O co tu naprawdę chodzi: mniej dopytywań o wysyłki
Gdy wolumen zamówień jest mały, aktualizacje wysyłek da się ogarnąć szybkimi kontrolami, arkuszem kalkulacyjnym i kilkoma wiadomościami do kuriera. W miarę wzrostu zamówień małe luki się kumulują: etykiety powstają późno, odbiory są pomijane, a śledzenie przestaje się aktualizować.
Wzorzec jest znajomy: klienci pytają „Gdzie jest moje zamówienie?”. Support pyta ops. Ops sprawdza portal. Ktoś ręcznie aktualizuje status, który powinien był zaktualizować się sam.
Integracja oznacza po prostu, że twój system potrafi wysyłać dane wysyłkowe (adres, waga, COD, wartość faktury) i pobierać dane z powrotem (numer AWB, potwierdzenie odbioru, skany trackingowe, wyniki doręczenia) w sposób niezawodny. „Niezawodny” ma znaczenie — powinno działać codziennie, nie tylko wtedy, gdy ktoś pamięta o przesłaniu pliku.
Dlatego to porównanie ma sens:
- Workflow z uploadem CSV to baza. Łatwo zacząć, ale zależy od tego, że ludzie będą powtarzać te same kroki na czas.
- Pełna integracja z API kuriera to wersja zawsze‑włączona. Może tworzyć przesyłki, pobierać skany śledzenia i reagować na wyjątki bez czekania na pracę ręczną.
Większość zespołów nie chce „więcej technologii”. Chcą mniej opóźnień, mniej ręcznych poprawek i śledzenia, któremu można ufać. Zmniejsz liczbę dopytywań (od klientów i zespołów wewnętrznych), a zwykle zmniejszysz też zwroty, koszty ponownych prób i zgłoszenia do supportu.
Gdzie praca przy wysyłkach się psuje w prawdziwych operacjach
Większość zespołów zaczyna od prostej rutyny: rezerwuj odbiory, drukuj etykiety, wklejaj ID trackingowe do arkusza i odpowiadaj, gdy klienci pytają o status. To działa przy niskim wolumenie, ale rysy pojawiają się szybko w Indiach, zwłaszcza gdy operujesz wieloma kurierami, obsługujesz COD i masz niejednolitą jakość adresów.
Ręczne kroki same w sobie nie wyglądają na duże. Ktoś wybiera kuriera, tworzy przesyłkę, pobiera etykiety i upewnia się, że właściwa paczka otrzyma właściwy list przewozowy (AWB). Potem ktoś inny aktualizuje status zamówienia, udostępnia tracking i sprawdza dowody doręczenia dla COD.
Najczęstsze punkty awarii wyglądają tak:
- Nieprawidłowy AWB trafia na złą paczkę, co prowadzi do zagubienia przesyłki lub zwrotu.
- Powstają duplikaty przesyłek po ponownej próbie lub przez błąd kopiowania arkusza.
- Tracking nie jest aktualizowany na czas, więc support nie ma jasnej odpowiedzi i klienci tracą zaufanie.
- Odbiór nie jest potwierdzony, więc zamówienia stoją jako „gotowe do wysyłki”, podczas gdy kurier myśli, że nic nie jest zaplanowane.
- Kwoty COD lub opłaty nie zgadzają się, co powoduje problemy z uzgadnianiem potem.
NDR oznacza Non‑Delivery Report. To, co się dzieje, gdy doręczenie się nie powiodło (zły adres, klient nieobecny, odmowa, problem z płatnością). NDR generuje dodatkową pracę, ponieważ wymaga podjęcia decyzji: zadzwonić do klienta, zaktualizować adres, zatwierdzić ponowną próbę czy oznaczyć do zwrotu.
Presję najpierw odczuwa ops. Support dostaje wiadomości z pretensjami. Finanse utkną przy uzgadnianiu COD. Klienci odczuwają ciszę, gdy statusy się nie zmieniają.
Opcja A: workflow uploadu CSV (co zyskujesz, a czego nie)
Upload CSV to domyślny punkt startowy dla wielu konfiguracji wysyłkowych w Indiach. Eksportujesz partię opłaconych zamówień ze sklepu lub ERP, formatujesz je do szablonu kuriera lub agregatora, a potem wysyłasz plik w panelu, by wygenerować AWB i etykiety.
