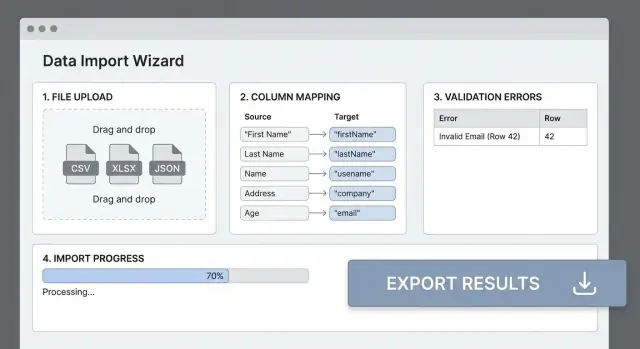
Zdefiniuj zakres i potrzeby użytkowników
Zanim zaprojektujesz ekrany lub wybierzesz parser plików, ustal kto przenosi dane do i z produktu oraz dlaczego. Aplikacja do importu danych zaprojektowana dla operatorów wewnętrznych będzie wyglądać bardzo inaczej niż samoobsługowe narzędzie do importu Excel dla klientów.
Kim są użytkownicy?
Zacznij od wypisania ról, które będą miały styczność z importami/eksportami:
- Administratorzy konfigurujący mapowania, reguły i uprawnienia
- Operatorzy uruchamiający importy regularnie i obsługujący wyjątki
- Klienci przesyłający własne pliki CSV/Excel i oczekujący jasnych wskazówek
Dla każdej roli określ oczekiwany poziom umiejętności i tolerancję na złożoność. Klienci zwykle potrzebują mniej opcji i znacznie lepszych wyjaśnień w produkcie.
Główne przypadki użycia (i co oznacza „gotowe”)
Spisz najważniejsze scenariusze i ustal ich priorytety. Typowe to:
- Początkowy masowy załadunek podczas onboardingu (duża objętość, nieuporządkowane dane)
- Okresowa synchronizacja (cotygodniowe/miesięczne aktualizacje, ważna spójność)
- Jednorazowe eksporty do raportów, migracji lub kopii zapasowej
Następnie określ metryki sukcesu, które możesz mierzyć. Przykłady: mniej nieudanych importów, krótszy czas rozwiązywania błędów, mniej zgłoszeń „mój plik się nie wgrywa”. Te metryki pomogą podejmować decyzje o kompromisach (np. inwestować w czytelniejsze raporty błędów vs. obsługę kolejnych formatów plików).
Bądź konkretny, co obsłużysz na dzień pierwszy:
- Format plików: CSV, Excel (XLSX), JSON
- Maksymalny rozmiar pliku i limity wierszy (i co się stanie po przekroczeniu)
- Oczekiwane kodowanie (np. UTF-8) i zasady dotyczące stref czasowych dla dat
Na koniec wcześnie zidentyfikuj wymogi zgodności: czy pliki zawierają PII, zasady przechowywania (jak długo przechowujesz uploady) oraz wymagania audytowe (kto, co i kiedy importował). Te decyzje wpływają na przechowywanie, logowanie i uprawnienia w całym systemie.
Wybierz architekturę i stos technologiczny
Zanim pomyślisz o wyszukanym UI mapowania kolumn czy regułach walidacji CSV, wybierz architekturę, którą zespół potrafi wdrożyć i obsługiwać. Importy i eksporty to „nudna” infrastruktura — szybkość iteracji i możliwość debugowania są ważniejsze niż nowinka.
Zacznij od stosu, który już znacie
Każdy mainstreamowy stos webowy poradzi sobie z aplikacją importującą dane. Wybierz na podstawie obecnych umiejętności i realiów rekrutacyjnych:
- React + Node (TypeScript) jeśli chcesz jednego języka w full-stacku i bogatego ekosystemu do zadań w tle.
- Django jeśli potrzebujesz „baterii w zestawie”, dojrzałego ORM i szybkiego dostarczania.
- Rails jeśli cenisz konwencje, szybkie CRUDy i sprawdzone wzorce zadań w tle.
Klucz to spójność: stos powinien ułatwiać dodawanie nowych typów importów, reguł walidacji i formatów eksportu bez przepisywania wszystkiego.
