20 mar 2025·8 min
Jak zbudować aplikację webową do obsługi klienta dla zgłoszeń i SLA
Zaplanuj, zaprojektuj i zbuduj aplikację webową do obsługi klienta z przepływami ticketów, śledzeniem SLA i przeszukiwalną bazą wiedzy — plus role, analitykę i integracje.
Określ cele, użytkowników i zakres
Produkt do obsługi zgłoszeń szybko się komplikuje, gdy buduje się go wokół funkcji zamiast wyników. Zanim zaprojektujesz pola, kolejki czy automatyzacje, ustal, dla kogo jest aplikacja, jaki ból rozwiązuje i jak wygląda „dobrze”.
Zidentyfikuj użytkowników (i ich codzienne zadania)
Zacznij od wypisania ról i tego, co każda powinna zrobić w typowym tygodniu:
- Agenci: przyjmować, odpowiadać, rozwiązywać i dokumentować rozwiązania szybko.
- Liderzy zespołów: balansować obciążenie, wyłapywać zablokowane zgłoszenia, egzekwować SLA, szkolić agentów.
- Administratorzy: konfigurować kanały, kategorie, automatyzacje, uprawnienia i szablony.
- Klienci (opcjonalnie): zgłaszać żądania, śledzić status, dodawać szczegóły, szukać odpowiedzi w portalu.
Jeśli pominiesz ten krok, przypadkowo zoptymalizujesz pod kątem administratorów, a agenci będą się męczyć w kolejce.
Zapisz problemy, które rozwiązujesz
Trzymaj to konkretne i powiązane z zachowaniem, które możesz zaobserwować:
- Przekroczone SLA: zgłoszenia się starzeją bez echa; eskalacje następują zbyt późno.
- Zamieszanie w kolejkach: niejasna odpowiedzialność, dublowanie pracy, pytanie „gdzie to powinno iść?”.
- Powtarzające się pytania: te same odpowiedzi wpisywane w kółko, co spowalnia rozwiązanie.
Zdecyduj, gdzie aplikacja będzie używana
Bądź konkretny: czy to narzędzie tylko wewnętrzne, czy będzie też portal dla klientów? Portale zmieniają wymagania (uwierzytelnianie, uprawnienia, treści, branding, powiadomienia).
Wybierz metryki sukcesu wcześnie
Wybierz mały zestaw, które będziesz śledzić od pierwszego dnia:
- Czas do pierwszej odpowiedzi
- Czas do rozwiązania
- Wskaźnik odciążenia (problem rozwiązany przez bazę wiedzy zamiast ticketu)
Stwórz prostą deklarację zakresu v1
Napisz 5–10 zdań opisujących, co jest w v1 (obowiązkowe przepływy) i co jest później (miłe do posiadania, jak zaawansowane routowanie, sugestie AI czy rozbudowane raporty). To stanie się twoją barierą, gdy napłyną prośby.
Zaprojektuj model ticketu i jego cykl życia
Model ticketu to „źródło prawdy” dla wszystkiego: kolejek, SLA, raportów i widoku dla agentów. Zrób to dobrze wcześnie, a unikniesz bolesnych migracji.
Zmapuj cykl życia, który wytłumaczysz jednym zdaniem
Zacznij od klarownego zestawu stanów i opisz, co każdy oznacza operacyjnie:
- Nowe: utworzone, jeszcze nie przeglądnięte
- Przydzielone: przypisane agentowi lub zespołowi
- W trakcie: aktywnie w pracy
- Oczekuje: zablokowane (odpowiedź klienta, strona trzecia, inżynieria)
- Rozwiązane: agent uważa, że problem jest załatwiony (często wysyła powiadomienie)
- Zamknięte: stan końcowy (zablokowane lub ograniczone edycje)
Dodaj reguły przejść między stanami. Na przykład tylko zgłoszenia w Przydzielone/W trakcie mogą przejść do Rozwiązane, a Zamknięte nie powinno się otwierać bez utworzenia follow-up.
Zdecyduj, jak zgłoszenia trafiają do systemu
Wypisz każdą ścieżkę przyjmowania, którą obsłużysz teraz (i co dodasz później): formularz webowy, przychodzący e-mail, czat i API. Każdy kanał powinien tworzyć ten sam obiekt ticketu, z kilkoma polami specyficznymi dla kanału (np. nagłówki e-mail czy ID transkryptu czatu). Spójność ułatwia automatyzację i raportowanie.
Wybierz wymagane pola (i trzymaj je minimalnie)
Przynajmniej wymagaj:
- Temat i opis
- Zgłaszający (tożsamość klienta)
- Priorytet (jak pilne)
- Kategoria (jaki rodzaj problemu)
Wszystko inne może być opcjonalne lub wyprowadzane. Przepchany formularz zmniejsza jakość uzupełniania i spowalnia agentów.
