Jak zbudować aplikację webową, która dokładnie śledzi zgodność ze SLA
Dowiedz się, jak zaprojektować i zbudować aplikację webową śledzącą zgodność ze SLA: zdefiniuj metryki, zbieraj zdarzenia, licz wyniki, alertuj o naruszeniach i raportuj rzetelnie.
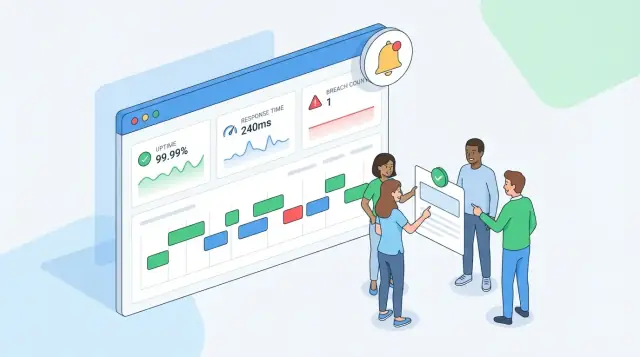
Zdefiniuj zgodność SLA i to, co budujesz
Zgodność ze SLA oznacza dotrzymanie mierzalnych zobowiązań w Service Level Agreement (SLA) — umowie między dostawcą a klientem. Zadaniem twojej aplikacji jest odpowiedzieć prostym dowodem na pytanie: Czy spełniliśmy to, co obiecaliśmy, dla tego klienta, w tym okresie?
Warto rozdzielić trzy powiązane pojęcia:
- SLI (Service Level Indicator): surowy pomiar (np. „procent pomyślnych kontroli”, „czas do pierwszej odpowiedzi”, „czas przywrócenia usługi”).
- SLO (Service Level Objective): wewnętrzny cel dla SLI (często ostrzejszy niż SLA). Przykład: „cel 99,95% dostępności”.
- SLA: zewnętrzne zobowiązanie, często powiązane z kredytami lub karami. Przykład: „99,9% miesięcznej dostępności”.
Typowe metryki SLA, które będziesz śledzić
Większość aplikacji do śledzenia SLA zaczyna od niewielkiego zestawu metryk, które odpowiadają rzeczywistym danym operacyjnym:
- Dostępność / uptime: procent czasu, gdy usługa jest „dostępna” w okresie raportowania.
- Czas odpowiedzi (support): od momentu utworzenia zgłoszenia do pierwszej odpowiedzi od człowieka.
- Czas rozwiązania: od utworzenia incydentu/tiketu do zamknięcia lub przywrócenia.
- Okna dostępności: reguły typu „liczyć tylko godziny pracy”, „wyłączyć planowane prace konserwacyjne” lub „mierzyć tylko od 08:00–18:00 w strefie klienta”.
Kto korzysta z aplikacji — i dlaczego
Różne osoby chcą tej samej prawdy, przedstawionej inaczej:
- Ops/SRE: wykrywać naruszenia wcześnie i weryfikować linię czasu incydentów.
- Zespoły wsparcia: śledzić zobowiązania odpowiedzi i rozwiązania per klient.
- Managerowie: widzieć trendy, ryzyko i czy zespoły konsekwentnie osiągają cele.
- Klienci: przeglądać przejrzyste raporty (czasem stronę statusową) pokazujące, co się wydarzyło.
Co budujesz (a czego nie)
Produkt dotyczy śledzenia, dowodów i raportowania: zbierania sygnałów, stosowania uzgodnionych reguł i generowania wyników zgodnych z audytem. To nie gwarantuje wydajności; mierzy ją — dokładnie, konsekwentnie i w sposób, który potem możesz obronić.
Wymagania: metryki, reguły i kto czego potrzebuje
Zanim zaprojektujesz tabele lub napiszesz kod, jasno określ, co „zgodność” znaczy dla twojego biznesu. Większość problemów ze śledzeniem SLA nie jest techniczna — to problemy z wymaganiami.
Zbierz dane wejściowe (nie ufaj pamięci)
Zacznij od zebrania źródeł prawdy:
- Umowy z klientami i MSA (wraz z załącznikami i dodatkami ticketowymi)
- Poziomy usług (np. Basic vs Premium) i mapowanie klientów do poziomów
- Godziny pracy i strefy czasowe per klient (lub per usługa)
- Wyłączenia i reguły specjalne: planowane okna konserwacji, siła wyższa, opóźnienia z winy klienta, zależności stron trzecich, okresy karencji
Zapisz je jako jawne reguły. Jeśli reguły nie da się jasno sformułować, nie da się ich rzetelnie policzyć.
