08 maj 2025·7 min
Jak zbudować aplikację webową do ocen i recenzji dostawców
Dowiedz się, jak zaplanować, zaprojektować i zbudować aplikację webową do kart wyników i recenzji dostawców: modele danych, przepływy, uprawnienia i wskazówki raportowe.
Dowiedz się, jak zaplanować, zaprojektować i zbudować aplikację webową do kart wyników i recenzji dostawców: modele danych, przepływy, uprawnienia i wskazówki raportowe.
Zanim naszkicujesz ekrany lub wybierzesz bazę danych, wyjaśnij dokładnie, do czego aplikacja ma służyć, kto będzie na niej polegać i jak wygląda „dobry” wynik. Aplikacje do oceny dostawców najczęściej zawodne są wtedy, gdy próbują zadowolić wszystkich naraz — albo gdy nie potrafią odpowiedzieć na podstawowe pytania, np. „Którego dostawcę właściwie oceniamy?”
Zacznij od nazwania głównych grup użytkowników i decyzji, które podejmują na co dzień:
Przydatna sztuczka: wybierz jednego „użytkownika rdzeniowego” (często zakupów) i zaprojektuj pierwsze wydanie wokół jego przepływu pracy. Kolejne grupy dodawaj dopiero, gdy potrafisz wyjaśnić, jaką nową zdolność to odblokowuje.
Formułuj rezultaty jako mierzalne zmiany, nie funkcje. Typowe rezultaty to:
Te cele później wpłyną na wybór KPI i raportowania.
„Dostawca” może znaczyć różne rzeczy w zależności od struktury organizacji i umów. Zdecyduj wcześnie, czy dostawca to:
Twój wybór wpływa na wszystko: agregację ocen, uprawnienia i to, czy jedno złe ogniwo fabryki powinno rzutować na całe relacje.
Spotyka się trzy wzorce:
Spraw, aby metoda punktowania była na tyle zrozumiała, by dostawca (i wewnętrzny audytor) mogli ją prześledzić.
Wybierz kilka metryk na poziomie aplikacji, które zweryfikują adopcję i wartość:
Mając cele, użytkowników i zakres, otrzymasz stabilne podstawy dla modelu punktacji i projektowania przepływów.
Aplikacja do ocen dostawców stoi i upada na tym, czy wynik odpowiada rzeczywistym doświadczeniom ludzi. Zanim zbudujesz ekrany, zapisz dokładne KPI, skale i reguły, aby zakupy, operacje i finanse interpretowały wyniki identycznie.
Zacznij od zestawu, który większość zespołów rozpoznaje:
Utrzymuj definicje mierzalne i powiąż każdy KPI ze źródłem danych lub pytaniem w recenzji.
Wybierz 1–5 (łatwe dla ludzi) lub 0–100 (bardziej szczegółowe), a potem określ, co oznacza każdy poziom. Na przykład: „Terminowość dostaw: 5 = ≥ 98%, 3 = 92–95%, 1 = < 85%.” Jasne progi redukują spory i ułatwiają porównania.
Przypisz wagi kategorii (np. Dostawy 30%, Jakość 30%, SLA 20%, Koszty 10%, Responsywność 10%) i udokumentuj, kiedy wagi się zmieniają (różne typy umów mogą priorytetyzować różne rezultaty).
Zdecyduj, jak postępować przy brakujących danych:
Cokolwiek wybierzesz, stosuj konsekwentnie i pokazuj to widocznie w widokach drill-down, żeby zespoły nie myliły „braku danych” z „dobrym wynikiem”.
Obsługuj więcej niż jedną kartę wyników per dostawca, aby zespoły mogły porównać wydajność według kontraktu, regionu lub okresu. Dzięki temu unikasz uśredniania problemów, które dotyczą konkretnego zakładu lub projektu.