Jeśli chcesz przyspieszyć szkielety bez zamrażania się na jednorazowym prototypie, platforma vibe-coding jak Koder.ai może tu pomóc: opisujesz przepływ importu (upload → podgląd → mapowanie → walidacja → przetwarzanie w tle → historia), generujesz UI w React z backendem Go + PostgreSQL i szybko iterujesz korzystając z trybu planowania i snapshotów/rollbacku.
Przechowywanie: oddziel „surowy plik” od „znormalizowanych rekordów”
Użyj relacyjnej bazy danych (Postgres/MySQL) dla znormalizowanych rekordów, upsertów i logów audytu zmian danych.
Przechowuj oryginalne uploady (CSV/Excel) w object storage (S3/GCS/Azure Blob). Trzymanie surowych plików jest nieocenione dla wsparcia: możesz odtworzyć problemy parsowania, uruchomić zadania ponownie i wyjaśnić decyzje związane z obsługą błędów.
Zdecyduj, jak będą działać importy
Małe pliki mogą być przetwarzane synchronizacyjnie (upload → walidacja → zastosowanie) dla szybkiego UX. Dla większych plików przenieś pracę do zadań w tle:
- upload → enqueue job → pokazuj postęp/historię → powiadom po zakończeniu
To też daje możliwości ponowień i ograniczania prędkości zapisu.
Multi-tenant vs single-tenant
Jeśli budujesz SaaS, wcześnie zdecyduj, jak separujesz dane tenantów (scope na poziomie wiersza, oddzielne schematy lub bazy). Wybór wpływa na API eksportu, uprawnienia i wydajność.
Wymagania niefunkcjonalne do udokumentowania teraz
Zapisz cele dla dostępności, maks. rozmiaru pliku, oczekiwanej liczby wierszy na import, czasu realizacji i limitów kosztów. Te liczby sterują wyborem kolejki zadań, strategią batchowania i indeksowaniem — długo zanim dopracujesz UI.
Zbuduj przepływ przyjęcia pliku
Przebieg przyjęcia ustawia ton dla każdego importu. Jeśli jest przewidywalny i wyrozumiały, użytkownicy spróbują ponownie, gdy coś pójdzie nie tak — a liczba zgłoszeń do wsparcia spadnie.
Punkty wejścia: upload w UI i API
Oferuj strefę drag-and-drop oraz klasyczny wybór pliku. Drag-and-drop jest szybszy dla zaawansowanych użytkowników, a wybieranie pliku bardziej dostępne i znane.
Jeśli klienci importują z innych systemów, dodaj też endpoint API. Może przyjmować multipart (plik + metadane) lub flow z pre-signed URL dla większych plików.
Parsuj bezpiecznie: nagłówki, kodowania i próbka
Po przesłaniu wykonaj lekkie parsowanie, by stworzyć „podgląd” bez zatwierdzania danych:
- Wykryj nagłówki i pokaż próbkę wierszy (np. pierwsze 20–100)
- Obsłuż typowe kodowania (UTF‑8, UTF‑16) i delimitery (przecinek, tabulator, średnik)
- Normalizuj nowe linie i przytnij oczywiste problemy formatowania
Ten podgląd zasila kolejne kroki, jak mapowanie kolumn i walidacja.
Przechowuj oryginalny plik do replayu
Zawsze przechowuj oryginalny plik bez modyfikacji (typowo w object storage). Dzięki temu możesz:
- Uruchomić import ponownie, gdy reguły walidacji się zmienią
- Zbadać błędy z dokładnym wejściem
- Udostępnić opcję „pobierz oryginał” z historii importu
Traktuj każde przesłanie jako pełnoprawny rekord. Zapisz metadane takie jak uploader, znacznik czasu, system źródłowy, nazwa pliku i checksum (do wykrywania duplikatów i zapewnienia integralności). To staje się nieocenione przy audycie i debugowaniu.
Pre-checki zanim użytkownik straci czas
Uruchamiaj szybkie pre-checki natychmiast i odrzucaj wcześnie, gdy trzeba:
- Typ pliku i limity rozmiaru
- Podstawowa czytelność (czy da się sparsować?)
- Obecność wymaganych kolumn (dla danego typu importu)
Jeśli pre-check nie przejdzie, zwróć jasny komunikat i powiedz, co poprawić. Cel: szybko blokować naprawdę złe pliki — bez blokowania danych, które można później zmapować i oczyścić.
Większość awarii importu wynika z tego, że nagłówki pliku nie pasują do pól aplikacji. Jasny etap mapowania kolumn zmienia „bałagan w CSV” w przewidywalne wejście i oszczędza użytkownikom prób i błędów.
