13 lis 2025·8 min
Jak bazy NoSQL powstały, by rozwiązać problemy skali i elastyczności
Dowiedz się, dlaczego powstały bazy NoSQL: skala webu, potrzeba elastycznych danych i ograniczenia systemów relacyjnych — oraz kluczowe modele i kompromisy.
Dowiedz się, dlaczego powstały bazy NoSQL: skala webu, potrzeba elastycznych danych i ograniczenia systemów relacyjnych — oraz kluczowe modele i kompromisy.
NoSQL pojawił się, gdy wiele zespołów napotkało rozbieżność między potrzebami aplikacji a tym, do czego tradycyjne bazy relacyjne (bazy SQL) były zoptymalizowane. SQL nie „zawiódł” — ale na skali webu niektóre zespoły zaczęły priorytetyzować inne cele.
Po pierwsze, skala. Popularne aplikacje konsumenckie zaczęły doświadczać skoków ruchu, stałych zapisów i ogromnych wolumenów danych generowanych przez użytkowników. Dla takich obciążeń „kup większy serwer” stało się drogie, trudne do wdrożenia i ostatecznie ograniczone przez największą maszynę, którą można racjonalnie obsługiwać.
Po drugie, zmiana. Funkcje produktu ewoluowały szybko, a dane nie zawsze mieściły się wygodnie w zestawie sztywnych tabel. Dodawanie nowych atrybutów do profili użytkowników, przechowywanie różnych typów zdarzeń czy przyjmowanie półstrukturalnego JSON z różnych źródeł często oznaczało powtarzające się migracje schematu i wymaganą koordynację między zespołami.
Bazy relacyjne świetnie sprawdzają się w egzekwowaniu struktury i umożliwianiu złożonych zapytań między znormalizowanymi tabelami. Jednak pewne obciążenia o dużej skali utrudniały wykorzystanie tych zalet:
W rezultacie niektóre zespoły szukały systemów, które wymieniały pewne gwarancje i możliwości na prostsze skalowanie i szybsze iteracje.
NoSQL nie jest pojedynczą bazą ani jednym projektem. To parasol terminów dla systemów, które kładą nacisk na pewne kombinacje:
NoSQL nigdy nie miał być uniwersalnym zamiennikiem SQL. To zestaw kompromisów: możesz zyskać skalowalność lub elastyczność schematu, ale możesz też zaakceptować słabsze gwarancje spójności, mniej opcji zapytań ad-hoc lub większą odpowiedzialność w modelowaniu danych po stronie aplikacji.
Przez lata standardowa odpowiedź na wolną bazę była prosta: kup większy serwer. Dodaj więcej CPU, więcej RAM, szybsze dyski i zachowaj ten sam schemat oraz model operacyjny. Podejście „scale up” działało — aż przestało być praktyczne.
Maszyny wysokiej klasy szybko drożeją, a krzywa cena/wydajność w końcu staje się niekorzystna. Ulepszenia często wymagają dużych, rzadkich zatwierdzeń budżetowych i okien konserwacyjnych na przenosiny danych i przełączenia. Nawet jeśli możesz pozwolić sobie na większy sprzęt, jedna maszyna ma sufit: jedna magistrala pamięci, jeden podsystem dyskowy i jeden główny węzeł absorbujący obciążenie zapisów.
W miarę rozwoju produktów bazy danych doświadczały ciągłego nacisku odczytów/zapisów zamiast epizodycznych szczytów. Ruch stał się rzeczywiście 24/7, a niektóre funkcje tworzyły nierównomierne wzorce dostępu. Mała liczba mocno eksploatowanych wierszy lub partycji potrafiła zdominować ruch, tworząc hot table (lub hot key), które spowalniały wszystko inne.
Występowały zwykłe wąskie gardła operacyjne:\n
Wiele aplikacji musiało być dostępnych w wielu regionach, nie tylko szybkie w jednym centrum danych. Pojedyncza „główna” baza w jednym miejscu zwiększa opóźnienia dla odległych użytkowników i sprawia, że awarie są bardziej katastrofalne. Pytanie przestało brzmieć „Jak kupimy większą maszynę?” a zaczęło brzmieć „Jak uruchomić bazę danych na wielu maszynach i lokalizacjach?”.
