Wyjaśnij problem zależności, który chcesz rozwiązać
Zanim zaprojektujesz ekrany lub wybierzesz stack technologiczny, sprecyzuj, co w Twojej organizacji oznacza „zależność”. Jeśli ludzie używają tego słowa do opisania wszystkiego, Twoja aplikacja na końcu niczego nie będzie śledzić dobrze.
Zdefiniuj „zależność” prostym językiem
Napisz jednowierszową definicję, którą każdy będzie potrafił powtórzyć, a potem wypisz, co się kwalifikuje. Częste kategorie to:
- Element pracy: inny zespół musi zbudować funkcję, naprawić błąd lub dostarczyć ticket.
- Dostarczalny wynik: dokument, zestaw danych, projekt lub zasób potrzebny do postępu.
- Decyzja: porozumienie lub zatwierdzenie, które odblokowuje implementację.
- Środowisko/dostęp: poświadczenia, infrastruktura, środowiska testowe lub zgody.
Zdefiniuj też, co nie jest zależnością (np. „ulepszenia miłe do mieć”, ogólne ryzyka czy zadania wewnętrzne, które nie blokują innego zespołu). To utrzymuje system w porządku.
Określ, dla kogo jest aplikacja
Śledzenie zależności zawodzi, jeśli jest zbudowane tylko dla PM-ów albo tylko dla inżynierów. Wymień głównych użytkowników i co każdy potrzebuje w 30 sekund:
- Liderzy zespołów / managerowie inżynierii: co blokuje dostawę i kto wykonuje następny krok.
- PM-y / program managerowie: terminy przekazania, zobowiązania i ścieżki eskalacji.
- Inżynierowie: dokładne żądanie, kontekst i kryteria akceptacji.
- Kierownictwo / operacje: przewidywalność dostaw, mniej niespodzianek i raporty trendowe.
Wybierz mierzalne cele sukcesu
Wybierz niewielki zestaw wyników, np.:
- Mniej „niespodziewanych blockerów” odkrywanych późno w sprincie lub cyklu wydania
- Krótszy czas od utworzenia zależności → przypisania właściciela
- Wyższy odsetek terminowych przekazań względem uzgodnionych terminów
- Jasna własność (mniej pozycji z przypisaniem „TBD”)
Wypisz bolączki, które chcesz usunąć
Zarejestruj problemy, które aplikacja musi rozwiązać od pierwszego dnia: przestarzałe arkusze, niejasni właściciele, pominięte daty, ukryte ryzyka i statusy rozproszone po wątkach czatu.
Zamapuj typy zależności, stany i definicje
Gdy zgodzisz się, co śledzisz i dla kogo, ustal słownictwo i cykl życia. Wspólne definicje zamieniają „listę ticketów” w system, który redukuje blokery.
Zacznij od typów zależności, które będziesz wspierać
Wybierz mały zestaw typów, które pokrywają większość realnych sytuacji, i spraw, by każdy typ był łatwy do rozpoznania:
- Blocked-by: Zespół A nie może dostarczyć, dopóki Zespół B czegoś nie ukończy.
- Provides-to: Zespół B dostarcza artefakt/usługę, którą Zespół A wykorzysta.
- Waiting-on: Podobne do blocked-by, ale często ograniczone czasowo (zatwierdzenie, dostęp, decyzja).
- Wspólny zasób: Zespoły konkurują o tych samych ludzi, środowisko, budżet lub dostawcę.
- Ograniczenie sekwencji: Prace muszą odbyć się w konkretnej kolejności, nawet jeśli żaden zespół nie jest bezpośrednio „zablokowany”.
Celem jest spójność: dwie osoby powinny sklasyfikować tę samą zależność tak samo.
Zdefiniuj minimalne atrybuty (i egzekwuj je)
Rekord zależności powinien być mały, ale wystarczająco kompletny, by zarządzać nim:
- Zespół właściciel (odpowiedzialny za dostarczenie)
- Zespół zgłaszający (potrzebuje wyniku)
- Data ukończenia (kiedy zgłaszający tego potrzebuje)
- Status (zobacz cykl życia poniżej)
- Poziom ryzyka (np. Niski/Średni/Wysoki)
- Notatki (kontekst, założenia)
- Linki do źródłowej pracy (zadanie Jira, dokument, PR, incydent itp.)