UI mapowania zrozumiały dla ludzi
Pokaż prostą tabelę: Kolumna źródłowa → Pole docelowe. Automatycznie wykrywaj prawdopodobne dopasowania (ignorowanie wielkości liter, synonimy jak „E-mail” → email), ale zawsze pozwól na zmianę.
Dodaj kilka udogodnień:
- Oznacz pola docelowe wymagane i pokaż, czy są zmapowane
- Pozwól „Ignoruj tę kolumnę” dla danych nieistotnych
- Wyróżnij niezmapowane kolumny, żeby użytkownicy niczego nie przegapili
Zapisane szablony mapowania (dla klienta lub typu danych)
Jeśli klienci importują ten sam format co tydzień, zrób to jednorazowym kliknięciem. Pozwól zapisywać szablony w kontekście:
- konta/organizacji
- zestawu danych/typu (np. Kontakty vs Faktury)
- opcjonalnie konkretnej integracji lub systemu źródłowego
Przy nowym pliku sugeruj szablon na podstawie pokrycia kolumn. Wspieraj też wersjonowanie, by użytkownicy mogli aktualizować szablon bez łamania starszych przetwarzań.
Dodaj lekkie transformacje, które użytkownik może zastosować per zmapowane pole:
- przycinanie spacji; konwersja pustych stringów na null
- parsowanie dat (MM/DD/YYYY vs DD.MM.YYYY) z opcją strefy czasowej
- normalizacja walut (np. “$1,200.00” → 1200.00 + waluta)
- enumy (np. „Active”, „enabled”, „1” → ACTIVE)
- rozdzielanie/scalanie pól (Pełne imię → Imię/Nazwisko lub odwrotnie)
Trzymaj transformacje jawne w UI („Zastosowano: Trim → Parsuj datę”), aby wynik był zrozumiały.
Podgląd przed zatwierdzeniem
Przed przetworzeniem całego pliku pokaż podgląd zmapowanych wyników dla (powiedzmy) 20 wierszy. Pokaż wartość oryginalną, wartość przekształconą i ostrzeżenia (np. „Nie można sparsować daty”). To tutaj użytkownicy wychwycą problemy wcześnie.
Wykrywanie duplikatów i pól kluczowych
Poproś użytkownika o wybór pola kluczowego (email, external_id, SKU) i wyjaśnij, co się stanie przy duplikatach. Nawet jeśli obsługujesz upserty później, ten krok ustawia oczekiwania: możesz ostrzec o duplikatach w pliku i zasugerować, który rekord „wygrywa” (pierwszy, ostatni lub błąd).
Zaprojektuj system walidacji
Walidacja to różnica między „uploaderem plików” a funkcją importu, której ludzie mogą zaufać. Cel nie polega na rygorze dla samego rygoru — chodzi o zapobieganie rozprzestrzenianiu się złych danych, dając użytkownikom jasne, wykonalne informacje zwrotne.
Podziel walidację na warstwy
Traktuj walidację jako trzy odrębne sprawdzenia, każde z innym przeznaczeniem:
- Walidacja schematu (typy i pola wymagane): „Czy
email to string?”, „Czy amount to liczba?”, „Czy customer_id jest obecne?” — szybkie i można uruchomić bezpośrednio po parsowaniu.
- Reguły biznesowe: „Kwota musi być dodatnia”, „Status musi być jednym z Active/Paused”, „Data rozpoczęcia nie może być w przeszłości.” — odzwierciedlają logikę produktu.
- Reguły między polami i relacyjne: „Jeśli
country=US, state jest wymagane”, „end_date musi być po start_date”, „Nazwa planu musi istnieć w tym workspace.” — często wymagają kontekstu (inne kolumny lub zapytania do bazy).
Oddzielenie warstw ułatwia rozbudowę systemu i wyjaśnianie komunikatów w UI.
Tryb ścisły vs tolerancyjny (i dlaczego to ważne)
Zdecyduj wcześnie, czy import ma:
- Całkowicie nie przejść (tryb ścisły): najlepsze dla danych finansowych, uprawnień lub wszędzie tam, gdzie częściowe aktualizacje są ryzykowne.
- Przyjmować poprawne wiersze (tryb tolerancyjny): najlepsze dla dużych list, gdzie użytkownicy chcą poprawiać tylko problematyczne rekordy.
