29 sie 2025·8 min
Jak zbudować aplikację webową do śledzenia zależności między działami
Praktyczny przewodnik projektowania aplikacji webowej do rejestrowania, wizualizacji i zarządzania zależnościami między działami — z jasnymi przepływami, rolami i raportowaniem.
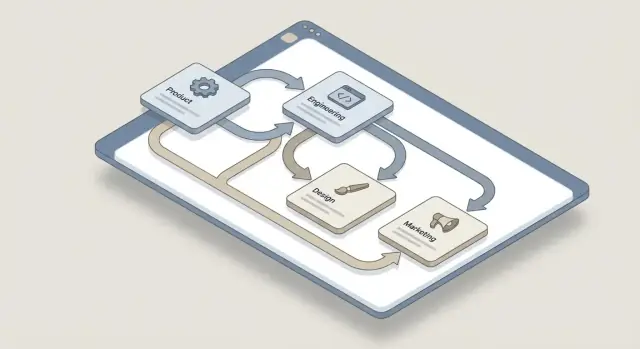
Wyjaśnij problem i zakres
Zanim zaczniesz szkicować ekrany czy wybierać stack technologiczny, ustal dokładnie, co chcesz śledzić i dlaczego. „Zależność” brzmi ogólnie, ale w praktyce zespoły rozumieją to różnie — i to właśnie rozbieżności powodują pominięte przekazania i blokery w ostatniej chwili.
Zdefiniuj, co dla was znaczy „zależność”
Zacznij od prostej, po polsku sformułowanej definicji, na którą wszyscy się zgodzą. W większości organizacji zależności mieszczą się w kilku praktycznych kategoriach:
- Dostarczalny element: Zespół A nie może zacząć/zakończyć, dopóki zespół B nie dostarczy pliku, funkcji lub dokumentu.
- Zatwierdzenie: Potrzebny jest podpis/akceptacja Legal, Finance, Security lub kierownictwa.
- Dane: Inny zespół musi udostępnić dostęp do danych, raport, eksport lub zmianę schematu.
- Zasoby / obsada: Inna grupa musi przydzielić czas (przegląd designu, QA, wsparcie ops).
Bądź konkretny również w kwestii tego, co nie jest zależnością. Na przykład „współpraca miła do posiadania” lub „aktualizacja do wiadomości” może trafiać do innego narzędzia.
Zmapuj działy i typowe rodzaje zależności
Wypisz działy, które regularnie blokują albo odblokowują pracę (Product, Engineering, Design, Marketing, Sales, Support, Legal, Security, Finance, Data, IT). Następnie zanotuj powtarzające się wzorce między nimi. Przykłady: „Marketing potrzebuje daty premiery od Product”, „Security potrzebuje modelu zagrożeń przed przeglądem”, „Zespół Data potrzebuje dwóch tygodni na wprowadzenie zmian śledzenia”.
Ten krok pomoże skupić aplikację na prawdziwych przekazaniach między zespołami, zamiast robić z niej ogólny tracker zadań.
Określ problemy, które chcesz usunąć
Zapisz bieżące tryby awarii:
- Przekazania są pomijane, bo właściciel nie jest jasny.
- Zależność wykrywana jest za późno (tuż przed premierą).
- Aktualizacje są rozsiane w wielu miejscach (email, czaty, arkusze kalkulacyjne).
- Dochodzi do eskalacji, bo nie ma wspólnego widoku statusu i terminów.
Ustal kryteria sukcesu (żeby „zrobione” dało się zmierzyć)
Zdefiniuj kilka wyników, które możesz mierzyć po wdrożeniu, na przykład:
- Mniej eskalacji związanych z blokadami międzyzespołowymi.
- Szybszy czas zatwierdzeń (mediana dni od prośby do decyzji).
- Większa jasność właścicielstwa (np. % zależności z przypisanym właścicielem).
- Mniej „niespodziewanych” blockerów wykrytych w ostatnim tygodniu przed kamieniem milowym.
