się wszędzie, a indeks na kolumnie zakresowej często daje natychmiastową poprawę.
Motyw jest prosty: indeksy pomagają najbardziej, gdy odzwierciedlają sposób, w jaki szukasz i sortujesz. Jeśli Twoje zapytania pasują do tych wzorców dostępu, baza może wykonać selektywne odczyty zamiast szerokich skanów.
Selektywność: dlaczego niektóre indeksy nie pomagają
Indeks pomaga najbardziej, gdy wyraźnie zawęża liczbę wierszy, które trzeba dotknąć. Ta właściwość to selektywność.
Co znaczy „selektywność” w praktyce
Selektywność to w zasadzie: ile wierszy pasuje do danej wartości? Kolumna o wysokiej selektywności ma wiele różnych wartości, więc każde wyszukiwanie pasuje do niewielu wierszy.
- Wysoka selektywność:
email, user_id, order_number (często unikalne lub bliskie unikalności)
- Niska selektywność:
is_active, is_deleted, status z kilkoma popularnymi wartościami
Przy wysokiej selektywności indeks może przeskoczyć do niewielkiego zbioru wierszy. Przy niskiej selektywności indeks wskazuje na dużą część tabeli — więc baza i tak musi odczytać i przefiltrować dużo.
Dlaczego indeksy na booleanach rozczarowują
Weź tabelę z 10 milionami wierszy i kolumną is_deleted, gdzie 98% ma wartość false. Indeks na is_deleted niewiele tu zyska dla:
SELECT * FROM orders WHERE is_deleted = false;
Zestaw pasujących wierszy i tak jest prawie całą tabelą. Użycie indeksu może być wolniejsze niż skan sekwencyjny, bo silnik wykonuje dodatkową pracę skacząc między wpisami indeksu a stronami tabeli.
Dlaczego baza może zignorować Twój indeks
Planner zapytań szacuje koszty. Jeśli indeks nie zredukuje wystarczająco pracy — bo za dużo wierszy pasuje lub zapytanie potrzebuje większości kolumn — może wybrać pełny skan tabeli.
Selektywność zmienia się w czasie
Rozkład danych nie jest stały. Kolumna status może zaczynać się od równomiernego rozkładu, a potem z czasem jedna wartość zacznie dominować. Jeśli statystyki nie są aktualizowane, planner może podjąć złe decyzje, a indeks, który kiedyś pomagał, przestanie się opłacać.
Indeksy złożone i pokrywające (i kolejność kolumn)
Indeksy jednopólkowe to dobry początek, ale wiele rzeczywistych zapytań filtruje po jednej kolumnie i sortuje lub filtruje po innej. Tu błyszczą indeksy złożone (multi-column): jeden indeks może obsłużyć kilka elementów zapytania.
Kolejność kolumn: zasada "od lewej do prawej"
Większość baz (szczególnie z B-tree) może efektywnie użyć indeksu złożonego tylko od lewej najbardziej kolumny w prawo. Pomyśl o indeksie jako posortowanym najpierw według kolumny A, potem w jej obrębie według kolumny B itd.
To oznacza:
- indeks (account_id, created_at) jest świetny do zapytań filtrujących po
account_id, a potem sortujących lub filtrujących po created_at
- ten sam indeks zwykle nie pomoże zapytaniom, które filtrują tylko po
created_at (bo to nie jest kolumna najbardziej po lewej)
Praktyczny wzorzec: timeline per-account
Częstym obciążeniem jest „pokaż najnowsze zdarzenia dla tego konta”. Ten wzorzec:
SELECT id, created_at, type
FROM events
WHERE account_id = ?
ORDER BY created_at DESC
LIMIT 50;
często zyskuje ogromnie dzięki:
CREATE INDEX events_account_created_at
ON events (account_id, created_at);
Baza może przejść prosto do części indeksu dla jednego konta i odczytywać wiersze w porządku czasowym, zamiast skanować i sortować dużą liczbę rekordów.
