Co rozwiązuje scentralizowane zarządzanie powiadomieniami
Scentralizowane zarządzanie powiadomieniami oznacza traktowanie każdej wiadomości wysyłanej przez produkt — e-maile, SMS, push, bannery w aplikacji, Slack/Teams, callbacki webhooków — jako elementu jednego skoordynowanego systemu.
Zamiast pozwalać każdemu zespołowi funkcjonalnemu budować własną logikę „wyślij wiadomość”, tworzysz jedno miejsce, gdzie wpływają zdarzenia, reguły decydują, co się dzieje, a dostawy są śledzone end-to-end.
Ból, który eliminuje
Kiedy powiadomienia są rozproszone po usługach i kodzie, stale pojawiają się te same problemy:
- Duplikacja logiki: wiele zespołów powtarza retry, limity prędkości, wypisy i formatowanie.
- Niespójne komunikaty: ta sama wiadomość „reset hasła” czy „faktura gotowa” różni się między kanałami lub obszarami produktu, co myli użytkowników i support.
- Brak ścieżek audytu: gdy klient mówi „nie dostałem”, trudno odpowiedzieć, co wysłano, do kogo, kiedy i dlaczego.
Centralizacja zastępuje doraźne wysyłanie spójnym workflow: utwórz zdarzenie, zastosuj preferencje i reguły, wybierz szablony, dostarcz przez kanały i zapisz wyniki.
Kto korzysta
Hub powiadomień zwykle służy:
- Administratorom: konfigurują kanały, szablony, routing i reguły zgodności bez redeployów.
- Zespołom wsparcia: wyszukują i weryfikują próby dostarczenia, diagnozują błędy i odpowiadają z pewnością.
- Zespołom produktowym: szybciej wdrażają funkcje, emitując zdarzenia zamiast budować nowe pipeline’y powiadomień.
- Użytkownikom końcowym: kontrolują preferencje (opt-in/out, quiet hours, kanały) z przewidywalnymi efektami.
Jak wygląda sukces
Podejście działa, gdy:
- Liczba incydentów spada, ponieważ retry, throttling i fallbacki są znormalizowane.
- Zmiany (edycje treści, tweak routing, nowi odbiorcy) zajmują minuty — nie cykl wydawniczy.
- Raportowanie jest jasne: wskaźniki dostarczeń wg kanału, czas do dostarczenia, powody błędów i kto co zmienił.
Wymagania i zakres: kanały, przypadki użycia, ograniczenia
Zanim zaprojektujesz architekturę, sprecyzuj, co „scentralizowana kontrola powiadomień” znaczy dla twojej organizacji. Jasne wymagania utrzymają pierwszą wersję w ryzach i zapobiegną przeobrażeniu hubu w niedokończone CRM.
Zdefiniuj typy powiadomień (i dlaczego się różnią)
Zacznij od listy kategorii, które będziesz obsługiwać — one determinują reguły, szablony i zgodność:
- Transakcyjne: reset hasła, potwierdzenia płatności, zmiany konta. Zazwyczaj obowiązkowe i wrażliwe czasowo.
- Marketingowe: promocje, newslettery, ogłoszenia produktowe. Wymagają zgody (opt-in/opt-out).
- Alerty: ostrzeżenia bezpieczeństwa, awarie, podejrzane aktywności. Często pilne i mogą ominąć niektóre preferencje.
- Przypomnienia: spotkania, odnowienia, niedokończone zadania. Liczy się okno czasowe i throttling.
Bądź konkretny, do której kategorii należy każda wiadomość — to zapobiegnie „marketingowi podszytemu pod transakcyjny”.
Wybierz kanały: obsługuj teraz vs później
Wybierz niewielki zestaw, który potrafisz obsłużyć niezawodnie od pierwszego dnia, i udokumentuj kanały „później”, aby model danych ich nie blokował.
Obsługa teraz (typowe MVP): e-mail + jeden kanał realtime (push lub in-app) lub SMS, jeśli produkt tego wymaga.
Obsługa później: chaty (Slack/Teams), WhatsApp, voice, poczta tradycyjna, webhooki partnerów.
