27 lip 2025·8 min
Jak języki, bazy danych i frameworki działają jako jeden system
Dowiedz się, jak języki, bazy danych i frameworki działają jako jeden system. Porównaj kompromisy, punkty integracji i praktyczne sposoby wyboru spójnego stosu.
Dowiedz się, jak języki, bazy danych i frameworki działają jako jeden system. Porównaj kompromisy, punkty integracji i praktyczne sposoby wyboru spójnego stosu.
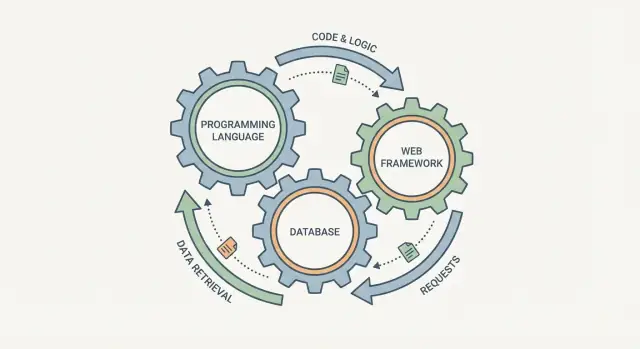
Łatwo jest wybrać język programowania, bazę danych i framework webowy jak trzy niezależne pola wyboru. W praktyce zachowują się raczej jak zazębiające się tryby: zmieniasz jeden, a pozostałe to odczuwają.
Framework webowy kształtuje sposób obsługi żądań, walidację danych i sposób raportowania błędów. Baza danych kształtuje, co oznacza „łatwo przechowywać”, jak zapytujesz informacje i jakie gwarancje dostajesz, gdy wielu użytkowników działa jednocześnie. Język siedzi pośrodku: określa, jak bezpiecznie wyrażasz reguły, jak zarządzasz współbieżnością i z jakich bibliotek oraz narzędzi możesz korzystać.
Traktowanie stosu jako jednego systemu oznacza, że nie optymalizujesz każdej części w izolacji. Wybierasz kombinację, która:
Ten artykuł pozostaje praktyczny i celowo nie-techniczny. Nie musisz zapamiętywać teorii baz danych ani wnętrz języków—po prostu zobaczysz, jak wybory rozchodzą się po całej aplikacji.
Krótki przykład: używanie bazy bez schematu dla silnie ustrukturyzowanych, raportowych danych biznesowych często prowadzi do rozsianych „reguł” w kodzie aplikacji i późniejszych problemów z analityką. Lepszym dopasowaniem jest sparowanie tego samego domeny z bazą relacyjną i frameworkiem, który zachęca do spójnej walidacji i migracji, dzięki czemu dane pozostają spójne w miarę rozwoju produktu.
Gdy planujesz stos razem, projektujesz jeden zestaw kompromisów — nie trzy osobne zakłady.
Pomocny sposób myślenia o „stosu” to traktowanie go jako jednej pipeline: żądanie użytkownika wchodzi do systemu, a odpowiedź (i zapisane dane) wychodzą. Język programowania, framework i baza danych nie są niezależnymi wyborami — to trzy części tej samej podróży.
Wyobraź sobie, że klient aktualizuje adres wysyłki.
/account/address). Walidacja sprawdza, czy dane są kompletne i sensowne.Gdy te trzy elementy się zgadzają, żądanie płynie gładko. Gdy nie, pojawia się tarcie: niezręczny dostęp do danych, nieszczelna walidacja i subtelne błędy spójności.
Większość debat o „stosie” zaczyna się od języka lub marki bazy. Lepszym punktem startowym jest twój model danych — bo to on cicho dyktuje, co będzie naturalne (lub bolesne) w pozostałych miejscach: walidacji, zapytaniach, API, migracjach, a nawet w przepływie pracy zespołu.
