Czym jest sharding (a czym nie jest)
Sharding (nazywany też partycjonowaniem horyzontalnym) polega na tym, że aplikacji wygląda jakby miała jedną bazę danych, ale dane są rozdzielone na wiele maszyn, zwanych shardami. Każdy shard przechowuje tylko podzbiór wierszy, ale razem oddają pełny zestaw danych.
Jedna tabela logiczna, wiele miejsc fizycznych
Przydatny model myślowy to rozróżnienie między strukturą logiczną a umiejscowieniem fizycznym.
- Logika: wciąż masz jedną tabelę „Users” (te same kolumny, to samo znaczenie).
- Fizycznie: wiersze tej tabeli są przechowywane w różnych miejscach — na przykład użytkownicy z ID 1–1 000 000 są na shardzie A, a kolejny milion na shardzie B.
Z punktu widzenia aplikacji chcesz uruchamiać zapytania tak, jakby to była jedna tabela. Pod spodem system musi jednak zdecydować, z którym(i) shardem się porozumieć.
To nie jest replikacja ani „kup większą maszynę”
Sharding różni się od replikacji. Replikacja tworzy kopie tych samych danych na wielu węzłach, głównie dla dostępności i skalowania odczytów. Sharding dzieli dane tak, że każdy węzeł ma inne rekordy.
Różni się też od skalowania wertykalnego, gdzie trzymasz jedną bazę, ale przenosisz ją na większą maszynę (więcej CPU/RAM/szybsze dyski). Skalowanie wertykalne może być prostsze, ale ma praktyczne limity i szybko staje się drogie.
Czego sharding nie naprawi automagicznie
Sharding zwiększa pojemność, ale nie sprawia, że baza jest „łatwa” ani że każde zapytanie będzie szybsze.
- JOIN-y mogą stać się kosztowne, jeśli powiązane wiersze są na różnych shardach.
- Transakcje obejmujące wiele shardów są trudniejsze; aktualizacje „wszystko albo nic” mogą wymagać koordynacji.
- Złożoność operacyjna rośnie: trasowanie, rebalansowanie, debugowanie i obsługa awarii stają się częścią systemu.
Dlatego sharding najlepiej rozumieć jako sposób na skalowanie przechowywania i przepustowości — nie jako darmową poprawkę do wszystkich aspektów działania bazy danych.
Dlaczego zespoły shardują: problemy, które to rozwiązuje
Sharding rzadko bywa pierwszym wyborem. Zespoły sięgają po niego zwykle po tym, jak działający system napotyka fizyczne limity — albo gdy ból operacyjny staje się zbyt częsty, by go ignorować. Motywacja to rzadziej „chcemy shardować”, a częściej „musimy rosnąć bez jednej bazy będącej pojedynczym punktem awarii i kosztu”.
Bóle, które popychają ku shardingowi
Pojedynczy węzeł bazy może skończyć miejsce na kilka sposobów:
- Limity przestrzeni: tabele i indeksy rosną, dysk robi się ciasny, backupy zwalniają, operacje konserwacyjne stają się ryzykowne.
- Limity zapisu: CPU, WAL/redo lub kontencja zamków ograniczają liczbę zapisów na sekundę.
- Limity odczytu: nawet z cache i replikami, niektóre obciążenia przytłaczają primary (albo repliki stają się kosztowne do skalowania).
- Noisy neighbors: jeden tenant, klient lub wzorzec obciążenia monopolizuje zasoby i degraduje innych.
Gdy te problemy pojawiają się regularnie, często nie chodzi o jedno złe zapytanie, lecz o to, że jedna maszyna dźwiga zbyt wiele odpowiedzialności.
Cele: skalować poziomo, izolować i kontrolować koszty
Sharding bazy danych rozprowadza dane i ruch po wielu węzłach, więc pojemność rośnie przez dodawanie maszyn zamiast ulepszania jednej. Przy dobrym wdrożeniu może też izolować obciążenia (żeby spike jednego tenant’a nie psuł latencji innym) i kontrolować koszty przez unikanie coraz droższych instancji premium.