Zdecyduj, co trzeba śledzić
Wypisz rzeczy, które rzeczywiście mogą wpłynąć na liczbę SLA:
- Incydenty/przerwy (początek, koniec, ważność, dotknięte usługi)
- Zgłoszenia/tikety (utworzone, pierwsza odpowiedź, rozwiązanie, oczekiwanie na klienta)
- Konserwacje (planowane vs awaryjne; czy liczyć je do dostępności)
- Częściowe przerwy (pogorszenie wydajności) i czy w ogóle je liczyć
Określ też, kto czego potrzebuje: support chce ryzyka naruszenia w czasie rzeczywistym, managerowie tygodniowe zliczenia, klienci proste podsumowania.
Wybierz 1–3 metryki na pierwszy release
Utrzymaj zakres mały. Wybierz minimalny zestaw, który udowodni działanie systemu end-to-end, np.:
- Procent dostępności usługi w miesiącu
- Czas reakcji na incydent (pierwsza odpowiedź) w godzinach pracy
- Czas do rozwiązania dla incydentów o najwyższej ważności
Lista kontrolna wymagań i kryteria sukcesu
Stwórz jednostronicową checklistę, którą możesz potem przetestować:
- Jasne definicje metryk (timestamps start/stop, strefa czasowa, zaokrąglanie)
- Reguły włączeń/wyłączeń (konserwacje, czas oczekiwania klienta)
- Progi per poziom (np. 99.9%, 1-godzinna odpowiedź)
- Wymagania wyjścia (raport dla klienta, dashboard wewnętrzny, eksport)
Sukces to sytuacja, w której dwie osoby obliczają przykładowy miesiąc ręcznie i twoja aplikacja daje identyczny wynik.
Model danych dla SLA, usług, incydentów i zdarzeń
Poprawny tracker SLA zaczyna się od modelu danych, który potrafi wyjaśnić dlaczego wynik jest taki, a nie inny. Jeśli nie możesz prześledzić miesięcznej dostępności do konkretnych zdarzeń i reguł, będziesz miał spory z klientami i wewnętrzne niepewności.
Główne byty (trzymaj je nudnymi i jednoznacznymi)
Przynajmniej zamodeluj:
- Customer (tenant/account): właściciel usług, kalendarzy, kontaktów i ustawień raportowania.
- Service: to, co jest mierzone (API, aplikacja webowa, komponent specyficzny dla regionu). Dodaj opcjonalną relację parent/child jeśli będziesz rolować komponenty.
- Plan: opakowanie komercyjne (np. “Gold”), używane do przypisania domyślnych polityk SLA.
- SLA policy: mierzalne reguły: cel dostępności, cel czasu odpowiedzi, okno pomiarowe i co jest „wyłączone”.
- Incident: przyjazne dla człowieka grupowanie (tytuł, ważność, linia czasu) odwołujące się do zdarzeń.
- Event: niezmienne fakty (zmiany stanu, sygnały monitoringu, potwierdzenia) napędzające obliczenia.
Przydatna relacja: customer → service → SLA policy (może przez plan). Incydenty i zdarzenia odnoszą się do usługi i klienta.
Minimalny schemat do śledzenia czasu
Błędy związane z czasem są główną przyczyną niepoprawnej matematyki SLA. Przechowuj:
occurred_atjako UTC (timestamp z semantyką strefy czasowej)received_at(kiedy system to zobaczył)source(nazwa monitora, integracja, manualne)external_id(do deduplikacji powtórzeń)payload(surowy JSON do przyszłego debugowania)
Przechowuj też customer.timezone (IANA, np. America/New_York) do wyświetlania i logiki godzin pracy, ale nie używaj go do przepisywania czasu zdarzenia.
Godziny pracy i święta
Jeśli SLA dotyczące czasu reakcji zatrzymują licznik poza godzinami pracy, modeluj kalendarze jawnie:
working_hoursper customer (lub per region/service): dzień tygodnia + start/koniecholiday_calendarpowiązany z regionem lub klientem, z zakresami dat i etykietami
Trzymaj reguły jako dane, żeby ops mógł zaktualizować święto bez deployu.
Audytowalność: surowe vs obliczone
Przechowuj surowe zdarzenia w tabeli append-only i oddzielnie wyniki obliczeń (np. sla_period_result). Każdy wiersz wyniku powinien zawierać: granice okresu, wersję wejścia (wersja polityki + wersja silnika) oraz referencje do użytych identyfikatorów zdarzeń. To pozwala bezpiecznie przeliczać i daje ślad audytowy, gdy klienci pytają: „Które minuty przerwy zostały policzone?”
Ingestia zdarzeń: jak dane trafiają do aplikacji
Twoje liczby SLA są tak wiarygodne, jak zdarzenia, które przyjmujesz. Cel jest prosty: uchwycić każdą zmianę, która ma znaczenie (rozpoczęcie przerwy, potwierdzenie incydentu, przywrócenie usługi) z konsekwentnymi znacznikami czasu i wystarczającym kontekstem do późniejszego obliczenia zgodności.
Typowe źródła zdarzeń
Większość zespołów łączy dane z różnych systemów:
- Ticketing / incident tools (Jira Service Management, ServiceNow, Zendesk): timestamps utworzenia/potwierdzenia/rozwiązania, zmiany priorytetu, zmiany przypisań.
