09 wrz 2025·8 min
Jak stworzyć stronę statusu SaaS z historią incydentów
Dowiedz się, jak zaplanować, zbudować i opublikować stronę statusu SaaS z historią incydentów, przejrzystymi komunikatami i subskrypcjami, aby klienci byli informowani podczas przerw.
Czym jest strona statusu SaaS (i dlaczego ma znaczenie)
Strona statusu SaaS to publiczna (lub tylko dla klientów) witryna, która pokazuje, czy twój produkt działa teraz — i co robicie, jeśli nie działa. Staje się jedynym źródłem prawdy podczas incydentów, oddzielonym od social media, zgłoszeń do supportu i plotek.
Pomaga większej liczbie osób, niż się spodziewasz:
- Klienci mogą szybko sprawdzić „Czy to tylko u mnie?” i zdecydować, czy poczekać, spróbować ponownie, czy użyć obejścia.\n- Zespoły wsparcia mogą odsyłać do jednego kanonicznego komunikatu zamiast powtarzać wyjaśnienia w dziesiątkach zgłoszeń.\n- Sprzedaż i Customer Success mogą proaktywnie zarządzać odnowieniami i kluczowymi kontami dzięki dokładnym, oznaczonym czasem informacjom.
Status w czasie rzeczywistym vs. historia incydentów vs. postmortemy
Dobra strona statusu zazwyczaj zawiera trzy powiązane (ale różne) warstwy:
- Status w czasie rzeczywistym: co działa, nie działa lub jest zdegradowane tu i teraz w poszczególnych komponentach (API, panel, billing itd.).
- Strona historii incydentów: oś czasu przeszłych incydentów i prac konserwacyjnych, aby klienci mogli zrozumieć wzorce i widzieć, że problemy zostały zaadresowane.
- Przeglądy po incydentach (postmortemy): głębsze opracowania wyjaśniające przyczynę źródłową, naprawy i kroki zapobiegawcze. Mogą być publiczne albo udostępniane prywatnie dotkniętym klientom.
Cel to przejrzystość: status w czasie rzeczywistym odpowiada „Czy mogę użyć produktu?”, historia odpowiada „Jak często się to zdarza?”, a postmortemy odpowiadają „Dlaczego to się stało i co się zmieniło?”.
Ustawianie oczekiwań: przejrzystość, szybkość i jasność
Strona statusu działa, gdy aktualizacje są szybkie, napisane prostym językiem i szczere w kwestii wpływu. Nie potrzebujesz perfekcyjnej diagnozy, żeby komunikować. Potrzebujesz znaczników czasu, zakresu (kogo dotyczy) i czasu następnej aktualizacji.
Typowe sytuacje, gdy jej użyjesz
Będziesz jej używać podczas awarii, zdegradowanej wydajności (wolne logowanie, opóźnione webhooki) i planowanej konserwacji, która może powodować krótkie przestoje lub ryzyko.
Gdy potraktujesz stronę statusu jak element produktu (a nie jednorazową stronę operacyjną), reszta konfiguracji stanie się znacznie łatwiejsza: możesz wyznaczyć właścicieli, przygotować szablony i podłączyć monitoring, zamiast wymyślać proces za każdym razem podczas incydentu.
Ustal cele, odbiorców i właściciela
Zanim wybierzesz narzędzie czy zaprojektujesz układ, zdecyduj, co twoja strona statusu ma robić. Jasny cel i wyraźny właściciel to to, co sprawia, że strony statusu są użyteczne podczas incydentu — gdy wszyscy są zajęci, a informacje są chaotyczne.
Zdefiniuj cel (jak wygląda „sukces”)
Większość zespołów SaaS tworzy stronę statusu dla trzech praktycznych rezultatów:
- Zmniejszenie liczby zgłoszeń do supportu przez odpowiedź „Czy to padło?” w jednym publicznym miejscu\n- Budowanie zaufania przez terminowe, proste komunikaty\n- Przyspieszenie komunikacji między Supportem, Engineeringiem, Sprzedażą i Customer Success
Zapisz 2–3 mierzalne sygnały, które możesz śledzić po uruchomieniu: mniej duplikatów zgłoszeń podczas awarii, krótszy czas do pierwszej aktualizacji lub więcej klientów korzystających z subskrypcji.
Zidentyfikuj odbiorców i poziom czytelniczy
Twój główny czytelnik to zwykle nietechniczny klient, który chce wiedzieć:
- Czy produkt działa teraz?\n- Co jest dotknięte (logowanie, API, billing itd.)?\n- Co powinienem zrobić dalej?\n- Kiedy to będzie naprawione?
To oznacza minimalizowanie żargonu. Lepiej „Niektórzy klienci nie mogą się zalogować” niż „Podwyższone wskaźniki 5xx na auth.” Jeśli potrzebujesz szczegółu technicznego, trzymaj go jako krótkie zdanie drugorzędne.
Wybierz ton, zasady i właściciela
Wybierz ton, którego będziesz w stanie dotrzymać pod presją: spokojny, rzeczowy i transparentny. Zdecyduj z wyprzedzeniem:
- Kto może publikować aktualizacje (pojedyncza rola lub rotacja on-call)\n- Kto zatwierdza aktualizacje (jeśli ktoś) i ile może trwać zatwierdzenie\n- Minimalna częstotliwość aktualizacji podczas aktywnego incydentu (np. co 30 minut)
Uczyń własność jednoznaczną: strona statusu nie powinna być „czyimś tam zadaniem”, bo wtedy jest niczyja.
