26 sie 2025·8 min
Jak tworzyć produkty AI-first z modelami w logice aplikacji
Praktyczny przewodnik po tworzeniu produktów AI-first, w których to model podejmuje decyzje: architektura, prompty, narzędzia, dane, ewaluacja, bezpieczeństwo i monitoring.
Co znaczy budować produkt AI-first
Budowanie produktu AI-first nie oznacza „dodania chatbota”. To znaczy, że model jest rzeczywistą, działającą częścią logiki twojej aplikacji — tak samo jak silnik reguł, indeks wyszukiwania czy algorytm rekomendacji.
Twoja aplikacja nie tylko używa AI; jest zaprojektowana wokół założenia, że model będzie interpretować dane wejściowe, wybierać działania i generować ustrukturyzowane wyniki, na których reszta systemu polega.
W praktyce: zamiast na stałe zapisywać każdą ścieżkę decyzyjną („jeśli X to zrób Y”), pozwalasz modelowi obsłużyć rozmyte części — język, intencję, dwuznaczność, priorytety — podczas gdy twój kod zajmuje się tym, co musi być dokładne: uprawnieniami, płatnościami, zapisami w bazie danych i egzekwowaniem polityk.
Kiedy AI-first ma sens (a kiedy nie)
AI-first sprawdza się najlepiej, gdy problem ma:
- Wiele prawidłowych wejść (tekst wolny, nieuporządkowane dokumenty, różnorodne cele użytkowników)
- Zbyt wiele przypadków brzegowych, by utrzymywać reguły ręcznie
- Wartość w ocenie, streszczeniu lub syntezie zamiast w doskonałej deterministyczności
Automatyzacja oparta na regułach jest zwykle lepsza, gdy wymagania są stabilne i dokładne — obliczenia podatkowe, logika zapasów, sprawdzenia uprawnień czy przepływy zgodności, gdzie wynik musi być zawsze taki sam.
Typowe cele produktowe, które wspiera AI-first
Zespoły zwykle przyjmują logikę sterowaną modelem, aby:
- Zwiększyć szybkość: szkice odpowiedzi, wydobywanie pól, szybsze kierowanie zgłoszeń
- Spersonalizować doświadczenie: dopasować wyjaśnienia, plany lub rekomendacje
- Wspierać decyzje: podkreślać kompromisy, generować opcje, podsumowywać dowody
Kompromisy, które trzeba zaakceptować (i zaprojektować dla nich)
Modele mogą być nieprzewidywalne, czasem pewne co do błędnych odpowiedzi, a ich zachowanie może się zmieniać wraz z promptami, dostawcami lub pobranym kontekstem. Dodają też koszty na zapytanie, mogą wprowadzać opóźnienia i rodzić obawy związane z bezpieczeństwem i zaufaniem (prywatność, szkodliwe treści, naruszenia polityk).
Właściwe podejście: traktuj model jako komponent, a nie magiczną skrzynkę z odpowiedziami. Traktuj go jak zależność z wymaganiami, trybami awaryjnymi, testami i monitoringiem — dzięki temu zyskasz elastyczność bez opierania produktu na życzeniach.
Wybierz odpowiedni przypadek użycia i zdefiniuj sukces
Nie każda funkcja zyska na tym, że model przejmuje ster. Najlepsze przypadki AI-first zaczynają się od jasno określonej pracy do wykonania i kończą mierzalnym wynikiem, który możesz śledzić tydzień do tygodnia.
Zacznij od zadania, nie od modelu
Zapisz jednozdaniową historię zadania: „Gdy ___, chcę ___, żeby móc ___.” Następnie spraw, by wynik był mierzalny.
Przykład: „Gdy otrzymuję długi e-mail od klienta, chcę propozycję odpowiedzi zgodną z naszymi politykami, żeby móc odpowiedzieć w mniej niż 2 minuty.” To jest zdecydowanie bardziej praktyczne niż „dodaj LLM do e-maila”.
Zmapuj punkty decyzyjne
Zidentyfikuj momenty, w których model będzie wybierał działania. Te punkty decyzyjne powinny być jawne, aby można je było testować.
Typowe punkty decyzyjne to:
- Klasyfikacja intencji i skierowanie do odpowiedniego workflow
- Decyzja, czy zadać pytanie doprecyzowujące, czy kontynuować
- Wybór narzędzi (wyszukiwanie, sprawdzenie w CRM, szkicowanie, tworzenie zgłoszenia)
- Decyzja, kiedy eskalować do człowieka
Jeśli nie potrafisz nazwać decyzji, nie jesteś gotowy do wdrożenia logiki sterowanej modelem.