Aplikacje zwykle żonglują czterema kształtami jednocześnie:
Dobre dopasowanie to takie, gdy nie spędzasz dni na tłumaczeniu między kształtami. Jeśli twoje dane są silnie połączone (użytkownicy ↔ zamówienia ↔ produkty), wiersze i JOINy utrzymają logikę prostą. Jeśli dane to głównie „jedna bryła na encję” z polami zmiennymi, dokumenty zmniejszą ceremoniał — dopóki nie pojawi się potrzeba raportowania między encjami.
Gdy baza ma silny schemat, wiele reguł może żyć blisko danych: typy, ograniczenia, klucze obce, unikalność. To często zmniejsza duplikację kontroli w różnych serwisach.
W strukturach elastycznych reguły przesuwają się w górę do aplikacji: kod walidacji, wersjonowane payloady, backfille i uważne czytanie („jeśli pole istnieje, to…”). To dobrze działa, gdy wymagania produktowe zmieniają się tygodniowo, ale zwiększa obciążenie frameworka i testów.
Twój model decyduje, czy kod to głównie:
To z kolei wpływa na potrzeby języka i frameworka: silne typowanie może zapobiec subtelnemu dryfowi w polach JSON, podczas gdy dojrzałe narzędzia migracyjne są ważniejsze, gdy schematy często ewoluują.
Wybierz model najpierw; „właściwy” framework i baza danych zwykle stają się jasne po tym kroku.
Transakcje to gwarancje „wszystko albo nic”, na których twoja aplikacja po cichu polega. Gdy checkout się powiedzie, oczekujesz, że rekord zamówienia, status płatności i aktualizacja stanu magazynu albo wszystkie zostaną zastosowane, albo żadna. Bez tej obietnicy pojawiają się najtrudniejsze błędy: rzadkie, kosztowne i trudne do odtworzenia.
Transakcja grupuje wiele operacji bazodanowych w pojedynczą jednostkę pracy. Jeśli coś zawiedzie w połowie (błąd walidacji, timeout, awaria procesu), baza może cofnąć się do poprzedniego bezpiecznego stanu.
To ma znaczenie poza przepływami pieniężnymi: tworzenie konta (wiersz użytkownika + wiersz profilu), publikowanie treści (post + tagi + wskaźniki do indeksu wyszukiwania) czy każdy workflow dotykający więcej niż jednej tabeli.
Spójność oznacza „odczyty odzwierciedlają rzeczywistość”. Szybkość to „zwróć coś szybko”. Wiele systemów robi kompromisy:
Typowy wzorzec porażki to wybór eventualnej spójności i kodowanie tak, jakby była silna.
Frameworki i ORM-y nie tworzą transakcji automatycznie tylko dlatego, że wywołałeś kilka metod „save”. Niektóre wymagają jawnych bloków transakcyjnych; inne zaczynają transakcję na żądanie, co może ukryć problemy wydajnościowe.
Retry są też trudne: ORM-y mogą ponawiać operacje przy deadlockach lub błędach przejściowych, ale twój kod musi być bezpieczny na wielokrotne wykonanie.
Częściowe zapisy pojawiają się, gdy zaktualizujesz A, a potem zawiedziesz przed aktualizacją B. Duplikaty akcji pojawiają się, gdy żądanie jest ponawiane po timeoutcie — szczególnie jeśli obciążyłeś kartę lub wysłałeś mail przed committem transakcji.
Prosta zasada pomaga: wykonuj efekty uboczne (emaile, webhooki) po zatwierdzeniu w bazie, a operacje czynią idempotentnymi przez unikalne ograniczenia lub klucze idempotencji.
To „warstwa tłumacząca” między kodem aplikacji a bazą danych. Wybory tutaj często mają większe znaczenie na co dzień niż sama marka bazy.
ORM (Object-Relational Mapper) pozwala traktować tabele jak obiekty: tworzysz User, aktualizujesz Post, a ORM generuje SQL w tle. Może przyspieszyć pracę, bo standaryzuje codzienne zadania i ukrywa powtarzalne szczegóły.
Budowniczy zapytań jest bardziej jawny: budujesz SQL-podobne zapytanie w kodzie (łańcuchy lub funkcje). Nadal myślisz w kategoriach „JOINy, filtry, grupy”, ale dostajesz bezpieczeństwo parametrów i komponowalność.