Zapisz też ograniczenia kanałów: limity prędkości, wymagania dostarczalności, tożsamości nadawcy (domeny, numery telefonów) i koszt za wysyłkę.
Ustal non-goals, aby chronić zakres
Scentralizowane zarządzanie powiadomieniami to nie to samo co „wszystko związane z klientem”. Typowe non-goals:
- Brak pełnego wzbogacania bazy kontaktów (trzymaj użytkowników/odbiorców minimalnie).
- Brak kreatora kampanii z segmentacją, testami A/B czy rozbudowanymi dashboardami analitycznymi.
- Brak workflow ticketów/escalation (integruj z istniejącymi narzędziami zamiast budować od nowa).
Wymagania zgodności i retencji
Uchwyć reguły wcześnie, by nie dopasowywać ich później na siłę:
- Opt-in/consent per kanał i typ powiadomienia (szczególnie marketing).
- Obsługa wypisania (one-click tam, gdzie wymagane) i listy supresji.
- Retencja: jak długo przechowywać treść wiadomości vs. metadane (np. 30/90/365 dni).
- Auditowalność: kto zmienił szablony, routing lub preferencje — i kiedy.
Jeśli masz już polityki, odnieś się do nich wewnętrznie (np. /security, /privacy) i traktuj je jako kryteria akceptacyjne dla MVP.
Wysoki poziom architektury hubu powiadomień
Hub powiadomień najłatwiej zrozumieć jako pipeline: zdarzenia wpływają, wiadomości wychodzą, a każdy krok jest obserwowalny. Oddzielenie odpowiedzialności ułatwia dodawanie kanałów później (SMS, WhatsApp, push) bez przepisywania wszystkiego.
Główne komponenty
1) Przyjmowanie zdarzeń (API + konektory). Twoja aplikacja, serwisy lub partnerzy zewnętrzni wysyłają zdarzenia „coś się stało” na jeden punkt wejścia. Typowe ścieżki to endpoint REST, webhooki lub bezpośrednie wywołania SDK.
2) Silnik routingu. Hub decyduje kogo powiadomić, przez które kanały i kiedy. Ta warstwa czyta dane odbiorcy i preferencje, ocenia reguły i tworzy plan dostarczenia.
3) Templating + personalizacja. Mając plan dostarczenia, hub renderuje wiadomość specyficzną dla kanału (HTML e-maila, tekst SMS, payload push) korzystając ze szablonów i zmiennych.
4) Workery dostarczające. Integrują się z dostawcami (SendGrid, Twilio, Slack itp.), obsługują retry i respektują limity prędkości.
5) Śledzenie + raportowanie. Każda próba jest rejestrowana: accepted, sent, delivered, failed, opened/clicked (gdy dostępne). To zasila panele admina i ścieżki audytu.
Przetwarzanie synchroniczne vs asynchroniczne
Używaj przetwarzania synchronicznego tylko do lekkiego intake (np. waliduj i zwróć 202 Accepted). W większości systemów kieruj i dostarczaj asynchronicznie:
- Kolekuj po przyjęciu aby chronić aplikację przed awariami dostawców i skokami ruchu.
- Oddziel kolejki per kanał lub priorytet (transakcyjne vs marketing), aby jeden strumień nie zagłodził innego.
Środowiska i konfiguracja
Planuj dev/staging/prod od początku. Przechowuj dane dostępowe do dostawców, limity prędkości i feature flagi w konfiguracji specyficznej dla środowiska (nie w szablonach). Wersjonuj szablony, by móc testować zmiany w staging przed produkcją.
Kto zarządza regułami i treścią?
Praktyczny podział:
- Inżynierowie odpowiadają za schematy zdarzeń, integracje i guardrails (timeouts, retry, idempotencja).
- Administratorzy/ops odpowiadają za reguły routingu i copy w szablonach, z workflow zatwierdzającym dla kanałów wysokiego ryzyka.
Ta architektura daje stabilne fundamenty, jednocześnie trzymając codzienne zmiany treści poza cyklem wydawniczym.
Model zdarzeń i kontrakty danych
System scentralizowanego zarządzania powiadomieniami żyje lub umiera dzięki jakości swoich zdarzeń. Jeśli różne części produktu opisują „to samo” w różny sposób, hub będzie się nieustannie tłumaczył, zgadywał i psuł.
