21 lip 2025·8 min
Jak stworzyć aplikację webową do dostępu konsultantów zewnętrznych
Dowiedz się, jak zbudować aplikację webową, która bezpiecznie przydziela, przegląda i cofa dostęp konsultantów zewnętrznych z rolami, zatwierdzeniami, limitami czasowymi i logami audytu.
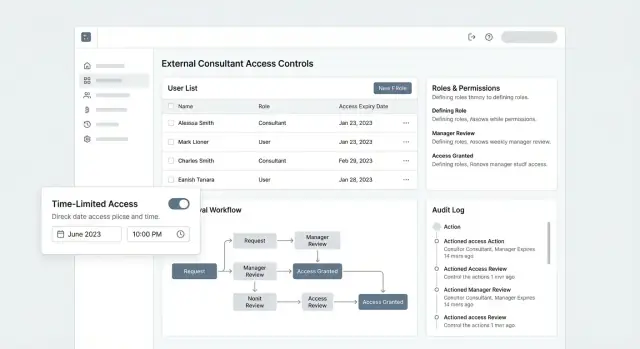
Co naprawdę oznacza „dostęp konsultanta”
„Dostęp konsultanta” to zestaw uprawnień i procesów, które pozwalają osobom spoza firmy wykonywać realną pracę w twoich systemach — bez zamieniania ich w stałych użytkowników, którzy z czasem zbierają coraz więcej uprawnień.
Konsultanci zwykle potrzebują dostępu, który jest:
- Zewnętrzny (logują się jako osobne tożsamości, nie przez współdzielone konto zespołowe)
- Powiązany z projektem (przydzielony do konkretnego klienta, projektu lub zlecenia)
- Ograniczony czasowo (kończy się automatycznie, jeśli nie zostanie przedłużony)
- Podlegający audytowi (każde działanie można przypisać osobie i zatwierdzeniu)
Problem, który rozwiązujesz
Pracownicy są objęci cyklem życia HR i wewnętrznymi procesami IT. Konsultanci często znajdują się poza tym systemem, a mimo to potrzebują szybkiego dostępu — czasem na kilka dni, czasem na kwartał.
Jeśli traktujesz konsultantów jak pracowników, onboarding jest powolny i powstają wyjątkowe przypadki. Jeśli traktujesz ich po macoszemu, powstają luki w bezpieczeństwie.
Typowe ryzyka, przed którymi warto się zabezpieczyć
Domyślnym trybem awarii jest nadawanie zbyt szerokich uprawnień: ktoś daje „tymczasowy” szeroki dostęp, żeby praca mogła ruszyć, i nigdy go nie ogranicza. Drugim problemem są przestarzałe konta: dostęp pozostaje aktywny po zakończeniu współpracy. Najgorsze są współdzielone dane logowania: tracisz rozliczalność, nie możesz udowodnić, kto co zrobił, a offboarding staje się niemożliwy.
Cele aplikacji do zarządzania dostępem konsultantów
Twoja aplikacja powinna optymalizować:
- Szybki onboarding z jasnym właścicielem i minimalną ilością pytań
- Zasada najmniejszego uprzywilejowania jako domył (dostęp zaczyna się wąsko i rozszerza tylko po uzasadnieniu)
- Jasna rozliczalność (wnioskodawca, zatwierdzający i tożsamość konsultanta są jednoznacznie określone)
- Łatwy offboarding, który niezawodnie usuwa dostęp wszędzie
Co aplikacja powinna zarządzać (zakres)
Bądź precyzyjny co do tego, co „dostęp” obejmuje w twojej organizacji. Typowy zakres obejmuje:
- Aplikacje (narzędzia wewnętrzne, systemy ticketowe, pulpity)
- Dane (zestawy danych, pliki, rekordy, eksporty)
- Środowiska (prod vs staging vs dev)
- Klienci/projekty (które dane klienta konsultant może zobaczyć i w jakiej roli)
Zdefiniuj dostęp konsultanta jako powierzchnię produktową z zasadami — nie jako doraźną pracę administratora — a reszta decyzji projektowych stanie się znacznie łatwiejsza.
Lista wymagań i interesariusze
Zanim zaprojektujesz ekrany lub wybierzesz dostawcę tożsamości, ustal kto potrzebuje dostępu, dlaczego i jak powinien on się kończyć. Zewnętrzny dostęp konsultantów najczęściej zawodzi dlatego, że wymagania były zakładane zamiast zapisane.
Interesariusze (i na czym im zależy)
- Sponsor wewnętrzny (właściciel projektu): chce, żeby konsultant był produktywny szybko, bez dodatkowej pracy wsparcia.
