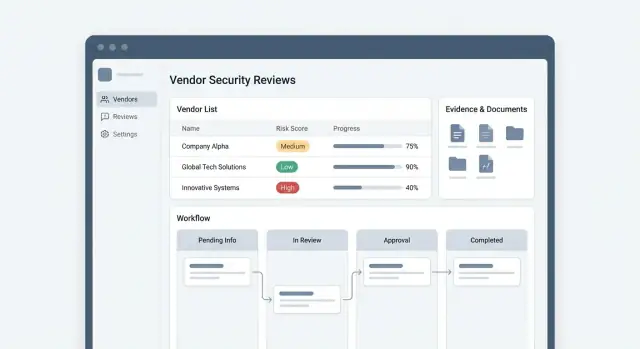
Cele, użytkownicy i zakres przeglądów bezpieczeństwa dostawców
Zanim zaprojektujesz ekrany czy wybierzesz bazę danych, ustal, co aplikacja ma osiągnąć i dla kogo jest przeznaczona. Zarządzanie przeglądami bezpieczeństwa dostawców najczęściej zawodzi, gdy różne zespoły używają tych samych słów („przegląd”, „zatwierdzenie”, „ryzyko”), mając na myśli różne rzeczy.
Kto będzie korzystał z aplikacji
W większości programów wyróżnisz co najmniej cztery grupy użytkowników, każda z innymi potrzebami:
- Security / GRC: odpowiada za proces przeglądu, pytania, wymagania dowodowe i końcową decyzję o ryzyku.
- Procurement / Zarządzanie dostawcami: potrzebuje szybkiego intake, jasnego statusu i widoczności odnowień, żeby zakupy nie blokowały się na ostatnią chwilę.
- Legal / Prywatność: koncentruje się na warunkach przetwarzania danych, DPA/SCCs, powiadamianiu o naruszeniach i miejscu przechowywania danych.
- Kontakty po stronie dostawcy: oczekują prostego portalu do jednokrotnego wypełnienia pytań, przesłania dowodów i odpowiadania na uzupełnienia bez długich wątków e-mail.
Implikacja projektowa: nie budujesz „jednego workflowu”. Budujesz wspólny system, w którym każda rola widzi wyselekcjonowany widok tego samego przeglądu.
Co oznacza „przegląd bezpieczeństwa dostawcy” w twojej firmie
Zdefiniuj granice procesu prostym językiem. Na przykład:
- Czy przegląd obejmuje tylko narzędzia SaaS, czy także konsultantów, agencje i dostawców hostingu?
- Czy celem jest potwierdzenie podstawowych kontroli, czy skwantyfikowanie ryzyka i zatwierdzanie wyjątków?
- Czy oceniasz dostawcę (firma jako całość), czy usługę (konkretny produkt i sposób waszego użycia)?
Zapisz, co wyzwala przegląd (nowy zakup, odnowienie, istotna zmiana, nowy typ danych) oraz co oznacza „zrobione” (zatwierdzone, zatwierdzone z warunkami, odrzucone lub odroczone).
Bieżące bolączki do usunięcia
Urealnij zakres, wypisując, co dziś boli:
- Statusy uwięzione w wątkach e-mail i prywatnych skrzynkach
- Arkusze kalkulacyjne, które się rozjeżdżają i nie mają pojedynczego źródła prawdy
- Brakujące lub przeterminowane dowody (SOC 2, ISO, pen test) i brak śledzenia dat wygaśnięcia
- Niejasne przekazania między Security, Procurement i Legal
- Brak spójnego sposobu rejestrowania decyzji, wyjątków czy kompensujących kontroli
Te punkty stają się backlogiem wymagań.
Mierniki sukcesu, które trzymają projekt w ryzach
Wybierz kilka metryk, które możesz mierzyć od pierwszego dnia:
- Czas cyklu (intake → decyzja) według poziomu krytyczności dostawcy
- Wskaźnik ukończeń na czas względem SLA
- Liczba przeglądów przeterminowanych i średnia liczba dni po terminie
- Wskaźnik poprawek (przeglądy odsyłane do dostawców z brakami)
Jeśli aplikacja nie potrafi ich wiarygodnie raportować, to nie zarządza programem — tylko przechowuje dokumenty.