Możesz wspierać oba: domyślnie ścisły, z opcją „Pozwól na częściowy import” dla adminów.
Przyjazne dla człowieka błędy (z odwołaniem do wiersza/kolumny)
Każdy błąd powinien odpowiadać: co się stało, gdzie i jak to naprawić.
Przykład: „Wiersz 42, Kolumna ‘Data rozpoczęcia’: musi być prawidłową datą w formacie RRRR-MM-DD.”
Rozróżniaj:
- Błędy: blokują przetwarzanie tego wiersza (lub całego pliku w trybie ścisłym)
- Ostrzeżenia: dozwolone, ale wyróżnione (np. „Nieznany dział; zostanie pozostawiony pusty”)
Umożliwiaj pętle „napraw i ponów”
Użytkownicy rzadko naprawiają wszystko za pierwszym razem. Ułatw ponowne przesłanie poprzez powiązanie wyników walidacji z próbą importu i umożliwienie ponownego przesłania poprawionego pliku. Połącz to z możliwością pobrania raportów błędów (opisane dalej), aby mogli masowo rozwiązać problemy.
Silnik reguł: konfigurowalny tam, gdzie trzeba; w kodzie tam, gdzie bezpieczniej
Praktyczne podejście to hybryda:
- Reguły konfigurowalne dla wymagań specyficznych dla tenantów (np. „Numer pracownika musi być unikalny w obrębie workspace”).
- Reguły w kodzie dla kluczowych inwariantów produktu (np. granice uprawnień, wymagane relacje), by uniknąć błędnej konfiguracji.
To daje elastyczność bez tworzenia trudnych do debugowania ustawień.
Zaimplementuj niezawodne przetwarzanie i ponawianie
Zaplanuj przed kodowaniem
Najpierw zaplanuj stany, zadania i przypadki brzegowe, a potem pozwól Koder.ai wygenerować kod.
Importy zwykle nie udają się z powodu nudnych przyczyn: powolne bazy, skoki plików w godzinach szczytu lub pojedynczy „zły” wiersz blokujący cały batch. Niezawodność to głównie przeniesienie ciężkiej pracy poza ścieżkę request/response i zapewnienie, że każdy krok da się bezpiecznie wykonać ponownie.
Używaj zadań w tle dla dużych plików
Uruchamiaj parsowanie, walidację i zapisy w zadaniach w tle (kolejki/workerzy), żeby uploady nie trafiały na timeouty webowe. Pozwala to też skalować workerów niezależnie, gdy klienci zaczną importować większe arkusze.
Praktyczny wzorzec: podziel pracę na kawałki (np. 1 000 wierszy na job). Jeden „rodzicielski” job planuje zadania dla kawałków, agreguje wyniki i aktualizuje postęp.
Śledź jasne stany i przejścia
Modeluj import jako maszynę stanów, aby UI i zespół operacyjny zawsze wiedzieli, co się dzieje:
- queued → running → completed
- queued/running → failed (z powodem)
- queued/running → canceled (przez użytkownika lub system)
Przechowuj znaczniki czasu i liczbę prób przy każdym przejściu, by odpowiadać na pytania „kiedy to się zaczęło?” i „ile było prób?” bez wertowania logów.
Postęp, któremu można zaufać
Pokaż mierzalny postęp: przetworzone wiersze, pozostałe wiersze i znalezione błędy. Jeśli potrafisz oszacować przepustowość, dodaj przybliżone ETA — lepiej „~3 min” niż precyzyjne odliczanie.
Spraw, by przetwarzanie było idempotentne (bezpieczne przy ponowieniach)
Ponowienia nie powinny tworzyć duplikatów ani podwójnie aplikować zmian. Częste techniki:
- Użyj import_id plus row_number (lub hash wiersza) jako stabilnego klucza idempotencyjnego.
- Upsertuj po kluczu naturalnym (np. external_id) zamiast zawsze insertować.
- Zapisuj w transakcjach per kawałek, by częściowe błędy nie naruszyły stanu.
Ograniczanie, by chronić wszystkich
Ogranicz jednoczesne importy na workspace i throttluj zapisy (np. max N wierszy/sec), by nie przytłoczyć bazy danych i nie pogorszyć doświadczenia innych użytkowników.