- Admin IT/Bezpieczeństwa: potrzebuje spójnego sposobu egzekwowania polityk (oczekiwania SSO/MFA, logowanie, limity czasowe) i reagowania na incydenty.
- Konsultant (użytkownik zewnętrzny): potrzebuje prostego logowania i tylko narzędzi/danych niezbędnych do wykonania zadań.
- Zatwierdzający (manager, lider klienta lub właściciel danych): potrzebuje pewności, że żądania dostępu są uzasadnione i ograniczone do właściwego projektu.
Wyjaśnij wcześnie, kto może zatwierdzać co. Powszechna zasada: właściciel projektu zatwierdza dostęp do projektu, a IT/bezpieczeństwo zatwierdza wyjątki (np. podwyższone role).
Podstawowy przepływ do obsługi end-to-end
Napisz „happy path” w jednym zdaniu, a potem go rozwinię:
Żądanie → zatwierdzenie → provisioning → przegląd → cofnięcie
Dla każdego kroku zanotuj:
- Jakie informacje muszą być podane (projekt, rola, data rozpoczęcia/końca, uzasadnienie)
- Kto jest odpowiedzialny (wnioskodawca vs sponsor vs IT/bezpieczeństwo)
- Oczekiwany czas realizacji (ten sam dzień, 24 godziny, 3 dni robocze)
- Co się dzieje w przypadku błędu (brak info, odmowa, wygasły termin)
Ograniczenia, które warto udokumentować
- Wielu klientów/projektów: jeden konsultant może pracować przy kilku projektach — nie może widzieć danych z innych klientów.
- Ograniczone okna czasowe: dostęp powinien wygasać automatycznie, z jasnym procesem odnowienia.
- Wymogi zgodności: przechowywanie zatwierdzeń i historii audytu, dowody okresowych przeglądów i szybkie cofanie przy zakończeniu umów.
- Model wsparcia: kto resetuje dostęp, obsługuje zablokowane konta i odpowiada na pytania „dlaczego nie widzę tego elementu?”
Metryki sukcesu (aby udowodnić, że to działa)
Wybierz kilka mierzalnych celów:
- Czas onboardingu (złożenie żądania → dostęp gotowy do użycia)
- % kont przeglądanych zgodnie z harmonogramem (miesięczne/kwartalne przeglądy dostępu)
- Czas cofnięcia (koniec umowy → usunięcie dostępu wszędzie)
Te wymagania staną się kryteriami akceptacji portalu, zatwierdzeń i nadzoru w dalszym etapie budowy.
Model danych: Użytkownicy, Projekty, Role i Polityki
Czysty model danych to to, co zapobiega zamienieniu „dostępu konsultanta” w stos jednorazowych wyjątków. Twoim celem jest reprezentować, kim ktoś jest, do czego ma dostęp i dlaczego — jednocześnie traktując ograniczenia czasowe i zatwierdzenia jako elementy pierwszorzędne.
Obiekty podstawowe (co przechowujesz)
Zacznij od niewielkiego zestawu trwałych obiektów:
- Użytkownicy: pracownicy i konsultanci zewnętrzni. Uwzględnij atrybuty tożsamości (email, imię i nazwisko), typ użytkownika (wewnętrzny/zewnętrzny) i status.
- Organizacje: firma konsultanta i twoje jednostki biznesowe, jeśli to istotne.
- Projekty: jednostka pracy, względem której przyznawany jest dostęp (konto klienta, zlecenie, sprawa, strona).
- Zasoby: to, co jest chronione (dokumenty, tickety, raporty, środowiska). Możesz modelować je jako typowane rekordy albo jako ogólny „resource” z polem typu.
- Role: przyjazne dla ludzi pakiety uprawnień (np. „Consultant Viewer”, „Consultant Editor”, „Finance Approver”).
- Polityki: reguły ograniczające role (dozwolone typy zasobów, zakres danych, wymagania IP/urządzenia, limity czasowe).
Relacje (jak wyrażany jest dostęp)
Większość decyzji o dostępie sprowadza się do relacji:
- User ↔ Project membership: tabela łącząca jak
project_memberships, która wskazuje, że użytkownik należy do projektu. - Role assignments: oddzielna tabela łącząca jak
role_assignments, która przyznaje rolę użytkownikowi w danym zakresie (cały projekt lub konkretna grupa zasobów). - Exceptions: modeluj je wprost (np.
policy_exceptions), aby później móc je audytować, zamiast chować je w doraźnych flagach.
