Ustal cele i określ użytkowników
Zanim zaprojektujesz ekrany lub wybierzesz stack technologiczny, zdecyduj, jak wygląda sukces dla twojej aplikacji logistycznej. „Śledzenie” może znaczyć wiele rzeczy, a niejasne cele zazwyczaj prowadzą do zaśmieconego produktu, którego nikt nie polubi.
Zacznij od jasnego celu biznesowego
Wybierz jeden główny cel biznesowy i kilka celów wspierających. Przykłady:
- Mniej opóźnionych dostaw (i mniej kar umownych)
- Mniej telefonów „Gdzie jest mój kierowca?”
- Lepsza widoczność dla dyspozytora przy wyjątkach (ruch, opóźnienia, nieudane przystanki)
Dobry cel jest wystarczająco konkretny, by kierować decyzjami. Na przykład „zmniejszyć liczbę opóźnionych dostaw” popchnie cię w stronę dokładnych ETA i obsługi wyjątków — a nie tylko ładniejszej mapy.
Zdefiniuj użytkowników (i czego każdy potrzebuje)
Większość systemów do śledzenia dostaw obsługuje kilka grup użytkowników. Zdefiniuj je wcześnie, żeby nie budować wszystkiego pod jedną rolę.
- Dyspozytor: potrzebuje żywego panelu dyspozycyjnego, szybkich możliwości reasignacji i pewności, co dzieje się teraz.
- Kierowca: potrzebuje prostego przepływu (start trasy → przyjazd → zakończenie przystanku), minimalnego wpisywania i niezawodnej nawigacji.
- Kierownik/operations lead: potrzebuje raportów wydajności, trendów w czasie i odpowiedzialności.
- Obsługa klienta: potrzebuje szybkich odpowiedzi: ostatni znany status, ostatnia aktualizacja od kierowcy i przewidywany kolejny krok.
Wybierz 3 mierzalne wyniki
Ogranicz się do trzech, by MVP pozostało skupione. Typowe metryki:
- Wskaźnik terminowych dostaw (np. poprawa z 92% do 96%)
- Liczba nieudanych przystanków / ponownych prób (błędny adres, nieobecny klient)
- Czas bezczynności (nieplanowane przystanki, czas między dostawami)
Wyjaśnij, co dla zespołu znaczy „śledzenie”
Zapisz dokładne sygnały, które system będzie przechwytywał:
- Śledzenie lokalizacji: ostatni znany punkt GPS, częstotliwość aktualizacji i zasady „starej” lokalizacji
- Aktualizacje statusu: planned → assigned → en route → arrived → delivered/failed
- Potwierdzenie doręczenia: zdjęcie, podpis, imię, stempel czasowy i opcjonalne notatki
Ta definicja stanie się wspólnym kontraktem przy decyzjach produktowych i oczekiwaniach zespołu.
Zmapuj przepływ dostawy i statusy
Zanim zaprojektujesz ekrany lub wybierzesz narzędzia, zgódźcie się na jedną "prawdę" o tym, jak dostawa przechodzi przez operację. Jasny workflow zapobiega zamieszaniu typu „Czy ten przystanek jest nadal otwarty?” albo „Dlaczego nie mogę przypisać tego zadania?” — i sprawia, że raportowanie jest wiarygodne.
Podstawowy przepływ dostawy (end-to-end)
Większość zespołów logistycznych zgodzi się na prosty kręgosłup:
Create jobs → assign driver → navigate → deliver → close out.
Nawet jeśli biznes ma przypadki specjalne (zwroty, trasy z wieloma punktami, pobranie przy dostawie), traktuj je jako wyjątki, a nie odrębny flow dla każdego klienta.