- Monitoring (Pingdom, Datadog, CloudWatch, Prometheus Alertmanager): sygnały up/down, alert fired/cleared, wyniki sprawdzeń syntetycznych.
- Logi infra i aplikacji: deploye, skoki błędów, niepowodzenia health checków (przydatne, gdy monitoring jest hałaśliwy lub brakujący).
- Wpisy manualne: małe UI do „biznesowo potwierdzonego startu/końca przerwy” lub „rozpoczęcia okna konserwacji” gdy automatyka nie zna prawdy.
Opcje ingestii (i kiedy ich używać)
Webhooks zwykle najlepiej dla dokładności w czasie rzeczywistym i mniejszego obciążenia: system źródłowy pushuje zdarzenia do twojego endpointu.
Polling to fallback, gdy brak webhooków: aplikacja okresowo pobiera zmiany od ostatniego kursora. Trzeba obsłużyć limity i ostrożną logikę „since”.
Import CSV pomaga przy backfillach i migracjach. Traktuj go jako pełnoprawną ścieżkę ingestii, żeby móc reprocessować historyczne okresy bez hacków.
Rekomendowany format zdarzenia (z idempotency)
Normalizuj wszystko do jednego wewnętrznego kształtu „event”, nawet jeśli upstreamy różnią się payloadami:
event_id(wymagane): unikalne i stabilne przy retryach. Preferuj GUID źródła lub wygeneruj deterministyczny hash.source(wymagane): np.datadog,servicenow,manual.event_type(wymagane): np.incident_opened,incident_acknowledged,service_down,service_up.occurred_at(wymagane): czas zdarzenia (nie czas odbioru), ze strefą czasową.received_at(system): kiedy twoja aplikacja to przyjęła.service_id(wymagane): SLA-relewantna usługa, której zdarzenie dotyczy.incident_id(opcjonalne, zalecane): łączy wiele zdarzeń w incydent.attributes(opcjonalne): priorytet, region, segment klienta itp.
Przechowuj event_id z unikalnym ograniczeniem, by uczynić ingestę idempotentną: retry nie utworzy duplikatów.
Reguły walidacji, które zapobiegają złym danym
Odrzucaj lub kwarantannuj zdarzenia, które:
- Mają brakujące/nieprawidłowe znaczniki czasu lub
occurred_atdalece w przyszłości. - Nie mapują do znanego
service_id(lub wymagaj explicite workflow „unmapped”). - Duplikują istniejące
event_id. - Przybywają w złej kolejności w sposób, który łamie reguły (oznacz je jako „needs review” zamiast cicho nadpisywać).
Ta dyscyplina na wejściu oszczędza kłótni o raporty SLA później — bo będziesz mieć czyste, śledzalne wejścia.
Silnik obliczeń SLA: jak zdarzenia stają się zgodnością
Twój silnik obliczeń to miejsce, gdzie „surowe zdarzenia” stają się wynikami SLA, które możesz obronić. Kluczowe jest traktowanie tego jak księgowości: deterministyczne reguły, jasne wejścia i możliwy do powtórzenia przebieg.
Zacznij od znormalizowanej osi czasu
Skonwertuj wszystko do jednego uporządkowanego strumienia per incydent (lub per wpływ na usługę):
- timestamps (UTC) dla: incydent rozpoczęty, potwierdzony/pierwsza odpowiedź, złagodzony, rozwiązany, ponownie otwarty
- zmiany stanu: pauza/wznów, oczekiwanie na klienta, aktywne okno konserwacji
- zakres: które usługi i klienci są dotknięci i z jaką ważnością
Z tej osi czasu obliczaj okresy przez sumowanie interwałów, nie przez bezmyślne odejmowanie dwóch timestamów.
Time-to-first-response (TTFR) i time-to-resolution (TTR)
Zdefiniuj TTFR jako upływ „liczonych” minut między incident_start a first_agent_response (lub acknowledged, zależnie od brzmienia SLA). Zdefiniuj TTR jako upływ „liczonych” minut między incident_start a resolved.
„Liczony” oznacza usuwanie interwałów, które nie powinny być wliczane:
- poza godzinami pracy (dla SLA liczących tylko godziny pracy)
- explicite pauzy (np. „oczekiwanie na klienta”)
- wyłączenia takie jak planowana konserwacja lub opóźnienia spowodowane klientem
Szczegół implementacyjny: przechowuj funkcję kalendarza (godziny pracy, święta) i funkcję reguły, która bierze oś czasu i zwraca opłacalne interwały.
Częściowe przerwy i incydenty dotykające wiele usług
Zdecyduj wcześniej, czy liczyć:
- SLA per usługę (zalecane): jeden incydent może wygenerować wiele rekordów wpływu na usługę, każdy z własnym TTFR/TTR
- SLA per klienta: ta sama awaria może dotykać tylko podzbiór tenantów
Dla częściowych przerw ważkuj według wpływu tylko jeśli umowa to wymaga; w przeciwnym razie traktuj „degraded” jako osobną kategorię naruszenia.