Zdecyduj, gdzie będzie się znajdować
Masz dwie powszechne opcje:
- Osobna strona (np. status.yourcompany.com): wyraźniejsze oddzielenie i często większa odporność na awarie\n- Podścieżka (np. /status): prostsze markowanie i analityka
Jeśli twoja główna aplikacja może paść, osobna strona statusu jest zwykle bezpieczniejsza. Nadal możesz ją prominentnie linkować z aplikacji i centrum pomocy (np. /help).
Zmapuj usługi i model statusu komponentów
Strona statusu jest tak użyteczna, jak „mapa” za nią stojąca. Zanim wybierzesz kolory czy napiszesz tekst, zdecyduj, o czym właściwie raportujesz. Cel to odzwierciedlić, jak klienci doświadczają produktu — nie jak wygląda twój schemat organizacyjny.
Zacznij od inwentaryzacji komponentów
Wypisz elementy, które klient mógłby opisać, gdy mówi „to nie działa”. Dla wielu produktów SaaS praktyczny zestaw startowy wygląda tak:
- API\n- Aplikacja webowa\n- Panel / admin\n- Autoryzacja (logowanie, SSO)\n- Billing\n- Integracje (Slack, Salesforce, webhooki itd.)
Jeśli oferujesz wiele regionów lub planów, uwzględnij to również (np. „API – US” i „API – EU”). Utrzymuj nazwy przyjazne klientowi: „Logowanie” jest czytelniejsze niż „IdP Gateway”.
Zdecyduj, jak grupować komponenty
Wybierz grupowanie, które odpowiada myśleniu klientów o usłudze:
- Po produkcie: dobre, jeśli masz odrębne oferty (Produkt A vs Produkt B)\n- Po regionie: dobre, jeśli dostępność różni się znacząco geograficznie\n- Po funkcji/workflowie: dobre, jeśli klienci polegają na konkretnych zadaniach (Raportowanie, Importy, Powiadomienia)
Staraj się unikać niekończącej się listy. Jeśli masz dziesiątki integracji, rozważ jeden komponent nadrzędny („Integracje”) plus kilka kluczowych dzieci (np. „Salesforce”, „Webhooki”).
Zdefiniuj poziomy statusu (i co znaczą)
Prosty, spójny model zapobiega nieporozumieniom podczas incydentów. Typowe poziomy to:
- Operational: działa jak oczekiwano\n- Degraded Performance: wolniej niż zwykle lub sporadyczne błędy\n- Partial Outage: znaczący podzbiór użytkowników/funkcji jest niedostępny\n- Major Outage: usługa jest szeroko niedostępna
Napisz wewnętrzne kryteria dla każdego poziomu (nawet jeśli ich nie publikujesz). Na przykład „Partial Outage = jeden region niedostępny” lub „Degraded = p95 latencji > X przez Y minut”. Spójność buduje zaufanie.
Udokumentuj zależności — i zdecyduj, co pokazywać
Większość awarii wiąże się z zewnętrznymi dostawcami: hosting w chmurze, dostarczanie emaili, procesory płatności czy dostawcy tożsamości. Udokumentuj te zależności, aby twoje aktualizacje incydentów były dokładne.
Czy pokazywać je publicznie, zależy od odbiorców. Jeśli klienci mogą być bezpośrednio dotknięci (np. płatności), pokazanie komponentu zależności może być pomocne. Jeśli to wprowadza hałas lub zachęca do szukania winnych, trzymaj zależności wewnętrznie, a w aktualizacjach odniesienia, gdy istotne (np. „Badamy podwyższone błędy u naszego dostawcy płatności”).
Gdy masz model komponentów, reszta ustawień strony statusu staje się prostsza: każdy incydent od początku ma jasne „gdzie” (komponent) i „jak poważne” (status).
Zaprojektuj prostą, przyjazną dla klienta stronę statusu
Strona statusu jest najbardziej użyteczna, gdy odpowiada na pytania klientów w kilka sekund. Ludzie przychodzą zestresowani i chcą jasności — nie dużej nawigacji.
Zacznij od tego, czego klienci potrzebują najpierw
Priorytetyzuj najważniejsze elementy na samej górze:
- Aktualny stan: czy wszystko działa, jest zdegradowane, czy niedostępne?\n- Wpływ: co jest dotknięte (kto/które regiony/funkcje) i co użytkownicy mogą doświadczyć\n- ETA (jeśli masz): ostrożnie — podawaj tylko takie szacunki, których możesz bronić\n- Czas następnej aktualizacji: konkretna obietnica jak „Następna aktualizacja przed 14:30 UTC” zmniejsza liczbę powtarzających się zgłoszeń
Pisz prostym językiem. „Podwyższone wskaźniki błędów na zapytaniach API” jest czytelniejsze niż „Partial outage in upstream dependency.” Jeśli musisz użyć terminu technicznego, dodaj krótkie tłumaczenie („Niektóre żądania mogą się nie powieść lub przekroczyć limit czasu”).