Statusy, które wszyscy rozumieją tak samo
Zdefiniuj statusy prostym językiem i spraw, by były wzajemnie wykluczające. Praktyczny zestaw to:
- Planned: zadanie istnieje, jeszcze nie przypisane do kierowcy
- Assigned: kierowca jest odpowiedzialny, ale jeszcze nie ruszył
- En route: kierowca zmierza do następnego przystanku
- Arrived: kierowca dotarł na miejsce
- Delivered: zakończone pomyślnie z dowodem
- Failed: próba wykonania, ale bez sukcesu (z powodem)
Uzgodnij, co powoduje każdą zmianę statusu. Na przykład "En route" może pojawiać się automatycznie po naciśnięciu „Start navigation”, podczas gdy „Delivered” powinno być zawsze potwierdzone ręcznie.
Działania kierowcy i dyspozytora (kto co może robić)
Działania kierowcy do obsługi:
- Rozpoczęcie zmiany, akceptacja zadania
- Skan/potwierdzenie pozycji, zbieranie podpisu/zdjęcia
- Oznaczenie jako delivered lub failed z powodem
Działania dyspozytora do obsługi:
- Przypisanie/reasignacja zadania, edycja przystanków
- Kontakt z kierowcą (skróty do połączeń/wiadomości)
- Oznaczanie wyjątków (np. zamknięty klient, problem z adresem)
Aby zmniejszyć spory później, loguj każdą zmianę z kim, kiedy i dlaczego (szczególnie dla Failed i reasignacji).
Zaprojektuj model danych (Dostawy, Kierowcy, Trasy)
Jasny model danych to to, co zamienia "mapę z kropkami" w niezawodne oprogramowanie do śledzenia dostaw. Jeśli dobrze zdefiniujesz obiekty podstawowe, panel dyspozytora będzie łatwiejszy do zbudowania, raporty dokładne, a operacje nie będą polegać na obejściach.
Dostawy (zadanie)
Modeluj każdą dostawę jako zadanie przechodzące przez statusy (planned, assigned, en route, delivered, failed itd.). Dodaj pola, które wspierają decyzje dyspozycyjne, nie tylko adresy:
- Adres odbioru i dostawy (przechowuj znormalizowane pola oraz oryginalny tekst)
- Okno czasowe (earliest/latest) dla każdego przystanku
- Kontakt (imię + telefon) oraz instrukcje/notatki do dostawy
- COD (cash on delivery) i reguły metod płatności
- Priorytet (normalny/pilny) i typ usługi (same-day, standard)
Wskazówka: traktuj pickup i drop-off jako "przystanki", żeby zadanie mogło rozrosnąć się do wielopunktowej trasy bez przebudowy modelu.
Kierowcy (i pojazdy)
Kierowcy to więcej niż imię na trasie. Zbieraj ograniczenia operacyjne, żeby optymalizacja tras i przydział były realistyczne:
- Imię, telefon i dostępność/godziny zmian
- Typ pojazdu, numer rejestracyjny i ładowność (waga/objętość)
- Certyfikaty (hazmat, chłodnia, windą załadunkowa) gdy istotne
Trasy (plan)
Trasa powinna przechowywać uporządkowaną listę przystanków oraz to, czego system oczekiwał kontra co się wydarzyło:
- Uporządkowane przystanki z planowanymi ETA i czasami obsługi
- Całkowity dystans i planowany czas
- Ograniczenia (typ pojazdu, maksymalne godziny, strefy ograniczone)
Zdarzenia / dziennik audytu (prawda)
Dodaj niezmienny dziennik zdarzeń: kto co zmienił i kiedy (aktualizacje statusów, edycje, reasignacje). To wspiera reklamacje klientów, zgodność i analizę „dlaczego to było opóźnione?” — szczególnie gdy połączysz to z dowodem doręczenia i wyjątkami.
Zaplanuj kluczowe ekrany i doświadczenie użytkownika
Świetne oprogramowanie do śledzenia dostaw to w dużej mierze problem UX: właściwe informacje, we właściwym momencie, przy jak najmniejszej liczbie kliknięć. Zanim zbudujesz funkcje, naszkicuj główne ekrany i zdecyduj, co każdy użytkownik musi móc zrobić w mniej niż 10 sekund.