Raw SQL to pisanie prawdziwego SQL samodzielnie. Jest najbardziej bezpośredni i często najjaśniejszy dla złożonych zapytań raportowych — kosztem większej ręcznej pracy i konieczności konwencji.
Języki z silnym typowaniem (TypeScript, Kotlin, Rust) skłaniają do narzędzi, które potrafią walidować zapytania i kształty wyników wcześniej. To może zredukować niespodzianki w czasie wykonywania, ale też naciska na centralizację dostępu do danych, by typy nie dryfowały.
Języki o elastycznym metaprogramowaniu (Ruby, Python) często sprawiają, że ORM-y wydają się naturalne i szybkie do iteracji — dopóki ukryte zapytania lub implicite zachowania nie stają się trudne do rozumienia.
Migracje to wersjonowane skrypty zmiany schematu: dodaj kolumnę, utwórz indeks, backfill danych. Cel jest prosty: każdy powinien móc wdrożyć aplikację i uzyskać tę samą strukturę bazy. Traktuj migracje jak kod: przeglądaj je, testuj i miej plan rollbacku gdy trzeba.
ORM-y mogą cicho generować N+1, pobierać ogromne wiersze których nie potrzebujesz lub utrudniać JOINy. Budownicze zapytań mogą dewaluować się do nieczytelnych „łańcuchów”. Raw SQL może być duplikowany i niespójny.
Dobra zasada: używaj najprostszego narzędzia, które czyni intencję oczywistą — a dla krytycznych ścieżek sprawdzaj SQL, który faktycznie jest wykonywany.
Ludzie często obwiniają „bazę danych”, gdy strona działa wolno. Ale większość opóźnień widocznych dla użytkownika to suma wielu małych oczekiwań w całej ścieżce żądania.
Pojedyncze żądanie zwykle płaci za:
Nawet jeśli baza odpowiada w 5 ms, aplikacja która wykonuje 20 zapytań na żądanie, blokuje się na I/O i spędza 30 ms na serializacji ogromnej odpowiedzi, nadal będzie powolna.
Otwarcie nowego połączenia do bazy jest kosztowne i może przytłoczyć DB pod obciążeniem. Pula połączeń ponownie wykorzystuje istniejące połączenia, żeby żądania nie płaciły za ten koszt za każdym razem.
Zaletą jest to, że „właściwy” rozmiar puli zależy od modelu runtime. Serwer asynchroniczny o wysokiej współbieżności może generować duże jednoczesne zapotrzebowanie; bez limitów puli pojawi się kolejkowanie, timeouty i hałaśliwe błędy. Z zbyt restrykcyjnymi limitami aplikacja staje się wąskim gardłem.
Cache może być w przeglądarce, CDN, w procesie lub współdzielony (Redis). Pomaga, gdy wiele żądań potrzebuje tych samych wyników.
Ale cache nie uratuje:
Runtime języka kształtuje przepustowość. Modele thread-per-request mogą marnować zasoby podczas oczekiwania na I/O; modele async zwiększają współbieżność, ale też sprawiają, że backpressure (np. limity puli) jest kluczowy. Dlatego strojenie wydajności to decyzja związana ze stosem, nie tylko z bazą.
Bezpieczeństwa nie „dodaje się” wtyczką do frameworka lub ustawieniem w bazie. To umowa między twoim runtime/językiem, frameworkiem webowym i bazą danych o tym, co musi być prawdą zawsze — nawet gdy deweloper popełni błąd lub dodany zostanie nowy endpoint.
Uwierzytelnianie (kto to jest?) zwykle żyje na krawędzi frameworka: sesje, JWT, OAuth, middleware. Autoryzacja (co może robić?) musi być egzekwowana spójnie zarówno w logice aplikacji, jak i w regułach danych.
