13 lip 2025·8 min
Jak frameworki backendowe kształtują organizację kodu i nawyki zespołu
Dowiedz się, jak frameworki backendowe wpływają na strukturę folderów, granice odpowiedzialności, testowanie i workflow zespołu — żeby zespoły mogły szybciej dostarczać spójny i łatwy w utrzymaniu kod.
Dlaczego frameworki backendowe mają znaczenie poza „wyborem stosu”
Framework backendowy to więcej niż zestaw bibliotek. Biblioteki pomagają wykonać konkretne zadania (routing, walidacja, ORM, logowanie). Framework dodaje opiniotwórczy "sposób pracy": domyślną strukturę projektu, wspólne wzorce, wbudowane narzędzia i zasady dotyczące tego, jak elementy się łączą.
Frameworki kształtują codzienne decyzje
Gdy framework zostanie wprowadzony, zaczyna kierować setkami drobnych wyborów:
- Gdzie trafia nowy kod (features, moduły, serwisy)
- Jak żądania przepływają przez aplikację (kontrolery, middleware, handlery)
- Jak obsługujesz przekrojowe zagadnienia jak auth, walidacja i błędy
- Jak zespoły nazywają rzeczy, piszą testy i przeglądają pull requesty
To dlatego dwa zespoły budujące „to samo API” mogą mieć bardzo różne codebase’y — nawet używając tego samego języka i bazy danych. Konwencje frameworka stają się domyślną odpowiedzią na pytanie „jak to tu robimy?”.
Szybkość i spójność vs elastyczność
Frameworki często wymieniają elastyczność na przewidywalną strukturę. Plusy to szybsze onboarding, mniej debat i powtarzalne wzorce redukujące przypadkową złożoność. Minusem bywa to, że konwencje frameworka mogą wydawać się ograniczające, gdy produkt potrzebuje niestandardowych przepływów, strojenia wydajności lub nietypowej architektury.
Dobrą decyzją nie jest "framework albo nie", lecz ile konwencji chcesz — i czy zespół jest gotów płacić koszt dostosowań w czasie.
Kogo to dotyczy
- Inżynierowie: mniej czasu na reinventowanie wzorców, więcej na dostarczanie funkcji
- Tech leady: jaśniejsze standardy dla architektury, testów i przeglądów kodu
- Zespoły produktowe: przewidywalniejsze dostarczanie i mniej regresji jakości w miarę rozwoju bazy kodu
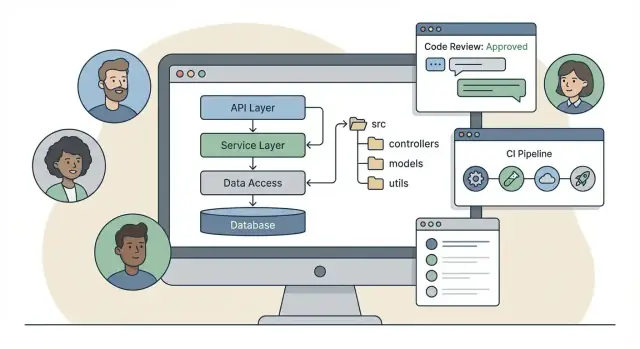
Domyślne ustawienia frameworka, które definiują strukturę projektu
Większość zespołów nie zaczyna od pustego folderu — zaczynają od "zalecanej" struktury frameworka. Te domyślne ustawienia decydują, gdzie ludzie umieszczają kod, jak nazywają rzeczy i co wydaje się "normalne" w przeglądach.
Dwa powszechne podejścia domyślne
Niektóre frameworki promują klasyczną strukturę warstwową: controllers / services / models. Łatwo się uczyć i ładnie odwzorowuje obsługę żądań:
/src
/controllers
/services
/models
/repositories
Inne frameworki skłaniają się ku modułom funkcjonalnym: grupowanie wszystkiego dla jednej funkcji razem (handlery HTTP, reguły domenowe, persistence). To sprzyja lokalnemu rozumieniu — gdy pracujesz nad „Billing”, otwierasz jeden folder:
/src
/modules
/billing
/http
/domain
/data
Żadne z tych rozwiązań nie jest automatycznie lepsze, ale oba kształtują nawyki. Struktury warstwowe ułatwiają centralizację zachowań przekrojowych (logowanie, walidacja, obsługa błędów). Podejście modułowe może zmniejszyć "poziome przewijanie" po kodzie w miarę jego rozwoju.
Narzędzia do scaffoldingu tworzą długotrwałe wzorce
CLI generators (scaffold) są „lepkie”. Jeśli generator tworzy parę controller + service dla każdego endpointu, ludzie będą to powtarzać — nawet gdy prosta funkcja wystarczy. Jeśli generuje moduł z wyraźnymi granicami, zespoły chętniej będą je respektować pod presją terminów.