Napisz kryteria akceptacji dla zachowania
Traktuj zachowanie modelu jak każde inne wymaganie produktowe. Zdefiniuj, co oznacza „dobrze” i „źle” prostym językiem.
Na przykład:
- Dobrze: używa aktualnej polityki, cytuje poprawny numer zamówienia, zada jedno jasne pytanie, jeśli brakuje danych
- Źle: wymyśla zniżki, odnosi się do nieobsługiwanych lokalizacji, odpowiada bez sprawdzenia wymaganych danych
Te kryteria staną się podstawą do zestawu ewaluacyjnego później.
Wcześnie zidentyfikuj ograniczenia
Wypisz ograniczenia, które kształtują decyzje projektowe:
- Czas (cele dotyczące opóźnień odpowiedzi)
- Budżet (koszt za zadanie)
- Zgodność (obsługa PII, wymagania audytowe)
- Obsługiwane lokalizacje (języki, ton, oczekiwania kulturowe)
Zdefiniuj metryki sukcesu, które możesz monitorować
Wybierz mały zestaw metryk powiązanych z zadaniem:
- Wskaźnik ukończenia zadania
- Dokładność (lub zgodność z polityką) na reprezentatywnych przypadkach
- CSAT lub jakościowa ocena użytkownika
- Czas zaoszczędzony na zadaniu (lub czas do rozwiązania)
Jeśli nie potrafisz zmierzyć sukcesu, skończy się to kłótnią o wrażenia zamiast ulepszaniem produktu.
Zaprojektuj przepływ użytkownika sterowany AI i granice systemu
Przepływ AI-first to nie „ekran, który wywołuje LLM”. To pełna ścieżka, w której model podejmuje określone decyzje, produkt wykonuje je bezpiecznie, a użytkownik pozostaje zorientowany.
Zmapuj pętlę end-to-end
Zacznij od narysowania potoku jako prostego łańcucha: wejścia → model → akcje → wyjścia.
- Wejścia: to, co dostarcza użytkownik (tekst, pliki, wybory) oraz kontekst aplikacji (poziom konta, workspace, ostatnia aktywność).
- Krok modelu: za co model odpowiada (klasyfikacja, szkic, streszczenie, wybór następnej akcji).
- Akcje: co może wykonać twój system (wyszukiwanie, utworzenie zadania, aktualizacja rekordu, wysłanie e-maila).
- Wyjścia: co widzi użytkownik (szkic, wyjaśnienie, ekran potwierdzenia, błąd z kolejnymi krokami).
Ta mapa wymusza jasność, gdzie dopuszczalna jest niepewność (tworzenie szkiców), a gdzie jej nie ma (zmiany w fakturowaniu).
Wyznacz granice systemu: model vs kod deterministyczny
Oddziel ścieżki deterministyczne (sprawdzanie uprawnień, reguły biznesowe, obliczenia, zapisy w bazie) od decyzji sterowanych modelem (interpretacja, priorytetyzacja, generowanie w języku naturalnym).
Przydatna zasada: model może zaproponować, ale kod musi zweryfikować zanim cokolwiek nieodwracalnego się wydarzy.
Zdecyduj, gdzie działa model
Wybierz środowisko uruchomieniowe na podstawie ograniczeń:
- Serwer: najlepszy dla prywatnych danych, spójnych narzędzi, logów audytu.
- Klient: przydatny dla lekkiej pomocy i prywatności poprzez lokalne przetwarzanie, ale trudniejszy do kontrolowania.
- Edge: szybsze globalne opóźnienia, ale ograniczone zależności.
- Hybrid: szybkie wykrywanie intencji na edge i cięższa praca na serwerze.
Zaplanuj opóźnienia, koszty i uprawnienia do danych
Ustal budżet na pojedyncze żądanie dotyczący opóźnienia i kosztów (wliczając powtórzenia i wywołania narzędzi), a potem zaprojektuj UX wokół tego (streaming, progresywne wyniki, „kontynuuj w tle”).
Udokumentuj źródła danych i uprawnienia potrzebne na każdym etapie: co model może czytać, co może zapisywać i co wymaga wyraźnej zgody użytkownika. To stanie się kontraktem dla inżynierii i zaufania.
