Jak LLM-y zamieniają pomysły w prostym angielskim na aplikacje full‑stack
Jak LLM zamienia pomysły w prostym angielskim w aplikacje web, mobilne i backendowe: wymagania, przepływy UI, modele danych, API, testy i wdrożenie.
Jak LLM-y zamieniają pomysły w prostym angielskim na aplikacje full‑stack | Koder.ai
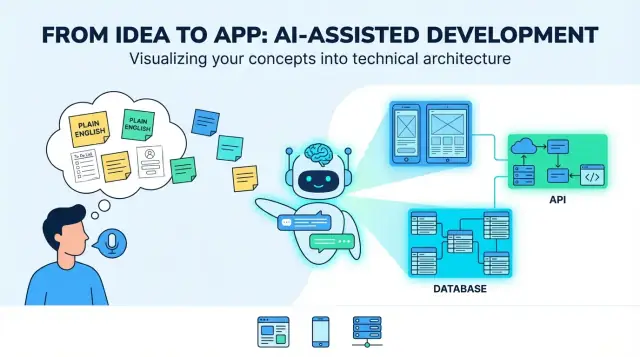
Od pomysłu do aplikacji: co naprawdę znaczy „tłumaczenie"\n\nPomysł opisany "prostym angielskim" zwykle zaczyna się od mieszanki intencji i nadziei: dla kogo jest, jaki problem rozwiązuje i jak wygląda sukces. To mogą być kilka zdań ("aplikacja do umawiania dog walkerów"), zgrubny workflow ("klient zgłasza → walker akceptuje → płatność") i kilka elementów obowiązkowych ("powiadomienia push, oceny"). To wystarcza, by omówić pomysł — ale nie wystarcza, by konsekwentnie zbudować produkt.\n\nKiedy ludzie mówią, że LLM może „przetłumaczyć" pomysł na aplikację, użyteczne znaczenie jest takie: przekształcenie nieostrych celów w konkretne, testowalne decyzje. „Tłumaczenie" to nie tylko parafraza — to dodanie struktury, którą możesz przeglądać, kwestionować i wdrażać.\n\n### Co LLM może wygenerować (szybko)\n\nLLM-y dobrze radzą sobie z przygotowaniem pierwszego szkicu kluczowych elementów budowy:\n\n- Role użytkowników i podstawowe ścieżki (np. klient, wykonawca, admin)\n- Lista funkcji i kryteria akceptacji ("użytkownik może zresetować hasło przez e-mail")\n- Inwentaryzacja ekranów i przepływy UI dla web i mobile\n- Sugerowana architektura (aplikacje frontendowe, usługi backendowe, integracje)\n- Modele danych (tabele/kolekcje, relacje)\n- Zarysy API (endpointy, kształty request/response)\n\nTypowy „wynik końcowy" wygląda jak blueprint produktu full‑stack: UI webowe (często dla adminów lub zadań desktopowych), UI mobilne (dla użytkowników w ruchu), usługi backendowe (auth, logika biznesowa, powiadomienia) i magazyn danych (baza danych plus przechowywanie plików/mediów).\n\n### Jakie decyzje wciąż wymagają ludzi\n\nLLM-y nie są wiarygodne w wyborze kompromisów produktowych, bo właściwe odpowiedzi zależą od kontekstu, którego możesz nie opisać:\n\n- Co liczy się jako „sukces" i jakie metryki są ważne?\n- Jakie są ograniczenia (budżet, harmonogram, zgodność, istniejące narzędzia)?\n- Które edge case'y są ważne (a które można odłożyć)?\n- Jaka jest najprostsza wersja, którą użytkownicy pokochają?\n\nTraktuj model jako system proponujący opcje i domyślne ustawienia, nie ostateczną prawdę.\n\n### Kluczowe ryzyka do nadzorowania\n\nNajwiększe tryby awarii są przewidywalne:\n\n- Niejasność: „szybko", „bezpiecznie", „łatwo" nie da się wdrożyć bez definicji.\n- Brakujące edge case'y: anulacje, ponawianie prób, tryb offline, zwroty, duplikaty, nadużycia.\n- Nadmierna pewność: wyjścia brzmią stanowczo nawet, gdy założenia są kruche.\n\nPrawdziwym celem „tłumaczenia" jest uczynienie założeń widocznymi — żebyś mógł je potwierdzić, poprawić lub odrzucić zanim utrwalą się w kodzie.\n\n## Krok 1: Wyjaśnij brief produktowy\n\nZanim LLM przekształci „Zbuduj aplikację dla X" w ekrany, API i modele danych, potrzebujesz briefu produktowego na tyle konkretnego, by dało się na jego podstawie projektować. Ten krok to przekształcenie nieostrej intencji w wspólny cel.\n\n### Zacznij od problemu i jak zmierzysz sukces\n\nNapisz zdanie problemtowe: kto ma problem, z czym i dlaczego to ważne. Dodaj metryki sukcesu, które są obserwowalne.\n\nPrzykład: „Skrócić czas potrzebny klinice na umówienie wizyty kontrolnej." Metryki: średni czas umawiania, odsetek nieobecności, % pacjentów rezerwujących samodzielnie.\n\n### Zdefiniuj docelowych użytkowników i główne przypadki użycia\n\nWypisz podstawowe typy użytkowników (nie wszystkich, którzy mogą dotknąć systemu). Podaj dla każdego najważniejsze zadanie i krótkie scenariusze.\n\nUżyteczny szablon promptu: „Jako [rola], chcę [coś zrobić] żeby [korzyść]." Celuj w 3–7 kluczowych przypadków opisujących MVP.