To rozdzielenie pozwala odpowiedzieć na typowe pytania: „Którzy konsultanci mają dostęp do Projektu A?” „Jakie role ma ten użytkownik i gdzie?” „Które uprawnienia są standardowe, a które są wyjątkami?”
Dostęp czasowy (ustaw tymczasowość jako domył)
Tymczasowy dostęp jest łatwiejszy do zarządzania, gdy model to wymusza:
- Dodaj znaczniki start/end na członkostwach i/lub przydziałach ról.
- Przechowuj zasady odnowienia (kto może odnowić, maksymalny czas trwania, liczba odnowień).
- Dodaj pole okresu karencji jeśli chcesz krótkie okno na przekazanie (np. tryb tylko do odczytu przez 48 godzin).
Zmiany stanu (śledź cykl życia)
Użyj jasnego pola statusu dla członkostw/przydziałów (nie tylko „usunięty”):
- pending (zażądane, jeszcze nie zatwierdzone)
- active
- suspended (tymczasowo zablokowane)
- expired (minęła data końcowa)
- revoked (skończone wcześniej przez administratora)
Te stany ułatwiają spójność workflowów, UI i logów audytu — i zapobiegają „duchowemu dostępowi”, który trwa po zakończeniu współpracy.
Projekt kontroli dostępu (RBAC + zabezpieczenia)
Dobry dostęp dla konsultantów rzadko jest „wszystko albo nic”. To jasna baza (kto może co robić) plus zabezpieczenia (kiedy, gdzie i pod jakimi warunkami). Wiele aplikacji zawodzi tutaj: implementują role, ale pomijają kontrole, które utrzymują te role bezpiecznymi w praktyce.
Zacznij od RBAC: proste role per projekt
Użyj kontroli dostępu opartej na rolach (RBAC) jako fundamentu. Trzymaj role zrozumiałe i powiązane z konkretnym projektem lub zasobem, nie globalnie dla całej aplikacji.
Powszechna baza to:
- Viewer: może czytać dane projektu i pobierać zatwierdzone artefakty.
- Editor: może tworzyć/aktualizować elementy w projekcie (np. przesyłać deliverables, komentować, aktualizować status).
- Admin: może zarządzać ustawieniami projektu i przydzielać role dla tego projektu.
Uczyń „zakres” explicite: Viewer on Project A nie oznacza dostępu do Project B.
Dodaj zabezpieczenia z warunkami w stylu ABAC
RBAC odpowiada na pytanie „co mogą zrobić?”. Zabezpieczenia odpowiadają na „pod jakimi warunkami jest to dozwolone?”. Dodaj sprawdzenia atrybutów (ABAC-style) tam, gdzie ryzyko jest większe lub wymagania się różnią.
Przykłady warunków, które warto wdrożyć:
- Atrybuty projektu: pozwalaj dostęp tylko do projektów w przypisanym koncie klienta lub regionie konsultanta.
- Lokalizacja / sieć: wymagaj zaufanej sieci (lub blokuj ryzykowne geografie) przy wrażliwych eksportach.
- Postawa urządzenia: ogranicz akcje, chyba że sesja spełnia wymagania bezpieczeństwa (np. ukończone MFA, zarządzane urządzenie).
- Okna czasowe: zezwalaj na dostęp tylko w czasie trwania zlecenia lub w godzinach pracy.
Te sprawdzenia można nakładać warstwowo: konsultant może być Edytorem, ale eksport danych może wymagać zaufanego urządzenia i przebywania w zatwierdzonym oknie czasowym.
Zasada najmniejszego uprzywilejowania domyślnie, wyjątki przez proces
Domyślnie nadaj wszystkim nowym użytkownikom zewnętrznym najniższą rolę (zwykle Viewer) z minimalnym zakresem projektu. Jeśli ktoś potrzebuje więcej, wymagaj wniosku wyjątkowego z:
- konkretnymi potrzebnymi uprawnieniami,
- projektami objętymi zmianą,
- pisemnym uzasadnieniem,
- datą wygaśnięcia.
To zapobiega cichym przemianom „tymczasowego” dostępu w stały.
Dostęp awaryjny (break-glass) i jego kontrola
Zdefiniuj ścieżkę break-glass na wypadek sytuacji kryzysowej (np. incydent produkcyjny, gdy konsultant musi działać szybko). Trzymaj ją rzadką i jednoznaczną:
- zatwierdzenie przez wyznaczonego właściciela on-call (lub dwuosobowe zatwierdzenie dla działań wysokiego ryzyka),
- limit czasowy (minuty/godziny, nie dni),
- pełne logowanie kto, co, kiedy i dlaczego.