Indeksy pokrywające: gdy indeks jest odpowiedzią
Indeks pokrywający zawiera wszystkie kolumny potrzebne zapytaniu, więc baza może zwrócić wyniki z samego indeksu bez odwołań do tabeli (mniej odczytów, mniejszy losowy I/O).
Uwaga: dodanie dodatkowych kolumn może powiększyć indeks i uczynić go kosztownym.
Nie buduj szerokich indeksów „na wszelki wypadek”
Szerokie indeksy złożone mogą spowolnić zapisy i zająć dużo miejsca. Dodawaj je tylko dla konkretnych, wartościowych zapytań i weryfikuj za pomocą planu EXPLAIN oraz rzeczywistych pomiarów przed i po.
Kompromisy: spowolnienia zapisów i dodatkowa przestrzeń
Indeksy często opisywane są jako „darmowe przyspieszenie”, ale to nie jest prawda. Struktury indeksów trzeba utrzymywać przy każdej zmianie tabeli, a one zajmują zasoby.
Wolniejsze INSERT/UPDATE/DELETE (bo każdy indeks trzeba zaktualizować)
Gdy robisz INSERT, baza nie tylko zapisuje wiersz — musi też dodać odpowiadające mu wpisy do każdego indeksu na tej tabeli. Podobnie przy DELETE i wielu UPDATEach.
Dlatego „więcej indeksów” może zauważalnie spowolnić obciążenia zapisów. UPDATE, który modyfikuje indeksowaną kolumnę, może być szczególnie kosztowny: baza może musieć usunąć stary wpis indeksu i dodać nowy (a w niektórych silnikach to może wywołać dzielenia stron lub wewnętrzne rebalansowanie).
Jeśli aplikacja intensywnie zapisuje — zdarzenia zamówień, dane z sensorów, logi audytu — indeksowanie wszystkiego może sprawić, że baza będzie odczuwać spowolnienie, nawet jeśli odczyty są szybkie.
Dodatkowa przestrzeń dyskowa i presja na pamięć
Każdy indeks zajmuje miejsce na dysku. Przy dużych tabelach indeksy mogą dorównywać (lub przewyższać) rozmiar tabeli, zwłaszcza gdy mamy wiele nachodzących na siebie indeksów.
To wpływa też na pamięć. Bazy intensywnie korzystają z cache; jeśli zestaw roboczy obejmuje kilka dużych indeksów, cache musi trzymać więcej stron, żeby pozostać szybkim. W przeciwnym razie zobaczysz więcej I/O z dysku i mniej przewidywalną wydajność.
Praktyczna równowaga
Indeksowanie to wybór, co przyspieszyć. Jeśli masz obciążenie zdominowane odczytami, więcej indeksów może się opłacić. Jeśli dominują zapisy, priorytetyzuj indeksy wspierające najważniejsze zapytania i unikaj duplikatów. Praktyczna zasada: dodaj indeks tylko wtedy, gdy potrafisz nazwać zapytanie, któremu pomaga — i zweryfikuj, czy zysk w odczytach przewyższa koszt zapisów i utrzymania.
Jak udowodnić, że indeks pomaga: EXPLAIN i pomiary
Dodanie indeksu wydaje się pomocne — ale możesz (i powinieneś) to zweryfikować. Dwa narzędzia, które to konkretują, to plan zapytania (EXPLAIN) i rzeczywiste pomiary przed/po.
Przeczytaj plan: czy indeks jest naprawdę używany?
Uruchom EXPLAIN (lub EXPLAIN ANALYZE) na dokładnym zapytaniu, które Cię interesuje.
- Typ skanu: Seq Scan / Full Table Scan oznacza, że baza czyta całą tabelę. Index Scan / Index Seek (lub Index Range Scan) sugeruje użycie indeksu do zawężenia wierszy.
- Szacowane vs. rzeczywiste wiersze (zwłaszcza w
EXPLAIN ANALYZE): jeśli plan oszacował 100 wierszy, a rzeczywiście dotknął 100 000, optymalizator się pomylił — często dlatego, że statystyki są przestarzałe lub filtr jest mniej selektywny niż oczekiwano.