\n\n### Uchwyć ograniczenia wcześnie (kształtują wszystko)\n\nOgraniczenia to różnica między czystym prototypem a produktem, który można wypuścić. Uwzględnij:\n\n- Platformy: web, iOS, Android (i ewentualne potrzeby offline)\n- Harmonogram i budżet: jakie kompromisy są akceptowalne\n- Zgodność/prywatność: HIPAA, GDPR, lokalizacja danych, logi audytowe\n- Integracje: płatności, kalendarze, SSO, CRM, dostawcy e-mail/SMS\n\n### Zdefiniuj „zrobione": MVP kontra później\n\nBądź precyzyjny, co jest w pierwszym wydaniu, a co zostaje odłożone. Prosta zasada: funkcje MVP muszą wspierać podstawowe przypadki użycia end‑to‑end bez ręcznych obejść.\n\nJeśli chcesz, przygotuj to jako jednostronicowy brief i trzymaj jako „źródło prawdy" dla następnych kroków (wymagania, przepływy UI i architektura).\n\n## Krok 2: Przekształć prosty angielski w wymagania\n\nPomysł w prostym języku to zwykle mieszanka celów ("pomóc ludziom rezerwować zajęcia"), założeń ("użytkownicy się zalogują") i niejasnego zakresu ("zrób to prosto"). LLM jest tu przydatny, bo może uporządkować chaotyczne wejście w wymagania, które możesz przeglądać, poprawiać i zatwierdzać.\n\n### Zamień wypowiedzi w user stories\n\nZacznij od przepisania każdego zdania jako user story. To wymusza jasność, kto czego potrzebuje i dlaczego:\n\n- Jako nowy użytkownik chcę zarejestrować się przez e-mail lub Google, żeby zacząć szybko.\n- Jako powracający użytkownik chcę widzieć moje nadchodzące rezerwacje, by zaplanować tydzień.\n\nJeśli story nie wskazuje typu użytkownika lub korzyści, prawdopodobnie jest wciąż zbyt ogólne.\n\n### Stwórz listę funkcji i ustal priorytety\n\nNastępnie pogrupuj story w funkcje i oznacz każdą jako must-have lub nice-to-have. To pomaga zapobiec rozszerzaniu zakresu przed etapem projektowym i programistycznym.\n\nPrzykład: „powiadomienia push" mogą być nice‑to‑have, a „anulowanie rezerwacji" zwykle jest must‑have.\n\n### Napisz kryteria akceptacji, które model może sprawdzać\n\nDodaj proste, testowalne reguły pod każdym story. Dobre kryteria akceptacji są konkretne i obserwowalne:\n\n- Given wpisuję nieprawidłowy e‑mail, when wysyłam formularz, then widzę komunikat o błędzie i konto nie jest utworzone.\n- Given anuluję w ciągu 24 godzin, when potwierdzam anulowanie, then moje miejsce zostaje zwolnione i otrzymuję potwierdzenie.\n\n### Wypisz edge case'y wcześnie\n\nLLM-y często domyślają się „happy path", więc jawnie poproś o edge case'y, takie jak:\n\n- Tryb offline lub słaby zasięg (kolejkowanie akcji, zachowanie ponowień)\n- Nieprawidłowe dane (puste pola, nieobsługiwane typy plików)\n- Anulacje i podwójne wysyłki (idempotencja, potwierdzenia)\n\nTen zestaw wymagań będzie Twoim źródłem prawdy do oceny późniejszych wyjść (przepływy UI, API i testy).\n\n## Krok 3: Zaprojektuj przepływy UI dla Web i Mobile\n\nPomysł w prostym języku staje się możliwy do zbudowania, gdy zamienia się w ścieżki użytkownika i ekrany połączone jasną nawigacją. Na tym etapie nie wybierasz kolorów — definiujesz, co ludzie mogą robić, w jakiej kolejności i co oznacza sukces.\n\n### Zmapuj kluczowe ścieżki użytkownika\n\nZacznij od wypisania najważniejszych dróg. Dla wielu produktów możesz ustrukturyzować je jako:\n\n- Onboarding: tworzenie konta, weryfikacja e‑mail/telefon, konfiguracja pierwszego użycia\n- Zadanie podstawowe: główna praca aplikacji (tworzenie, wyszukiwanie, rezerwacja, śledzenie, udostępnianie)\n- Płatności: widok cen, checkout, potwierdzenia, zarządzanie subskrypcją\n- Wsparcie: FAQ, formularz kontaktowy, zgłaszanie problemu\n- Ustawienia: profil, powiadomienia, prywatność, wyloguj, usuń konto\n\nModel może szkicować te przepływy jako sekwencje kroków. Twoim zadaniem jest potwierdzić, co jest opcjonalne, co wymagane i gdzie użytkownik może bezpiecznie przerwać i wznowić zadanie.