Gdy zakres i metryki sukcesu są jasne, każda decyzja o funkcji staje się prostsza: jeśli nie redukuje niejasności dotyczącej właściciela, terminów czy przekazań, prawdopodobnie nie powinna trafić do wersji pierwszej.
Zmapuj użytkowników i kluczowe przepływy pracy
Zanim zaprojektujesz ekrany lub tabele, wyraźnie określ, kto będzie korzystał z aplikacji i co chce osiągnąć. Tracker zależności zawodzi, gdy jest budowany „dla wszystkich”, więc zacznij od małej grupy głównych person i optymalizuj doświadczenie pod ich potrzeby.
Wybierz główne persony (i co każda potrzebuje)
Większość zależności między działami pasuje do czterech ról:
- Zgłaszający (Requester): potrzebuje czegoś od innego zespołu; zależy mu na jasności, terminach i wiedzy „co dalej”.
- Właściciel (Owner): zespół/osoba, która musi dostarczyć; zależy mu na zakresie pracy, nakładzie i negocjacji terminów.
- Zatwierdzający (Approver): weryfikuje priorytet lub alokację zasobów; zależy mu na ryzyku, kompromisach i odpowiedzialności.
- Program manager: potrzebuje ogólnej widoczności; zależy mu na wąskich gardłach, przeterminowanych pozycjach i ścieżkach eskalacji.
Napisz jedną krótką historię zadaniową (job story) dla każdej persony: co ją skłania do otwarcia aplikacji, jaką decyzję musi podjąć, i jak wygląda sukces.
Udokumentuj kluczowe przepływy end‑to‑end
Zarejestruj główne przepływy jako proste sekwencje, wskazując miejsca przekazań:
- Utwórz zależność (requester) → wprowadź szczegóły, dołącz kontekst, zaproponuj datę potrzebną.
- Zaakceptuj / odrzuć / poproś o zmiany (owner/approver) → potwierdź właścicielstwo i oczekiwania.
- Zrealizuj zależność (owner) → oznacz jako wykonane, dodaj dowody/uwagi, powiadom zgłaszającego.
- Eskaluj (program manager) → uruchom przegląd, gdy coś jest zablokowane, przeterminowane lub sporne.
Utrzymaj przepływ stanowczy. Jeśli użytkownicy mogą przenosić zależność do dowolnego statusu w dowolnym momencie, jakość danych szybko się pogorszy.
Zapobiegaj przeciążeniu formularzy: pola wymagane vs opcjonalne
Zdefiniuj minimum potrzebne do rozpoczęcia: tytuł, zgłaszający, zespół/dostawca, data potrzebna, krótki opis. Wszystko inne niech będzie opcjonalne (wpływ, linki, załączniki, tagi).
Zdecyduj, co musi być śledzone w czasie
Zależności dotyczą zmian. Zaplanuj rejestrowanie śladu audytowego dla zmian statusu, komentarzy, edycji terminu, zmiany właściciela oraz decyzji akceptacji/odrzucenia. Ta historia jest niezbędna do nauki i sprawiedliwej eskalacji później.
Zaprojektuj rekord zależności
Rekord zależności to „jednostka prawdy”, którą zarządza aplikacja. Jeśli jest niespójny lub niejasny, zespoły będą dyskutować, co dana zależność oznacza, zamiast ją rozwiązywać. Celuj w rekord, który da się utworzyć w mniej niż minutę, ale będzie na tyle ustrukturyzowany, by można go było filtrować i raportować później.
Zacznij od spójnego szablonu
Używaj tych samych pól wszędzie, aby ludzie nie wymyślali własnych formatów:
- Tytuł: krótki, nakierowany na działanie („Przegląd bezpieczeństwa dla nowego flow płatności")
- Opis: czego potrzeba, jak wygląda „zrobione”, ograniczenia
- Zespół zgłaszający (team, który potrzebuje czegoś)
- Zespół dostarczający (team, który dostarczy)
- Właściciel (osoba odpowiedzialna za następny krok)
- Data potrzebna
- Status: trzymaj prosto (np. Draft → Proposed → Accepted → In Progress → Blocked → Done)
Dodaj kilka pól opcjonalnych, które zmniejszają dwuznaczność bez tworzenia systemu punktowego:
- Wpływ: co się opóźni lub jakie ryzyko wzrasta, jeśli nie zostanie dostarczone (Low/Medium/High wystarczy)
- Pilność: jak wrażliwe czasowo to jest (Normal/Soon/ASAP)
Powiąż to z rzeczywistą pracą
Zależności rzadko żyją same. Pozwól na wielokrotne powiązania z powiązanymi elementami — ticketami, dokumentami, notatkami ze spotkań, PRD — żeby ludzie szybko mogli sprawdzić kontekst. Przechowuj zarówno URL, jak i krótką etykietę (np. „Jira: PAY‑1842”) żeby listy były czytelne.