Zaplanuj tagi i pola niestandardowe dla rzeczywistych zespołów
Używaj tagów do lekkiego filtrowania (np. „billing”, „bug”, „vip”), a pól niestandardowych gdy potrzebujesz strukturalnych raportów lub routowania (np. „Obszar produktu”, „ID zamówienia”, „Region”). Upewnij się, że pola mogą być przypisane do zespołu, by jeden dział nie zaśmiecał drugiego.
Zdefiniuj współpracę wewnątrz ticketu
Agenci potrzebują bezpiecznego miejsca do koordynacji:
- Notatki wewnętrzne (niewidoczne dla klientów)
- @wzmianki i listy obserwujących/CC
- Powiązane ticket'y (duplikaty, parent/child incydenty)
Interfejs agenta powinien mieć te elementy jednego kliknięcia od głównej osi czasu.
Zbuduj kolejki ticketów i przepływy przypisywania
Kolejki i przypisania to moment, gdy system ticketowy przestaje być wspólną skrzynką, a zaczyna działać jak narzędzie operacyjne. Twój cel jest prosty: każdy ticket powinien mieć oczywistą „następną najlepszą akcję”, a każdy agent powinien wiedzieć, nad czym pracować teraz.
Zaprojektuj kolejkę agenta, która odpowiada „co dalej?”
Stwórz widok kolejki, który domyślnie pokazuje najpilniejsze rzeczy. Popularne opcje sortowania, których agenci faktycznie użyją:
- Priorytet (np. P1–P4)
- Czas do SLA (najbliższe pierwsze)
- Ostatnia aktualizacja (by złapać utkane konwersacje)
Dodaj szybkie filtry (zespół, kanał, produkt, poziom klienta) i szybkie wyszukiwanie. Trzymaj listę zwartą: temat, zgłaszający, priorytet, status, odliczanie SLA i przypisany agent zazwyczaj wystarczą.
Reguły przypisywania: automatycznie, gdy to możliwe, manualnie, gdy trzeba
Wspieraj kilka ścieżek przypisywania, by zespoły mogły ewoluować bez zmiany narzędzi:
- Ręczne przypisanie dla wyjątków i treningu
- Round-robin do równomiernego rozdziału obciążenia
- Routowanie oparte na umiejętnościach (język, obszar produktu, rozliczenia vs. techniczne)
- Routowanie zespołowe (np. „Płatności”, „Enterprise”, „Zwroty”)
Uczyń decyzje reguł widocznymi („Przydzielono przez: Umiejętności → Francuski + Płatności”), żeby agenci ufali systemowi.
Statusy i szablony, które popychają pracę do przodu
Statusy takie jak Oczekuje na klienta i Oczekuje na stronę trzecią zapobiegają temu, że zgłoszenia wyglądają „bezczynnie” gdy akcja jest zablokowana, i sprawiają, że raportowanie jest uczciwsze.
Aby przyspieszyć odpowiedzi, dodaj gotowe odpowiedzi i szablony odpowiedzi z bezpiecznymi zmiennymi (imię, numer zamówienia, data SLA). Szablony powinny być przeszukiwalne i edytowalne przez uprawnionych liderów.
Zapobiegaj kolizjom (dwóch agentów, jeden ticket)
Dodaj obsługę kolizji: gdy agent otwiera ticket, nałóż krótkotrwały „lock widoku/edycji” lub baner „aktualnie obsługiwane przez”. Jeśli ktoś inny próbuje odpisać, ostrzeż go i wymagaj potwierdzenia przed wysłaniem (lub zablokuj wysyłkę), by uniknąć powielonych, sprzecznych odpowiedzi.
Wdróż reguły SLA, timery i ścieżki eskalacji
SLA pomagają tylko wtedy, gdy wszyscy zgadzają się, co jest mierzone, a aplikacja to konsekwentnie egzekwuje. Zacznij od zamiany „odpowiadamy szybko” w polityki, które system może policzyć.
Zdefiniuj polityki SLA (co będziesz mierzyć)
Większość zespołów zaczyna od dwóch timerów na ticket:
- Czas do pierwszej odpowiedzi: czas od utworzenia ticketu do pierwszej odpowiedzi agenta (albo pierwszej publicznej odpowiedzi nie-automatycznej).
- Czas do rozwiązania: czas od utworzenia ticketu do „Rozwiązane/Zamknięte”.