Jeśli pozwolisz tworzyć zależność bez zespołu właścicielskiego lub daty ukończenia, tworzysz „tracker obaw”, a nie narzędzie koordynacyjne.
Uzgodnij stany cyklu życia i co je wywołuje
Użyj prostego modelu stanów, który odzwierciedla faktyczną pracę zespołów:
Proposed → Accepted → In progress → Ready → Delivered/Closed, plus Rejected.
Spisz reguły zmiany stanu. Na przykład: „Accepted wymaga przypisanego zespołu właścicielskiego i początkowej daty docelowej” albo „Ready wymaga dowodu”.
Spraw, by „zrobione” było jednoznaczne
Dla zamknięcia wymaga się wszystkich poniższych:
- Kryteria akceptacji: co liczy się za kompletne
- Zatwierdzenie: kto to potwierdza (imię/zespół)
- Dowód/link: PR, release note, zrzut ekranu, dokument lub ticket
- Znacznik czasu: kiedy zostało zaakceptowane/zamknięte
Te definicje staną się podstawą filtrów, przypomnień i przeglądów statusów później.
Zaprojektuj prosty model danych, który się skaluje
Tracker zależności odnosi sukces lub porażkę w zależności od tego, czy ludzie mogą opisać rzeczywistość bez walki z narzędziem. Zacznij od małego zestawu obiektów, które odpowiadają językowi zespołów, a strukturę dodawaj tam, gdzie zapobiega nieporozumieniom.
Główne obiekty (nie przesadzaj)
Użyj garstki podstawowych rekordów:
- Zespół: grupa, która posiada pracę lub dostarcza zależność.
- Projekt/Inicjatywa: kontener pracy z jasnym celem.
- Element pracy: jednostka wykonawcza (funkcja, zadanie, epic, link do ticketu).
- Zależność: obietnica między zgłaszającym a dostawcą.
- Kamień milowy/Release: punkt kontrolny zależny od daty, który może być blokowany przez zależności.
Unikaj tworzenia osobnych typów dla każdego przypadku brzegowego. Lepiej dodać kilka pól (np. „type: data/API/approval”) niż zbyt wcześnie rozdzielać model.
Relacje, które odzwierciedlają rzeczywistą koordynację
Zależności często angażują wiele grup i wiele zadań. Modeluj to jawnie:
- Zespoły ↔ Zależności: wiele-do-wielu (zależność może mieć wielu dostawców; zespół może być w wielu zależnościach).
- Zależności ↔ Elementy pracy: wiele-do-wielu (jedna zależność może blokować kilka elementów pracy; jeden element może zależeć od kilku zależności).
To zapobiega kruchemu myśleniu „jedna zależność = jeden ticket” i umożliwia raportowanie zbiorcze.
Audytowalność: spraw, by zmiany były zaufane
Każdy główny obiekt powinien zawierać pola audytu:
- Utworzone przez / utworzono w, zaktualizowane przez / zaktualizowano w
- Historia zmian (co i kiedy się zmieniło)
- Komentarze (decyzje i kontekst)
- Załączniki/linki (specyfikacje, dokumenty, zadania Jira, notatki ze spotkań)
Lekka obsługa zależności zewnętrznych
Nie każda zależność ma zespół w Twojej strukturze organizacyjnej. Dodaj rekord Owner/Contact (imię, organizacja, email/Slack, notatki) i pozwól, by zależności wskazywały na niego. To utrzymuje blokery od dostawców lub innych działów widoczne bez wpychania ich do wewnętrznego katalogu zespołów.
Zdefiniuj role, własność i uprawnienia
Jeśli role nie są jawne, śledzenie zależności zmienia się w wątek komentarzy: każdy zakłada, że ktoś inny jest odpowiedzialny, a daty są „dostosowywane” bez kontekstu. Jasny model ról utrzymuje zaufanie do aplikacji i czyni eskalacje przewidywalnymi.
Podstawowe role (prosto)
Zacznij od czterech codziennych ról i jednej roli administracyjnej:
- Requester: tworzy prośbę i dostarcza „dlaczego”, wymagane daty oraz kryteria akceptacji.
- Owner: jedna osoba odpowiedzialna za dostarczenie (lub formalne odrzucenie) zależności.
- Approver: potwierdza zobowiązanie, gdy zależność wpływa na pojemność, zakres lub plan wydania.
- Viewer: może obserwować postęp i komentować, ale nie zmieniać zobowiązań.
