29 kwi 2025·6 min
Jak zbudować aplikację webową do eksperymentów cenowych
Zaprojektuj i wdroż panel webowy do zarządzania eksperymentami cenowymi: warianty, podziały ruchu, przypisania, metryki, dashboardy i bezpieczne zabezpieczenia wdrożenia.
Zaprojektuj i wdroż panel webowy do zarządzania eksperymentami cenowymi: warianty, podziały ruchu, przypisania, metryki, dashboardy i bezpieczne zabezpieczenia wdrożenia.
Eksperymenty cenowe to uporządkowane testy, w których pokazujesz różne ceny (lub pakiety) różnym grupom klientów i mierzysz, co się zmienia—konwersję, upgrade’y, churn, przychód na odwiedzającego i więcej. To wersja A/B testu dla cen, ale z większym ryzykiem: błąd może zdezorientować klientów, wygenerować zgłoszenia do wsparcia lub naruszyć wewnętrzne zasady.
Manager eksperymentów cenowych to system, który utrzymuje te testy pod kontrolą, widoczne i odwracalne.
Kontrola: Zespoły potrzebują jednego miejsca do zdefiniowania, co jest testowane, gdzie i dla kogo. „Zmieniliśmy cenę” to nie jest plan—eksperyment wymaga jasnej hipotezy, dat, reguł targetowania i przycisku awaryjnego.
Śledzenie: Bez stabilnych identyfikatorów (klucz eksperymentu, klucz wariantu, znacznik czasu przypisania) analiza staje się zgadywanką. Manager powinien zapewnić, że każde ekspozycja i zakup można przypisać do właściwego testu.
Spójność: Klienci nie powinni widzieć jednej ceny na stronie cenowej, a innej przy finalizacji zakupu. Manager powinien koordynować, jak warianty są stosowane na różnych powierzchniach, aby doświadczenie było spójne.
Bezpieczeństwo: Błędy cenowe kosztują. Potrzebujesz ograniczeń jak limity ruchu, reguły kwalifikowalności (np. tylko nowi klienci), kroki zatwierdzające i możliwość audytu.
Ten artykuł koncentruje się na wewnętrznej aplikacji webowej, która zarządza eksperymentami: ich tworzeniem, przypisaniem wariantów, zbieraniem zdarzeń i raportowaniem wyników.
To nie jest pełny silnik cenowy (obliczanie podatków, fakturowanie, katalogi wielowalutowe, proporcje rozliczeń itp.). Zamiast tego to panel sterowania i warstwa śledzenia, która sprawia, że testy cenowe są wystarczająco bezpieczne do regularnego uruchamiania.
Manager eksperymentów cenowych jest użyteczny tylko wtedy, gdy jasne jest, co będzie—i czego nie będzie—robił. Ograniczony zakres utrzymuje produkt prostym w obsłudze i bezpieczniejszym do wdrożenia, szczególnie gdy w grę wchodzi prawdziwy przychód.
Przynajmniej twoja aplikacja webowa powinna umożliwić nietechnicznemu operatorowi przeprowadzenie eksperymentu od początku do końca:
Jeśli nic więcej nie zbudujesz, zbuduj te elementy dobrze—with jasnymi domyślnymi ustawieniami i zabezpieczeniami.
Zdecyduj wcześnie, jakie formaty eksperymentów będziesz wspierać, aby UI, model danych i logika przypisań pozostały spójne:
Bądź konkretny, by zapobiec „rozrostowi zakresu” zamieniającemu narzędzie eksperymentowe w delikatny system krytyczny dla biznesu:
Określ sukces w kategoriach operacyjnych, nie tylko statystycznych:
Aplikacja do eksperymentów cenowych żyje lub umiera dzięki modelowi danych. Jeśli nie możesz wiarygodnie odpowiedzieć „jaką cenę ten klient widział i kiedy?”, twoje metryki będą zaszumione, a zespół straci zaufanie.
Zacznij od niewielkiego zestawu głównych obiektów, które odzwierciedlają, jak cena faktycznie działa w produkcie:
Używaj stabilnych identyfikatorów między systemami (product_id, plan_id, customer_id). Unikaj „ładnych nazw” jako kluczy—one się zmieniają.
Pola czasu są równie ważne:
Rozważ również effective_from / effective_to na rekordach Price, aby odtworzyć ceny w dowolnym momencie historycznym.
