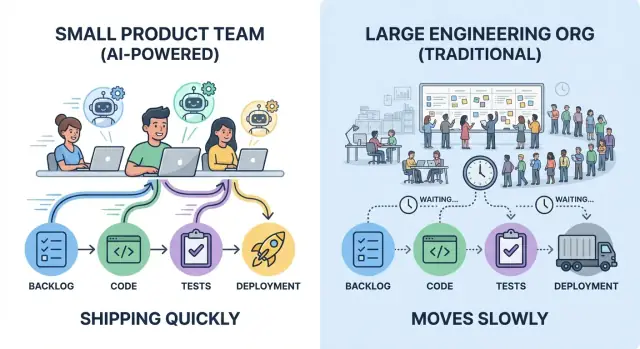
Co w praktyce oznacza „szybkość” w dostarczaniu produktu
„Szybsze wdrażanie” to nie tylko szybsze pisanie kodu. Prawdziwa szybkość dostawy to czas między pomysłem a niezawodną poprawką, którą użytkownicy odczuwają — i momentem, w którym zespół dowiaduje się, czy to zadziałało.
Metryki, które rzeczywiście opisują szybkość
Zespoły kłócą się o szybkość, bo mierzą różne rzeczy. Praktyczny zestaw to kilka metryk dostawy:
- Lead time: ile czasu mija od „zdecydowaliśmy to zrobić” do „jest to dostępne dla użytkowników”.
- Cycle time: ile czasu dana praca spędza w stanie „w toku”, gdy ktoś nad nią zaczyna pracować.
- Deployment frequency: jak często możesz bezpiecznie wypuszczać (codziennie, tygodniowo, na żądanie).
- Time-to-learning: jak szybko otrzymujesz wiarygodny sygnał (użycie, zgłoszenia wsparcia, retencja, przychód), który mówi, co robić dalej.
Mały zespół, który wdraża pięć małych zmian w tygodniu, często uczy się szybciej niż większa organizacja wypuszczająca jedną dużą wersję raz na miesiąc — nawet jeśli miesięczny release zawiera więcej linii kodu.
Co znaczy „używać AI” (a czego nie znaczy)
W praktyce „AI dla inżynierii” zwykle wygląda jak zestaw asystentów wbudowanych w istniejącą pracę:
- Copiloty do pisania kodu, refaktoringu i dokumentacji
- Narzędzia do generowania i utrzymania testów
- Wsparcie w przeglądach kodu (wyłapywanie przypadków brzegowych, sugestie uproszczeń)
- Boty do wsparcia i ops (podsumowywanie incydentów, szkice runbooków, odpowiedzi na „gdzie to jest zaimplementowane?”)
AI pomaga przede wszystkim zwiększyć przepustowość na osobę i zmniejszyć przeróbki — ale nie zastępuje dobrego wyczucia produktu, jasnych wymagań ani odpowiedzialności.
Kluczowa idea: narzut vs. pętle iteracyjne
Szybkość ograniczają głównie dwie siły: narzut koordynacyjny (przekazania, zatwierdzenia, czekanie) i pętle iteracyjne (buduj → wypuść → obserwuj → dostosuj). AI wzmacnia zespoły, które już trzymają pracę małą, decyzje jasne i sprzężenia zwrotne krótkie.
Bez nawyków i zabezpieczeń — testów, przeglądu kodu i dyscypliny releasowej — AI może równie efektywnie przyspieszyć niewłaściwą pracę.
Ukryty podatek skali: narzut koordynacyjny
Duże organizacje inżynieryjne nie dodają tylko ludzi — dodają połączenia. Każda nowa granica zespołu wprowadza pracę koordynacyjną, która nie dostarcza funkcji: synchronizowanie priorytetów, wyrównywanie projektów, negocjowanie własności i kierowanie zmian przez „właściwe” kanały.