- Admin: zarządza konfiguracją (zespoły, uprawnienia, szablony), nie podejmuje decyzji dnia codziennego.
Zasady własności, które zapobiegają niejasnościom
Zrób właściciela wymaganym i jednoznacznym: jedna zależność, jeden odpowiedzialny właściciel. Nadal możesz wspierać współpracowników (kontrybutorów z innych zespołów), ale nie powinni oni zastępować odpowiedzialności.
Dodaj ścieżkę eskalacji, gdy właściciel nie odpowiada: najpierw ping do właściciela, potem do jego managera (lub lidera zespołu), potem do właściciela programu/release — zgodnie ze strukturą organizacyjną.
Uprawnienia: chroń zobowiązania, nie widoczność
Oddziel „edycję szczegółów” od „zmiany zobowiązań”. Praktyczny domyślny zestaw:
- Requester może tworzyć, dodawać kontekst i proponować daty; nie może ustawić „Committed” bez akceptacji.
- Owner może aktualizować status, dodawać notatki dostawy i proponować nowe daty; zamknąć może tylko, gdy kryteria akceptacji są spełnione.
- Approver może ustawić stany zobowiązań (Committed/Rejected) i zatwierdzać zmiany dat.
- Viewer widzi i komentuje; nie edytuje.
Jeśli wspierasz prywatne inicjatywy, zdefiniuj, kto je widzi (np. tylko zaangażowane zespoły + Admin). Unikaj „sekretnych zależności”, które zaskakują zespoły wykonawcze.
Wskazówki RACI w UI
Nie chowaj odpowiedzialności w dokumencie polityki. Pokaż ją na każdej zależności:
- Accountable (A): Owner
- Responsible (R): Współpracownicy (opcjonalnie)
- Consulted (C): Approver i zespoły dotknięte zmianą
- Informed (I): Viewers/watchers
Oznaczenie „Accountable vs Consulted” bezpośrednio w formularzu redukuje błędne skierowanie spraw i przyspiesza przeglądy statusów.
Zaplanuj UX: widoki, z których zespoły faktycznie będą korzystać
Tracker zależności działa tylko wtedy, gdy ludzie znajdują swoje elementy w kilka sekund i aktualizują je bez zastanawiania. Projektuj wokół najczęstszych pytań: „Co ja blokuję?”, „Co mnie blokuje?” i „Czy coś zaraz się przesunie?”.
Kluczowe ekrany do wypuszczenia wcześnie
Zacznij od małego zestawu widoków, które odzwierciedlają sposób, w jaki zespoły mówią o pracy:
- Lista zależności: filtrowalna tabela „wszystkie otwarte zależności” z szybkimi akcjami.
- Szczegóły zależności: jedno miejsce z prośbą, statusem, właścicielami, datami i historią.
- Widok zespołu: wszystko, co zespół jest winien i na co czeka, z jasnymi priorytetami.
- Widok inicjatywy: zależności pogrupowane pod projektem/release, aby liderzy widzieli ryzyko.
- Oś czasu: lekki widok dat dla terminów i przekazań (prosty — to nie ma być pełne narzędzie Gantta).
Ułatwiaj tworzenie i aktualizacje
Większość narzędzi zawodzi przy „codziennych aktualizacjach”. Optymalizuj pod szybkość:
- Szablony i pola domyślne (popularne typy zależności, wstępnie ustawione reguły SLA/dat)
- Edycja inline na listach i stronach szczegółów (bez modalnych formularzy dla prostych zmian)
- Kontrolki przyjazne klawiaturze dla zaawansowanych użytkowników (kolejność tabulacji, szybkie zapisy, przewidywalne skróty)
Spraw, by status był nie do pomylenia
Używaj koloru plus etykiety tekstowej (nigdy tylko koloru) i trzymaj słownictwo spójne. Dodaj widoczny „Ostatnia aktualizacja” na każdej zależności oraz ostrzeżenie o przestarzałości, gdy nie była edytowana przez określony czas (np. 7–14 dni). To zachęca do aktualizacji bez wymuszania spotkań.
Zmniejsz liczbę spotkań przez rejestrowanie kontekstu
Każda zależność powinna mieć jeden wątek, który zawiera:
- Komentarze i aktualizacje postępu
- Decyzje (z datą i kto się zgodził)
- Linki do wspierającej pracy (tickety, dokumenty)
Gdy strona szczegółów opowiada pełną historię, przeglądy statusów są szybsze — i wiele „szybkich synchronizacji” znika, bo odpowiedź jest już zapisana.