\n\n### Wygeneruj listę ekranów (web + mobile) z nawigacją\n\nPoproś o dwa dostarczone efekty: inwentaryzację ekranów i mapę nawigacji.\n\n- Web zazwyczaj preferuje lewy sidebar/top nav z większą liczbą widocznych opcji.\n- Mobile zwykle używa zakładek i stosu ekranów, z mniejszą liczbą wyborów na widok.\n\nDobry wynik nazywa ekrany konsekwentnie (np. „Szczegóły zamówienia" vs „Szczegóły zamówienia"), definiuje punkty wejścia i zawiera stany puste (brak wyników, brak zapisanych elementów).\n\n### Formularze i reguły walidacji\n\nPrzekształć wymagania w pola formularzy z regułami: obowiązkowe/opcjonalne, formaty, limity i przyjazne komunikaty o błędach. Przykład: wymagania dla hasła, formaty adresu do płatności, lub „data musi być w przyszłości". Upewnij się, że walidacja działa inline (w trakcie wpisywania) i przy wysyłce.\n\n### Podstawy dostępności do zaimplementowania\n\nUwzględnij czytelne rozmiary tekstu, dobry kontrast, pełne wsparcie klawiatury na webie i komunikaty błędów, które wyjaśniają jak naprawić problem (a nie tylko „Nieprawidłowe dane"). Upewnij się też, że każde pole formularza ma etykietę, a porządek fokusu ma sens.\n\n## Krok 4: Zaproponuj architekturę aplikacji\n\n„Architektura" to plan aplikacji: jakie części istnieją, za co odpowiada każda część i jak się komunikują. Gdy LLM proponuje architekturę, Twoim zadaniem jest upewnić się, że jest wystarczająco prosta, by zbudować teraz i wystarczająco klarowna, by ewoluować później.\n\n### Zacznij od domyślu: monolit czy modułowy?\n\nDla większości nowych produktów pojedynczy backend (monolit) jest dobrym punktem startowym: jedno repozytorium, jedno wdrożenie, jedna baza danych. Szybciej zbudujesz, łatwiej zdebugujesz i taniej utrzymasz.\n\nModularny monolit często jest najlepszym kompromisem: nadal jedno wdrożenie, ale organizacja w moduły (Auth, Billing, Projects itd.) z czystymi granicami. Podział na usługi zostaw, dopóki nie pojawi się realne uzasadnienie — duży ruch, potrzeba niezależnych deployów lub część systemu skalująca się inaczej.\n\nJeśli LLM od razu proponuje „mikrousługi", poproś, aby uzasadnił ten wybór konkretnymi potrzebami, a nie przyszłymi hipotezami.\n\n### Zdefiniuj główne komponenty (i trzymaj je nudnymi)\n\nDobry zarys architektury wymienia niezbędne elementy:\n\n- Auth & user management: rejestracja/logowanie, role, sesje/tokeny.\n- Warstwa logiki biznesowej: reguły produktu (cennik, zatwierdzenia, limity).\n- Dostęp do danych: jak aplikacja czyta/zapisuje bazę.\n- Zadania w tle: prace długotrwałe (importy, generowanie raportów, zadania zaplanowane).\n- Powiadomienia: e‑mail/push/in‑app, szablony i preferencje.\n\nModel powinien też określić, gdzie każdy element żyje (backend vs mobile vs web) i jak klienci komunikują się z backendem (zwykle REST lub GraphQL).\n\n### Uczyń założenia technologiczne jawne\n\nArchitektura pozostaje niejednoznaczna, dopóki nie przypniesz podstaw: framework backendowy, baza danych, hosting i podejście mobilne (natywne vs cross‑platform). Poproś model, by wypisał to jako „Założenia", żeby każdy wiedział, co projektuje.\n\n### Plan skalowania bez nadmiernego inżynierowania\n\nZamiast wielkich przepisań, preferuj małe „escape hatches": cache dla gorących odczytów, kolejka zadań dla pracy w tle i bezstanowe serwery aplikacji, by móc dodać więcej instancji później. Najlepsze propozycje architektury wyjaśniają te opcje, jednocześnie utrzymując v1 prostym.\n\n## Krok 5: Zmodeluj dane\n\nPomysł produktu jest pełen rzeczowników: „użytkownicy", „projekty", „zadania", „płatności", „wiadomości". Modelowanie danych to etap, w którym LLM zamienia te rzeczowniki w wspólny obraz tego, co aplikacja musi przechowywać i jak elementy się łączą.\n\n### Zamień rzeczowniki w encje i relacje\n\nZacznij od wypisania kluczowych encji i pytania: co należy do czego?