Śledzalność: przechowuj wejścia, wyjścia i replaye
Każde obliczenie powinno być odtwarzalne. Persistuj:
- dokładne zdarzenia użyte (z id, timestampami i źródłem)
- wyprowadzone interwały (co zostało wyłączone i dlaczego)
- końcowe wyniki (TTFR, TTR, flagi naruszenia i wersja reguły)
Gdy reguły się zmieniają, możesz przeliczyć wyniki po wersji bez przepisywania historii — kluczowe dla audytów i sporów z klientami.
Logika raportowania: okresy, dostępność i przypadki brzegowe
Raportowanie to moment, w którym tracker SLA zyskuje zaufanie — albo je traci. Twoja aplikacja powinna jasno pokazywać jaki zakres czasu jest mierzony, które minuty się liczą i jak uzyskano końcowe liczby.
Okresy: kalendarzowe, rozliczeniowe i rolling
Wspieraj powszechne okresy raportowe używane przez klientów:
- Kalendarz miesięczny/kwartalny (np. 1–31 marca)
- Cykl rozliczeniowy (np. 15.–14., zgodny z fakturami)
- Rolling windows (np. „ostatnie 30 dni” aktualizowane codziennie)
Przechowuj okresy jako jawne start/end timestamps (nie „miesiąc = 3”), żeby móc odtworzyć obliczenia później.
Dostępność: minuty całkowite vs minuty uprawnione
Częstym źródłem nieporozumień jest, czy mianownik to cały okres, czy tylko „uprawniony” czas. Zdefiniuj dwie wartości per okres:
- Eligible minutes: minuty, które liczą się do SLA (często wyłączają konserwacje, awarie z winy klienta lub czasy poza godzinami wsparcia)
- Downtime minutes: uprawnione minuty, gdy usługa jest uznana za niedostępną
Następnie oblicz:
availability_percent = 100 * (eligible_minutes - downtime_minutes) / eligible_minutes
Jeśli eligible minutes mogą wynosić zero (np. usługa monitorowana tylko w godzinach pracy i okres ich nie zawiera), zdefiniuj regułę: „N/A” lub traktuj jako 100% — ale bądź konsekwentny i udokumentuj to.
Przekład liczb na jasne pass/fail
Większość SLA potrzebuje zarówno procentu, jak i wyniku binarnego.
- Procent: np. 99.95% za okres
- Pass/Fail: porównaj z celem SLA (np. pass jeśli ≥ 99.9%)
Trzymaj też „distance to breach” (pozostały budżet przerwy), żeby dashboardy mogły ostrzegać przed przekroczeniem progu.
Przypadki brzegowe, które musisz obsłużyć świadomie
- Strefy czasowe: wybierz strefę raportową per klient/kontrakt (często strefa klienta) i konwertuj zdarzenia konsekwentnie.
- Czas letni (DST): nie zakładaj, że dzień ma 1440 minut. Używaj znaczników czasu z uwzględnieniem strefy, by długość okresu była poprawna przy przejściach DST.
- Brak czasu zakończenia: incydenty czasem nie mają resolved timestamp. Traktuj je jako „otwarte” i ogranicz do końca raportu, oznaczając rekord do wyczyszczenia.
Na koniec, przechowuj surowe wejścia (włączone/wyłączone zdarzenia i korekty), by każdy raport mógł odpowiedzieć „dlaczego ta liczba wygląda tak, a nie inaczej?” bez ręcznych wyjaśnień.
UI i dashboardy, które jasno pokazują status SLA
Silnik obliczeń może być perfekcyjny, ale użytkownicy go odrzucą, jeśli UI nie odpowie natychmiast: „Czy teraz spełniamy SLA i dlaczego?” Projektuj aplikację tak, by każdy ekran zaczynał od jasnego statusu, a potem pozwalał wgłębić się w liczby i surowe zdarzenia.
Główne widoki do zbudowania
Dashboard przeglądowy (dla operatorów i managerów). Wypisz kilka kafli: zgodność bieżącego okresu, dostępność, zgodność czasu odpowiedzi i „czas pozostały do naruszenia” tam, gdzie ma to sens. Stosuj jasne etykiety (np. „Dostępność (ten miesiąc)” zamiast „Uptime”). Jeśli wspierasz wiele SLA na klienta, pokaż najgorszy status najpierw i pozwól rozwijać widok.
Szczegóły klienta (dla zespołów kont i raportów dla klientów). Strona klienta powinna podsumować wszystkie usługi i poziomy SLA dla klienta, z prostym stanem pass/warn/fail i krótkim wyjaśnieniem („liczono 2 incydenty; policzono 18m przerwy”). Dodaj linki do tekstu /status (jeśli oferujesz stronę statusową) i eksportu raportu.