Co dostajesz, to prostota. Zwykle nie wymaga pracy inżynierskiej i możesz być na produkcji w jeden dzień. Dla niskiego wolumenu lub przewidywalnej wysyłki (ten sam adres odbioru, mały zestaw SKU, niewiele wyjątków) codzienny CSV może być „wystarczający” i łatwy do przeszkolenia.
Gdzie to się psuje, to wszystko po uploadzie. Większość zespołów codziennie robi te same porządki: naprawia nieudane wiersze, bo pincode lub format telefonu nie pasuje do szablonu, ponownie wysyła poprawione pliki, sprawdza przypadkowe duplikaty i kopiuj‑wklej numerów trackingowych z powrotem do panelu sklepu.
Potem zaczyna się bałagan: gonienie wyjątków (problemy z adresem, płatności, ryzyko RTO) przez e‑maile, telefony i portale kurierów oraz aktualizowanie statusu w wielu miejscach, bo panel kuriera nie jest twoim systemem źródłowym.
Ukryty koszt to czas i niespójność. Różni kurierzy oczekują różnych kolumn i reguł, więc „jeden CSV” zmienia się w wiele wersji i obejścia w arkuszach. A ponieważ aktualizacje nie są w czasie rzeczywistym, support często dowiaduje się o opóźnieniach dopiero, gdy klient zaczyna narzekać.
Opcja B: pełna integracja z API kuriera (co zyskujesz i co to kosztuje)
Pełna integracja z API kuriera oznacza, że twój system i system kuriera rozmawiają ze sobą bezpośrednio. Zamiast uploadować pliki, wysyłasz dane zamówienia i adresu automatycznie, otrzymujesz etykietę i ciągle pobierasz aktualizacje śledzenia bez potrzeby sprawdzania wielu paneli. Zwykle to moment, w którym wysyłka przestaje być codziennym obowiązkiem ops i zaczyna działać jak niezawodna infrastruktura.
Co to otwiera
Większość zespołów zaczyna integrację API kuriera dla trzech podstawowych działań: rezerwacja, etykiety i śledzenie. Typowe możliwości obejmują tworzenie przesyłki i uzyskanie AWB natychmiast, generowanie etykiety i danych faktury, zamawianie odbioru (tam, gdzie jest to wspierane) oraz pobieranie skanów śledzenia w niemal rzeczywistym czasie.
Gdy masz te podstawy, możesz też czyściej obsługiwać wyjątki, jak problemy z adresem czy statusy NDR.
Nagroda jest prosta: szybsza dyspozycja, mniej błędów kopiuj‑wklej i jaśniejsze aktualizacje dla klientów. Jeśli zamówienie zostanie opłacone o 14:00, twój system może automatycznie zarezerwować przesyłkę, wydrukować etykietę i wysłać numer śledzenia w ciągu minut, bez czekania na eksport CSV i ponowny upload.
Co to kosztuje
Integracje API nie są „ustaw i zapomnij”. Zaplanuj czas na konfigurację, testy i bieżące utrzymanie.
Typowe źródła wysiłku:
- Reguły specyficzne dla kuriera (obsługiwalność pincode, progi wagowe, limity COD)\n- Rozbieżności kodów statusów (u jednego kuriera „RTO initiated”, u innego „return in transit")\n- Niezawodność webhooków i logika retry dla przegapionych zdarzeń\n- Format etykiety i wymagania dokumentów zmieniające się w czasie\n- Sandboksy, które nie odzwierciedlają produkcji w 100%\n
Jeśli zaplanujesz te niedoskonałości wcześniej, wdrożenie skaluje się czysto. Jeśli nie, możesz skończyć z przesyłkami zarezerwowanymi, ale nieodebranymi, albo klientami widzącymi mylące statusy, bo zdarzenia trackingowe nie zostały poprawnie odwzorowane.
Co automatyzować, a co zostawić manualnie (praktyczne rozdzielenie)
Prosta zasada działa dobrze: automatyzuj zadania, które dzieją się wiele razy dziennie i generują najwięcej pracy, gdy ktoś popełni mały błąd.
W Indiach zwykle oznacza to rezerwacje, etykiety i aktualizacje śledzenia. Jedno literówka lub jeden pominięty skan może uruchomić łańcuch dopytań.
Ręczne kroki wciąż mają sens. Zachowaj je, gdy wolumen jest niski, gdy wyjątki są częste lub gdy procesy kuriera są zbyt niejednolite, by ufać automatyzacji.
