Co powinna rozwiązać ta aplikacja webowa
Większość zespołów nie zawodzą z braku pomysłów na eksperymenty — zawodzą, bo wyniki są rozproszone. Jeden produkt ma wykresy w narzędziu analitycznym, inny ma arkusz, trzeci ma slajd z zrzutami ekranu. Kilka miesięcy później nikt nie potrafi odpowiedzieć na proste pytania typu „Czy już to testowaliśmy?” albo „Która wersja wygrała, według jakiej definicji metryki?”
Główny problem: rozproszone wyniki i niejednolita prawda
Aplikacja do śledzenia eksperymentów powinna scentralizować co testowano, dlaczego, jak to mierzono i co się stało — w wielu produktach i zespołach. Bez tego zespoły tracą czas na odtwarzanie raportów, kłócą się o liczby i ponownie uruchamiają stare testy, bo wnioski nie są przeszukiwalne.
Dla kogo to jest (i czego każda grupa potrzebuje)
To nie jest tylko narzędzie dla analityków.
- Product managerowie potrzebują szybkiego wglądu w wyniki, pewność i status decyzji.
- Analitycy potrzebują wiarygodnego miejsca do dokumentowania założeń, definicji metryk i zastrzeżeń.
- Inżynierowie potrzebują jasności, które feature flagi, warianty i warunki rolloutu były w zakresie.
- Kadra kierownicza potrzebuje spójnego widoku wpływu między produktami, bez przygotowywania dedykowanych decków.
Wyniki, które warto optymalizować
Dobry tracker tworzy wartość biznesową przez umożliwienie:
- Szybszych decyzji (mniej czasu na szukanie linków i zgody)
- Mniej błędów w raportowaniu (jedno źródło prawdy dla „ostatecznych liczb”)
- Dzielenia się wnioskami (przeszukiwalna historia wygranych, przegranych i neutralnych testów)
Jasne granice zakresu
Bądź eksplicytny: ta aplikacja służy głównie do śledzenia i raportowania wyników eksperymentów — nie do uruchamiania eksperymentów end‑to‑end. Może linkować do istniejących narzędzi (feature flagi, analityka, magazyn danych), jednocześnie będąc właścicielem ustrukturyzowanego zapisu eksperymentu i jego ostatecznej, uzgodnionej interpretacji.
Wymagania: minimalny wykonalny tracker eksperymentów
Minimalny tracker powinien odpowiadać na dwa pytania bez grzebania w dokumentach czy arkuszach: co testujemy i czego się nauczyliśmy. Zacznij od małego zestawu encji i pól, które działają we wszystkich produktach, a rozwijaj dopiero, gdy zespoły odczują realny ból.
Podstawowe encje do obsługi
Utrzymaj model danych prosty, tak aby każdy zespół używał go w ten sam sposób:
- Product: obszar, w którym zmiana jest wdrażana (aplikacja/strona/API).
- Experiment: jedna hipoteza i jedna decyzja.
- Variant: kontrola i jeden lub więcej wariantów.
- Metric: nazwana miara z właścicielem i definicją.
- Segment: opcjonalne wycinki odbiorców (nowi użytkownicy, płacący, region) używane w raportach.
Typy eksperymentów (zacznij od małego, zostań elastyczny)
Obsługuj najczęstsze wzorce od pierwszego dnia:
- A/B tests (control vs treatment)
- Multivariate tests (wiele wariantów)
- Feature flag rollouts (ekspozycja procentowa)
Nawet jeśli rollouty na początku nie używają formalnej statystyki, śledzenie ich obok testów pomaga uniknąć powtarzania „testów” bez zapisu.
Minimalne pola, których każdy eksperyment potrzebuje
Przy tworzeniu wymagaj tylko tego, co potrzebne do późniejszego uruchomienia i interpretacji testu:
- Hipoteza (jaka zmiana, dla kogo i dlaczego)
- Właściciel (jedna osoba odpowiedzialna)
- Daty start/koniec (planowane i rzeczywiste)
- Targetowanie (reguły kwalifikacji) i alokacja (podział ruchu)
- Linki do rolloutu/flagi, ticketa lub specyfikacji (adresy względne jak /projects/123)
Kryteria sukcesu i status decyzji
Ułatw porównywanie wyników przez wymuszenie struktury:
- Metryka podstawowa (główna miara sukcesu)
- Guardrails (metryki, które nie mogą się pogorszyć)
- Status decyzji: proposed → running → analyzed → shipped/rolled back → archived
Jeśli zbudujesz tylko to, zespoły będą mogły znaleźć eksperymenty, zrozumieć konfigurację i zapisać wyniki — nawet zanim dodasz zaawansowaną analitykę czy automatyzację.