Gdzie naprawdę ucieka czas
Narzut koordynacyjny objawia się w znanych miejscach:
- Spotkania, żeby „wszyscy mieli tę samą informację” (status, planowanie, wyrównanie roadmapy)
- Przeglądy wymagające wielu interesariuszy (security, prywatność, architektura, brand)
- Przekazania między rolami lub zespołami (produkt → design → inżynieria → platforma → SRE)
- Dokumentacja tworzona, by umożliwić te przekazania i bronić decyzji później
Żadne z tych rzeczy nie jest z natury złe. Problem w tym, że się kumulują — i rosną szybciej niż liczba pracowników.
Zależności tworzą oczekiwanie, nie pracę
W dużej organizacji prosta zmiana często przecina kilka linii zależności: jeden zespół odpowiada za UI, inny za API, zespół platformy za wdrożenia, a grupa infosec za zatwierdzenia. Nawet jeśli każda grupa jest efektywna, czas w kolejce dominuje.
Typowe spowolnienia wyglądają tak:
- Funkcja zablokowana przez kwartalną radę architektoniczną
- Mała zmiana w API czekająca dwa tygodnie w backlogu platformy
- Release wstrzymany do otwarcia centralnego okna QA lub zgodności
- „Potrzebujemy zgody Zespołu X”, które zmienia się w wątek trzech spotkań
Jak narzut wydłuża lead time
Lead time to nie tylko czas kodowania; to czas upływający od pomysłu do produkcji. Każde dodatkowe podanie ręki dodaje opóźnienie: czekasz na następne spotkanie, następnego recenzenta, następny sprint, następne miejsce w czyjejś kolejce.
Małe zespoły często wygrywają, bo trzymają własność blisko i decyzje lokalne. To nie eliminuje przeglądów — zmniejsza liczbę przeskoków między „gotowe” a „wdrożone”, gdzie duże organizacje po cichu tracą dni i tygodnie.
Małe zespoły wygrywają dzięki jasnej własności i mniejszej liczbie przekazań
Szybkość to nie tylko szybsze pisanie — to sprawianie, by mniej ludzi musiało czekać. Małe zespoły szybko wdrażają, gdy praca ma jednowątkową własność: jedną jasno odpowiedzialną osobę (lub parę), która prowadzi funkcję od pomysłu do produkcji, z nazwanym decydentem, który może rozstrzygać kompromisy.
Jednowątkowa własność sprawia, że decyzje są tanie
Gdy jeden właściciel odpowiada za rezultaty, decyzje nie odbijają się między produktem, designem, inżynierią i „zespołem platformy” w pętli. Właściciel zbiera wkład, podejmuje decyzję i idzie dalej.
To nie znaczy, że ktoś pracuje w izolacji. To znaczy, że wszyscy wiedzą, kto steruje, kto zatwierdza i co oznacza „gotowe”.
Mniej przekazań to mniej przeróbek
Każde przekazanie dodaje dwa rodzaje kosztu:
- Utrata kontekstu: szczegóły są upraszczane, założenia pozostają niewypowiedziane, przypadki brzegowe znikają.
- Przeróbka: następna osoba odkrywa ograniczenia za późno i odsyła pracę w górę strumienia.
Małe zespoły unikają tego, trzymając problem w ciasnej pętli: ten sam właściciel uczestniczy w wymaganiach, implementacji, wdrożeniu i follow-upie. Efekt: mniej momentów „czekaj, to nie o to mi chodziło”.
Jak AI pomaga jednemu właścicielowi ogarnąć więcej
AI nie zastępuje własności — rozszerza ją. Jeden właściciel może być skuteczny w większej liczbie zadań, używając AI do:
- Szkicowania pierwszych wersji specyfikacji, release notes i komunikatów do klientów
- Podsumowywania długich wątków, historii incydentów lub wcześniejszych decyzji do krótkiego briefu
- Szablonowania implementacji: generowania boilerplate, zarysów testów, skryptów migracyjnych lub stubów klientów API
Właściciel nadal weryfikuje i decyduje, ale czas od pustej strony do działającego szkicu spada gwałtownie.