Zbuduj workflowy dla zgłoszeń, aktualizacji i zamknięć
Rozszerz poza web
Dodaj aplikację mobilną Flutter do szybkich aktualizacji i akceptacji w podróży.
Tracker zależności odnosi sukces lub porażkę w codziennych działaniach, które wspiera. Jeśli zespoły nie potrafią szybko poprosić, odpowiedzieć jasnym zobowiązaniem i zamknąć sprawę z dowodem, aplikacja stanie się tablicą „do wiadomości”, a nie narzędziem wykonawczym.
Podstawowy workflow: request → decision → commitment
Zacznij od jednego flow „Utwórz prośbę”, który rejestruje, co zespół dostarczający musi zrobić, dlaczego to ważne i kiedy jest potrzebne. Trzymaj strukturę: proponowana data, kryteria akceptacji i link do epica/specyfikacji.
Następnie wymuszaj jawny stan odpowiedzi:
- Accept (zobowiązanie do daty)
- Decline (wymagane uzasadnienie)
- Propose new date (contra-oferta z wyjaśnieniem)
To zapobiega najczęstszemu błędowi: cichym „może” zależnościom, które wyglądają ok, dopóki nie wybuchną.
Oczekiwania w stylu SLA, które zapobiegają przestarzałości
Zdefiniuj lekkie oczekiwania w samym workflowie. Przykłady:
- Odpowiedź w ciągu X dni roboczych od utworzenia prośby
- Częstotliwość aktualizacji (np. co tydzień, albo za każdym razem, gdy status się zmienia)
- Oznacz jako stare jeśli brak aktualizacji przez Y dni i data ukończenia jest w ciągu Z dni
Celem nie jest kontrola; celem jest utrzymanie zobowiązań aktualnych, by planowanie było uczciwe.
Aktualizacje z kontrolą zmian (bez biurokracji)
Pozwól zespołom ustawić zależność jako At risk z krótką notatką i następnym krokiem. Gdy ktoś zmienia datę lub status, wymagaj powodu (lista wyboru + wolny tekst). Ta jedna zasada tworzy ścieżkę audytu, która sprawia, że retrospektywy i eskalacje są faktograficzne, nie emocjonalne.
Zamknięcie, które udowadnia wykonanie pracy
„Zamknij” powinno znaczyć, że zależność jest zaspokojona. Wymagaj dowodu: link do scalonego PR, wydanego ticketu, dokumentu lub notatki zatwierdzającej. Jeśli zamknięcie jest niejasne, zespoły będą wcześnie „zazieleniać” pozycje, żeby zmniejszyć szum.
Akcje zbiorcze na potrzeby cotygodniowego planowania
Wspieraj masowe aktualizacje podczas przeglądów statusów: zaznacz kilka zależności i ustaw ten sam status, dodaj wspólną notatkę (np. „przeplanowane po resecie Q1”) lub poproś o aktualizacje. To sprawia, że aplikacja jest wystarczająco szybka, by używać jej na spotkaniach, nie tylko po nich.
Dodaj alerty i powiadomienia bez tworzenia spamu
Powiadomienia mają chronić dostawy, nie rozpraszać ludzi. Najłatwiej stworzyć hałas, powiadamiając wszystkich o wszystkim. Zamiast tego projektuj alerty wokół punktów decyzyjnych (ktoś musi zareagować) i sygnałów ryzyka (coś się przesuwa).
Zacznij od małego zestawu wartościowych wyzwalaczy
Skup pierwszą wersję na zdarzeniach, które zmieniają plan lub wymagają odpowiedzi:
- Nowa prośba utworzona (zespół właścicielski otrzymuje powiadomienie)
- Wymagana akceptacja (zależność przypisana i czeka na potwierdzenie)
- Zmiana daty (jedna ze stron zmienia obiecaną/potrzebną datę)
- Status at risk / blocked (podniesiono flagę ryzyka)
- Przestarzałe aktualizacje (brak aktualizacji przez X dni dla aktywnej zależności)
Każdy wyzwalacz powinien wskazywać jasny następny krok: zaakceptuj/odrzuć, zaproponuj nową datę, dodaj kontekst lub eskaluj.