Model danych działający między produktami
Tracker eksperymentów obejmujący wiele produktów wygrywa lub przegrywa na poziomie modelu danych. Jeśli ID się pokrywają, metryki dryfują, a segmenty są niespójne, pulpit może wyglądać „poprawnie”, a opowiadać złą historię.
Wybierz stabilne identyfikatory (i trzymaj się ich)
Zacznij od jasnej strategii identyfikatorów:
- product_id: stabilne przy zmianie nazwy (nie używaj nazw wyświetlanych jako kluczy)
- experiment_key: czytelny slug (np.
checkout_free_shipping_banner) plus niemodyfikowalny experiment_id
- variant_key: stabilne etykiety jak
control, treatment_a
To pozwala porównywać wyniki między produktami bez zgadywania, czy „Web Checkout” i „Checkout Web” to to samo.
Główne kolekcje/tabele
Utrzymaj podstawowe encje małe i jawne:
- experiments: product_id, hypothesis, primary_metric_def_id, start/end, status
- variants: experiment_id, variant_key, traffic_split
- assignments: experiment_id, user_id (lub anonymous_id), variant_key, assigned_at
- metric_defs: nazwa metryki, logika numerator/denominator, jednostka (user/session/order), właściciel
- results: experiment_id, metric_def_id, time_window_id, segment_id, computed_at, effect, uncertainty
Nawet jeśli obliczenia zachodzą gdzie indziej, przechowywanie wyników umożliwia szybkie pulpity i wiarygodną historię.
Okna czasowe i wersjonowanie
Metryki i eksperymenty nie są statyczne. Modeluj:
- time windows (np. „pierwsze 7 dni po przypisaniu”, „tygodnie kalendarzowe”)
- wersjonowane definicje metryk: kiedy obliczenie metryki się zmienia, stwórz nową wersję zamiast edytować starą
To zapobiega zmianie wyników z poprzedniego miesiąca, gdy ktoś zaktualizuje logikę KPI.
Segmenty i ślad audytu
Zapewnij spójne segmenty między produktami: kraj, urządzenie, plan, nowy vs powracający.
Na koniec dodaj audit trail rejestrujący kto co i kiedy zmienił (zmiany statusu, podziały ruchu, aktualizacje definicji metryk). To klucz do zaufania, przeglądów i governance.
Definicje metryk i spójne obliczenia
Jeśli tracker źle liczy metryki (albo niespójnie między produktami), to „wynik” jest jedynie opinią z wykresem. Najszybszy sposób, by tego uniknąć, to traktować metryki jako wspólne zasoby produktu — nie ad‑hocowe fragmenty zapytań.
Zbuduj kanoniczny katalog metryk
Stwórz katalog metryk jako jedno źródło prawdy dla definicji, logiki obliczeń i właściciela. Każdy wpis metryki powinien zawierać:
- prostą definicję (co wspiera decyzję)
- właściciela (osoba/zespół odpowiedzialny za zmiany)
- dokładną formułę i wymagane eventy/pola
- reguły inkluzji/wykluczenia (np. użytkownicy wewnętrzni, boty, zwrócone zamówienia)
- dopuszczalne poziomy agregacji i obsługiwane produkty
Trzymaj katalog blisko miejsca pracy (np. link z flow tworzenia eksperymentu) i wersjonuj go, by wyjaśnić historyczne wyniki.
Ustandaryzuj poziomy agregacji
Zdecyduj wcześniej, jaka jest „jednostka analizy” dla każdej metryki: na użytkownika, na sesję, na konto lub na zamówienie. Współczynnik konwersji „na użytkownika” może różnić się od „na sesję” nawet gdy obie są poprawne.
Aby zmniejszyć zamieszanie, przechowuj wybór agregacji z definicją metryki i wymagaj jego określenia przy konfiguracji eksperymentu. Nie pozwól, by każdy zespół wybierał jednostkę ad hoc.
