03 wrz 2025·8 min
Jak zbudować aplikację webową do zarządzania uprawnieniami w wielu produktach
Naucz się projektować i budować aplikację webową centralizującą role, grupy i uprawnienia w wielu produktach — z audytem, SSO i bezpiecznym rolloutem.
Naucz się projektować i budować aplikację webową centralizującą role, grupy i uprawnienia w wielu produktach — z audytem, SSO i bezpiecznym rolloutem.
Kiedy ludzie mówią, że muszą zarządzać uprawnieniami w „wielu produktach”, zwykle mają na myśli jedno z trzech:
We wszystkich przypadkach problem jest podobny: decyzje o dostępie zapadają w zbyt wielu miejscach, z wieloma sprzecznymi definicjami ról jak „Admin”, „Manager” czy „Read‑only”.
Zespoły zwykle odczuwają skutki zanim potrafią je jasno nazwać.
Niespójne role i polityki. W jednym produkcie „Editor” może usuwać rekordy; w innym nie. Użytkownicy proszą o dostęp na wyrost, bo nie wiedzą, czego będą potrzebować.
Ręczne provisionowanie i deprovisionowanie. Zmiany dostępu dzieją się przez ad‑hoc wiadomości w Slacku, arkusze kalkulacyjne lub kolejki ticketów. Offboarding jest szczególnie ryzykowny: użytkownik traci dostęp w jednym narzędziu, a w innym nadal go ma.
Niejasne właścicielstwo. Nikt nie wie, kto może zatwierdzić dostęp, kto powinien go przeglądać i kto ponosi odpowiedzialność, gdy błąd w uprawnieniu powoduje incydent.
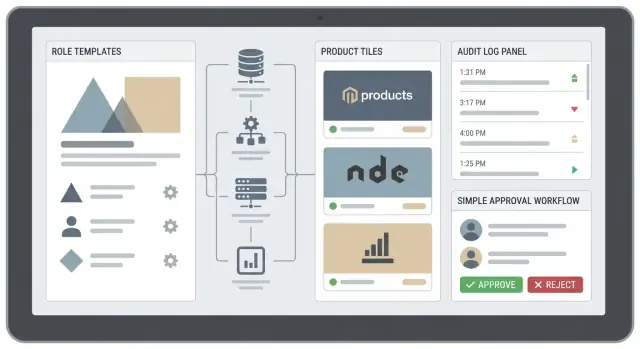
Dobra aplikacja do zarządzania uprawnieniami to nie tylko panel kontrolny — to system tworzący jasność.
Centralna administracja ze spójnymi definicjami. Role są zrozumiałe, wielokrotnego użytku i mapują się między produktami (albo przynajmniej wyraźnie pokazują różnice).
Samoobsługa z zabezpieczeniami. Użytkownicy mogą prosić o dostęp bez szukania właściwej osoby, a jednocześnie wrażliwe uprawnienia wymagają zatwierdzeń.
Przepływy zatwierdzania i odpowiedzialność. Każda zmiana ma właściciela: kto jej żądał, kto zatwierdził i dlaczego.
Audytowalność domyślnie. Możesz odpowiedzieć „kto miał dostęp do czego i kiedy?” bez sklejenia logów z pięciu systemów.
Śledź wyniki powiązane z szybkością i bezpieczeństwem:
Jeśli potrafisz robić zmiany dostępu szybciej i bardziej przewidywalnie, idziesz w dobrym kierunku.
Zanim zaprojektujesz role lub wybierzesz stack technologiczny, ustal, co aplikacja do zarządzania uprawnieniami musi obejmować od pierwszego dnia — i co wyklucza. Wąski zakres zapobiega budowaniu wszystkiego od nowa w połowie pracy.
Zacznij od krótkiej listy (zwykle 1–3 produkty) i zapisz, jak każdy z nich wyraża obecnie dostęp:
is_admin?Jeśli dwa produkty mają zasadniczo różne modele, zanotuj to wcześnie — może być potrzebna warstwa translacji zamiast natychmiastowego wymuszania jednego kształtu.
System uprawnień musi obsłużyć więcej niż „użytkowników końcowych”. Zdefiniuj przynajmniej:
Uchwyć przypadki brzegowe: kontrahenci, konta współdzielone, użytkownicy należący do wielu organizacji.