Projektuj z myślą o częściowych informacjach (to normalne)
Nie każda zależność zaczyna się z idealnym właścicielem. Wspieraj opcję „Nieznany właściciel” i kieruj ją do kolejki triage, gdzie koordynator (lub rotacyjna osoba) może przypisać właściwy zespół. To zapobiega pozostawaniu zależności poza systemem tylko dlatego, że jedno pole jest puste.
Dobry rekord zależności sprawia, że odpowiedzialność jest jasna, priorytetyzacja możliwa, a follow‑up bezbolesny — bez proszenia użytkowników o dodatkową pracę.
Zaplanuj model danych (prosty, ale odporny na przyszłość)
Aplikacja do śledzenia zależności żyje lub umiera przez model danych. Celuj w strukturę łatwą do zapytania i wyjaśnienia, pozostawiając przestrzeń do rozwoju (więcej zespołów, projektów, reguł) bez konieczności przebudowy.
Zacznij od małego zestawu podstawowych encji
Większość organizacji pokryje 80% potrzeb pięcioma tabelami (kolekcjami):
- Department/Team: nazwa, centrum kosztów (opcjonalne), zespół nadrzędny (opcjonalne)
- Person: imię i nazwisko, email, team_id, rola/tytuł (opcjonalne)
- Project/Initiative: nazwa, owner_team_id, daty start/koniec (opcjonalne)
- Milestone: project_id, data, notatki „definition of done”
- Dependency: rekord, o którym wszyscy dyskutują — co jest potrzebne, przez kogo i kiedy
Trzymaj Dependency skupione: title, description, requesting_team_id, providing_team_id, owner_person_id, needed_by_date, status, priority oraz linki do powiązanej pracy.
Modeluj relacje jawnie
Dwie relacje są najważniejsze:
- Dependency → Project/Initiative: zależność powinna być przypięta do projektu (opcjonalnie do milestone). To umożliwia widoczność projektu i raportowanie.
- Dependency → Dependency (blocked by): czasami zależność nie może się zacząć, dopóki inna nie będzie skończona. Przechowuj to w tabeli łączącej (np.
dependency_edges) zblocking_dependency_idiblocked_dependency_id, żeby później zbudować graf zależności.
Zdefiniuj stany statusu i przejścia
Użyj prostego, wspólnego cyklu życia, np.:
Draft → Proposed → Accepted → In Progress → Blocked → Done
Zdefiniuj mały zestaw dozwolonych przejść (na przykład Done nie wraca bez akcji administratora). To zapobiega „losowemu” zmienianiu statusów i sprawia, że powiadomienia są przewidywalne.
Przechowuj historię, bez przesadnego skomplikowania
Będziesz chciał odpowiedzieć na pytanie: „Kto co zmienił i kiedy?” Dwa powszechne podejścia:
- Tabela audytu: przechowuj
entity_type,entity_id,changed_by,changed_ati JSON‑owy diff. Łatwe do wdrożenia i zapytań. - Strumień zdarzeń: append‑only events (np.
DependencyAccepted,DueDateChanged). Potężne, ale bardziej pracochłonne.
Dla większości zespołów zacznij od tabeli audytu; można potem przejść na eventy, jeśli zajdzie potrzeba zaawansowanej analityki lub odtwarzania stanu.