\n\nPrzykład:\n\n- User ma wiele Projects\n- Project zawiera wiele Tasks\n- Task może mieć wiele Comments\n\nNastępnie zdefiniuj relacje i ograniczenia: czy zadanie może istnieć bez projektu, czy komentarze można edytować, czy projekty można archiwizować i co dzieje się z zadaniami po usunięciu projektu.\n\n### Szkic tabel/kolekcji i istotnych pól\n\nModel proponuje pierwszy szkic schematu (SQL lub NoSQL). Utrzymuj prostotę i koncentruj się na decyzjach wpływających na zachowanie.\n\nTypowy szkic może zawierać:\n\n- users: id, email, name, password_hash/identity_provider_id, created_at\n- projects: id, owner_user_id, name, status, created_at\n- project_members: project_id, user_id, role\n- tasks: id, project_id, title, description, status, due_date, assignee_user_id\n\nWażne: wcześnie uchwyć pola statusu, znaczniki czasowe i ograniczenia unikalności (np. unikalny email). Detale te napędzają filtry w UI, powiadomienia i raportowanie później.\n\n### Własność, uprawnienia i separacja multi‑tenant\n\nWiększość realnych aplikacji potrzebuje jasnych reguł, kto co widzi. LLM powinien wyeksponować własność (owner_user_id) i model dostępu (członkostwa/role). Dla produktów multi‑tenant wprowadź encję tenant/organization i dołącz tenant_id tam, gdzie konieczna jest izolacja.\n\nZdefiniuj też sposób egzekwowania uprawnień: przez role (admin/member/viewer), przez własność albo kombinację obu.\n\n### Retencja, usuwanie i logi audytu\n\nNa koniec zdecyduj, co trzeba logować i co usuwać. Przykłady:\n\n- Zdarzenia audytu: „task created", „permission changed", „export performed"\n- Reguły retencji: usuń dane osobowe na żądanie, przechowuj faktury X lat\n- Soft delete vs hard delete: czy rekordy mają być odzyskiwalne, czy usuwane na stałe\n\nTe wybory zapobiegają nieprzyjemnym niespodziankom przy zgodności, wsparciu i rozliczeniach później.\n\n## Krok 6: Wygeneruj backendowe API\n\nAPI backendowe to miejsce, gdzie obietnice aplikacji stają się rzeczywistymi akcjami: "zapisz mój profil", "pokaż moje zamówienia", "wyszukaj ogłoszenia". Dobry output zaczyna od akcji użytkownika i zamienia je w mały zbiór jasnych endpointów.\n\n### Zacznij od akcji użytkownika → CRUD + wyszukiwanie\n\nWypisz główne obiekty interakcji użytkownika (np. Projects, Tasks, Messages). Dla każdego zdefiniuj, co użytkownik może zrobić:\n\n- Create: dodać nowy element\n- Read: pobrać pojedynczy element lub listę\n- Update: zmienić pola\n- Delete: usunąć/wyłączyć\n- Search/filter: znaleźć elementy po słowie kluczowym, statusie, dacie itp.\n\nTo zwykle mapuje się na endpointy jak:\n\n- POST /api/v1/tasks (create)\n- GET /api/v1/tasks?status=open&q=invoice (list/search)\n- GET /api/v1/tasks/{taskId} (read)\n- PATCH /api/v1/tasks/{taskId} (update)\n- DELETE /api/v1/tasks/{taskId} (delete)\n\n### Przykłady request/response (plain language + JSON)\n\nUtwórz zadanie: użytkownik wysyła tytuł i datę wykonania.\n\njson\nPOST /api/v1/tasks\n{\n "title": "Send invoice",\n "dueDate": "2026-01-15"\n}\n\n\nOdpowiedź zwraca zapisany rekord (w tym pola generowane po stronie serwera):\n\njson\n201 Created\n{\n "id": "tsk_123",\n "title": "Send invoice",\n "dueDate": "2026-01-15",\n "status": "open",\n "createdAt": "2025-12-26T10:00:00Z"\n}\n\n\n(Blok kodu powyżej zachowuje oryginalną zawartość JSON — nie tłumacz pól wewnątrz przykładów.)\n\n### Obsługa błędów, którą aplikacje mobilne zniosą\n\nPoproś model o spójne błędy:\n\n- 400 błędy walidacji (z komunikatami per pole)\n- 401/403 problemy z autoryzacją/uprawnieniami\n- 404 nie znaleziono\n- 409 konflikt (duplikat, przestarzała aktualizacja)\n- 429 za dużo żądań (powiedz klientom, kiedy retry)\n- 500 nieoczekiwane błędy (ogólny komunikat + request id)\n\nDla ponowień preferuj klucze idempotencyjne w POST i jasne wskazówki typu „retry after 5 seconds."