Raportowanie błędów i historia importów
Jeśli ludzie nie rozumieją, co poszło nie tak, będą wysyłać te same pliki aż do zrezygnowania. Traktuj każdy import jako oddzielne „uruchomienie” z czytelną historią i wykonalnymi błędami.
Stwórz rekord uruchomienia importu
Zacznij od utworzenia rekordu import run w momencie przesłania pliku. Rekord powinien zawierać istotne dane:
- Kto to zainicjował (użytkownik + organizacja)
- Co zostało zaimportowane (nazwa pliku źródłowego, rozmiar, checksum, typ encji)
- Kiedy to się odbyło (czasy start/koniec)
- Jak to zinterpretowano (użyta konfiguracja mapowania, wersja transformacji)
- Wynik (sukces/niepowodzenie/częściowy, liczba przetworzonych/odrzuconych wierszy)
To staje się ekranem historii importów: prostą listą uruchomień ze statusem, licznikami i stroną „zobacz szczegóły”.
Przechowuj błędy na poziomie wiersza (nie tylko logi)
Logi aplikacyjne są świetne dla inżynierów, ale użytkownicy potrzebują zapytywalnych błędów. Przechowuj błędy jako strukturalne rekordy powiązane z uruchomieniem importu, najlepiej na obu poziomach:
- Poziom wiersza: numer wiersza, wykryty identyfikator podstawowy (jeśli wykryto), zrzut surowych wartości
- Poziom pola: nazwa kolumny, kod błędu (np. REQUIRED, INVALID_DATE), komunikat użytkowy, ważność
Dzięki temu możesz oferować szybkie filtrowanie i agregować insighty, np. „Top 3 typy błędów w tym tygodniu”.
Uczyń błędy użytecznymi: UI + raport do pobrania
Na stronie szczegółów uruchomienia daj filtry po typie, kolumnie i ważności oraz pole wyszukiwania (np. „email”). Następnie zaoferuj pobieralny raport CSV błędów zawierający oryginalny wiersz plus dodatkowe kolumny error_columns i error_message, z jasnymi wskazówkami typu „Popraw format daty na RRRR-MM-DD”.
Dodaj tryb „dry run”
Tryb dry run waliduje wszystko przy użyciu tej samej konfiguracji mapowania i reguł, ale nie zapisuje danych. To idealne rozwiązanie dla pierwszych importów i pozwala użytkownikom iterować bez ryzyka.
Model danych, upserty i audytowalność
Zbuduj pełny przebieg przyjęcia danych
Wygeneruj ekrany przesyłania, podglądu, mapowania i walidacji, nad którymi od razu możesz pracować.
Importy są „zrobione”, gdy wiersze trafią do bazy — ale długoterminowy koszt to zwykle nieporządne aktualizacje, duplikaty i niejasna historia zmian. Ten rozdział dotyczy projektowania modelu danych tak, by importy były przewidywalne, odwracalne i wyjaśnialne.
Zdecyduj: tworzyć, aktualizować czy oba
Określ, jak wiersz importu mapuje się na model domenowy. Dla każdej encji zdecyduj, czy import może:
- Tworzyć tylko nowe rekordy
- Tylko aktualizować istniejące
- Robić oba (częsty przypadek w SaaS)
Ta decyzja powinna być jawna w konfiguracji importu i zapisana z zadaniem importu, aby zachować powtarzalność zachowania.
Wybierz klucze upsert i zasady kolizji
Jeśli wspierasz „create or update”, potrzebujesz stabilnych kluczy upsert — pól identyfikujących ten sam rekord za każdym razem. Popularne wybory:
external_id (najlepsze, gdy pochodzi z innego systemu)- Email (działa dla użytkowników/kontaktów, ale może się zmieniać)
- Klucze złożone (np.
account_id + sku)
Zdefiniuj reguły kolizji: co jeśli dwa wiersze mają ten sam klucz, albo klucz pasuje do wielu rekordów? Dobre domyślne ustawienia to „zwróć błąd dla wiersza z jasnym komunikatem” lub „ostatni wiersz wygrywa”, ale wybieraj świadomie.
Transakcje bez blokowania wszystkiego
Używaj transakcji tam, gdzie chronią spójność (np. tworzenie rodzica i jego dzieci). Unikaj jednej wielkiej transakcji dla pliku 200k wierszy; może zablokować tabele i utrudnić ponowienia. Preferuj zapisy w kawałkach (np. 500–2000 wierszy) z upsertami idempotentnymi.