Zdefiniuj relacje wprost:
W praktyce oznacza to, że Event powinien nosić (lub być łączalny z) customer_id, experiment_id i variant_id. Jeśli przechowujesz tylko customer_id i „szukasz przypisania później”, ryzykujesz błędne joiny, gdy przypisania się zmienią.
Eksperymenty cenowe potrzebują historii przyjaznej audytowi. Kluczowe rekordy traktuj jako append-only:
Takie podejście utrzymuje spójność raportowania i upraszcza wdrożenie funkcji governance jak dzienniki audytu.
Manager eksperymentów cenowych potrzebuje przejrzystego cyklu życia, aby wszyscy wiedzieli, co można edytować, co jest zablokowane i co się dzieje z klientami, gdy eksperyment zmienia stan.
Draft → Scheduled → Running → Stopped → Analyzed → Archived
Aby zmniejszyć ryzykowne uruchomienia, wymuszaj wymagane pola w miarę postępu eksperymentu:
Dla cen dodaj opcjonalne bramy dla Finance i Legal/Compliance. Tylko zatwierdzający mogą przejść Scheduled → Running. Jeśli wspierasz nadpisania (np. pilny rollback), zapisuj kto nadpisał, dlaczego i kiedy w dzienniku audytu.
Kiedy eksperyment jest Stopped, określ dwa zachowania:
Uczyń ten wybór wymaganym podczas zatrzymania, aby zespół nie mógł zatrzymać eksperymentu bez decyzji o wpływie na klientów.
Prawidłowe przypisanie to różnica między wiarygodnym testem cenowym a szumem. Twoja aplikacja powinna ułatwiać określenie kto otrzymuje cenę i zapewnić, że klienci będą ją widzieć konsekwentnie.
Klient powinien widzieć ten sam wariant między sesjami, urządzeniami (gdy to możliwe) i po odświeżeniu. To oznacza, że przypisanie musi być deterministyczne: dla tego samego klucza przypisania i eksperymentu wynik jest zawsze ten sam.
Typowe podejścia:
(experiment_id + assignment_key) i przypisz do wariantu.Wiele zespołów używa domyślnie przypisania opartego na hash, a zapisuje przypisania tylko wtedy, gdy jest to wymagane (wsparcie, governance).
Twoja aplikacja powinna wspierać wiele kluczy, bo ceny mogą być na poziomie użytkownika lub konta:
user_id po rejestracji.Ta ścieżka upgrade’u ma znaczenie: jeśli ktoś przegląda anonimowo, a potem tworzy konto, powinieneś zdecydować, czy zachować ich pierwotny wariant (ciągłość) czy ponownie przypisać (czystsze reguły tożsamości). Zrób to jasnym, eksplicytnym ustawieniem.
Wspieraj elastyczne alokacje:
Podczas rampowania utrzymuj przypisania sticky: zwiększanie ruchu powinno dodawać nowych użytkowników do eksperymentu, a nie przetasowywać istniejących.
Równoległe testy mogą kolidować. Zbuduj zabezpieczenia dla:
Ekran „Podgląd przypisania” (dla przykładowego użytkownika/konta) pomaga nietechnicznym zespołom zweryfikować reguły przed uruchomieniem.
Eksperymenty cenowe najczęściej zawodzą na warstwie integracji—nie dlatego, że logika eksperymentu jest zła, ale dlatego, że produkt pokazuje jedną cenę, a pobiera inną. Twoja aplikacja powinna sprawić, że „jaka jest cena” i „jak produkt jej używa” będą bardzo jawne.
Traktuj definicję ceny jako źródło prawdy (reguły wariantu, daty obowiązywania, waluta, obsługa podatków itp.). Traktuj dostarczenie ceny jako prosty mechanizm do pobrania ceny wybranego wariantu przez endpoint API lub SDK.
To rozdzielenie utrzymuje narzędzie eksperymentowe czyste: nietechniczne zespoły edytują definicje, a inżynierowie integrują stabilny kontrakt dostawy jak GET /pricing?sku=....
Są dwa typowe wzorce:
Praktyczne podejście: „wyświetlanie na kliencie, weryfikacja i obliczenia na serwerze”, przy użyciu tego samego przypisania eksperymentu.
Warianty muszą stosować te same zasady dla:
Przechowuj te reguły wraz z ceną, aby każdy wariant był porównywalny i zgodny z wymaganiami finansów.