Obsługa opóźnionych konwersji i atrybucji
Wiele produktów ma okna konwersji (np. rejestracja dziś, zakup w ciągu 14 dni). Zdefiniuj reguły atrybucji spójnie:
- Kiedy zaczyna się zegar (czas ekspozycji, pierwsza wizyta, czas przypisania)?
- Co liczy się jako konwersja, jeśli użytkownik był eksponowany wielokrotnie?
- Jak obsługujesz podróże cross‑device lub cross‑product?
Uczyń te reguły widocznymi w pulpicie, żeby czytelnik wiedział, co ogląda.
Przechowuj surowe liczniki i obliczone statystyki
Dla szybkich pulpitów i audytowalności przechowuj oba typy danych:
- surowe wartości (eksponowania, konwerterzy, sumy przychodów, składniki wariancji)
- obliczone statystyki (lift, przedziały ufności, p‑value)
To pozwala na szybkie renderowanie i jednocześnie umożliwia ponowne przeliczenie po zmianie definicji.
Konwencje nazewnictwa zapobiegają rozrostowi metryk
Przyjmij standard nazewnictwa, który koduje znaczenie (np. activation_rate_user_7d, revenue_per_account_30d). Wymagaj unikalnych ID, egzekwuj aliasy i oznaczaj bliskie duplikaty przy tworzeniu metryki, żeby katalog pozostał czysty.
Zbieranie danych: eventy, pipeline’y i kontrole jakości
Tracker eksperymentów jest tyle wiarygodny, ile dane, które go zasilają. Celem jest niezawodne odpowiedzenie na dwa pytania dla każdego produktu: kto był eksponowany na który wariant i co potem zrobił? Wszystko inne — metryki, statystyka, pulpity — opiera się na tym fundamencie.
Wybierz podejście do ingestii
Większość zespołów wybiera jeden z tych wzorców:
- Strumień eventów (near real‑time): świetny do szybkich odczytów i debugowania. Wymaga większej dojrzałości inżynieryjnej.
- Codzienny batch: prostszy i tańszy w utrzymaniu. Najlepszy, gdy decyzje nie muszą zapadać co godzinę.
- Hybryda: strumień dla ekspozycji i krytycznych eventów (walidacja przypisań), batch dla reszty dla kompletności i kontroli kosztów.
Cokolwiek wybierzesz, ustandaryzuj minimalny zestaw eventów między produktami: exposure/assignment, kluczowe eventy konwersji oraz wystarczający kontekst do łączenia (user ID/device ID, timestamp, experiment ID, variant).
Mapuj eventy produktu na metryki (i waliduj kompletność)
Zdefiniuj jasne mapowanie surowych eventów na metryki, które tracker raportuje (np. purchase_completed → Revenue, signup_completed → Activation). Utrzymuj to mapowanie per produkt, ale trzymaj nazwy spójne między produktami, by dashboard wyników A/B porównywał podobne rzeczy.
Weryfikuj kompletność wcześnie:
- potwierdź, że każda ekspozycja ma experiment ID i wariant
- upewnij się, że eventy konwersji zawierają te same pola identyfikacyjne używane do łączeń ekspozycji
- obserwuj dropy eventów między klientem, serwerem i magazynem danych (SDK mobilne to częsty winowajca)
Kontrole jakości danych, które należy zautomatyzować
Zbuduj kontrole uruchamiane przy każdym załadowaniu i alarmujące głośno:
- Brakujące eventy ekspozycji: konwersje bez wcześniejszej ekspozycji (często luki w instrumentacji lub mismatch identyfikatorów)
- Zniekształcony podział: warianty z 70/30 zamiast oczekiwanych 50/50 (może wskazywać bug targetowania)
- Sanity check timestampów: ekspozycje po konwersjach lub duże opóźnienia sugerujące problem z zegarem
Wyświetlaj to w aplikacji jako ostrzeżenia przypisane do eksperymentu, nie ukryte w logach.
Backfille i ponowne przetwarzanie
Pipeline’y się zmieniają. Gdy naprawisz błąd instrumentacji albo logikę deduplikacji, będziesz musiał ponownie przetworzyć dane historyczne, aby metryki i KPI były zgodne.