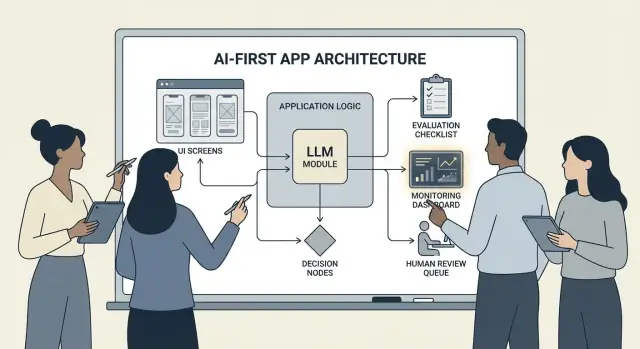
Wzorce architektoniczne: orkiestracja, stan i ślady
Gdy model jest częścią logiki aplikacji, „architektura” to nie tylko serwery i API — to sposób, w jaki niezawodnie uruchamiasz łańcuch decyzji modelu, nie tracąc kontroli.
Orkiestracja: dyrygent pracy modelu
Orkiestracja to warstwa, która zarządza sposobem wykonywania zadania AI end-to-end: promptami i szablonami, wywołaniami narzędzi, pamięcią/kontekstem, powtórzeniami, limitami czasu i ścieżkami awaryjnymi.
Dobre orkiestratory traktują model jako jeden komponent w potoku. Decydują, którego prompta użyć, kiedy wywołać narzędzie (wyszukiwanie, baza danych, e-mail, płatność), jak skompresować lub pobrać kontekst i co zrobić, jeśli model zwróci coś nieprawidłowego.
Jeśli chcesz szybciej przejść od pomysłu do działającej orkiestracji, przepływ typu vibe-coding może pomóc w prototypowaniu tych potoków bez przebudowywania szkieletu aplikacji od zera. Na przykład, Koder.ai pozwala zespołom tworzyć aplikacje webowe (React), backendy (Go + PostgreSQL) i nawet aplikacje mobilne (Flutter) za pomocą czatu — a następnie iterować nad przepływami typu „wejścia → model → wywołania narzędzi → walidacje → UI” z funkcjami takimi jak tryb planowania, snapshoty i rollback, oraz eksportem kodu źródłowego, gdy jesteś gotów przejąć repo.
Maszyny stanów dla zadań wieloetapowych
Doświadczenia wieloetapowe (triage → zbierz informacje → potwierdź → wykonaj → podsumuj) najlepiej modelować jako workflow lub maszynę stanów.
Prosty wzorzec: każdy krok ma (1) dozwolone wejścia, (2) oczekiwane wyjścia i (3) przejścia. To zapobiega błądzeniu rozmów i uwidacznia przypadki brzegowe — na przykład, co się dzieje, gdy użytkownik zmieni zdanie lub poda niepełne informacje.
Jednorazowe vs wieloetapowe rozumowanie
Jednorazowe wywołanie sprawdza się przy zadaniach zamkniętych: sklasyfikuj wiadomość, zrób krótki szkic odpowiedzi, wydobądź pola z dokumentu. Jest tańsze, szybsze i łatwiejsze do walidacji.
Wieloetapowe rozumowanie jest lepsze, gdy model musi zadawać pytania doprecyzowujące lub gdy narzędzia są potrzebne iteracyjnie (np. plan → wyszukaj → dopracuj → potwierdź). Używaj go świadomie i ogranicz liczbę pętli czasowo lub liczbowo.
Idempotencja: unikaj powtarzających się efektów ubocznych
Modele powtarzają żądania. Sieci zawodzą. Użytkownicy klikają podwójnie. Jeśli krok AI może wywołać efekty uboczne — wysłanie e-maila, rezerwację, obciążenie karty — upewnij się, że jest idempotentny.
Typowe taktyki: dołącz klucz idempotencji do każdej akcji „execute”, zapisz wynik akcji i zapewnij, że powtórzenia zwracają ten sam rezultat zamiast powtarzać działanie.
Ślady: spraw, by każdy krok dało się debugować
Dodaj śledzenie, by móc odpowiedzieć: Co model zobaczył? Co postanowił? Jakie narzędzia zostały uruchomione?
Loguj ustrukturyzowany ślad dla każdego uruchomienia: wersja prompta, wejścia, identyfikatory pobranego kontekstu, żądania/odpowiedzi narzędzi, błędy walidacji, powtórzenia i końcowy wynik. To zamienia „AI zrobiło coś dziwnego” w audytowalną, możliwą do naprawienia linię czasu.
Promptowanie jako logika produktowa: jasne kontrakty i formaty
Gdy model jest częścią logiki aplikacji, twoje prompty przestają być „tekstem reklamowym” i stają się wykonalnymi specyfikacjami. Traktuj je jak wymagania produktowe: zakres, przewidywalne wyjścia i kontrola zmian.
Zacznij od prompta systemowego, który definiuje kontrakt
Twój prompt systemowy powinien określać rolę modelu, co może, a czego nie może robić, oraz zasady bezpieczeństwa ważne dla produktu. Trzymaj go stabilnym i wielokrotnego użytku.