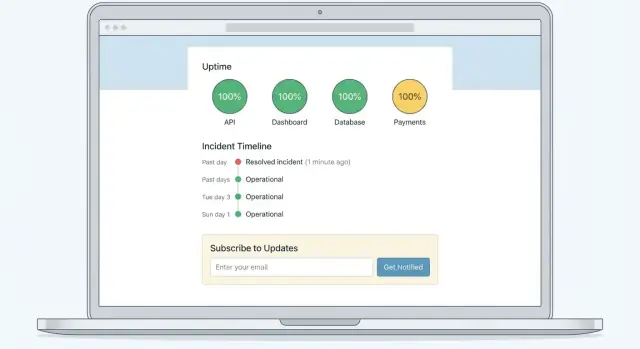
Użyj prostego, skanowalnego układu
Sprawdzony wzór to:
- Górny baner dla ogólnego statusu (All Systems Operational / Degraded Performance / Major Outage)\n2. Lista komponentów z czytelnymi statusami (Web App, API, Billing, Integrations itd.)\n3. Aktywne incydenty i zaplanowane prace konserwacyjne bezpośrednio poniżej, posortowane według najnowszych aktualizacji
Dla listy komponentów trzymaj etykiety przyjazne klientowi. Jeśli wewnętrzna usługa nazywa się „k8s-cluster-2”, klienci prawdopodobnie potrzebują „API” lub „Background Jobs”.
Dostępność i podstawy mobilne
Spraw, aby strona była czytelna pod presją:\n\n- Silny kontrast kolorów i etykiety tekstowe (nie polegaj wyłącznie na kolorze)\n- Czytelne ikony o stałym znaczeniu (np. zielony = operational, żółty = degraded, czerwony = outage)\n- Responsywne odstępy i elementy dotykowe; wielu użytkowników sprawdzi status na telefonie
Dodaj szybkie linki tam, gdzie się ich oczekuje
Umieść mały zestaw linków blisko góry (w nagłówku lub tuż pod banerem):\n\n- Subscribe (dla powiadomień email/SMS/webhook)\n- Incident History (dla przeszłych incydentów i osi czasu)\n- Contact Support w /support
Celem jest pewność: klient powinien natychmiast rozumieć, co się dzieje, co to wpływa i kiedy usłyszy od was ponownie.
Stwórz szablony aktualizacji incydentów i konserwacji
Gdy pojawi się incydent, twój zespół żongluje diagnozą, łagodzeniem skutków i pytaniami klientów jednocześnie. Szablony usuwają niepewność, dzięki czemu aktualizacje pozostają spójne, jasne i szybkie — zwłaszcza gdy różne osoby mogą publikować.
Zdefiniuj pola incydentu, które zawsze publikujesz
Dobra aktualizacja zaczyna się od tych samych kluczowych faktów za każdym razem. Przynajmniej wystandaryzuj te pola, by klienci szybko rozumieli sytuację:
- Czas rozpoczęcia incydentu (ze strefą czasową)\n- Dotknięte komponenty/usługi (mapowane do modelu statusu)\n- Wpływ na klienta (kogo dotyczy i jak)\n- Aktualny status (Investigating, Identified, Monitoring, Resolved)\n- Log aktualizacji (wpisy z oznaczeniami czasu)\n- Czas rozwiązania (kiedy usługa wróciła do normy)
Jeśli publikujesz stronę historii incydentów, konsekwentne pola ułatwiają przeglądanie i porównywanie przeszłych zdarzeń.
Użyj prostego, powtarzalnego szablonu aktualizacji incydentu
Celuj w krótkie aktualizacje, które odpowiadają na te same pytania klientów za każdym razem. Oto praktyczny szablon, który możesz skopiować do narzędzia strony statusu:
Tytuł: Krótko i konkretne podsumowanie (np. „Błędy API dla regionu EU”)\n\nCzas rozpoczęcia: YYYY-MM-DD HH:MM (TZ)\n\nDotknięte komponenty: API, Dashboard, Payments\n\nWpływ: Co widzą użytkownicy (błędy, timeouty, zdegradowana wydajność) i kogo to dotyczy\n\nCo wiemy: Jedno zdanie o przyczynie jeśli potwierdzona (unikaj spekulacji)\n\nCo robimy: Konkretne działania (rollback, skalowanie, eskalacja do dostawcy)\n\nNastępna aktualizacja: Czas kolejnej publikacji\n\nAktualizacje:\n\n- HH:MM (TZ) — Investigating: …\n- HH:MM (TZ) — Identified: …\n- HH:MM (TZ) — Monitoring: …\n- HH:MM (TZ) — Resolved: …
Ustal jasne zasady częstotliwości aktualizacji
Klienci nie chcą tylko informacji — chcą przewidywalności.
- Dla poważnych incydentów zobowiąż się do aktualizacji co 30–60 minut, nawet jeśli aktualizacja brzmi „Wciąż badamy; brak ETA; następna aktualizacja o X.”\n- Dla mniejszych problemów możesz publikować rzadziej, ale nadal podawaj obiecany „czas następnej aktualizacji”.\n- Jeśli nie możesz dotrzymać rytmu, opublikuj krótką notkę przyznając opóźnienie i resetując oczekiwania.