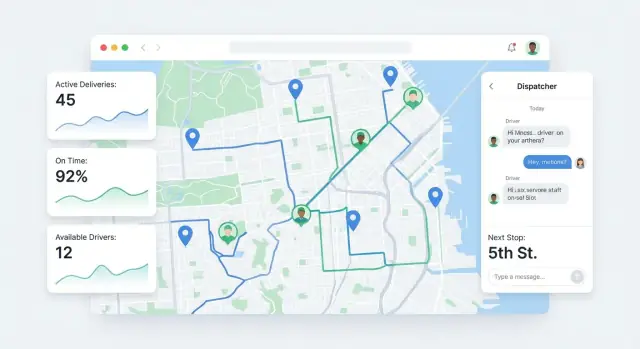
Panel dyspozytora (centrum kontroli)
To tutaj przydziela się pracę i obsługuje problemy. Zrób go „przeglądowym” i ukierunkowanym na akcję:
- Zadania na dziś z filtrami (nieprzypisane, w toku, spóźnione, failed)
- Panel wyjątków (brak odpowiedzi, problem z adresem, klient nieobecny, uszkodzony pakunek)
- Wskaźnik ryzyka opóźnienia (na podstawie harmonogramu vs. aktualny postęp)
- Przypisz/reasignuj jednym kliknięciem, plus akcje zbiorcze na ostatnią chwilę
Utrzymuj widok listy szybki, możliwy do przeszukania i zoptymalizowany pod klawiaturę.
Widok mapy (świadomość sytuacyjna)
Dyspozytorzy potrzebują mapy, która wyjaśnia przebieg dnia, a nie tylko punkty na mapie.
Pokaż pozycje kierowców na żywo, pinezki przystanków i kolorowane statusy (Planned, En route, Arrived, Delivered, Failed). Dodaj przełączniki: „pokaż tylko ryzyko opóźnienia”, „pokaż tylko nieprzypisane” i „śledź kierowcę”. Kliknięcie pinezki powinno otworzyć kompaktową kartę przystanku z ETA, notatkami i kolejnymi akcjami.
Widok kierowcy (zrób następny właściwy krok)
Ekran kierowcy powinien skupiać się na następnym przystanku, nie na całym planie.
Zawieraj: adres następnego przystanku, instrukcje (kod bramy, uwagi przy porcie), przyciski kontaktu (zleceniodawca/klient), oraz szybką aktualizację statusu z minimalnym wpisywaniem. Jeśli wspierasz POD, trzymaj go w tym samym przepływie (zdjęcie/podpis + krótka notatka).
Raporty dla menedżerów (ulepszanie operacji)
Menedżerowie potrzebują trendów, nie surowych zdarzeń: terminowość, czas dostawy według strefy i główne przyczyny niepowodzeń. Ułatwiaj eksport raportów i porównania tydzień do tygodnia.
Wskazówka projektowa: zdefiniuj spójne słownictwo statusów i system kolorów w każdym ekranie — to skraca czas szkolenia i zmniejsza kosztowne nieporozumienia.
Zbuduj mapy, geokodowanie i planowanie tras
Mapy to miejsce, gdzie twoja aplikacja przekształca „listę przystanków” w coś, na czym dyspozytorzy i kierowcy mogą działać. Celem nie jest efektowna kartografia, lecz mniej złych zakrętów, czytelniejsze ETA i szybsze decyzje.
Wybierz podstawowe elementy mapy
Większość aplikacji logistycznych potrzebuje tych funkcji mapowych:
- Geokodowanie: zamiana adresów na współrzędne do routingu i pinezek na mapie.
- Macierz odległości: czas i dystans podróży między wieloma przystankami (krytyczne dla planowania i ETA).
- Rysowanie trasy: wyświetlanie wybranej ścieżki i kolejności przystanków.
- ETA: przewidywane czasy przyjazdu dla każdego przystanku i całej trasy.
Zdecyduj wcześniej, czy polegasz na jednym dostawcy (prościej), czy zrobisz warstwę abstrakcji nad dostawcami (więcej pracy teraz, elastyczność później).