Wczesne sygnały, że zbliżasz się do sufitu
Powtarzające się wzorce to rosnące p95/p99 w szczycie, dłuższe opóźnienie replikacji, backupy/przywracanie przekraczające dopuszczalny czas oraz „małe” zmiany schematu stające się dużymi wydarzeniami.
Dlaczego sharding zwykle jest ostatnim krokiem
Zanim się zaangażujesz, zespoły zwykle wyczerpują prostsze opcje: indeksowanie i naprawy zapytań, cachowanie, repliki do odczytów, partycjonowanie w obrębie jednej bazy, archiwizację starych danych i upgrade sprzętu. Sharding może rozwiązać skalę, ale dodaje koordynację, złożoność operacyjną i nowe tryby awarii — więc próg wejścia powinien być wysoki.
Sharded database to nie pojedyncza rzecz — to mały system współpracujących części. Powodem, dla którego sharding może wydawać się „trudny do rozgryzienia”, jest to, że poprawność i wydajność zależą od interakcji tych elementów, a nie tylko od silnika bazy.
Shardy: niezależne partycje (z własnymi indeksami)
Shard to podzbiór danych, zwykle na własnym serwerze lub klastrze. Każdy shard zazwyczaj ma:
- storage (pliki danych)
- indeksy (by zapytania były szybkie w obrębie shardu)
- lokalne limity (CPU, pamięć, dysk, połączenia)
Z punktu widzenia aplikacji, sharded setup często stara się wyglądać jak jedna logiczna baza. Jednak zapytanie, które byłoby „jednym odwołaniem do indeksu” na pojedynczej maszynie, może zmienić się w „znajdź właściwy shard, a potem wykonaj odwołanie”.
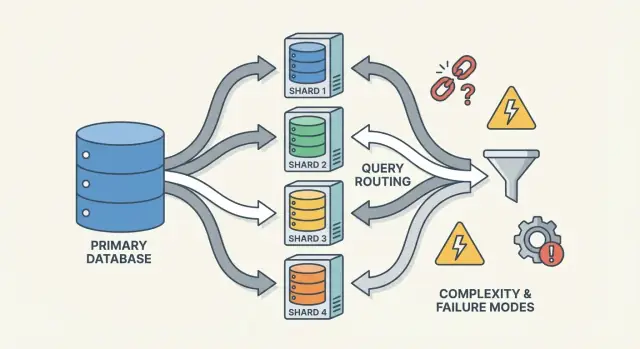
Routery/koordynatory: jak ruch trafia do właściwego shardu
Router (czasem koordynator, query router albo proxy) jest policjantem ruchu. Odpowiada na praktyczne pytanie: dla tego żądania, który shard powinien się nim zająć?
Są dwa typowe wzorce:
- Trasowanie po stronie klienta: biblioteka aplikacji zna mapę shardów i łączy się bezpośrednio z właściwym shardem.
- Trasowanie przez proxy: aplikacja łączy się z usługą routera, która przekazuje żądanie dalej.
Routery zmniejszają złożoność w aplikacji, ale mogą też stać się wąskim gardłem lub nowym punktem awarii, jeśli nie są zaprojektowane starannie.
Sharding opiera się na metadatach — źródle prawdy opisującym:
- mapę shardów (który shard „własni” które zakresy/buckety/ID)
- własność (szczególnie podczas migracji, gdy własność może chwilowo się pokrywać)
- stan i członkostwo (które węzły są online, role primary/replica, stan drain)
Ta informacja często żyje w serwisie konfiguracyjnym (lub małej bazie control plane). Jeśli metadata jest przestarzała lub niespójna, routery mogą wysyłać ruch we właściwe miejsce — nawet jeśli wszystkie shardy są zdrowe.