Praktyczny podział wg workflow:
- Automatyzuj najpierw: rezerwację przesyłek z systemu zamówień, generowanie i druk etykiet, pobieranie statusów śledzenia lub webhooki, alerty NDR z wewnętrzną kolejką oraz potwierdzenia doręczenia dla zespołu supportu.\n- Pozostaw ręczne (dopóki nie ma wolumenu): wybór kuriera dla przypadków brzegowych, negocjowanie zmian odbioru przez telefon, zatwierdzanie ryzykownych ponownych prób COD i jednorazowe poprawki adresów wymagające oceny.
Krótka tabela decyzji przed budową czegokolwiek:
| Czynnik | Kiedy manual jest OK | Kiedy automatyzacja się opłaca |\n|---|---|---|\n| Dzienne zamówienia | < ~20/dzień | 50+/dzień lub częste skoki |\n| Liczba kurierów | 1 kurier | 2+ kurierów lub częste zmiany |\n| Presja SLA | 3–5 dni dostawy akceptowalne | Obietnice tego samego/następnego dnia, wysokie kary |\n| Wielkość zespołu | dedykowana osoba ops | role współdzielone ops/support |\n
Prosty checkpoint: jeśli zespół dotyka tych samych danych dwukrotnie (kopiuj‑wklej z zamówienia do panelu kuriera, potem z powrotem do arkusza), ten krok jest mocnym kandydatem do automatyzacji.
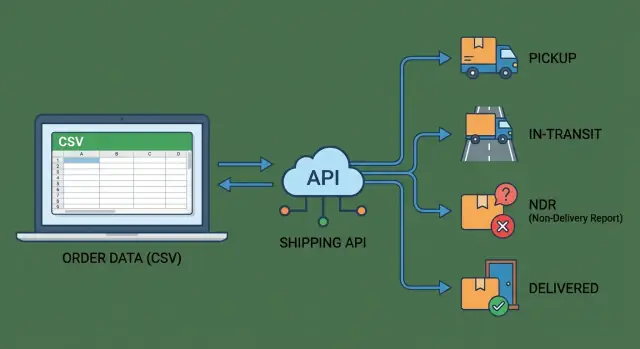
Lista zdarzeń śledzenia: pickup, in‑transit, NDR, delivered
Wprowadź workflow na żywo
Uruchom swój workflow wysyłkowy i iteruj bez czekania na długie cykle wydań.
Jeśli chcesz mniej pytań „gdzie jest moje zamówienie?”, traktuj śledzenie jako oś czasu zdarzeń, a nie pojedynczy status. To ma znaczenie w Indiach, gdzie ta sama przesyłka może krążyć między hubami, mieć ponowne próby i zwroty.
Rejestruj te etapy, by zespół i klienci widzieli tę samą historię:
- Pickup: kiedy odbiór jest zaplanowany, czy próbowano go wykonać i jaki jest wynik (odebrano lub nie). Jeśli się nie powiodło, zapisz powód niepowodzenia podany przez kuriera, żeby można było działać bez dzwonienia do kierowcy.\n- In‑transit: pierwszy skan (często to prawdziwy start), główne skany hubów, flagi wyjątków/opóźnień i „out for delivery”. To punkty wyzwalające większość pytań do supportu.\n- NDR (Non‑Delivery Report): kiedy NDR jest zgłoszony, kod powodu, czy klient był kontaktowany i co dalej (planowana ponowna próba czy rozpoczęty zwrot). Zwykle tu czas gra rolę.\n- Delivered (lub nie): czas doręczenia i szczegóły dowodu doręczenia, jeśli dostępne (imię, podpis, odniesienie do zdjęcia). Oddziel „dostarczono” od „zwrócono”, bo klienci odbierają to jako bardzo różne rezultaty.
Dla każdego zdarzenia zapisuj te same pola rdzeniowe: timestamp, lokalizacja (miasto i hub jeśli dostępne), surowy tekst statusu, znormalizowany status, kod powodu i referencję kuriera/AWB. Przechowywanie zarówno surowych, jak i znormalizowanych wartości ułatwia audyty i spory z kurierami.
Dane, które musisz mieć zanim zintegrujesz się (żeby nic potem nie padło)
Wiele integracji wysyłkowych zawodzi z nudnych powodów: brak numeru telefonu, niespójne wagi albo brak jasnej decyzji, który system „ma” prawdę. Zanim dotkniesz API, zdefiniuj minimum danych, które zawsze będziesz mieć dla każdego zamówienia.