Nie ignoruj jakości adresów
Błędne adresy to główna przyczyna nieudanych dostaw. Zbuduj zabezpieczenia:
- Walidacja i sugestie podczas wpisywania (autocomplete, standaryzacja)
- Wskaźniki pewności (np. dopasowanie do poziomu ulicy vs. poziomu miasta)
- Ręczne umieszczanie pinezki na mapie, gdy adres jest niekompletny
Przechowuj oryginalny tekst adresu i rozwiązaną pozycję osobno, by móc audytować i naprawiać powtarzające się problemy.
Planowanie tras: ręcznie vs. prosta optymalizacja
Zacznij od ręcznego porządkowania (drag-and-drop) oraz praktycznych narzędzi: „grupuj pobliskie przystanki”, „przenieś nieudane dostawy na koniec”, albo „priorytetyzuj pilne przystanki”. Następnie dodaj podstawowe reguły optymalizacji (następny najbliższy, minimalizuj czas jazdy, unikaj zawracania) w miarę poznawania zachowań dyspozytorów.
Wspieraj ograniczenia rzeczywistego świata
Nawet MVP planowania tras powinno uwzględniać ograniczenia typu:
- Okna czasowe (godziny otwarcia klienta, umówione wizyty)
- Pojemność (rozmiar pojazdu, liczba paczek)
- Drogi ograniczone (ograniczenia dla ciężarówek, unikanie opłat drogowych)
- Wiele baz/depot (operacje hub-and-spoke)
Jeśli dokumentujesz te ograniczenia w UI, dyspozytorzy zaufają planowi i będą wiedzieć, kiedy go nadpisać.
Wdrożenie śledzenia lokalizacji kierowcy w czasie rzeczywistym
Ship a Dispatcher Dashboard Fast
Generate a React dashboard with a Go and PostgreSQL backend in minutes, then iterate fast.
Śledzenie na żywo jest użyteczne tylko jeśli jest niezawodne, zrozumiałe i szanuje baterię. Zanim zaczniesz programować, ustal, co dla was oznacza „w czasie rzeczywistym”: czy dyspozytorzy potrzebują ruchu co sekundę, czy wystarczy co 30–60 sekund, by odpowiadać na pytania klientów i reagować na opóźnienia?
Wybierz częstotliwość aktualizacji (i chroń baterię)
Wyższa częstotliwość daje płynniejszy ruch na panelu, ale szybciej rozładowuje baterię i zużywa dane.
Praktyczny start:
- Podczas aktywnej dostawy: co 10–30 sekund (lub co 50–100 metrów)
- Między przystankami / bezczynność: co 60–180 sekund
- Aplikacja w tle: rzadsze aktualizacje, chyba że jest to pilne
Możesz też wywoływać aktualizacje przy znaczących zdarzeniach (przyjazd na przystanek, opuszczenie przystanku) zamiast stałych pingów.
Aktualizacje na żywo vs. okresyczne odświeżanie
Dla widoku dyspozytora masz dwa popularne wzorce:
- Aktualizacje na żywo (WebSockets): pozycje pojawiają się natychmiast, dobre dla intensywnego panelu dyspozytora.
- Okresyczne odświeżanie (polling): przeglądarka odświeża pozycje co X sekund, prostsze do zbudowania i często wystarczające.
Wiele zespołów zaczyna od pollingu i dodaje WebSockets, gdy rośnie wolumen dyspozycji.
Przechowuj historię lokalizacji (nie tylko ostatnią kropkę)
Nie zapisuj tylko najnowszego współrzędnego. Zapisuj punkty śledzenia (timestamp + lat/long + opcjonalnie prędkość/accuracy), żeby móc:
- Pokazać breadcrumb trail dla okna dostawy
- Zbadać spory („Gdzie był kierowca o 15:12?”)
- Wyświetlić wyraźną ostatnią znaną lokalizację kiedy kierowca jest offline
Obsługuj tryb offline łagodnie
Sieci mobilne zawodzą. Aplikacja kierowcy powinna kolejkować zdarzenia lokalizacji lokalnie gdy sygnał zniknie i synchronizować automatycznie po powrocie. Na panelu pokaż status „Last update: 7 min ago” zamiast udawać, że kropka jest aktualna.