Planuj:
- wersjonowane transformacje (żeby wiedzieć, która logika wygenerowała wynik)
- bezpieczne backfille (ograniczone po dacie/produkcie/eksperymencie)
- ślad audytu recomputation
Dokumentuj integracje
Traktuj integracje jak cechy produktu: dokumentuj wspierane SDK, schematy eventów i kroki rozwiązywania problemów. Jeśli macie obszar dokumentacji, odwołuj się do niego jako do względnej ścieżki, np. /docs/integrations.
Statystyka i obliczenia wyników, którym można ufać
Dodaj widok mobilny
Stwórz towarzyszącą aplikację Flutter do szybkich podglądów i sprawdzania statusu.
Jeśli ludzie nie ufają liczbom, nie będą korzystać z trackera. Celem nie jest imponowanie matematyką — chodzi o to, by decyzje były powtarzalne i obronne między produktami.
Wybierz jedną statystyczną „dialektę” i trzymaj się jej
Zdecyduj z wyprzedzeniem, czy aplikacja będzie raportować wyniki frequentistyczne (p‑value, przedziały ufności) czy bayesowskie (prawdopodobieństwo poprawy, przedziały wiarygodne). Oba podejścia działają, ale mieszanie ich między produktami powoduje dezorientację.
Praktyczna zasada: wybierz podejście, które organizacja już rozumie, a potem ustandaryzuj terminologię, domyślne ustawienia i progi.
Dokładnie określ, co UI pokazuje
Widok wyników powinien jednoznacznie przedstawiać przynajmniej:
- Lift (absolutny i/lub względny) wobec kontroli
- Przedział (confidence interval lub credible interval) pokazany jako zakres, nie tylko estymata punktowa
- Siła dowodu (p‑value dla frequentist, albo prawdopodobieństwo pokonania kontroli dla bayesowskiego podejścia)
Pokaż też okno analizy, jednostki liczone (użytkownicy, sesje, zamówienia) oraz wersję definicji metryki użytej. Te „detale” to różnica między spójnym raportowaniem a debatą.
Wielokrotne porównania i polityka „peeking”
Jeśli zespoły testują wiele wariantów, wiele metryk lub sprawdzają wyniki codziennie, rośnie prawdopodobieństwo fałszywych pozytywów. Aplikacja powinna zakodować politykę zamiast pozostawiać to każdemu zespołowi:
- Wielokrotne porównania: zdecyduj, czy dopasowujesz (np. kontrola FDR), czy wyraźnie oznaczasz wyniki jako „niezadjustowane eksploracyjne”
- Ciągłe sprawdzanie: albo (1) zniechęcaj do tego przez ustalony termin końcowy i status „finalized”, albo (2) wspieraj metody sekwencyjne i pokaż wskazówki „bezpieczne do zatrzymania”
Guardrails łapiące typowe tryby porażek
Dodaj automatyczne flagi widoczne obok wyników, nie ukryte w logach:
- Sample Ratio Mismatch (SRM): ostrzeżenie, gdy podział ruchu odbiega od oczekiwanego
- Wykrywanie anomalii: flagowanie nagłych spadków/wzrostów w ruchu, konwersjach czy przychodach, które mogą wskazywać przerwy w śledzeniu, awarie lub ruch botski
Wyjaśnienia w języku prostym
Obok liczb dodaj krótkie wyjaśnienie zrozumiałe dla nietechnicznego czytelnika, np.: „Najlepsza estymata to +2.1% lift, ale prawdziwy efekt może mieścić się między -0.4% a +4.6%. Nie mamy wystarczających dowodów, by wybrać zwycięzcę.”
UX i pulpity do szybkiego podejmowania decyzji
Dobre narzędzia eksperymentacyjne pomagają odpowiedzieć na dwa pytania szybko: Na co mam spojrzeć dalej? i Co powinniśmy z tym zrobić? UI powinno minimalizować szukanie kontekstu i uczynić „stan decyzji” oczywistym.
Kluczowe strony kotwiczące workflow
Zacznij od trzech stron, które obejmują większość użycia:
- Lista eksperymentów: sortowalna kolejka dla całej organizacji (lub per produkt).
- Szczegóły eksperymentu: pojedyncze źródło prawdy dla konfiguracji, wyników i decyzji.
- Przegląd produktu: agregat aktywnych testów, ostatnich decyzji i zdrowia metryk dla konkretnego produktu.
Na liście i stronach produktu filtry powinny być szybkie i zapamiętywane: product, owner, zakres dat, status, metryka główna i segment. Użytkownik powinien móc zawęzić widok do „Eksperymenty Checkout, właściciel Maya, uruchomione w tym miesiącu, metryka główna = konwersja, segment = new users” w kilka sekund.