Zacznij od podstaw, która też działa z CSV. Jeśli nie potrafisz wiarygodnie wyeksportować tych pól, API tylko przyspieszy pojawianie się błędów:
- ID zamówienia (unikalne i nigdy niepowtarzalne)\n- Pełny adres dostawy (imię, pincode, miasto, stan, punkt orientacyjny jeśli zbierasz)\n- Numer telefonu (zweryfikowany format) i e‑mail (opcjonalnie)\n- Pozycje i informacje przesyłki (SKU, ilość, waga brutto, wymiary jeśli je masz)\n- Dane płatności (kwota COD, flaga prepaid)
Następnie zdefiniuj, czego oczekujesz zwrotu od kuriera, bo to staną się twoje „uchwyty” dla wszystkiego innego. Minimum to: ID przesyłki, numer AWB, nazwa lub kod kuriera, referencja etykiety i data/okno odbioru.
Jedna decyzja zapobiega tygodniom zamieszania: wybierz jedno źródło prawdy dla statusu przesyłki. Jeśli zespół będzie sprawdzał portal kuriera i nadpisywał twój system, klienci będą widzieć jedno, a support mówić coś innego.
Prosty plan mapowania, który utrzyma wszystkich w zgodzie:
- Wybierz wewnętrzne statusy, których będziesz używać (np.: Created, Picked Up, In Transit, Out for Delivery, Delivered, NDR).\n- Mapuj każdy status kuriera na jeden wewnętrzny status (nawet jeśli traci detaliczność).\n- Zapisuj surowy tekst statusu kuriera osobno do audytu.\n- Zdecyduj, które zdarzenia mogą zmieniać status automatycznie, a które tylko przez człowieka.
Jeśli budujesz to w narzędziu takim jak Koder.ai, traktuj te pola i mapowania jako pierwszorzędne modele wcześnie, by eksporty, śledzenie i rollback nie zepsuły się, gdy dodasz drugiego kuriera.
Krok po kroku: przejście z CSV do API bez chaosu
Wdroż pierwszą integrację API wysyłkową
Zaprojektuj prototyp przepływu API kuriera do rezerwacji, etykiet i śledzenia z jednej konwersacji.
Najbezpieczniejsza ścieżka modernizacji to seria małych przełączeń, a nie jedno duże odcięcie. Ops powinien nadal wykonywać wysyłki, podczas gdy integracja się dopina.
1) Zamknij zakres zanim napiszesz kod
Wybierz kurierów, których faktycznie będziesz używać, a potem potwierdź, które akcje są potrzebne teraz, a które później: rezerwacja przesyłek, śledzenie, obsługa NDR i zwroty (RTO). To ważne, bo każdy kurier nazywa statusy inaczej i udostępnia różne pola.
2) Najpierw zintegruj śledzenie (tylko do odczytu)
Zanim zautomatyzujesz rezerwacje czy tworzenie etykiet, pobierz zdarzenia śledzenia do swojego systemu i pokaż je obok zamówienia. To niski risk, bo nie zmienia sposobu tworzenia paczek.
Upewnij się, że potrafisz pobierać zdarzenia po AWB i obsłuż przypadki, gdy AWB jest brakujący lub błędny.
3) Mapuj statusy, ale zapisuj surową prawdę
Stwórz mały wewnętrzny model statusów (pickup, in‑transit, NDR, delivered), potem mapuj statusy kuriera do niego. Zapisuj też każdy surowy payload zdarzenia dokładnie takim, jak go otrzymałeś.
Gdy klient mówi „pokazuje jako doręczone, ale nie dostałem”, surowe zdarzenia pozwolą supportowi odpowiedzieć szybko.
4) Dodaj automatyzację NDR ostrożnie
Zautomatyzuj łatwe elementy: wykrywanie NDR, przypisanie do kolejki, powiadomienie klienta i ustawianie timerów dla okien reattemptu.
Zachowaj ręczny override dla zmian adresów i przypadków specjalnych.
5) Dopiero potem dodaj rezerwacje, etykiety i planowanie odbioru
Gdy śledzenie jest stabilne, dodaj rezerwacje przez API, generowanie etykiet i żądania odbioru. Wdrażaj kurier‑po‑kurierze, trzymając ścieżkę CSV jako fallback przez kilka tygodni.