Zawrzyj:
- Rolę i cel: kim jest (np. „asystent triage wsparcia”) i jak wygląda sukces.
- Granice zakresu: czego żądań ma odmówić lub eskalować.
- Zasady bezpieczeństwa: obsługa PII, zastrzeżenia medyczne/prawne, brak zgadywania.
- Politykę użycia narzędzi: kiedy wywoływać narzędzia, a kiedy odpowiadać bez nich.
Strukturyzuj prompt z jasnymi wejściami/wyjściami
Pisz prompt jak definicję API: wypisz dokładne wejścia, które dostarczasz (tekst użytkownika, poziom konta, locale, fragmenty polityk) i dokładne wyjścia, których oczekujesz. Dodaj 1–3 przykłady odpowiadające rzeczywistemu ruchowi, włączając trudne przypadki.
Przydatny wzorzec: Kontekst → Zadanie → Ograniczenia → Format wyjścia → Przykłady.
Używaj ograniczonych formatów dla wyników czytelnych maszynowo
Jeśli kod ma działać na wyniku, nie polegaj na prozie. Poproś o JSON zgodny ze schematem i odrzuć wszystko inne.
{
"type": "object",
"properties": {
"intent": {"type": "string"},
"confidence": {"type": "number", "minimum": 0, "maximum": 1},
"actions": {
"type": "array",
"items": {"type": "string"}
},
"user_message": {"type": "string"}
},
"required": ["intent", "confidence", "actions", "user_message"],
"additionalProperties": false
}
Wersjonuj prompt i wdrażaj bezpiecznie
Przechowuj prompt w kontroli wersji, taguj wydania i wdrażaj jak funkcję: etapowe wdrożenie, A/B tam, gdzie to sensowne, oraz szybki rollback. Loguj wersję prompta z każdą odpowiedzią dla debugowania.
Zbuduj zestaw testów promptów
Utwórz mały, reprezentatywny zestaw przypadków (happy path, niejednoznaczne żądania, naruszenia polityk, długie wejścia, różne locale). Uruchamiaj je automatycznie przy każdej zmianie prompta i blokuj build, gdy wyjścia łamią kontrakt.
Wywoływanie narzędzi: niech model zdecyduje, kod wykona
Szybko prototypuj logikę AI
Zbuduj przepływ AI-first za pomocą czatu, a następnie iteruj bezpiecznie dzięki snapshotom i rollbackowi.
Wywoływanie narzędzi to najczystszy sposób podziału odpowiedzialności: model decyduje co trzeba zrobić i które narzędzie użyć, a twoja aplikacja wykonuje akcję i zwraca zweryfikowane wyniki.
To pozwala trzymać fakty, obliczenia i efekty uboczne (tworzenie zgłoszeń, aktualizacje, wysyłka e-maili) w kodzie deterministycznym i audytowalnym — zamiast ufać swobodnemu tekstowi.
Zaprojektuj mały, celowy zestaw narzędzi
Zacznij od kilku narzędzi, które pokrywają 80% żądań i są łatwe do zabezpieczenia:
- Search (twoja dokumentacja/centrum pomocy) do odpowiadania na pytania o produkt
- DB lookup (najpierw tylko do odczytu) dla statusu użytkownika/konta/zamówienia
- Kalkulator do cen, sum, konwersji i matematyki regułowej
- Ticketing do otwierania zgłoszeń, gdy użytkownik potrzebuje kontaktu człowieka
Utrzymuj celowość każdego narzędzia. Narzędzie, które robi „wszystko”, staje się trudne do testowania i łatwe do nadużycia.
Waliduj wejścia, sanityzuj wyjścia
Traktuj model jak nieufnego wywołującego.
- Waliduj wejścia do narzędzi za pomocą ścisłych schematów (typy, zakresy, enumeracje). Odrzucaj lub naprawiaj niebezpieczne argumenty (np. brakujące ID, zbyt ogólne zapytania).
- Sanityzuj wyjścia narzędzi zanim przekażesz je z powrotem do modelu: usuń sekrety, ujednolić formaty i zwróć tylko pola, których model potrzebuje.
To redukuje ryzyko injekcji promptów przez pobrany tekst i ogranicza przypadkowe wycieki danych.
Dodaj uprawnienia i limity na każde narzędzie
Każde narzędzie powinno egzekwować:
- Sprawdzenia uprawnień (kto ma dostęp do których rekordów i akcji)
- Limity zapytań (na użytkownika/session/narzędzie) by ograniczyć nadużycia i pętle
Jeśli narzędzie może zmieniać stan (ticketing, zwroty), wymagaj silniejszej autoryzacji i zapisz log audytu.