Wypisz akcje ważne dla biznesu i użytkowników. Typowe kategorie:
Formułuj je jako czasowniki powiązane z obiektami (np. „edytuj ustawienia workspace’u”), nie jako niejasne etykiety.
Wyjaśnij, skąd pochodzą tożsamości i atrybuty:
Dla każdego źródła zdecyduj, co twoja aplikacja uprawnień będzie posiadać jako źródło prawdy, a co będzie mirrorować, oraz jak rozwiązywać konflikty.
Pierwsza duża decyzja to gdzie „mieszka” autoryzacja. Ten wybór kształtuje wysiłek integracyjny, doświadczenie administratora i jak bezpiecznie będziesz mógł rozwijać uprawnienia w czasie.
W modelu scentralizowanym dedykowana usługa autoryzacji ocenia dostęp dla wszystkich produktów. Produkty odwołują się do niej (lub weryfikują centralnie wystawione decyzje) zanim pozwolą na akcje.
To atrakcyjne, gdy potrzebujesz spójnego zachowania polityk, ról międzyproduktowych i jednego miejsca do audytu. Główny koszt to integracja: każdy produkt musi polegać na dostępności, latencji i formacie decyzji usługi współdzielonej.
W modelu federowanym każdy produkt implementuje i ocenia swoje uprawnienia. Twoja „aplikacja menedżerska” obsługuje głównie przepływy przypisywania i synchronizuje wyniki do poszczególnych produktów.
To maksymalizuje autonomię zespołów produktowych i zmniejsza zależności runtime. Wadą jest dryft: nazwy, semantyka i przypadki brzegowe mogą się rozjechać, utrudniając administrację międzyproduktową i raportowanie.
Praktyczny środek to traktować menedżera uprawnień jako control plane (jeden panel administracyjny), podczas gdy produkty pozostają punktami egzekucji.
Utrzymujesz wspólny katalog uprawnień dla koncepcji, które muszą pasować między produktami (np. „Billing Admin”, „Read Reports”), oraz miejsce na uprawnienia specyficzne dla produktu, gdy zespoły potrzebują elastyczności. Produkty pobierają lub otrzymują aktualizacje (role, granty, mapowania grup) i wymuszają lokalnie.
Jeśli spodziewasz się szybkiego przyrostu produktów, hybryda często jest najlepszym punktem startowym: daje jeden panel administracyjny bez przymusu przenoszenia każdego produktu na ten sam silnik autoryzacji od razu.
System uprawnień udaje się lub nie na poziomie modelu danych. Zacznij prosto od RBAC (role‑based access control), aby było łatwo tłumaczyć, zarządzać i audytować. Dodawaj atrybuty (ABAC) tylko tam, gdzie RBAC staje się zbyt gruby.
Przynajmniej jawnie zamodeluj:
project.read, project.write, billing.manage).Praktyczny wzorzec: przydział roli łączy principal (użytkownik lub grupa) z rolą w ramach zakresu (globalny dla produktu, poziom zasobu lub oba).
Definiuj role per produkt, żeby słownictwo produktu pozostało jasne (np. „Analyst” w Produkcie A nie musi być identyczny z „Analyst” w Produkcie B).
Następnie dodaj szablony ról: znormalizowane role wielokrotnego użytku między tenantami, środowiskami lub kontami klientów. Na to nałóż bundle dla powszechnych funkcji (np. „Support Agent bundle” = role w Produkcie A + Produkt B + Produkt C). Bundles zmniejszają wysiłek administracyjny bez scalania wszystkiego w jedną mega‑rolę.
Ustaw domyślnie bezpieczne zachowania:
billing.manage, user.invite, audit.export zamiast ukrywać je pod „admin”.Dodaj ABAC, gdy potrzebujesz reguł typu „może widzieć zgłoszenia tylko dla swojego regionu” lub „może wdrażać tylko do stagingu”. Używaj atrybutów jako ograniczeń (region, environment, klasyfikacja danych), zachowując RBAC jako główny sposób rozumienia dostępu przez ludzi.
Jeśli chcesz głębszy przewodnik po nazewnictwie ról i konwencjach zakresów, odnieś się do wewnętrznych dokumentów lub strony referencyjnej takiej jak /docs/authorization-model.