- Kroki sortowania: jeśli widzisz explicite Sort, baza porządkuje wyniki po ich pobraniu. Jeśli nowy indeks pokrywa
ORDER BY, ten krok może zniknąć, co jest dużym zyskiem.
Mierz poprawnie: przed/po, w tych samych warunkach
Zbenchmarkuj zapytanie z takimi samymi parametrami, na reprezentatywnej ilości danych i zapisz zarówno latencję, jak i liczbę przetworzonych wierszy.
Uważaj na cache: pierwsze uruchomienie może być wolniejsze, bo dane nie są w pamięci; powtórne uruchomienia mogą wyglądać „naprawione” nawet bez indeksu. Aby się nie zmylić, porównaj wiele uruchomień i skup się na tym, czy plan się zmienia (indeks użyty, mniej odczytanych wierszy), oprócz surowego czasu.
Jeśli EXPLAIN ANALYZE pokazuje mniej dotkniętych wierszy i mniej kosztownych kroków (np. sortów), udowodniłeś, że indeks pomaga — nie tylko miałeś nadzieję, że to zrobi.
Częste błędy, które niweczą korzyści z indeksów
Możesz dodać „właściwy” indeks i nadal nie zobaczyć przyspieszenia, jeśli zapytanie jest napisane tak, że uniemożliwia jego użycie. Te problemy bywają subtelne, bo zapytanie nadal zwraca poprawne wyniki — po prostu wymusza wolniejszy plan.
Antywzorce blokujące użycie indeksu
1) Wildcardy na początku
Gdy piszesz:
WHERE name LIKE '%term'
baza nie może użyć normalnego indeksu B-tree, by przeskoczyć do właściwego miejsca, bo nie wiadomo, gdzie w uporządkowanym porządku zaczyna się „%term”. Często kończy się na skanowaniu wielu wierszy.
Alternatywy:
- jeśli to możliwe, użyj wyszukiwania prefiksowego:
WHERE name LIKE 'term%'.
- jeśli naprawdę potrzebujesz wyszukiwania „zawiera”, rozważ specjalny typ indeksu (np. full-text/trigram), zamiast oczekiwać, że standardowy indeks to udźwignie.
2) Funkcje na indeksowanych kolumnach
Wygląda niewinnie:
WHERE LOWER(email) = '[email protected]'
Ale LOWER(email) zmienia wyrażenie, więc indeks na email nie może być użyty bezpośrednio.
Alternatywy:
- przechowuj znormalizowane dane (np. małe litery w emailach) i zapytuj
WHERE email = ....
- albo stwórz indeks oparty na wyrażeniu/funkcji (zależne od bazy) specjalnie dla
LOWER(email).
Ukryte blokery indeksów, których ludzie nie zauważają
Rzutowania typów: porównywanie różnych typów może wymusić rzutowanie jednej strony, co dezaktywuje indeks. Przykład: porównanie kolumny integer z literałem string.
Niezgodne kolacje/kodowania: jeśli porównanie używa innej kolacji niż ta, z którą zbudowano indeks (częste przy tekstach w różnych lokalizacjach), optimizer może uniknąć indeksu.
Szybka lista kontrolna: „Dlaczego mój indeks nie jest używany?”
- Czy warunek zaczyna się od wildcarda (
LIKE '%x')?
- Czy stosujesz funkcję na indeksowanej kolumnie (
LOWER(col), DATE(col), CAST(col)) ?
- Czy typy są zgodne po obu stronach (brak ukrytego rzutowania)?
- Czy kolacja/lokalizacja są zgodne przy porównaniu?
- Czy predykat jest na tyle selektywny (nie pasuje do ogromnej części tabeli)?
- Czy filtrujesz/sortujesz po najbardziej lewostronnych kolumnach indeksu złożonego?
- Czy sprawdziłeś plan przez
EXPLAIN, żeby potwierdzić wybór silnika?