Zawsze wspieraj ścieżkę „bez narzędzia”
Czasem najlepszą akcją jest brak akcji: odpowiedzieć z istniejącego kontekstu, zadać pytanie doprecyzowujące lub wyjaśnić ograniczenia.
Uczyń „bez narzędzia” równorzędnym wynikiem, żeby model nie wywoływał narzędzi tylko po to, by „wyglądać zajętym”.
Dane i RAG: ugruntuj model w swojej rzeczywistości
Jeśli odpowiedzi twojego produktu muszą odpowiadać twoim politykom, stanom magazynowym, umowom czy wiedzy wewnętrznej, musisz ugruntować model w swoich danych — nie tylko w jego ogólnym treningu.
RAG vs. fine-tuning vs. prosty kontekst
- Prosty kontekst (wklejenie kilku akapitów do prompta) działa, gdy wiedza jest mała, stabilna i można ją wysyłać za każdym razem (np. krótka tabela cen).
- RAG (Retrieval-Augmented Generation) jest najlepszy, gdy informacje są obszerne, często się zmieniają lub wymagają cytowań (np. artykuły help-center, dokumentacja produktu, dane specyficzne dla konta).
- Fine-tuning sprawdza się, gdy chcesz spójnego stylu/formatu lub wzorców specyficznych dla domeny — nie jako główny sposób „przechowywania faktów”. Użyj go do poprawy sposobu, w jaki model pisze i przestrzega reguł; łącz z RAG dla aktualnej prawdy.
Podstawy ingestii: chunkowanie, metadane, świeżość
Jakość RAG to głównie problem ingestii.
Dziel dokumenty na kawałki dopasowane do modelu (często kilkaset tokenów), najlepiej zgodne z naturalnymi granicami (nagłówki, wpisy FAQ). Przechowuj metadane takie jak: tytuł dokumentu, nagłówek sekcji, produkt/wersja, grupa docelowa, locale i uprawnienia.
Planuj świeżość: harmonogram reindeksacji, śledź „ostatnia aktualizacja” i wygasaj stare fragmenty. Przestarzały fragment, który wysoko się klasyfikuje, potrafi cicho pogorszyć całą funkcję.
Cytowania i skalibrowane odpowiedzi
Miej model zwracający cytaty przez: (1) odpowiedź, (2) listę identyfikatorów fragmentów/tekstu źródłowego, i (3) oświadczenie o pewności.
Jeśli wyniki wyszukiwania są skąpe, nakazuj modelowi powiedzieć, czego nie może potwierdzić i zaproponować dalsze kroki („Nie znalazłem tej polityki; skontaktuj się z ...”). Unikaj pozwalania mu na zapełnianie luk.
Dane prywatne: kontrola dostępu i redakcja
Wymuś filtr przed pobraniem (filtrowanie według uprawnień użytkownika/organizacji) i ponownie przed generacją (redakcja wrażliwych pól).
Traktuj osadzenia (embeddings) i indeksy jako wrażliwe magazyny danych z logami audytu.
Gdy retrieval zawodzi: łagodne fallbacky
Jeśli najlepsze wyniki są nieistotne lub puste, zamiast zgadywać: zapytaj doprecyzowująco, skieruj do wsparcia człowieka lub przełącz na tryb bez-RAG, który wyjaśnia ograniczenia zamiast zgadywać.
Niezawodność: zabezpieczenia, walidacja i cache
Gdy model siedzi w logice aplikacji, „wystarczająco dobrze większość czasu” nie wystarcza. Niezawodność oznacza, że użytkownik widzi spójne zachowanie, system bezpiecznie konsumuje wyjścia, a awarie degradują się łagodnie.
Zdefiniuj cele niezawodności (przed dodaniem poprawek)
Spisz, co „niezawodne” znaczy dla funkcji:
- Spójne wyjścia: podobne wejścia powinny dawać porównywalne odpowiedzi (ton, poziom szczegółów, ograniczenia).
- Stabilne formaty: odpowiedź musi być parsowalna za każdym razem (JSON, lista wypunktowana, konkretne pola).
- Zachowanie w granicach: jasne limity działania modelu (bez zgadywania, cytuj źródła, zadawaj pytanie, gdy niepewny).
Te cele stają się kryteriami akceptacji dla promptów i kodu.
Zabezpieczenia: waliduj, filtruj i egzekwuj polityki
Traktuj wyjście modelu jako nieufne wejście.
- Walidacja schematu: wymagaj ścisłego formatu (np. JSON z wymaganymi kluczami) i odrzucaj wszystko, co się nie parsuje.