Jeśli używasz workflow vibe-coding (na przykład Koder.ai), model „jeden właściciel pokrywa cały wycinek” staje się jeszcze łatwiejszy: możesz napisać plan, wygenerować UI w React i szkielet backendu Go/PostgreSQL, iterować przez małe zmiany w tym samym czatowym loopie — potem eksportować kod źródłowy, gdy chcesz większej kontroli.
Sygnały, że masz silne własnictwo
Zwróć uwagę na te operacyjne sygnały:
- Jeden backlog na inicjatywę (nie porozrzucany po wielu narzędziach lub zespołach)
- Jedna definicja „gotowe”, włączając testy i rollout (nie „gotowe w dev")
- Jednoznaczny decyzjonista dla priorytetów i zakresu
- Jasne interfejsy z innymi zespołami: żądania są jawne, ograniczone w czasie i zdokumentowane
Gdy te sygnały są obecne, mały zespół może działać pewnie — a AI ułatwia utrzymanie tego impetu.
Krótsze pętle sprzężenia zwrotnego przewyższają większe plany
Duże plany wydają się efektywne, bo zmniejszają liczbę momentów decyzyjnych. Często jednak przesuwają uczenie na koniec — po tygodniach budowy — kiedy zmiany są najdroższe. Małe zespoły przyspieszają, skracając dystans między pomysłem a rzeczywistym feedbackiem.
Krótkie pętle zapobiegają marnowaniu pracy
Krótka pętla feedbacku jest prosta: zbuduj najmniejszą rzecz, która może cię czegoś nauczyć, pokaż ją użytkownikom i zdecyduj, co dalej.
Gdy feedback przychodzi w dniach (a nie kwartałach), przestajesz dopracowywać niewłaściwe rozwiązanie. Unikasz też nadmiernego projektowania „na wszelki wypadek”, które nigdy się nie pojawia.
Jak wygląda szybkie uczenie się
Małe zespoły mogą prowadzić lekkie cykle dające mocne sygnały:
- Szybkie prototypy: klikalne makiety lub cienkie „happy path” flow, by sprawdzić, czy użytkownicy rozumieją wartość.
- Wczesne wywiady z użytkownikami: 5–8 rozmów często ujawnia główne zastrzeżenia i brakujące elementy.
- Szybkie iteracje A/B: małe zmiany UI lub onboardingu mierzone w krótkim oknie pokazują, która kierunek redukuje tarcie.
Kluczowe jest traktowanie każdego cyklu jako eksperymentu, a nie mini-projektu.
AI może przyspieszać uczenie, nie tylko budowanie
Największe dźwignie AI tu to nie pisanie więcej kodu, tylko skracanie czasu od „usłyszeliśmy coś” do „wiemy, co spróbować dalej”. Przykłady użycia AI:
- Podsumowywanie feedbacku z wywiadów, zgłoszeń supportu, recenzji aplikacji czy notatek sprzedażowych do zwięzłych wniosków.
- Grupowanie tematów (np. punkty dezorientacji, brakujące funkcje, obawy o zaufanie), by szybko wyłoniły się wzorce.
- Szkicowanie eksperymentów: proponowanie hipotez, metryk sukcesu i najmniejszego testu, który potwierdzi lub obali hipotezę.
To znaczy mniej czasu na spotkania syntetyzujące i więcej na uruchamianie następnego testu.
Szybkość wdrażania vs. szybkość uczenia się
Zespoły często świętują prędkość wysyłania — ile funkcji wypuszczono. Ale prawdziwa szybkość to prędkość uczenia się: jak szybko zmniejszasz niepewność i podejmujesz lepsze decyzje.
Duża organizacja może dużo wypuszczać i wciąż być wolna, jeśli uczy się późno. Mały zespół może wypuszczać mniejszą „objętość”, ale poruszać się szybciej, ucząc się wcześniej, korygując szybciej i pozwalając, by dowody — nie opinie — kształtowały roadmapę.