Dodaj szablony ogłoszeń konserwacyjnych
Planowana konserwacja powinna wyglądać spokojnie i uporządkowanie. Ustandaryzuj wpisy konserwacyjne takimi polami:
- Okno konserwacji: czas rozpoczęcia/końca (ze strefą czasową)\n- Oczekiwany wpływ: brak / zdegradowany / sporadyczny / przerwa\n- Dotknięte komponenty\n- Działania klienta (jeśli są): „Brak działań wymaganych” lub jasne kroki\n- Przypomnienie: krótki wpis, gdy konserwacja się zaczyna i kolejny, gdy się kończy
Trzymaj język konserwacji konkretny (co się zmienia, co użytkownicy mogą zauważyć) i unikaj nadmiernego optymizmu — klienci cenią dokładność bardziej niż życzeniowość.
Zbuduj historię incydentów, którą łatwo przeglądać
Udostępnij szablony incydentów
Przekształć szablon aktualizacji incydentów w edytowalny interfejs i backend w Koder.ai.
Strona historii incydentów to więcej niż log — to sposób, by klienci (i twój zespół) szybko zrozumieli, jak często zdarzają się problemy, jakie rodzaje problemów się powtarzają i jak reagujecie.
Dlaczego historia incydentów jest warta wysiłku
Jasna historia buduje zaufanie przez transparentność. Daje też widoczność trendów: jeśli widzisz powtarzające się incidenty „opóźnienie API” co kilka tygodni, to sygnał, by zainwestować w pracę nad wydajnością (i priorytetyzować postmortemy). Z czasem konsekwentne raportowanie może zmniejszyć liczbę zgłoszeń, bo klienci znajdą odpowiedzi sami.
Zdecyduj o retencji: jak daleko wstecz przechowywać?
Wybierz okres retencji zgodny z oczekiwaniami klientów i dojrzałością produktu.
- 90 dni: powszechne dla startupów, utrzymuje stronę lekką\n- 6–12 miesięcy: lepsze dla kupujących enterprise oceniających niezawodność\n- Dłużej: rozważ eksport starszych rekordów do oddzielnej archiwalnej strony, jeśli oś czasu robi się zbyt gęsta
Cokolwiek wybierzesz, napisz to jasno (np. „Historia incydentów przechowywana jest przez 12 miesięcy”).
Spraw, by każdy wpis był od razu czytelny
Konsekwencja ułatwia skanowanie. Użyj przewidywalnego formatu nazewnictwa, np.:
YYYY-MM-DD — Krótkie podsumowanie (np. „2025-10-14 — Opóźnione dostarczanie emaili”)
Dla każdego incydentu pokaż przynajmniej:\n\n- dotknięte komponenty\n- czas rozpoczęcia/zakończenia (ze strefą czasową)\n- poziom wpływu (minor/major)\n- krótką notkę o rozwiązaniu
Linkuj do głębszego kontekstu, gdy dostępny
Jeśli publikujesz postmortemy, linkuj z widoku szczegółowego incydentu do opracowania (np. „Read the postmortem” linking to /blog/postmortems/2025-10-14-email-delays). To utrzymuje oś czasu czystą, a jednocześnie daje szczegóły tym, którzy ich chcą.
Dodaj subskrypcje i powiadomienia
Strona statusu pomaga, gdy klienci pamiętają, by na nią zajrzeć. Subskrypcje odwracają to: klienci otrzymują aktualizacje automatycznie, bez odświeżania strony czy pisania do supportu.
Oferuj kanały, których klienci już używają
Większość zespołów oczekuje przynajmniej kilku opcji:\n\n- Email (domyślne dla wielu klientów)\n- SMS (najlepszy dla pilnych, wysokiego priorytetu alertów)\n- Slack lub Microsoft Teams (idealne dla klientów biznesowych i zespołów operacyjnych)\n- RSS/Atom (wciąż popularne wśród technicznych użytkowników i do wewnętrznych narzędzi)
Jeśli wspierasz wiele kanałów, utrzymaj spójny przebieg konfiguracji, aby klienci nie mieli wrażenia, że zapisują się czterema różnymi sposobami.
Uczyń opt‑in i preferencje przejrzystymi
Subskrypcje zawsze powinny być dobrowolne. Jasno powiedz, co ludzie dostaną, zanim potwierdzą — zwłaszcza dla SMS.
Daj subskrybentom kontrolę nad:\n\n- Zakresem: wszystkie incydenty vs. wybrane komponenty (np. „API” ale nie „Strona marketingowa”)\n- Typem: tylko incydenty, tylko konserwacje lub oba\n- Ciężkością (opcjonalnie): tylko „Major outage” vs. „Wszystkie aktualizacje”
Takie preferencje zmniejszają zmęczenie alertami i utrzymują zaufanie do powiadomień. Jeśli nie masz jeszcze subskrypcji po poziomie komponentów, zacznij od „Wszystkie aktualizacje” i dodaj filtrowanie później.
Nie pozwól, by powiadomienia zawiodły w momencie, gdy ich najbardziej potrzebujesz
Podczas incydentu natężenie wiadomości rośnie, a dostawcy zewnętrzni mogą ograniczać ruch. Sprawdź:\n\n- Dostarczalność: SPF/DKIM/DMARC dla emaili; zweryfikowane domeny wysyłkowe; rozpoznawalne adresy nadawcy\n- Limity i throttling: limity twojego dostawcy email/SMS, limity webhooków Slack/Teams i zachowanie retry\n- Fallbacky: jeśli posty do Slacka nie przejdą, czy nadal wysyłasz email? Jeśli SMS opóźni się, czy pokażesz jasny baner na stronie statusu?