Zadania tła: balansowanie, migracje i backupy
Na koniec, sharding zależy od procesów tła, które utrzymują system w używalnym stanie:
- rebalansowanie danych, gdy jeden shard rośnie szybciej niż inne
- migracje przy zmianie własności między shardami
- procedury backup/restore, które działają przez wiele shardów i odpowiadają twoim celom przywracania
Te zadania łatwo zignorować na początku, ale to właśnie tam pojawia się wiele niespodzianek produkcyjnych — bo zmieniają kształt systemu, gdy wciąż obsługuje ruch.
Wybór klucza shardu: pierwszy istotny kompromis
Klucz shardu to pole (lub kombinacja pól), którego system używa, by zdecydować, który shard ma przechowywać wiersz/dokument. Ta pojedyncza decyzja w cichy sposób determinuje wydajność, koszty, a nawet które funkcje będą „proste” później — bo kontroluje, czy żądania można trasować do jednego shardu, czy muszą się rozlać na wiele.
Co czyni klucz shardu „dobrym”
Dobry klucz ma zwykle:
- Wysoką kardynalność: dużo możliwych wartości (np.
user_id zamiast kraju).
- Równomierny rozkład: wartości rozkładają zapisy i odczyty po shardach zamiast kumulować je na jednym.
- Stabilne wzorce dostępu: pasuje do tego, jak najczęściej zapytujesz dane dziś i jak spodziewasz się je zapytywać za kwartał.
Powszechny przykład to shardowanie po tenant_id w aplikacji multi-tenant: większość odczytów i zapisów dla tenant’a trafia na jeden shard, a tenant’y są wystarczająco liczne, by rozłożyć obciążenie.
Co czyni klucz shardu „złym” (i dlaczego to boli)
Niektóre klucze niemal gwarantują problemy:
- Monotoniczne klucze związane z czasem (timestampy, autoinkrementy): nowe dane skupiają się na „ostatnim” shardzie, tworząc hotspot zapisu.
- Pola o niskiej kardynalności (status, plan_tier, kraj): zbyt mało wartości powoduje, że kilka shardów wykonuje większość pracy.
- Zmienialne identyfikatory (email, edytowane nazwy użytkownika): jeśli klucz się zmienia, przeniesienie danych między shardami jest kosztowne i ryzykowne.
Nawet jeśli klucz o niskiej kardynalności jest wygodny do filtrowania, często zmienia rutynowe zapytania w scatter-gather — bo pasujące wiersze są porozrzucane.
Rzeczywisty kompromis: wygoda zapytań kontra jakość dystrybucji
Najlepszy klucz dla równoważenia obciążenia nie zawsze jest najlepszy dla zapytań produktowych.
- Wybierz klucz dopasowany do głównego wzorca dostępu (np.
user_id), a niektóre „globalne” zapytania (np. raporty administracyjne) staną się wolniejsze lub będą wymagać oddzielnych pipeline’ów.
- Wybierz klucz dopasowany do raportowania (np.
region), i ryzykujesz hotspoty i nierówną pojemność.
Większość zespołów projektuje wokół tego kompromisu: optymalizują klucz shardu pod najczęstsze, wrażliwe na opóźnienia operacje — a resztę obsługują indeksami, denormalizacją, replikami lub dedykowanymi tabelami analitycznymi.
Popularne strategie shardowania (range, hash, directory)
Nie ma jednej „najlepszej” metody shardowania. Strategia wpływa na to, jak łatwo trasować zapytania, jak równomiernie rozkłada się dane i jakie wzorce dostępu będą problematyczne.
Range sharding
W range sharding każdy shard posiada spójny wycinek przestrzeni klucza — np.:
- Shard A: customer_id 1–1 000 000
- Shard B: customer_id 1 000 001–2 000 000
Trasowanie jest proste: spojrzyj na klucz, wybierz shard.