Chroń integralność referencyjną
Importy powinny respektować relacje: jeśli wiersz odwołuje się do rekordu nadrzędnego (np. Firma), albo wymagaj jego istnienia, albo twórz go w kontrolowanym kroku. Wczesne zwracanie błędu „brakujący rodzic” zapobiega częściowo połączonym danym.
Audytuj wszystko, co importy zmieniają
Dodaj logi audytu dla zmian dokonanych przez importy: kto uruchomił import, kiedy, plik źródłowy i podsumowanie na poziomie rekordu (stare vs nowe). To ułatwia wsparcie, buduje zaufanie użytkowników i upraszcza rollbacky.
Buduj eksporty, które skalują
Eksporty wydają się proste, dopóki klienci nie spróbują pobrać „wszystkiego” tuż przed deadlinem. Skalowalny system eksportu powinien obsłużyć duże zbiory danych bez spowalniania aplikacji i bez tworzenia niespójnych plików.
Oferuj odpowiednie typy eksportów
Zacznij od trzech opcji:
- Pełny eksport: wszystko, do czego użytkownik ma dostęp.
- Eksport filtrowany: stosuje te same filtry/szukania, co UI (status, zakres dat, właściciel itp.).
- Eksport przyrostowy: „zmiany od X” dla zadań synchronizacji i pipeline’ów raportowych.
Eksporty przyrostowe są szczególnie przydatne dla integracji i zmniejszają obciążenie w porównaniu do powtarzanych pełnych zrzutów.
- CSV jako domyślny format do arkuszy i analizy masowej.
- JSON jako najlepszy wybór dla API eksportu danych i automatyzacji.
- Excel tylko gdy potrzebne (wiele arkuszy, bogate formatowanie lub przepływy nietechniczne).
Cokolwiek wybierzesz, zachowaj spójne nagłówki i stabilny porządek kolumn, aby procesy downstream nie przestały działać.
Strumieniuj i paginuj, by uniknąć skoków pamięci
Duże eksporty nie powinny ładować wszystkich wierszy do pamięci. Używaj paginacji/streamingu, aby zapisywać wiersze w miarę ich pobierania. To zapobiega timeoutom i utrzymuje responsywność aplikacji.
Generuj duże eksporty asynchronicznie
Dla dużych datasetów generuj eksporty w zadaniu w tle i powiadamiaj użytkownika, gdy będą gotowe. Typowy wzorzec:
- Użytkownik żąda eksportu.
- Aplikacja kolejkowanie zadania.
- Zadanie zapisuje plik w object storage.
- UI pokazuje link do pobrania i przechowuje wpis w historii eksportów.
To dobrze współgra z zadaniami w tle dla importów i tym samym wzorcem „historia uruchomień + pobieralny artefakt”, którego używasz dla raportów błędów.
Eksporty często są audytowane. Zawsze dołącz:
- Jasną politykę strefy czasowej (np. przechowuj w UTC, eksportuj w strefie użytkownika).
- Spójne formatowanie dat (ISO-8601 dla JSON; jawne formaty dla CSV/Excel).
- Znacznik „wygenerowano o” i, dla eksportów przyrostowych, czas graniczny użyty.
Te detale zmniejszają nieporozumienia i ułatwiają rekonsyliację.
Bezpieczeństwo, uprawnienia i prywatność danych
Importy i eksporty to potężne funkcje, bo przenoszą dużo danych szybko. To też częste miejsce błędów bezpieczeństwa: jedna zbyt szeroka rola, jeden wyciek linku do pliku albo log z przypadkowo ujawnionymi danymi.
Uwierzytelnianie: wybierz to, co pasuje do użycia produktu
Użyj tego samego mechanizmu uwierzytelniania, co reszta aplikacji — nie twórz „specjalnej” ścieżki auth tylko dla importów.
Jeśli użytkownicy korzystają z przeglądarki, uwierzytelnianie sesyjne (plus opcjonalne SSO/SAML) zazwyczaj wystarcza. Jeśli importy/eksporty są zautomatyzowane (zadania nocne, partnerzy integracji), rozważ klucze API lub tokeny OAuth z jasnym zakresem i możliwością rotacji.
Praktyczne założenie: UI importu i API importu powinny wymuszać te same uprawnienia, nawet jeśli używane są przez różne grupy odbiorców.