Udokumentuj, jak spory wpływają na wyniki: czy metryka może być poprawiona retrospektywnie, czy spór tymczasowo oznacza wynik, i która wersja jest „oficjalna”. Nawet prosta reguła typu „wyniki przeliczają się po zatwierdzonej korekcie, z notką wyjaśniającą zmianę” zapobiegnie późniejszym nieporozumieniom.
Czysty model danych to to, co utrzymuje punktacje fair, recenzje śledzalne, a raporty wiarygodne. Chcesz móc rzetelnie odpowiedzieć na pytania „Dlaczego ten dostawca dostał 72 w tym miesiącu?” i „Co się zmieniło od zeszłego kwartału?” bez wymówek i ręcznych arkuszy.
Co najmniej zdefiniuj te encje:
Ten zestaw obsługuje zarówno twarde, mierzalne wyniki, jak i miękkie opinie użytkowników, które zwykle wymagają innych przepływów.
Modeluj relacje explicite:
Typowe podejście to:
scorecard_period (np. 2025-10)vendor_period_score (wynik ogólny)vendor_period_metric_score (per KPI, zawiera licznik/mianownik jeśli dotyczy)Dodaj spójne pola w większości tabel:
created_at, updated_at, oraz dla zatwierdzeń submitted_at, approved_atcreated_by_user_id, plus approved_by_user_id gdzie istotnesource_system i zewnętrzne identyfikatory jak erp_vendor_id, crm_account_id, erp_invoice_idconfidence lub data_quality_flag do oznaczania niekompletnych feedów lub estymatTo napędza ślady audytu, obsługę sporów i wiarygodną analitykę zakupową.
Wyniki zmieniają się, bo dane przychodzą z opóźnieniem, formuły ewoluują lub ktoś poprawia mapowanie. Zamiast nadpisywać historię, przechowuj wersje:
calculation_run_id) do każdego wiersza score.Dla retencji zdefiniuj, jak długo przechowujesz surowe transakcje vs. pochodne wyniki. Często pochodne wyniki trzyma się dłużej (mniejsze zużycie miejsca, wysoka wartość raportowa), a ekstrakty ERP krócej zgodnie z polityką.
Traktuj zewnętrzne ID jako pola pierwszej klasy, nie notatki:
unique(source_system, external_id)).To przygotowanie ułatwia implementację integracji, śledzenie KPI i moderację recenzji.
Aplikacja do ocen dostawców jest tak dobra, jak źródła, które ją zasilają. Zaplanuj wiele ścieżek importu od początku, nawet jeśli startujesz z jedną. Większość zespołów potrzebuje mixu: ręcznego wprowadzania dla edge-case'ów, masowego uploadu do historycznego bootstrapu i synchronizacji API dla bieżących aktualizacji.
Ręczne wprowadzanie jest przydatne dla małych dostawców, jednorazowych incydentów lub gdy zespół musi szybko dodać recenzję.
CSV upload pomaga wypełnić system danymi historycznymi: performance, faktury, zgłoszenia. Uczyń import przewidywalnym: opublikuj szablon i wersjonuj go, aby zmiany nie łamały importów.
Synchronizacja API zwykle łączy ERP/narzędzia zakupowe (PO, przyjęcia, faktury) i systemy serwisowe jak helpdeski (zgłoszenia, naruszenia SLA). Preferuj przyrostowy sync (od ostatniego kursora), aby nie pobierać wszystkiego za każdym razem.
Ustal jasne reguły walidacji podczas importu:
Przechowuj niepoprawne wiersze z komunikatami o błędach, aby admini mogli naprawić i ponownie załadować bez utraty kontekstu.
Importy czasem będą błędne. Wspieraj ponowne uruchomienia (idempotentne wg ID źródła), backfille (okresy historyczne) oraz logi przeliczeń, które rejestrują co się zmieniło, kiedy i dlaczego. To kluczowe dla zaufania, gdy wynik dostawcy się przesunie.
Większości zespołów wystarczą dzienne/tygodniowe importy dla finansów i metryk dostaw, plus near-real-time eventy dla krytycznych incydentów.