Projekt workflowu: od zgłoszenia do zatwierdzenia
Jasny workflow to różnica między „ping-pongiem e-mailowym” a przewidywalnym programem przeglądów. Zanim zbudujesz ekrany, odwzoruj ścieżkę end-to-end i zdecyduj, co musi się wydarzyć na każdym kroku, by dojść do zatwierdzenia.
Mapuj przepływ end-to-end
Zacznij od prostego, liniowego szkieletu, który możesz później rozszerzyć:
Intake → Triage → Kwestionariusz → Zbieranie dowodów → Ocena bezpieczeństwa → Zatwierdzenie (lub odrzucenie).
Dla każdego etapu zdefiniuj, co oznacza „zrobione”. Na przykład „Kwestionariusz zakończony” może wymagać 100% wymaganych pytań i przypisanego właściciela bezpieczeństwa. „Dowody zebrane” mogą wymagać minimalnego zestawu dokumentów (raport SOC 2, podsumowanie pen testu, diagram przepływu danych) lub uzasadnionego wyjątku.
Zdefiniuj punkty wejścia (jak zaczynają się przeglądy)
Większość aplikacji potrzebuje co najmniej trzech sposobów tworzenia przeglądu:
- Nowe zgłoszenie dostawcy: inicjowane przez Procurement, IT lub właściciela biznesowego
- Odnowienie: tworzone automatycznie na podstawie daty wygaśnięcia przeglądu
- Przegląd wywołany incydentem: uruchamiany przy naruszeniu dostawcy lub istotnej zmianie
Traktuj je jako różne szablony: mogą dzielić ten sam workflow, ale mieć inne domyślne priorytety, wymagane kwestionariusze i terminy.
Statusy, SLA i właścicielstwo
Uczyń statusy jawne i mierzalne — szczególnie stany „oczekujące”. Powszechne to Waiting on vendor, In security review, Waiting on internal approver, Approved, Approved with exceptions, Rejected.
Przypinaj SLA do właściciela statusu (dostawca vs zespół wewnętrzny). Dzięki temu dashboard pokaże „zablokowane przez dostawcę” osobno od „wewnętrznego backlogu”, co zmienia sposób przydziału zasobów i eskalacji.
Automatyzacja vs ocena ludzka
Automatyzuj kierowanie, przypomnienia i tworzenie odnowień. Zachowaj punkty decyzyjne dla ludzi przy akceptacji ryzyka, kontrolach kompensujących i zatwierdzeniach.
Przydatna zasada: jeśli krok wymaga kontekstu lub kompromisów, zapisz rekord decyzji zamiast próbować go automatycznie rozstrzygać.
Podstawowy model danych: Dostawcy, Przeglądy, Kwestionariusze, Dowody
Czysty model danych pozwala aplikacji skalować się z „pojedynczego kwestionariusza” do powtarzalnego programu z odnowieniami, metrykami i spójnymi decyzjami. Traktuj dostawcę jako rekord długoterminowy, a wszystko inne jako związane z nim aktywności o określonym czasie.
Vendor (trwały profil)
Zacznij od encji Vendor, która zmienia się powoli i jest referencją w całym systemie. Przydatne pola to:
- Właściciel biznesowy (wewnętrzny sponsor), dział i główne kontakty
- Krytyczność / tier (np. niski/średni/wysoki) i status „w produkcji”
- Typy danych, które obsługują (PII, dane płatnicze, dane medyczne, kod źródłowy itp.)
- Systemy / integracje, do których mają dostęp (SSO, hurtownia danych, narzędzia wsparcia)
- Podstawy kontraktu (daty rozpoczęcia/końca), żeby później automatyzować odnowienia
Modeluj typy danych i systemy jako wartości strukturalne (tabele lub enuma), a nie wolny tekst, aby raportowanie było dokładne.
Review (ocena w danym punkcie czasu)
Każdy Review to snapshot: kiedy się rozpoczął, kto go zażądał, zakres, tier w czasie, daty SLA i ostateczna decyzja (zatwierdzone/ zatwierdzone z warunkami/ odrzucone). Przechowuj uzasadnienie decyzji i powiązania do wszelkich wyjątków.
Kwestionariusz (szablony i odpowiedzi)
Oddziel QuestionnaireTemplate od QuestionnaireResponse. Szablony powinny wspierać sekcje, pytania wielokrotnego użytku i logikę warunkową (pytania zależne od wcześniejszych odpowiedzi).