Bazy relacyjne błyszczą, gdy kształt danych jest stabilny. Ale wiele współczesnych produktów się nie zatrzymuje. Schemat tabeli jest celowo ścisły: każdy wiersz ma ten sam zestaw kolumn, typów i ograniczeń. Ta przewidywalność jest cenna — dopóki nie iterujesz szybko.
W praktyce częste zmiany schematu mogą być kosztowne. Pozornie mała aktualizacja może wymagać migracji, backfilli, aktualizacji indeksów, zsynchronizowanego czasu wdrożeń i planowania kompatybilności, aby starsze ścieżki kodu nie przestały działać. Przy dużych tabelach nawet dodanie kolumny lub zmiana typu może stać się czasochłonną operacją z realnym ryzykiem operacyjnym.
Ten opór skłania zespoły do odkładania zmian, gromadzenia obejść lub przechowywania chaotycznych blobów w polach tekstowych — żadne z tych rozwiązań nie jest idealne dla szybkiego iterowania.
Wiele danych aplikacyjnych jest naturalnie półstrukturalnych: zagnieżdżone obiekty, pola opcjonalne i atrybuty, które zmieniają się w czasie.
Na przykład „profil użytkownika” może zacząć się od imienia i e‑maila, a potem rozrosnąć o preferencje, powiązane konta, adresy wysyłkowe, ustawienia powiadomień i flagi eksperymentów. Nie każdy użytkownik ma każde pole, a nowe pola pojawiają się stopniowo. Modele dokumentowe mogą przechowywać zagnieżdżone i niejednolite kształty bez zmuszania każdego rekordu do trzymania się tej samej, sztywnej szablony.
Elastyczność zmniejsza też potrzebę złożonych joinów dla pewnych kształtów danych. Gdy jeden ekran potrzebuje złożonego obiektu (zamówienie z pozycjami, informacją o wysyłce i historią statusów), projekt relacyjny może wymagać wielu tabel i joinów — plus warstwy ORM, które próbują to ukryć, ale często dodają tarcia.
Opcje NoSQL ułatwiły modelowanie danych bliżej tego, jak aplikacja czyta i zapisuje je, pomagając zespołom szybciej dostarczać zmiany.
Aplikacje webowe nie tylko urosły — zmieniły kształt. Zamiast obsługiwać przewidywalną liczbę wewnętrznych użytkowników w godzinach pracy, produkty zaczęły obsługiwać miliony globalnych użytkowników przez całą dobę, z nagłymi skokami wywoływanymi przez premiery, wiadomości czy udostępnienia społecznościowe.
Oczekiwania „zawsze włączony” podniosły poprzeczkę: przestoje stały się nagłówkiem, nie tylko niedogodnością. Jednocześnie od zespołów oczekiwano szybszego wdrażania funkcji — często zanim ktokolwiek znał „ostateczny” model danych.
Aby nadążyć, skalowanie pojedynczego serwera przestało wystarczać. Im więcej ruchu obsługiwałeś, tym bardziej chciałeś pojemności, którą można dodawać stopniowo — dołóż kolejny węzeł, rozłóż obciążenie, izoluj awarie.
To przesunęło architekturę w kierunku flot maszyn zamiast jednej „głównej” skrzynki i zmieniło oczekiwania: nie tylko poprawność, ale przewidywalna wydajność przy dużej współbieżności i łagodne zachowanie, gdy część systemu jest niezdrowa.
Zanim „NoSQL” stał się mainstreamem, wiele zespołów już wyginało systemy w kierunku realiów web‑skali:\n
Te techniki działały, ale przesuwały złożoność do kodu aplikacji: unieważnianie cache, utrzymanie spójności zduplikowanych danych i budowanie potoków dla rekordów „gotowych do serwowania”.
Gdy te wzorce stały się standardem, bazy musiały wspierać rozproszenie danych po maszynach, tolerować częściowe awarie, obsługiwać wysokie wolumeny zapisów i czytelnie reprezentować ewoluujące dane. Bazy NoSQL pojawiły się częściowo po to, by uczynić powszechne strategie web‑skali cechami pierwszorzędnymi, a nie stałymi obejściami.