Zdefiniuj czytelny schemat zdarzenia
Zacznij od małego, jawnego kontraktu, którego będą przestrzegać producenci. Praktyczny baseline wygląda tak:
- event_name: stabilny identyfikator (np.
invoice.paid, comment.mentioned)
- actor: kto to wywołał (ID użytkownika, nazwa serwisu)
- recipient: dla kogo (user ID, team ID lub lista)
- payload: pola biznesowe potrzebne do złożenia wiadomości (amount, invoice_id, comment_excerpt)
- metadata: kontekst dla routingu i operacji (tenant/workspace ID, timestamp, source, wskazówki locale)
Taka struktura utrzymuje zdarzenia zorientowane na zdarzenia zrozumiałe i wspiera reguły routingu, szablony i śledzenie dostaw.
Wersjonuj kontrakty (nie bój się zmian)
Zdarzenia ewoluują. Zapobiegaj regresjom przez wersjonowanie, np. schema_version: 1. Przy złamaniu kompatybilności opublikuj nową wersję (lub nową nazwę zdarzenia) i wspieraj obie przez okres przejściowy. Ma to znaczenie, gdy wielu producentów (backendy, webhooki, zadania cykliczne) wysyła do jednego hubu.
Waliduj, sanitizuj i zapewnij idempotencję
Traktuj przychodzące zdarzenia jako nieufne dane, nawet z własnych systemów:
- Waliduj wymagane pola i typy; odrzucaj lub izoluj nieprawidłowe zdarzenia.
- Sanitizuj łańcuchy, by zapobiec wstrzyknięciom lub problemom formatowania przy renderowaniu szablonów (HTML e-mail, markdown Slack/Teams, SMS).
- Dodaj idempotency_key (np.
idempotency_key: invoice_123_paid), by retry nie tworzyły duplikatów wysyłek w wielokanałowych scenariuszach.
Silne kontrakty danych redukują zgłoszenia do supportu, przyspieszają integracje i czynią raportowanie oraz logi audytu znacznie bardziej wiarygodnymi.
Użytkownicy, odbiorcy i preferencje powiadomień
Hub działa tylko wtedy, gdy wie kim ktoś jest, jak do niego dotrzeć i na co wyraził zgodę. Traktuj tożsamość, dane kontaktowe i preferencje jako byty pierwszej klasy — nie jako poboczne pola w rekordzie użytkownika.
Odbiorcy vs użytkownicy
Oddziel User (konto, które się loguje) od Recipient (byt, który może otrzymywać wiadomości):
- Użytkownik może mieć wiele recipientów (służbowy e-mail, prywatny e-mail, numer SMS, handle Slack).
- Recipient może być miejscem współdzielonym, jak skrzynka zespołowa czy rotacja on-call, a nie pojedynczą osobą.
Dla każdego punktu kontaktowego przechowuj: wartość (np. e-mail), typ kanału, label, właściciela oraz status weryfikacji (unverified/verified/blocked). Trzymaj też metadane jak ostatni czas weryfikacji i metodę (link, kod, OAuth).
Preferencje: kanał, temat i czas
Preferencje powinny być ekspresyjne, ale przewidywalne:
- Według tematu (np. Billing, Security, Deployments)
- Według kanału (Email, SMS, Push, Slack)
- Quiet hours (strefa czasowa recipienta), z wyjątkami dla alertów krytycznych
Modeluj to z warstwami domyślnymi: organization → team → user → recipient, gdzie niższe poziomy nadpisują wyższe. Pozwala to adminom ustawić rozsądne bazowe wartości, a osobom indywidualnym kontrolować dostarczanie.
Zgoda, wypis i dowody
Zgoda to nie tylko checkbox. Przechowuj:
- Timestampy opt-in/opt-out per kanał i temat
- Źródło zgody (UI, API, import) i aktora (user/admin/system)
- Powody wypisania (tekst wolny lub enum) i wygaśnięcie supresji jeśli tymczasowe
- Dowody tam, gdzie wymagane (token double opt-in, callback webhooka, podpisany zapis)
Ułatw eksport historii zgód z jednego miejsca (np. /settings/notifications), bo support będzie tego potrzebował, gdy użytkownicy pytają „dlaczego to dostałem?” lub „dlaczego nie dostałem?”.