Częsty wzorzec: aplikacja decyduje o intencji („użytkownik może edytować ten projekt”), a baza wymusza granice (tenant ID, ograniczenia właścicielstwa, a gdzie sensowne — polityki na poziomie wiersza). Jeśli autoryzacja istnieje tylko w kontrolerach, zadania w tle i skrypty wewnętrzne mogą przez przypadek ją obejść.
Walidacja we frameworku daje szybką informację zwrotną i dobre komunikaty. Ograniczenia w bazie zapewniają ostateczną siatkę bezpieczeństwa.
Używaj obu tam, gdzie ma to znaczenie:
To zmniejsza „niemożliwe stany”, które pojawiają się, gdy dwa żądania się ścigają lub gdy nowy serwis zapisuje dane inaczej.
Sekrety powinny być obsługiwane przez runtime i workflow wdrożeniowy (zmienne środowiskowe, menedżery sekretów), a nie być hardkodowane w kodzie czy migracjach. Szyfrowanie może być realizowane w aplikacji (szyfrowanie pól) i/lub w bazie (szyfrowanie at-rest, zarządzane KMS), ale potrzebujesz jasności, kto rotuje klucze i jak działa odzyskiwanie.
Audyt też jest współdzielony: aplikacja powinna emitować znaczące zdarzenia; baza powinna przechowywać niezmienne logi tam, gdzie ma to sens (np. tabele audytowe append-only z ograniczonym dostępem).
Nadmierne zaufanie do logiki aplikacji to klasyczny błąd: brakujące ograniczenia, ciche wartości null, flagi „admin” przechowywane bez kontroli. Naprawa jest prosta: zakładaj, że błędy się zdarzą i projektuj stos tak, by baza mogła odmówić niebezpiecznych zapisów — nawet od twojego własnego kodu.
Skalowanie rzadko zawodzi, bo „baza nie daje rady”. Zawodzi, gdy cały stos reaguje źle, gdy zmienia się kształt obciążenia: jeden endpoint staje się popularny, jedno zapytanie robi się gorące, jeden workflow zaczyna powtarzać operacje.
Większość zespołów trafia na te same wczesne wąskie gardła:
last_seen, tabele kolejek), spowalniając wszystko.Czy możesz szybko zareagować zależy od tego, jak dobrze framework i narzędzia bazy eksponują plany zapytań, migracje, poolowanie połączeń i bezpieczne wzorce cache.
Typowe ruchy skalujące pojawiają się w kolejności:
Skalowalny stos potrzebuje wsparcia pierwszorzędnego dla zadań w tle, harmonogramowania i bezpiecznych retry.
Jeśli system zadań nie może wymusić idempotencji (to samo zadanie uruchomione dwukrotnie bez podwojenia opłat czy wysyłek), „zaskalujesz” się w problemach z korupcją danych. Wczesne wybory — poleganie na implicite transakcjach, słabych ograniczeniach unikalności lub niejawnych zachowaniach ORM — mogą zablokować czyste wprowadzenie kolejek, wzorca outbox lub zbliżonych do dokładnie-jednokrotnych workflowów później.
Wczesne dopasowanie się opłaca: wybierz bazę dopasowaną do potrzeb spójności i framework z ekosystemem, który sprawia, że następny krok skalowania (repliki, kolejki, partycjonowanie) jest wspierany, a nie wymaga przepisywania.
Stos wydaje się „łatwy”, gdy development i operacje dzielą te same założenia: jak uruchomić aplikację, jak zmieniają się dane, jak uruchamiają się testy i jak dowiesz się, co się stało, gdy coś się zepsuje. Jeśli te elementy się nie zgadzają, zespoły tracą czas na glue code, kruche skrypty i ręczne runbooki.
Szybkie lokalne ustawienie to funkcja. Preferuj workflow, w którym nowy członek zespołu może sklonować repo, zainstalować, uruchomić migracje i mieć realistyczne dane testowe w minutach — nie godzinach.
To zwykle oznacza:
Jeśli narzędzie migracji frameworka kłóci się z wyborem bazy, każda zmiana schematu staje się małym projektem.