Break-glass powinien być uciążliwy — bo to zawór bezpieczeństwa, nie skrót.
Uwierzytelnianie: SSO, MFA i bezpieczne sesje
Uwierzytelnianie to miejsce, gdzie „zewnętrzny” dostęp może albo wydawać się bezproblemowy — albo stać się trwałym ryzykiem. Dla konsultantów chcesz friction tam, gdzie realnie zmniejsza to ekspozycję.
Wybierz podejście do tożsamości: konta lokalne vs SSO
Konta lokalne (email + hasło) są szybkie do wdrożenia i działają dla każdego konsultanta, ale generują wsparcie przy resetach i zwiększają ryzyko słabych haseł.
SSO (SAML lub OIDC) to zwykle najczystsza opcja, gdy konsultant należy do firmy z dostawcą tożsamości (Okta, Entra ID, Google Workspace). Otrzymujesz scentralizowane polityki logowania, łatwiejszy offboarding po stronie firmy konsultanta i mniej haseł w twoim systemie.
Praktyczny wzorzec:
- Domyślnie używaj SSO, gdy firma konsultanta jest onboardowana.
- Dla niezależnych konsultantów stosuj konta lokalne.
Jeśli dopuszczasz oba sposoby, zaznacz wyraźnie, która metoda jest aktywna dla każdego użytkownika, żeby uniknąć nieporozumień podczas reagowania na incydenty.
MFA bez „teatru bezpieczeństwa” (i bez słabych metod odzyskiwania)
Wymagaj MFA dla wszystkich sesji konsultantów — preferuj aplikacje uwierzytelniające lub klucze bezpieczeństwa. SMS może być fallbackiem, nie pierwszym wyborem.
Odzyskiwanie to miejsce, gdzie wiele systemów niechcący osłabia bezpieczeństwo. Unikaj stałych „backupowych emaili” jako obejścia. Zamiast tego użyj ograniczonego zestawu bezpieczniejszych opcji:
- jednorazowe kody odzyskiwania pokazane raz przy rejestracji,
- reset wspierany przez administratora wymagający weryfikacji tożsamości i pełnego logowania,
- ponowna rejestracja urządzenia, która wymusza ponowne MFA.
Flow zaproszeń: wygasające linki i kontrola domen
Większość konsultantów dołącza przez zaproszenie. Traktuj link zaproszeniowy jak tymczasowe poświadczenie:
- krótkie wygaśnięcie (np. 24–72 godziny),
- jednorazowe użycie, powiązane z zaproszonym adresem email,
- ograniczenie liczby prób i czytelne komunikaty o błędach.
Dodaj whitelistę/blacklistę domen per klient lub projekt (np. zezwalaj na @partnerfirm.com; blokuj darmowe domeny email, gdy potrzeba). To zapobiega błędnym zaproszeniom, które mogłyby stać się dostępem.
Bezpieczeństwo sesji: krótkie, odwoływalne tokeny
Konsultanci często używają współdzielonych maszyn, podróżują i zmieniają urządzenia. Twoje sesje powinny to uwzględniać:
- używaj krótkotrwałych tokenów dostępu,
- rotuj tokeny odświeżania i odwołuj je przy podejrzanej aktywności,
- oferuj „wyloguj ze wszystkich urządzeń” dla użytkowników i administratorów.
Powiąż ważność sesji ze zmianami ról i zatwierdzeń: jeśli dostęp konsultanta zostaje ograniczony lub wygasł, aktywne sesje powinny zakończyć się szybko — nie dopiero przy następnym logowaniu.
Przepływ żądań i zatwierdzeń
Prototypuj portal w czacie
Opisz w czacie swój proces dostępu konsultantów i otrzymaj działającą aplikację do iteracji.
Czysty przepływ żądania i zatwierdzenia zapobiega temu, by „szybkie przysługi” zamieniły się w stały, niezadokumentowany dostęp. Traktuj każde żądanie dostępu konsultanta jak małą umowę: jasny zakres, właściciel i data końcowa.
Formularz żądania: przechwytuj zamiar, nie tylko tożsamość
Zaprojektuj formularz tak, by wnioskujący nie mogli być niejasni. Co najmniej wymagaj:
- Projekt (lub zlecenie klienta), nad którym będzie pracować konsultant
- Żądana rola (mapowana do twoich standardowych ról, nie wolny tekst)
- Czas trwania (data rozpoczęcia + data końca, z wyraźną strefą czasową)
- Uzasadnienie biznesowe (krótki akapit wyjaśniający, dlaczego i jakie prace blokuje brak dostępu)
Jeśli dopuszczasz wielokrotne projekty, zrób formularz specyficzny dla projektu, żeby approwals i polityki się nie mieszały.