Reguły routingu: kto dostaje co, gdzie i kiedy
Zachowaj kontrolę nad kodem
Zachowaj kontrolę nad wygenerowanym kodem, aby system powiadomień pozostał przenośny i łatwy w utrzymaniu.
Reguły routingu to „mózg” hubu powiadomień: decydują, którzy odbiorcy powinni otrzymać powiadomienia, przez które kanały i w jakich warunkach. Dobre reguły redukują hałas bez pomijania krytycznych alertów.
Wejścia reguł ("kiedy" i "kto")
Zdefiniuj wejścia, które reguły mogą oceniać. Utrzymaj pierwszą wersję małą, ale ekspresyjną:
- Typ zdarzenia (np.
invoice.overdue, deployment.failed, comment.mentioned)
- Segment użytkowników (rola, plan, zespół, region, ownership — kto jest uprawniony)
- Poziom/priorytet (info, warning, critical)
- Okno czasowe (godziny pracy vs poza godzinami; quiet hours)
- Locale (by wybrać właściwy język szablonu i formatowanie)
Te wejścia powinny pochodzić z kontraktu zdarzenia, a nie być ręcznie wpisywane przez administratorów dla każdego powiadomienia.
Akcje reguł ("jak")
Akcje określają zachowanie dostarczania:
- Wybierz kanał(e): email, SMS, push, Slack/Teams, webhook, in-app inbox
- Throttle/digest: ogranicz powtórzenia (np. „max 1 na 30 min”) lub grupuj niepilne wiadomości
- Escalate: jeśli nie potwierdzono w ciągu X minut, skieruj do rotacji on-call
- Route to on-call: integruj harmonogramy, aby poza godzinami sprawy trafiały do odpowiedniej osoby
Priorytet, fallback i obsługa błędów
Zdefiniuj jawny priorytet i kolejność fallbacków dla każdej reguły. Przykład: najpierw push, jeśli zawiedzie — SMS, na końcu e-mail.
Powiąż fallback z rzeczywistymi sygnałami dostarczenia (bounced, provider error, device unreachable) i zakończ pętle retry jasnymi limitami.
Bezpieczna edycja i przegląd
Reguły powinny być edytowalne przez przyjazne UI (dropdowny, podglądy, ostrzeżenia), z:
- Stanami draft vs published
- Przeglądem/zatwierdzeniem dla zmian o dużym wpływie
- Trybem symulacji (pokaż „kto by to otrzymał?” na przykładowych zdarzeniach)
- Ścieżką audytu łączącą każdą zmianę z adminem i timestampem
Szablony i lokalizacja dla spójnych komunikatów
Szablony to miejsce, gdzie scentralizowane powiadomienia stają się spójnym doświadczeniem produktu. Dobry system szablonów utrzymuje ton, redukuje błędy i sprawia, że dostarczanie międzykanałowe (email, SMS, push, in-app) wydaje się przemyślane, a nie improwizowane.
Struktura szablonu: przewidywalna i świadoma kanału
Traktuj szablon jako strukturalny zasób, nie kawałek tekstu. Przynajmniej przechowuj:
- Subject/title (temat e-maila, tytuł push, nagłówek in-app)
- Body (HTML + plaintext dla e-maila; krótkie/długie warianty dla push/SMS)
- Zmienne (typowane placeholdery jak
{{first_name}}, {{order_id}}, {{amount}})
- Zasady formatowania (dozwolony markup per kanał, maks. długości, polityka linków)
Utrzymuj zmienne jawne z schematem, aby system mógł zwalidować, że zdarzenie dostarcza wszystko, co wymagane. To zapobiega wysyłaniu „Cześć {{name}}”.
Lokalizacja: wybór locale i brakujące tłumaczenia
Zdefiniuj, jak wybierany jest locale odbiorcy: preferencja użytkownika, potem ustawienie konta/org, potem domyślny (często en). Dla każdego szablonu przechowuj tłumaczenia per locale z polityką fallbacku:
- Jeśli brakuje
fr-CA, fallback do fr.