Twoja aplikacja uprawnień stoi pomiędzy ludźmi, produktami i politykami — dlatego potrzebujesz jasnego planu, jak każde żądanie identyfikuje kto działa, który produkt pyta i jakie uprawnienia mają zostać zastosowane.
Traktuj każdy produkt (i środowisko) jako klienta z własną tożsamością:
Cokolwiek wybierzesz, loguj tożsamość produktu przy każdym wydarzeniu autoryzacyjnym/audytowym, by potem móc odpowiedzieć „który system to zażądał?”.
Wspieraj dwa wejścia:
Dla sesji używaj krótkotrwałych tokenów dostępowych plus po‑stronnej sesji lub tokenu odświeżającego z rotacją. Upewnij się, że wylogowanie i unieważnianie sesji jest przewidywalne (szczególnie dla adminów).
Dwa popularne wzory:
Praktyczny hybryd: JWT zawiera identity + tenant + role, a produkty wywołują endpoint dla drobnych, precyzyjnych decyzji w razie potrzeby.
Nie używaj tokenów użytkowników dla zadań tła. Twórz konta serwisowe z explicite zakresem (least privilege), wydawaj tokeny client‑credentials i trzymaj je oddzielnie w logach audytu od działań ludzkich.
Aplikacja uprawnień działa tylko wtedy, gdy każdy produkt potrafi zadać te same pytania i otrzymać spójne odpowiedzi. Celem jest zdefiniowanie niewielkiego zestawu stabilnych API, które każdy produkt zintegrować raz, a potem wielokrotnie używać.
Skup się na niewielu operacjach potrzebnych każdemu produktowi:
Unikaj logiki specyficznej dla produktu w tych endpointach. Standaryzuj słownictwo: subject (użytkownik/serwis), action, resource, scope (tenant/org/project) i context (atrybuty przydatne później).
Większość zespołów używa kombinacji:
POST /authz/check (lub używa lokalnego SDK) przy każdej wrażliwej operacji.Praktyczna zasada: traktuj scentralizowane sprawdzenie jako źródło prawdy dla akcji wysokiego ryzyka, a replikowane dane używaj do UX (menu, feature flags, badge „masz dostęp”), gdzie okazjonalna nieświeżość jest dopuszczalna.
Gdy uprawnienia się zmieniają, nie polegaj na pollingu produktów.
Publikuj zdarzenia jak role.granted, role.revoked, membership.changed, policy.updated do kolejki lub webhooków. Produkty subskrybują i aktualizują swoje cache/read modele.
Projektuj zdarzenia tak, by były:
Sprawdzenia dostępu muszą być szybkie, ale cache może tworzyć błędy bezpieczeństwa przy słabym unieważnianiu.
Powszechny wzorzec:
Jeśli używasz JWT z wbitymi rolami, trzymaj krótki czas życia tokenów i wspieraj serwerowe strategie unieważniania (albo claim „token version”), żeby revoke'y propagowały się szybko.
Uprawnienia ewoluują z funkcjami produktów. Zaplanuj to:
/v1/authz/check) i schematy zdarzeń.Mała inwestycja w kompatybilność zapobiega temu, by system uprawnień stał się wąskim gardłem dla nowych funkcji produktu.
System uprawnień może być poprawny technicznie i mimo to zawieść, jeśli administratorzy nie potrafią pewnie odpowiedzieć: „Kto ma dostęp do czego i dlaczego?” Twoje UX powinno zmniejszać niepewność, zapobiegać przypadkowemu nadawaniu nadmiernych uprawnień i przyspieszać typowe zadania.
Zacznij od niewielkiego zestawu stron, które pokrywają 80% codziennych operacji:
Przy każdej roli dodaj wyjaśnienie w prostym języku: „Co ta rola pozwala” plus konkretne przykłady („Może zatwierdzać faktury do 10k” jest lepsze niż „invoice:write”). Odnośniki do głębszej dokumentacji zostaw jako tekst (np. /help/roles).
Narzędzia masowe oszczędzają czas, ale potęgują skutki błędów — tak więc projektuj je bezpiecznie:
Dodaj zabezpieczenia jak „dry run”, limity prędkości i jasne instrukcje rollbacku na wypadek błędnego importu.