Testuj na realnych scenariuszach:\n\n- Zmiana adresu po NDR\n- Poproszona, ale nie wykonana ponowna próba\n- Wywołane RTO, a potem anulowane\n- Częściowe doręczenie lub przesyłka rozdzielona\n- Skan doręczenia bez OTP lub szczegółów POD
Typowe błędy, które powodują opóźnienia i zgłoszenia do supportu
Większość ticketów wysyłkowych to nie tylko „gdzie jest moje zamówienie?”. To niedopasowane oczekiwania: twój system mówi jedno, kurier drugie, a klient widzi trzecie.
Pułapką jest zakładanie, że tekst statusu jest jednolity. Ten sam etap może pojawić się w różnych frazach w zależności od strefy, typu usługi czy huba. Jeśli mapujesz po dokładnym tekście zamiast normalizować do własnego małego zestawu stanów, dashboard i wiadomości do klientów będą dryfować.
Błędy, które generują opóźnienia i dodatkowe follow‑upy:
- Zapisywanie tylko najnowszego statusu: nadpisywanie zdarzeń traci linię czasu, która tłumaczy, co się wydarzyło. Przechowuj pełną historię ze znacznikami czasu i lokalizacją.\n- Traktowanie NDR jako jednego statusu: NDR to proces. Potrzebujesz kodu powodu, podjętych działań i daty następnej próby.\n- Brak obsługi późnych lub nieuporządkowanych wydarzeń: kurierzy mogą wysyłać zdarzenia w paczkach lub w dziwnej kolejności. Bez reconciliacji i bezpiecznych aktualizacji system może przeskakiwać między statusami.\n- Brak logiki retry i obsługi limitów szybkości: wywołania API zawodzą. Jeśli nie retryujesz bezpiecznie, tracisz aktualizacje. Jeśli retryujesz zbyt agresywnie, łapiesz rate limit.\n- Brak planu zapasowego operacyjnego: zdecyduj, co robić, gdy API padnie. Czy przełączyć się na CSV na dzień, wstrzymać powiadomienia czy oznaczyć zamówienia do ręcznej weryfikacji?
Prosty przykład: klient dzwoni mówiąc, że paczka została „zwrócona”. Twój system pokazuje tylko „NDR”. Gdybyś zapisał powód NDR i historię ponownych prób, agent mógłby odpowiedzieć jedną wiadomością zamiast eskalować do ops.
Szybkie kontrole zanim uznasz integrację za „gotową"
Zanim ogłosisz sukces, testuj integrację tak, jak będzie jej używać ops i support w dniu zwiększonego ruchu. Aktualizacja statusu od kuriera, która przychodzi późno lub bez właściwych szczegółów, tworzy ten sam problem co brak aktualizacji.
Przeprowadź „jedna przesyłka, end‑to‑end” dla co najmniej 10 realnych zamówień przez różne pincode i typy płatności (prepaid i COD). Wybierz jedno zamówienie i zmierz, ile czasu zajmuje odpowiedź na pytania:
- Gdzie jest teraz?\n- Co było wcześniej?\n- Co robimy dalej?
Szybka lista kontrolna, która łapie większość luk:
- Dowód odbioru jest widoczny szybko: widzisz potwierdzenie odbioru w oczekiwanym oknie i potrafisz odróżnić „etykieta utworzona” od „fizycznie odebrane”.\n- NDR jest możliwy do działania, nie tylko status: zapisujesz kod powodu NDR oraz następny krok (ponowna próba, telefon, RTO) i możesz tę decyzję zmienić.\n- Oś czasu jest łatwa do znalezienia: agent może w ciągu 30 sekund wyciągnąć pełną historię zdarzeń dla jednego AWB, łącznie ze znacznikami czasu i skanami lokalizacji.\n- Doręczenie zgadza się z pieniędzmi i zwrotami: dostarczone przesyłki rekoncyliują się z raportami rozliczeń COD i danymi zwrotów/RTO, więc finanse nie gonią niejasności pod koniec tygodnia.\n- Jest bezpieczny ręczny override: możesz poprawić adres, przełożyć dostawę lub przypisać do innego kuriera, a każda ręczna zmiana jest logowana.
Jeśli budujesz wewnętrzne ekrany, pierwsza wersja niech będzie nudna: jedno pole wyszukiwania przesyłki, jedna czytelna oś czasu i dwa przyciski (ręczna notatka i nadpisanie).
Narzędzia takie jak Koder.ai mogą pomóc szybko prototypować taki panel ops i wyeksportować kod źródłowy, gdy będziesz gotowy przejąć go na własność. Jeśli chcesz to później zbadać, znajdziesz informacje na koder.ai.