- Jeśli brakuje
fr, fallback do domyślnego locale szablonu.
- Jeśli brakuje wymaganej tłumaczenia, zablokuj wysyłkę dla tego locale lub przełącz na domyślny i zaloguj fallback w metadanych dostawy.
To sprawia, że brak tłumaczeń jest widoczny w raportach zamiast cicho pogarszać jakość wiadomości.
Podgląd i test-send (admini + QA)
Daj ekran podglądu, który pozwala adminowi wybrać:
- kanał (email/SMS/push)
- locale
- przykładowy payload zdarzenia (rzeczywiste złapane zdarzenie lub mockowane JSON)
Wyrenderuj wiadomość dokładnie tak, jak pipeline ją wyśle, łącznie z przepisaniem linków i regułami przycinania. Dodaj test-send kierowany do bezpiecznej „listy sandboxowej”, aby uniknąć przypadkowego kontaktu z klientami.
Wersjonowanie i zatwierdzenia, by zapobiec wpadkom
Szablony powinny być wersjonowane jak kod: każda zmiana tworzy nową niezmienną wersję. Używaj statusów Draft → In review → Approved → Active, z opcjonalnymi zatwierdzeniami ról. Cofnięcie (rollback) powinno być jednym kliknięciem.
Dla audytowalności zapisuj, kto co zmienił, kiedy i dlaczego, i łącz te zmiany z wynikami dostarczania, aby skorelować skoki błędów z edycjami szablonów (patrz także /blog/audit-logs-for-notifications).
Integracje kanałów i pipeline dostarczania
Zbuduj swój hub powiadomień MVP
Zbuduj MVP hubu powiadomień w Koder.ai, opisując w czacie swoje zdarzenia, reguły i szablony.
Hub jest tak dobry, jak jego ostatnia mila: dostawcy kanałów, którzy ostatecznie dostarczają e-maile, SMS i push. Celem jest, aby każdy dostawca działał jak „plug-in”, a jednocześnie zachować spójne zachowanie dostarczania między kanałami.
Integruj jednego dostawcę na kanał (na start)
Zacznij od jednego, dobrze wspieranego dostawcy na kanał — np. SMTP lub API e-mail, bramka SMS i serwis push (APNs/FCM przez vendor). Trzymaj integracje za wspólnym interfejsem, aby móc zmieniać lub dodawać dostawców bez przepisywania logiki biznesowej.
Każda integracja powinna obsługiwać:
- Autentykację i podpisywanie żądań
- Mapowanie payloadu (twoja wiadomość → format dostawcy)
- Ograniczenia specyficzne dla dostawcy (limity załączników, sender IDs, nagłówki opt-out)
Zbuduj pipeline dostarczania, nie tylko wywołania API
Traktuj „wyślij powiadomienie” jako pipeline z jasnymi etapami: enqueue → prepare → send → record. Nawet dla małej aplikacji model workerów oparty na kolejce zapobiega blokowaniu web aplikacji przez wolne wywołania dostawcy i daje miejsce na bezpieczne retry.
Praktyczne podejście:
- Web app zapisuje „zadanie dostarczenia” do kolejki
- Workery pobierają zadania, wywołują dostawcę, a następnie zapisują wynik
- Opcjonalne webhooki aktualizują status asynchronicznie (niektórzy dostawcy potwierdzają później)
Standaryzuj statusy i obsługę błędów
Dostawcy zwracają bardzo różne odpowiedzi. Znormalizuj je do jednego wewnętrznego modelu statusu, np.: queued, sent, delivered, failed, bounced, suppressed, throttled.
Przechowuj surowe odpowiedzi dostawcy do debugowania, ale dashboardy i alerty opieraj na znormalizowanym statusie.
Retry, backoff, limity i batchowanie
Implementuj retry z wykładniczym backoffem i maksymalnym limitem prób. Retry tylko przy błędach przejściowych (timeouts, 5xx, throttling), nie przy błędach trwałych (nieprawidłowy numer, hard bounce).