\n\n### Wersjonowanie i kompatybilność wstecz\n\nKlienci mobilni aktualizują się powoli. Użyj wersjonowanej ścieżki bazowej (/api/v1/...) i unikaj łamiących zmian:\n\n- Dodawaj nowe pola jako opcjonalne zamiast zmieniać/usuwać istniejących\n- Zachowuj stare pola przez okres deprecjacji\n- Dokumentuj zmiany w krótkim changelogu (np. GET /api/version)\n\n## Krok 7: Bezpieczeństwo i prywatność domyślnie\n\nBezpieczeństwo nie jest zadaniem „na później". Gdy LLM przekształca pomysł w specyfikację, chcesz jawnych bezpiecznych domyślnych ustawień — żeby pierwsza wygenerowana wersja nie była przypadkowo podatna na nadużycia.\n\n### Uwierzytelnianie: jak użytkownicy udowadniają tożsamość\n\nPoproś model o rekomendację głównej metody logowania i zapasowej, plus co się dzieje przy problemach (utrata dostępu, podejrzane logowania). Typowe opcje:
\n- E-mail + hasło (znane, ale trzeba obsłużyć reset, reguły siły hasła i ryzyko wycieków)\n- Magic links / kody jednorazowe (mniejsze ryzyko haseł, ale wymaga solidnej dostarczalności e‑mail i krótkiego czasu życia tokenu)\n- Logowanie społecznościowe (szybkie onboardowanie, ale zależność od zewnętrznych dostawców i reguły łączenia kont)\n\nNiech model określi obsługę sesji (krótkotrwałe tokeny dostępu, refresh tokeny, wylogowanie na urządzeniu) i czy wspiera MFA.\n\n### Autoryzacja: do czego użytkownicy mają prawo\n\nUwierzytelnienie identyfikuje użytkownika; autoryzacja ogranicza dostęp. Zachęć model do wyboru jednego jasnego schematu:
\n- Role (Admin, Member, Viewer) dla prostych aplikacji
Często zadawane pytania
Co oznacza „tłumaczenie”, kiedy mówi się, że LLM może przetłumaczyć pomysł na aplikację?
W tym kontekście „tłumaczenie” oznacza przekształcenie nieostrego pomysłu w konkretne, testowalne decyzje: role, ścieżki użytkownika, wymagania, dane, API i kryteria sukcesu.
To nie jest tylko parafrazowanie — to uczynienie założeń jawnych, żebyś mógł je potwierdzić lub odrzucić zanim zacznie się implementacja.
Jakie wyniki mogę spodziewać się, że LLM wygeneruje szybko dla nowego produktu?
Praktyczny pierwszy szkic zwykle zawiera:
Role użytkowników i podstawowe ścieżki
Listę funkcji z priorytetami (must-have vs nice-to-have)
User stories z kryteriami akceptacji
Inwentaryzację ekranów + mapę nawigacji (web i mobile)
Model danych (encje, relacje, ograniczenia)
Zarys API (endpointy, schematy, błędy)
Traktuj to jako wstępny blueprint, który musisz przejrzeć, nie jako finalną specyfikację.
Jakie decyzje nadal wymagają udziału człowieka, nawet jeśli LLM dobrze wygenerował materiały?
Ponieważ LLM nie zna wiarygodnie Twoich realnych ograniczeń i kompromisów bez Twojego udziału, dalej potrzebujesz ludzi do decyzji takich jak:
Co oznacza „sukces” (metryki)
Ograniczenia budżetowe/terminowe i akceptowalny poziom ryzyka
Które edge case'y są ważne teraz, a które odłożyć
Co stanowi najprostsze, lecz atrakcyjne MVP
Używaj modelu do proponowania opcji, potem wybieraj świadomie.
Jak napisać brief produktowy, którego LLM faktycznie użyje?
Daj modelowi wystarczający kontekst do projektowania:
To staje się Twoim „źródłem prawdy” dla UI, API i testów.
Jak najlepiej używać LLM do tworzenia UI flows, aby nie otrzymać „ładnych, ale nieużytecznych” projektów?
Poproś o dwa wyniki:
Inwentaryzację ekranów (każdy ekran, który trzeba zbudować)
Mapę nawigacji (jak użytkownicy przechodzą między ekranami)
Następnie zweryfikuj:
Czy zacząć od monolitu, modularnego monolitu, czy mikrousług?
Dla większości v1 zacznij od monolitu lub modularnego monolitu.
Zwróć uwagę, jeśli model od razu proponuje mikrousługi — poproś o uzasadnienie (ruch, potrzeba niezależnych wdrożeń, różne wymagania skalowania). Lepiej mieć „escape hatches” zamiast przedwczesnej dystrybucji:
Kolejka zadań w tle
Cache dla gorących odczytów
Bezustanne serwery aplikacji dla łatwego skalowania poziomego
Utrzymaj v1 prostym do wypuszczenia i debugowania.
Na co zwrócić uwagę w modelu danych wygenerowanym przez LLM, aby uniknąć kłopotliwych przeróbek?