Dobrze wdrożone śledzenie GPS buduje zaufanie: dyspozytor widzi, co się dzieje, a kierowcy nie są karceni za brak niezawodnego połączenia.
Dodaj powiadomienia, obsługę wyjątków i potwierdzenia doręczenia
Powiadomienia i obsługa wyjątków przekształcają podstawową aplikację w niezawodne narzędzie śledzenia. Pomagają zespołowi działać wcześnie i zmniejszają liczbę telefonów od klientów.
Powiadomienia, które pomagają (a nie spamują)
Zacznij od niewielkiego zestawu zdarzeń ważnych dla operacji i klientów: dispatched, arriving soon, delivered i failed delivery. Pozwól użytkownikom wybrać kanał — push, SMS lub e-mail — i kto co otrzymuje (tylko dyspozytor, tylko klient, albo oboje).
Praktyczna zasada: wysyłaj wiadomości widoczne dla klienta tylko gdy coś się zmienia, a wiadomości operacyjne niech będą bardziej szczegółowe (powód przystanku, próby kontaktu, notatki).
Alerty wyjątków i sygnały „ryzyka opóźnienia”
Wyjątki powinny być wyzwalane przez jasne warunki, nie intuicję. Typowe w ostatniej mili:
- Late risk: ETA oddala się od obiecanego okna czasowego
- Missed time window: dostawa nie została ukończona w umówionym terminie
- Kierowca zatrzymał się za długo: lokalizacja niezmieniona ponad próg (np. 15–30 min) poza znanymi przystankami
Gdy wyjątek wystąpi, pokaż sugerowany następny krok w panelu dyspozytora: „zadzwoń do odbiorcy”, „reasignuj” lub „oznacz jako opóźnione”. To utrzymuje decyzje spójne.
Potwierdzenie doręczenia (POD), któremu można ufać
POD powinno być łatwe dla kierowców i możliwe do weryfikacji przy sporach. Typowe opcje:
- Podpis (palcem/rysikiem) z imieniem odbiorcy
- Zdjęcie (paczka przy drzwiach / w miejscu odbioru)
- Skan kodu kreskowego/QR do potwierdzenia właściwej paczki
- Stempel czasowy + współrzędne GPS zapisywane automatycznie
Przechowuj POD jako część rekordu dostawy i udostępniaj do pobrania dla obsługi klienta.
Szablony, ciche godziny i konfiguracja
Różni klienci chcą innego brzmienia komunikatów. Dodaj szablony wiadomości i ustawienia per-klient (okna czasowe, reguły eskalacji i ciche godziny). Dzięki temu aplikacja jest elastyczna bez konieczności zmian w kodzie w miarę wzrostu wolumenu dostaw.
Zarządzanie kontami, rolami i uprawnieniami
Keep Full Code Ownership
Export the source code when you are ready to move to a traditional engineering pipeline.
Dostęp i kontrola ról łatwo przeoczyć, aż do pierwszego sporu, pierwszego nowego depotu lub pytania typu „Kto zmienił tę dostawę?”. Jasny model uprawnień zapobiega przypadkowym edycjom, chroni dane i przyspiesza pracę zespołu.
Podstawy uwierzytelniania (i co dodać później)
Zacznij od prostego flow e-mail/hasło, ale przygotuj je produkcyjnie:
- Weryfikacja e-mail przy nowych użytkownikach
- Reset hasła z krótkim terminem ważności (np. 15–60 minut)
- Opcjonalne 2FA dla administratorów i dyspozytorów
Jeśli klienci używają dostawców tożsamości (Google Workspace, Microsoft Entra ID/AD), zaplanuj SSO jako ścieżkę rozwoju. Nawet jeśli nie zbudujesz tego w MVP, projektuj rekordy użytkowników tak, żeby później można było powiązać je z tożsamością SSO bez duplikatów.
Role: mało, ale sensownie
Unikaj tworzenia dziesiątek mikrowuprawnień na start. Zdefiniuj kilka ról odpowiadających rzeczywistym zadaniom, a potem dopracuj je na podstawie feedbacku.