Udostępnij adminowski, przyjazny ekran importów (np. /admin/imports) pokazujący status, liczby wierszy, ostrzeżenia i dokładne błędy — aby problemy były widoczne i dały się naprawić bez programisty.
Jasne role i przewidywalna ścieżka zatwierdzeń zapobiegają „chaosowi kart wyników”: konfliktowym edytom, nieoczekiwanym zmianom ocen i niepewności, co dostawca widzi. Zdefiniuj reguły dostępu wcześnie i egzekwuj je konsekwentnie w UI i API.
Praktyczny zestaw startowy:
Unikaj niejasnych uprawnień typu „może zarządzać dostawcami”. Zamiast tego kontroluj konkretne możliwości:
Rozważ rozdzielenie „eksportu” na „eksport własnych dostawców” vs. „eksport wszystkich”, szczególnie dla analityki zakupowej.
Użytkownicy-dostawcy powinni zwykle widzieć tylko swoje dane: swoje oceny, opublikowane recenzje i status otwartych pozycji. Ogranicz domyślnie szczegóły tożsamości recenzentów (np. pokaż dział lub rolę zamiast pełnego imienia), aby zmniejszyć napięcia personalne. Jeśli pozwalasz na odpowiedzi dostawcy, trzymaj je w wątkach i wyraźnie oznaczonych jako treść od dostawcy.
Traktuj recenzje i zmiany wyników jako propozycje aż do zatwierdzenia:
Przydatne są reguły ograniczone czasowo: np. zmiany wyników mogą wymagać zatwierdzenia tylko podczas miesięcznego/kwartalnego zamknięcia.
Dla zgodności i rozliczalności loguj każde znaczące zdarzenie: kto co zrobił, kiedy, skąd i co się zmieniło (wartości przed/po). Wpisy audytu powinny obejmować zmiany uprawnień, edycje recenzji, zatwierdzenia, publikacje, eksporty i usunięcia. Uczyń ślad audytu przeszukiwalnym, możliwym do eksportu na audyty i chronionym przed modyfikacją (append-only lub immutable logs).
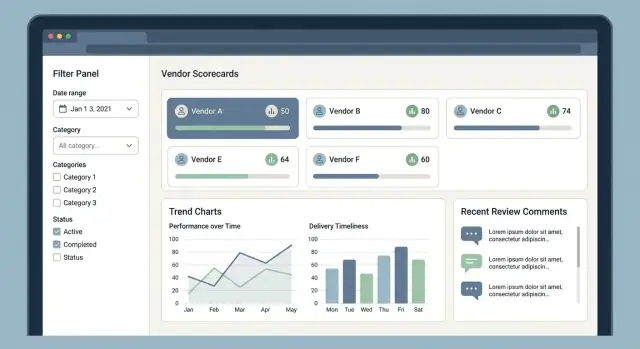
Aplikacja do ocen dostawców odnosi sukces lub porażkę w zależności od tego, czy zapracowani użytkownicy szybko znajdą właściwego dostawcę, zrozumieją wynik na pierwszy rzut oka i bez trudu zostawią wiarygodny feedback. Zacznij od niewielkiego zestawu „ekranów bazowych” i spraw, by każda liczba była wytłumaczalna.
Tu zaczyna się większość sesji. Utrzymaj prosty układ: nazwa dostawcy, kategoria, region, aktualny przedział wyników, status i ostatnia aktywność.
Filtrowanie i wyszukiwanie powinny być natychmiastowe i przewidywalne:
Zapisz często używane widoki (np. „Krytyczni dostawcy w EMEA poniżej 70”), aby zespoły zakupowe nie musiały odtwarzać filtrów codziennie.
Profil dostawcy powinien podsumować „kim są” i „jak sobie radzą”, bez zmuszania użytkownika do wczesnego przechodzenia między zakładkami. Umieść dane kontaktowe i metadata kontraktu obok czytelnego podsumowania wyników.