Wybierz odpowiednie wzorce UI
Tracker zależności działa, gdy ludzie potrafią w kilka sekund odpowiedzieć na dwa pytania: co ja mam na głowie i na co ja czekam. Wzorce UI powinny zmniejszać obciążenie poznawcze, uwidaczniać status i trzymać typowe akcje w zasięgu jednego kliknięcia.
Zacznij od filtrowalnej listy (domyślny widok)
Domyślny widok niech będzie prostą tabelą lub listą kart z mocnymi filtrami — tutaj spędzi większość użytkowników. Umieść dwa „starterowe” filtry na wyciągnięcie ręki:
- My team provides (zależności, które twój zespół musi dostarczyć)
- My team requests (zależności blokujące twój zespół)
Lista powinna być przeglądalna: tytuł, zespół zgłaszający, zespół dostarczający, termin, status i ostatnia aktualizacja. Nie wtłaczaj wszystkich pól; szczegóły dostępne w widoku szczegółowym.
Używaj czytelnych wskazówek wizualnych zgodnych z decyzjami
Ludzie triage’ują pracę wzrokowo. Używaj spójnych oznaczeń (kolor + etykieta tekstowa, nie tylko kolor) dla:
- Przeterminowane
- Ryzyko (np. niedługo termin i brak odpowiedzi)
- Czeka na zatwierdzenie
- Zablokowane
Dodaj małe, czytelne wskaźniki typu „3 dni po terminie” lub „Potrzebna odpowiedź właściciela”, żeby użytkownicy wiedzieli, co zrobić dalej, a nie tylko że coś jest nie tak.
Zaproponuj graf zależności — ale jako opcję
Widok grafu zależności jest przydatny w dużych programach, podczas planowania i wykrywania cykli czy ukrytych blockerów. Jednak grafy mogą przytłaczać użytkowników okazjonalnych, więc traktuj je jako widok dodatkowy („Przełącz na graf”), a nie domyślny. Pozwól użytkownikom powiększać fragment dotyczący jednego inicjatywy lub zespołu, zamiast zmuszać do oglądania całego pajęczego wykresu.
Umieść szybkie akcje tam, gdzie są potrzebne
Wspieraj szybką koordynację za pomocą akcji inline na liście i w widoku szczegółowym:
- Akceptuj / potwierdź właścicielstwo
- Poproś o info
- Zmień termin (z powodem)
- Skomentuj (z @wzmiankami)
Projektuj te akcje tak, żeby tworzyły jasny ślad audytu i wyzwalały właściwe powiadomienia, żeby aktualizacje nie ginęły w wątkach czatu.
Ustal uprawnienia, właścicielstwo i dostęp
Keep full control of code
When you are ready, export the codebase and keep building in-house.
To tu powodzenie lub porażka trackerów zależności. Zbyt luźne — ludzie przestaną ufać danym. Zbyt ścisłe — aktualizacje staną.
Trzymaj role małe (i zapadające w pamięć)
Zacznij od czterech ról, które odzwierciedlają codzienne zachowania:
- Viewer: może przeglądać zależności i subskrybować aktualizacje.
- Contributor: może dodawać nowe zależności i komentować, ale nie zmienia właściciela.
- Owner: odpowiedzialny za rekord; może aktualizować status, terminy i notatki rozliczeniowe.
- Admin: zarządza zespołami, przypisaniami ról i ustawieniami globalnymi.
To sprawia, że „kto może co robić” jest oczywiste, bez tworzenia podręcznika polityk.
Zdefiniuj jasne zasady edycji
Uczyń rekord jednostką odpowiedzialności:
- Właściciele aktualizują status, terminy i zobowiązania dostawy.
- Contributorzy proponują zmiany (sugerowane edycje lub komentarze), gdy zauważą błąd lub nowe ryzyko.
- Admini zarządzają zespołami i mogą przypisać właściciela, gdy ludzie zmieniają role.
Aby zapobiec cichej dryfie danych, loguj zmiany (kto co zmienił i kiedy). Prosty ślad audytu buduje zaufanie i redukuje spory.