Szanuj limity dostawcy przez throttling per-dostawca. Dla wysokiego wolumenu grupuj wysyłki tam, gdzie dostawca to wspiera (np. bulk API dla e-mail), by zmniejszyć koszty i poprawić przepustowość.
Śledzenie, statusy i dashbordy raportowe
Hub jest tak wiarygodny, jak jego widoczność. Gdy klient powie „nie dostałem tego e-maila”, potrzebujesz szybkiego sposobu, by odpowiedzieć: co wysłano, przez który kanał i co się potem wydarzyło.
Zdefiniuj jasne stany dostarczeń
Ustandaryzuj niewielki zestaw stanów dostarczeń między kanałami, by raportowanie było spójne. Praktyczny baseline:
- queued (zaakceptowano i czeka na wysyłkę)
- sent (przekazano dostawcy)
- delivered (potwierdzone dostarczenie, gdy kanał to wspiera)
- bounced (permanentny błąd dostarczenia, zwykle e-mail)
- failed (nie udało się wysłać z powodu błędów lub odrzucenia przez dostawcę)
- opened (jeśli dostępne) (śledzone przez niektórych dostawców e-mail; często niedostępne dla SMS/push)
Traktuj to jako oś czasu, nie pojedynczą wartość — każda wiadomość może emitować wiele aktualizacji statusu.
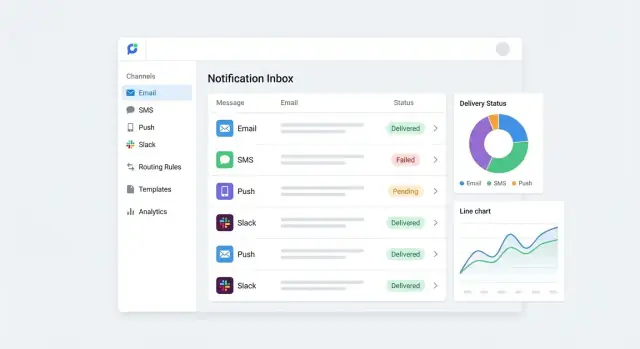
Zbuduj przeszukiwalny dziennik wiadomości
Stwórz dziennik wiadomości łatwy w użyciu dla supportu i operacji. Przynajmniej umożliwiaj wyszukiwanie po:
- recipient (user ID, e-mail, telefon)
- event (np.
invoice.paid, password.reset)
- zakres czasu (dzisiaj, ostatnie 7 dni)
Dołącz kluczowe szczegóły: kanał, nazwa/wersja szablonu, locale, dostawca, kody błędów i licznik retry. Domyślnie bezpieczny: maskuj pola wrażliwe (częściowo redaguj e-mail/telefon) i ogranicz dostęp rolami.
Korelacja wiadomości ze zdarzeniami upstream
Dodaj trace IDs, by połączyć powiadomienie z wyzwalającą akcją (checkout, update admina, webhook). Użyj tego samego trace ID w:
- oryginalnym zapisie zdarzenia
- żądaniu notyfikacji
- wszystkich próbach dostarczania i aktualizacjach statusów
To zmienia „co się stało?” w jedno filtrowane widzenie zamiast poszukiwań w wielu systemach.
Dashboardy, które naprawdę pomagają
Skup się na decyzjach, nie metrykach próżności:
- Wolumen wg kanału i zdarzenia (wykrywaj skoki)
- Błędy wg dostawcy, szablonu i powodu (znajduj awarie i złe dane)
- Top szablonów wg liczby wysyłek i wskaźnika błędów (priorytetyzuj poprawki)
Dodaj możliwość przejścia z wykresów do podstawowego dziennika wiadomości, by każda metryka była wytłumaczalna.
Bezpieczeństwo, kontrola dostępu i audytowalność
Hub dotyka danych klientów, credentiali dostawców i treści wiadomości — więc bezpieczeństwo musi być zaprojektowane od początku. Cel jest prosty: tylko uprawnione osoby mogą zmieniać zachowanie, sekrety pozostają tajne, a każda zmiana jest śledzona.
Kontrola dostępu oparta na rolach (RBAC)
Zacznij od niewielkiego zestawu ról i przypisz je do istotnych działań:
- Admin: zarządza ustawieniami organizacji, użytkownikami i politykami retencji.