Ten sam mechanizm widać też w szybkich workflowach — jeśli domyślne ustawienia platformy dają przewidywalny układ i jasne przegrody modułów, zespoły mają tendencję do utrzymywania spójności kodu w miarę jego rozrastania się. Na przykład Koder.ai generuje full-stackowe aplikacje z promptów czatu, a praktyczna korzyść (poza szybkością) polega na tym, że zespół może ustandaryzować struktury i wzorce wcześnie — a potem iterować nad nimi jak nad zwykłym kodem (w tym eksportować źródło, gdy chce mieć pełną kontrolę).
Unikanie „grubych kontrolerów”
Frameworki, które ustawiają kontrolery w centrum, kuszą do upychania reguł biznesowych w handlerach żądań. Przydatna zasada: kontrolery tłumaczą HTTP → wywołanie aplikacji, i nic poza tym. Umieść logikę biznesową w warstwie serwisu/use-case (lub warstwie domenowej modułu), aby była testowalna bez HTTP i możliwa do ponownego użycia przez zadania w tle lub CLI.
Szybka kontrola struktury
Jeśli nie potrafisz odpowiedzieć na pytanie „Gdzie znajduje się logika cenowa?” jednym zdaniem, domyślne ustawienia frameworka mogą walczyć z twoją domeną. Dostosuj wczesne — foldery łatwo zmienić; nawyki nie.
Przepływ żądania: routing, kontrolery i konwencje middleware
Framework backendowy to nie tylko zestaw bibliotek — definiuje, jak żądanie powinno podróżować przez twój kod. Gdy wszyscy stosują tę samą ścieżkę żądania, funkcje wdraża się szybciej, a przeglądy dotyczą bardziej poprawności niż stylu.
Routing: publiczna mapa twojego systemu
Trasy powinny czytać się jak spis treści API. Dobre frameworki zachęcają do tego, by trasy były:
- Deklaratywne (można szybko przeskanować i zrozumieć, co jest wystawione)
- Spójne (te same wzorce URL i HTTP verbs w całej bazie)
- Blisko brzegu (konfiguracja routingu nie powinna zawierać reguł biznesowych)
Praktyczna konwencja to trzymać pliki routingu skoncentrowane na mapowaniu: GET /orders/:id -> OrdersController.getById, a nie „jeśli użytkownik jest VIP, zrób X”.
Kontrolery/handlery: cienkie tłumacze żądań
Kontrolery sprawdzają się najlepiej jako tłumacze między HTTP a rdzeniem logiki:
- Odczytują dane wejściowe (params, headers, body)
- Wywołują serwis/use-case
- Zwracają odpowiedź
Gdy frameworki dostarczają pomocników do parsowania, walidacji i formatu odpowiedzi, zespoły łatwo ulegają pokusie dorzucenia logiki do kontrolerów. Zdrowszy wzorzec to „cienkie kontrolery, grube serwisy”: trzymaj kwestie request/response w kontrolerach, a decyzje biznesowe w oddzielnej warstwie, która nie zna HTTP.
Middleware/filtry: jedno miejsce na zachowania przekrojowe
Middleware (albo filtry/interceptory) decydują, gdzie zespoły umieszczają powtarzalne zachowania jak autoryzacja, logowanie, rate limiting czy identyfikatory żądań. Kluczowa konwencja: middleware powinno wzbogacać lub chronić żądanie, a nie implementować reguł produktowych.
Na przykład auth middleware może dołączać req.user, a kontrolery przekazywać tę tożsamość do rdzenia logiki. Middleware logujący może ustandaryzować, co jest logowane, bez potrzeby, żeby każdy kontroler wymyślał to od nowa.
Konwencje nazewnictwa, które redukują tarcia w przeglądach
Uzgodnij przewidywalne nazwy:
OrdersController,OrdersService,CreateOrder(use-case)authMiddleware,requestIdMiddlewarevalidateCreateOrder(schema/validator)
Gdy nazwy kodują zamiar, przeglądy koncentrują się na zachowaniu, nie na tym, gdzie coś „powinno być”.
Warstwy i granice: gdzie żyje logika biznesowa
Framework backendowy nie tylko pomaga wypuszczać endpointy — popycha zespół w stronę określonego „kształtu” kodu. Jeśli nie zdefiniujesz granic wcześnie, domyślną grawitacją jest: kontrolery wywołują ORM, ORM wywołuje bazę, a reguły biznesowe są porozrzucane.
Praktyczna architektura warstwowa
Prosty, trwały podział wygląda tak:
- Warstwa prezentacji: kwestie HTTP (routing, kontrolery, auth middleware). Konwertuje żądania na polecenia aplikacji i zwraca odpowiedzi.
- Warstwa aplikacji: use-case’y (np.
CreateInvoice,CancelSubscription). Orkiestruje pracę i transakcje, ale pozostaje mało uzależniona od frameworka. - Warstwa domeny: rdzeń reguł biznesowych i koncepcji (encje, polityki, serwisy domenowe). Powinna czytać się jak biznes, nie jak SQL.
- Warstwa danych: repozytoria, modele/mappery ORM, zapytania, migracje.