Statusy decyzji, którym można zaufać
Traktuj status jako kontrolowany słownik, nie wolny tekst:
Draft → Running → Stopped → Shipped / Rolled back
Pokaż status wszędzie (wiersze listy, nagłówek szczegółów i linki do udostępniania) i zapisuj, kto go zmienił i dlaczego. To zapobiega „cichym wprowadzeniom” i niejasnym wynikom.
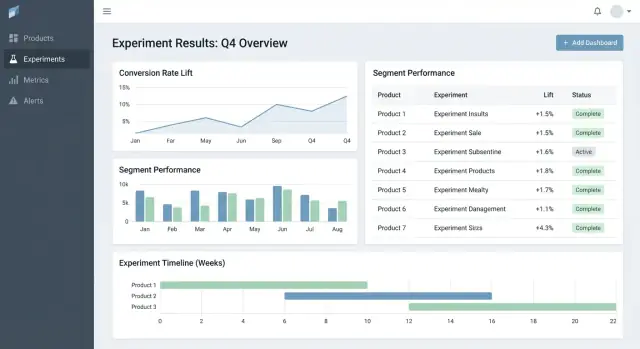
Tabela wyników, która ułatwia decyzję
W widoku szczegółów eksperymentu prowadź od zwartej tabeli wyników na metrykę:
- Baseline
- Variant
- Lift
- Niepewność (przedział ufności lub przedział wiarygodny)
- Notatki (np. zastrzeżenia instrumentacyjne, niuanse segmentu)
Ukryj zaawansowane wykresy w sekcji „Więcej szczegółów”, aby decydenci nie byli przytłoczeni.
Udostępnianie i eksport bez utraty kontroli
Dodaj eksport CSV dla analityków i linki do udostępniania dla interesariuszy, ale egzekwuj dostęp: linki powinny respektować role i uprawnienia produktowe. Prosty przycisk „Kopiuj link” plus „Eksportuj CSV” zaspokajają większość potrzeb współpracy.
Uprawnienia, prywatność i governance
Opublikuj na własnej domenie
Użyj domeny niestandardowej, aby tracker wyglądał jak prawdziwy produkt wewnętrzny.
Jeśli tracker obejmuje wiele produktów, kontrola dostępu i audytowalność nie są opcjonalne. To one sprawiają, że narzędzie jest bezpieczne do adopcji w organizacji i wiarygodne podczas przeglądów.
Kontrola dostępu oparta na rolach (RBAC)
Zacznij od prostego zestawu ról i trzymaj je spójne w aplikacji:
- Viewer: dostęp tylko do odczytu do eksperymentów, wyników i pulpitów.
- Editor: tworzenie/edycja eksperymentów, dodawanie dokumentów, zmiana statusów.
- Admin: zarządzanie użytkownikami, uprawnieniami, definicjami metryk, regułami retencji i integracjami.
Centralizuj decyzje RBAC (jedna warstwa polityk), aby UI i API egzekwowały te same zasady.
Uprawnienia na poziomie produktu i wiersza
Wiele organizacji potrzebuje dostępu ograniczonego do produktu: Zespół A widzi eksperymenty Produktu A, ale nie Produktu B. Modeluj to jawnie (np. user ↔ product memberships) i filtruj każde zapytanie po produkcie.
Dla wrażliwych przypadków (partnerzy, regulowane segmenty) dodaj ograniczenia wierszowe. Praktyczne podejście to tagowanie eksperymentów (lub wycinków wyników) poziomem wrażliwości i wymaganie dodatkowego uprawnienia do ich przeglądu.
Ślad audytu: dostęp + historia zmian
Loguj osobno dwie rzeczy:
- Historia zmian: kto edytował eksperyment, definicję metryki lub decyzję — co się zmieniło i kiedy.
- Logi dostępu: kto przeglądał lub eksportował wyniki (szczególnie eksperymenty wrażliwe).
Udostępnij historię zmian w UI dla przejrzystości i trzymaj głębsze logi do dochodzeń.