AI jako mnożnik siły, nie zastępstwo
Wdróż swoją następną część
Zamień jedną cienką część funkcjonalności w działającą aplikację za pomocą czatu do budowy.
AI nie robi z małego zespołu „większego”. Sprawia, że decyzje i własność zespołu mają większy zasięg. Sukces to nie to, że AI pisze kod; to to, że usuwa opóźnienia w częściach dostawy, które kradną czas bez poprawiania produktu.
Wysokowydajne zastosowania, które się kumulują
Małe zespoły osiągają duże korzyści, gdy celują AI w pracę potrzebną, ale rzadko różnicującą produkt:
- Generowanie boilerplate: szkielety endpointów, pliki testów, szablony migracji, konfiguracje CI czy powtarzalne komponenty UI.
- Refaktory z planem: zmiany nazw, wyodrębnianie helperów, konwersje wzorców i aktualizacje miejsc wywołań — zwłaszcza przy jasnych ograniczeniach („nie zmieniać zachowania”, „zachować stabilne API publiczne”).
- Szkice dokumentacji: release notes, zarysy ADR, dokumentacja API, przewodniki onboardingu i instrukcje „jak uruchomić lokalnie”.
Wzorzec jest stały: AI przyspiesza pierwsze 80%, żeby ludzie mogli spędzić więcej czasu na ostatnich 20% — części wymagającej wyczucia produktu.
Gdzie AI pomaga najwięcej (a gdzie nie)
AI błyszczy na rutynowych zadaniach, „znanych problemach” i wszystkim, co startuje od istniejącego wzorca w kodzie. Jest też świetne do szybkiego eksplorowania opcji: proponowania dwóch implementacji, wypisania kompromisów czy wykrycia brakujących przypadków brzegowych.
Najmniej pomaga, gdy wymagania są niejasne, decyzja architektoniczna ma długoterminowe konsekwencje lub problem jest bardzo specyficzny dla domeny i ma niewiele pisemnego kontekstu. Jeśli zespół nie potrafi wyjaśnić, co znaczy „gotowe”, AI może tylko szybciej wygenerować coś, co wygląda wiarygodnie.
Szybkość bez skrótów: weryfikacja jest niezbędna
Traktuj AI jak młodszego współpracownika: użyteczne, szybkie i czasem błędne. Ludzie nadal odpowiadają za rezultat.
To oznacza, że każda zmiana wspomagana przez AI powinna mieć przegląd, testy i podstawowe kontrole zdrowia. Praktyczna zasada: używaj AI do szkicowania i transformacji; używaj ludzi do decydowania i weryfikacji. Tak małe zespoły wdrażają szybciej, nie zamieniając prędkości w przyszłe porządki do naprawy.
Redukcja przełączania kontekstu dzięki asyście AI
Przełączanie kontekstu jest jednym z cichych zabójców prędkości w małych zespołach. To nie tylko „przerwanie” — to mentalne przeładowanie za każdym razem, gdy przeskakujesz między kodem, ticketami, dokumentacją, wątkami Slack i nieznanymi fragmentami systemu. AI pomaga, gdy zmienia te przeładowania w szybkie postoje.
Jak AI obniża koszt przełączania
Zamiast tracić 20 minut na szukanie odpowiedzi, możesz poprosić o szybkie podsumowanie, wskazanie prawdopodobnych plików lub proste wyjaśnienie po polsku tego, co widzisz. Dobrze użyte, AI staje się generatorem „pierwszego szkicu” zrozumienia: może podsumować długi PR, zamienić niejasny bug report w hipotezy lub przetłumaczyć przerażający stack trace na prawdopodobne przyczyny.
Zysk nie polega na tym, że AI zawsze ma rację — ale że szybciej się orientujesz i możesz podjąć realne decyzje.