Obsłuż wrażliwe zależności
Niektóre zależności dotyczą planów zatrudnienia, prac bezpieczeństwa, przeglądów prawnych czy eskalacji klienta. Wspieraj ograniczoną widoczność per zależność (lub per projekt):
- Prywatne dla wymienionego zestawu zespołów
- Prywatne w przestrzeni projektowej
- Widoczne dla wszystkich uwierzytelnionych użytkowników
Upewnij się, że pozycje z ograniczonym dostępem mogą nadal pojawiać się w raportach agregowanych jako liczniki (bez szczegółów), jeśli potrzebujesz widoczności na wysokim poziomie.
Uwierzytelnianie: wybierz rozwiązanie o najniższym oporze
Jeśli firma ma, użyj SSO, żeby ludzie nie tworzyli nowych haseł, a admini nie musieli zarządzać kontami. Jeśli nie, wspieraj email/hasło z podstawowymi zabezpieczeniami (weryfikacja email, reset, opcjonalne MFA później). Utrzymaj proces logowania prostym, aby aktualizacje odbywały się wtedy, gdy są potrzebne.
Zbuduj powiadomienia i reguły eskalacji
Powiadomienia zamieniają arkusz kalkulacyjny w aktywne narzędzie koordynacji. Cel jest prosty: właściwe osoby otrzymują właściwe przypomnienie we właściwym czasie — bez konieczności odświeżania dashboardu.
Wybierz kanały zgodne z rzeczywistą pracą
Zacznij od dwóch domyślnych kanałów:
- Powiadomienia w aplikacji dla lekkich aktualizacji i widocznego śladu aktywności.
- Email dla tego, co wymaga działania lub jest czasowo wrażliwe.
Następnie zrób integracje z czatem opcjonalnymi (Slack/Microsoft Teams) dla zespołów, które żyją w kanałach. Traktuj czat jako warstwę wygody, nie jedyny kanał — inaczej stracisz interesariuszy, którzy nie używają tego narzędzia.
Wyzwalaj alerty przy znaczących zdarzeniach
Projektuj listę zdarzeń wokół decyzji i ryzyka:
- Przypisanie (nowa zależność przypisana do właściciela)
- Akceptacja/potwierdzenie (właściciel potwierdza dostawę)
- Zmiana terminu (zwłaszcza gdy przesunięto wcześniej)
- Przeterminowanie (termin minął bez ukończenia)
Każde powiadomienie powinno zawierać, co się zmieniło, kto jest następnym właścicielem, termin oraz bezpośredni link do rekordu.
Zapobiegaj spamowi za pomocą zaufanych ustawień
Jeśli aplikacja jest głośna, użytkownicy ją wyciszą. Dodaj:
- Codzienne/tygodniowe podsumowania dla zmian niepilnych
- Godziny ciszy (per użytkownik, zgodne ze strefą czasową)
- Preferencje per użytkownik według typu zdarzenia i kanału
Unikaj też powiadamiania osoby o akcji, którą sama wykonała.
Dodaj reguły eskalacji dla utknionej pracy
Eskalacje to siatka bezpieczeństwa, nie kara. Częsta reguła: „Przeterminowane o 7 dni powiadamia grupę menedżerów” (lub sponsora zależności). Trzymaj kroki eskalacji widoczne w rekordzie, żeby oczekiwania były jasne, i pozwól adminom dostosowywać progi w miarę uczenia się zespołów.
Dodaj wyszukiwanie, filtry i raportowanie
Ship React and Go fast
Build a React UI with a Go and PostgreSQL backend from a single conversation.
Gdy zależności się skumulują, powodzenie aplikacji zależy od tego, jak szybko ludzie znajdą „tę jedną rzecz, która nas blokuje”. Dobre wyszukiwanie i raporty zamieniają tracker w narzędzie robocze używane cotygodniowo.
Spraw, by wyszukiwanie było natychmiastowe
Projektuj wyszukiwanie wokół pytań, które ludzie zadają:
- Wyszukiwanie słów kluczowych w tytule, opisie, powiązanych projektach i komentarzach (w tym popularne akronimy).
- Filtry po zespole/właścicielu, projekcie, statusie i zakresie dat (utworzone, zaktualizowane, termin).