Trzymaj polityki konfigurowalne wg priorytetu, kanału lub poziomu klienta (np. VIP ma 1 godz. do pierwszej odpowiedzi, Standard 8 godzin roboczych).
Zdecyduj, kiedy zegary SLA startują i zatrzymują się
Zapisz reguły przed kodowaniem, bo przypadki brzegowe rosną szybko:
- Godziny pracy vs. 24/7: zdefiniuj kalendarz (strefa czasowa, dni robocze, święta).
- Stany pauzy: zatrzymaj zegar, gdy ticket jest w „Oczekuje na klienta” lub „Wstrzymane przez dostawcę zewnętrznego”.
- Warunki wznowienia: wznow, gdy klient odpowie lub stan zmieni się na „Otwarte/W trakcie”.
Przechowuj zdarzenia SLA (start, pauza, wznowienie, naruszenie), by później móc wyjaśnić dlaczego coś naruszono.
Uczyń status SLA oczywistym w UI
Agenci nie powinni otwierać ticketu, by dowiedzieć się, że zaraz nastąpi naruszenie. Dodaj:
- Timer odliczający (pozostały czas)
- Flagę po przekroczeniu z jasnym poziomem (ostrzeżenie vs. naruszone)
- Opcjonalne alerty (w aplikacji, e-mail lub czat) gdy próg jest bliski
Zbuduj ścieżki eskalacji
Eskalacja powinna być automatyczna i przewidywalna:
- Powiadom lidera zespołu przy 80% dopuszczonego czasu
- Przypisz do dyżurnej kolejki, jeśli nastąpi naruszenie
- Podnieś priorytet lub dodaj tag „Eskalowane”
Zaplanuj raportowanie SLA
Przynajmniej śledź liczbę naruszeń, wskaźnik naruszeń i trend w czasie. Zapisuj też powody naruszeń (zbyt długo w pauzie, źle ustawiony priorytet, niedoszacowanie obsady), żeby raporty prowadziły do akcji, a nie do obwiniania.
Stwórz bazę wiedzy, która zmniejsza powtarzające się zgłoszenia
Dobra baza wiedzy (KB) to nie tylko folder FAQ — to funkcja produktu, która powinna wymiernie zmniejszać powtarzające się pytania i przyspieszać rozwiązania. Projektuj ją jako część przepływu ticketowego, a nie jako oddzielną „stronę dokumentacji”.
Struktura: ułatwiaj utrzymanie treści
Zacznij od prostego modelu informacji, który skaluje się:
- Kategorie → sekcje → artykuły (łatwa nawigacja dla klientów i agentów)
- Tagi dla tematów przekrojowych (billing, logowanie, integracje) bez duplikowania artykułów
- Jasna odpowiedzialność (kto przegląda co), żeby treść była aktualna
Utrzymuj szablony artykułów: opis problemu, krok po kroku naprawa, opcjonalne zrzuty ekranu i „Jeśli to nie pomogło…” kierujące do odpowiedniego formularza ticketu lub kanału.
Wyszukiwanie, które faktycznie znajduje odpowiedzi
Większość porażek KB to porażki wyszukiwania. Zaimplementuj wyszukiwanie z:
- Tuningiem trafności (wzmocnienia tytułu/nagłówków, wzmocnienie świeżości)
- Synonimami (np. „invoice” ↔ „bill”, „2FA” ↔ „authentication code")
- Tolerancją na literówki i stemmatyzacją (liczba pojedyncza/mnoga)
Indeksuj też tematy ticketów (anonymizowane), by uczyć się realnego języka klientów i zasilać listę synonimów.
Szkice, przeglądy i zatwierdzenia publikacji
Dodaj lekki workflow: szkic → przegląd → opublikowane, z opcjonalnym planowanym publikowaniem. Przechowuj historię wersji i metadata „ostatnia aktualizacja”. Połącz to z rolami (autor, recenzent, wydawca), by nie każdy agent mógł edytować treści publiczne.
Mierz, co redukuje ticket'y
Śledź więcej niż odsłony stron. Przydatne metryki to:
- Głosy pomocne (tak/nie) i feedback „czego brakowało?”
- Sygnały odciążenia: wyszukiwanie → artykuł obejrzany → brak utworzonego ticketu w ciągu X godzin
- Najczęściej wyszukiwane hasła bez trafnych wyników (luki w treści)
Powiąż artykuły z ticketami tam, gdzie praca się dzieje
W komponencie odpowiedzi agenta pokaż sugerowane artykuły na podstawie tematu ticketu, tagów i wykrytego zamiaru. Jedno kliknięcie powinno wstawić link publiczny (np. /help/account/reset-password) lub wewnętrzny fragment do szybszej odpowiedzi.