- Notification Manager: edytuje reguły routingu, szablony i ciągi lokalizacyjne.
- Integration Manager: dodaje/aktualizuje klucze dostawców kanałów (email/SMS/push), webhooki i URL-e callbacków.
- Viewer/Auditor: dostęp tylko do odczytu do dashboardów i logów audytu.
Stosuj zasadę najmniejszych uprawnień: nowi użytkownicy nie powinni móc edytować reguł ani credentiali dopóki nie zostaną explicite uprawnieni.
Obsługa sekretów i rotacja credentiali
Klucze dostawców, sekretne podpisy webhooków i tokeny API traktuj jako sekrety end-to-end:
- Szyfruj sekrety w spoczynku (KMS/vault) i ogranicz odszyfrowanie do serwisu dostarczającego.
- Wspieraj rotację bez przestojów (przechowuj wiele aktywnych kluczy, wersjonuj i pozwól na etapowy cutover).
- Redukuj logowanie wrażliwych pól i unikaj logowania treści wiadomości, jeśli mogą zawierać PII.
Logi audytu, którym można zaufać
Każda zmiana konfiguracji powinna zapisywać niezmienny event audytu: kto zmienił, co, kiedy, skąd (IP/urządzenie) oraz wartości przed/po (pola sekretne zamaskowane). Śledź zmiany reguł routingu, szablonów, kluczy dostawców i przypisań uprawnień. Daj prosty eksport (CSV/JSON) dla przeglądów zgodności.
Retencja i żądania usunięcia
Zdefiniuj retencję per typ danych (zdarzenia, próby dostawy, treść, logi audytu) i udokumentuj to w UI. Gdzie to możliwe, obsługuj żądania usunięcia poprzez usuwanie lub anonimizację identyfikatorów recipientów, zachowując agregaty metryk dostaw i zmaskowane logi audytu.
UX dla administratorów i użytkowników końcowych
Umieść to na swojej domenie
Dodaj domenę niestandardową dla konsoli administracyjnej, aby zespoły wewnętrzne mogły korzystać z niej jak z prawdziwego narzędzia.
Hub powiadomień zwycięża lub przegrywa przez użyteczność. Większość zespołów nie będzie „zarządzać powiadomieniami” codziennie — dopóki coś nie pęknie. Projektuj UI pod szybkie skanowanie, bezpieczne zmiany i jasne rezultaty.
Konsola administracyjna: strony, które się liczą
Rules powinny czytać się jak polityki, nie kod. Użyj tabeli z frazą „IF event… THEN send…”, plus chipy kanałów (Email/SMS/Push/Slack) i odbiorców. Dodaj symulator: wybierz zdarzenie i zobacz dokładnie, kto otrzyma co, gdzie i kiedy.
Templates korzystają z edytora obok podglądu. Pozwól adminom przełączać locale, kanał i przykładowe dane. Zapewnij wersjonowanie i krok „publish” oraz jednoklikowy rollback.
Recipients powinny obsługiwać osoby i grupy (zespoły, role, segmenty). Pokaż członkostwo w widoku („dlaczego Alex jest w On-call?”) i pokaż, gdzie recipient jest używany w regułach.
Health dostawców wymaga szybkiego widoku: latencja dostaw, wskaźnik błędów, głębokość kolejek i ostatnie incydenty. Podlinkuj każdy problem do zrozumiałego wyjaśnienia i następnych kroków (np. „Twilio auth failed — sprawdź uprawnienia klucza API”).
Ustawienia użytkownika: kontrola bez zamieszania
Utrzymuj preferencje lekkie: opt-in kanałów, quiet hours i przełączniki tematów/kategorii (np. „Billing”, „Security”, „Product updates”). Pokaż podsumowanie w prostym języku na górze („Będziesz otrzymywać alerty bezpieczeństwa SMS-em, o każdej porze”).
Włącz przyjazne flow unsubscribe: one-click dla marketingu i jasne komunikaty, gdy alerty krytyczne nie mogą być wyłączone („Wymagane dla bezpieczeństwa konta”). Jeśli użytkownik wyłącza kanał, potwierdź, co się zmieni („Brak SMS-ów; e-mail pozostaje włączony”).