Praktyczne taktyki, które działają w prawdziwych zespołach
Kilka wzorców promptów regularnie redukuje chaos:
- Poproś o opcje: „Podaj 3 podejścia do naprawy tego, z kompromisami i ryzykiem.”
- Wytłumacz ten kod: „Wyjaśnij, co robi ta funkcja, przypadki brzegowe i co się zepsuje, jeśli zmienimy X.”
- Wygeneruj plan: „Stwórz krok po kroku plan wysłania tego w dwóch małych PR-ach, łącznie z testami.”
- Napisz checklistę: „Lista kontrolna do bezpiecznego wydania (monitoring, rollback, walidacja).”
Te prompt-y przesuwają cię od błądzenia do wykonania.
Spraw, by prompt-y były wielokrotnego użytku, nie heroicznymi
Szybkość się kumuluje, gdy prompt-y stają się szablonami używanymi przez cały zespół. Trzymaj mały wewnętrzny „pakiet promptów” do typowych zadań: review PR, notatki z incydentów, plany migracji, checklisty QA i runbooki wydania. Spójność się liczy: dołącz cel, ograniczenia (czas, zakres, ryzyko) i oczekiwany format wyjścia.
Ograniczenia i zabezpieczenia
Nie wklejaj sekretów, danych klientów ani niczego, czego nie umieścisz w tickecie. Traktuj wyniki jako sugestie: weryfikuj krytyczne tezy, uruchamiaj testy i dokładnie sprawdzaj generowany kod — szczególnie wokół auth, płatności i usuwania danych. AI zmniejsza przełączanie kontekstu; nie zastąpi inżynierskiego osądu.
Wdróż mało, wdróż często: praktyki, które AI wzmacnia
Szybsze wdrażanie to nie bohaterskie sprinty; to zmniejszanie rozmiaru każdej zmiany, aż dostawa stanie się rutynowa. Małe zespoły już mają przewagę: mniejsza liczba zależności ułatwia krojenie pracy na cienkie kawałki. AI wzmacnia tę przewagę, skracając czas między „pomysł” a „bezpieczna, releasowalna zmiana”.
Lekki pipeline dostawy (który dobrze działa w dół skali)
Prosty pipeline bije rozbudowany:
- Trunk-based development: integruj często do main zamiast długotrwałych branchy.
- Małe PR-y: zmiany dające się zrecenzować w minutach, nie godzinach.
- Częste deploye: wypuszczaj, gdy zmiana jest gotowa, nie gdy paczka jest „wystarczająco duża”.
AI pomaga szkicując release notes, sugerując mniejsze commity i wskazując pliki, które prawdopodobnie będą dotknięte razem — popychając w kierunku czyściejszych, zwartych PR-ów.
Testy z przyspieszeniem AI: pokrycie bez obciążenia
Testy często są miejscem, gdzie „wdróż często” się łamie. AI może zredukować ten opór przez:
- Generowanie starterowych testów jednostkowych/integracyjnych na podstawie istniejących wzorców kodu.
- Wymyślanie przypadków brzegowych, które możesz pominąć (strefy czasowe, stany puste, retry, limity rate).
- Proponowanie danych testowych i mocków zgodnych z realnymi kształtami API.
Traktuj testy generowane przez AI jako pierwszy szkic: sprawdź ich poprawność, a potem zachowaj te, które rzeczywiście chronią zachowanie.
Pewność release’u: monitoring, alerty, rollback
Częste deploye wymagają szybkiego wykrywania i szybkiej naprawy. Ustaw:
- Podstawowe health checks i dashboardy dla kluczowych user flows
- Alerty powiązane z objawami (wzrost error rate, latencja, nieudane zadania), nie z mało istotnymi metrykami
- Jednoprzyciskowy rollback (albo automatyczny rollback), by zły release był drobnym incydentem
Jeśli fundamenty dostawy potrzebują odświeżenia, powiąż to z zespołową lekturą: /blog/continuous-delivery-basics.