Reguły retencji i usuwania
Zdefiniuj zasady retencji dla:
- Metadanych eksperymentu (hipoteza, właściciele, daty, notatki decyzyjne)
- Obliczonych wyników (efekty, przedziały, flagi istotności)
Uczyń retencję konfigurowalną per produkt i poziom wrażliwości. Gdy dane muszą zostać usunięte, zachowaj minimalny tombstone (ID, czas usunięcia, powód), by zachować integralność raportów bez trzymania wrażliwej treści.
Funkcje workflow: od pomysłu do biblioteki wniosków
Tracker staje się naprawdę przydatny, gdy obejmuje cały cykl życia eksperymentu, nie tylko wartość p. Funkcje workflow zamieniają rozsiane dokumenty, tickety i wykresy w powtarzalny proces, który poprawia jakość i ułatwia ponowne wykorzystanie wniosków.
Cykl życia: idea → review → run → post‑mortem
Modeluj eksperymenty jako serię stanów (Draft, In Review, Approved, Running, Ended, Readout Published, Archived). Każdy stan powinien mieć jasne „kryteria wyjścia”, aby eksperymenty nie trafiały na produkcję bez elementów niezbędnych, jak hipoteza, metryka podstawowa i guardrails.
Zatwierdzenia nie muszą być ciężkie. Prosty krok review (np. produkt + dane) plus ślad audytu kto co i kiedy zatwierdził, może zapobiec błędom. Po zakończeniu wymuś krótkie post‑mortem przed oznaczeniem eksperymentu jako „Published”, by zapewnić zapis wyników i kontekstu.
Szablony, które standaryzują myślenie
Dodaj szablony dla:
- briefu eksperymentu (cel, hipoteza, grupa docelowa, metryki sukcesu, guardrails, plan rolloutu)
- notatek analitycznych (źródła danych, wykluczenia, sanity checks, interpretacja, ryzyka)
Szablony zmniejszają opór przed rozpoczęciem i przyspieszają review, bo wszyscy wiedzą, gdzie czego szukać. Trzymaj je edytowalne per produkt, zachowując wspólne jądro.
Wnioski: linkuj wszystko, utrzymuj przeszukiwalność
Eksperymenty rzadko żyją same — użytkownicy potrzebują kontekstu. Pozwól na dołączanie linków do ticketów/specyfikacji i powiązanych writeupów (np. /blog/how-we-define-guardrails, /blog/experiment-analysis-checklist). Przechowuj ustrukturyzowane pola „Learning” takie jak:
- Co zmieniono (decyzja)
- Czego się nauczyliśmy (insight)
- Co robić dalej (kolejne kroki)
Alerty dla guardrails i zmiany wyników
Wspieraj powiadomienia, gdy guardrails się pogarszają (np. wskaźnik błędów, anulowania) lub gdy wyniki zmieniają się znacząco po późnych danych lub przeliczeniu metryk. Uczyń alerty wykonalnymi: pokaż metrykę, próg, ramy czasowe i właściciela do potwierdzenia albo eskalacji.
Widok biblioteki do ponownego wykorzystania pracy
Udostępnij bibliotekę z filtracją po produkcie, obszarze funkcjonalnym, odbiorcach, metryce, wyniku i tagach (np. „pricing”, „onboarding”, „mobile”). Dodaj sugestie „podobnych eksperymentów” na podstawie wspólnych tagów/metryk, by zespoły mogły uniknąć powtarzania testów i zamiast tego budować na wcześniejszych wnioskach.
Architektura i opcje stacku technologicznego
Nie potrzebujesz „idealnego” stacku, żeby zbudować tracker eksperymentów — potrzebujesz jasnych granic: gdzie żyją dane, gdzie odbywają się obliczenia i jak zespoły uzyskują dostęp do wyników.
Praktyczny bazowy stack
Dla wielu zespołów prosty i skalowalny zestaw to:
- Frontend: React (lub Vue) dla pulpitów i workflowów
- Backend API: Node.js/Express, Python/FastAPI lub Java/Spring — wybierz to, czym zespół potrafi utrzymać
- Baza danych: Postgres dla danych aplikacji (eksperymenty, definicje metryk, uprawnienia)
- Magazyn analityczny: BigQuery/Snowflake/Redshift dla danych eventów i ciężkich agregacji
To rozdzielenie utrzymuje szybkie workflowy transakcyjne, a magazyn radzi sobie z dużymi obliczeniami.