Typowe role:
- Dispatcher: tworzenie/edycja zadań, przypisywanie kierowców, dostosowywanie ETA
- Driver: przegląd przypisanych przystanków, aktualizacja statusów, capture POD
- Operations manager: dostęp do pulpitów i eksportów
- Admin: zarządzanie użytkownikami, depotami, integracjami, ustawieniami bezpieczeństwa
Następnie ustal, kto może wykonywać wrażliwe akcje:
- Edycja lub anulowanie zadań po statusie „En route”
- Podgląd pól cenowych/kosztów i marż
- Eksport danych (CSV/PDF) i dostęp do historycznych raportów
Wielooddziałowość (depoty/zespoły)
Jeśli masz więcej niż jeden depot, warto wcześnie wprowadzić separację podobną do tenancy:
- Użytkownicy należą do oddziału/depot (albo wielu)
- Dostawy i kierowcy są przypisane do oddziału
- Dostęp między oddziałami przyznawany jest tylko menedżerom/regionalnym adminom
To pomaga utrzymać fokus zespołów i zmniejsza przypadkowe zmiany w pracy innego depot.
Audytowalność: niezmienny dziennik zdarzeń
Dla sporów, chargebacków i pytań „dlaczego to zostało przekierowane?” zbuduj append-only event log dla kluczowych akcji:
- Zmiany statusów (kto, kiedy, gdzie)
- Reasignacje kierowców
- Edycje adresów i okien czasowych
- Przesłania POD i przechwytywanie podpisów
Uczyń wpisy audytowe niezmiennymi i możliwymi do wyszukania po ID dostawy i użytkowniku. Przydatne jest też pokazanie przyjaznej dla człowieka osi aktywności na ekranie szczegółów dostawy.
Zaplanuj integracje i API
Integracje zmieniają narzędzie śledzące w codzienne centrum operacyjne. Zanim napiszesz kod, spisz systemy, z których już korzystasz i zdecyduj, który jest źródłem prawdy dla zamówień, danych klientów i bilingów.
Połącz systemy, których już używasz
Większość zespołów logistycznych korzysta z kilku platform: OMS, WMS, TMS, CRM i systemów księgowych. Zdecyduj, jakie dane pobierasz (zamówienia, adresy, okna czasowe, liczbę przedmiotów) i jakie dane wysyłasz z powrotem (statusy, POD, wyjątki, opłaty).
Prosta zasada: unikaj ręcznego przepisywania. Jeśli dispatcher tworzy zadania w OMS, nie zmuszaj go do ponownego wprowadzania w twojej aplikacji.
Projektuj API zgodne z realnymi przepływami
Trzymaj API wokół obiektów, które rozumie zespół:
- Jobs/Deliveries: create, assign, update status, attach POD
- Drivers/Vehicles: availability, assignments, device identifiers
- Tracking events: pings, stop arrivals, exceptions, timestamps
REST sprawdza się w większości przypadków, a webhooki obsłużą aktualizacje w czasie rzeczywistym do zewnętrznych systemów. Wymagaj idempotencji dla aktualizacji statusów, by ponowne próby nie dublowały zdarzeń.
Zaplanuj import/eksport i synchronizacje
Nawet z API operacje będą prosiły o CSV:
- Masowy import dostaw na dzień
- Eksport linków POD i stempeli czasowych dla obsługi klienta
Dodaj zaplanowane synchronizacje (co godzinę/noc), oraz przejrzyste raporty błędów: co nie przeszło, dlaczego i jak to naprawić.
Nie zapomnij o integracji urządzeń
Jeśli workflow używa skanerów kodów kreskowych lub drukarek etykiet, zdefiniuj, jak będą działać z twoją aplikacją (skan potwierdza przystanek, skan weryfikuje paczkę, druk w depo). Zacznij od małej listy wspieranych urządzeń, udokumentuj je i rozszerzaj po pilotażu.