Szczegóły usługi (do głębokiej analizy). Tutaj pokaż dokładne reguły SLA, okno obliczeń i rozbicie tego, jak powstała liczba zgodności. Dodaj wykres dostępności w czasie i listę incydentów, które wpłynęły na SLA.
Oś czasu incydentu (do audytów). Widok pojedynczego incydentu powinien pokazywać linię czasu zdarzeń (wykryty, potwierdzony, złagodzony, rozwiązany) i które timestampy użyto do metryk „odpowiedź” i „rozwiązanie”.
Filtry odpowiadające realnym pytaniom
Utrzymuj filtry spójne: zakres dat, klient, usługa, poziom, ważność. Używaj tych samych jednostek wszędzie (minuty vs sekundy; procenty z tymi samymi miejscami po przecinku). Gdy użytkownik zmieni zakres dat, zaktualizuj wszystkie metryki na stronie, by nie było niespójności.
Drill-down bez utraty zaufania
Każda metryka podsumowująca powinna mieć ścieżkę „Dlaczego?”:
- Z procentu zgodności → lista policzonych incydentów w tym okresie.
- Z incydentu → surowe zdarzenia i wyprowadzone timestampy użyte w obliczeniach.
- Z dostępności → interwały przerwy z podaniem źródła (zdarzenie monitoringu vs korekta manualna).
Używaj tooltipów oszczędnie do definiowania terminów jak „Wyłączona przerwa” lub „Godziny pracy” i pokaż dokładny tekst reguły na stronie usługi, by ludzie nie zgadywali.
Utrzymaj prostotę, ale jednoznaczność
Wybieraj zwykły język zamiast skrótów („Czas odpowiedzi” zamiast „MTTA”, chyba że odbiorcy oczekują skrótu). Dla statusu łącz kolor z tekstem („Ryzyko: wykorzystano 92% budżetu błędów”), by uniknąć dwuznaczności. Jeśli aplikacja wspiera logi audytu, dodaj małe okienko „Ostatnia zmiana” przy regułach SLA z odniesieniem do /settings/audit-log, żeby użytkownicy mogli zweryfikować kiedy definicje się zmieniły.
Alerty i powiadomienia dotyczące naruszeń
Alertowanie to moment, gdy aplikacja SLA przestaje być pasywnym raportem i zaczyna pomagać zespołom unikać kar. Najlepsze alerty są terminowe, konkretne i wykonalne — mówią, co zrobić dalej, a nie tylko, że „coś jest złe”.
Definiuj wyzwalacze odpowiadające realnym decyzjom
Zacznij od trzech typów wyzwalaczy:
- Zbliżające się naruszenie: np. „Pozostało 30 minut budżetu odpowiedzi” lub „Dostępność tego miesiąca spadła do 99.92%, SLA to 99.9%.” To najcenniejszy alert, bo pozwala działać.
- Naruszenie nastąpiło: odpalany, kiedy silnik obliczeń potwierdzi, że SLA nie został spełniony za dany okres.
- Powtarzające się naruszenia: wykrywaj wzorce jak „3 naruszenia w 30 dni” lub „ta sama usługa naruszona 2 razy w tygodniu”, co zwykle wskazuje na problem systemowy.
Uczyń wyzwalacze konfigurowalnymi per klient/usługa/SLA, bo różne umowy tolerują różne progi.
Wybierz kanały i rób komunikaty wykonalnymi
Wysyłaj alerty tam, gdzie ludzie naprawdę reagują:
- Email dla powiadomień audytowalnych i interesariuszy zewnętrznych.
- Slack dla szybkiej wewnętrznej koordynacji.
- SMS (opcjonalnie) dla eskalacji wysokiego priorytetu.
Każdy alert powinien zawierać deep linki do /alerts, /customers/{id}, /services/{id} i do strony incydentu, żeby reagujący mogli szybko zweryfikować liczby.
Redukcja szumu: deduplikacja, ciche godziny, eskalacja
Wdroż deduplikację przez grupowanie alertów o tym samym kluczu (klient + usługa + SLA + okres) i tłumienie powtórek przez okno cooldown. Dodaj ciche godziny (per strefę czasową zespołu), żeby niekrytyczne alerty „zbliżające się do naruszenia” czekały do godzin pracy; za to „naruszenie nastąpiło” może nadpisać ciche godziny jeśli ważność jest wysoka.
Na końcu wspieraj reguły eskalacji (np. powiadom on-call po 10 minutach, eskaluj do managera po 30), by alerty nie ugrzęzły w jednej skrzynce.
Kontrola dostępu, uwierzytelnienie i logi audytu
Dane SLA są wrażliwe, bo ujawniają wydajność wewnętrzną i przywileje klienta. Traktuj kontrolę dostępu jako część „matematyki SLA”: ten sam incydent może dać różne wyniki zależnie od tego, której umowy klienta dotyczy.