Narzędzia operacyjne przy incydentach
Operatorzy potrzebują bezpiecznych narzędzi pod presją:
- Ponowne wysłanie z guardrailami (limity, potwierdzenie i „wysyłaj tylko do oryginalnych odbiorców” domyślnie)
- Anuluj zaplanowane powiadomienia z zapisem audytu
- Suppress hałaśliwe źródła czasowo (z limitem czasu)
- Tryb incydentu do nadpisania routingu (np. eskalacja do on-call) i wstrzymania nieistotnych wiadomości
Puste stany i błędy, na które użytkownik może zareagować
Puste stany powinny prowadzić do konfiguracji („Brak reguł — utwórz pierwszą regułę”) i wskazywać następny krok (np. /rules/new). Komunikaty błędów powinny zawierać co się stało, co to dotyczy i jak to naprawić — bez wewnętrznego żargonu. Tam, gdzie to możliwe, proponuj szybkie poprawki („Ponownie połącz dostawcę”) i przycisk „kopiuj szczegóły” do zgłoszeń supportu.
Plan MVP, testy i strategia wdrożenia
Hub może rozrastać się w duże narzędzie, ale powinien zaczynać mało. Celem MVP jest udowodnić end-to-end flow (zdarzenie → routing → szablon → wysyłka → śledzenie) z jak najmniejszą liczbą ruchomych części, a potem bezpiecznie rozszerzać.
Jeśli chcesz przyspieszyć pierwszą działającą wersję, platforma vibe-coding taka jak Koder.ai może pomóc szybko postawić konsolę admina i core API: zbuduj UI w React, backend w Go z PostgreSQL i iteruj w workflowie opartym na czacie — potem użyj trybu planowania, snapshotów i rollbacków, by trzymać zmiany pod kontrolą.
Minimalne MVP, które wciąż udowadnia koncepcję
Zachowaj pierwsze wydanie celowo wąskie:
- Jeden typ zdarzenia (np. „password reset requested” lub „invoice paid”).
- Jeden kanał (najczęściej e-mail) z jedną integracją dostawcy.
- Podstawowe szablony z prostymi zmiennymi (imię, data, kwota) i zwykłą wiadomością zapasową.
- Małe UI admina do przeglądu wysyłek i statusów (queued/sent/failed).
To MVP powinno odpowiedzieć: „Czy potrafimy niezawodnie wysłać właściwą wiadomość do właściwego odbiorcy i zobaczyć, co się stało?”.
Testy, które chronią dostarczalność i zaufanie
Powiadomienia są widoczne dla użytkownika i wrażliwe czasowo, więc automatyczne testy szybko się zwracają. Skup się na trzech obszarach:
- Testy routingu: dla danego zdarzenia i preferencji odbiorcy asercja na wybrane kanały i reguły supresji.
- Testy templatingu: renderuj szablony na przykładowych danych, waliduj wymagane zmienne i upewnij się o escapingu (unikaj zepsutego HTML czy źle sformułowanego SMS-a).
- Testy retry i błędów: symuluj timeouty i błędy dostawcy, potwierdź politykę retry, idempotencję (brak duplikatów) i obsługę dead-letter.
Dodaj kilka end-to-end testów wysyłających do konta sandboxowego dostawcy w CI.
Wdrażanie bez niespodzianek
Użyj etapowego wdrażania:
- Tryb shadow: przetwarzaj zdarzenia i generuj rekordy „co by było wysłane”, ale nie dostarczaj.
- Stopniowy ruch: zacznij od użytkowników wewnętrznych, potem mały procent prod events.
- Fallback do legacy: jeśli hub zawiedzie, automatycznie wróć do poprzedniej ścieżki wysyłki aż do rozwiązania problemu.
Roadmap po MVP
Gdy będzie stabilnie, rozszerzaj etapami: dodaj kanały (SMS, push, in-app), bogatszy routing, lepsze narzędzia szablonów i głębszą analitykę (wskaźniki dostarczalności, czas do dostarczenia, trendy wypisów).