Gdy dane mieszkają na jednej maszynie, zasady wydają się proste: istnieje pojedyncze źródło prawdy i każdy odczyt lub zapis można od razu sprawdzić. Gdy rozkładasz dane na serwery (często po regionach), pojawia się nowa rzeczywistość: wiadomości mogą się opóźniać, węzły mogą padać, a części systemu czasowo przestają komunikować się ze sobą.
Baza rozproszona musi zdecydować, co zrobić, gdy nie można bezpiecznie się skoordynować. Czy nadal obsługiwać żądania, by aplikacja była „dostępna”, nawet jeśli wyniki mogą być nieco nieaktualne? Czy odrzucać część operacji, dopóki repliki się nie zgadzają, co może wyglądać jak przestój dla użytkowników?
Takie sytuacje występują podczas awarii routerów, przeciążonych sieci, wdrożeń krokowych, błędnych konfiguracji zapór i opóźnień replikacji między regionami.
Twierdzenie CAP to skrót od trzech właściwości, które chciałbyś mieć jednocześnie:\n
Wyobraź sobie aplikację działającą w dwóch regionach dla odporności. Przerwanie światłowodu lub problem z routingiem uniemożliwia synchronizację.
Różne systemy NoSQL (a nawet różne konfiguracje tej samej bazy) przyjmują różne kompromisy w zależności od tego, co jest najważniejsze: doświadczenie użytkownika podczas awarii, gwarancje poprawności, prostota operacyjna czy zachowanie przy odzyskiwaniu.
Skalowanie poziome (scale out) oznacza zwiększanie pojemności przez dodawanie więcej maszyn (węzłów) zamiast kupowania jednego większego serwera. Dla wielu zespołów była to zmiana finansowa i operacyjna: można było dodawać tańsze, standardowe węzły stopniowo, oczekiwać awarii i nie wymagać ryzykownych migracji „big box”.
Aby wiele węzłów było użytecznych, systemy NoSQL opierały się na shardingowaniu (zwanym też partycjonowaniem). Zamiast jednej bazy obsługującej każde żądanie, dane dzieli się na partycje i rozprowadza po węzłach.
Prosty przykład partycjonowania po kluczu (jak user_id):\n
Odczyty i zapisy się rozkładają, zmniejszając hot‑spoty i pozwalając na wzrost przepustowości wraz z dodawaniem węzłów. Klucz partycji staje się decyzją projektową: wybierz klucz zgodny ze wzorcami zapytań, inaczej możesz przypadkowo skierować zbyt duży ruch do jednego shardu.
Replikacja oznacza przechowywanie wielu kopii tych samych danych na różnych węzłach. Poprawia to:\n
Replikacja umożliwia też rozkład danych po rackach lub regionach, aby przetrwać lokalne awarie.
Sharding i replikacja wprowadzają bieżącą pracę operacyjną. W miarę wzrostu danych lub zmiany węzłów system musi przerebalansować — przenosić partycje podczas działania. Jeśli to jest źle zaimplementowane, rebalance może powodować skoki latencji, nierównomierne obciążenie lub tymczasowe braki pojemności.
To podstawowy kompromis: tańsze skalowanie przez więcej węzłów w zamian za bardziej złożone rozproszenie, monitorowanie i obsługę awarii.
Gdy dane są rozproszone, baza musi zdefiniować, co oznacza „poprawne” w sytuacjach, gdy aktualizacje zachodzą współbieżnie, sieć zwalnia lub węzły nie mogą się komunikować.
Przy silnej spójności, gdy zapis zostanie potwierdzony, każdy czytelnik powinien go zobaczyć natychmiast. To odpowiada doświadczeniu „pojedynczego źródła prawdy”, które wiele osób kojarzy z bazami relacyjnymi.
Wyzwanie to koordynacja: ścisłe gwarancje między węzłami wymagają wielu komunikatów, oczekiwania na wystarczającą liczbę odpowiedzi i radzenia sobie z awariami w trakcie operacji. Im dalej od siebie węzły (lub im bardziej obciążone), tym większe opóźnienie — czasami na każdy zapis.