Trasowanie zatwierdzeń: określ własność
Zatwierdzenia powinny iść za odpowiedzialnością, nie za strukturą organizacyjną. Typowy routing:
- Właściciel projektu (potwierdza, że konsultant powinien pracować przy tym projekcie)
- Bezpieczeństwo lub IT (potwierdza, że rola jest odpowiednia i zgodna z zasadą najmniejszego uprzywilejowania)
- Kontakt u klienta (opcjonalnie, jeśli klient musi autoryzować dostęp zewnętrzny)
Unikaj „zatwierdzeń przez email”. Używaj ekranów zatwierdzania w aplikacji, które pokazują co zostanie przyznane i na jak długo.
SLA, przypomnienia i eskalacje
Dodaj lekką automatyzację, żeby żądania nie ugrzęzły:
- przypomnienia o oczekujących zatwierdzeniach (np. po 24 godzinach)
- powiadomienia o nadchodzącym wygaśnięciu (np. 7 dni przed datą końcową)
- eskalacja do zastępczego zatwierdzającego, gdy główny jest niedostępny
Zapisuj każdą decyzję
Każdy krok powinien być niemodyfikowalny i przeszukiwalny: kto zatwierdził, kiedy, co się zmieniło i jaką rolę/długość zatwierdzono. Ten ślad audytu to twoje źródło prawdy podczas przeglądów, incydentów i pytań od klientów — i zapobiega temu, by „tymczasowy” dostęp stał się niewidoczny.
Provisioning i dostęp ograniczony czasowo
Provisioning to moment, w którym „zatwierdzone na papierze” staje się „używalne w produkcie”. Dla konsultantów celem jest szybkość bez nadmiernej ekspozycji: daj tylko to, co potrzebne, tylko na czas potrzebny i ułatw zmiany, gdy praca się zmieni.
Zautomatyzuj ścieżkę domyślną
Zacznij od przewidywalnego, zautomatyzowanego przepływu powiązanego z zatwierdzonym żądaniem:
- Przydział roli: mapuj każdy typ zatwierdzonego zlecenia do roli (np. Finance Analyst – Read Only, Implementation Partner – Project Admin).
- Członkostwo w grupach: dodaj konsultanta do właściwych grup, aby uprawnienia były spójne w projektach.
- Uprawnienia do zasobów: automatycznie nadaj dostęp tylko do wskazanych projektów, workspace'ów lub zestawów danych — nie do całego tenant.
Automatyzacja powinna być idempotentna (bezpieczna do uruchomienia wielokrotnie) i powinna generować jasne „podsumowanie provisioningu” pokazujące, co przyznano.
Wspieraj kroki manualne (z checklistami)
Niektóre uprawnienia żyją poza twoją aplikacją (współdzielone dyski, narzędzia stron trzecich, środowiska zarządzane przez klientów). Gdy nie da się zautomatyzować, spraw, by praca manualna była bezpieczna:
- dostarcz krok po kroku checklistę z właścicielem, terminem i weryfikacją (np. „Potwierdź dostęp do folderu”, „Potwierdź profil VPN”, „Potwierdź kod rozliczeniowy”).
- wymagaj, aby wykonawca oznaczył każdy krok jako zrobiony i dołączył dowód, gdy to stosowne (link do ticketu, zrzut ekranu lub ID systemowe).
Dostęp ograniczony czasowo z przypomnieniami o odnowieniu
Każde konto konsultanta powinno mieć datę końcową przy tworzeniu. Wdróż:
- Auto-wygaśnięcie: dostęp cofany automatycznie w dacie końcowej (nie tylko „wyłączone teoretycznie”).
- Powiadomienia o odnowieniu: informuj konsultanta i sponsora wewnętrznego z wyprzedzeniem (np. 14 dni i 3 dni przed) z opcją jednego kliknięcia na żądanie odnowienia.
- Zasady karencji: unikaj cichych przedłużeń; jeśli praca ma trwać dalej, powinna przejść przez tę samą logikę zatwierdzania.
Zmiany w trakcie zlecenia: podwyższenia, zmiany zakresu, zawieszenia
Praca konsultanta ewoluuje. Wspieraj bezpieczne aktualizacje:
- Podwyższenia/obniżenia ról z opisem powodu i śladem zatwierdzeń.
- Zmiany zakresu (dodaj/usun projekty) bez konieczności ponownego onboardingu.
- Zawieszenia na czas przerwy (przegląd bezpieczeństwa, luka w kontrakcie), które zachowują historię, ale natychmiast usuwają dostęp.