Frameworki, które generują „controllers + services + repositories” mogą być pomocne — jeśli traktujesz to jako kierunkowy przepływ, a nie wymóg, że każda funkcja potrzebuje każdej warstwy.
Jak ORM-y i repozytoria wpływają na granice
ORM kusi, żeby przekazywać modele bazy danych wszędzie, bo są wygodne i częściowo już walidowane. Repozytoria pomagają, dając węższy interfejs ("get customer by id", "save invoice"), dzięki czemu aplikacja i domena nie zależą od szczegółów ORM.
Aby uniknąć projektu, w którym „wszystko zależy od bazy danych":
- Nie zwracaj encji ORM bezpośrednio z kontrolerów.
- Trzymaj kształt zapytań w warstwie danych; trzymaj reguły w domenie.
- Preferuj wejścia/wyjścia przyjazne domenie dla use-case’ów.
Kiedy wprowadzić warstwę serwisów (a kiedy nie)
Dodaj warstwę serwisów/use-case, gdy logika jest ponownie używana przez różne endpointy, wymaga transakcji lub musi wymuszać reguły spójnie. Pomiń ją dla prostego CRUD, który rzeczywiście nie ma zachowań biznesowych — dodanie warstwy w takich miejscach może stworzyć ceremoniał bez jasności.
Wstrzykiwanie zależności i nawyki projektowania modułowego
Dependency Injection to jedno z tych domyślnych zachowań frameworka, które kształtuje cały zespół. Gdy DI jest wbudowane, przestajesz tworzyć instancje usług w losowych miejscach i zaczynasz traktować zależności jako coś, co deklarujesz, wiążesz i świadomie wymieniasz.
Co DI zachęca (i co może komplikować)
DI popycha zespoły w kierunku małych, skupionych komponentów: kontroler zależy od serwisu, serwis od repozytorium, każdy fragment ma jasną rolę. To poprawia testowalność i ułatwia zamianę implementacji (np. prawdziwy gateway płatności vs mock).
Minusem jest to, że DI może ukrywać złożoność. Jeśli każda klasa zależy od pięciu innych klas, trudniej zrozumieć, co faktycznie uruchamia się przy żądaniu. Źle skonfigurowane kontenery potrafią też powodować błędy, które wydają się daleko od miejsca, które edytowałeś.
Wstrzykiwanie przez konstruktor i projektowanie oparte na interfejsach
Większość frameworków promuje wstrzykiwanie przez konstruktor, bo jawnie pokazuje zależności i zapobiega wzorcowi "service locator".
Pomocnym nawykiem jest łączenie injection przez konstruktor z projektowaniem opartym na interfejsach: kod zależy od stabilnego kontraktu (np. EmailSender) zamiast konkretnego klienta dostawcy. To lokalizuje zmiany, gdy zmieniasz dostawcę lub refaktoryzujesz.
Spójne moduły bez zależności cyklicznych
DI działa najlepiej, gdy moduły są spójne: jeden moduł odpowiada za jedną funkcjonalność (orders, billing, auth) i wystawia mały publiczny surface.
Zależności cykliczne to częsty tryb awarii. Często oznaczają, że granice są niejasne — dwa moduły dzielą pojęcia, które zasługują na własny moduł, lub jeden moduł robi za dużo.
Uzgadnianie, gdzie odbywa się wiring
Zespoły powinny uzgodnić gdzie rejestruje się zależności: jeden punkt kompozycji (startup/bootstrap), plus wiring na poziomie modułu dla wewnętrznych zależności modułu.
Centralizacja wiringu ułatwia przeglądy kodu: reviewer może zauważyć nowe zależności, ocenić ich uzasadnienie i zapobiec „container sprawl”, który zamienia DI z narzędzia w zagadkę.
Kontrakty API: walidacja, błędy i kształty danych
Pozostań elastyczny później
Zyskaj pełny eksport kodu źródłowego, gdy chcesz pełnej kontroli nad refaktorami i upgrade'ami.
Framework wpływa na to, co na twoim zespole znaczy „dobre API”. Jeśli walidacja jest funkcją pierwszorzędną (dekoratory, schemy, pipes, guards), ludzie projektują endpointy wokół jasnych wejść i przewidywalnych wyjść — bo łatwiej zrobić dobrze niż pominąć to.
Walidacja kształtuje endpointy
Gdy walidacja jest na granicy (przed logiką biznesową), zespoły zaczynają traktować payloady żądań jak kontrakty, a nie „cokolwiek prześle klient”. To zwykle prowadzi do:\n
- Explicit required vs optional fields (mniej debat o „null oznacza nieznane”)\n
- Jasnych reguł formatów (daty, ID, enumy) i ograniczeń (min/max, długość)\n
- Wczesnego odrzucania złych żądań, dzięki czemu kod serwisów skupia się na regułach biznesowych
To także miejsce, gdzie frameworki zachęcają do wspólnych konwencji: gdzie definiuje się walidację, jak prezentować błędy i czy dopuszczać nieznane pola.