Bezpieczeństwo, prywatność i retencja danych
Śledzenie dostaw i kierowców to często wrażliwe dane: adresy klientów, telefony, podpisy i lokalizacja w czasie rzeczywistym. Kilka decyzji z góry może uchronić przed kosztownymi incydentami.
Chroń dane w każdym miejscu
Przynajmniej szyfruj ruch w tranzycie przez HTTPS/TLS. Dla danych w spoczynku włącz szyfrowanie tam, gdzie oferuje je provider (bazy danych, storage obiektowy, backupy). Przechowuj klucze API i tokeny w managerze sekretów — nie w kodzie ani arkuszach współdzielonych.
Prywatność lokalizacji zgodna z potrzebą
GPS jest potężny, ale nie musi być dokładniejszy niż potrzeba. Wiele zespołów wymaga:
- przybliżonej pozycji kierowcy dla dyspozycji (np. „w tej strefie”)
- precyzyjnej lokalizacji tylko dla aktywnych przystanków lub wyjątków
Zdefiniuj okresy retencji. Na przykład: trzymaj szczegółowe pings przez 7–30 dni, potem downsampleuj (punkty godzinowe/dzienne) do raportowania.
Zabezpieczenia operacyjne: limity, logi i odzyskiwanie
Dodaj rate limiting do logowania, śledzenia i publicznych linków POD, by zmniejszyć nadużycia. Centralizuj logi (zdarzenia aplikacji, akcje adminów, żądania API), żeby szybko odpowiedzieć na pytanie "kto to zmienił?".
Zaplanuj też backup i restore od pierwszego dnia: codzienne backupy, przetestowane kroki przywracania i checklistę incydentu do użycia pod presją.
Podstawy zgodności i jasne polityki
Zbieraj tylko to, co potrzebujesz i dokumentuj dlaczego. Zapewnij zgodę i informacje dla kierowców odnośnie śledzenia oraz procedury dotyczące żądań dostępu lub usunięcia danych. Krótka, zrozumiała polityka — wewnętrzna i udostępniona klientom — wyrównuje oczekiwania.
Testy, pilotaż i wdrożenie przez zespół
Go Live Under Your Brand
Use custom domains when you are ready to share your tracking app with customers.
Aplikacja do śledzenia udaje się lub nie w realnym życiu: błędne adresy, spóźnienia kierowców, słaby zasięg i dyspozytorzy pod presją. Plan testów, ostrożny pilotaż i praktyczne szkolenie zamieniają "działające oprogramowanie" w "oprogramowanie, którego ludzie naprawdę używają".
Testuj scenariusze łamiące dostawy
Wyjdź poza scenariusze idealne i odtwórz codzienny chaos:
- Edge case tras: wiele przystanków o tej samej nazwie ulicy, osiedla zamknięte, drogi z ograniczeniami, podwójne miejsca dostaw i błędy typu „dostawa przed odbiorem”.
- Złe adresy: brak kodu pocztowego, błędne miasto, adres tylko dla mieszkania, pinezka daleko od wejścia.
- Offline: kierowca oznacza przystanek jako wykonany bez sygnału, potem synchronizacja — upewnij się, że nie powstają duplikaty.
- Okna czasowe: przyjazdy za wcześnie, za późno i nakładające się okna — upewnij się, że dyspozytor widzi konflikty jasno.
Testuj zarówno web (dyspozytor), jak i mobile (kierowca), plus scenariusze wyjątków: failed delivery, return-to-depot, klient nieobecny.
Sprawdzenia wydajności przed skalowaniem
Śledzenie i mapy mogą być wolne zanim padną. Testuj:
- Renderowanie mapy z wieloma przystankami i trasami na ekranie
- Duże listy zadań (np. setki lub tysiące dostaw)
- Godziny szczytu śledzenia gdy wielu kierowców jednocześnie wysyła aktualizacje
Mierz czasy ładowania i responsywność, a potem ustal cele wydajności do monitorowania.