Dla każdego pytania określ, czy dowód jest wymagany, dozwolone typy odpowiedzi (tak/nie, wielokrotny wybór, przesyłanie pliku) i reguły walidacji.
Dowody i artefakty
Traktuj uploady i linki jako rekordy Evidence powiązane z przeglądem i opcjonalnie z konkretnym pytaniem. Dodaj metadane: typ, znacznik czasu, kto dostarczył i reguły retencji.
Na koniec przechowuj artefakty przeglądu — notatki, ustalenia, zadania naprawcze i zatwierdzenia — jako encje pierwszej klasy. Pełna historia przeglądu ułatwia odnowienia, śledzenie trendów i szybsze kolejne przeglądy bez ponownego zadawania wszystkich pytań.
Role, uprawnienia i dostęp dostawcy
Jasne role i restrykcyjne uprawnienia sprawiają, że aplikacja do przeglądów pozostaje użyteczna, nie zamieniając się w ryzyko wycieku danych. Zaprojektuj to wcześnie, bo uprawnienia wpływają na workflow, UI, powiadomienia i ścieżkę audytu.
Podstawowe role do zamodelowania
Większość zespołów potrzebuje pięciu ról:
- Requester: inicjuje przegląd (często Procurement, IT lub właściciel biznesowy), śledzi status i odpowiada na pytania kontekstowe (jakie dane dotyka dostawca, cel, wartość kontraktu).
- Reviewer: prowadzi ocenę, żąda dowodów, doprecyzowuje odpowiedzi i proponuje decyzję.
- Approver: formalnie akceptuje wynik ryzyka (zatwierdź, zatwierdź z warunkami, odrzuć), zazwyczaj lider Security, Legal lub Risk.
- Vendor respondent: wypełnia kwestionariusze i przesyła dowody.
- Admin: zarządza szablonami, integracjami, przypisaniami ról i ustawieniami globalnymi.
Oddziel role od „osób”. Ta sama osoba może być requesterem w jednym przeglądzie i reviewerem w innym.
Uprawnienia do wrażliwych dowodów
Nie wszystkie artefakty przeglądu powinny być widoczne dla każdego. Traktuj elementy takie jak raporty SOC 2, wyniki pentestów, polityki bezpieczeństwa i kontrakty jako ograniczone dowody.
Praktyczne podejście:
- Oddziel metadane przeglądu (nazwa dostawcy, status, data odnowienia) od ograniczonych załączników.
- Dodaj flagę widoczności na poziomie dowodu (np. „Wszyscy użytkownicy wewnętrzni”, „Tylko zespół przeglądowy”, „Tylko Legal + Security”).
- Loguj każdy dostęp do ograniczonych plików (wyświetlenie/pobranie) dla rozliczalności.
Bezpieczny dostęp dla dostawcy (i izolacja)
Dostawcy powinni widzieć tylko to, co potrzebne:
- Ogranicz konta dostawców do ich organizacji i ich zgłoszeń.
- Zapewnij dedykowany widok portalu: przypisane kwestionariusze, żądania uploadu i komunikacja — nic więcej.
- Wyłącz wyszukiwanie między dostawcami i domyślnie ukrywaj komentarze wewnętrzne.
Delegacja, backupy i ciągłość
Przeglądy zatrzymują się, gdy kluczowa osoba jest nieobecna. Wspieraj:
- Delegatów (tymczasowe pokrycie z tymi samymi uprawnieniami)
- Backupy zatwierdzające (drugorzędni zatwierdzający po przekroczeniu progu SLA)
- Jasną akcję „przypisz ponownie” z obowiązkowym powodem, zapisaną w logu audytu
To utrzymuje przepływ pracy bez naruszania zasady najmniejszych uprawnień.
Program przeglądów może wydawać się powolny, gdy każde zgłoszenie zaczyna się od długiego kwestionariusza. Rozwiązanie to oddzielić intake (szybkie, lekkie) od triage (wybór właściwej ścieżki).