Centralizacja błędów tworzy spójne oczekiwania klientów
Frameworki, które wspierają globalne filtry/handlery wyjątków, umożliwiają spójność. Zamiast pozwalać każdemu kontrolerowi wymyślać własne odpowiedzi, możesz ustandaryzować:\n
- Kopertę błędu (np.
code,message,details,traceId)\n- Mapowanie statusów HTTP (walidacja → 400, auth → 401/403, not found → 404)\n- Logowanie i identyfikatory korelacyjne, by wsparcie mogło debugować pojedyncze żądanie
Spójny kształt błędu zmniejsza rozgałęzienia po stronie front-endu i ułatwia zaufanie do dokumentacji API.
DTO i view modele chronią twoje wnętrza
Wiele frameworków skłania do używania DTO (wejście) i view-modeli (wyjście). To dobre: zapobiega przypadkowemu ujawnieniu pól wewnętrznych, unika sprzężenia klientów ze schematem bazy i ułatwia bezpieczne refaktory. Praktyczna zasada: kontrolery mówią w DTO; serwisy mówią w modelach domenowych.
Versioning i podstawy kompatybilności wstecznej
Nawet małe API ewoluują. Konwencje routingu często decydują, czy wersjonowanie będzie w URL (/v1/...) czy w nagłówkach. Cokolwiek wybierzesz, ustal podstawy wcześnie: nigdy nie usuwaj pól bez okna deprecjacji, dodawaj pola w sposób kompatybilny wstecz i dokumentuj zmiany w jednym miejscu (np. /docs lub changelog).
Strategia testów wpływana przez narzędzia frameworka
Framework backendowy nie tylko pomaga wypuszczać funkcje; determinuje też, jak je testujesz. Wbudowany runner testów, narzędzia do bootstrappingu i kontener DI często określają, co jest łatwe — a to staje się tym, co zespół naprawdę robi.
Helpery frameworka: unit vs integration vs end-to-end
Wiele frameworków oferuje "test app" bootstrapper, który potrafi uruchomić kontener, zarejestrować trasy i wykonywać żądania w pamięci. To skłania zespoły ku testom integracyjnym, bo są tylko o kilka linijek więcej niż test jednostkowy.
Praktyczny podział wygląda tak:
- Unit tests dla czystej logiki biznesowej (bez bootowania frameworka i DB).
- Integration tests dla modułów/serwisów powiązanych przez kontener DI.
- End-to-end tests dla rzeczywistego zachowania HTTP (routing, middleware, auth, mapowanie błędów).
Piramida testów dopasowana do serwisów backendowych
Dla większości serwisów prędkość jest ważniejsza niż idealna „czystość piramidy”. Dobra zasada: dużo małych testów jednostkowych, skoncentrowany zestaw testów integracyjnych wokół granic (baza, kolejki), i cienka warstwa E2E potwierdzająca kontrakt.
Jeśli framework ułatwia symulację żądań, możesz nieco bardziej polegać na testach integracyjnych — jednocześnie izolując logikę domenową tak, by testy jednostkowe były stabilne.
Mockowanie zgodne z DI i runtime
Strategia mockowania powinna iść za tym, jak framework rozwiązuje zależności:\n
- Preferuj nadpisywanie bindingów DI (zamień realny klient email na fake) zamiast monkey-patchingu importów.\n
- Używaj adapterów in-memory tam, gdzie to możliwe (np. in-memory repositories), aby uniknąć kruchego mockowania.\n
- Mockuj na granicy modułu, nie wewnątrz logiki biznesowej, by refaktory nie łamały testów.
Szybkie, wiarygodne testy dla CI
Czas bootowania frameworka może zdominować CI. Utrzymuj testy szybkie przez cachowanie kosztownych setupów, uruchamianie migracji raz na suite i użycie paralelizacji tam, gdzie izolacja jest gwarantowana. Ułatw diagnozę błędów: spójne seedy, deterministyczne zegary i ścisłe cleanup hooks są lepsze niż „retry on fail”.
Skalowanie bazy kodu: moduły, paczki i współdzielony kod
Wbuduj operacyjność
Wbuduj od początku logowanie i operacyjne domyślne ustawienia, generując aplikację, którą można rozwijać.
Frameworki nie tylko pomagają wypuścić pierwsze API — kształtują też, jak kod rośnie, gdy „jeden serwis” zamienia się w dziesiątki funkcji, zespołów i integracji. Mechaniki modułów i pakietów, które framework ułatwia, zwykle stają się twoją długoterminową architekturą.
Wzorce modułowości, które zachęcają frameworki
Większość frameworków skłania ku modułowości przez konstrukcję: apps, plugins, blueprints, modules, feature folders lub packages. Gdy to jest domyślne, zespoły mają tendencję do dodawania nowych funkcji jako „jeszcze jeden moduł” zamiast rozsypywać pliki po całym projekcie.