Jeśli serwis eksperymentów jest wolny lub niedostępny, produkt powinien zwrócić bezpieczną domyślną cenę (zwykle obecny baseline). Zdefiniuj timeouty, cache’owanie i politykę „fail closed”, aby checkout nie przestał działać—i loguj fallbacky, abyś mógł zmierzyć ich wpływ.
Eksperymenty cenowe żyją lub umierają dzięki pomiarowi. Twoja aplikacja powinna utrudniać „wydanie i liczenie na szczęście” przez wymóg jasnych metryk sukcesu, czystych zdarzeń i spójnego podejścia do atrybucji zanim eksperyment zostanie uruchomiony.
Zacznij od jednej lub dwóch metryk, które posłużą do wyboru zwycięzcy. Typowe wybory:
Przydatna zasada: jeśli zespoły się spierają o wynik po teście, prawdopodobnie nie zdefiniowano metryki decyzyjnej wystarczająco jasno.
Guardrails wychwytują szkody, które wyższa cena może powodować, nawet jeśli krótkoterminowy przychód wygląda dobrze:
Twoja aplikacja może egzekwować guardrails przez wymaganie progów (np. „wzrost zwrotów nie może przekroczyć 0.3%”) i wyróżnianie przekroczeń na stronie eksperymentu.
Co najmniej twoje śledzenie musi zawierać stabilne identyfikatory eksperymentu i wariantu na każdym istotnym zdarzeniu.
{
"event": "purchase_completed",
"timestamp": "2025-01-15T12:34:56Z",
"user_id": "u_123",
"experiment_id": "exp_earlybird_2025_01",
"variant_id": "v_price_29",
"currency": "USD",
"amount": 29.00
}
Uczyń te właściwości wymaganymi przy ingestii, a nie „najlepszą próbą”. Jeśli zdarzenie przyjdzie bez experiment_id/variant_id, skieruj je do kubełka „unattributed” i oznacz problem jakości danych.
Wyniki cen często są opóźnione (odnowienia, upgrade’y, churn). Zdefiniuj:
To pomaga zespołom zgodzić się, kiedy wynik jest wiarygodny—i zapobiega przedwczesnym decyzjom.
Narzędzie do eksperymentów cenowych działa tylko wtedy, gdy PM, marketing i finanse mogą nim zarządzać bez angażowania inżyniera przy każdym kliknięciu. UI powinien szybko odpowiadać na trzy pytania: Co jest uruchomione? Co zmieni się dla klientów? Co się wydarzyło i dlaczego?
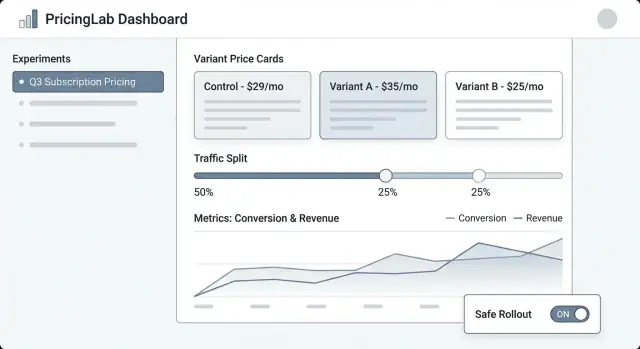
Lista eksperymentów powinna wyglądać jak dashboard operacyjny. Pokaż: nazwę, status (Draft/Scheduled/Running/Paused/Ended), start/end, podział ruchu, metrykę główną i właściciela. Dodaj widoczny „ostatnio zaktualizowane przez” i znacznik czasu, aby ludzie ufali temu, co widzą.
Szczegóły eksperymentu to centrum dowodzenia. Umieść kompaktowe podsumowanie na górze (status, daty, audytorium, podział, metryka główna). Poniżej użyj zakładek jak Variants, Targeting, Metrics, Change log i Results.
Edytor wariantu powinien być prosty i stanowczy. Każdy wiersz wariantu powinien zawierać cenę (lub regułę ceny), walutę, okres rozliczeniowy i opis po ludzku („Roczny plan: $120 → $108”). Utrudnij przypadkową edycję aktywnego wariantu, wymagając potwierdzenia.
Widok wyników powinien prowadzić od decyzji, nie tylko od wykresów: „Wariant B zwiększył konwersję checkoutu o 2.1% (95% CI …).” Następnie zapewnij szczegóły do drill-downów i filtrów.
Używaj spójnych odznak statusu i pokaż linię czasu kluczowych dat. Wyświetl podział ruchu jako procent i jako mały pasek. Dodaj panel „Kto co zmienił” (lub zakładkę) z listą edycji wariantów, targetowania i metryk.