Dostarczaj przez kanały, które zespoły już sprawdzają
Domyślnie dawaj powiadomienia w aplikacji (żeby alerty były powiązane z rekordem) plus email dla rzeczy, które nie mogą czekać.
Oferuj opcjonalne integracje czatowe — Slack lub Microsoft Teams — ale traktuj je jako mechanizmy dostarczania, nie system źródłowy. Wiadomości czatowe powinny linkować głęboko do elementu (np. /dependencies/123) i zawierać minimum kontekstu: kto musi działać, co się zmieniło i do kiedy.
Zmniejsz hałas przez preferencje i digesty
Daj kontrolę na poziomie zespołu i użytkownika:
- natychmiastowe alerty dla akceptacji, zablokowanych, przeterminowanych
- tryb digest (codzienny/tygodniowy) dla niskiego priorytetu, jak drobne przesunięcia lub komentarze
- grupowanie i deduplikacja (jedno podsumowanie na zależność w okienku czasowym)
To też miejsce, gdzie „watcherzy” mają znaczenie: powiadamiaj requestera, zespół właścicielski i explicite dodanych interesariuszy — unikaj szerokich broadcastów.
Eskaluj tylko, gdy wzorce wskazują ryzyko
Eskalacja powinna być zautomatyzowana, ale konserwatywna: alarmuj, gdy zależność jest przeterminowana, gdy data jest wielokrotnie przesuwana, lub gdy zablokowany status nie ma aktualizacji przez określony czas.
Kieruj eskalacje na odpowiedni poziom (lider zespołu, program manager) i dołącz historię, żeby odbiorca mógł działać szybko bez gonienia kontekstu.
Wybierz integracje, które usuwają powtarzanie pracy
Najpierw zdefiniuj workflow
Użyj trybu planowania, aby zdefiniować role, statusy i pola wymagane zanim zbudujesz ekrany.
Integracje mają eliminować przepisywanie, nie zwiększać nakładu konfiguracji. Najbezpieczniej zacząć od systemów, którym zespoły już ufają (trackery issue, kalendarze, tożsamość), utrzymać pierwszą wersję jako read-only lub jednokierunkową, a rozszerzać dopiero gdy ludzie będą z niej korzystać.
Zacznij od jednego trackera zadań
Wybierz główny tracker (Jira, Linear lub Azure DevOps) i wspieraj prosty flow o nastawieniu „link-first”:
- Rekord zależności przechowuje URL i klucz trackera (np.
PROJ-123).
- Twoja aplikacja cyklicznie pobiera status (Open/In Progress/Done), assignee i datę ukończenia.
- Aktualizacje pozostają w trackerze początkowo; Twoja aplikacja je odzwierciedla.
To unika „dwóch źródeł prawdy”, a jednocześnie daje widoczność zależności. Później dodaj opcjonalną synchronizację dwukierunkową dla małego podzbioru pól (status, data) z jasnymi regułami konfliktu.
Dodaj kamienie milowe z kalendarzy (najpierw tylko do odczytu)
Kamienie milowe i terminy często przechowywane są w Google Calendar lub Microsoft Outlook. Zacznij od czytania wydarzeń do osi czasu zależności (np. „Release Cutoff”, „UAT Window”) bez zapisu w kalendarzu.
Synchronizacja tylko do odczytu pozwala zespołom zachować planowanie tam, gdzie już to robią, podczas gdy Twoja aplikacja pokazuje wpływy i nadchodzące daty w jednym miejscu.
Ułatw dostęp przez SSO
Single sign-on zmniejsza tarcie przy onboardingu i dryf uprawnień. Wybierz w oparciu o realia klienta:
- Google Workspace (często dla mniejszych organizacji)
- Microsoft Entra ID (często w enterprise)
- Okta (często w środowiskach mieszanych)
Jeśli jesteś wczesnym etapem, wypuść jednego dostawcę najpierw i udokumentuj, jak prosić o inne.
Oferuj małe, dobrze udokumentowane API i webhooks
Nawet nietechniczne zespoły korzystają, gdy ops potrafi automatyzować przekazania. Dostarcz kilka endpointów i event hooków z przykładami kopiuj-wklej.
curl -X POST /api/dependencies \\
-H "Authorization: Bearer $TOKEN" \\
-d '{"title":"API contract from Payments","trackerUrl":"https://jira/.../PAY-77"}'
Webhooks jak dependency.created i dependency.status_changed pozwalają zespołom integrować się z narzędziami wewnętrznymi bez czekania na Twój roadmap. Dla więcej informacji odwołaj się do /docs/integrations.