Praktyczna reguła: traktuj każdy moduł jak mini-produkt z własnym publicznym surface (routes/handlers, interfejsy serwisów), prywatnymi internals i testami. Jeśli framework wspiera auto-discovery (np. skanowanie modułów), używaj tego ostrożnie — jawne importy często ułatwiają rozumienie zależności.
Moduły domeny podstawowej vs infrastruktury
W miarę rozrostu kodu mieszanie reguł biznesowych z adapterami staje się kosztowne. Użyteczny podział to:\n
- Core domain modules: reguły biznesowe, polityki, serwisy domenowe i modele domenowe (elementy, które powinny przetrwać zamianę bazy danych)\n- Infrastructure modules: klienci baz danych, modele ORM, brokerzy wiadomości, klienci HTTP, cache, providerzy auth
Konwencje frameworka wpływają na to: jeśli framework zachęca do „service classes”, umieść serwisy domenowe w modułach core, a wiring specyficzny dla frameworka (kontrolery, middleware, providery) trzymaj na krawędziach.
Wspólne biblioteki vs kopiuj-wklej: reguły decyzji
Zespoły często dzielą się kodem zbyt wcześnie. Preferuj kopiowanie małego kawałka kodu, dopóki nie jest stabilny, a potem ekstrakcję, gdy:\n
- dwie lub więcej drużyn utrzymuje tę samą logikę\n- poprawka błędu musi być zastosowana w wielu miejscach\n- możesz zdefiniować jasne API i wersjonować je
Jeśli wyciągasz, publikuj wewnętrzne pakiety (lub biblioteki w workspace) z jasnym właścicielstwem i dyscypliną changelogu.
Przygotowanie na modular monolith → microservices (później)
Modularny monolit jest często najlepszym „pośrednim” rozwiązaniem. Jeśli moduły mają jasne granice i minimalne cross-importy, możesz później wyodrębnić moduł do serwisu z mniejszymi kosztami. Projektuj moduły wokół zdolności biznesowych, nie technicznych warstw. Dla głębszej strategii, zobacz /blog/modular-monolith.
Konfiguracja, środowiska i gotowość operacyjna
Model konfiguracji frameworka wpływa na to, jak spójne (lub chaotyczne) będą twoje wdrożenia. Gdy konfiguracja jest porozrzucana pomiędzy plikami ad-hoc, zmiennymi środowiskowymi i „tylko to jedno ustawienie”, zespoły spędzają czas na debugowaniu różnic zamiast budowaniu funkcji.
Styl konfiguracji = spójność
Większość frameworków zachęca do jednego źródła prawdy: pliki konfiguracyjne, zmienne środowiskowe lub konfiguracja w kodzie (moduły/plugins). Cokolwiek wybierzesz, ustandaryzuj to wcześnie:
- Pliki działają dobrze dla lokalnego developmentu i jasnych domyślnych ustawień (np.
config/default.yml). - Zmienne środowiskowe są świetne do różnic w czasie wdrożenia i platform kontenerowych.
- Konfiguracja w kodzie może być potężna, ale łatwo ukryć ważne ustawienia za logiką.
Dobrą konwencją jest: domyślne wartości w wersjonowanych plikach konfiguracyjnych, zmienne środowiskowe nadpisują dla środowisk, oraz kod czyta z jednego typowanego obiektu konfiguracyjnego. To sprawia, że "gdzie zmienić wartość" jest oczywiste podczas incydentów.
Sekrety: traktuj je jako osobną kategorię
Frameworki często dostarczają helpery do czytania env varów, integracji z secret store lub walidacji konfiguracji przy starcie. Wykorzystaj te narzędzia, by utrudnić nieprawidłowe obchodzenie się z sekretami:
- Nigdy nie commituj sekretów do repo (włącznie z "tymczasowymi" kluczami).
- Trzymaj sekrety poza logami i stronami błędów.
- Preferuj runtime injection (CI/CD, orchestrator kontenerów lub manager sekretów) zamiast lokalnego roznoszenia
.env.
Na operacyjny nawyk: developers mogą uruchamiać lokalnie ze bezpiecznymi placeholderami, a prawdziwe poświadczenia istnieją tylko w środowiskach, które ich potrzebują.
Parzystość środowisk: dev, staging, production
Domyślne ustawienia frameworka mogą albo zachęcać do parzystości (ten sam proces startowy wszędzie), albo tworzyć specjalne przypadki ("production używa innego punktu wejścia serwera"). Dąż do tej samej komendy startowej i tego samego schematu konfiguracji we wszystkich środowiskach, zmieniając tylko wartości.
Staging traktuj jak próbę generalną: te same feature flagi, ta sama ścieżka migracji, te same background joby — tylko mniejsza skala.