Wybierz kilka kanałów intake (i zachowaj spójność)
Większość zespołów potrzebuje trzech punktów wejścia:
- Formularz wewnętrzny dla pracowników (Procurement, Legal, Engineering) do inicjowania przeglądu
- Zgłoszenie procurementowe (np. Jira/Service Desk), które może automatycznie stworzyć rekord przeglądu
- API intake dla narzędzi, które już wiedzą o wdrożeniu nowego dostawcy
Niezależnie od kanału, normalizuj zgłoszenia do tej samej kolejki „New Intake”, aby nie tworzyć równoległych procesów.
Zbieraj minimum na starcie
Formularz intake powinien być krótki, żeby ludzie nie zgadywali. Celuj w pola umożliwiające kierowanie i priorytetyzację:
- Nazwa dostawcy i strona internetowa
- Właściciel biznesowy (wnioskodawca) i dział
- Co będzie robił dostawca (kategoria/przypadek użycia)
- Typy danych zaangażowane (PII, dane płatnicze, medyczne, brak)
- Poziom dostępu (dostęp do produkcji, tylko wewnętrzny, brak dostępu)
- Data uruchomienia / termin zakupu
Odraczaj dogłębne pytania bezpieczeństwa, dopóki nie ustalisz poziomu przeglądu.
Dodaj reguły triage, które tworzą jasne ścieżki
Użyj prostych reguł decyzyjnych do klasyfikacji ryzyka i pilności. Na przykład oznacz wysoki priorytet, jeśli dostawca:
- Przetwarza PII lub dane płatnicze
- Ma dostęp do produkcji lub uprzywilejowane integracje
- Jest krytyczny dla operacji (fakturowanie, uwierzytelnianie, infrastruktura core)
Automatycznie kieruj do właściwej kolejki i zatwierdzającego
Po triage automatycznie przypisz:
- Odpowiedni szablon przeglądu (lite vs pełny)
- Właściwą kolejkę (np. Security, Privacy, Compliance)
- Zatwierdzającego na podstawie typu danych, regionu lub jednostki biznesowej
To utrzymuje SLA przewidywalne i zapobiega „zagubionym” przeglądom w czyjejś skrzynce.
UX kwestionariuszy i zbierania dowodów
Zbuduj szybko swój workflow przeglądów
Przekształć proces od zgłoszenia do akceptacji w działającą aplikację poprzez rozmowę z Koder.ai.
UX kwestionariuszy i dowodów to miejsce, gdzie przeglądy albo idą szybko, albo stoją w miejscu. Cel: przepływ przewidywalny dla recenzentów i naprawdę prosty dla dostawców.
Zacznij od wielokrotnego użytku szablonów według poziomu ryzyka
Stwórz małą bibliotekę szablonów przypisanych do poziomów ryzyka (niski/średni/wysoki). Cel to spójność: ten sam typ dostawcy powinien widzieć te same pytania za każdym razem, a recenzenci nie powinni budować formularzy od zera.
Utrzymuj szablony modułowo:
- Krótki zestaw „baseline” (informacje o firmie, przetwarzaniu danych, kontrolach dostępu)
- Sekcje dodatkowe dla wyższych poziomów ryzyka (incydent response, SDLC, pentesty, podwykonawcy)
Gdy tworzysz przegląd, pre-selektuj szablon według tieru i pokaż dostawcy wskaźnik postępu (np. 42 pytania, ~20 minut).
Uczyń przesyłanie dowodów elastycznym (uploady + linki)
Dostawcy często już mają artefakty jak raporty SOC 2, certyfikaty ISO, polityki i podsumowania skanów. Wspieraj zarówno przesyłanie plików, jak i bezpieczne linki, żeby mogli dostarczyć to, co mają, bez tarcia.
Dla każdego żądania opisz prosto („Prześlij raport SOC 2 Type II (PDF) lub udostępnij link czasowy”) i dodaj krótką wskazówkę „jak powinno to wyglądać”.
Śledź aktualność i automatyzuj przypomnienia
Dowody nie są statyczne. Przechowuj metadane przy każdym artefakcie — datę wydania, datę wygaśnięcia, okres pokrycia i (opcjonalnie) notatki recenzenta. Użyj tych danych do wyzwalania przypomnień odnowieniowych (dla dostawcy i wewnętrznie), aby kolejne roczne przeglądy były szybsze.