- Filtry treści: uruchamiaj sprawdzenia wulgarności, detektory PII lub walidatory polityk zarówno na wejściu użytkownika, jak i na wyjściu modelu.
- Reguły biznesowe: egzekwuj ograniczenia w kodzie (zakresy cen, reguły uprawnień, dozwolone akcje), nawet jeśli prompt je wymienia.
Jeśli walidacja zawiedzie, zwróć bezpieczny fallback (zadaj pytanie doprecyzowujące, przełącz na prostszy szablon lub skieruj do człowieka).
Powtórzenia, które rzeczywiście pomagają
Unikaj ślepego powtarzania. Ponawiaj z zmienionym promptem, który adresuje tryb awaryjny:
- „Zwróć tylko poprawny JSON. Bez markdown.”
- „Jeśli niepewny, ustaw
confidencena niskie i zadaj jedno pytanie.”
Limituj powtórzenia i loguj powód każdej nieudanej próby.
Deterministyczne post-processing
Użyj kodu do normalizacji tego, co model generuje:
- kanonizuj jednostki, daty i nazwy
- usuwaj duplikaty
- stosuj reguły rankingowe lub progi
To redukuje zmienność i ułatwia testowanie wyjść.
Cache bez problemów prywatności
Cacheuj powtarzalne wyniki (np. identyczne zapytania, współdzielone osadzenia, odpowiedzi narzędzi), by zmniejszyć koszty i opóźnienia.
Preferuj:
- krótkie TTL dla danych specyficznych dla użytkownika
- klucze cache, które wykluczają surowe PII (lub haszuj ostrożnie)
- flagi „nie cache’ować” dla wrażliwych przepływów
Dobrze przeprowadzony caching zwiększa spójność przy zachowaniu zaufania użytkownika.
Bezpieczeństwo i zaufanie: zmniejsz ryzyko bez zabijania UX
Uruchom pod własną marką
Umieść swoją aplikację AI-first na własnej domenie, gdy będzie gotowa dla użytkowników.
Bezpieczeństwo nie jest warstwą zgodności doklejaną na końcu. W produktach AI-first model wpływa na działania, słowa i decyzje — dlatego bezpieczeństwo musi być częścią kontraktu produktowego: co asystent może robić, czego musi odmówić i kiedy ma poprosić o pomoc.
Kluczowe obawy bezpieczeństwa do zaprojektowania
Nazwij ryzyka, które faktycznie dotykają twoją aplikację, a potem odwzoruj każde na kontrolę:
- Dane wrażliwe: identyfikatory osobiste, poświadczenia, prywatne dokumenty i wszystko regulowane prawnie.
- Szkodliwe wskazówki: instrukcje mogące umożliwić samookaleczenie, przemoc, działalność nielegalną lub niebezpieczne działania medyczne/finansowe.
- Stronniczość i niesprawiedliwe wyniki: niespójna jakość usług, rekomendacji lub decyzji między grupami.
Tematy dozwolone/zablokowane + ścieżki eskalacji
Napisz eksplicytną politykę, którą produkt może egzekwować. Bądź konkretny: kategorie, przykłady i oczekiwane odpowiedzi.
Użyj trzech poziomów:
- Dozwolone: odpowiadaj normalnie.
- Ograniczone: odpowiadaj z ograniczeniami (np. ogólne informacje, bez instrukcji krok po kroku).
- Zablokowane: odmów i skieruj do ścieżki eskalacji (wsparcie, zasoby lub człowiek).
Eskalacja powinna być przepływem produktowym, nie tylko komunikatem odmownym. Zapewnij opcję „Porozmawiaj z człowiekiem” i upewnij się, że przekazanie zawiera kontekst, który użytkownik już podał (za zgodą).
Przegląd ludzki dla działań o dużym wpływie
Jeśli model może wywołać realne konsekwencje — płatności, zwroty, zmiany konta, anulowania, usuwanie danych — dodaj punkt kontrolny.
Dobre wzorce: ekrany potwierdzające, „szkicuj, potem zatwierdź”, limity (progi kwotowe) i kolejka do przeglądu przez człowieka dla przypadków brzegowych.
Ujawnienia, zgoda i testowalne polityki
Informuj użytkowników, gdy rozmawiają z AI, jakie dane są używane i co jest przechowywane. Proś o zgodę tam, gdzie potrzeba, szczególnie przy zapisywaniu konwersacji lub użyciu danych do ulepszania systemu.
Traktuj wewnętrzne polityki bezpieczeństwa jak kod: wersjonuj je, dokumentuj racjonalność i dodawaj testy (przykładowe prompti + oczekiwane wyniki), by bezpieczeństwo nie regresowało przy każdej zmianie prompta lub modelu.