Wyniki powinny być czytelne: pokaż tytuł zależności, aktualny status, termin, zespół dostarczający i najbardziej istotny link (np. „Zablokowane przez przegląd Security”).
Zapisane filtry dla powtarzalnych rutyn
Większość uczestników regularnie wraca do tych samych widoków co tydzień. Dodaj zapisane filtry (osobiste i współdzielone) dla typowych wzorców:
- Cotygodniowy przegląd zależności (tylko „Blocked” + „Termin w ciągu 14 dni”)
- Nadchodzące terminy wg zespołu
- „Czekamy na nas” vs. „Czekają na nich”
Zadbaj, żeby zapisane widoki miały stabilny URL, żeby można było wstawiać je do notatek ze spotkań lub wiki, np. /operations/dependency-review.
Tagi i lekkie raporty
Używaj tagów lub kategorii do szybkiego grupowania (np. Legal, Security, Finance). Tagi powinny uzupełniać — nie zastępować — ustrukturyzowanych pól jak status i właściciel.
Do raportowania zacznij od prostych wykresów i tabel: liczba wg statusu, zalegające zależności, nadchodzące terminy wg zespołu. Skup się na akcjach, nie na metrykach dla samego patrzenia.
Eksporty z zachowaniem reguł dostępu
Eksporty są paliwem spotkań, ale mogą wyciekać dane. Wspieraj eksport CSV/PDF, który:
- Zawiera tylko wiersze i pola, które użytkownik może zobaczyć
- Wyraźnie oznacza elementy „ograniczone” (lub pomija je)
- Dołącza kryteria filtra i znacznik czasu, żeby raporty nie były źle interpretowane później
Wybierz utrzymalny stack technologiczny
Tracker zależności działa, gdy pozostaje łatwy do zmiany. Wybierz narzędzia, które twój zespół już zna (lub może długoterminowo wspierać), i optymalizuj pod kątem czytelnych relacji danych, niezawodnych powiadomień i prostego raportowania.
Zacznij od standardowego web stacku
Nie potrzebujesz ekstrawagancji. Konwencjonalne podejście ułatwia zatrudnianie, onboardingi i reakcję na incydenty.
- Frontend: dowolny popularny framework (React, Vue lub podobny) — priorytet to spójne wzorce komponentów dla formularzy, tabel i stron szczegółów.
- Backend: powszechnie używany framework serwerowy (Node, Python, Ruby, Java, .NET) zgodny z umiejętnościami zespołu.
Jeśli chcesz zweryfikować UX i przepływy przed zaangażowaniem inżynierii, platforma do szybkiego prototypowania taka jak Koder.ai może pomóc w iteracji przez chat — a potem wyeksportować kod, gdy będziesz gotowy. (Koder.ai często celuje w React na frontendzie oraz Go + PostgreSQL na backendzie, co dobrze pasuje do relacyjnych danych zależności.)
Użyj bazy relacyjnej dla danych zależności
Zależności między działami są z natury relacyjne: zespoły, właściciele, projekty, terminy, statusy i linki „depends on”. Baza relacyjna (np. Postgres/MySQL) ułatwia:
- wymuszanie integralności danych (pola wymagane, ważne statusy)
- zapytania typu „kto kogo blokuje i od kiedy?”
- generowanie raportów bez wymyślania obejść
Jeśli później potrzebujesz widoków typu graf, nadal możesz modelować krawędzie w tabelach relacyjnych i renderować je w UI.
Zaplanuj warstwę API pod przyszłe integracje
Nawet jeśli zaczynasz od pojedynczego UI, zaprojektuj backend jako API, żeby inne narzędzia mogły się integrować później.
- REST dobrze działa dla CRUD + endpointów raportowych.
- GraphQL jest przydatny, jeśli wiele ekranów potrzebuje elastycznych, zagnieżdżonych danych.
Tak czy inaczej, wersjonuj API i standaryzuj identyfikatory, żeby integracje nie łamały się przy zmianach.