Bądź przyjazny dla dostawcy: wskazówki i terminy
Każda strona dostawcy powinna od razu odpowiadać na trzy pytania: co jest wymagane, kiedy jest termin i kto kontakt. Podawaj jasne terminy dla każdego żądania, pozwól na częściowe przesyłanie i potwierdzaj odbiór prostym statusem („Submitted”, „Needs clarification”, „Accepted”). Jeśli wspierasz dostęp dostawcy, prowadź go bezpośrednio do checklisty, zamiast do ogólnych instrukcji.
Ocena ryzyka, wyjątki i rejestrowanie decyzji
Przegląd nie kończy się na „kompletnym” kwestionariuszu. Potrzebujesz powtarzalnego sposobu przetłumaczenia odpowiedzi i dowodów na decyzję, której ufają interesariusze i którą mogą zweryfikować audytorzy.
Podejście do punktacji, które pozostaje zrozumiałe
Zacznij od tieringu na podstawie wpływu (np. czułość danych + krytyczność systemu). Tier wyznacza poprzeczkę: procesor płac i dostawca przekąsek nie powinny być oceniani tak samo.
Następnie punktuj w ramach tieru za pomocą ważonych kontroli (szyfrowanie, kontrola dostępu, IR, pokrycie SOC 2 itp.). Trzymaj wagi widoczne, żeby recenzenci mogli wytłumaczyć wyniki.
Dodaj czerwone flagi, które mogą nadpisać wynik liczbowy — np. „brak MFA dla kont administratorów”, „znane naruszenie bez planu remediacji” czy „brak wsparcia dla usuwania danych”. Czerwone flagi powinny być jawne i oparte na regułach, nie na intuicji recenzenta.
Wyjątki bez utraty kontroli
Rzeczywistość wymaga wyjątków. Modeluj je jako encje pierwszej klasy z:
- Typem: kontrola kompensująca, dostęp o ograniczonym zakresie, tymczasowe zatwierdzenie
- Właścicielem: kto akceptuje ryzyko
- Wygaśnięciem: z datą i przypomnieniami odnowienia
- Warunkami: wymagane zmiany (np. włączenie SSO w ciągu 60 dni)
To pozwala zespołom iść dalej, jednocześnie stopniowo zaostrzając kontrolę.
Rejestruj decyzje i wymagane działania
Każdy wynik (Approve / Approve with conditions / Reject) powinien zawierać uzasadnienie, powiązane dowody i zadania follow-up z terminami. To zapobiega „wiedzy plemiennej” i przyspiesza odnowienia.
Proste podsumowanie ryzyka dla interesariuszy
Udostępnij jedną stronę „risk summary”: tier, wynik, czerwone flagi, status wyjątków, decyzja i następne kamienie milowe. Zachowaj czytelność dla Procurement i kierownictwa — szczegóły dostępne jednym kliknięciem głębiej w pełnym rekordzie przeglądu.
Współpraca, zatwierdzenia i ścieżka audytu
Widoki oparte na rolach dla każdego zespołu
Wygeneruj widoki oparte na rolach dla Security, Procurement, Legal i dostawców w jednym projekcie.
Przeglądy stoją, gdy feedback rozsiany jest po e-mailach i notatkach. Twoja aplikacja powinna uczynić współpracę domyślną: jeden wspólny rekord przeglądu, jasne właścicielstwo, decyzje i znaczniki czasowe.
Komentarze, @wzmianki i notatki
Wspieraj wątkowane komentarze na poziomie przeglądu, pojedynczych pytań i elementów dowodów. Dodaj @wzmianki, aby skierować pracę do właściwych osób (Security, Legal, Procurement, Engineering) i stworzyć lekki strumień powiadomień.
Podziel notatki na dwa typy:
- Notatki wewnętrzne (tylko twoja organizacja): triage, uzasadnienia ryzyka, punkty negocjacyjne i przypomnienia.
- Notatki widoczne dla dostawcy: wyjaśnienia i prośby, na które dostawca może odpowiedzieć.
Ten podział zapobiega przypadkowemu nadmiernemu udostępnianiu, a jednocześnie utrzymuje responsywność dostawcy.
Zatwierdzenia, w tym warunkowe
Modeluj zatwierdzenia jako jawne podpisy, a nie status, który ktoś może dowolnie edytować. Dobry wzorzec to:
- Approve
- Reject
- Approve with conditions (plan remediacji)
Dla zatwierdzenia warunkowego zapisz: wymagane działania, terminy, kto weryfikuje i jakie dowody zamkną warunek. To pozwala biznesowi iść dalej, a jednocześnie mierzyć pracę ograniczającą ryzyko.