Role do wsparcia od pierwszego dnia
Zacznij od prostych ról, potem dodawaj bardziej szczegółowe uprawnienia.
- Admin: konfiguruje globalne ustawienia, zarządza usługami, SLA, użytkownikami, integracjami i fakturowaniem.
- Agent: tworzy/aktualizuje incydenty i okna konserwacji, dołącza zdarzenia i dodaje notatki postmortem.
- Manager: ma dostęp do odczytu wszystkiego w swoim zakresie, zatwierdza definicje SLA i eksportuje raporty.
- Customer viewer: widzi tylko swoje usługi, cele SLA, historię incydentów i raporty dla klienta.
Praktyczny domyśl to RBAC + tenant scoping:
- Każdy rekord (service, SLA policy, report) ma właściciela tenant/klienta.
- Użytkownicy wewnętrzni mogą mieć zakres wielu tenantów; widzowie-klienci dokładnie jednego.
- Uprawnienia edycji są węższe niż odczytu: np. agenci mogą edytować incydenty, ale nie zmieniać reguł SLA.
Co każda rola może widzieć/edytować
Bądź jawny wobec danych specyficznych dla klienta:
- Widok klienta nigdy nie powinien widzieć pól wewnętrznych (hipotezy root cause, wewnętrzna ważność, notatki on-call, prywatne tagi).
- Polityki SLA powinny być wersjonowane, żeby klient widział warunki SLA obowiązujące w czasie incydentu.
Opcje uwierzytelniania, które nie zamkną ci drogi
Zacznij od email/hasło i wymagaj MFA dla ról wewnętrznych. Planuj SSO później (SAML/OIDC) przez oddzielenie tożsamości od autoryzacji. Dla integracji wydawaj klucze API przypisane do kont serwisowych z wąskimi zakresami i możliwością rotacji.
Logi audytu, za które będziesz wdzięczny
Dodaj niezmienne wpisy audytu dla:
- Zmian reguł SLA (progi, kalendarze, wyłączenia, mapowanie do usług/klientów)
- Edycji incydentów (timestamps, przejścia statusów, ręczne nadpisania przestojów)
- Zmian uprawnień i kluczy API
Przechowuj kto, co się zmieniło (przed/po), kiedy, skąd (IP/user agent) i identyfikator korelacji. Uczyń logi audytu przeszukiwalnymi i eksportowalnymi (np. /settings/audit-log).
API do integracji i automatyzacji
Aplikacja śledząca SLA rzadko działa samotnie. Potrzebujesz API, które pozwoli narzędziom monitorującym, systemom ticketowym i wewnętrznym workflowom tworzyć incydenty, pushować zdarzenia i pobierać raporty bez ręcznej pracy.
Zacznij od małej, przewidywalnej powierzchni
Użyj wersjonowanej ścieżki bazowej (np. /api/v1/...), by ewoluować payloady bez łamania integracji.
Podstawowe endpointy:
- Events:
POST /api/v1/eventsdo ingestowania zmian stanu (up/down, próbki latencji, okna konserwacji).GET /api/v1/eventsdo audytu i debugowania. - Incidents:
POST /api/v1/incidents,PATCH /api/v1/incidents/{id}(acknowledge, resolve, assign),GET /api/v1/incidents. - SLAs:
GET /api/v1/slas,POST /api/v1/slas,PUT /api/v1/slas/{id}do zarządzania kontraktami i progami. - Reports:
GET /api/v1/reports/sla?service_id=...&from=...&to=...do podsumowań zgodności. - Alerts:
POST /api/v1/alerts/subscriptionsdo zarządzania webhookami/emailami;GET /api/v1/alertsdo historii alertów.
Ujednolicona paginacja i filtrowanie
Wybierz jedną konwencję i stosuj ją wszędzie. Na przykład: limit, paginacja cursor, plus standardowe filtry service_id, sla_id, status, from, to. Trzymaj sortowanie przewidywalne (np. sort=-created_at).
Zdefiniuj odpowiedzi błędów, na których mogą polegać integratorzy
Zwracaj strukturalne błędy z polem stabilnym:
{ "error": { "code": "VALIDATION_ERROR", "message": "service_id is required", "fields": { "service_id": "missing" } } }
Używaj jasnych statusów HTTP (400 walidacja, 401/403 auth, 404 not found, 409 conflict, 429 rate limit). Dla ingestii zdarzeń rozważ idempotencję (Idempotency-Key) by retry nie duplikował incydentów.
Limity i podstawowe zabezpieczenia
Nakładaj rozsądne limity per token (i ostrzejsze dla endpointów ingestujących), sanityzuj wejścia i waliduj znaczniki czasu/strefy. Preferuj tokeny API o wąskich zakresach (read-only vs write), i loguj, kto wywołał który endpoint (szczegóły w sekcji logów audytu /blog/audit-logs).