Utrzymanie indeksów: statystyki, bloat i długoterminowe zdrowie
Indeksów nie można „ustawić i zapomnieć”. Z czasem dane się zmieniają, wzorce zapytań ewoluują, a fizyczny kształt tabel i indeksów dryfuje. Dobrze dobrany indeks może z czasem stać się mniej skuteczny — a nawet szkodliwy — jeśli go nie utrzymujesz.
Statystyki: mapa plannera może się zestarzeć
Większość baz używa planera zapytań, by wybrać jak wykonać zapytanie: który indeks użyć, w jakiej kolejności wykonywać joiny i czy warto robić lookup po indeksie. Do podejmowania tych decyzji planner używa statystyk — podsumowań o rozkładzie wartości, liczbie wierszy i skew.
Gdy statystyki są przestarzałe, estymaty wierszy mogą być skrajnie błędne. To prowadzi do złych planów, np. wybrania indeksu, który zwraca o wiele więcej wierszy niż oczekiwano, albo pominięcia indeksu, który byłby szybszy.
Typowy fix: zaplanuj regularne aktualizacje statystyk (często ANALYZE lub podobne). Po dużych ładowaniach danych, masowych usunięciach lub znacznym churnie odśwież statystyki szybciej.
Bloat i fragmentacja: gdy struktury stają się niechlujne
W miarę jak wiersze są wstawiane, aktualizowane i usuwane, indeksy mogą narastać w postaci bloatu (pustych stron) i fragmentacji (danych rozrzuconych w sposób zwiększający I/O). Efekt to większe indeksy, więcej odczytów i wolniejsze skany — szczególnie przy zapytaniach zakresowych.
Typowy fix: okresowo przebudowuj lub reorganizuj mocno używane indeksy, gdy urosły nieproporcjonalnie lub gdy wydajność spadła. Narzędzia i wpływ zależą od bazy, więc traktuj to jako operację mierzoną, nie ogólną zasadę.
Monitoruj w czasie, nie tylko jednorazowo
Ustaw monitoring dla:
- wolnych zapytań (latencja, częstotliwość i najgorsi sprawcy)
- użycia indeksów (indeksy nigdy nieużywane vs. „gorące”)
- wzrostu rozmiaru indeksów i nagłych zmian planów
Taka pętla informacji zwrotnej pozwala wychwycić, kiedy potrzebna jest konserwacja — albo kiedy indeks należy zmodyfikować lub usunąć. Więcej o walidacji ulepszeń znajdziesz w /blog/how-to-prove-an-index-helps-explain-and-measurements.
Praktyczny workflow dodawania właściwego indeksu
Dodanie indeksu powinno być świadomą zmianą, nie strzałem na ślepo. Lekki workflow pomaga skupić się na mierzalnych zyskach i zapobiega „rozrostowi indeksów”.
1) Zidentyfikuj prawdziwe problematyczne zapytanie
Zacznij od dowodów: logi wolnych zapytań, ślady APM lub raporty użytkowników. Wybierz jedno zapytanie, które jest jednocześnie wolne i częste — rzadki raport trwający 10 sekund ma mniejsze znaczenie niż często wykonywane wyszukiwanie 200 ms.
Zapisz dokładne SQL i wzorzec parametrów (np. WHERE user_id = ? AND status = ? ORDER BY created_at DESC LIMIT 50). Małe różnice zmieniają, który indeks pomoże.
2) Zmierz punkt wyjścia
Zarejestruj aktualne opóźnienia (p50/p95), przeskanowane wiersze i wpływ na CPU/I/O. Zapisz też bieżący plan (EXPLAIN / EXPLAIN ANALYZE), żeby później porównać.
3) Zaprojektuj najmniejszy użyteczny indeks
Wybierz kolumny, które pasują do filtrów i sortowania w zapytaniu. Preferuj minimalny indeks, który sprawi, że plan przestanie skanować wielkie zakresy.
Testuj w stagingu przy danych zbliżonych do produkcji. Indeksy mogą wyglądać dobrze na małych zbiorach, a zawieść w skali.