Ewaluacja: testuj model jak każdy inny krytyczny komponent
Jeśli LLM może zmienić działanie twojego produktu, potrzebujesz powtarzalnego sposobu, by udowodnić, że nadal działa — zanim użytkownicy odkryją regresje za ciebie.
Traktuj prompt, wersje modeli, schematy narzędzi i ustawienia retrieval jako artefakty wymagające testów.
Zbuduj zestaw ewaluacyjny z realnych danych
Zbieraj prawdziwe intencje użytkowników z ticketów wsparcia, zapytań wyszukiwania, logów czatu (za zgodą) i rozmów handlowych. Zamieniaj je na przypadki testowe, które zawierają:
- Typowe żądania happy-path
- Niejasne prompti, wymagające pytań doprecyzowujących
- Przypadki brzegowe (brak danych, sprzeczne ograniczenia, nietypowe formaty)
- Scenariusze wrażliwe politycznie (dane osobowe, treści niedozwolone)
Każdy przypadek powinien zawierać oczekiwane zachowanie: odpowiedź, podjęta decyzja (np. „wywołaj narzędzie A”) i wymagane struktury (pola JSON obecne, cytowania itp.).
Wybierz metryki odpowiadające ryzyku produktowemu
Jedna metryka nie uchwyci jakości. Użyj małego zestawu metryk powiązanych z wynikiem użytkownika:
- Dokładność / sukces zadania: czy osiągnął cel użytkownika?
- Ugruntowanie: czy twierdzenia są poparte kontekstem lub źródłami?
- Poprawność formatu: czy wyjście spełnia kontrakt (JSON, tabela, punktor)?
- Wskaźnik odmówień: czy odmawia, gdy powinien — i unika odmawiania, gdy nie powinien?
Monitoruj też koszt i opóźnienie obok jakości; „lepszy” model, który podwaja czas odpowiedzi, może pogorszyć konwersję.
Uruchamiaj offline ewaluacje przy każdej zmianie
Uruchamiaj ewaluacje offline przed wydaniem i po każdej zmianie prompta, modelu, narzędzia lub ustawień retrieval. Przechowuj wyniki wersjonowane, by porównywać przebiegi i szybko lokalizować, co się zepsuło.
Dodaj testy online z zabezpieczeniami
Używaj testów A/B, by mierzyć rzeczywiste rezultaty (wskaźnik ukończeń, edycje, oceny użytkowników), ale dodaj bezpieczniki: zdefiniuj warunki zatrzymania (np. skoki w liczbie niepoprawnych wyjść, odmówień lub błędów narzędzi) i automatycznie wycofuj, gdy progi są przekroczone.
Monitoring w produkcji: dryfy, błędy i feedback
Iteruj bez obaw
Eksperymentuj z promptami i narzędziami, a potem szybko cofnij zmiany, gdy coś przestanie działać.
Wypuszczenie funkcji AI-first to nie kres. Gdy przyjdą prawdziwi użytkownicy, model napotka nowe sformułowania, przypadki brzegowe i zmieniające się dane. Monitoring zamienia „działało na stagingu” w „działa cały następny miesiąc”.
Loguj to, co ważne (bez zbierania sekretów)
Zbieraj wystarczający kontekst do odtworzenia błędów: intencję użytkownika, wersję prompta, wywołania narzędzi i końcowe wyjście modelu.
Loguj wejścia/wyjścia z redakcją prywatności. Traktuj logi jak dane wrażliwe: usuwaj e-maile, numery telefonów, tokeny i teksty, które mogą zawierać dane osobowe. Miej „tryb debugowania”, który możesz włączyć tymczasowo dla konkretnych sesji zamiast domyślnego maksymalnego logowania.
Obserwuj właściwe sygnały
Monitoruj wskaźniki błędów, awarie narzędzi, naruszenia schematu i dryf. Konkretnie śledź:
- Sukces wywołań narzędzi i limity czasowe (czy model wybrał właściwe narzędzie i czy wykonanie się powiodło?)
- Zgodność formatu/schematu wyjść (czy walidatory odrzuciły?)
- Użycie fallbacków (jak często trzeba użyć bezpieczniejszej lub prostszej ścieżki)
- Blokowania bezpieczeństwa (jak często odmówiono lub poddano sanitacji)
Dla dryfu porównuj aktualny ruch do bazowego: zmiany w miksie tematów, języku, średniej długości prompta i „nieznanych” intencjach. Dryf nie zawsze jest zły — ale zawsze jest sygnałem do ponownej oceny.