Dzięki tym praktykom AI nie „czyni cię szybszym” magicznie — usuwa małe opóźnienia, które składają się potem w cykle tygodniowe.
Opóźnienia decyzyjne: zatwierdzenia vs. guardrails
Buduj szybciej z jednym właścicielem
Szybko stwórz UI w React i backend w Go, a potem iteruj w małych, przeglądalnych zmianach.
Duże organizacje inżynieryjne rzadko są wolne, bo ludzie są leniwi. Są wolne, bo decyzje się kolejkowują. Rady architektoniczne spotykają się co miesiąc. Przeglądy security i prywatności siedzą w backlogach. „Prosta” zmiana może wymagać przeglądu tech leada, potem staff inżyniera, potem zgody platformy, potem zatwierdzenia release managera. Każdy przeskok dodaje czas oczekiwania, nie tylko czasu pracy.
Małe zespoły nie mogą sobie pozwolić na takie opóźnienia decyzyjne, więc powinny dążyć do modelu: mniej zatwierdzeń, silniejsze guardrails.
Co zatwierdzenia próbują rozwiązać (i dlaczego blokują)
Łańcuchy zatwierdzeń to narzędzie do zarządzania ryzykiem. Zmniejszają szansę na złe zmiany, ale też centralizują decyzje. Gdy ta sama mala grupa musi pochwalać każdą istotną zmianę, przepustowość się rozpada, a inżynierowie zaczynają optymalizować pod „zdobycie zgody” zamiast ulepszania produktu.
Guardrails: alternatywa dla małych zespołów
Guardrails przenoszą kontrole jakości ze spotkań do domyślnych ustawień:
- Jasne standardy kodu i definicje done
- Lekkie checklisty dla obszarów ryzykownych (auth, płatności, usuwanie danych)
- Zautomatyzowane kontrole: testy, lint, typy, skan zależności
Zamiast „kto to zatwierdził?”, pytanie brzmi „czy to przeszło ustalone bramki?”.
Jak AI zmniejsza koszt guardrails
AI może standaryzować jakość bez dodawania kolejnych ludzi do pętli:
- Sugestie refaktora i lintu, by dopasować kod do standardów zespołu
- Podsumowania PR wyjaśniające zamiar, zakres i ryzyko prostym językiem
- Checklisty przeglądu wygenerowane z diffu (np. „dotyczy PII: potwierdź politykę retencji”), by recenzenci nie polegali na pamięci
To poprawia spójność i przyspiesza przeglądy, bo recenzent zaczyna od uporządkowanego briefu zamiast pustej strony.
Utrzymanie zgodności lekko (bez omijania)
Zgodność nie musi oznaczać komisji. Utrzymuj powtarzalność:
- Zdefiniuj wyzwalacze „wymaga przeglądu” (PII, przepływ pieniędzy, uprawnienia)
- Używaj szablonów dowodów (podsumowanie PR + checklist + wyniki testów)
- Przechowuj decyzje w wątku PR, by audyt był na wyciągnięcie ręki
Zatwierdzenia stają się wyjątkiem dla bardzo ryzykownych prac; guardrails radzą sobie z resztą. Dzięki temu małe zespoły pozostają szybkie, nie lekkomyślne.
Praca projektowa jako cienkie wycinki, by utrzymać impet
Duże zespoły często „projektują cały system” zanim cokolwiek zostanie wysłane. Małe zespoły mogą działać szybciej, projektując cienkie wycinki: najmniejszą jednostkę end-to-end, która może przejść od pomysłu → kod → produkcję i być używana (nawet przez małą kohortę).
Czym naprawdę jest cienki wycinek
Cienki wycinek to własność pionowa, a nie etap horyzontalny. Zawiera wszystko, co potrzebne w designie, backendzie, frontendzie i ops, by zrealizować jeden rezultat.