Twórz dashboardy i raporty do przeglądów statusów
Dashboardy to miejsce, gdzie aplikacja do śledzenia zależności zarabia swoje miejsce: zamienia „myślę, że jesteśmy zablokowani” w jasny, wspólny obraz tego, co wymaga uwagi przed kolejnym spotkaniem.
Dashboardy dla różnych odbiorców
Jeden uniwersalny dashboard zwykle zawodzi. Zamiast tego zaprojektuj kilka widoków odpowiadających temu, jak prowadzi się spotkania:
- Widok lidera zespołu: pokazuje zależności, które Twój zespół jest winien i na co czeka, z naciskiem na daty, aktualny status i następny krok.
- Widok programu: grupuje zależności według inicjatywy/release i uwypukla wąskie gardła międzyzespołowe (gdzie wiele elementów czeka na ten sam zespół lub kamień milowy).
- Podsumowanie dla kierownictwa: kompaktowy roll-up: łączna liczba otwartych zależności, ile jest w ryzyku, co jest nowo przeterminowane i top 3 blockerów. Ma być czytelne w mig.
Raporty, które napędzają decyzje (nie robótkę papierkową)
Zbuduj kilka raportów, których ludzie rzeczywiście będą używać na przeglądach:
- Przeterminowane zależności: posortowane po dniach zaległości i wadze/ryzyku.
- Top blokujące zespoły: kto ma najwięcej zależności oczekujących na niego (i trendy w czasie).
- Nadchodzące kamienie milowe w ryzyku: kamienie milowe w najbliższych 2–4 tygodniach z otwartymi lub oznaczonymi „at risk” zależnościami.
Każdy raport powinien odpowiadać: „Kto ma co zrobić dalej?” Dołącz właściciela, oczekiwaną datę i ostatnią aktualizację.
Filtry, które mają znaczenie
Ułatw szybkie filtrowanie, bo większość spotkań zaczyna się od „pokaż mi tylko…”.
Wspieraj filtry takie jak zespół, inicjatywa, status, zakres dat, poziom ryzyka i tagi (np. „przegląd bezpieczeństwa”, „umowa danych”, „release train”). Zapisz popularne zestawy filtrów jako nazwy widoków (np. „Release A — następne 14 dni”).
Eksport i udostępnianie
Nie wszyscy będą żyć w Twojej aplikacji cały dzień. Zapewnij:
- Eksport CSV dla analizy i jednorazowego udostępniania.
- Udostępnialne linki do przefiltrowanego dashboardu lub raportu (np. widok programu na cotygodniowy sync). Trzymaj linki wewnętrzne i stabilne, jak /reports/overdue?team=payments.
Jeśli oferujesz płatny plan, zachowaj kontrolę administracyjną nad udostępnianiem i powiąż szczegóły z /pricing.
Wybierz praktyczny stack technologiczny i architekturę
Nie potrzebujesz złożonej platformy, by wypuścić tracker zależności. MVP może być prostym systemem trójwarstwowym: UI webowe dla ludzi, API dla reguł i integracji oraz baza danych jako źródło prawdy. Optymalizuj pod „łatwe do zmiany” zamiast „idealne”. Nauczysz się więcej z rzeczywistego użycia niż z miesięcy projektowania architektury.
Prosty stos dla MVP
Pragmatyczny start może wyglądać tak:
- Web UI: React, Vue lub strony renderowane po stronie serwera (Rails/Django) jeśli chcesz szybsze CRUD.
- API: Node (Express/Nest), Python (FastAPI/Django) lub Rails — wybierz to, co Twój zespół już wspiera.
- Baza danych: Postgres to zwykle najlepszy domyślny wybór dla relacyjnych danych jak zależności, właściciele, statusy i znaczniki czasu.
Jeśli spodziewasz się integracji Slack/Jira wkrótce, trzymaj integracje jako oddzielne moduły/zadania, które rozmawiają z tym samym API, zamiast pozwalać narzędziom zewnętrznym pisać bezpośrednio do bazy.