Zanim pozwolisz na Start, wymagaj: co najmniej jednej metryki głównej, co najmniej dwóch wariantów z prawidłowymi cenami, zdefiniowanego planu rampy (opcjonalne, ale zalecane) i planu rollbacku lub ceny fallback. Jeśli czegoś brakuje, pokaż akcje do wykonania („Dodaj metrykę główną, aby włączyć wyniki”).
Zapewnij bezpieczne, widoczne akcje: Pause, Stop, Ramp up (np. 10% → 25% → 50%) i Duplicate (skopiuj ustawienia do nowego Draft). Dla ryzykownych akcji używaj potwierdzeń podsumowujących wpływ („Pauza zamraża przypisania i zatrzymuje ekspozycję”).
Jeśli chcesz zwalidować workflow (Draft → Scheduled → Running) zanim zainwestujesz w pełny build, platforma vibe-coding jak Koder.ai może pomóc szybko postawić wewnętrzną aplikację z konwersacji—potem iterować z ekranami z ograniczeniami ról, dziennikami audytu i prostymi dashboardami. To szczególnie przydatne dla wczesnych prototypów, gdy chcesz działające UI w React i backend Go/PostgreSQL, które później możesz wyeksportować i wzmocnić.
To wewnętrzny panel sterowania i warstwa śledzenia dla testów cenowych. Pomaga zespołom definiować eksperymenty (hipoteza, grupa docelowa, warianty), wyświetlać spójną cenę na różnych ekranach, zbierać zdarzenia gotowe do atrybucji oraz bezpiecznie uruchamiać/pauzować/zatrzymywać testy z pełnym audytem.
Celowo nie jest to pełny system rozliczeniowy ani silnik podatkowy; orkiestruje eksperymenty wokół istniejącego stosu cenowego/rozliczeniowego.
Praktyczne MVP powinno zawierać:
Jeśli te elementy działają solidnie, można rozszerzać celowanie i raportowanie później.
Modeluj kluczowe obiekty, które pozwolą odpowiedzieć na pytanie: „Jaką cenę zobaczył ten klient i kiedy?”. Zwykle najważniejsze są:
Unikaj nadpisywania historii: wersjonuj ceny i dodawaj nowe rekordy przypisań zamiast edytować istniejące.
Zdefiniuj cykl życia, np. Draft → Scheduled → Running → Stopped → Analyzed → Archived.
Zablokuj ryzykowne pola podczas Running (warianty, targetowanie, podział) i wymuszaj walidacje przed przejściem do kolejnych stanów (wybrane metryki, potwierdzone śledzenie, plan rollbacku). Zapobiega to edycjom w trakcie testu, które czynią wyniki niewiarygodnymi i powodują niespójności dla klientów.
Użyj sticky assignment, aby ten sam klient otrzymywał ten sam wariant między sesjami/urządzeniami, gdy to możliwe.
Typowe podejścia:
(experiment_id + assignment_key) i przypisz do kubełka wariantuWiele zespołów stosuje najpierw hashing, a zapisywanie przypisań tylko tam, gdzie potrzebne są nadzór lub wsparcie.
Wybierz klucz zgodny z doświadczeniem klienta:
Jeśli zaczynasz anonimowo, zdefiniuj jasne zasady „identity upgrade” przy rejestracji (zachować oryginalny wariant dla ciągłości vs przypisać ponownie dla czystości danych).
Traktuj „Stop” jako dwie oddzielne decyzje:
Uczyń wybór polityki obowiązkowym podczas zatrzymywania, aby zespół musiał świadomie uwzględnić wpływ na klientów.
Upewnij się, że ten sam wariant napędza zarówno wyświetlanie, jak i pobranie płatności:
Zdefiniuj bezpieczny fallback, jeśli serwis eksperymentów będzie wolny/ niedostępny (zwykle cena baseline) i loguj każdy fallback dla widoczności.
Wymagaj spójnego schematu zdarzeń, gdzie każde istotne zdarzenie zawiera experiment_id i variant_id.
Typowo śledzisz:
Jeśli zdarzenie przychodzi bez pól experiment/variant, kieruj je do kubełka „unattributed” i oznacz problem jakości danych.
Użyj prostego modelu ról i kompletnego dziennika audytu:
To zmniejsza ryzyko przypadkowych uruchomień i ułatwia przeglądy finansowe/compliance oraz retrospektywy.