Zadania, właściciele i opcjonalna synchronizacja z ticketami
Każde żądanie powinno stać się zadaniem z właścicielem i datą wykonania: „Przejrzyj SOC 2”, „Potwierdź klauzulę retencji danych”, „Zweryfikuj ustawienia SSO”. Zadania przypisuj wewnętrznym użytkownikom i, gdzie to sensowne, dostawcom.
Opcjonalnie synchronizuj zadania z narzędziami ticketowymi jak Jira, aby dopasować istniejące workflowy — przy zachowaniu przeglądu jako systemu źródłowego prawdy.
Pełna ścieżka audytu
Utrzymuj niemodyfikowalny audit trail dla: edycji kwestionariusza, uploadów/usunięć dowodów, zmian statusu, zatwierdzeń i zamknięć warunków.
Każdy wpis powinien zawierać kto to zrobił, kiedy, co się zmieniło (przed/po) i powód gdy istotny. Dobrze zrobione wspiera audyty, redukuje przeróbki przy odnowieniach i wzmacnia wiarygodność raportowania.
Integracje: SSO, ticketing, komunikacja i storage
Integracje decydują, czy aplikacja do przeglądów będzie „jeszcze jednym narzędziem”, czy naturalnym rozszerzeniem pracy. Cel: minimalizować duplikację danych, utrzymywać ludzi w systemach, które już sprawdzają, i zapewnić, że dowody i decyzje łatwo znaleźć później.
SSO dla użytkowników wewnętrznych (i prosty dostęp dla dostawców)
Dla recenzentów wewnętrznych wspieraj SSO przez SAML lub OIDC, aby dostęp zsynchronizował się z twoim IdP (Okta, Azure AD, Google Workspace). Ułatwia to onboarding/offboarding i umożliwia mapowanie ról przez grupy (np. „Security Reviewers” vs „Approvers”).
Dostawcy zazwyczaj nie potrzebują pełnych kont. Popularny wzorzec to czasowe magic linki ograniczone do konkretnego kwestionariusza lub żądania dowodu. Sparuj to z opcjonalną weryfikacją e-mail i jasnymi zasadami wygaśnięcia, aby zredukować tarcie przy jednoczesnym kontrolowaniu dostępu.
Gdy przegląd generuje wymagane poprawki, zespoły często śledzą je w Jira lub ServiceNow. Integruj, aby recenzenci mogli tworzyć ticket remediacyjny bezpośrednio z ustalenia, wstępnie wypełniony o:
- nazwę dostawcy i ID przeglądu
- dotknięty system/produkt
- wymaganą kontrolę i termin
- priorytet i sugerowane kryteria akceptacji
Synchronizuj status ticketu (Open/In Progress/Done) z aplikacją, aby właściciele przeglądu widzieli postęp bez ganiania za aktualizacjami.
Komunikacja: Slack/Teams dla terminów i zatwierdzeń
Dodaj lekkie powiadomienia tam, gdzie ludzie już pracują:
- nadchodzące terminy kwestionariuszy i uploadów dowodów
- prośby o zatwierdzenie z jednoklikowymi linkami do przeglądu
- przypomnienia przy zbliżającym się naruszeniu SLA
Utrzymuj wiadomości zwięzłe i akcjonalne, pozwól użytkownikom konfigurować częstotliwość, by uniknąć zmęczenia powiadomieniami.
Przechowywanie dokumentów (z kontrolą dostępu)
Dowody często mieszkają w Google Drive, SharePoint lub S3. Integruj, przechowując referencje i metadane (ID pliku, wersja, uploader, znacznik czasu) i egzekwuj zasadę najmniejszych uprawnień.
Unikaj niepotrzebnego kopiowania wrażliwych plików; gdy przechowujesz, stosuj szyfrowanie, reguły retencji i restrykcyjne uprawnienia per-przegląd.
Praktyczne podejście: linki do dowodów żyją w aplikacji, dostęp rządzi się przez IdP, a pobrania są logowane dla audytu.
Wymagania bezpieczeństwa i prywatności dla aplikacji webowej
Narzędzie do przeglądów szybko staje się repozytorium wrażliwych materiałów: raporty SOC, podsumowania pen testów, diagramy architektury, kwestionariusze i czasem dane osobowe (imiona, e-maile, numery). Traktuj je jak wysokowartościowy system wewnętrzny.