Minus to hotspoty. Jeśli nowi użytkownicy zawsze dostają rosnące ID, „ostatni” shard staje się wąskim gardłem zapisów. Range sharding jest też wrażliwy na nierównomierny wzrost (jeden zakres staje się popularny, inny cichy). Zaletą jest to, że zapytania zakresowe („wszystkie zamówienia od 1–31 października”) mogą być wydajne, bo dane są fizycznie pogrupowane.
Hash sharding
Hash sharding przepuszcza klucz shardu przez funkcję hashującą i używa wyniku do wybrania shardu. Zwykle rozkłada dane bardziej równomiernie, co pomaga uniknąć problemu „wszystko idzie do najnowszego sharda”.
Koszt: zapytania zakresowe stają się kłopotliwe. Zapytanie typu „klienci z ID między X i Y” już nie mapuje się na mały zestaw shardów; może dotykać wielu.
Praktyczny detal, który zespoły często lekceważą, to consistent hashing. Zamiast mapować bezpośrednio na liczbę shardów (co przetasowuje wszystko przy dodaniu shardu), wiele systemów używa pierścienia hashującego z „wirtualnymi węzłami”, więc dodanie pojemności przesuwa tylko część kluczy.
Directory (lookup) sharding
Directory sharding przechowuje jawne mapowanie (tabelę/serwis lookup) z klucza → lokalizacja shardu. To najbardziej elastyczne: możesz przypisać konkretnych tenantów do dedykowanych shardów, przenosić jednego klienta bez przesuwania wszystkich i wspierać nierówne rozmiary shardów.
Minus to dodatkowa zależność. Jeśli katalog jest wolny, przestarzały lub niedostępny, trasowanie cierpi — nawet gdy shardy są zdrowe.
Klucze złożone i sub-sharding
Rzeczywiste systemy często łączą podejścia. Złożony klucz shardu (np. tenant_id + user_id) izoluje tenantów i jednocześnie rozkłada obciążenie wewnątrz tenant’a. Sub-sharding jest podobny: najpierw trasujesz po tenant, potem hashujesz wewnątrz grupy shardów tenant’a, by uniknąć dominacji jednego „dużego klienta”.
Jak działają zapytania: trasowanie kontra scatter-gather
Modeluj shardy dla multi-tenant
Zbuduj małą aplikację multi-tenant i zobacz, jak shardowanie po `tenant_id` zmienia zapytania.
Sharded baza ma dwie bardzo różne „ścieżki zapytań”. Zrozumienie, na której ścieżce jesteś, wyjaśnia większość niespodzianek wydajnościowych — i dlaczego sharding może wydawać się nieprzewidywalny.
Zapytania jednoshardowe: szybka ścieżka
Idealnie zapytanie trafia na dokładnie jeden shard. Jeśli żądanie zawiera klucz shardu (lub coś, co router może zamapować), system wysyła je bezpośrednio tam.
Dlatego zespoły zabiegają, aby typowe odczyty były „świadome klucza shardu”. Jeden shard oznacza mniej połączeń sieciowych, prostsze wykonanie, mniej blokad i znacznie mniej koordynacji. Latencja to głównie czas wykonania bazy, a nie kłótnie klastra o to, kto ma wykonać pracę.
Odczyty scatter-gather: fan-out i ogony opóźnień
Gdy zapytanie nie może być precyzyjnie trasowane (np. filtr na polu niebędącym kluczem shardu), system może rozesłać je do wielu lub wszystkich shardów. Każdy shard uruchamia zapytanie lokalnie, a router (lub koordynator) scala rezultaty — sortując, deduplikując, stosując limity i łącząc częściowe agregaty.
Ten fan-out potęguje tail latency: nawet jeśli 9 shardów odpowie szybko, jeden wolny shard może trzymać całe żądanie jako zakładnika. To też mnoży obciążenie: jedno żądanie użytkownika staje się N zapytań do shardów.
Joiny i agregacje między shardami
Joiny między shardami są kosztowne, bo dane, które kiedyś łączyły się „wewnątrz” bazy, muszą teraz przemieszczać się między shardami (lub do koordynatora). Nawet proste agregacje (COUNT, SUM, GROUP BY) mogą wymagać planu dwufazowego: oblicz częściowe wyniki na każdym shardzie, potem je scal.