Wiele organizacji potrzebuje lekkiego procesu:
Request → Approve → Provision → Notify
Żądania powinny zawierać kontekst biznesowy („potrzebne do zamknięcia Q4”) i czas trwania. Zatwierdzenia muszą być świadome roli i produktu (właściwy zatwierdzający). Provisioning generuje wpis audytu i powiadamia zarówno wnioskodawcę, jak i zatwierdzającego.
Używaj spójnego nazewnictwa, unikaj skrótów w UI i dodawaj inline‑owe ostrzeżenia („To daje dostęp do PII klienta”). Zapewnij obsługę klawiatury, czytelny kontrast i jasne stany pustki („Brak przypisanych ról — dodaj jedną, aby włączyć dostęp”).
Audyt to różnica między „myślimy, że dostęp jest poprawny” a „możemy to udowodnić”. Gdy aplikacja zarządza uprawnieniami w wielu produktach, każda zmiana musi być śledzona — zwłaszcza przydziały ról, edycje polityk i działania administratorów.
Przynajmniej loguj kto zmienił co, kiedy, skąd i dlaczego:
Traktuj zdarzenia audytu jako append‑only. Nie pozwalaj na modyfikacje lub usuwanie przez kod aplikacji; jeśli potrzebna korekta, zapisz zdarzenie kompensujące.
Określ retencję wg ryzyka i regulacji: wiele zespołów trzyma „gorące” przeszukiwalne logi 30–90 dni, a archiwum 1–7 lat. Ułatw eksport: zapewnij zaplanowaną dostawę (np. codziennie) i strumieniowanie do narzędzi SIEM. Przynajmniej wspieraj eksport newline‑delimited JSON i dołącz stabilne ID do de‑duplikacji.
Zbuduj proste detektory, które flagują:
Wyświetl je w widoku „Admin activity” i opcjonalnie wysyłaj alerty.
Spraw, by raporty były praktyczne i eksportowalne:
Jeśli później dodasz workflowy zatwierdzania, łącz zdarzenia audytu z ID żądania, aby przeglądy zgodności były szybkie i obronne.
Aplikacja zarządzania uprawnieniami sama w sobie jest wartościowym celem: jedna zła decyzja może dać szeroki dostęp we wszystkich produktach. Traktuj powierzchnię admina i mechanizmy autoryzacji jako systemy „tier‑0”.
Zacznij od zasady najmniejszych uprawnień i utrudnij eskalację:
Typowy błąd: „role editor” może edytować rolę admina, a potem przypisać ją sobie.
APIs admina nie powinny być tak dostępne jak API użytkownika:
Typowy błąd: wygodny endpoint („grant all for support”) wypuszczony do produkcji bez zabezpieczeń.
HttpOnly, Secure, SameSite, krótkie czasy sesji i ochrona CSRF dla przepływów przeglądarkowych.Typowy błąd: wyciek poświadczeń serwisowych, które pozwalają na zapisy polityk.
Błędy autoryzacji to zwykle scenariusze „braku deny”:
System uprawnień nigdy nie jest „gotowy” przy starcie — zdobywasz zaufanie stopniowo. Celem jest bezpieczny rollout: udowodnienie poprawności decyzji o dostępie, szybkie rozwiązywanie problemów i możliwość rollbacku bez paraliżu zespołów.
Zacznij od jednego produktu o jasnych rolach i aktywnych użytkownikach. Zmapuj jego obecne role/grupy do niewielkiego zestawu kanonicznych ról w nowym systemie, a następnie zbuduj adapter, który przetłumaczy „nowe uprawnienia” na to, co produkt wymusza dziś (scope API, feature flagi, pola w bazie).
Podczas pilota potwierdź cały cykl:
Zdefiniuj metryki sukcesu z przodu: mniej ticketów wsparcia dotyczących dostępu, brak krytycznych incydentów nadmiernych uprawnień i czas‑do‑cofnięcia mierzony w minutach.
Stare uprawnienia są zwykle chaotyczne. Zaplanuj krok translacji, który przekonwertuje istniejące grupy, wyjątki i role specyficzne dla produktu do nowego modelu. Trzymaj tabelę mapowań, aby wyjaśnić każde przypisanie po migracji.
Wykonaj próbę w stagingu, potem migruj falami (według organizacji, regionu lub tieru klienta). Dla trudnych klientów migruj trybem shadow — porównuj stare i nowe decyzje przed ich wymuszeniem.