Warto okresowo (np. kwartalnie) uruchamiać test, żeby upewnić się, że subskrypcje nadal działają.
Umieść „Subscribe to updates” tam, gdzie nikt tego nie przegapi
Dodaj wyraźne wezwanie do subskrypcji na stronie statusu — najlepiej nad pierwszym ekranem — aby klienci zapisywali się zanim nastąpi kolejny incydent. Upewnij się, że jest widoczne na mobilu i umieść je także tam, gdzie klienci szukają pomocy (link z portalu wsparcia lub /help).
Wybierz metodę budowy: narzędzie hostowane vs. DIY
Zaplanuj workflow najpierw
Użyj Planning Mode, aby zdefiniować właścicieli, zasady częstotliwości aktualizacji i workflow zanim zaczniesz budować.
Wybór metody budowy dotyczy bardziej tego, co chcesz optymalizować: szybkość uruchomienia, odporność podczas incydentów i nakład utrzymania.
Opcja 1: Użyj hostowanego narzędzia status page
Narzędzie hostowane to zwykle najszybsza droga. Otrzymujesz gotową stronę statusu, subskrypcje, oś czasu incydentów i często integracje z powszechnym monitoringiem.
Co warto szukać w narzędziu hostowanym:\n\n- Niezawodność i niezależność: strona statusu powinna być dostępna nawet jeśli twoja główna aplikacja jest niedostępna\n- API i automatyzacja: możliwość tworzenia incydentów, aktualizowania komponentów i publikowania postępów przez API lub webhooks\n- Kontrola dostępu: role kto może publikować vs. kto może szkicować; SSO to bonus\n- Branding i własna domena: logo/kolory oraz domena jak status.yourcompany.com\n- Analityka: liczba subskrybentów, odsłony aktualizacji i metryki dostarczalności emaili (pomocne przy ulepszaniu komunikacji)\n- Wymogi compliance: logi audytowe i retencja, jeśli działasz w regulowanym środowisku
Opcja 2: Zbuduj samodzielnie (DIY)
DIY może być dobrym wyborem, jeśli chcesz pełnej kontroli nad designem, przechowywaniem danych i sposobem prezentacji historii incydentów. Kosztem jest odpowiedzialność za niezawodność i operacje.
Praktyczna architektura DIY to:\n\n- Strona statyczna (szybka, przyjazna cache) dla UI statusu i stron historii incydentów\n- API jako źródło danych (albo lekki CMS) przechowujące incydenty, komponenty i aktualizacje\n- Agresywne cache’owanie + CDN żeby strona statusu pozostała szybka przy skokach ruchu podczas awarii
Jeśli hostujesz samodzielnie, zaplanuj tryby awaryjne: co jeśli twoja główna baza danych jest niedostępna lub pipeline deploya nie działa? Wiele zespołów trzyma stronę statusu na innej infrastrukturze (albo u innego dostawcy) niż produkt główny.
Jeśli chcesz kontroli DIY bez budowania wszystkiego od zera, platforma typu vibe-coding jak Koder.ai może pomóc szybko postawić niestandardową stronę statusu (UI web + małe API incydentów) z czatowego specyfikatu. To szczególnie przydatne dla zespołów, które chcą dostosowanego modelu komponentów, niestandardowego UX historii incydentów lub wewnętrznych workflowów administracyjnych — przy możliwości eksportu kodu i szybkiego wdrażania.
Planowanie kosztów
Narzędzia hostowane mają przewidywalne miesięczne ceny; DIY wiąże się z czasem inżynieryjnym, kosztami hostingu/CDN i utrzymania. Porównując opcje, przedstaw spodziewane miesięczne wydatki i wymaganą ilość pracy wewnętrznej — potem sprawdź to względem budżetu (zobacz /pricing).
Podłącz monitoring i workflow incydentów
Strona statusu jest użyteczna tylko wtedy, gdy odzwierciedla rzeczywistość szybko. Najprostszy sposób to połączenie systemów wykrywających problemy (monitoring) z systemami koordynującymi odpowiedź (workflow incydentów), tak aby aktualizacje były spójne i terminowe.
Skąd powinny pochodzić aktualizacje statusu
Większość zespołów łączy trzy źródła danych:\n\n- Alerty monitoringowe (health checks, testy syntetyczne, wskaźniki błędów, opóźnienia, głębokość kolejek). Dobre do wykrywania, ale nie zawsze opisują wpływ klienta.\n- Ręczne aktualizacje od on-call lub zespołu wsparcia. Ludzie dodają kontekst: kogo dotyczy, jakie obejście, co się zmieniło.\n- Narzędzia do zarządzania incydentami (PagerDuty, Opsgenie, Jira Service Management itd.). Dają oś czasu, role i notatki o rozwiązaniu, które strona statusu może podsumować.
Praktyczna zasada: monitoring wykrywa; workflow incydentu koordynuje; strona statusu komunikuje.