Pilotaż z kryteriami sukcesu
Zacznij od jednego depo/regionu, nie całej firmy. Zdefiniuj z góry kryteria sukcesu (np. % dostaw z POD, mniej telefonów "gdzie jest mój kierowca?", poprawa terminowości). Zbieraj feedback co tydzień, szybko poprawiaj błędy i rozszerzaj.
Szkolenie dopasowane do pracy
Stwórz krótki quick-start, dodaj podpowiedzi w aplikacji dla nowych użytkowników i ustal proces wsparcia: kogo kierowcy kontaktują na drodze i jak dyspozytor zgłasza błąd. Adopcja rośnie, gdy ludzie wiedzą dokładnie, co robić, gdy coś pójdzie nie tak.
Zakres MVP, stack technologiczny i planowanie kosztów
Jeśli budujesz aplikację logistyczną po raz pierwszy, najszybsza droga do wysłania produktu to zdefiniowanie wąskiego MVP, które udowodni wartość dla dyspozytora i kierowców, a potem dodawanie automatyzacji i analityki gdy workflow jest stabilny.
Zakres MVP: must-haves vs. nice-to-haves
Must-haves na pierwszy release zazwyczaj obejmują: panel dyspozytora do tworzenia dostaw i przypisywania kierowców, przyjazny widok mobilny dla kierowcy (lub prosta aplikacja) z listą przystanków, podstawowe aktualizacje statusów (Picked up, Arrived, Delivered) oraz widok mapy.
Nice-to-haves które często spowalniają early teams: zaawansowane reguły optymalizacji tras, planowanie multi-depot, zautomatyzowane ETA dla klientów, niestandardowe raporty i szerokie integracje. Trzymaj je poza MVP, chyba że już wiesz, że przynoszą przychód.
Typowe wybory technologiczne
Praktyczny stack do developmentu aplikacji logistycznej:
- Frontend web: React, Vue lub Angular dla panelu dyspozytora
- Backend API: Node.js/TypeScript, Python (Django/FastAPI) lub Java/.NET dla stabilnego CRUD i auth
- Baza danych: PostgreSQL dla głównych encji; Redis dla cache i sesji czasu rzeczywistego
- Realtime: WebSockets (albo managed pub/sub) dla aktualizacji śledzenia
- Mapy/geokodowanie: Google Maps, Mapbox lub HERE (koszty i zasięg się różnią)
Szybsza ścieżka do MVP (gdy ważna jest szybka weryfikacja)
Jeśli głównym wyzwaniem jest szybkość do pierwszej wersji, podejście vibe-coding może pomóc zweryfikować workflow przed dużym inwestowaniem w custom build. Z pomocą Koder.ai zespoły mogą opisać panel dyspozytora, flow kierowcy, statusy i model danych w czacie, a następnie wygenerować działającą aplikację webową (React) z backendem Go + PostgreSQL.
To bywa szczególnie przydatne do pilotażu:
- core CRUD dla deliveries/drivers/routes
- role-based access (dispatcher/driver/manager)
- fundament osi aktywności / audit log
- snapshoty i rollback podczas szybkiej iteracji
Gdy MVP udowodni wartość, możesz wyeksportować kod źródłowy i kontynuować w tradycyjnym pipeline'ie inżynieryjnym albo dalej wdrażać przez platformę.
Co napędza koszty (i zaskakuje budżety)
Największe koszty w software do śledzenia dostaw są często zależne od użycia:
- Tile map, geokodowanie i routing (liczba zapytań)
- SMS/WhatsApp powiadomienia (koszt za wiadomość)
- Przechowywanie zdjęć dla POD (plus transfer danych)
- Infrastruktura śledzenia GPS na żywo (częstotliwość aktualizacji + współbieżność)
Jeśli potrzebujesz pomocy w estymacji tych pozycji, warto poprosić o szybką wycenę na /pricing lub omówić workflow na /contact.
Kolejne funkcje do planowania (ale nie na start)
Gdy MVP jest stabilne, typowe ulepszenia to: linki śledzenia dla klientów, mocniejsza optymalizacja tras, analityka dostaw (on-time %, dwell time) oraz raporty SLA dla kluczowych klientów.