Zamiast „przeprojektować onboarding”, cienki wycinek może być „dodaj jedno pole przy rejestracji, zweryfikuj je, zapisz, pokaż w profilu i śledź ukończenie”. Jest na tyle mały, by szybko dokończyć, ale kompletny, by dać lekcję.
Jak AI pomaga kroić pracę (bez zgadywania)
AI przydaje się jako uporządkowany partner myślowy:
- Proponuje 2–4 opcje kamieni milowych (najmniejsza wykonalna, średnia, pełna)
- Generuje rozbicie zadań po warstwach (UI, API, dane, analityka, rollout)
- Wykrywa ukryte zależności (migracje, uprawnienia, przypadki brzegowe)
- Sugeruje plan rolloutu (feature flag, ograniczona kohorta, fallback)
Cel to nie więcej zadań — to jasna, wysyłalna granica.
Zdefiniuj „gotowe” dla każdego wycinka
Momentum gaśnie, gdy „prawie gotowe” się ciągnie. Dla każdego wycinka napisz jawne elementy Definition of Done:
- Zachowanie widoczne dla użytkownika (co się zmieniło, dla kogo)
- Kryteria akceptacji (happy path + kluczowe przypadki brzegowe)
- Instrumentacja (nazwy eventów, dashboardy, alerty jeśli potrzebne)
- Kroki deploymentu/rollbacku (albo reguły feature flag)
Przykłady cienkich wycinków
- Jeden endpoint:
POST /checkout/quote zwracający cenę + podatki
- Jeden ekran: strona ustawień dla preferencji powiadomień
- Jeden workflow: reset hasła od żądania → email → nowe hasło → potwierdzenie
Cienkie wycinki trzymają design przy ziemi: projektujesz to, co możesz wysłać teraz, szybko się uczysz i pozwalasz, by kolejny wycinek zasłużył na swoją złożoność.
Ryzyka przyspieszenia z AI (i jak nimi zarządzać)
Rozciągnij budżet
Zwiększ budżet przez tworzenie treści o Koder.ai lub zapraszanie współpracowników, którzy dołączą.
AI może pomóc małemu zespołowi poruszać się szybko, ale też zmienia tryby awarii. Cel to nie „spowolnić, by być bezpiecznym” — to dodać lekkie guardrails, żebyś mógł dalej wysyłać bez gromadzenia niewidzialnego długu.
Typowe ryzyka przy AI w pętli
Przy szybszym tempie pojawiają się charakterystyczne problemy:
- Niespójny kod i styl: poprawki generowane przez AI mogą różnić się wzorcami, nazewnictwem i architekturą, utrudniając utrzymanie bazy.
- Problemy bezpieczeństwa: sugestie mogą wprowadzać niebezpieczne domyślne ustawienia (słabe sprawdzanie auth, brak walidacji wejścia, niebezpieczna deserializacja).
- Urojona logika: kod może wyglądać przekonująco, a być subtelnie błędny (przypadki brzegowe, złe założenia API, niepoprawne obsługi błędów).
- Rozrost zależności: AI może dodać nowe biblioteki „dla wygody”, zwiększając powierzchnię ataku i koszty utrzymania.
Guardrails, które utrzymają szybkość bez chaosu
Uczyń reguły jawne i łatwe do stosowania. Kilka praktyk szybko się zwraca:
- Zasady bezpiecznego programowania: krótka lista kontrolna dla obszarów (auth, uprawnienia, walidacja, logowanie, szyfrowanie).
- Skan sekretów w CI i pre-commit hooks oraz jasne zasady, gdzie trzymać sekrety.
- Polityka zależności: zatwierdzona lista bibliotek, przypinanie wersji i zasada „nowa zależność wymaga uzasadnienia”.
Kontrole ludzkie, które mają znaczenie
AI może szkicować kod; ludzie muszą odpowiadać za rezultaty.
- Threat modeling dla zmian dotykających danych, auth, płatności lub paneli admina. Nawet 10-minutowy przegląd łapie ryzyka dużego wpływu.