Alerty, runbooki i reagowanie na incydenty
Ustal progi alertów i runbooki on-call. Alerty powinny wskazywać działania: cofnąć wersję prompta, wyłączyć wadliwe narzędzie, zaostrzyć walidację lub przełączyć na fallback.
Zaplanuj reakcję na incydenty związane z niebezpiecznym lub niepoprawnym zachowaniem. Zdefiniuj, kto może przełączyć wyłączniki bezpieczeństwa, jak powiadomić użytkowników i jak udokumentujesz oraz wyciągniesz naukę z zdarzenia.
Zamknij pętlę feedbackiem od użytkowników
Wykorzystaj pętle feedbacku: kciuk w górę/w dół, kody przyczyn, zgłoszenia błędów. Zapytaj krótko „dlaczego?” (błędne fakty, nie realizuje instrukcji, niebezpieczne, zbyt wolne), żeby kierować problemy do właściwej naprawy — prompt, narzędzia, dane czy polityka.
UX dla logiki sterowanej modelem: przejrzystość i kontrola
Funkcje sterowane modelem działają magicznie, gdy działają — i wydają się kruche, gdy nie działają. UX musi zakładać niepewność i jednocześnie pomóc użytkownikowi dokończyć zadanie.
Pokaż „dlaczego” bez przytłaczania
Użytkownicy bardziej ufają wynikom AI, gdy widzą ich źródło — nie dlatego, że chcą wykładu, ale ponieważ pomaga to zdecydować, czy działać.
Użyj progresywnego ujawniania:
- Zacznij od wyniku (odpowiedź, szkic, rekomendacja).
- Oferuj przycisk „Dlaczego?” lub „Pokaż pracę”, który ujawnia kluczowe wejścia: żądanie użytkownika, użyte narzędzia i źródła lub rekordy, które sprawdzono.
- Jeśli używasz retrieval, pokaż cytowania prowadzące do konkretnego fragmentu (np. „Na podstawie: Polityka §3.2”). Trzymaj to zwięzłe.
Jeśli masz głębszy opis, odnoś wewnętrznie (np. /blog/rag-grounding) zamiast zapełniać UI detalami.
Projektuj dla niepewności (bez strasznych ostrzeżeń)
Model to nie kalkulator. Interfejs powinien komunikować pewność i zachęcać do weryfikacji.
Praktyczne wzorce:
- Wskazówki pewności w prostym języku („Prawdopodobnie poprawne”, „Wymaga weryfikacji”) zamiast fałszywej precyzji.
- Opcje zamiast jednej odpowiedzi: „Oto 3 sposoby odpowiedzi.” To zmniejsza koszt złego pierwszego wyboru.
- Potwierdzenia dla działań o dużym wpływie (wysyłka e-maili, usuwanie danych, płatności). Zapytaj jasno: „Wysłać tę wiadomość do 12 odbiorców?”
Ułatw poprawki i odzyskiwanie
Użytkownik powinien móc nakierować wynik bez zaczynania od nowa:
- Edycja inline z „Zastosuj zmiany”, aby model kontynuował od poprawek użytkownika.
- „Regeneruj” z kontrolami (ton, długość, ograniczenia) zamiast losowego ponownego generowania.
- „Cofnij” i widoczna historia, by błędy były odwracalne.
Zapewnij wyjście awaryjne
Gdy model zawiedzie — lub użytkownik nie ma pewności — zaoferuj deterministyczny przepływ lub pomoc człowieka.
Przykłady: „Przełącz na formularz ręczny”, „Użyj szablonu” lub „Skontaktuj się ze wsparciem” (np. /support). To nie jest fallback wstydliwy; to sposób na ochronę ukończenia zadania i zaufania.
Od prototypu do produkcji (bez przebudowywania wszystkiego)
Większość zespołów nie zawodzi, bo LLM-y nie potrafią; zawodzi, bo droga od prototypu do niezawodnej, testowalnej funkcji jest dłuższa, niż się spodziewano.
Praktyczny sposób skrócenia tej drogi to wczesne uzstandardyzowanie „szkieletu produktu”: maszyny stanów, schematy narzędzi, walidacje, ślady i historia wdrożeń/rollbacków. Platformy takie jak Koder.ai mogą być tu pomocne, gdy chcesz szybko postawić workflow AI-first — budując UI, backend i bazę danych razem — a następnie iterować bezpiecznie ze snapshotami/rollbackiem, własnymi domenami i hostingiem. Gdy będziesz gotów do operacjonalizacji, możesz wyeksportować kod źródłowy i kontynuować z preferowanym CI/CD i stosami obserwowalności.