Dobrze zrobiona KB staje się pierwszą linią wsparcia: klienci rozwiązują problemy sami, a agenci obsługują mniej powtórzeń z większą spójnością.
Ustaw role, uprawnienia i audytowalność
Od specyfikacji do działającej aplikacji
Zamień model ticketów i cykl życia w działające ekrany React i API w Go.
Uprawnienia to miejsce, gdzie narzędzie ticketowe albo pozostaje bezpieczne i przewidywalne, albo szybko się zaśmieca. Nie czekaj z „zamknięciem” dostępu do po uruchomieniu. Modeluj dostęp wcześnie, by zespoły mogły działać szybko bez ujawniania wrażliwych ticketów lub możliwości zmiany reguł systemowych.
Oddziel role (i trzymaj je proste)
Zacznij od kilku jasnych ról i dodawaj niuanse tylko wtedy, gdy pojawi się realna potrzeba:
- Agent: obsługuje ticket, dodaje notatki, odpowiada, aktualizuje pola.
- Lider: wszystko, co agent + przypisywanie, zarządzanie kolejkami i workflow coachingowy.
- Admin: ustawienia systemowe jak kanały, zarządzanie użytkownikami i konfiguracja.
- Redaktor treści: tworzy i publikuje artykuły KB.
- Tylko do odczytu: audyt, finanse, prawnicy lub interesariusze potrzebujący wglądu bez zmian.
Definiuj uprawnienia według możliwości
Unikaj dostępu „wszystko albo nic”. Traktuj główne akcje jako eksplicytne uprawnienia:
- Przegląd vs. edycja ticketów (w tym notatek prywatnych)
- Zarządzanie makrami/gotowymi odpowiedziami
- Edycja reguł SLA, timerów i polityk eskalacji
- Publikacja/odpublikowanie treści KB
To ułatwia nadawanie zasady najmniejszych uprawnień i wspiera rozwój (nowe zespoły, regiony, kontraktorzy).
Dostęp zespołowy dla wrażliwych kolejek
Niektóre kolejki powinny być domyślnie ograniczone—billing, security, VIP czy sprawy HR. Użyj członkostwa w zespole, by kontrolować:
- Które kolejki są widoczne
- Kto może przypisywać lub scalać ticket'y
- Czy pola danych klienta są maskowane
Logi audytu, z których będziesz korzystać
Loguj kluczowe akcje z kto, co, kiedy i wartościami przed/po: zmiany przypisań, usunięcia, edycje reguł SLA/polityk, zmiany ról i publikacje KB. Zrób logi przeszukiwalne i eksportowalne, by śledztwa nie wymagały dostępu do bazy danych.
Zaplanuj multi-brand lub multi-inbox wcześnie
Jeśli obsługujesz wiele marek lub skrzynek, zdecyduj, czy użytkownicy będą przełączać kontekst, czy dostęp będzie partycjonowany. To wpływa na sprawdzanie uprawnień i raportowanie — powinno być spójne od początku.
Zaprojektuj doświadczenie użytkownika agenta i administratora
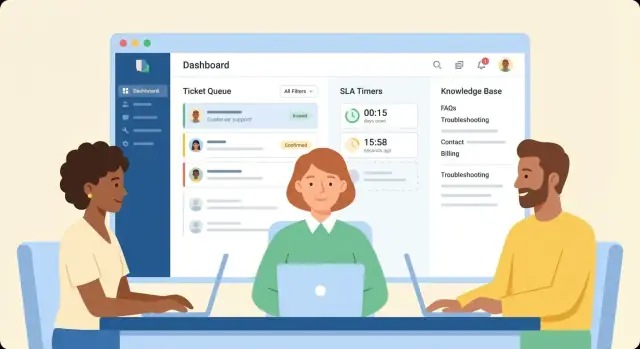
System ticketowy wygrywa albo przegrywa na tym, jak szybko agenci rozumieją sytuację i wykonują kolejną akcję. Traktuj przestrzeń agenta jako „ekran główny”: powinna od razu odpowiadać na trzy pytania — co się stało, kim jest ten klient i co mam zrobić dalej.
Układ przestrzeni agenta
Zacznij od widoku dzielonego, który utrzymuje kontekst podczas pracy:
- Wątek konwersacji (e-mail/czat/wiadomości) z wyraźnymi znacznikami czasu, załącznikami i cytowaniami.
- Panel klienta z tożsamością, planem/poziomem konta, organizacją, poprzednimi ticketami i kluczowymi notatkami.
- Pola ticketu (status, priorytet, kolejka, przypisany, tagi, timery SLA) pogrupowane logicznie, nie rozrzucone.