Twój stos powinien ułatwiać pisanie:
Częstym błędem jest poleganie na testach jednostkowych, bo testy integracyjne są wolne lub trudne do skonfigurowania. To często oznaka niezgodności stack/ops — provisionowanie testowej bazy, migracje i fixture powinny być prostsze.
Gdy latencja rośnie, musisz prześledzić jedno żądanie przez framework do bazy.
Szukaj spójnych ustrukturyzowanych logów, podstawowych metryk (rate żądań, błędy, czas DB) i trace'ów z czasami zapytań. Nawet proste ID korelacji, które pojawia się w logach aplikacji i logach bazy, potrafi zmienić „zgadywanie” w „znalezienie”.
Operacje nie są oddzielne od rozwoju; to jego kontynuacja.
Wybierz narzędzia, które wspierają:
Jeśli nie możesz z pewnością przećwiczyć odzysku czy migracji lokalnie, nie zrobisz tego dobrze pod presją.
Wybór stosu to mniej wybór „najlepszych” narzędzi, a bardziej wybór narzędzi, które razem się sprawdzą pod twoimi realnymi ograniczeniami. Użyj tej checklisty, aby wymusić wczesne dopasowanie.
Ogranicz czas do 2–5 dni. Zbuduj cienki pionowy wycinek: jeden kluczowy workflow, jedno zadanie w tle, jedno zapytanie raportowe i podstawowy auth. Mierz tarcie deweloperskie, ergonomię migracji, przejrzystość zapytań i łatwość testowania.
Jeśli chcesz przyspieszyć, narzędzia vibe-coding takie jak Koder.ai mogą pomóc szybko wygenerować działający pionowy wycinek (UI, API i baza) z eksperta w czacie — potem iterować z migawkami/rollback i eksportować kod źródłowy, gdy będziesz gotów zaakceptować kierunek.
Title:
Date:
Context (what we’re building, constraints):
Options considered:
Decision (language/framework/database):
Why this fits (data model, consistency, ops, hiring):
Risks & mitigations:
When we’ll revisit:
Nawet silne zespoły kończą z niezgodnościami stosu — wyborami, które wyglądają dobrze w izolacji, ale tworzą tarcie, gdy system jest zbudowany. Dobra wiadomość: większość jest przewidywalna i można ich uniknąć kilkoma kontrolami.
Klasyczny zapach to wybór bazy lub frameworka bo „jest modny”, podczas gdy model danych wciąż nie jest jasny. Inny to przedwczesne skalowanie: optymalizacja pod miliony użytkowników zanim potrafisz solidnie obsłużyć setki, co zazwyczaj prowadzi do nadmiaru infrastruktury i nowych trybów awarii.
Obserwuj też stosy, w których zespół nie potrafi wytłumaczyć, dlaczego każdy główny element istnieje. Jeśli odpowiedź to głównie „wszyscy tego używają”, gromadzisz ryzyko.
Wiele problemów pojawia się na styku:
To nie są „problemy bazy” czy „problemy frameworka” — to problemy systemowe.
Preferuj mniej ruchomych części i jedną jasną ścieżkę dla typowych zadań: jedno podejście do migracji, jeden styl zapytań dla większości funkcji i spójne konwencje między serwisami. Jeśli framework promuje wzorzec (lifecycle żądania, dependency injection, pipeline zadań), korzystaj z niego zamiast mieszać style.
Przejrzyj decyzje, gdy widzisz powtarzające się incydenty produkcyjne, trwałe tarcie deweloperskie lub gdy nowe wymagania produktowe zasadniczo zmieniają wzorce dostępu do danych.
Zmieniaj bezpiecznie, izolując miejsce styku: wprowadź warstwę adaptera, migrację inkrementalną (dual-write lub backfill gdy potrzeba) i udowodnij równoważność testami automatycznymi przed przekierowaniem ruchu.
Wybór języka programowania, frameworka webowego i bazy danych to nie trzy niezależne decyzje — to jedno projektowe postanowienie wyrażone w trzech miejscach. „Najlepsza” opcja to kombinacja dopasowana do kształtu twoich danych, potrzeb spójności, workflowu zespołu i sposobu, w jaki spodziewasz się rozwoju produktu.