Jeśli chcesz szybko zrobić prototyp UI (lista eksperymentów → szczegóły → readout) zanim zaangażujesz pełny cykl inżynierski, platforma vibe‑codingowa taka jak Koder.ai może pomóc wygenerować działający fundament React + backend z opisu w czacie. Przydatne do uruchomienia encji, formularzy, szkieletu RBAC i audytowalnych operacji CRUD, a potem iteracji nad kontraktami danych z zespołem analitycznym.
Gdzie powinny być obliczenia metryk?
Masz zwykle trzy opcje:
- Warehouse‑first: modele SQL obliczają metryki i tabele wyników. Aplikacja głównie odczytuje.
- Backend jobs: worker wykonuje obliczenia cyklicznie lub przy zmianie eksperymentu.
- Hybryda: kanoniczne agregacje w magazynie, z backendowym post‑processingiem (formatowanie, guardrails, cache).
Warehouse‑first jest często najprostsze, jeśli zespół danych już posiada zaufane SQL. Backend‑heavy działa, gdy potrzebujesz niskich opóźnień lub niestandardowej logiki, ale zwiększa złożoność aplikacji.
Wydajność: cache i precompute
Pulpity eksperymentów często powtarzają te same zapytania. Planuj, by:
- Precompute’ować rollupy (dobowe agregaty metryk per experiment/variant/segment)
- Cache’ować drogie odczyty na warstwie API (np. Redis) z jasnymi regułami unieważniania
- używać materialized views lub tabel zaplanowanych w magazynie dla typowych pulpitów
Multi‑tenant vs single‑tenant
Jeśli wspierasz wiele produktów/jednostek biznesowych, zdecyduj wcześnie:
- Single‑tenant (wspólne schema): łatwiejsze w operacji, ale wymaga rygorystycznego filtrowania uprawnień
- Multi‑tenant: oddzielne schematy/projekty per produkt/zespół dla silniejszej izolacji, więcej narzutu operacyjnego
Częsty kompromis to wspólna infrastruktura z silnym modelem tenant_id i wymuszonym dostępem wierszowym.
Zdefiniuj podstawowe API
Utrzymaj powierzchnię API małą i jasną. Większość systemów potrzebuje endpointów dla experiments, metrics, results, segments i permissions (plus odczyty przyjazne audytowi). Ułatwia to dodawanie produktów bez przepisywania fundamentów.
Testowanie, monitoring i niezawodne operacje
Dostarcz środowisko produkcyjne
Wdróż i hostuj swój tracker, żeby zespoły mogły z niego korzystać podczas iteracji.
Tracker eksperymentów jest użyteczny tylko wtedy, gdy ludzie mu ufają. To zaufanie pochodzi ze zdyscyplinowanego testowania, jasnego monitoringu i przewidywalnych operacji — szczególnie, gdy wiele produktów i pipeline’ów zasila te same pulpity.
Observability zgodna z użyciem aplikacji
Zacznij od zorganizowanego logowania dla każdego krytycznego kroku: ingestia eventów, przypisania, rollupy metryk i obliczanie wyników. Dołącz identyfikatory jak product, experiment_id, metric_id i pipeline run_id, aby wsparcie mogło prześledzić pojedynczy wynik do jego danych wejściowych.
Dodaj metryki systemowe (opóźnienia API, czasy jobów, głębokość kolejek) i metryki dane (eventy przetworzone, % opóźnionych eventów, % odrzuconych przez walidację). Uzupełnij to śledzeniem (tracing) między usługami, żeby odpowiedzieć na pytanie: „Dlaczego temu eksperymentowi brakuje danych z wczoraj?”
Kontrole świeżości danych są najszybszym sposobem zapobiegania cichym awariom. Jeśli SLA to „codziennie do 9:00”, monitoruj świeżość per produkt i per źródło, i alarmuj, gdy:
- brakuje najnowszej partycji
- wolumen eventów znacznie odbiega od podstawy
- joby rollupowe kończą się, ale zwracają zero wierszy
Testy automatyczne: chroń dane i matematykę
Twórz testy na trzech poziomach:
- Schemat i constraints: wymagane pola, unikalność (np. jedno przypisanie na użytkownika na eksperyment), klucze obce, poprawne zakresy dat
- Uprawnienia: testy RBAC (viewer/editor/admin) i filtrowanie per produkt
- Matematyka wyników: testy jednostkowe dla liftu, przedziałów ufności, flag istotności i przypadków brzegowych (małe próbki, mianownik zero, wiele wariantów)
Trzymaj mały „golden dataset” ze znanymi wynikami, aby wychwycić regresje przed wydaniem.