Strategia testów: udowodnij, że liczby są poprawne
Liczby SLA są użyteczne tylko, jeśli ludzie im ufają. Testowanie aplikacji SLA powinno skupiać się mniej na „czy strona się ładuje”, a bardziej na „czy matematyka czasu działa dokładnie tak, jak mówi umowa”. Traktuj reguły obliczeń jak produkt z własnym zestawem testów.
Unit-testuj reguły z ustalonymi osiami czasu
Zacznij od testów jednostkowych silnika obliczeń z deterministycznymi wejściami: oś czasu zdarzeń (incydent otwarty, potwierdzony, złagodzony, rozwiązany) i jasno zdefiniowanymi regułami SLA.
Używaj stałych timestampów i „zamrażaj czas”, by testy nie zależały od zegara. Pokryj przypadki brzegowe:
- Incydent zaczyna się przed okresem raportowym i kończy w jego trakcie
- Nakładające się incydenty (czy przerwy scalać, czy nakładać?)
- Wiele pauz (konserwacje, oczekiwanie na klienta)
- Graniczne minuty/sekundy (dokładnie o 00:00, koniec miesiąca, rok przestępny)
Testy end-to-end dla całego pipeline’u
Dodaj kilka testów E2E, które przechodzą cały flow: ingest wydarzeń → oblicz zgodność → wygeneruj raport → wyrenderuj UI. One wychwycą niezgodności między „co silnik obliczył” a „co pokazuje dashboard”. Trzymaj scenariusze nieliczne, ale wysokowartościowe i asercje na końcowych liczbach (availability %, breach yes/no, time-to-ack).
Reużywalne fikstury dla kalendarzy i stref czasowych
Stwórz testowe fixture’y dla godzin pracy, świąt i stref czasowych. Chcesz powtarzalne przypadki jak „incydent w piątek 17:55 czasu lokalnego” i „święto przesuwa liczenie czasu reakcji”.
Monitoruj samą aplikację SLA
Testowanie nie kończy się deployem. Dodaj monitoring jobów, wielkości kolejek, czasu przeliczeń i wskaźników błędów. Jeśli ingestia się opóźnia lub nocne joby padają, raport SLA może być nieprawidłowy nawet jeśli kod jest poprawny.
Wdrożenie, eksploatacja i praktyczna mapa drogowa MVP
Wypuszczenie aplikacji SLA to mniej kwestia wyrafinowanej infrastruktury, a więcej przewidywalnej operacji: obliczenia muszą odbywać się na czas, dane muszą być bezpieczne, a raporty odtwarzalne.
Prosta, niezawodna ścieżka wdrożeniowa
Zacznij od usług zarządzanych, by skupić się na poprawności:
- Zarządzana baza (PostgreSQL): automatyczne backupy, point-in-time recovery, szyfrowanie.
- Hosting kontenerów dla web/API (np. PaaS): łatwe rollbacki i spójne środowiska.
- Storage obiektowy dla eksportów (CSV/PDF) i dużych artefaktów, z regułami lifecycle.
Utrzymuj środowiska minimalne: dev → staging → prod, każde z własną bazą i sekretami.
Procesy backgroundowe potrzebne od pierwszego dnia
Tracker SLA to nie tylko request/response; potrzebujesz prac okresowych.
- Joby obliczeniowe: przeliczaj okna SLA po nowych zdarzeniach i uruchamiaj ponownie po spóźnionej ingestii.
- Generowanie raportów: podsumowania dzienne/miesięczne, eksporty dla klientów.
- Higiena danych: archiwizacja surowych zdarzeń, kompaktowanie tabel pochodnych, weryfikacja integralności.
Uruchamiaj joby przez worker + queue lub managed scheduler wywołujący wewnętrzne endpointy. Rób joby idempotentnymi i loguj każdy przebieg dla audytu.
Retencja i eksporty (bez zbytnich obietnic)
Zdefiniuj retencję per typ danych: trzymaj wyniki obliczeń dłużej niż surowe zdarzenia. Dla eksportów zaoferuj najpierw CSV (szybkie, przejrzyste), potem szablony PDF. Bądź jasny: eksporty to „best-effort formatowanie”, a baza danych pozostaje źródłem prawdy.
Fazy roadmapy, które trzymają zakres pod kontrolą
- MVP: jedna usługa, jedno SLA, jedna strefa czasowa, podstawowy dashboard + miesięczny raport.
- Więcej metryk: SLA czasu reakcji, okna konserwacji, wyjątki, wiele kalendarzy.
- Portal klienta: widoki per klient, kontrola dostępu, pobieralne raporty.
- Strona statusu: publiczne/prywatne strony oparte na obliczonej dostępności (zobacz /blog/status-pages).