Spójność ostateczna rozluźnia tę gwarancję: po zapisie różne węzły mogą chwilowo zwracać różne odpowiedzi, ale system z czasem się zbiegnie.
Przykłady:\n
Dla wielu doświadczeń użytkownika taka chwilowa niezgodność jest akceptowalna, jeśli system pozostaje szybki i dostępny.
Jeśli dwie repliki zaakceptują aktualizacje niemal w tym samym czasie, baza potrzebuje reguły scalania.\n Typowe podejścia obejmują:\n
Silna spójność zwykle jest warta kosztu dla transferów pieniężnych, limitów zapasów, unikalnych nazw użytkowników, uprawnień i wszelkich procesów, gdzie „dwie prawdy przez chwilę” mogą wyrządzić realną szkodę.
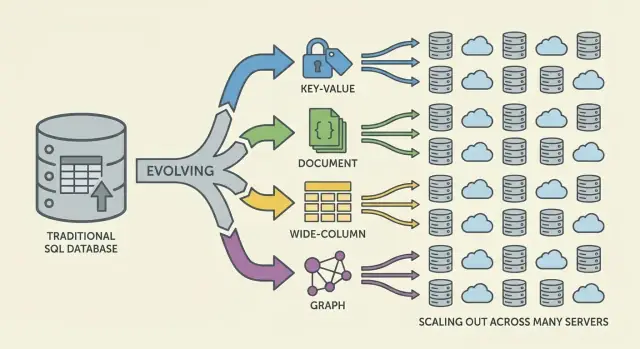
NoSQL to zestaw modeli, które robią różne kompromisy wokół skali, latencji i kształtu danych. Zrozumienie „rodziny” pomaga przewidzieć, co będzie szybkie, co bolesne i dlaczego.
Bazy key‑value przechowują wartość pod unikalnym kluczem, jak ogromna, rozproszona hashmapa. Ponieważ wzorzec dostępu to zwykle „get po kluczu” / „set po kluczu”, mogą być ekstremalnie szybkie i horyzontalnie skalowalne.
Sprawdzają się, gdy znasz klucz wyszukiwania (sesje, cache, feature flags), ale są ograniczone w zapytaniach ad‑hoc: filtrowanie po wielu polach często nie jest celem tego systemu.
Bazy dokumentowe przechowują dokumenty w stylu JSON (często grupowane w kolekcje). Każdy dokument może mieć nieco inną strukturę, co wspiera elastyczność schematu w miarę ewolucji produktu.
Optymalizują odczyt i zapis całych dokumentów oraz zapytania po polach wewnątrz nich — bez wymuszonego trzymania się sztywnych tabel. Kompromis: modelowanie relacji może być trudniejsze, a joiny (jeśli są wspierane) ograniczone w porównaniu z systemami relacyjnymi.
Bazy szerokokolumnowe (inspirowane Bigtable) organizują dane według kluczy wierszy, z wieloma kolumnami, które mogą się różnić w zależności od wiersza. Świetnie radzą sobie z olbrzymim tempem zapisów i rozproszonym przechowywaniem, co czyni je dobrym wyborem dla time‑series, zdarzeń i logów.
Nagrodą jest konieczność starannego projektowania pod kątem wzorców dostępu: zapytujesz efektywnie po kluczu podstawowym i regułach klastrowania, a nie po dowolnych filtrach.
Bazy grafowe traktują relacje jako dane najwyższej klasy. Zamiast wielokrotnych joinów, przeszukują krawędzie między węzłami, co czyni zapytania typu „jak te rzeczy są powiązane?” naturalnymi i szybkimi (wykrywanie pierścieni oszustw, rekomendacje, grafy zależności).
Bazy relacyjne zachęcają do normalizacji: dziel danych na wiele tabel i łącz je joinami w czasie zapytania. Wiele systemów NoSQL skłania do projektowania wokół najważniejszych wzorców dostępu — czasem kosztem duplikacji — by utrzymać przewidywalną latencję między węzłami.
W bazach rozproszonych join może wymagać pobrania danych z wielu partycji lub maszyn. To dodaje skoków sieciowych, koordynacji i nieprzewidywalnej latencji. Denormalizacja (przechowywanie powiązanych danych razem) zmniejsza liczbę rund i utrzymuje odczyt „lokalnym” tak często, jak to możliwe.