Przykład: zespół D2C skalujący się z 20 do 150 zamówień/dzień
Zaplanuj swój model wysyłek
Zdefiniuj mapowanie statusów i pola danych zanim zaczniesz pisać kod.
Średniej wielkości marka D2C zaczyna od ~20 zamówień dziennie, wysyła głównie w jednym metrze. Korzysta z dwóch partnerów kurierskich. Proces jest prosty: eksport zamówień, upload CSV dwa razy dziennie, potem kopiuj‑wklej numerów trackingowych do panelu sklepu.
Przy 150 zamówień/dzień i trzech kurierach ta rutyna zaczyna pękać. Klienci pytają „gdzie moja paczka?”, a support musi sprawdzać trzy panele.
Najgorsza część to NDRy. Próba doręczenia kończy się telefonem od kuriera, a follow‑up zamienia się w wątek na WhatsAppie. Ponowne próby są pomijane, a małe opóźnienie zamienia się w anulacje i zwroty.
Przechodzą na setup, który synchronizuje zdarzenia automatycznie. Teraz każda aktualizacja przesyłki trafia w jedno miejsce, a zespół pracuje z jednej kolejki zamiast z zrzutów ekranu z czatów.
Zmiany dzień‑do‑dnia:
- Zdarzenia trackingowe synchronizują się z zamówieniem automatycznie (pickup, in‑transit, out for delivery, delivered).\n- NDRy tworzą widoczną kolejkę z powodem (problem z adresem, brak kontaktu, problem z płatnością).\n- Przypomnienia o ponownej próbie odpalają się w ustalonym czasie, więc nic nie leży przez dwa dni.\n- Support widzi aktualny status bez logowania do paneli kurierów.
Nie wszystko jest zautomatyzowane. Nadal ręcznie zmieniają kurierów dla trudnych pincode lub problemów z przepustowością w sezonie. Gdy klient dzwoni poprawić adres, człowiek to weryfikuje zanim uruchomi się ponowna próba.
Kolejne kroki: wybierz zakres i zbuduj prostą pierwszą wersję
Zdecyduj, czego potrzebujesz w pierwszych 2–4 tygodniach. Największy zwrot zwykle daje niezawodne śledzenie i mniej zapytań „gdzie jest moje zamówienie?”, a nie budowanie wszystkich funkcji od pierwszego dnia.
Wybierz początkowy zakres zgodny z bólem twojego zespołu:
- Tylko śledzenie: pobieraj zdarzenia od kuriera i utrzymuj zgodność klientów i supportu.\n- Rezerwacja + etykieta: twórz przesyłki, generuj etykiety i zapisuj numery AWB automatycznie.\n- Rezerwacja + etykieta + odbiór: dodaj planowanie odbioru i potwierdzenie odbioru, by ops nie gonił kierowców.
Zanim napiszesz kod, ustal język, którego będziesz używać wewnętrznie. Spisz listę zdarzeń (pickup, in‑transit, NDR, delivered) i przypisz każdy status kuriera do jednego ze swoich statusów. Jeśli tego pominiesz, skończysz z pięcioma wariantami „in transit” i niejasnymi regułami, kiedy powiadamiać klienta, otwierać zadanie NDR czy oznaczać zamówienie jako zakończone.
Wdrażaj etapami (i nie szalej z UI)
Bezpieczne wdrożenie wygląda tak: jeden kurier, jedna trasa (lub jedno magazyn), potem rozszerzaj.
Uruchom nowy flow równolegle z procesem CSV przez krótki czas, żeby ops mógł porównać AWB, etykiety i aktualizacje trackingowe. Miej prosty fallback: jeśli wywołanie API zawiedzie, utwórz zadanie do ręcznej rezerwacji zamiast blokować wysyłkę.
Buduj szybko, ale nie zamykaj sobie dróg ucieczki
Jeśli chcesz iść szybko, prototypuj integrację API kuriera z Koder.ai: zdefiniuj tabelę przechowywania zdarzeń, reguły mapowania statusów i mały panel ops (wyszukiwanie po zamówieniu lub AWB, ostatnie zdarzenie, następne działanie). Gdy zachowuje się tak, jak zespół oczekuje, wyeksportuj kod źródłowy i wzmocnij go retryami, logowaniem i kontrolą dostępu.
Dobra pierwsza wersja nie jest „kompletna”. To jeden kurier działający end‑to‑end, z czystymi zdarzeniami, jasną własnością NDR i widokiem dziennym, który mówi ops, co wymaga uwagi teraz.