Ograniczenia indeksowania: lokalne kontra globalne
Większość systemów domyślnie używa lokalnych indeksów: każdy shard indeksuje tylko swoje dane. Są tanie w utrzymaniu, ale nie pomagają w trasowaniu — więc zapytania mogą nadal rozsyłać się szeroko.
Globalne indeksy umożliwiają celowane trasowanie po polach niebędących kluczem shardu, ale dodają narzut przy zapisie, dodatkową koordynację i własne problemy skalowania oraz spójności.
Zapisy i transakcje między shardami
To przy zapisach sharding przestaje wyglądać jak „tylko skalowanie” i zaczyna zmieniać projekt funkcji. Zapis dotykający jednego shardu może być szybki i prosty. Zapis obejmujący wiele shardów może być wolny, podatny na błędy i zaskakująco trudny do poprawnego wdrożenia.
Zapisy jednoshardowe: ścieżka szczęśliwa
Jeśli każde żądanie da się trasować do dokładnie jednego shardu (zwykle przez klucz shardu), baza może użyć swojej normalnej maszyny transakcyjnej. Masz atomowość i izolację w obrębie shardu — większość problemów operacyjnych wygląda wtedy jak znane, pojedyncze-węzłowe przypadki, po prostu powtórzone N razy.
Zapisy wieloshardowe: tu rośnie złożoność
Gdy trzeba zaktualizować dane na dwóch shardach w jednym „logicznym akcie” (np. transfer pieniędzy, przeniesienie zamówienia między klientami, aktualizacja agregatu gdzie indziej), wkraczasz w obszar transakcji rozproszonych.
Transakcje rozproszone są trudne, bo wymagają koordynacji między maszynami, które mogą być wolne, przecięte siecią lub restartowane. Protokóły stylu two‑phase commit dodają rundy komunikacyjne, mogą blokować się na timeoutach i czynią awarie niejednoznacznymi: czy shard B zastosował zmianę zanim zginął koordynator? Jeśli klient ponowi, czy zastosujemy drugi raz? Jeśli nie powtórzymy, czy dane przepadły?
Wzorce unikające zapisów między shardami
Kilka popularnych taktyk zmniejsza potrzebę transakcji wieloshardowych:
- Lokalność danych: współlokuj powiązane rekordy na tym samym shardzie (np. wszystko dla klienta).
- Trasowanie żądań: upewnij się, że operacja jest „własnością” jednego shardu i traktuj inne jako dane tylko do odczytu.
- Denormalizacja: duplikuj małe fragmenty danych, aby aktualizacje nie musiały się rozgłaszać.
Idempotencja i bezpieczeństwo powtórek
W systemach sharded ponawiania są nieuniknione. Spraw, by zapisy były idempotentne przez użycie stabilnych ID operacji (np. idempotency key) i przechowywanie znaczników „już zastosowano” w bazie. Dzięki temu, jeśli wystąpi timeout i klient ponowi, druga próba będzie no-op zamiast podwójnego pobrania, zdublowanego zamówienia czy niespójnego licznika.
Spójność i replikacja: jak utrzymać dane poprawne
Zasługuj na kredyty za treści
Zarabiaj kredyty, dzieląc się wnioskami z budowania na Koder.ai.
Sharding dzieli dane między maszyny, ale nie znosi potrzeby redundancji. Replikacja utrzymuje shard dostępny po awarii węzła — i jednocześnie komplikuje odpowiedź na pytanie „co jest teraz prawdą?”.
Replikacja wewnątrz każdego sharda
Większość systemów replikuje wewnątrz shardu: jeden primary (leader) przyjmuje zapisy, a jedna lub więcej replik kopiuje zmiany. Jeśli primary padnie, system promuje replikę (failover). Repliki mogą też obsługiwać odczyty, by zmniejszyć obciążenie.