Praktyczny skutek: możesz przechowywać tę samą nazwę klienta w rekordzie orders, nawet jeśli istnieje też w customers, ponieważ „pokaż mi ostatnie 20 zamówień” jest kluczowym zapytaniem.
Wiele baz NoSQL wspiera ograniczone joiny (lub wcale), więc aplikacja bierze na siebie większą odpowiedzialność:\n
Dlatego modelowanie NoSQL często zaczyna się od pytań: „Jakie ekrany musimy załadować?” i „Które zapytania muszą być najszybsze?”.
Indeksy pomocnicze umożliwiają nowe zapytania ("znajdź użytkowników po e‑mailu"), ale nie są darmowe. W systemach rozproszonych każdy zapis może aktualizować wiele struktur indeksu, co prowadzi do:\n
user_profile_summary, by serwować stronę profilu bez skanowania postów, polubień i followówNoSQL nie został przyjęty dlatego, że był „lepszy” we wszystkim. Przyjęto go, ponieważ zespoły były skłonne wymienić pewne wygody baz relacyjnych na szybkość, skalę i elastyczność pod presją web‑skali.
Skalowanie poziome jako element projektu. Wiele systemów NoSQL uczyniło dodawanie maszyn (scale‑out) praktycznym zamiast ciągłej modernizacji pojedynczego serwera. Sharding i replikacja stały się funkcjami pierwszorzędnymi.
Elastyczne schematy. Systemy dokumentowe i key‑value pozwalały aplikacjom ewoluować bez każdorazowego przechodzenia przez ścisły opis tabel, zmniejszając tarcie przy zmianach co tydzień.
Wzorce wysokiej dostępności. Replikacja między węzłami i regionami ułatwiała utrzymanie usług podczas awarii sprzętu lub prac konserwacyjnych.
Duplikacja danych i denormalizacja. Unikanie joinów często oznacza duplikowanie danych. To poprawia wydajność odczytu, ale zwiększa koszty przechowywania i wprowadza złożoność „zaktualizuj wszędzie”.
Niespodzianki związane ze spójnością. Spójność ostateczna może być akceptowalna — aż do momentu, gdy nie jest. Użytkownicy mogą widzieć nieświeże dane lub mylące przypadki brzegowe, jeśli aplikacja nie jest zaprojektowana do tolerowania lub rozwiązywania konfliktów.
Trudniejsza analityka (czasami). Niektóre sklepy NoSQL doskonale radzą sobie z operacyjnymi odczytami/zapisami, ale utrudniają zapytania ad‑hoc, raportowanie czy złożone agregacje w porównaniu z rozwiązaniami SQL‑first.
Wczesne adopcje NoSQL często przesuwały wysiłek z funkcji bazy danych na dyscyplinę inżynieryjną: monitorowanie replikacji, zarządzanie partycjami, uruchamianie kompakcji, planowanie backupów/przywróceń i testowanie scenariuszy awarii. Zespoły o wysokiej dojrzałości operacyjnej zyskiwały najwięcej.
Wybieraj na podstawie realiów obciążenia: oczekiwanej latencji, szczytowej przepustowości, dominujących wzorców zapytań, tolerancji na nieświeże odczyty oraz wymagań odzyskiwania (RPO/RTO). "Właściwy" wybór NoSQL to zwykle ten, który pasuje do tego, jak aplikacja się psuje, skaluje i jest zapytana — niekoniecznie ten z najbardziej imponującą listą cech.
Wybór NoSQL nie powinien zaczynać się od marek baz danych czy hype’u — powinien zaczynać się od tego, co twoja aplikacja musi robić, jak będzie rosła i co oznacza „poprawność” dla twoich użytkowników.
Zanim wybierzesz magazyn danych, zapisz:\n
Użyj tego jako szybkiego filtra:\n
Sygnał praktyczny: jeśli twoje „core truth” (zamówienia, płatności, zapasy) musi być poprawne zawsze, trzymaj to w SQL lub innym sklepie o silnej spójności. Jeśli serwujesz treści o dużym wolumenie, sesje, cache, feedy lub elastyczne dane tworzone przez użytkowników, NoSQL może być dobrym dopasowaniem.