Dostęp oparty na rolach: określ, kto może co robić
Traktuj możliwości importu/eksportu jako jawne uprawnienia. Typowe role:
- Może importować (przesyłać pliki, uruchamiać importy)
- Może eksportować (generować i pobierać eksporty)
- Może przeglądać historię (widzieć uruchomienia importów, błędy, liczniki)
- Może pobierać pliki (oryginalne uploady, raporty błędów)
Uczyń „pobieranie plików” osobnym uprawnieniem. Wiele przecieków wrażliwych danych następuje, gdy ktoś widzi szczegóły importu, a system zakłada, że może też pobrać plik z danymi.
Rozważ też ograniczenia na poziomie wiersza lub tenantów: użytkownik powinien importować/eksportować tylko dane konta lub workspace, do którego należy.
Chroń wrażliwe dane end-to-end
Dla przechowywanych plików (uploady, wygenerowane raporty błędów, archiwa eksportów) używaj prywatnego object storage i krótkotrwałych linków do pobrania. Szyfruj dane w spoczynku, gdy wymaga tego zgodność, i zachowaj konsekwencję: oryginalny upload, pliki stagingowe i generowane raporty powinny przestrzegać tych samych zasad.
Uważaj na logi. Zatajaj wrażliwe pola (e-maile, numery telefonów, identyfikatory, adresy) i nigdy nie loguj surowych wierszy domyślnie. Gdy debugowanie jest niezbędne, ogranicz „verbose row logging” do ustawień dla administratorów i zapewnij wygasanie tych danych.
Waliduj i skanuj uploady przed przetwarzaniem
Traktuj każdy upload jako nieufne wejście:
- Wymuszaj sprawdzenia typu pliku (nie polegaj tylko na nazwie pliku)
- Ustal limity rozmiaru, by zapobiegać DoS i przypadkowym ogromnym uploadom
- Rozważ skanowanie antywirusowe jeśli profil ryzyka lub branża tego wymaga
Waliduj też strukturę wcześnie: odrzuć oczywiście sformatowane pliki, zanim trafią do jobów w tle, i daj użytkownikowi jasny komunikat, co jest nie tak.
Ślady audytu dla zdarzeń istotnych dla bezpieczeństwa
Zapisuj zdarzenia, które przydadzą się w dochodzeniu: kto przesłał plik, kto uruchomił import, kto pobrał eksport, zmiany uprawnień i nieudane próby dostępu.
Wpisy audytu powinny zawierać aktora, znacznik czasu, workspace/tenant i obiekt (ID uruchomienia importu, ID eksportu), bez przechowywania wrażliwych danych wierszy. To dobrze współgra z historią importów i pomaga szybko odpowiedzieć „kto co zmienił i kiedy?”.
Testowanie, monitoring i operacyjność
Skonfiguruj role i dostęp
Wcześnie odwzoruj uprawnienia multi-tenant i wygeneruj potrzebne panele administracyjne.
Jeśli importy i eksporty dotykają danych klientów, w końcu trafisz na przypadki brzegowe: dziwne kodowania, scalone komórki, półwypełnione wiersze, duplikaty i „wczoraj działało”. Operacyjność to to, co zapobiega przekształceniu tych problemów w koszmar wsparcia.
Testy odzwierciedlające realne pliki
Zacznij od testów skupionych na najbardziej awaryjnych obszarach: parsowanie, mapowanie i walidacja.
- Testy parsowania: użyj zestawu reprezentatywnych fixture’ów CSV/XLSX (różne delimitery, formaty dat, puste kolumny, duże liczby, UTF‑8 vs Windows-1252). Asserty na liczby wierszy i poprawne parsowanie kluczowych pól.
- Testy mapowania + transformacji: dla danego zestawu kolumn weryfikuj, że aplikacja mapuje do właściwych pól wewnętrznych i stosuje transformacje (trim, normalizacja wielkości liter, konwersja waluty/procentów).
- Testy reguł walidacji: dla każdej reguły (wymagane, unikalne, zakres, istnienie klucza obcego) dodaj „dobre” i „złe” wiersze i sprawdź dokładne kody/komunikaty błędów.
Potem dodaj co najmniej jeden test end-to-end: upload → przetwarzanie w tle → generowanie raportu. Testy te wykrywają niezgodności kontraktowe między UI, API i workerami (np. brak konfiguracji mapowania w payloadzie joba).
Monitoring odpowiadający na pytanie „co się zepsuło?”