Koszt to czas. Replica może być kilka milisekund — albo sekund — za leaderem. Ta różnica jest normalna, ale ma znaczenie, gdy użytkownicy oczekują „właśnie to zaktualizowałem, więc powinienem to widzieć”.
Modele spójności w prostych słowach
- Silna spójność: po zakończeniu zapisu, odczyty go odzwierciedlą (z punktu widzenia gwarancji systemu). Zwykle wymaga czytania z leadera lub czekania na potwierdzenie replik.
- Spójność eventualna: system zbiegnie się do stanu, ale odczyt może tymczasowo zwrócić starsze dane.
W sharded konfiguracjach często masz silną spójność w obrębie shardu i słabsze gwarancje między shardami, szczególnie przy operacjach wieloshardowych.
„Pojedyncze źródło prawdy”, gdy dane są podzielone
W sharding zwykle „pojedyncze źródło prawdy” oznacza: dla każdego fragmentu danych istnieje jedno autorytatywne miejsce zapisu (zwykle leader shardu). Globalnie jednak nie ma jednej maszyny, która natychmiast potwierdziłaby najnowszy stan wszystkiego. Masz wiele lokalnych prawd, które trzeba synchronizować przez replikację.
Globalne ograniczenia: unikalność, klucze obce, liczniki
Ograniczenia stają się trudne, gdy dane do sprawdzenia leżą na różnych shardach:
- Unikalność (np. username): wymuszenie „brak duplikatów nigdzie” może wymagać scentralizowanego indeksu, dedykowanego „sharda ograniczeń” lub workflow rezerwacji na poziomie aplikacji.
- Klucze obce: jeśli wiersze parent i child są na różnych shardach, baza nie może łatwo wymusić referencyjnej integralności bez koordynacji między shardami.
- Liczniki (globalne sumy, sekwencyjne ID): proste podejścia tworzą wąskie gardło. Typowe rozwiązania to zakresy per-shard, batchowanie lub akceptacja przybliżonych zliczeń.
Te wybory nie są drobnymi detalami implementacyjnymi — definiują, co „poprawne” znaczy dla twojego produktu.
Rebalansowanie i resharding bez przestojów
Rebalansowanie utrzymuje sharded bazę użyteczną w miarę zmian. Dane rosną nierównomiernie, początkowo „zbalansowany” klucz może z czasem przemieścić się w stronę skosu, dodajesz nowe węzły, lub trzeba wycofać sprzęt. Każde z tych może przemienić shard w wąskie gardło — nawet jeśli projekt początkowy wydawał się idealny.
Dlaczego to trudne
W przeciwieństwie do pojedynczej bazy, sharding „wpisuje” lokację danych w logikę trasowania. Gdy przenosisz dane, nie kopiujesz tylko bajtów — zmieniasz miejsce, do którego muszą trafiać zapytania. To znaczy, że rebalansowanie to tak samo temat metadanych i klientów, jak i storage.
Wzorzec migracji online (kopiuj → overlap → cutover)
Większość zespołów dąży do workflow online, unikając dużego „stop the world”:
- Kopiuj: backfilluj docelowe shardy z shardu źródłowego, gdy system działa.
- Dual-write (czasem dual-read): podczas przejścia zapisy kierowane są do starej i nowej lokalizacji. Odczyty mogą sprawdzać obie (lub stosować regułę "nowe wygrywa") aż do pewności.
- Cutover: zaktualizuj mapę shardów tak, aby routery/klienci wysyłali ruch do nowego miejsca.
- Cleanup: zatrzymaj dual-writes, usuń starą kopię i odzyskaj/przekompresuj przestrzeń.
Mapy shardów i zachowanie klientów
Zmiana mapy shardów jest wydarzeniem łamiącym, jeśli klienci cachują decyzje trasowania. Dobre systemy traktują metadata trasowania jak konfigurację: wersjonuj ją, odświeżaj często i bądź explicite co robić, gdy klient natrafi na przeniesiony klucz (redirect, retry lub proxy).