Dokumentuj konfigurację jak API
Gdy konfiguracja nie jest dokumentowana, kolejni współpracownicy zgadują — a zgadywanie prowadzi do awarii. Trzymaj krótkie, utrzymywane odniesienie w repo (np. /docs/configuration) wymieniające:
- każdy klucz konfiguracji i co kontroluje
- oczekiwany typ/format (string, URL, integer)
- wartość domyślną i bezpieczne przykłady
- które środowiska powinny to ustawić
Wiele frameworków może walidować config przy starcie. Sparuj to z dokumentacją i zmniejszysz "u mnie działa" do rzadkiego wyjątku zamiast stałego problemu.
Standardy obserwowalności narzucone przez framework
Framework backendowy ustawia bazę tego, jak rozumiesz system w produkcji. Gdy obserwowalność jest wbudowana (lub silnie zalecana), zespoły przestają traktować logi i metryki jako "późniejszą" pracę i zaczynają projektować je jako element API.
Logowanie, śledzenie i metryki: co dostajesz „za darmo”
Wiele frameworków integruje się z narzędziami do strukturalnego logowania, rozproszonego śledzenia i zbierania metryk. Ta integracja wpływa na organizację kodu: masz tendencję do centralizowania zachowań przekrojowych (middleware logujące, interceptory śledzenia, kolektory metryk) zamiast rozsypywania printów po kontrolerach.
Dobre standardy to zdefiniowanie małego zestawu wymaganych pól logów, które każda linia logu związana z żądaniem powinna zawierać:
correlation_id(alborequest_id) do łączenia logów pomiędzy serwisamirouteimethoddo identyfikacji endpointuuser_idlubaccount_id(gdy dostępne) do analiz wsparciaduration_msistatus_codedla wydajności i niezawodności
Konwencje frameworka (jak obiekty kontekstu żądania czy pipeline middleware) ułatwiają generowanie i przekazywanie correlation ID konsekwentnie, więc developerzy nie wymyślają wzorca dla każdego feature.
Health checks i readiness endpoints
Domyślne ustawienia frameworka często decydują, czy health checks są priorytetem, czy późnym dodatkiem. Standardowe endpointy jak /health (liveness) i /ready (readiness) stają się częścią definicji "done" i wymuszają czystsze granice:
- liveness: "czy proces działa?"
- readiness: "czy może obsługiwać ruch?" (np. połączenie z DB, zastosowane migracje)
Gdy te endpointy są standardem wcześnie, wymagania operacyjne przestają przeciekać do losowego kodu funkcji.
Używanie obserwowalności do kierowania refaktoringiem
Dane z obserwowalności są też narzędziem decyzyjnym. Jeśli trace pokazuje, że konkretny endpoint spędza czas w tym samym zależniku, to sygnał do wyodrębnienia modułu, dodania cache'a lub przeprojektowania zapytania. Jeśli logi ujawniają niespójne kształty błędów — znak, że trzeba scentralizować obsługę błędów. Innymi słowy: hooki obserwowalności frameworka nie tylko pomagają debugować — pomagają reorganizować kod z przekonaniem.
Workflow zespołu: konwencje, narzędzia i przeglądy kodu
Ujednolicaj nawyki zespołu
Wyrównaj nawyki zespołowe: nazewnictwo, zasady folderów i praktyki przeglądu dzięki wspólnej bazie.
Framework backendowy nie tylko organizuje kod — ustala „reguły domu” dla pracy zespołu. Gdy wszyscy trzymają się tych samych konwencji (układ plików, nazewnictwo, sposób wiązania zależności), przeglądy są szybsze, a onboarding łatwiejszy.
Generowanie kodu i scaffolds: używaj ich, nie uwielbiaj
Narzędzia scaffoldingu mogą ustandaryzować nowe endpointy, moduły i testy w minutach. Pułapką jest pozwolić generatorom dyktować model domenowy.
Używaj scaffoldów do tworzenia spójnych szkieletów (routes/controllers, DTO, test stubs), a potem natychmiast edytuj wynik, aby pasował do zasad architektonicznych. Dobra polityka: generatory są dozwolone, ale końcowy kod musi czytać się jak przemyślany projekt — nie zrzut szablonu.
Jeśli używasz workflowów wspieranych AI, stosuj tę samą dyscyplinę: traktuj wygenerowany kod jako szkic. Na platformach takich jak Koder.ai możesz szybko iterować przez chat, jednocześnie egzekwując konwencje zespołu (granice modułów, wzorce DI, kształty błędów) w czasie przeglądów — bo szybkość pomaga tylko wtedy, gdy struktura pozostaje przewidywalna.
Style guides dopasowane do idiomów frameworka
Frameworki często sugerują idiomatyczną strukturę: gdzie trafia walidacja, jak podnosić błędy, jak nazywać serwisy. Utrwal te oczekiwania w krótkim przewodniku stylu, który zawiera:
- Konwencje nazewnictwa zgodne z prymitywami frameworka (np. Controller, Service, Module)
- Granice folderów (co jest dozwolone w kontrolerze vs. w warstwie domeny/serwisu)
- Przykłady „dobrego” implementowania endpointu
Trzymaj to lekkie i praktyczne; linkuj z /contributing.