Automatyzacja, która pomaga (bez przesadnych obietnic)
Automatyzacja może zaoszczędzić minuty, gdy to ma znaczenie:\n\n- Utwórz incydent z alertu gdy monitor wysokiego priorytetu się uruchomi (np. „współczynnik błędów API > 5% przez 5 minut”). Wstępnie wypełnij tytuł, dotknięte komponenty i początkową ciężkość.\n- Aktualizuj komponenty z health checks dla obiektywnych sygnałów (np. „Web app: Degraded Performance” gdy przekroczone progi latencji).\n- Synchronizuj zmiany statusu z kanałem incydentu (Slack/Teams), by reagujący widzieli to, co widzą klienci.
Trzymaj pierwszy komunikat publiczny konserwatywny. „Badamy podwyższone błędy” jest bezpieczniejsze niż „Potwierdzona awaria”, gdy nadal weryfikujesz.
Nie idź w pełni automatycznie bez przeglądu człowieka
W pełni automatyczne wiadomości mogą się obrócić przeciwko tobie:\n\n- Hałasujący alert może opublikować fałszywy incydent.\n- Częściowa awaria może sprawiać wrażenie „down” dla jednego monitora, ale klienci nie są dotknięci.\n- Auto‑resolve może zamknąć incydent, gdy użytkownicy wciąż są dotknięci.
Używaj automatyzacji do wstępnego wypełniania i sugerowania aktualizacji, ale wymagaj człowieka do zatwierdzenia komunikatów dla klientów — szczególnie dla stanów Identified, Mitigated i Resolved.
Zachowaj ślad audytu
Traktuj stronę statusu jak publiczny dziennik. Upewnij się, że możesz odpowiedzieć na pytania:\n\n- Kto zmienił status incydentu?\n- Co zostało zmienione (tekst, komponenty, znaczniki czasu)?\n- Kiedy to zmieniono?
Ślad audytu pomaga w retrospektywach, zmniejsza zamieszanie podczas przekazywania zmian i buduje zaufanie, gdy klienci proszą o wyjaśnienia.
Uczyń to niezawodnym: hosting, DNS i odporność na awarie
Strona statusu pomaga tylko wtedy, gdy jest dostępna, gdy twój produkt nie działa. Najczęstszy błąd to budowanie strony statusu na tej samej infrastrukturze co aplikacja — wtedy przy awarii aplikacji znika też strona statusu, a klienci tracą źródło prawdy.
Izoluj ją od głównego stosu
Gdy to możliwe, hostuj stronę statusu u innego dostawcy niż produkcyjna aplikacja (albo przynajmniej w innym regionie/kontekstcie). Cel to separacja blast radius: awaria platformy aplikacji nie powinna zabrać komunikacji o incydencie.
Rozważ też oddzielny DNS. Jeśli DNS głównej domeny jest zarządzany tam, gdzie masz edge/CDN aplikacji, problem z DNS lub certyfikatem może zablokować oba. Wiele zespołów używa dedykowanego subdomeny (np. status.yourcompany.com) z DNS hostowanym niezależnie.
Spraw, aby strona była szybka i odporna
Utrzymuj zasoby lekkie: minimalny JavaScript, skompresowane CSS i brak zależności, które wymagają API twojej aplikacji, żeby wyrenderować stronę. Postaw CDN przed stroną statusu i włącz cache dla zasobów statycznych, aby ładowała się nawet przy dużym ruchu podczas incydentów.
Praktyczny bezpiecznik to tryb awaryjny statyczny:\n\n- prerenderuj ostatni znany status i baner incydentu\n- serwuj go z object storage lub hostingu statycznego\n- aktualizuj dynamicznie, gdy systemy są zdrowe, ale degradować łagodnie, gdy nie są
Publiczna domyślnie, z bezpiecznym dostępem admina
Klienci nie powinni logować się, żeby zobaczyć stan usługi. Trzymaj stronę statusu publiczną, ale narzędzia admina/redaktora za autoryzacją (SSO jeśli masz), z mocnymi kontrolami dostępu i logami audytu.
Na koniec, testuj scenariusze awarii: tymczasowo zablokuj origin aplikacji w środowisku staging i potwierdź, że strona statusu nadal rozwiązuje się, ładuje szybko i można ją zaktualizować, gdy jest to najbardziej potrzebne.
Proces operacyjny: kto aktualizuje i kiedy
Prawidłowo mapuj komponenty
Wygeneruj czystą listę komponentów i model statusu, który zrozumieją klienci.
Strona statusu buduje zaufanie tylko wtedy, gdy jest konsekwentnie aktualizowana podczas prawdziwych incydentów. Ta konsekwencja nie dzieje się przypadkiem — potrzebujesz jasnej własności, prostych zasad i przewidywalnego rytmu.
Zdefiniuj role (zanim coś się zepsuje)
Utrzymaj mały, jasny zespół rdzeniowy:
- Incident Commander (IC): prowadzi odpowiedź, decyduje o priorytecie i potwierdza stabilność\n- Communications Lead: publikuje aktualizacje na stronie statusu i dba o zrozumiały język\n- Inżynierowie on call: badają, łagodzą i przekazują potwierdzone fakty IC
W małym zespole jedna osoba może pełnić dwie role — po prostu ustal to wcześniej. Udokumentuj przekazania ról i ścieżki eskalacji w podręczniku on-call (zobacz /docs/on-call).