Dzienniki audytu, monitoring i alerty
Automatyzuj wygaśnięcia i cofnięcia
Uczyń domyślnie dostęp czasowy, z planowanym wygaśnięciem i czystą logiką cofania dostępu.
Dzienniki audytu to twój „papierowy ślad” dla zewnętrznego dostępu: wyjaśniają, kto co zrobił, kiedy i skąd. W zarządzaniu dostępem konsultantów to nie tylko checkbox zgodności — to sposób na badanie incydentów, dowodzenie najmniejszego uprzywilejowania i szybkie rozwiązywanie sporów.
Praktyczny schemat dziennika audytu
Zacznij od spójnego modelu zdarzeń, który działa w całej aplikacji:
- actor: kto zainicjował akcję (ID użytkownika, rola, organizacja)
- target: co zostało dotknięte (ID projektu, ID pliku, ID użytkownika)
- action: kanoniczny czasownik (INVITE_SENT, ROLE_GRANTED, DATA_EXPORTED)
- timestamp: czas serwera (UTC)
- ip: IP źródłowe (plus user agent, jeśli dostępny)
- metadata: JSON z kontekstem (ID polityki, poprzednie/nowe wartości, kody powodów, ticket)
Trzymaj działania znormalizowane, żeby raportowanie nie stało się zgadywanką.
Zdarzenia warte logowania (minimum)
Loguj zarówno „zdarzenia bezpieczeństwa”, jak i „zdarzenia o wpływie biznesowym”:
- Zaproszenia wysłane/przyjęte/wygasłe, aktywacja konta, reset hasła
- Logowania, wylogowania, odświeżanie sesji, nieudane próby logowania
- Rejestracja/zmiana MFA, niepowodzenia MFA, błędy SSO
- Zmiany ról lub polityk (w tym kto zatwierdził i dlaczego)
- Dostęp do wrażliwych widoków, eksporty/pobrania i użycie kluczy API
- Działania administracyjne: dezaktywacja użytkownika, zmiana projektu, zmiany masowe
Monitoring i wyzwalacze alertów
Dzienniki audytu są użyteczne, gdy sparować je z alertami. Typowe wyzwalacze:
- Niezwykłe wzorce logowania (nowy kraj/urządzenie, niemożliwy travel, wzrost aktywności poza godzinami)
- Powtarzające się nieudane próby MFA lub logowania (możliwa kradzież konta)
- Eskalacja uprawnień (podwyższenie roli konsultanta, nadanie nowego admina)
- Duże lub powtarzające się eksporty, szczególnie z ograniczonych projektów
Eksport i retencja
Daj możliwość eksportu audytu w CSV/JSON z filtrami (zakres dat, actor, projekt, akcja) i zdefiniuj ustawienia retencji per politykę (np. domyślnie 90 dni, dłużej dla zespołów regulowanych). Udokumentuj dostęp do eksportów audytu jako uprzywilejowaną akcję (i loguj ją). Dla powiązanych kontroli zobacz /security.
Przeglądy dostępu i stałe zarządzanie
Przyznanie dostępu to tylko połowa zadania. Prawdziwe ryzyko narasta cicho przez czas: konsultanci kończą projekt, zmieniają zespoły lub przestają się logować — a ich konta dalej działają. Stałe zarządzanie to sposób, żeby „tymczasowy” dostęp nie stał się permanentny.
Stwórz pulpity przeglądowe, których ludzie będą używać
Utwórz prosty widok przeglądu dla sponsorów i właścicieli projektów, który za każdym razem odpowiada na te same pytania:
- Aktywni konsultanci według projektu i roli
- Ostatnia aktywność (i ostatnia wrażliwa akcja, jeśli istotne)
- Data wygaśnięcia dostępu i pozostały czas
- Oczekujące zatwierdzenia, odnowienia i wyjątki
Skup dashboard na najważniejszym. Przeglądający powinien móc powiedzieć „zachowaj” lub „usuń” bez otwierania pięciu różnych stron.
Dodaj attestation (potwierdzenia właściciela)
Zaplanuj potwierdzenia — miesięcznie dla systemów wysokiego ryzyka, kwartalnie dla niższego ryzyka — gdzie właściciel potwierdza, że każdy konsultant dalej potrzebuje dostępu. Uczyń decyzję jednoznaczną:
- Ponowne zatwierdzenie na określony okres (np. 30/60/90 dni)
- Obniżenie roli (zasada najmniejszego uprzywilejowania)
- Cofnięcie dostępu
Aby zmniejszyć biurokrację, ustaw domyślnie „wygasa, chyba że potwierdzone” zamiast „kontynuuje bez końca”. Powiąż potwierdzenia z rozliczalnością, zapisując kto potwierdził, kiedy i na jak długo.