Pokaż wynik ogólny i rozkład KPI (jakość, dostawy, koszty, zgodność). Każdy KPI musi mieć widoczne źródło: recenzje, incydenty lub metryki, które go wygenerowały.
Dobry wzorzec to:
Uczyń wprowadzanie recenzji przyjaznym mobilnie: duże cele dotykowe, krótkie pola i szybkie komentowanie. Zawsze przypisuj recenzje do przedziału czasowego i (jeśli istotne) do zamówienia, zakładu lub projektu, aby feedback pozostał wykonalny.
Raporty powinny odpowiadać na pytania: „Którzy dostawcy mają trend spadkowy?” i „Co się zmieniło w tym miesiącu?” Używaj czytelnych wykresów, jasnych opisów i obsługi klawiatury dla dostępności.
Recenzje to miejsce, gdzie aplikacja staje się naprawdę użyteczna: uchwytują kontekst, dowody i „dlaczego” stojące za liczbami. Aby były spójne (i obronne), traktuj recenzje najpierw jako uporządkowane rekordy, a dopiero potem jako tekst swobodny.
Różne momenty wymagają różnych szablonów. Prosty zestaw startowy:
Każdy typ może dzielić pola wspólne, ale dopuszczać pytania specyficzne, aby zespoły nie próbowały na siłę dopasować incydentu do formularza okresowego.
Obok narracji dodaj pola strukturalne, które napędzają filtrowanie i raportowanie:
Ta struktura zmienia „feedback” w śledzone zadania, a nie tylko tekst w polu.
Pozwól recenzentom dołączać dowody w tym samym miejscu, gdzie piszą recenzję:
Przechowuj metadata (kto załadował, kiedy, do czego się odnosi), aby audyty nie były polowaniem na skarby.
Nawet narzędzia wewnętrzne potrzebują moderacji. Dodaj:
Unikaj cichych edycji — przejrzystość chroni zarówno recenzentów, jak i dostawców.
Zdefiniuj reguły powiadomień:
Dobrze wykonane, recenzje stają się zamkniętym obiegiem informacji, a nie jednorazową skargą.
Pierwsza decyzja architektoniczna powinna bardziej brać pod uwagę, jak szybko możesz wypuścić niezawodną platformę do ocen i recenzji bez tworzenia długu technicznego.
Jeśli celem jest szybkie wdrożenie, rozważ prototypowanie przepływu (dostawcy → karty wyników → recenzje → zatwierdzenia → raporty) na platformie, która potrafi wygenerować działającą aplikację z jasnej specyfikacji. Na przykład Koder.ai jest platformą vibe-coding, gdzie możesz budować web, backend i mobile przez interfejs czatu, a potem eksportować kod źródłowy, gdy będziesz gotowy. To praktyczny sposób na walidację modelu punktacji i ról zanim zainwestujesz w niestandardowe UI i integracje.
Dla większości zespołów modularny monolit to dobre wyjście: jedna aplikacja do wdrożenia, zorganizowana w moduły (Vendors, Scorecards, Reviews, Reporting, Admin). Masz prostszą pracę przy developmentcie i debugowaniu oraz łatwiejsze bezpieczeństwo i wdrożenia.
Przejdź do oddzielnych serwisów dopiero, gdy masz silny powód — np. ciężkie obciążenia raportowania, wiele zespołów produktowych lub wymogi izolacji. Typowa ścieżka ewolucji: monolit teraz, z czasem wydziel „imports/reporting”.
REST API zwykle jest najłatwiejsze do integracji z narzędziami zakupowymi. Dąż do przewidywalnych zasobów i kilku endpointów „zadaniowych”, gdzie system wykonuje realną pracę.
Przykłady:
/api/vendors (create/update vendors, status)/api/vendors/{id}/scores (current score, historical breakdown)/api/vendors/{id}/reviews (list/create reviews)/api/reviews/{id} (update, moderate actions)/api/exports (request exports; returns job id)Trzymaj ciężkie operacje (eksporty, masowe przeliczenia) asynchroniczne, aby UI pozostał responsywny.