Linting, formatowanie i pre-commit hooks
Zautomatyzuj standardy. Skonfiguruj formatery i linters zgodnie z konwencjami frameworka (importy, dekoratory/annotacje, wzorce async). Wymuszaj to spójnie przez pre-commit hooks i CI, żeby przeglądy skupiały się na designie zamiast na whitespace i nazwach.
Szablony PR i checklisty przeglądów powiązane z architekturą
Checklista oparta na frameworku zapobiega powolnemu dryfowi w stronę niespójności. Dodaj szablon PR, który prosi reviewerów o potwierdzenie rzeczy takich jak:
- Nowe endpointy przestrzegają konwencji routing/controller
- Walidacja i odpowiedzi błędów pasują do standardu zespołu
- Granice zależności są respektowane (brak bezpośrednich wywołań DB z kontrolerów itp.)
- Testy trzymają się rekomendowanych wzorców frameworka
Z czasem te małe strażniki workflowu utrzymują czytelność bazy kodu wraz ze wzrostem zespołu.
Wybór i ewolucja frameworka bez bolesnych przepisów
Wybór frameworka zazwyczaj blokuje wzorce — układ katalogów, styl kontrolerów, DI, a nawet sposób pisania testów. Celem nie jest wybór idealnego frameworka; celem jest wybrać taki, który pasuje do sposobu dostarczania oprogramowania przez twój zespół i pozwala na zmianę, gdy wymagania się przesuną.
Ocena dopasowania do rozmiaru i celów zespołu
Zacznij od ograniczeń dostawy, nie od listy funkcji. Mały zespół zwykle skorzysta z silnych konwencji, narzędzi „batteries-included” i szybkiego onboardingu. Większe zespoły potrzebują jaśniejszych granic modułów, stabilnych punktów rozszerzeń i wzorców utrudniających ukryte sprzężenia.
Zadaj praktyczne pytania:
- Czy możesz wymuszać spójną strukturę przy minimalnym nadzorze w przeglądach kodu?\n- Czy framework ułatwia robienie właściwych rzeczy (walidacja, obsługa błędów, logowanie), czy każdy zespół musi wymyślać własne rozwiązania?\n- Czy aktualizacje są przewidywalne (czytelne changelogi, ścieżki deprecjacji), i czy ekosystem jest wystarczająco dojrzały dla twoich potrzeb?
Czerwone flagi zwiastujące rewrites
Rewrite jest często wynikiem ignorowania mniejszych problemów. Obserwuj:\n
- Niejasne granice: logika biznesowa przemyca się do kontrolerów, middleware lub modeli ORM\n- Powolne testy: integracyjne testy trwające minuty, co skłania zespoły do ich pomijania\n- Krucha modernizacja: częste breaking changes, mocne poleganie na wewnętrznych API lub „obejścia społecznościowe” stają się normą
Wzorce inkrementalnej refaktoryzacji, które pozwalają dostarczać dalej
Możesz ewoluować bez zatrzymywania dostaw, wprowadzając szwy:\n
- Podejście strangler: kieruj mały zestaw endpointów przez nowy moduł, zostawiając stary system w ruchu\n- Warstwy adapterów: owijaj prymitywy frameworka własnymi interfejsami (request context, logger, repozytoria)\n- Granice „ports and adapters”: przenieś logikę domenową do prostych modułów z minimalnymi importami frameworka, a potem podłączaj je z krawędzi
Lista kontrolna adopcji i następne kroki
Zanim się zobowiążesz (albo przed kolejną dużą aktualizacją), zrób krótki trial:
- Zbuduj jeden rzeczywisty endpoint end-to-end: auth, walidacja, odpowiedzi błędów i logowanie.
- Napisz dwa testy: szybki unit dla logiki domenowej i test integracyjny dla warstwy HTTP.
- Zasymuluj zmianę: dodaj pole, wersjonuj odpowiedź i zrefaktoryzuj moduł.
- Przejrzyj notatki o aktualizacji z ostatniej głównej wersji — czy to by was dotknęło?
Jeśli chcesz ustrukturyzowanego sposobu oceny opcji, stwórz lekki RFC i zapisz go w repo (np. /docs/decisions), żeby przyszłe zespoły rozumiały, dlaczego podjęto daną decyzję — i jak bezpiecznie ją zmienić.
Jeden dodatkowy punkt: jeśli zespół eksperymentuje z szybszymi pętlami budowania (w tym developmentem napędzanym czatem), oceń, czy workflow wciąż produkuje te same artefakty architektoniczne — wyraźne moduły, egzekwowalne kontrakty i operacyjne domyślne ustawienia. Najlepsze przyspieszenia (czy to z CLI frameworka, czy platformy takiej jak Koder.ai) to te, które skracają czas cyklu bez erozji konwencji, które utrzymują backend w dobrej kondycji.
Często zadawane pytania
What’s the practical difference between a backend framework and a set of libraries?