Wdrożenia, migracje i bezpieczeństwo historyczne
Traktuj migracje jako część operacji: wersjonuj definicje metryk i logikę obliczeń, i unikaj przepisywania historycznych eksperymentów bez wyraźnego żądania. Gdy zmiany są konieczne, zapewnij kontrolowaną ścieżkę backfilla i udokumentuj, co się zmieniło w śladzie audytu.
Narzędzia administracyjne dla incydentów i reprocessingu
Daj adminom widok do ponownego uruchomienia pipeline’u dla konkretnego eksperymentu/zakresu dat, inspekcji błędów walidacji i oznaczania incydentów z aktualizacjami statusu. Linkuj notatki o incydentach bezpośrednio z dotkniętych eksperymentów, aby użytkownicy rozumieli opóźnienia i nie podejmowali decyzji na niekompletnych danych.
Plan wdrożenia i typowe pułapki do unikania
Wdrażanie trackera eksperymentów w wielu produktach to mniej „dzień premiery”, a bardziej stopniowe redukowanie niejednoznaczności: co jest śledzone, kto za to odpowiada i czy liczby zgadzają się z rzeczywistością.
Praktyczna sekwencja rolloutu
Zacznij od jednego produktu i małego, pewnego zestawu metryk (np. conversion, activation, revenue). Celem jest zweryfikowanie end‑to‑end workflow — tworzenie eksperymentu, uchwycenie ekspozycji i wyników, przeliczenie rezultatów i zapis decyzji — zanim dodasz złożoność.
Gdy pierwszy produkt jest stabilny, rozszerzaj po produkcie z przewidywalnym procesem onboardingu. Każdy nowy produkt powinien być powtarzalną konfiguracją, a nie projektem na zamówienie.
Jeśli organizacja ma tendencję do długich cykli budowy platformy, rozważ podejście dwutorowe: równoległe budowanie trwałych kontraktów danych (eventy, ID, definicje metryk) i cienkiej warstwy aplikacyjnej. Zespoły czasem używają Koder.ai do szybkiego postawienia tej cienkiej warstwy — formularze, pulpity, uprawnienia i eksport — a potem wzmacniają ją w miarę adopcji (eksport kodu źródłowego i iteracyjne rollbacki przez snapshots, gdy wymagania się zmieniają).
Checklist rolloutu dla każdego produktu
Używaj lekkiej checklisty do onboardingu produktów i schematów eventów:
- potwierdź taksonomię eventów i konwencje nazewnictwa (i kto je może zmieniać)
- zweryfikuj, że istnieją eventy exposure i są jednoznacznie przypisywalne do użytkownika/sesji
- zmapuj metryki do schematu eventów produktu (włączając przypadki krawędziowe jak zwroty)
- uruchom backfill lub okres równoległego działania, by porównać z istniejącą analityką
- przypisz właścę dla konfiguracji eksperymentu, walidacji danych i notatek decyzyjnych
Tam, gdzie pomaga adopcji, linkuj „kolejne kroki” z wyników eksperymentu do odpowiednich obszarów produktu (np. eksperymenty cenowe → /pricing). Trzymaj linki informacyjne i neutralne — bez sugerowania wyników.
Mierz adopcję, by szybko usuwać tarcia
Zmierz, czy narzędzie staje się domyślnym miejscem decyzji:
- tygodniowo aktywni użytkownicy według roli (PM, analityk, inżynier)
- utworzone i zakończone eksperymenty
- odsetek eksperymentów z wypełnionymi notatkami decyzyjnymi (nie tylko przeglądanych wyników)
- czas od zakończenia eksperymentu do zapisania decyzji
Typowe pułapki do unikania
W praktyce rollouty potykają się o kilka powtarzających się problemów:
- Niespójne definicje metryk między produktami (ta sama nazwa, inna matematyka)
- Brakujące lub wadliwe śledzenie ekspozycji, prowadzące do błędnych wyników
- Niejasna własność walidacji i zatwierdzeń, powodująca „zombie eksperymenty”
- ciche zmiany schematu, które psują trendy bez czyjejś wiedzy
- skalowanie do wielu metryk za wcześnie, zanim podstawowy workflow zyska zaufanie