Chroń uploady dowodów
Dowody to największa powierzchnia ataku, bo akceptują nieufne pliki.
Ustaw jasne ograniczenia: listę dozwolonych typów plików, limity rozmiaru i timeouty dla wolnych uploadów. Skanuj każdy plik pod kątem malware przed udostępnieniem recenzentom i poddaj kwarantannie wszystko podejrzane.
Przechowuj pliki szyfrowane w spoczynku (najlepiej z per-tenant keys, jeśli obsługujesz wiele jednostek). Używaj krótkotrwałych, podpisanych linków do pobrania i unikaj ujawniania bezpośrednich ścieżek do storage.
Stosuj bezpieczne domy wszędzie
Bezpieczeństwo powinno być domyślne, nie opcjonalne.
Stosuj zasadę najmniejszych uprawnień: nowi użytkownicy zaczynają z minimalnym dostępem, a konta dostawców widzą tylko swoje zgłoszenia. Chroń formularze i sesje przed CSRF, używaj bezpiecznych ciasteczek i restrykcyjnego wygaśnięcia sesji.
Dodaj rate limiting i mechanizmy anti-abuse dla logowań, endpointów uploadu i eksportów. Waliduj i sanityzuj wszystkie wejścia, szczególnie pola tekstowe renderowane w UI.
Logowanie i audyt dla wrażliwych akcji
Loguj dostęp do dowodów i kluczowe zdarzenia workflow: podgląd/pobranie plików, eksporty raportów, zmiany ocen ryzyka, zatwierdzenia wyjątków i modyfikacje uprawnień.
Uczyń logi odporne na manipulację (append-only) i przeszukiwalne według dostawcy, przeglądu i użytkownika. Dodaj UI ścieżki audytu, aby osoby nietechniczne mogły odpowiedzieć na pytanie „kto co widział i kiedy?” bez kopania w surowych logach.
Retencja, usuwanie i blokady prawne
Zdefiniuj, jak długo przechowujesz kwestionariusze i dowody, i wymuś to technicznie.
Wspieraj polityki retencji według dostawcy/typu przeglądu, workflowy usuwania obejmujące pliki i generowane eksporty oraz flagi „legal hold”, które blokują usuwanie. Udokumentuj te zachowania w ustawieniach produktu i procedurach wewnętrznych, a usunięcia weryfikuj (np. potwierdzenia usunięcia i wpisy w audycie).
Raportowanie, dashboardy i zarządzanie odnowieniami
Testuj zmiany ze snapshotami
Używaj snapshotów i rollbacku, by testować zmiany bez przerywania aktywnych przeglądów.
Raportowanie to moment, gdy program przeglądów staje się zarządzalny: przestajesz gonić aktualizacje w e-mailach i zaczynasz sterować pracą dzięki wspólnej widoczności. Celuj w dashboardy odpowiadające na „co się teraz dzieje?” oraz eksporty satysfakcjonujące audytorów bez ręcznej pracy w arkuszach.
Dashboardy, które prowokują działanie
Przydatny dashboard startowy mniej koncentruje się na wykresach, a bardziej na kolejkach. Zawieraj:
- Pipeline przeglądów według statusu (Intake, In Progress, Waiting on Vendor, Waiting on Approver, Approved/Rejected)
- Pozycje przeterminowane (kwestionariusze, żądania dowodów, zatwierdzenia) z jasnymi właścicielami i terminami
- Dostawcy wysokiego ryzyka i „wysoki ryzyko + zablokowane” wymagające eskalacji
Uczyń filtry elementem pierwszorzędnym: jednostka biznesowa, krytyczność, recenzent, właściciel procurement, miesiąc odnowienia i powiązane tickety.
Dla Procurement i właścicieli biznesowych zapewnij prostszy widok „moich dostawców”: na co czekają, co jest zablokowane i co jest zatwierdzone.