Używaj kolejki zadań do:
To także pomaga w automatycznym retry i uniknięciu ręcznego gaszenia pożarów.
Dashboardy mogą być kosztowne. Cache’uj agregowane metryki (po zakresie dat, kategorii, jednostce biznesowej) i unieważniaj przy istotnych zmianach albo odświeżaj według harmonogramu. Dzięki temu ekran dashboardu jest szybki, a drill-down pozostaje dokładny.
Napisz dokumentację API (OpenAPI/Swagger jest ok) i utrzymuj wewnętrzny, przyjazny adminom przewodnik w formie /blog — np. „Jak działa scoring”, „Jak obsługiwać sporne recenzje”, „Jak uruchamiać eksporty” — i linkuj go z aplikacji na /blog, aby było łatwo znaleźć i aktualizować.
Zacznij od wskazania jednego „użytkownika rdzeniowego” i zoptymalizuj pierwsze wydanie pod ich przepływ pracy (często jest to dział zakupów). Zapisz:
Funkcje dla finansów lub operacji dodawaj tylko wtedy, gdy potrafisz jasno wyjaśnić, jaką nową decyzję to umożliwia.
Wybierz definicję wcześnie i zaprojektuj model danych wokół niej:
Jeśli nie jesteś pewien, modeluj dostawcę jako parent z elementami podrzędnymi (jednostki: zakłady/linie usług), żeby później móc zwinąć lub rozwinąć poziomy raportowania.
Używaj ważonych KPI, gdy masz wiarygodne dane operacyjne i chcesz automatyzacji oraz przejrzystości. Używaj rubryk, gdy oceny są głównie jakościowe lub niespójne między zespołami.
Praktyczny domyślny wybór to model hybrydowy:
Niezależnie od metody, upewnij się, że jest ona zrozumiała dla audytorów i dostawców.
Zacznij od niewielkiego zestawu, który większość interesariuszy zna i potrafi konsekwentnie zmierzyć:
Dla każdego KPI zdefiniuj dokładnie definicję, skalę i źródło danych zanim zaczniesz budować UI czy raporty.
Wybierz skalę, którą ludzie potrafią opisać słownie (zwykle 1–5 lub 0–100) i zdefiniuj progi w jasnym języku.
Przykład:
Unikaj ocen opartych na „wrażeniu”. Jasne progi zmniejszają spory między recenzentami i ułatwiają porównania między zespołami.
Wybierz i udokumentuj jedną politykę dla każdego KPI i stosuj ją konsekwentnie:
Dodatkowo przechowuj wskaźnik jakości danych (np. ), żeby raporty mogły odróżnić „zły wynik” od „brakujących danych”.
Traktuj spory jako proces z możliwością śledzenia wyników:
Przechowuj identyfikator wersji (np. calculation_run_id), aby można było wiarygodnie odpowiedzieć na pytanie „co się zmieniło od ostatniego kwartału?”.
Minimum schematu zwykle obejmuje:
Dodaj też pola ułatwiające śledzenie: znaczniki czasu, identyfikatory aktorów, źródło systemu + zewnętrzne ID oraz referencję do wersji obliczeń, aby każda wartość mogła być wytłumaczona i odtworzona.
Planuj kilka ścieżek ingestii, nawet jeśli zaczynasz od jednej:
Na etapie importu egzekwuj wymagane pola, zakresy numeryczne i wykrywanie duplikatów. Przechowuj niepoprawne wiersze z jasnymi komunikatami o błędach, żeby administratorzy mogli poprawić plik i ponownie wysłać bez utraty kontekstu.
Używaj kontroli dostępu opartej na rolach i traktuj zmiany jako propozycje:
Rejestruj każde ważne zdarzenie (edytowanie, zatwierdzenia, eksporty, zmiany uprawnień) z wartościami przed/po. To chroni zaufanie i upraszcza audyty — zwłaszcza gdy dostawcy mają dostęp do danych.
data_quality_flag