Jeśli chcesz szybko uzyskać działający produkt bez budowy wszystkiego od zera, workflow vibe-coding może pomóc: na przykład Koder.ai potrafi wygenerować UI React i backend Go + PostgreSQL z czatu, a potem pozwala iterować używając trybu planowania, snapshotów i rollbacków. Nadal jesteś właścicielem decyzji architektonicznych, ale skracasz drogę od wymagań do użytecznego pilotażu i możesz wyeksportować kod, gdy będziesz gotowy przejąć rozwój do środka.
Techniczne podstawy, za które będziesz wdzięczny
- Uwierzytelnianie: SSO (SAML/OIDC) jeśli dostępne; w przeciwnym razie bezpieczny login emailowy.
- Logowanie: strukturalne logi żądań plus śledzenie błędów, by debugować „dlaczego to się zmieniło?”
- Limitowanie ruchu: chroń API przed głośnymi integracjami i pętlami.
- Kopie zapasowe: automatyczne codzienne backupy i przetestowane restore (nie pomijaj testu przywracania).
Wydajność i higiena danych
Większość ekranów to widoki list: otwarte zależności, blokery według zespołu, zmiany w tym tygodniu. Projektuj z myślą o tym:
- Dodaj indeksy dla typowych filtrów (status, zespół właścicielski, data ukończenia, updated_at).
- Używaj paginacji wszędzie.
- Zapewnij wyszukiwanie (podstawowy full-text w Postgres często wystarczy).
Prywatność i zaufanie
Dane o zależnościach mogą zawierać wrażliwe szczegóły dostaw. Stosuj zasadę najmniejszych uprawnień (widoczność na poziomie zespołu tam, gdzie to stosowne) i prowadź logi audytu dla edycji — kto co zmienił i kiedy. Ten ślad audytu zmniejsza spory na przeglądach statusów i sprawia, że narzędzie wydaje się wiarygodne.
Plan wdrożenia: pilotaż, migracja i napędzenie adopcji
Zamień wymagania w aplikację
Opisz swój tracker zależności na czacie i wygeneruj starter aplikacji React, Go i Postgres.
Wdrażanie aplikacji do śledzenia zależności to mniej kwestia funkcji, a bardziej zmiany nawyków. Traktuj wdrożenie jak launch produktu: zacznij od małego, pokaż wartość, a potem skaluj z jasnym rytuałem operacyjnym.
1) Zacznij od skoncentrowanego pilota
Wybierz 2–4 zespoły pracujące nad jedną wspólną inicjatywą (np. release train lub program dla jednego klienta). Zdefiniuj kryteria sukcesu mierzalne w kilka tygodni:
- Mniej „nieznanych” blockerów podczas przeglądów statusu
- Krótszy czas od zgłoszenia zależności do przypisania właściciela
- Wyższy odsetek terminowych przekazań dla pilota
Trzymaj konfigurację pilota minimalną: tylko pola i widoki potrzebne, by odpowiedzieć na pytanie „Co jest zablokowane, przez kogo i do kiedy?”.
2) Migruj arkusze kalkulacyjne bez wprowadzania chaosu
Większość zespołów już śledzi zależności w spreadsheetach. Importuj je, ale rób to celowo:
- Mapuj kolumny na pola (opis zależności, zespół zgłaszający, zespół właścicielski, data, status, powód blokady)
- Oczyść duplikaty i znormalizuj nazwy zespołów przed importem
- Zdecyduj, co zrobić z wierszami historycznymi (często lepiej je zarchiwizować niż przenosić)
Przeprowadź krótkie QA danych z pilotowymi użytkownikami, by potwierdzić definicje i poprawić niejednoznaczne wpisy.
3) Napędź adopcję lekkim playbookiem
Adopcja przykleja się, gdy aplikacja wspiera istniejący rytuał. Dostarcz:
- 15–20 minut szkolenia z 2–3 realistycznymi przykładami zależności
- Cotygodniową rutynę aktualizacji (np. każdy wtorek przed cross-team sync)
- Jasne reguły: zależności bez właściciela lub daty nie są „zalogowane”, są niekompletne
Jeśli budujesz szybko (np. iterujesz pilotaż w Koder.ai), używaj środowisk/snapshotów do testowania zmian pól wymaganych, stanów i dashboardów z zespołami pilota — potem wdróż (albo przywróć) bez zakłócania wszystkich.