Utrzymaj czytelność wątku: rozróżniaj klienta, agenta i zdarzenia systemowe, a notatki wewnętrzne wizualnie odróżniaj, by nigdy nie zostały wysłane przez pomyłkę.
Jednoklikowe akcje, które usuwają tarcie
Umieść najczęstsze akcje tam, gdzie jest kursor — blisko ostatniej wiadomości i na górze ticketu:
- Przypisz / zmień przypisanie
- Zmień status (w tym „oczekuje na klienta”)
- Dodaj notatkę wewnętrzną
- Zastosuj makro (wstępnie wypełniona odpowiedź + aktualizacje pól)
Dąż do przepływów „jeden klik + opcjonalny komentarz”. Jeśli akcja wymaga modala, niech będzie krótki i przyjazny klawiaturze.
Funkcje przyspieszające dla zespołów o dużej przepustowości
Obsługa dużej liczby zgłoszeń potrzebuje skrótów, które są przewidywalne:
- Skróty klawiaturowe do odpowiedzi, notatki, przypisz do mnie, zamknij i następny ticket
- Akcje zbiorcze w widokach list (taguj, przypisz, zamknij, scal)
- Szybka paleta poleceń dla zaawansowanych użytkowników
Dostępność i bezpieczeństwo UI
Buduj dostępność od pierwszego dnia: odpowiedni kontrast, widoczne stany focus, pełna nawigacja tabem i etykiety zgodne z czytnikami ekranu dla kontrolek i timerów. Zapobiegaj kosztownym błędom: potwierdzaj akcje destrukcyjne, wyraźnie oznaczaj „publiczna odpowiedź” vs „notatka wewnętrzna” i pokaż podgląd tego, co zostanie wysłane.
UX dla administratora i portalu klienta
Administratorzy potrzebują prostych, prowadzących ekranów dla kolejek, pól, automatyzacji i szablonów—unikaj ukrywania podstaw za zagnieżdżonymi ustawieniami.
Jeśli klienci mogą zgłaszać i śledzić sprawy, zaprojektuj lekki portal: utwórz ticket, zobacz status, dodaj aktualizacje i zobacz sugerowane artykuły przed wysłaniem. Trzymaj spójność z publicznym brandem i odwołuj się do widocznego tekstu /help.
Zaplanuj integracje, API i omnichannel intake
Zacznij mało, skaluj później
Zbuduj system ticketowy na Koder.ai i rozwijaj go od planu darmowego do wersji biznesowej.
Aplikacja ticketowa staje się użyteczna, gdy łączy się z miejscami, w których klienci już rozmawiają z tobą — i z narzędziami, których zespół używa, by rozwiązywać problemy.
Zacznij od systemów, które musisz podłączyć
Wypisz integracje „dzień 1” i jakie dane potrzebujesz z każdej z nich:
- E-mail (wspólne skrzynki, reguły przekierowań, outbound SMTP)
- Czat (widget na stronie, WhatsApp, narzędzia typu Intercom)
- CRM (kontekst konta, właściciel, poziom planu)
- Billing (status subskrypcji, faktury, zwroty)
- Provider tożsamości (SSO przez Google/Microsoft, SCIM do provisioningu użytkowników)
Zapisz kierunek przepływu danych (tylko do odczytu vs. zapis zwrotny) i kto w organizacji odpowiada za integrację.
Zaprojektuj API i webhooki wcześnie
Nawet jeśli integracje wyślesz później, zdefiniuj stabilne prymitywy teraz:
- Endpointy API do tworzenia, aktualizacji, wyszukiwania ticketów oraz komentarzy/wiadomości i zmian statusu.
- Webhooki dla kluczowych zdarzeń (ticket.created, ticket.updated, message.received, sla.breached), aby systemy zewnętrzne mogły reagować.
Utrzymuj przewidywalne uwierzytelnianie (klucze API dla serwerów; OAuth dla aplikacji instalowanych przez użytkownika) i wersjonuj API, by nie łamać klientów.
Zapobiegaj dublowaniu ticketów solidnym wątkowaniem e-maili
E-mail to miejsce, gdzie pojawiają się brudne przypadki. Zaplanuj, jak sobie z nimi poradzisz:
- Wątkowanie odpowiedzi przy użyciu nagłówków Message-ID / In-Reply-To / References
- Bezpieczne parsowanie wiadomości przesłanych dalej i powszechnych sygnatur
- Dededuplikację przez wykrywanie powtarzających się przychodzących payloadów (zwłaszcza od providerów poczty)
Mały nakład pracy tutaj zapobiega „każda odpowiedź tworzy nowy ticket” katastrofom.