Dodaj zadania w tle dla alertów i digestów
Powiadomienia nie powinny zależeć od odświeżania strony. Użyj zadań w tle do:
- zaplanowanych digestów (codzienny/tygodniowy)
- reguł eskalacji (przeterminowane zależności)
- ponownych prób dostarczenia webhooków i grupowania emaili
To rozdzielenie utrzymuje responsywność aplikacji i sprawia, że powiadomienia są bardziej niezawodne przy wzroście użycia.
Zaplanuj integracje z istniejącymi narzędziami
Integracje powodują, że tracker zależności się przyjmie. Jeśli ludzie muszą opuszczać system ticketowy, dokumenty czy kalendarz, żeby zaktualizować zależność, aktualizacje będą opóźnione i aplikacja stanie się „jeszcze jednym miejscem do sprawdzania”. Celem jest spotkać zespoły tam, gdzie już pracują, a jednocześnie utrzymać aplikację jako źródło prawdy.
Zacznij od systemów, których ludzie najczęściej używają
Priorytetyzuj mały zestaw narzędzi o wysokim użyciu — zwykle ticketing (Jira/ServiceNow), dokumenty (Confluence/Google Docs) i kalendarze (Google/Microsoft). Cel nie polega na lustrzanym odwzorowaniu każdego pola. Chodzi o to, by było łatwo:
- powiązać zależność z elementem pracy, który ją dostarczy
- przejść z aplikacji do kanonicznego artefaktu
- pobrać minimalne sygnały statusu (np. „Done”, termin, właściciel)
Wybieraj linkowanie dwukierunkowe zamiast pełnej synchronizacji
Pełna synchronizacja jest kusząca, ale tworzy problemy z rozwiązywaniem konfliktów i kruche edge case’y. Lepszy wzorzec to linkowanie dwukierunkowe:
- Twoja aplikacja przechowuje referencję zewnętrzną (narzędzie, ID elementu, URL).
- Narzędzie zewnętrzne przechowuje backlink do zależności (często jako komentarz, pole niestandardowe lub wklejony URL).
To utrzymuje kontekst połączony bez wymuszania identycznych modeli danych.
Zaplanuj importy na początkowe wdrożenie
Większość organizacji ma już arkusz lub backlog zależności. Wspieraj szybką ścieżkę „startu”:
- upload CSV ze szablonami
- import przez API dla power userów lub adminów
Sparuj to z lekkim raportem walidacyjnym, żeby zespoły mogły poprawić brakujących właścicieli lub dat przed publikacją.
Udokumentuj ograniczenia i obsługę błędów
Zapisz, co się dzieje, gdy coś pójdzie nie tak: brak uprawnień, usunięte/archiwizowane elementy, zmienione nazwy projektów lub limity tempa. Pokaż konkretne komunikaty błędów („Nie możemy uzyskać dostępu do tego issue w Jira — poproś o permisje lub ponownie połącz”) i utrzymuj stronę stanu integracji (np. /settings/integrations), żeby admini mogli szybko diagnozować problemy.
Wdrażaj stopniowo z zasadami zarządzania
Add a graph view later
Create an optional dependency graph screen once your core list workflow is stable.
Tracker zależności działa tylko wtedy, gdy ludzie mu ufają i utrzymują go aktualnym. Najbezpieczniejsza droga to wypuszczenie wersji minimalnej, przetestowanie jej na małej grupie, a potem dodanie lekkiego zarządzania, aby aplikacja nie stała się cmentarzem starych pozycji.
Zacznij od Minimum Viable Version (MVP)
Dla pierwszego wydania utrzymaj zakres wąski i oczywisty:
- rekordy zależności z jasnym tytułem i krótkim opisem
- właściciel (osoba) oraz zespoły zgłaszający/dostarczający
- status (Draft → Proposed → Accepted → In Progress → Blocked → Done)
- data potrzebna (opcjonalna, ale zalecana)
- prosty flagger ryzyka/wpływu
- powiadomienia o przypisaniu, zmianach statusu i zbliżających się terminach
Jeśli nie możesz odpowiedzieć „kto to ma?” i „co dalej?” z poziomu listy, model jest za skomplikowany.