Używaj reguł nieaktywności bez przerywania pracy
Nieaktywność to silny sygnał. Wdróż reguły typu „zawieś po X dniach bez logowania”, ale dodaj krok uprzejmy:
- Powiadom sponsora/właściciela przed zawieszeniem lub cofnięciem
- Daj opcję jednego kliknięcia „przedłuż” z nową datą wygaśnięcia
- Automatycznie cofnij, jeśli brak odpowiedzi
To zapobiega cichym ryzykom, unikając jednocześnie niespodziewanych blokad.
Śledź wyjątki i przeglądaj je okresowo
Niektórzy konsultanci będą potrzebować nietypowego dostępu (więcej projektów, szersze dane, dłuższy czas). Traktuj wyjątki jako tymczasowe z definicji: wymagaj uzasadnienia, daty końcowej i zaplanowanego ponownego sprawdzenia. Twój dashboard powinien wyróżniać wyjątki osobno, aby nigdy nie zostały zapomniane.
Jeśli potrzebujesz praktycznego następnego kroku, odwołaj się do obszaru administracyjnego, np. /admin/access-reviews, i ustaw go jako domyślną stronę startową dla sponsorów.
Offboarding: cofanie dostępu, które faktycznie działa
Offboarding zewnętrznych konsultantów to nie tylko „wyłącz konto”. Jeśli tylko usuniesz rolę w aplikacji, ale pozostawisz sesje, klucze API, współdzielone foldery czy sekrety, dostęp może utrzymywać się długo po zakończeniu współpracy. Dobra aplikacja traktuje offboarding jako powtarzalną procedurę z jasnymi wyzwalaczami, automatyzacją i weryfikacją.
Zdefiniuj jasne wyzwalacze offboardingu
Zacznij od decyzji, jakie zdarzenia automatycznie uruchamiają przepływ offboardingu. Typowe wyzwalacze:
- Data zakończenia umowy (zapasowa w systemie)
- Zamknięcie projektu (projekt oznaczony jako „closed”)
- Naruszenia polityki (incydent bezpieczeństwa, negatywny wynik przeglądu dostępu, żądanie HR/prawne)
System powinien uczynić te wyzwalacze jawne i audytowalne. Na przykład: rekord kontraktu z datą końcową lub zmiana stanu projektu tworząca zadanie „Wymagany offboarding”.
Automatyzuj cofanie, nie tylko „usuń uprawnienia”
Cofanie musi być kompleksowe i szybkie. Co najmniej zautomatyzuj:
- Dezaktywację konta (lub oznaczenie jako nieaktywne) w twojej aplikacji
- Usunięcie wszystkich ról/grup nadających dostęp do projektów, danych lub funkcji administracyjnych
- Odwołanie aktywnych sesji i tokenów (sesje webowe, refresh tokeny, tokeny API)
Jeśli wspierasz SSO, pamiętaj, że samo zakończenie połączenia SSO może nie zakończyć istniejących sesji w aplikacji. Nadal potrzebujesz odwołania sesji po stronie serwera, żeby konsultant nie mógł dalej pracować z już uwierzytelnionej przeglądarki.
Przekazanie danych i czyszczenie sekretów
Offboarding to też moment porządkowania danych. Stwórz checklistę, żeby nic nie zostało w prywatnych skrzynkach czy prywatnych dyskach.
Typowe elementy do objęcia:
- Deliverables i artefakty pracy: upewnij się, że są wgrane do przestrzeni projektu i że własność została przypisana do wewnętrznego użytkownika
- Rotacja poświadczeń: obróć hasła, klucze API i konta serwisowe, do których konsultant mógł mieć dostęp
- Czyszczenie współdzielonych sekretów: usuń je z vaultów, współdzielonych folderów, list dystrybucyjnych i kanałów czatu
Jeśli twój portal obsługuje przesył plików lub ticketing, rozważ krok „Export handover package”, który pakuje istotne dokumenty i linki dla wewnętrznego właściciela.
Zweryfikuj zamknięcie z finalnym zapisem audytu
Skuteczne cofnięcie zawiera weryfikację. Nie polegaj na „powinno być dobrze” — zapisz, że to się stało.