- Przegląd kodu skupiony na zachowaniu, nie tylko stylu: wejścia/wyjścia, ścieżki błędów, uprawnienia i obsługa danych.
- Strategia testów: wymagaj testów jednostkowych dla logiki, testów integracyjnych dla krytycznych przepływów i kilku istotnych end-to-end checks.
Codzienne bezpieczne używanie AI
Traktuj prompt-y jak tekst publiczny: nie wklejaj sekretów, tokenów ani danych klientów. Poproś model o wyjaśnienie założeń, a potem zweryfikuj w źródłowych dokumentach i testach. Jeśli coś wydaje się „zbyt wygodne”, zwykle wymaga bliższego spojrzenia.
Jeśli używasz środowiska budowy opartego na AI jak Koder.ai, stosuj te same zasady: trzymaj dane wrażliwe poza promptami, wymagaj testów i przeglądów oraz polegaj na snapshotach/rollbackach, aby „szybko” znaczyło też „odwracalne”.
Jak mierzyć zyski i zbudować powtarzalny system
Szybkość ma sens tylko wtedy, gdy ją widzisz, umiesz uzasadnić i odtworzyć. Cel to nie „używać więcej AI” — to prosty system, w którym praktyki wspomagane przez AI powtarzalnie skracają time-to-value, nie zwiększając ryzyka.
Metryki pokazujące prawdziwą szybkość dostawy (nie aktywność)
Wybierz mały zestaw, który możesz śledzić co tydzień:
- Cycle time: od „rozpoczęto pracę” do „w produkcji”.
- PR size: linie/pliki zmienione (mniejsze zwykle oznaczają łatwiejsze przeglądy i bezpieczniejsze releasy).
- Review time: mediana czasu oczekiwania PR na pierwszy review i na merge.
- Incydenty/regresje: issues produkcyjne tygodniowo (i ich ciężkość), plus mean time to recover.
- Czas reakcji na klienta: czas od feedbacku użytkownika do wdrożonej zmiany.
Dodaj jeden jakościowy sygnał: „Co nas najbardziej spowolniło w tym tygodniu?” — pomaga wykrywać wąskie gardła, których metryki nie pokażą.
Lekki rytm operacyjny
Trzymaj go spójnym i przyjaznym dla małego zespołu:
- Tygodniowe cele (30 minut): 1–3 rezultaty, nie długa lista zadań.
- Codzienne asynchroniczne aktualizacje: wczoraj/dziś/blokery w Slack/Linear/GitHub.
- Demonstracje (co tydzień lub co dwa tygodnie): pokazuj wdrożone funkcje, nie slajdy. To wzmacnia „gotowe = w rękach użytkowników”.
30-dniowy plan wdrożenia workflowów AI
Tydzień 1: Baseline. Zmierz powyższe metryki przez 5–10 dni roboczych. Bez zmian.
Tygodnie 2–3: Wybierz 2–3 workflowy AI. Przykłady: generowanie opisu PR + checklisty ryzyka, pomoc w pisaniu testów, tworzenie release notes + changeloga.
Tydzień 4: Porównaj przed/po i utrwal nawyki. Jeśli PR-y się skurczyły i review jest szybsze bez wzrostu incydentów, utrzymaj rozwiązanie. Jeśli incydenty rosną, dodaj guardrails (mniejsze rollouty, lepsze testy, jaśniejsze właścicielstwo).
Lista kontrolna: zacznij w tym tygodniu
- Wybierz 3 metryki do publikowania w cotygodniowym wątku.
- Ustaw domyślny cel rozmiaru PR (i egzekwuj go normami społecznymi, nie biurokracją).
- Dodaj krok „przeglądu przed” z AI: podsumowanie zmian, ryzyka i pokrycia testowego.
- Umów jedno demo w kalendarzu.
- Przeprowadź jedno „retro wąskiego gardła”: co spowodowało największe opóźnienie i co zmienimy w następnym tygodniu?