Prosta lista kontrolna aktualizacji za każdym razem
Gdy alert przeradza się w incydent wpływający na klientów, przejdź powtarzalny flow:
- Potwierdź: opublikuj szybko aktualizację „Investigating” (nawet jeśli szczegóły są ograniczone)\n2. Oceń wpływ: potwierdź które komponenty, regiony lub segmenty klientów są dotknięte\n3. Opublikuj aktualizację: opisz, co użytkownicy widzą, obejścia (jeśli są) i kiedy zaktualizujesz ponownie\n4. Rozwiąż: potwierdź, że usługa wróciła i co monitorujecie\n5. Podsumuj: dodaj krótkie streszczenie i link do pełnego przeglądu, gdy będzie dostępny
Praktyczna zasada: opublikuj pierwszą aktualizację w ciągu 10–15 minut, potem co 30–60 minut dopóki wpływ trwa — nawet jeśli wiadomość brzmi „Brak zmian, nadal badamy.”
Po rozwiązaniu: przegląd i poprawa
W ciągu 1–3 dni roboczych przeprowadź lekki przegląd po incydencie:
- Oś czasu: kluczowe zdarzenia od wykrycia do przywrócenia\n- Przyczyna podstawowa (najlepsze znane wyjaśnienie): w prostym języku\n- Zadania: konkretne naprawy, właściciele i terminy
Następnie zaktualizuj wpis incydentu o finalne podsumowanie, aby historia incydentów pozostała użyteczna — nie tylko jako log "resolved".
Lista kontrolna uruchomienia i ciągłe ulepszanie
Strona statusu jest użyteczna tylko wtedy, gdy łatwo ją znaleźć, ufa się jej i jest konsekwentnie aktualizowana. Zrób szybki przegląd „gotowości produkcyjnej” przed ogłoszeniem, a potem ustaw lekki rytm ciągłego ulepszania.
Lista kontrolna uruchomienia (praktyczna wersja)
Treść i struktura\n\n- Potwierdź, że nazwy komponentów pasują do tego, co rozpoznają klienci (np. „Dashboard” vs nazwy wewnętrzne).\n- Dodaj krótki wstęp „Co pokazuje ta strona” i wyraźny link do supportu (np. /support) dla spraw związanych z kontem.\n- Upewnij się, że aktualizacje incydentów wyjaśniają wpływ na klienta („płatności nie działają”) i dają następne kroki („spróbuj ponownie za 10 minut”).
Branding i zaufanie\n\n- Dodaj logo, favicon i prosty system kolorów statusów (unikaj zbyt subtelnych odcieni).\n- Dołącz czytelny format znaczników czasu i strefę czasową.
Dostęp i uprawnienia\n\n- Zweryfikuj, kto może publikować incydenty, planować konserwacje i edytować ustawienia strony.\n- Ustaw „backup on-call”, aby publikacje nie blokowały się na jednej osobie.
Przetestuj cały workflow\n\n- Przeprowadź testowy incydent (oznaczony jako test i zamknięty).\n- Zapisz się na powiadomienia przez email/SMS i potwierdź, że powiadomienia docierają i zawierają poprawne odniesienia.
Ogłoś\n\n- Dodaj link do strony statusu w stopce aplikacji, centrum pomocy i automatycznych odpowiedziach supportu.\n- Wyślij krótkie ogłoszenie do klientów wyjaśniające, czego mogą oczekiwać i jak subskrybować.
Jeśli budujesz własną stronę, rozważ przeprowadzenie tej samej listy kontrolnej w środowisku staging. Narzędzia jak Koder.ai mogą przyspieszyć pętlę iteracyjną, generując UI web, ekrany admina i endpointy backendowe z jednego specyfikatu — a potem pozwalając wyeksportować kod i wdrożyć go tam, gdzie potrzebujesz.
Mierz, co oznacza „lepiej”
Śledź kilka prostych wyników i przeglądaj je co miesiąc:\n\n- Zmniejszone zgłoszenia: porównaj liczbę zgłoszeń związanych z incydentami przed i po uruchomieniu\n- Szybsza pierwsza aktualizacja: mierz czas od wykrycia do pierwszej publicznej aktualizacji\n- Wzrost subskrybentów: śledź subskrybentów po kanałach i które komponenty obserwują
Ucz się z wzorców incydentów
Utrzymuj podstawową taksonomię, aby historia stawała się użyteczna:\n\n- Oznaczaj incydenty według kategorii (wydajność, partial outage, dostawca zewnętrzny, konserwacja, kwestie bezpieczeństwa).\n- Notuj powtarzające się komponenty i nawracające problemy.\n- Użyj tego do priorytetyzacji napraw i kierowania procesu przeglądu po incydencie.
Podstawy SEO (żeby klienci znaleźli właściwą stronę)
- Używaj jasnych tytułów stron jak „Service Status” i „Incident History.”\n- Utrzymuj strukturę nagłówków (H2/H3), aby strony historii były łatwe do przeglądania.\n- Preferuj indeksowalne strony historii incydentów (chyba że są powody bezpieczeństwa/prywatności), i upewnij się, że linki między stroną główną statusu a każdym incydentem są możliwe do crawlowania.
Z czasem drobne ulepszenia — jaśniejsze sformułowania, szybsze aktualizacje, lepsza kategoryzacja — kumulują się w mniejszej liczbie przestojów, mniejszej liczbie zgłoszeń i większym zaufaniu klientów.