4) Zbuduj pętlę feedbacku i iteruj
Śledź, gdzie ludzie utkną: pola mylące, brakujące statusy lub widoki, które nie odpowiadają na pytania przeglądu. Przeglądaj feedback co tydzień podczas pilota, potem dostosuj pola i widoki domyślne przed zaproszeniem kolejnych zespołów. Prosty link „Zgłoś problem” do /support pomaga utrzymać szybką pętlę.
Unikaj pułapek i zaplanuj kolejną iterację
Gdy tracker jest live, największe ryzyka nie są techniczne — są behawioralne. Większość zespołów nie porzuca narzędzi, bo „nie działają”, ale dlatego, że aktualizowanie ich wydaje się opcjonalne, mylące lub generujące hałas.
Typowe tryby porażki (i jak ich uniknąć)
Za dużo pól. Jeśli tworzenie zależności przypomina wypełnianie formularza, ludzie będą to odkładać. Zacznij z minimalnym zestawem wymaganych pól: tytuł, zespół zgłaszający, zespół właścicielski, „następne działanie”, data i status.
Niejasna własność. Jeśli nie wiadomo, kto ma działać, zależności stają się wątkami statusowymi. Uczyń „owner” i „następny krok” jawne i wyświetlaj je prominentnie.
Brak nawyku aktualizacji. Nawet świetne UI zawiedzie, jeśli pozycje staną się przestarzałe. Dodaj delikatne bodźce: wyróżniaj przestarzałe elementy na listach, wysyłaj przypomnienia tylko gdy data się zbliża lub ostatnia aktualizacja jest stara, i upraszczaj aktualizacje (jednoklikowa zmiana statusu + krótka notatka).
Przeciążenie powiadomieniami. Jeśli każdy komentarz powiadamia wszystkich, użytkownicy wyciszą system. Domyślne ustawienia niech używają watcherów opt-in i wysyłają podsumowania (codzienne/tygodniowe) dla niskiego priorytetu.
Strażnice, które utrzymują system zdrowy
Traktuj „następne działanie” jako pole pierwszorzędne: każda otwarta zależność powinna zawsze mieć jasny następny krok i jedną osobę rozliczalną. Jeśli brakuje tych informacji, pozycja nie powinna wyglądać „kompletna” w kluczowych widokach.
Zdefiniuj też, co znaczy „done” (np. rozwiązane, już niepotrzebne lub przeniesione do innego trackera) i wymagaj krótkiego powodu zamknięcia, żeby unikać zombie items.
Governance: zapobiegaj dryfowi taksonomii
Zadecyduj, kto zarządza tagami, listą zespołów i kategoriami. Zwykle to rola program managera lub ops z lekką kontrolą zmian. Ustal prostą politykę emerytury: archiwizuj stare inicjatywy automatycznie po X dniach od zamknięcia i przeglądaj nieużywane tagi kwartalnie.
Pomysły na roadmapę następnej iteracji
Po ustabilizowaniu adopcji rozważ ulepszenia, które dodadzą wartości bez zwiększania tarcia:
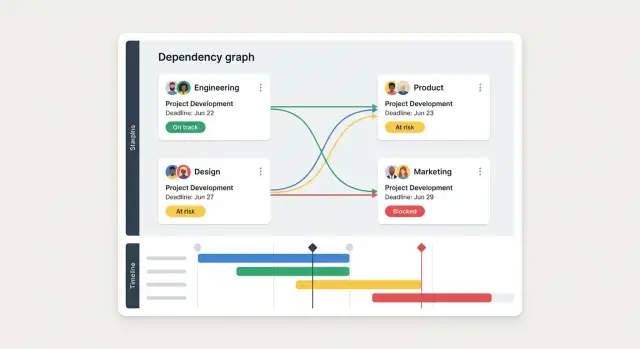
- Widok grafu zależności dla złożonych wydań i prac wielozespołowych
- Skoring ryzyka (np. starzenie się, przeterminowania, tagi wysokiego wpływu)
- Analizy SLA do wykrywania chronicznych wąskich gardeł i ustawiania oczekiwań
- Szablony per dział, żeby popularne typy zależności tworzyć jednym kliknięciem
Jeśli potrzebujesz struktury do priorytetyzacji usprawnień, powiąż każdy pomysł z rytuałem przeglądu (cotygodniowe spotkanie statusowe, planowanie wydań, retrospekcja incydentu), żeby ulepszenia wynikały z rzeczywistego użytkowania, nie domysłów.