Obsługuj załączniki bezpiecznie
Obsługuj załączniki, ale z zabezpieczeniami: limity typu/rozmiaru pliku, bezpieczne przechowywanie i haki do skanowania wirusów (lub usługa skanująca). Rozważ odfiltrowanie niebezpiecznych formatów i nigdy nie renderuj niezaufanego HTML inline.
Dokumentuj konfigurację jak funkcję produktu
Stwórz krótki przewodnik integracji: wymagane poświadczenia, krok po kroku konfiguracja, rozwiązywanie problemów i kroki testowe. Jeśli utrzymujesz dokumentację, odwołuj się do hubu integracji w tekście /docs, żeby administratorzy nie musieli prosić inżynierii o pomoc.
Dodaj analitykę i raportowanie wydajności wsparcia
Analityka to miejsce, gdzie system ticketowy przestaje być „miejscem pracy”, a zaczyna być „narzędziem do poprawy”. Klucz to uchwycić właściwe zdarzenia, policzyć kilka spójnych metryk i przedstawić je różnym odbiorcom bez ujawniania wrażliwych danych.
Zacznij od śladu zdarzeń (nie tylko bieżącego stanu ticketu)
Przechowuj momenty, które wyjaśniają dlaczego ticket wygląda tak, jak wygląda. Minimum do śledzenia: zmiany statusu, odpowiedzi klienta i agenta, przypisania i zmiany przypisań, aktualizacje priorytetu/kategorii oraz zdarzenia timerów SLA (start/stop, pauzy i naruszenia). To pozwoli odpowiedzieć na pytanie „czy naruszyliśmy, bo brakowało ludzi, czy bo czekaliśmy na klienta?”
Tam, gdzie to możliwe, trzymaj zdarzenia dopisywane; ułatwia to audyt i raportowanie.
Kokpity dla liderów zespołów
Liderzy zwykle potrzebują operacyjnych widoków, na które mogą od razu zareagować:
- Backlog wg kolejki, priorytetu i kategorii
- Starzejące się ticket'y (np. najstarsze otwarte, najstarsze oczekujące na klienta)
- Ryzyko SLA (ticket'y, które prawdopodobnie naruszą w ciągu X godzin)
- Obciążenie agentów (liczba przypisanych, aktywna praca, czas od ostatniej aktualizacji)
Uczyń kokpity filtrowalnymi wg zakresu czasu, kanału i zespołu — bez zmuszania menedżerów do Excela.
Raporty dla zarządu
Zarząd interesuje się mniej poszczególnymi ticketami, a bardziej trendami:
- Wolumen wg kategorii/kanału, w tym dni i godziny szczytu
- Trendy pierwszej odpowiedzi i rozwiązania (mediana i 90 percentyl)
- Trendy CSAT (i wskaźnik odpowiedzi, żeby wyniki nie były mylące)
Jeśli powiążesz wyniki z kategoriami, możesz uzasadnić zatrudnienie, szkolenia czy poprawki w produkcie.
Filtry, eksporty i kontrola dostępu
Dodaj eksport CSV dla popularnych widoków, ale ogranicz go uprawnieniami (i najlepiej kontrolą poziomu pól), by nie wyciekały e-maile, treści wiadomości czy identyfikatory klientów. Loguj kto eksportował co i kiedy.
Retencja danych bez ryzykownych obietnic
Zdefiniuj, jak długo przechowujesz zdarzenia ticketów, treści wiadomości, załączniki i agregaty analityczne. Preferuj konfigurowalne ustawienia retencji i dokumentuj, co naprawdę usuwasz vs. anonimizujesz, by nie składać obietnic, których nie możesz zweryfikować.
Wybierz praktyczną architekturę i stack technologiczny
Produkt ticketowy nie potrzebuje skomplikowanej architektury, by być skutecznym. Dla większości zespołów prosty setup szybciej się wdraża, łatwiej utrzymuje i nadal dobrze skaluje.
Zacznij od prostego diagramu systemu
Praktyczny baseline wygląda tak:
- Frontend webowy: UI agenta/admina plus formularze i portal klienta
- Backend API: reguły biznesowe dla ticketów, SLA, użytkowników i bazy wiedzy
- Baza danych: źródło prawdy dla ticketów, użytkowników, zdarzeń i ustawień
- Zadania tła: wszystko, co zależy od czasu lub trwa dłużej
To podejście „modularnego monolitu” (jeden backend, jasne moduły) utrzymuje v1 w ryzach i pozwala na późniejsze rozdzielenie usług w razie potrzeby.