Przeprowadź pilotaż przed ogólnofirmowym launch'em
Wybierz 1–2 przekrojowe programy, gdzie zależności już bolą (premiera produktu, projekt zgodności, duża integracja). Przeprowadź krótki pilotaż 2–4 tygodnie.
Organizuj cotygodniowe 30‑minutowe sesje feedbacku z przedstawicielami każdego działu. Pytaj:
- Które pola ignorujecie?
- Które aktualizacje wydają się powtarzalne?
- Które powiadomienia są pomocne, a które uciążliwe?
Wykorzystaj feedback z pilota do dopracowania formularza, statusów i widoków przed skalowaniem.
Dodaj lekkie zasady zarządzania (żeby praca nie stała się stara)
Governance nie oznacza komitetu. To kilka jasnych zasad:
- Triage owner: rola rotacyjna (lub mały zespół ops), który przypisuje nieprzypisane zależności w ciągu 24–48 godzin.
- Polityka starych pozycji: po X dniach bez aktywności aplikacja pingnie właściciela; po Y dniach eskaluje do lidera programu.
- Kryteria zamknięcia: zdefiniuj, kiedy zależność można oznaczyć jako Done i kto może ją zamknąć / ponownie otworzyć.
Opublikuj krótką instrukcję użycia
Wypuść jednostronicowy przewodnik wyjaśniający statusy, oczekiwania dotyczące właścicielstwa i zasady powiadomień. Dołącz go w aplikacji (np. /help/dependencies), żeby był zawsze pod ręką.
Mierz sukces i iteruj
Wypuszczenie aplikacji to tylko połowa drogi. Tracker zależności działa, gdy zespoły rzeczywiście z niego korzystają, by robić przekazania czytelniejszymi i szybszymi — i gdy liderzy ufają mu jako źródłu prawdy.
Mierz adopcję (czy jest używany?)
Zacznij od kilku prostych metryk, które przeglądasz co tydzień:
- aktywni użytkownicy wg działu (i ilu wraca)
- zależności tworzone tygodniowo/miesięcznie
- kompletność danych, zwłaszcza % z przypisanym właścicielem i datą potrzebną
Problemy z adopcją zwykle wyglądają tak: ludzie tworzą wpisy, ale ich nie aktualizują; tylko jeden zespół loguje zależności; lub brak właścicieli/dat powoduje, że nic się nie rusza.
Mierz rezultaty (czy poprawia dostarczanie?)
Mierz, czy śledzenie zależności zmniejsza tarcie, nie tylko generuje aktywność:
- średni czas do akceptacji (od utworzenia do zaakceptowania/ potwierdzenia)
- odsetek przeterminowanych
- ponownie otwarte pozycje (zamknięte, a potem reaktywowane)
Jeśli czas do akceptacji jest długi, prośba może być niejasna albo workflow ma za dużo kroków. Jeśli często występują ponowne otwarcia, definicja „zrobione” jest prawdopodobnie niejasna.
Zbieraj jakościowy feedback tam, gdzie praca się dzieje
Wykorzystaj regularne spotkania cross‑team (planowanie tygodniowe, release syncs), aby szybko zbierać opinie.
Pytaj, jakich informacji brakuje przy otrzymaniu zależności, które statusy są mylące i jakich aktualizacji ludzie zapominają robić. Trzymaj wspólną notatkę z powtarzającymi się uwagami — to twoje najlepsze kandydatury do iteracji.
Planuj małe cykle iteracyjne
Zobowiąż się do przewidywalnego rytmu (np. co 2–4 tygodnie) na dopracowywanie:
- Pól (usuń rzadko używane; uprość nazwy; dodawaj tylko gdy wiele osób prosi)
- Widoków (strona „Moje zależności”, widok „Przeterminowane”, prosty dashboard działu)
- Powiadomień (zredukuj hałas; skup się na zmianach właściciela, ryzyku terminu i przeterminowaniach)
Traktuj każdą zmianę jak pracę produktową: zdefiniuj oczekiwane usprawnienie, wypuść, potem ponownie zmierz te same metryki, aby potwierdzić, że pomogła.