Prototypowanie szybciej z Koder.ai (opcjonalnie)
Jeśli chcesz szybko zweryfikować model danych, przepływ ingestii i UI raportowania, platforma vibe-codingowa taka jak Koder.ai może pomóc stworzyć działający prototyp bez pełnego cyklu inżynieryjnego. Ponieważ Koder.ai generuje aplikacje przez chat (UI web + backend), to praktyczny sposób na szybkie postawienie:
- dashboardu React dla zgodności, budżetów błędów i osi czasu;
- backendu Go + PostgreSQL do przechowywania surowych zdarzeń i wyników okresów;
- endpointów eksportu/raportów i prostego portalu klienta.
Gdy wymagania i obliczenia zostaną potwierdzone (to najtrudniejsza część), możesz iterować, wyeksportować kod źródłowy i przejść do bardziej tradycyjnego trybu budowy i operacji — zachowując funkcje jak snapshoty i rollback podczas szybkiej iteracji.
Często zadawane pytania
Co oznacza „zgodność ze SLA” w aplikacji śledzącej SLA?
An SLA tracker answers one question with evidence: did you meet the contractual commitments for a specific customer and time period?
In practice, it means ingesting raw signals (monitoring, tickets, manual updates), applying the customer’s rules (business hours, exclusions), and producing an audit-friendly pass/fail plus supporting details.
Czym różnią się SLI, SLO i SLA — i dlaczego aplikacja powinna modelować je osobno?
Use:
- SLI for the raw measurement (e.g., successful checks %, time-to-first-response).
- SLO for your internal target (often stricter than the contract).
- SLA for the external commitment (often tied to credits).
Model them separately so you can improve reliability (SLO) without accidentally changing contractual reporting (SLA).
Które metryki SLA powinienem wdrożyć najpierw dla MVP?
A strong MVP usually tracks 1–3 metrics end-to-end:
- Availability % per service per month
- Time to first human response (TTFR) (often business-hours-only)
- Time to resolution (TTR) for high-severity incidents
These map cleanly to real data sources and force you to implement the tricky parts (periods, calendars, exclusions) early.
Jakie dane wejściowe są potrzebne zanim zaprojektuję bazę danych lub napisan kalkulator?
Requirements failures usually come from unstated rules. Collect and write down:
- Contract/SLA text (including addenda)
- Tier mapping (which customer is on which plan)
- Time zone and business hours per customer/service
- Explicit exclusions (maintenance, customer-caused delays, force majeure, grace periods)
If a rule can’t be expressed clearly, don’t try to “infer” it in code—flag it and get it clarified.
Jaki jest minimalny model danych dla wiarygodnego trackera SLA?
Start with boring, explicit entities:
- Customer (tenant)
- Service (what’s measured)
- Plan (commercial wrapper)
- SLA policy (targets + windows + exclusions)
- Incident (human-friendly container)
- Event (immutable facts used for math)
Aim for traceability: every reported number should link back to specific event IDs and a specific policy version.
Jak przechowywać znaczniki czasu i obsługiwać strefy czasowe (w tym DST)?
Store time correctly and consistently:
- Save
occurred_atin UTC with timezone semantics - Also store
received_at(when you ingested it) - Keep the customer’s IANA time zone for display and business-hours logic, not for rewriting history
Then make periods explicit (start/end timestamps) so you can reproduce reports later—even across DST changes.
Jak niezawodnie przyjmować zdarzenia bez duplikatów albo złych danych psujących raporty?
Normalize everything into a single internal event shape with a stable unique ID:
event_id(unique, stable across retries)source,event_type,occurred_at,service_id- Optional
incident_idandattributes
Enforce idempotency with a unique constraint on event_id. For missing mappings or out-of-order arrivals, quarantine/flag them—don’t silently “fix” the data.
Jak poprawnie obliczać TTFR/TTR gdy uwzględnione są godziny pracy, pauzy i wyłączenia?
Compute durations by summing intervals on a timeline, not by subtracting two timestamps.
Define “chargeable time” explicitly by removing intervals that don’t count, such as:
- outside business hours
- “waiting on customer” pauses
- scheduled maintenance (if excluded by policy)
Persist the derived intervals and the reason codes so you can explain exactly what was counted.
Jak obliczać dostępność (eligible minutes vs total minutes)?
Track two denominators explicitly:
- Eligible minutes (minutes that count toward the SLA)
- Downtime minutes (eligible minutes where the service is down)
Then calculate:
availability_percent = 100 * (eligible_minutes - downtime_minutes) / eligible_minutes
Also decide what happens if eligible minutes is zero (e.g., show N/A). Document this rule and apply it consistently.
Co powinny zawierać dashboardy i alerty, żeby były użyteczne (i niehałaśliwe)?
Make the UI answer “are we meeting the SLA, and why?” in one glance:
- Show current-period compliance plus “distance to breach” (remaining downtime budget)
- Provide a drill-down path: metric → counted incidents → raw events/intervals
- Keep labels explicit (“Availability (this month)”), and show the exact SLA rule text on the service page
For alerts, prioritize actionable triggers: approaching breach, breach occurred, and repeated violations—each linking to relevant pages like /customers/{id} or /services/{id}.