Wiele zespołów odnosi sukcesy z wieloma magazynami: na przykład SQL dla transakcji, baza dokumentowa dla profili/treści i key‑value dla sesji. Cel nie jest komplikacją dla samej komplikacji — to dopasowanie każdego obciążenia do narzędzia, które radzi sobie z nim najbardziej elegancko.
To też miejsce, gdzie workflow deweloperski ma znaczenie. Jeśli iterujesz nad architekturą (SQL vs NoSQL vs hybryda), możliwość szybkiego uruchomienia działającego prototypu — API, model danych i UI — może zmniejszyć ryzyko decyzji. Platformy takie jak Koder.ai pomagają zespołom to zrobić, generując aplikacje full‑stack z czatu, zwykle z frontendem w React i backendem Go + PostgreSQL, a następnie pozwalając eksportować kod źródłowy. Nawet jeśli później wprowadzisz NoSQL dla konkretnych obciążeń, posiadanie silnego SQL‑owego „systemu źródłowego” plus szybkie prototypowanie, snapshoty i rollbacki może uczynić eksperymenty bezpieczniejszymi i szybszymi.
Cokolwiek wybierzesz, udowodnij to:\n
Jeśli nie możesz tych scenariuszy przetestować, twoja decyzja o bazie pozostaje teoretyczna — a produkcja przetestuje ją za ciebie.
NoSQL odpowiadał na dwa powszechne naciski:
Nie chodziło o to, że SQL był „zły”, lecz o to, że różne obciążenia priorytetyzowały inne kompromisy.
Tradycyjne „scale up” napotyka praktyczne limity:
Systemy NoSQL postawiły na scale out — dodawanie węzłów zamiast ciągłego kupowania większego serwera.
Schematy relacyjne są z definicji sztywne, co jest świetne dla stabilności, ale bolesne przy szybkim iterowaniu. Na dużych tabelach nawet „proste” zmiany mogą wymagać:
Modele dokumentowe często zmniejszają ten opór, pozwalając na pola opcjonalne i ewoluujące kształty.
Nie zawsze. Wiele baz SQL potrafi rozrosnąć się poziomo, lecz bywa to operacyjnie skomplikowane (strategia shardingowa, cross-shard joins, transakcje rozproszone).
Systemy NoSQL często traktowały dystrybucję (partycyjowanie + replikacja) jako cechę pierwszorzędną, upraszczając przewidywalne wzorce dostępu przy dużej skali.
Denormalizacja przechowuje dane w kształcie, w jakim się je czyta, często duplikując pola, aby uniknąć kosztownych joinów między partycjami.
Przykład: przechowywanie nazwy klienta w rekordzie orders, aby „ostatnie 20 zamówień” było szybkim, pojedynczym odczytem.
Kosztem jest złożoność aktualizacji: trzeba utrzymywać spójność zduplikowanych danych w logice aplikacji lub w potokach przetwarzania.
W systemach rozproszonych baza musi zdecydować, co robić podczas partycji sieciowych:
CAP przypomina, że pod partycją nie da się jednocześnie zagwarantować zarówno pełnej spójności, jak i pełnej dostępności.
Silna spójność oznacza, że po potwierdzeniu zapisu wszyscy czytający widzą go natychmiast; zwykle wymaga koordynacji między węzłami.
Spójność ostateczna oznacza, że repliki mogą chwilowo się różnić, ale z czasem się zbiegną. Sprawdza się dla feedów, liczników i scenariuszy, gdzie krótka nieścisłość jest akceptowalna.
Konflikt powstaje, gdy różne repliki zaakceptują równoległe aktualizacje. Typowe strategie to:
Wybór zależy od tego, czy utrata pośrednich aktualizacji jest dopuszczalna dla danego typu danych.
Krótki przewodnik dopasowania:
Wybieraj na podstawie dominujących wzorców dostępu, nie tylko popularności rozwiązań.
Zacznij od wymagań i zweryfikuj je testami:
W praktyce wiele systemów to hybryda: SQL dla „źródła prawdy” (płatności, zapasy), NoSQL dla danych o dużym natężeniu (feed, sesje, profile).