Wymagaj, żeby model jasno wypisał:
Encje i relacje (co należy do czego)
Własność i kontrolę dostępu (owner_user_id, członkostwa, role)
Ograniczenia (unikalny email, pola obowiązkowe, enumy statusów)
Zasady usuwania (soft vs hard delete) i zdarzenia audytu
Izolację multi-tenant (tenant/organization + tenant_id wszędzie tam, gdzie trzeba)
Decyzje dotyczące danych wpływają później na filtry w UI, powiadomienia, raportowanie i bezpieczeństwo.
Jak ocenić, czy projekt API wygenerowany przez LLM nadaje się do użycia w rzeczywistych aplikacjach?
Nalegaj na spójność i przyjazne zachowanie dla mobile:
Wersjonowana ścieżka bazowa (np. /api/v1/...)
Jasne endpointy CRUD + wyszukiwanie/filtry
Stabilne kształty request/response z przykładami
Standardowy format błędów obejmujący 400/401/403/404/409/429/500
Klucze idempotencyjne dla powtarzanych POST
Unikaj łamania kompatybilności: dodawaj nowe pola jako opcjonalne i stosuj okno deprecjacji.
Jak użyć LLM do zaprojektowania strategii testów, która nie będzie tylko boilerplate?
Wykorzystaj model do stworzenia planu, potem porównaj go z kryteriami akceptacji:
Testy jednostkowe dla reguł biznesowych i uprawnień
Testy integracyjne dla zachowania API + bazy danych
Testy end‑to‑end dla krytycznych ścieżek
Kontrole specyficzne dla mobile (offline, backgrounding, prośby o uprawnienia)
Wymagaj także realistycznych fixture'ów: strefy czasowe, długie teksty, niemal-duplikaty, sieci z fluktuacjami. Traktuj wygenerowane testy jako punkt wyjścia, nie jako finalne QA.
Permisje (finie‑grane akcje typu project:edit, invoice:export) dla elastyczności
Dostęp na poziomie obiektu (istotne): użytkownicy mogą czytać/pisać tylko rzeczy, które posiadają lub które są z nimi współdzielone\n\nDobry output zawiera przykładowe reguły: „Tylko właściciele projektów mogą usuwać projekt; współpracownicy mogą edytować; widzowie mogą komentować."\n\n### Kontrole bezpieczeństwa, które chcesz w planie\n\nPoproś model o konkretne zabezpieczenia, nie ogólniki:
\n- Walidacja i sanityzacja inputu na każdym endpointzie (nie ufaj klientom)\n- Rate limiting dla logowania, OTP/magic-linków i kosztownych endpointów\n- Obsługa sekretów: trzymaj klucze poza kodem, rotuj poświadczenia, nigdy nie loguj tokenów\n\nPoproś też o listę zagrożeń: CSRF/XSS, bezpieczne ciasteczka i bezpieczne przesyłanie plików, jeśli dotyczy.\n\n### Podstawy prywatności: zbieraj mniej, wyjaśniaj więcej\n\nDomyślnie zbieraj minimalne dane: tylko to, czego funkcja naprawdę potrzebuje, i tylko na potrzebny czas.\n\nNiech LLM przygotuje prosty tekst wyjaśniający:
\n- Jakie dane zbieramy (i dlaczego)\n- Jak długo je przechowujemy\n- Jak użytkownik może je usunąć lub wyeksportować\n\nJeśli dodajesz analitykę, zapewnij opcję opt‑out (lub opt‑in tam, gdzie wymagane) i udokumentuj to w ustawieniach i stronach polityki.\n\n## Krok 8: Strategia testowania, którą model może wygenerować\n\nDobry LLM może przekształcić wymagania w plan testów, który jest zaskakująco użyteczny — jeśli wymusisz, by wszystko było osadzone w kryteriach akceptacji, a nie w ogólnych stwierdzeniach "powinno działać".\n\n### Mapowanie testów bezpośrednio do kryteriów akceptacji\n\nZacznij od przekazania modelowi listy funkcji i kryteriów akceptacji, potem poproś o testy dla każdego kryterium. Solidny output zawiera:
\n- Testy jednostkowe dla reguł biznesowych (np. obliczenia cen, walidacja, sprawdzenie uprawnień)\n- Testy integracyjne dla zachowania API + bazy (np. tworzenie zamówienia zapisuje odpowiednie wiersze)\n- Testy E2E dla krytycznych ścieżek użytkownika (np. rejestracja → onboarding → ukończenie pierwszego zadania)\n\nJeśli test nie odnosi się do konkretnego kryterium, to prawdopodobnie jest szumem.\n\n### Dane testowe i fixture'y z realnych scenariuszy\n\nLLM-y mogą też zaproponować fixture'y odzwierciedlające rzeczywiste użycie: nieporadne nazwy, brakujące pola, strefy czasowe, długi tekst i „prawie duplikaty".\n\nPoproś o:\n\n- Zestawy seed danych (mały, średni) z edge case'ami\n- Reużywalne factory/fixtures dla użytkowników, ról i wspólnych obiektów\n- „Golden path" dataset używany w E2E dla spójności\n\n### Kontrole specyficzne dla mobile, o których ludzie zapominają\n\nPoproś model o dedykowaną listę kontrolną mobile:\n\n- Tryb offline (tryb tylko do odczytu vs kolejka zapisów, rozwiązywanie konfliktów)\n- Backgrounding/foregrounding (odtwarzanie stanu, oczekujące żądania)\n- Prośby o uprawnienia (kamera, lokalizacja, powiadomienia) i obsługa odmów\n\n### Używanie LLM do generowania testów — i jak je przeglądać\n\nLLM-y są świetne w szkicowaniu szkieletów testów, ale przeglądaj:
\n- Assercje: czy weryfikują wyniki, a nie szczegóły implementacji?\n- Pokrycie: czy uwzględniono przypadki błędne (401/403, 422, timeouty)?\n- Ryzyko flakiness: oczekiwania czasowe, zależności sieciowe, niestabilne selektory\n\nTraktuj model jako szybkie narzędzie do pisania testów, nie jako finalne QA sign‑off.\n\n## Krok 9: Wdrożenie, wydania i monitoring\n\nModel może wygenerować dużo kodu, ale użytkownicy zyskują dopiero, gdy to bezpiecznie wypuścisz i widzisz, co się dzieje po starcie. Ten etap dotyczy powtarzalnych wydań: tych samych kroków za każdym razem, z jak najmniejszymi niespodziankami.\n\n### Podstawy CI (co automatyzować)\n\nSkonfiguruj prosty pipeline CI, który uruchamia się przy każdym pull request i przy merge do main:
\n- Linting/formatowanie żeby łapać niespójności i powszechne błędy wcześnie.\n- Automatyczne testy (unit + niewielka liczba E2E „happy path").\n- Kroki budowania dla każdej powierzchni:\n - Build aplikacji web\n - Build aplikacji mobilnej (Android/iOS)\n - Build/package backendu\n\nNawet jeśli LLM wygenerował kod, CI mówi Ci, czy dalej działa po zmianach.\n\n### Środowiska: dev, staging, production\n\nUżywaj trzech środowisk z jasnymi celami:\n\n- Dev: szybkie iteracje, lokalne bazy, debug logs.\n- Staging: ustawienia zbliżone do produkcji do końcowej weryfikacji.\n- Production: prawdziwi użytkownicy, restrykcyjny dostęp, najmniej szumów w logach.\n\nKonfiguracja powinna iść przez zmienne środowiskowe i sekrety (nie twardo w kodzie). Zasada: jeśli zmiana wymaga modyfikacji kodu, to prawdopodobnie zła konfiguracja.\n\n### Zarys wdrożenia\n\nDla typowej aplikacji full‑stack:\n\n- Hosting backendu: wdrożenie kontenera lub usługi zarządzanej i uruchomienie health checks.\n- Migracje bazy: wersjonowane migracje, uruchamiane automatycznie podczas deployu, odwracalne gdy to możliwe.\n- Wydania mobilne: publikuj najpierw buildy wewnętrzne (TestFlight / internal testing), potem stopniowe wypuszczenie w App Store/Play Store.\n\n### Monitoring i workflow zgłaszania problemów\n\nPlanuj trzy sygnały:\n\n- Logi (co się wydarzyło), metryki (jak często) i alerty (co wymaga natychmiastowej uwagi).\n- Lekki on‑call: alerty muszą być wykonalne, nie hałaśliwe.\n- Ścieżka dla użytkowników do zgłaszania problemów (w aplikacji lub /support), trafiająca do kolejki triage z priorytetem, krokami reprodukcji i planem rollbacku.\n\nTu AI‑wspomagane wytwarzanie staje się operacyjne: nie chodzi tylko o generowanie kodu — chodzi o uruchamianie produktu.\n\n## Gdzie wyjścia LLM idą źle (i jak je naprawić)\n\nLLM-y potrafią przekształcić niejasny pomysł w coś, co wygląda jak kompletny plan — ale wypolerowany tekst może ukrywać luki. Najczęstsze porażki są przewidywalne i można ich uniknąć kilkoma powtarzalnymi nawykami.\n\n### Dlaczego prompty zawodzą\n\nWiększość słabych wyników ma cztery źródła:\n\n- Brak kontekstu: model nie zna twoich użytkowników, ograniczeń (budżet, harmonogram, umiejętności zespołu), wymogów zgodności ani tego, co już istnieje.\n- Sprzeczne wymagania: "Zrób to prosto" plus "obsłuż każde edge case" daje niejasne specyfikacje.\n- Ukryte założenia: model może założyć, że login to e‑mail/hasło, że „real‑time" oznacza WebSockets, albo że „admin" ma pełny dostęp do danych.\n- Nieokreślone priorytety: bez trade‑offów (szybkość vs koszt vs jakość) dostaniesz ogólne odpowiedzi, które nie pasują do twojej sytuacji.\n\n### Jak prosić o lepsze wyniki\n\nDostarcz modelowi konkretne materiały wejściowe:
\n- Przykłady: „Jak Calendly, ale do usług na miejscu" plus 2–3 przykładowe user stories.\n- Ograniczenia: "Musimy użyć Postgres, wdrażać na AWS i obsłużyć 10k MAU."\n- Wymuś widoczne rozumowanie: poproś, by wypisał założenia, otwarte pytania i alternatywy: "Pokaż pracę: decyzje + dlaczego."\n\n### Dodaj „Definition of Done", żeby zmniejszyć przeróbki\n\nPoproś o checklisty dla każdego deliverable. Np. wymagania nie są „zrobione", dopóki nie mają kryteriów akceptacji, stanów błędów, ról/uprawnień i mierzalnych metryk sukcesu.\n\n### Trzymaj jedno źródło prawdy\n\nWyniki LLM rozjeżdżają się, gdy specyfikacje, notatki API i pomysły projektowe żyją w różnych wątkach. Prowadź jeden żywy dokument (nawet proste markdown), który łączy:
\n- spec produktu,\n- kontrakt API (endpointy + schematy),\n- notatki projektowe (kluczowe przepływy i edge case'y).\n\nKiedy ponownie promptujesz, wklej najnowszy fragment i powiedz: "Zaktualizuj tylko sekcje X i Y; resztę pozostaw bez zmian."\n\nJeśli implementujesz w miarę postępu, pomaga workflow z migawkami i możliwością rollbacku. Na przykład tryb „planning mode" Koder.ai pasuje tu naturalnie: możesz zablokować spec (założenia, otwarte pytania, kryteria akceptacji), wygenerować szkielety web/mobile/backend z jednego wątku czatu i polegać na snapshotach/rollback, gdy zmiana wprowadzi regresje. Eksport kodu jest szczególnie przydatny, gdy chcesz, by wygenerowana architektura i repo pozostały zgodne.\n\n## Praktyczny przegląd i punkty przeglądu ludzkiego\n\nOto jak „tłumaczenie LLM" może wyglądać end‑to‑end — oraz miejsca, gdzie człowiek powinien się zatrzymać i podjąć rzeczywiste decyzje.\n\n### Krótki przykład: pomysł → ekrany, dane, API\n\nPomysł: „Marketplace opieki nad zwierzętami, gdzie właściciele zamieszczają prośby, opiekunowie aplikują, a płatności uwalniane są po wykonaniu usługi."\n\nLLM może to przekształcić w pierwszy szkic jak:\n\n- Ekrany: Rejestracja/logowanie, Utwórz prośbę, Szczegóły prośby (z aplikacjami), Aplikuj do prośby, Chat w aplikacji, Checkout, Zakończenie zlecenia, Oceny/Recenzje, Panel admina (spory).\n- Model danych: Users (rola: owner/sitter), PetProfiles, Requests (daty, lokalizacja, status), Applications, Messages, Payments, Reviews.\n- API:POST /requests, GET /requests/{id}, POST /requests/{id}/apply, GET /requests/{id}/applications, POST /messages, POST /checkout/session, POST /jobs/{id}/complete, POST /reviews.\n\nTo jest użyteczne — ale to nie jest „zrobione." To uporządkowana propozycja, którą trzeba zweryfikować.\n\n### Gdzie ludzie przeglądają (i dlaczego to ważne)\n\nDecyzje produktowe: Co czyni „aplikację" prawidłową? Czy właściciel może zaprosić opiekuna bezpośrednio? Kiedy prośba jest „wypełniona"? Te reguły wpływają na wszystkie ekrany i API.\n\nPrzegląd bezpieczeństwa i prywatności: Potwierdź dostęp oparty na rolach (właściciele nie powinni czytać czatów innych właścicieli), zabezpiecz płatności i zdefiniuj retencję danych (np. usuwanie czatu po X miesiącach). Dodaj kontrole nadużyć: rate limiting, zapobieganie spamowi, logi audytu.\n\nKompromisy wydajności: Zadecyduj, co musi być szybkie i skalowalne (wyszukiwanie/filtry, chat). To wpływa na cache, paginację, indeksowanie i zadania w tle.\n\n### Pętla iteracji: feedback → wymagania → kod\n\nPo pilocie użytkownicy mogą poprosić o „powiel prośbę" lub „anuluj z częściowym zwrotem". Wprowadź to jako zaktualizowane wymagania, wygeneruj lub załat ją zmieniając przepływy i ponownie uruchom testy i przegląd bezpieczeństwa.\n\n### Co dokumentować dla utrzymania\n\nZapisz „dlaczego", nie tylko „co": kluczowe reguły biznesowe, macierz uprawnień, kontrakty API, kody błędów, migracje bazy i krótki runbook do wydań i reakcji na incydenty. To trzyma wygenerowany kod zrozumiałym po sześciu miesiącach.
Czy każda kluczowa ścieżka da się ukończyć end‑to‑end
Czy istnieją stany puste i stany błędów
Czy wzorce web vs mobile mają sens (sidebar/top nav vs tabs/stack)
Czy formularze mają reguły walidacji i przyjazne komunikaty o błędach