Feature flags pozwalają oddzielić „ścieżkę zapisu” od „ścieżki wymuszania”. Typowe fazy:
Jeśli coś pójdzie nie tak, możesz wyłączyć wymuszanie, zachowując widoczność audytu.
Udokumentuj runbooki dla typowych incydentów: użytkownik nie ma dostępu do produktu, użytkownik ma zbyt szerokie uprawnienia, admin popełnił błąd, nagłe unieważnienie. Zawieraj, kto jest na wezwanie, gdzie sprawdzić logi, jak zweryfikować efektywne uprawnienia i jak wykonać „break‑glass” revoke propagujący się szybko.
Po ustabilizowaniu pilota powtarzaj tę samą procedurę dla kolejnych produktów. Każda nowa integracja powinna być pracą integracyjną, a nie reinwencją modelu dostępu.
Nie potrzebujesz egzotycznych technologii, aby dostarczyć solidną aplikację do zarządzania uprawnieniami. Priorytetuj poprawność, przewidywalność i operacyjność — potem optymalizuj.
Typowy zestaw bazowy:
Trzymaj logikę decyzji autoryzacyjnych w jednej usłudze/bibliotece, aby uniknąć dryftu w zachowaniu produktów.
Jeśli chcesz szybko postawić wewnętrzny panel admina i API (szczególnie do pilota), platformy takie jak Koder.ai mogą pomóc prototypować i dostarczyć webową aplikację szybciej przez chat‑driven workflow. Może to przyspieszyć wygenerowanie Reactowego admin UI, backendu Go + PostgreSQL oraz szkieletu logów audytu i zatwierdzeń — nadal jednak wymaga to rygorystycznego przeglądu logiki autoryzacji.
Zacznij od wypisania 1–3 produktów, które zintegrujesz najpierw i udokumentuj, dla każdego z nich:
Jeśli modele znacznie się różnią, zaplanuj warstwę translacji zamiast próby narzucenia jednego modelu od razu.
Wybór zależy od tego, gdzie mają być podejmowane decyzje polityk:
Jeśli spodziewasz się wielu produktów i częstych zmian, hybrid jest zwykle bezpiecznym domyślnym wyborem.
Praktyczny punkt startowy to RBAC z wyraźnymi encjami:
billing.manage)Przechowuj jako: , żeby łatwo odpowiadać „kto ma co i gdzie”.
Traktuj RBAC jako sposób, w jaki ludzie myślą o dostępie, i dodawaj ABAC tylko tam, gdzie RBAC jest za gruby.
Użyj ABAC do reguł typu:
Ogranicz liczbę atrybutów (region, environment, klasyfikacja danych) i dokumentuj je; role powinny pozostać głównym sposobem przydzielania dostępu.
Unikaj jednego mega‑rola przez warstwowanie:
To zmniejsza wysiłek administracyjny, nie zacierając istotnych różnic między produktami.
Dwa podejścia:
Praktyczny hybryd: JWT zawiera identity + tenant + role, a produkty odwołują się do endpointu sprawdzającego dla akcji wysokiego ryzyka. Utrzymuj krótkie czasy życia tokenów i strategię unieważniania.
Utrzymaj małe, stabilne API, które każdy produkt może zaimplementować:
POST /authz/check (hot path)Ujednolicaj słownictwo: , , , (tenant/org/workspace) i opcjonalny . Unikaj logiki specyficznej dla produktu w rdzeniu.
Użyj zdarzeń, by produkty nie musiały ciągle pollingować. Publikuj:
role.granted / role.revokedmembership.changedpolicy.updatedProjektuj zdarzenia tak, by były , jeśli to możliwe, i albo (a) wystarczająco opisujące stan lokalny, albo (b) parowane z endpointem „fetch current state” do rekonsyliacji.
Włącz ekrany i zabezpieczenia, które zmniejszają ryzyko nadawania zbyt szerokich uprawnień:
Dodaj opisy ról w języku prostym i ostrzeżenia przy wrażliwym dostępie (np. PII, billing).
Loguj każdą wrażliwą zmianę jako zdarzenie append‑only z wystarczającym kontekstem, aby odpowiedzieć „kto miał dostęp do czego, kiedy i dlaczego?”.
Przynajmniej zapisuj:
Wspieraj eksport (np. newline‑delimited JSON), długoterminowe przechowywanie i stabilne ID do de‑duplikacji w narzędziach SIEM.