Śledź sygnały odzwierciedlające wpływ na użytkowników:
- Błędy jobów (liczba i częstość)
- Czas przetwarzania (p50/p95)
- Wskaźnik błędów walidacji (nagłe skoki często oznaczają zmianę szablonu)
- Głębokość kolejki i przepustowość workerów
Podłącz alerty do symptomów (rosnąca liczba błędów, rosnąca głębokość kolejki), a nie do każdej wyjątkowej sytuacji.
Narzędzia administracyjne i pomoc dla użytkownika
Daj zespołom wewnętrznym niewielki panel administracyjny do ponownego uruchamiania jobów, anulowania zawieszonych importów i inspekcji błędów (metadane pliku wejściowego, użyte mapowanie, podsumowanie błędów i odnośnik do logów/trace’ów).
Dla użytkowników zmniejsz liczbę błędów zapobiegawczych za pomocą podpowiedzi w linii, pobieralnych szablonów przykładowych i jasnych kolejnych kroków na ekranach błędów. Trzymaj centralną stronę pomocy i linkuj ją z UI importu (na przykład: /docs).
Wdrożenie, rollout i przyszłe udoskonalenia
Wdrożenie systemu import/eksport to nie tylko „push do produkcji”. Traktuj to jako funkcję produktu z bezpiecznymi domyślnymi ustawieniami, jasnymi ścieżkami odzyskiwania i miejscem na rozwój.
Środowiska: dev, staging, prod
Skonfiguruj oddzielne środowiska dev/staging/prod z izolowanymi bazami i oddzielnymi bucketami object storage (lub prefixami) dla uploadów i wygenerowanych eksportów. Używaj różnych kluczy szyfrujących i poświadczeń per środowisko, a workerzy zadań powinni wskazywać na właściwe kolejki.
Staging powinien odzwierciedlać produkcję: ta sama konkurencyjność jobów, timeouty i limity rozmiaru plików. Tam możesz weryfikować wydajność i uprawnienia bez ryzyka dla danych klientów.
Migracje i wersjonowane szablony
Importy zwykle „żyją wiecznie”, bo klienci przechowują stare arkusze. Stosuj migracje bazy danych jak zwykle, ale także wersjonuj szablony importu (i presety mapowania), aby zmiana schematu nie zepsuła CSV z zeszłego kwartału.
Praktyczne podejście: przechowuj template_version z każdym uruchomieniem importu i trzymaj kompatybilny kod dla starszych wersji, dopóki nie możesz ich zdeprecjonować.
Strategia rollout z flagami funkcji
Używaj feature flagów, aby bezpiecznie wdrażać zmiany:
- Nowe reguły walidacji (najpierw jako ostrzeżenia, potem jako błędy)
- Nowe formaty eksportu (np. dodanie JSON obok CSV)
- Nowe opcje mapowania (np. rozdzielenie „Pełne imię”)
Flagi pozwalają testować z wewnętrznymi użytkownikami lub małą grupą klientów przed szerokim włączeniem funkcji.
Workflow wsparcia i diagnozy
Udokumentuj, jak dział wsparcia powinien badać niepowodzenia używając historii importów, ID jobów i logów. Proste checklisty pomagają: potwierdź wersję szablonu, przejrzyj pierwszy błędny wiersz, sprawdź dostęp do storage, potem logi workerów. Podlinkuj to w wewnętrznym runbooku i, jeśli to stosowne, w panelu administracyjnym (np. /admin/imports).
Następne kroki: integracje
Gdy podstawowy przepływ będzie stabilny, rozszerz go poza uploady:
- Importy oparte na API dla zautomatyzowanych pipeline’ów
- Webhooki „import zakończony” lub „eksport gotowy”
- Connectory do popularnych narzędzi (Google Sheets, S3, Snowflake)
Te ulepszenia zmniejszają pracę ręczną i sprawiają, że aplikacja do importu danych będzie naturalnie wpisywać się w istniejące procesy klientów.
Jeśli budujesz to jako funkcję produktu i chcesz skrócić czas do „pierwszej używalnej wersji”, rozważ użycie Koder.ai do prototypowania kreatora importu, stron stanu zadań i ekranów historii uruchomień end-to-end, a potem wyeksportuj kod źródłowy do konwencjonalnego workflow inżynierskiego. Takie podejście jest praktyczne, gdy celem jest niezawodność i szybkość iteracji (nie perfekcyjny UI od dnia zero).