Często zadawane pytania
Czym jest strona statusu SaaS i dlaczego ma znaczenie?
Strona statusu SaaS to dedykowana strona pokazująca w jednym kanonicznym miejscu aktualny stan usług i aktualizacje incydentów. Ma znaczenie, ponieważ zmniejsza liczbę pytań "Czy to tylko u mnie?", ustawia oczekiwania podczas przerw i buduje zaufanie przez jasne, oznaczone czasowo komunikaty.
Jaka jest różnica między statusem w czasie rzeczywistym, historią incydentów i postmortem?
Status w czasie rzeczywistym odpowiada „Czy mogę teraz korzystać z produktu?” poprzez stany na poziomie komponentów.
Historia incydentów odpowiada „Jak często się to zdarza?” przez oś czasu przeszłych incydentów i prac konserwacyjnych.
Postmortemy odpowiadają „Dlaczego to się stało i co się zmieniło?” przez przyczyny źródłowe i kroki zapobiegawcze (często linkowane z wpisu incydentu).
Jak ustawić jasne cele dla strony statusu przed jej budową?
Zacznij od 2–3 mierzalnych rezultatów:
- Zmniejszyć powtarzające się zgłoszenia do supportu podczas incydentów
- Poprawić czas do pierwszej aktualizacji (np. w ciągu 10–15 minut)
- Zwiększyć liczbę subskrypcji powiadomień (email/SMS/Slack)
Zapisz te cele i przeglądaj je co miesiąc, aby strona nie stała się przestarzała.
Kto powinien odpowiadać za aktualizacje strony statusu i jak uniknąć nieporozumień podczas incydentów?
Wyznacz jawnego właściciela i zapasową osobę (często rotacja on-call). Wiele zespołów ma:
- Incident Commander, który potwierdza fakty i priorytety
- Communications Lead, który publikuje przyjazne klientowi aktualizacje
Zdefiniuj też zasady wcześniej: kto może publikować, czy wymagane są zatwierdzenia i minimalna częstotliwość aktualizacji (np. co 30–60 minut podczas poważnych incydentów).
Jak zdecydować, które komponenty pokazywać na stronie statusu?
Wybieraj komponenty na podstawie tego, jak klienci opisują problemy, a nie nazw wewnętrznych usług. Typowe komponenty to:
- API
- Web app / Dashboard
- Authentication (Login/SSO)
- Billing
- Integrations (z ważnymi dziećmi jak Webhooks czy Salesforce)
Jeśli dostępność różni się geograficznie, podziel komponenty po regionach (np. „API – US” i „API – EU”).
Jakie poziomy statusu powinniśmy stosować i jak utrzymać ich spójność?
Użyj małego, spójnego zestawu poziomów i udokumentuj wewnętrzne kryteria dla każdego z nich:
- Operational
- Degraded Performance
- Partial Outage
- Major Outage
Spójność jest ważniejsza niż absolutna precyzja. Klienci powinni nauczyć się, co oznacza każdy poziom na podstawie powtarzalnego użycia.
Co powinna zawsze zawierać aktualizacja incydentu, żeby była użyteczna dla klientów?
Praktyczna aktualizacja incydentu powinna zawsze zawierać:
- Czas rozpoczęcia (z strefą czasową)
- Dotknięte komponenty/regiony
- Opis wpływu w prostym języku
- Aktualny stan (Investigating/Identified/Monitoring/Resolved)
- Czas następnej aktualizacji, którego możesz dotrzymać
Nawet jeśli nie znasz jeszcze przyczyny, możesz komunikować zakres, wpływ i kolejne kroki.
Jak często powinniśmy aktualizować stronę statusu podczas awarii?
Opublikuj pierwszą aktualizację „Investigating” szybko (zazwyczaj w ciągu 10–15 minut od potwierdzenia wpływu). Potem:
- Poważne incydenty: aktualizuj co 30–60 minut
- Mniejsze incydenty: rzadziej, ale zawsze z obiecanym czasem następnej aktualizacji
Jeśli nie dotrzymasz rytmu, opublikuj krótką notkę resetującą oczekiwania zamiast milczeć.
Czy powinniśmy użyć narzędzia hostowanego czy zbudować stronę sami?
Narzędzia hostowane priorytetowo traktują szybkość uruchomienia i niezawodność (często pozostają online nawet jeśli twoja aplikacja padnie) i zwykle zawierają subskrypcje oraz integracje.
DIY daje pełną kontrolę, ale musisz projektować pod kątem odporności:
- Preferuj stronę statyczną + CDN
- Oddziel hostowanie (i najlepiej DNS) od stosu produkcyjnego
- Upewnij się, że aktualizacje można publikować, gdy podstawowe systemy są zdegradowane
Jakie kanały powiadomień powinniśmy oferować i jak zapobiegać zmęczeniu alertami?
Oferuj kanały, których klienci już używają (zwykle email i SMS, plus Slack/Teams lub RSS). Trzymaj subskrypcje opty‑in i wyjaśnij:
- Co będą otrzymywać (incydenty, konserwacje lub oba)
- Opcjonalne filtrowanie po komponencie lub ciężkości
Testuj dostarczalność i limity szybkości okresowo, aby powiadomienia działały, gdy ruch gwałtownie rośnie podczas incydentu.