Przydatne kroki weryfikacyjne:
- Potwierdź, że konsultant ma zero aktywnych ról i brak członkostw w projektach
- Potwierdź, że wszystkie sesje/tokeny zostały odwołane i żadne tokeny nie są już ważne
- Utwórz finalne zdarzenie offboardingu w audycie (kto to zainicjował, kiedy to się wykonało, co usunięto, jakie były wyjątki)
Ten końcowy wpis audytu wykorzystasz podczas przeglądów dostępu, śledztw incydentów i kontroli zgodności. Zamienia offboarding z nieformalnego zadania w niezawodny kontrolny proces.
Plan implementacji: API, UI, testy i wdrożenie
Skonfiguruj zatwierdzenia end-to-end
Stwórz przepływy żądań, zatwierdzeń i provisioning, które odpowiadają twoim zasadom i potrzebom audytu.
To plan budowy, który zamienia politykę dostępu w działający produkt: mały zestaw API, prosty interfejs admina/przeglądającego i wystarczająco testów oraz higieny wdrożeniowej, by dostęp nie zawiódł w ciszy.
Jeśli chcesz szybko pokazać pierwszą wersję interesariuszom, podejście vibe-coding może być skuteczne: opisujesz workflow, role i ekrany, a iterujesz od działającego oprogramowania zamiast od wireframów. Na przykład Koder.ai może pomóc zespołom prototypować portal dla użytkowników zewnętrznych (React UI, Go backend, PostgreSQL) z czatu jako specyfikacją, a potem dopracować zatwierdzenia, zadania wygaszeń i widoki audytu ze snapshotami/rollbackem oraz eksportem kodu, gdy będziesz gotowy wejść w formalne SDLC.
Powierzchnia API (utrzymuj ją prostą i spójną)
Zaprojektuj endpointy wokół obiektów, które już zdefiniowałeś (users, roles, projects, policies) i workflowu (requests → approvals → provisioning):
- Users & roles:
GET /api/users,POST /api/users,GET /api/roles,POST /api/roles - Access requests:
POST /api/access-requests,GET /api/access-requests?status=pending - Approvals:
POST /api/access-requests/{id}/approve,POST /api/access-requests/{id}/deny - Provisioning/expiry:
POST /api/grants,PATCH /api/grants/{id}(extend/revoke),GET /api/grants?expires_before=... - Audit:
GET /api/audit-logs?actor=...&project=...(tylko do odczytu; nigdy nie „edytuj” logów)
Po stronie UI dąż do trzech ekranów:
- Portal konsultanta (co ma dostęp, data wygaśnięcia, żądanie dostępu)
- Skrzynka zatwierdzającego
- Konsola administracyjna (role, polityki, przydziały, wyszukiwanie audytu)
Podstawy bezpieczeństwa, które wdrażasz wszędzie
Waliduj wejście na każdym endpointcie zapisu, wymuszaj ochronę CSRF dla sesji opartych na ciasteczkach i dodaj rate limiting do logowań, tworzenia żądań i wyszukiwania audytu.
Jeśli obsługujesz przesyłanie plików (np. umowy), używaj listy dozwolonych MIME types, skanowania antywirusowego, limitów rozmiaru i przechowuj pliki poza web rootem z losowymi nazwami.
Plan testów (błędy uprawnień to błędy produktu)
Pokryj testami:
- testy uprawnień: „może/nie może” według roli, projektu i ograniczeń polityk
- testy workflow: request → approve → utworzony grant → powiadomienia
- testy bazujące na czasie: dostęp kończy się po expiry, a „extend” wymaga zatwierdzenia
Notatki o wdrożeniu
Oddziel środowiska dev/staging/prod, zarządzaj sekretami w vault (nie w plikach env w git) i szyfruj kopie zapasowe. Dodaj zadanie cykliczne do wygaszania/cofania i alert, jeśli ono zawiedzie.
Jeśli chcesz listę kontrolną, odwołaj się do /blog/access-review-checklist, a szczegóły cen/planów trzymaj na /pricing.
Ostateczna lista kontrolna: jak wygląda „dobrze”
Aplikacja do dostępu konsultantów działa, gdy za każdym razem daje te same rezultaty:
- Każdy konsultant ma unikalną tożsamość, MFA i zakres związany z projektem.
- Każde nadanie dostępu ma właściciela, zatwierdzającego, uzasadnienie i datę końcową.
- Wygaszenia i cofnięcia są zautomatyzowane (łącznie z unieważnieniem sesji/tokenów).
- Wyjątki są widoczne, ograniczone czasowo i poddawane ponownym przeglądom.
- Logi są wystarczająco spójne, by badać incydenty bez zgadywania.
Zbuduj najmniejszą wersję, która wymusza te invariants, a potem iteruj nad wygodą (dashboardy, operacje masowe, bogatsze polityki) bez osłabiania podstawowych kontroli.