Ryzyka operacyjne do zaplanowania
Rebalansowanie często powoduje tymczasowe spadki wydajności (dodatkowe zapisy, zaburzenia cache, obciążenie kopiami w tle). Częste są częściowe przeniesienia — niektóre zakresy migracji odbywają się wcześniej — więc potrzebujesz obserwowalności i planu rollback (np. przywrócenie mapy i drenowanie dual-writes) przed startem cutoveru.
Hotspoty i skosy: kiedy „równy podział” zawodzi
Sharding zakłada, że praca rozłoży się równomiernie. Zaskoczenie polega na tym, że klaster może wyglądać „równy” na papierze (ta sama liczba wierszy na shard), a w produkcji zachowywać się skrajnie nierównomiernie.
Gorące partycje (hot keys)
Hotspot występuje, gdy mały wycinek przestrzeni klucza przyciąga większość ruchu — pomyśl konto znanej osoby, popularny produkt, tenant odpalający ciężkie zadanie wsadowe lub klucz oparty na czasie, gdzie „dzisiaj” przyciąga wszystkie zapisy. Jeśli te klucze mapują do jednego shardu, on staje się wąskim gardłem, nawet gdy inne shardy są bezczynne.
Skew: rozmiar danych kontra ruch
„Skew” to nie jedna rzecz:
- Skew danych: jeden shard ma więcej bajtów/wierszy (presja storage, dłuższe backupy, wolniejsze skany).
- Skew ruchu: jeden shard obsługuje więcej QPS lub cięższe zapytania (saturacja CPU, kolejkowanie, skoki latencji).
Nie zawsze idą w parze. Shard z mniejszą ilością danych może być najgorętszy, jeśli posiada najczęściej żądane klucze.
Jak szybko to wykryć
Nie potrzebujesz zaawansowanego trace’owania, by zauważyć skew. Zacznij od dashboardów per-shard:
- p95 latencja per shard (jeśli p95 jednego shardu odjeżdża, to czerwone lampki)
- QPS (i write QPS) per shard
- Użycie storage / rozmiar tabeli per shard
Jeśli latencja jednego shardu rośnie wraz z jego QPS, a inne stoją w miejscu, prawdopodobnie masz hotspot.
Środki zaradcze
Naprawy zwykle wymieniają prostotę na równowagę:
- Wybierz klucz shardu, który rozprowadza ruch, nie tylko rekordy.
- Dodaj bucketing/salting dla gorących kluczy (podziel jeden logiczny klucz na wiele bucketów fizycznych).
- Użyj cachowania dla gorących, często czytanych obiektów.
- Stosuj rate limiting lub kwoty per-tenant, by chronić klaster.
- Podziel gorące shardy (lub przenieś gorące zakresy), gdy jeden shard nie chłodzi się wystarczająco.
Tryby awarii i debugowanie w systemie sharded
Współpracuj nad projektem
Zapraszaj zespół, aby wspólnie recenzować plan, testować zmiany i szybko cofać.
Sharding nie tylko dodaje więcej serwerów — dodaje więcej sposobów, w jakie coś może pójść nie tak, i więcej miejsc do sprawdzania, gdy się to dzieje. Wiele incydentów to nie „baza padła”, lecz „jeden shard jest niedostępny” albo „system nie może się zgodzić, gdzie są dane”.
Typowe tryby awarii
Kilka wzorców pojawia się często:
- Shard niedostępny (crash, brak miejsca na dysku, długie pauzy GC), powodując częściowe przerwy: niektórzy klienci działają, inni zawodzą.
- Router źle trasuje ruch, często po zmianie konfiguracji lub złym deployu. Odczyty mogą cicho zwracać puste wyniki, jeśli trafią na nieodpowiedni shard.
- Przestarzała lub niespójna metadata (np. mapa shardów, tabela katalogowa). Podczas przenosin różne komponenty mogą inaczej kierować ten sam klucz.