Jeśli chcesz przyspieszyć budowę v1 bez wymyślania całego pipeline'u od nowa, platforma typu Koder.ai może pomóc zaprojektować panel agenta, cykl ticketu i ekrany administracyjne przez rozmowę — a potem wyeksportować kod źródłowy, gdy będziesz gotowy przejąć pełną kontrolę.
Wiedz, co musi działać w tle
Systemy ticketowe sprawiają wrażenie działania w czasie rzeczywistym, ale wiele pracy jest asynchroniczne. Zaplanuj zadania tła wcześnie dla:
- Timerów SLA i eskalacji (np. „pierwsza odpowiedź za 30 minut”)
- Powiadomień (e-mail, in-app, webhooki)
- Indeksowania wyszukiwania (ticketów i artykułów KB)
- Przetwarzania przychodzących e-maili (parsowanie, załączniki, wątkowanie)
Jeśli przetwarzanie tła jest myślą dodaną, SLA stają się niewiarygodne, a agenci tracą zaufanie.
Przechowuj dane dla poprawności, wyszukuj dla szybkości
Użyj relacyjnej bazy danych (PostgreSQL/MySQL) dla podstawowych rekordów: ticketów, komentarzy, statusów, przypisań, polityk SLA i tabeli audytu/zdarzeń.
Dla szybkiego wyszukiwania i trafności trzymaj oddzielny indeks wyszukiwania (Elasticsearch/OpenSearch lub zarządzana alternatywa). Nie próbuj robić pełnotekstowego wyszukiwania na skalę w relacyjnej bazie, jeśli produkt od tego zależy.
Zdecyduj: budować czy kupić (i dlaczego)
Trzy obszary często oszczędzają miesiące, gdy się je kupi:
- Uwierzytelnianie: sprawdzony provider (SSO, MFA, polityki haseł)
- Wysyłka e-maili: serwis transakcyjny dla dostarczalności i obsługi bounce'ów
- Wyszukiwanie: wyszukiwarka zarządzana, jeśli brak doświadczenia wewnętrznego
Buduj to, co was wyróżnia: reguły workflow, zachowanie SLA, logika routingu i doświadczenie agenta.
Zaplanuj kamienie milowe z jasną listą v1
Szacuj wysiłek według kamieni milowych, nie funkcji. Solidna lista v1 to: CRUD ticketów + komentarze, podstawowe przypisanie, core timery SLA, powiadomienia e-mail, minimalne raportowanie. Trzymaj „miłe do posiadania” (zaawansowana automatyzacja, złożone role, głęboka analityka) wyraźnie poza zakresem v1, dopóki użytkowanie nie pokaże, co naprawdę się liczy.
Zadbaj o podstawy bezpieczeństwa, prywatności i niezawodności
Zacznij od solidnego backendu
Uruchom Go i PostgreSQL dla ticketów, zdarzeń i timerów SLA za pomocą jasnych poleceń.
Decyzje dotyczące bezpieczeństwa i niezawodności są najłatwiejsze (i najtańsze), gdy wbudujesz je od początku. Aplikacja wsparcia obsługuje wrażliwe rozmowy, załączniki i dane kont — traktuj ją jak system krytyczny, nie narzędzie poboczne.
Chroń dane klientów domyślnie
Zacznij od szyfrowania komunikacji (HTTPS/TLS) wszędzie, w tym w połączeniach serwis‑do‑serwisu, jeśli masz wiele usług. Dla danych w spoczynku szyfruj bazy i object storage (załączniki) i przechowuj sekrety w zarządzanym sejfie.
Stosuj zasadę najmniejszych uprawnień: agenci widzą tylko ticket'y, do których mają dostęp, a administratorzy mają podwyższone prawa tylko gdy potrzebne. Dodaj logowanie dostępu, by móc odpowiedzieć „kto przeglądał/eksportował co i kiedy?” bez domysłów.
Wybierz uwierzytelnianie dopasowane do odbiorców
Uwierzytelnianie nie jest uniwersalne. Dla małych zespołów e-mail + hasło może wystarczyć. Jeśli sprzedajesz większym organizacjom, SSO (SAML/OIDC) często jest wymagane. Dla lekkich portali klienta magic link może zmniejszyć tarcie.
Cokolwiek wybierzesz, zapewnij bezpieczne sesje (krótkie tokeny, strategia odświeżania, bezpieczne ciasteczka) i dodaj MFA dla kont administracyjnych.
Zapobiegaj najczęstszym atakom zanim się pojawią
Nałóż rate limiting na logowanie, tworzenie ticketów i endpointy wyszukiwania, by spowolnić brute-force i spam. Waliduj i sanitizuj wejścia, by zapobiec iniekcjom i niebezpiecznemu HTML w komentarzach.