Zapisz powody stojące za wyborem: spodziewane wzorce ruchu, akceptowalna latencja, zasady retencji danych, tryby awarii które możesz tolerować i co wyraźnie nie optymalizujesz teraz. To uczyni kompromisy widocznymi, pomoże przyszłym współpracownikom zrozumieć „dlaczego” i zapobiegnie przypadkowemu dryfowi architektury wraz ze zmianą wymagań.
Przeprowadź bieżącą konfigurację przez sekcję checklisty i zanotuj miejsca, gdzie decyzje się nie zgadzają (np. schemat, który walczy z ORM, albo framework, który utrudnia pracę w tle).
Jeśli eksplorujesz nowy kierunek, narzędzia takie jak Koder.ai mogą pomóc szybko porównać założenia stosu, generując bazową aplikację (np. React na web, serwisy w Go z PostgreSQL i Flutter na mobile), którą możesz przejrzeć, wyeksportować i rozwijać — bez zobowiązania do długiego cyklu budowy.
Dla głębszego dalszego zgłębienia, przeglądaj powiązane poradniki na /blog, szukaj szczegółów implementacyjnych w /docs lub porównaj opcje wsparcia i wdrożeń na /pricing.
Traktuj je jako jedną pipeline dla każdego żądania: framework → kod (język) → baza danych → odpowiedź. Jeśli jeden element wymusza wzorce, którym inne elementy zaprzeczają (np. baza bez schematu + intensywne raportowanie), stracisz czas na łączenie, zdublowane reguły i trudne do debugowania problemy ze spójnością.
Zacznij od swojego rdzeniowego modelu danych i operacji, które będziesz wykonywać najczęściej:
Gdy model będzie jasny, naturalne wybory bazy i funkcji frameworka zwykle staną się oczywiste.
Jeśli baza wymusza silny schemat, wiele reguł można trzymać blisko danych:
NOT NULL, unikalnośćCHECK dla dozwolonych zakresów/stanuW strukturach elastycznych więcej reguł trafia do kodu aplikacji (walidacja, wersjonowanie payloadów, backfill). To przyspiesza wczesne iteracje, ale zwiększa ciężar testowania i ryzyko dryfu.
Używaj transakcji, gdy wiele zapisów musi powieść się lub nie powieść razem (np. zamówienie + status płatności + zmiana magazynu). Bez transakcji ryzykujesz:
Również wykonuj efekty uboczne (maile/webhooki) po commitcie i tworzyć operacje idempotentne (bezpieczne do ponownego uruchomienia).
Wybierz najprostsze rozwiązanie, które zachowuje jasny zamiar:
Dla krytycznych ścieżek zawsze sprawdzaj SQL, który faktycznie jest wykonywany.
Trzymaj schemat i kod w syncu za pomocą migracji traktowanych jak kod produkcyjny:
Jeśli migracje są ręczne lub zawodzą, środowiska się rozjadą i wdrożenia będą ryzykowne.
Profiluj całą ścieżkę żądania, nie tylko bazę danych:
Baza, która odpowiada w 5 ms, nie pomoże jeśli aplikacja wykonuje 20 zapytań lub blokuje się na I/O.
Użyj puli połączeń, żeby nie płacić za tworzenie połączenia przy każdym żądaniu i żeby chronić bazę pod obciążeniem.
Praktyczne wskazówki:
Źle dobrane pule objawiają się timeoutami i głośnymi błędami przy skokach ruchu.
Używaj obu warstw:
NOT NULL, CHECK)To zapobiega „niemożliwym stanom” gdy żądania się ścigają, zadania backgroundowe zapisują dane lub nowy endpoint zapomni o jakiejś walidacji.
Zrób proof of concept ograniczony czasowo (2–5 dni), który ćwiczy prawdziwe miejsca styku:
Potem zapisz krótką kartę decyzyjną, żeby przyszłe zmiany były świadome (zob. powiązane poradniki na /docs i /blog).