4) Utwórz go bezpiecznie
Dla dużych tabel użyj opcji online, jeśli są wspierane (np. PostgreSQL CREATE INDEX CONCURRENTLY). Planuj zmiany w okresach mniejszego ruchu, jeśli baza może blokować zapisy.
5) Zweryfikuj dowodami przed/po
Uruchom to samo zapytanie i porównaj:
- kształt planu (czy przeszedł z full scan na dostęp przez indeks?)
- czas wykonania i liczbę przeskanowanych wierszy
- wpływ na zapisy (opóźnienia insert/update)
6) Miej plan wycofania
Jeśli indeks podniesie koszty zapisów lub spowoduje wzrost zużycia przestrzeni, usuń go czysto (np. DROP INDEX CONCURRENTLY, jeśli dostępne). Zachowaj możliwość cofnięcia migracji.
7) Udokumentuj „dlaczego”
W migracji lub notatkach schematu zapisz, które zapytanie obsługuje indeks i jaka metryka się poprawiła. Przyszłe Ty (lub kolega) będzie wiedział, po co istnieje i kiedy bezpiecznie go usunąć.
Gdzie Koder.ai pasuje do tego workflow
Jeśli budujesz nową usługę i chcesz unikać „rozrostu indeksów” od początku, Koder.ai pomaga szybciej zamknąć cały cykl: generuje aplikację React + Go + PostgreSQL z czatu, pozwala dopracować schemat/migracje w miarę zmiany wymagań, a potem eksportuje kod, gdy chcesz przejąć kontrolę ręcznie. W praktyce ułatwia to przejście od „ten endpoint jest wolny” do „oto plan EXPLAIN, minimalny indeks i odwracalna migracja” bez czekania na tradycyjny pipeline.
Kiedy indeksowanie to za mało (i co robić dalej)
Indeksy to potężna dźwignia, ale nie magiczny przycisk „przyspiesz”. Czasem wolna część żądania pojawia się po tym, jak baza znajdzie odpowiednie wiersze — albo wzorzec zapytań sprawia, że indeksowanie to niewłaściwy pierwszy krok.
Przypadki, gdy indeksy nie są głównym rozwiązaniem
Jeżeli zapytanie już używa dobrego indeksu, ale nadal jest wolne, poszukaj:
- Brakującej lub nieefektywnej paginacji: pobieranie strony 1000 z
OFFSET 999000 może być wolne nawet z indeksami. Preferuj paginację klucza (keyset), np. „daj wiersze po ostatnim id/timestamp”.
- Zwracania zbyt dużej ilości danych: wybieranie
SELECT * lub zwracanie dziesiątek tysięcy rekordów może zablokować sieć, serializację JSON lub przetwarzanie w aplikacji.
- Niedopasowania schematu: nadmierne normalizowanie joinów, przechowywanie wartości wyszukiwalnych w JSON/text blobach albo używanie niewłaściwych typów danych może wymusić kosztowne operacje, których indeksy nie ukryją.
Optymalizacje uzupełniające, które często są ważniejsze
- Przepisz zapytanie: usuń niepotrzebne joiny, unikaj funkcji na indeksowanych kolumnach w WHERE, uprość złożone predykaty OR.
- Ogranicz kolumny i wiersze: wybieraj tylko potrzebne pola, używaj sensownych LIMIT i świadomej paginacji.
- Cache: cache'uj gorące odczyty na poziomie aplikacji lub użyj read-through cache dla drogich, powtarzalnych zapytań.
- Partycyjność: jeśli większość zapytań trafia w „ostatnie dane”, partycjonuj po czasie (lub innej naturalnej granicy), by zmniejszyć przestrzeń poszukiwań.
Jeśli chcesz głębiej diagnozować wąskie gardła, sparuj to z workflowem w /blog/how-to-prove-an-index-helps.
Priorytetyzacja: napraw największe wąskie gardło najpierw
Nie zgaduj. Mierz, gdzie spędzany jest czas (wykonanie bazy vs. liczba zwróconych wierszy vs. kod aplikacji). Jeśli baza jest szybka, a API wolne, kolejne indeksy nic nie poprawią.
Szybka lista kontrolna