Jeśli używasz ciasteczek, dodaj ochronę CSRF. Dla API zastosuj restrykcyjne reguły CORS. Dla uploadów plików skanuj pod kątem malware i ograniczaj typy/rozmiary.
Kopie zapasowe, odzyskiwanie i mierzalne cele
Zdefiniuj RPO/RTO (ile danych możesz stracić, jak szybko musisz wrócić). Automatyzuj backupy dla baz i przechowywania plików i — co ważniejsze — testuj przywracanie regularnie. Kopia, której nie da się przywrócić, nie jest kopią.
Podstawy prywatności, o które klienci zapytają
Aplikacje wsparcia często podlegają wnioskom o prywatność. Zapewnij sposób eksportu i usuwania danych klienta i udokumentuj, co jest usuwane, a co zatrzymywane z powodów prawnych/auditowych. Trzymaj logi audytu i dostępu dostępne dla administratorów, by szybko badać incydenty.
Testuj, uruchamiaj i poprawiaj z rzeczywistymi zespołami wsparcia
Wdrożenie aplikacji wsparcia klienta to nie koniec — to początek nauki, jak prawdziwi agenci pracują pod presją. Celem testów i rolloutu jest zabezpieczenie codziennej obsługi, jednocześnie weryfikując, że system ticketowy i zarządzanie SLA działają poprawnie.
Napisz scenariusze end-to-end odpowiadające realnej pracy
Poza testami jednostkowymi udokumentuj (i zautomatyzuj, gdzie możliwe) kilka scenariuszy E2E, które odzwierciedlają najwyższe ryzyka:
- Tworzenie ticketu: intake z e-maila/weba/API tworzy ticket z właściwymi polami, tożsamością klienta i początkowym statusem.
- Odpowiedzi i wątkowanie: odpowiedzi klienta trafiają do właściwego ticketu, odpowiedzi agenta powiadamiają klienta, notatki wewnętrzne pozostają prywatne.
- Naruszenia SLA: timery start/stop działają poprawnie (np. pauza na „Oczekuje na klienta”), naruszenia uruchamiają odpowiednie eskalacje, a ślad audytu rejestruje, co się stało.
- Wyszukiwanie KB: agenci szybko znajdują odpowiednie artykuły z widoku ticketu, a klienci widzą sugestie przed wysłaniem zgłoszenia.
Jeśli masz środowisko stagingowe, zasil je realistycznymi danymi (klienci, tagi, kolejki, godziny pracy), żeby testy nie przeszły „teoretycznie”.
Uruchom pilota i zbieraj feedback co tydzień
Zacznij od małej grupy wsparcia (albo jednej kolejki) na 2–4 tygodnie. Ustal tygodniowy rytuał feedbacku: 30 minut na przegląd, co spowalniało, co myliło klientów i które reguły powodowały niespodzianki.
Trzymaj feedback ustrukturyzowany: „Jakie zadanie?”, „Czego się spodziewałeś?”, „Co się stało?” i „Jak często to występuje?” — pomoże to priorytetyzować poprawki wpływające na przepustowość i zgodność SLA.
Stwórz checklistę onboardingu dla adminów i agentów
Uczyń onboarding powtarzalnym, by rollout nie zależał od jednej osoby.
Dołącz podstawy: logowanie, widoki kolejek, odpowiadanie vs. notatka wewnętrzna, przypisywanie/wzmiankowanie, zmiana statusu, używanie makr, czytanie wskaźników SLA i znajdowanie/tworzenie artykułów KB. Dla adminów: zarządzanie rolami, godzinami pracy, tagami, automatyzacjami i podstawami raportowania.
Zaplanuj etapowy rollout (z opcją rollback)
Wdrażaj po zespołach, kanałach lub typach ticketów. Zdefiniuj ścieżkę rollback przed czasem: jak tymczasowo przekierujesz intake, jakie dane trzeba będzie synchronizować i kto podejmuje decyzję.
Zespoły budujące na Koder.ai często używają snapshotów i rollbacku podczas wczesnych pilotów, by bezpiecznie iterować nad workflow (kolejki, SLA i formularze portalu) bez przerywania operacji.
Ustal roadmapę iteracji
Gdy pilot się ustabilizuje, planuj poprawki falami:
- Lepsze reguły automatyzacji (makra, triggery, auto-tagging)
- Zaawansowane routowanie (przypisanie wg umiejętności, balansowanie obciążenia)
- Bogatsze workflowy KB (przeglądy artykułów, pętle feedbacku, metryki odciążenia)
Traktuj każdą falę jak małe wydanie: testuj, pilotażuj, mierz, potem rozszerzaj.