- Częściowe problemy sieciowe: timouty między routerami a podzbiorem shardów mogą wyglądać jak „losowe” błędy i uruchamiać ponowienia, które potęgują obciążenie.
Jak debugowanie się zmienia
W pojedynczej bazie ogarniasz jeden log i zestaw metriców. W systemie sharded potrzebujesz obserwowalności, która podąża za żądaniem przez shardy.
Używaj correlation IDs w każdym żądaniu i propaguj je od warstwy API przez routery do każdego shardu. Sparuj to z distributed tracing, aby zapytanie scatter-gather pokazało, który shard był wolny lub zawiódł. Metryki powinny być łamane per shard (latencja, głębokość kolejek, wskaźnik błędów), bo inaczej gorący shard ukryje się w średniej z floty.
Incydenty związane z poprawnością danych
Błędy shardingowe często objawiają się jako bugi poprawności:
- Duplikaty po ponowieniach lub nie-idempotentnych zapisach.
- Brakujące wiersze gdy migracja przeniosła dane, ale routing dalej wskazuje stare miejsce.
- Split-brain writes jeśli dwie widoki metadata akceptują zapisy dla tego samego zakresu kluczy.
Backup, restore i odzyskiwanie po katastrofie
„Przywróć bazę” staje się „przywróć wiele części we właściwej kolejności”. Może być konieczne przywrócenie najpierw metadata, potem każdego sharda i weryfikacja, że granice shardów i reguły trasowania odpowiadają przywróconemu punktowi czasowemu. Plany DR powinny zawierać ćwiczenia, które udowodnią, że potrafisz zmontować spójny klaster — nie tylko odzyskać pojedyncze maszyny.
Kiedy nie shardować: praktyczne alternatywy i checklist decyzyjny
Sharding często traktuje się jak „przełącznik skalowania”, ale to też trwałe zwiększenie złożoności systemu. Jeśli możesz spełnić cele wydajnościowe i niezawodności bez dzielenia danych między węzłami, zwykle uzyskasz prostszą architekturę, łatwiejsze debugowanie i mniej krawędziowych przypadków operacyjnych.
Praktyczne alternatywy, które często dają dużo zapasu
Zanim zdecydujesz się na sharding, spróbuj opcji, które zachowują jedną logiczną bazę:
- Lepsze indeksy + tuning zapytań: najpierw napraw wolne ścieżki — brakujące indeksy, nieskończone zapytania, kosztowne joiny i pattern N+1.
- Caching: umieść odczyty o dużej liczbie i stabilne odpowiedzi za cache (cache w aplikacji, CDN dla treści publicznych lub in‑memory cache dla gorących kluczy).
- Repliki do odczytów: odciąż odczyty bez zmiany ścieżki zapisu (i zaakceptuj lag replik tam, gdzie to OK).
- Partycjonowanie tabel na jednym węźle: wiele baz wspiera partycjonowanie tabel, które poprawia konserwację i wydajność zapytań bez trasowania między węzłami.
Gdzie narzędzia pomagają: prototypowanie świadomych shardów usług
Praktyczny sposób zmniejszenia ryzyka to prototypowanie okablowania (granice trasowania, idempotencja, workflow migracji i obserwowalność) przed zadeklarowaniem produkcyjnej bazy.
Na przykład, z Koder.ai możesz szybko uruchomić małą realistyczną usługę z chatu — często Reactowe UI admina plus backend w Go z PostgreSQL — i eksperymentować z API świadomymi klucza shardu, kluczami idempotencji i zachowaniami cutover w bezpiecznym sandboxie. Ponieważ Koder.ai wspiera tryb planowania, snapshoty/rollback i eksport kodu źródłowego, możesz iterować nad decyzjami dot. shardowania (trasowanie i kształt metadata) i przenieść powstały kod oraz runbooki do głównego stosu, gdy będziesz pewny.