Eksport gotowy na audyt
Audytorzy zwykle chcą dowodów, nie streszczeń. Eksport powinien pokazywać:
- Kto zatwierdził co, kiedy i dlaczego (decyzja, wynik ryzyka w czasie, tekst wyjątku)
- Jakie dowody były przeglądane (nazwa pliku/link, wersja, znaczniki czasu)
- Pełną ścieżkę audytu kluczowych zdarzeń (wysłano, zażądano zmian, ponownie otwarto)
Wspieraj eksporty CSV i PDF oraz możliwość eksportu paczki przeglądów pojedynczego dostawcy za dany okres.
Kalendarz odnowień i przypomnienia
Traktuj odnowienia jako funkcję produktu, nie arkusz kalkulacyjny.
Śledź daty wygaśnięcia dowodów (np. raporty SOC 2, pen testy, ubezpieczenia) i stwórz kalendarz odnowień z automatycznymi przypomnieniami: najpierw do dostawcy, potem do właściciela wewnętrznego, następnie eskalacja. Gdy dowód zostanie odnowiony, zachowaj starą wersję dla historii i automatycznie zaktualizuj datę następnej odnowy.
Plan wdrożenia, zakres MVP i mapa iteracji
Wypuszczenie aplikacji do przeglądów to mniej budowanie wszystkiego naraz, a więcej uruchomienia jednego workflowu end-to-end, a potem dopracowywania go w oparciu o rzeczywiste użycie.
Zakres MVP (co wypuścić najpierw)
Zacznij od cienkiego, niezawodnego przepływu, który zastępuje arkusze i wątki e-mail:
- Intake: pojedynczy formularz zgłoszeniowy (nazwa dostawcy, usługa, typy danych, właściciel biznesowy, planowana data uruchomienia)
- Kwestionariusz: wyślij standardowy kwestionariusz i śledź status (wysłane, w toku, przesłane)
- Upload dowodów: podstawowy obszar dowodów na przegląd (SOC 2, pen test, polityki) z datami wygaśnięcia
- Decyzja: rejestruj wynik (zatwierdź/z warunkami/odrzuć), kluczowe ryzyka i wymagane działania
Uczyń MVP stanowczym: jeden domyślny kwestionariusz, jedna ocena ryzyka i prosty timer SLA. Zaawansowane reguły routingu mogą poczekać.
Jeśli chcesz przyspieszyć dostawę, platforma typu "vibe-coding" jak Koder.ai może być praktycznym wyborem dla takiego wewnętrznego systemu: pozwala iterować nad intake, widokami ról i stanami workflowu przez chat-driven implementację, a potem wyeksportować kod źródłowy, gdy chcesz przenieść projekt w pełni do siebie. To szczególnie przydatne, gdy MVP i tak potrzebuje podstawowych elementów (SSO, audit trail, obsługa plików, dashboardy) bez miesięcznego cyklu budowy.
Najpierw pilot, potem ekspansja
Przeprowadź pilota z jednym zespołem (np. IT, Procurement lub Security) przez 2–4 tygodnie. Wybierz 10–20 aktywnych przeglądów i zmigruj tylko niezbędne dane (nazwa dostawcy, bieżący status, ostateczna decyzja). Mierz:
- czas od intake do decyzji
- % przeglądów z brakami dowodów w momencie decyzji
- miejsca, w których recenzent i dostawca „utknęli” (gdzie porzucają proces)
Iteruj co tydzień (małe wydania, widoczne wins)
Przyjmij cotygodniowy rytm z krótką pętlą sprzężenia zwrotnego:
- 15-minutowy check-in z pilotowymi użytkownikami
- jedna poprawka redukująca tarcie (tekst szablonu, mniej pól, jaśniejsze instrukcje dla dostawcy)
- jedna poprawka redukująca ryzyko (wymagane pola dla notatek decyzji, przypomnienia o wygaśnięciu dowodów)
Dokumentacja, która zapobiega zgłoszeniom do wsparcia
Napisz dwa proste przewodniki:
- Poradnik administratora: jak edytować kwestionariusze, zarządzać użytkownikami i zamykać przeglądy.
- Poradnik dostawcy: jak odpowiadać na pytania, przesyłać dowody i co oznacza „zatwierdzone z warunkami”.
Roadmapa: co dodać po MVP
Plan faz po MVP: reguły automatyzacji (routing według typu danych), pełniejszy portal dostawcy, API i integracje. Jeśli cena lub model licencyjny wpływa na adopcję (liczba miejsc, liczba dostawców, storage), od razu skonsultuj interesariuszy z informacjami o /pricing.