Framework backendowy dostarcza opiniotwórczy sposób budowy aplikacji: domyślną strukturę projektu, konwencje cyklu życia żądania (routing → middleware → kontrolery/handlery), wbudowane narzędzia i „zalecane” wzorce. Biblioteki zwykle rozwiązują izolowane problemy (routing, walidacja, ORM), ale nie narzucają, jak te elementy mają współgrać w zespole.
How do frameworks influence day-to-day engineering decisions?
Konwencje frameworka stają się domyślną odpowiedzią na codzienne pytania: gdzie umieszczać kod, jak przepływa żądanie, jak wyglądają błędy i jak są łączone zależności. Ta spójność przyspiesza onboardowanie i zmniejsza spory podczas przeglądów, ale też powoduje „lock-in” do pewnych wzorców, które później trudno zmienić.
Should we organize code by layers (controllers/services/models) or by feature modules?
Wybierz strukturę warstwową, gdy chcesz wyraźnego rozdziału technicznych odpowiedzialności i łatwej centralizacji zachowań przekrojowych (auth, walidacja, logowanie).
Wybierz moduły funkcjonalne, gdy chcesz, żeby zespoły mogły pracować „lokalnie” w ramach kompetencji biznesowej (np. Billing) bez skakania po folderach.
Niezależnie od wyboru, udokumentuj zasady i egzekwuj je w przeglądach, żeby struktura pozostała spójna wraz ze wzrostem kodu.
Are CLI generators/scaffolding tools helpful or harmful long-term?
Używaj generatorów do tworzenia spójnych szkieletów (routes/controllers, DTO, szablony testów), a następnie traktuj wynik jako punkt wyjścia — nie jako ostateczną architekturę.
Jeśli scaffold zawsze generuje controller+service+repo dla wszystkiego, może to dodać ceremonii do prostych endpointów. Regularnie przeglądaj wzorce generowane i aktualizuj szablony tak, by odpowiadały rzeczywistej metodzie pracy.
How do we avoid “fat controllers” in framework-based APIs?
Trzymaj kontrolery przy obowiązkach tłumaczenia HTTP:
- Parsuj wejścia (params/body/headers)
- Waliduj na granicy
- Wywołaj serwis/use-case
- Zwróć odpowiedź
Przenieś reguły biznesowe do warstwy application/service lub domain, aby były wielokrotnego użytku (zadania w tle/CLI) i testowalne bez uruchamiania stacku HTTP.
What belongs in middleware/filters vs in services/use-cases?
Middleware powinno wzbogacać albo chronić żądanie, a nie realizować reguły produktowe.
Dobre zastosowania:
- Autoryzacja/autentykacja
- Request ID / correlation ID
- Strukturalne logowanie
- Ograniczanie liczby żądań (rate limiting)
- Parsowanie/normalizacja wejścia
Decyzje biznesowe (pricing, eligibility, branching workflow) powinny mieszkać w serwisach/use-cases, gdzie można je testować i ponownie używać.
How does dependency injection (DI) change design and maintenance?
DI poprawia testowalność i ułatwia wymianę implementacji (np. zamiana dostawcy płatności na mock) przez jawne wiązanie zależności.
Utrzymuj DI czytelną przez:
- Używanie injection w konstruktorze
- Rejestrowanie zależności w klarownym "composition root"
- Unikanie głębokich grafów zależności
Jeśli widzisz zależności cykliczne, zwykle oznacza to problem z granicami, a nie z DI.
What’s a good approach to validation, DTOs, and consistent error responses?
Traktuj żądania/odpowiedzi jak kontrakty:
- Waliduj wejścia przed uruchomieniem logiki biznesowej
- Ustandaryzuj kopertę błędu (np.
code,message,details,traceId) - Mapuj typowe błędy konsekwentnie (400/401/403/404)
Używaj DTO/view-modeli, żeby nie ujawniać przypadkowo wewnętrznych pól ORM i by klienci nie byli sprzężeni z schematem bazy danych.
How should our testing strategy adapt to framework conventions?
Niech narzędzia frameworka podpowiadają, co jest łatwe, ale zachowaj świadomy podział:
- Testy jednostkowe dla logiki domenowej (bez bootowania frameworka i DB)
- Testy integracyjne dla wiązań modułów/DI i granic persistence
- Cienka warstwa E2E potwierdzająca routing/middleware/obsługę błędów
Wol preferować nadpisywanie bindingów DI lub używanie adapterów in-memory zamiast łamania testów przez monkey-patching; utrzymuj CI szybkie przez minimalizowanie powtarzającego się bootowania frameworka i setupu DB.
What are red flags that a framework choice will lead to a rewrite, and how do we evolve safely?
Uważaj na wczesne sygnały problemów:
- Logika biznesowa przenika do kontrolerów/modeli ORM
- Powolne lub niestabilne testy, które zniechęcają zespoły do ich uruchamiania
- Uciążliwe aktualizacje z częstymi breaking changes
Zmniejsz ryzyko rewrite przez wprowadzenie szwów:
- Owiń prymitywy frameworka własnymi interfejsami (logger, request context, repository)