15 lis 2025·8 min
Jak stworzyć aplikację web do roszczeń gwarancyjnych i zgłoszeń serwisowych
Dowiedz się, jak zaplanować, zbudować i wdrożyć aplikację web do roszczeń gwarancyjnych i zgłoszeń serwisowych: formularze, przepływy, zatwierdzenia, aktualizacje statusu i integracje.
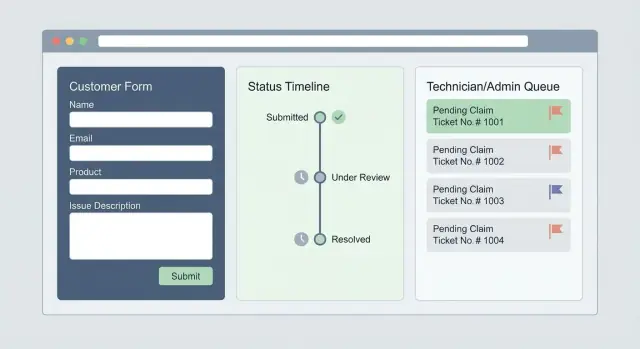
Co powinna robić aplikacja web do roszczeń gwarancyjnych i zgłoszeń serwisowych
Aplikacja do roszczeń i serwisu zastępuje rozrzucone maile, PDF-y i telefony jednym miejscem do zgłaszania problemów, weryfikacji uprawnień i śledzenia postępów.
Zanim pomyślisz o funkcjach, ustal dokładnie problem, który rozwiązujesz, i wyniki, które chcesz poprawić.
Zdefiniuj zakres: roszczenia, zgłoszenia serwisowe czy oba
Zacznij od jasnego rozróżnienia między dwoma podobnymi (ale innymi) ścieżkami:
- Roszczenia gwarancyjne: „Czy to jest objęte?” plus dowód zakupu, warunki gwarancji oraz decyzja o akceptacji/odmowie.
- Zgłoszenia serwisowe (poza gwarancją lub ogólne wsparcie): „Czy to naprawimy?” plus diagnostyka, umawianie i płatność, jeśli potrzeba.
Wiele zespołów obsługuje oba w jednym portalu, ale aplikacja powinna poprowadzić użytkownika właściwą ścieżką, żeby nie złożył niewłaściwego zgłoszenia.
Poznaj użytkowników, dla których budujesz
Funkcjonalny system zwykle obsługuje cztery grupy:
- Klienci, którzy składają zgłoszenia, przesyłają dokumenty i sprawdzają status.
- Agenci wsparcia, którzy triagują, zadają pytania uzupełniające i zatwierdzają kolejne kroki.
- Technicy/partnerzy serwisowi, którzy diagnozują, naprawiają i zapisują części oraz robociznę.
- Managerowie, którzy nadzorują wydajność, wyjątki i główne koszty.
Każda grupa potrzebuje dostosowanego widoku: klienci jasności, zespoły wewnętrzne kolejek, przydziałów i historii.
Zdefiniuj „sukces” w mierzalnych kategoriach
Dobre cele są praktyczne i mierzalne: mniej maili tam i z powrotem, szybsza pierwsza odpowiedź, mniej niekompletnych zgłoszeń, krótszy czas do rozwiązania i wyższa satysfakcja klienta.
Te rezultaty powinny kształtować twoje funkcje obowiązkowe (śledzenie statusu, powiadomienia i spójne zbieranie danych).
Tylko samoobsługa, czy także narzędzia back-office?
Prosty portal samoobsługowy często nie wystarcza. Jeśli twój zespół nadal zarządza pracą w arkuszach, aplikacja powinna zawierać też narzędzia wewnętrzne: kolejki, własność spraw, ścieżki eskalacji i logowanie decyzji.
W przeciwnym razie przeniesiesz przyjmowanie zleceń online, zostawiając chaos w tle.
Zdefiniuj przepływ zanim zbudujesz
Aplikacja do roszczeń udaje się lub nie w zależności od przepływu pod spodem. Zanim zaprojektujesz ekrany lub wybierzesz system ticketowy, zapisz ścieżkę end-to-end jaką przejdzie zgłoszenie — od momentu złożenia do zamknięcia i zapisania wyniku.
Zmapuj przepływ end-to-end (i utrzymaj czytelność)
Zacznij od prostego schematu: zgłoszenie → przegląd → akceptacja → serwis → zamknięcie. Potem dodaj rzeczywiste szczegóły, które zwykle psują projekty:
- Jakie informacje są wymagane na każdym etapie (numer seryjny, dowód zakupu, zdjęcia, kody błędów)?
- Jakie decyzje są podejmowane (uprawniony vs nieuprawniony, naprawa vs wymiana, wysyłka do serwisu vs serwis u klienta)?
- Co jest tworzone „w tle” (sprawa, numer RMA, zlecenie naprawy, etykieta wysyłkowa)?
Dobrym ćwiczeniem jest zmapowanie przepływu na jednej stronie. Jeśli się nie mieści, to znak, że proces trzeba uprościć zanim portal będzie prosty.
Oddziel roszczenia gwarancyjne od płatnych zgłoszeń serwisowych
Nie wciskaj dwóch różnych podróży w jedną.
Roszczenia gwarancyjne i płatne zgłoszenia serwisowe często mają różne zasady, ton i oczekiwania:
- Gwarancja: walidacja, reguły uprawnień, możliwa bezpłatna naprawa, jasne komunikaty o polityce.
- Płatny serwis: kosztorysy, kroki płatności, zgody i inny zestaw pytań dla klienta.
Oddzielając je zmniejszasz zamieszanie i zapobiegasz „niespodziankom” (np. klient myśli, że płatna naprawa jest objęta gwarancją).
Zdefiniuj statusy widoczne dla klienta
Klienci powinni zawsze wiedzieć, na jakim etapie się znajdują. Wybierz niewielki zestaw statusów, które potrafisz utrzymać — np. Submitted, In Review, Approved, Shipped, Completed — i zdefiniuj, co każdy oznacza wewnętrznie.
Jeśli nie potrafisz wyjaśnić statusu jednym zdaniem, jest zbyt ogólny.
Zidentyfikuj przekazania i właścicieli
Każde przekazanie to punkt ryzyka. Uczyń własność jasną: kto przegląda, kto zatwierdza wyjątki, kto umawia, kto obsługuje wysyłkę, kto zamyka.
Gdy krok nie ma jasnego właściciela, kolejki rosną, a klienci czują się zignorowani — bez względu na to, jak dopracowana wygląda aplikacja.
Projekt formularzy roszczeń i zgłoszeń serwisowych
Formularz to „drzwi wejściowe” do aplikacji. Jeśli jest mylący lub prosi o za dużo, klienci porzucają go — albo składają niskiej jakości zgłoszenia, które generują później pracę ręczną.
Dąż do jasności, szybkości i wystarczającej struktury, by skierować sprawę poprawnie.
Zbieraj właściwe informacje (i nic ponadto)
Zacznij od zwięzłego zestawu pól wspierających walidację gwarancji i proces RMA:
- Dane klienta (imię, e-mail, telefon, adres jeśli wysyłka może być wymagana)
- Model produktu, numer seryjny i data zakupu
- Opis problemu (krótka podpowiedź: „Co się stało? Kiedy to się zaczęło? Czy są kody błędów?”)
Jeśli sprzedajesz przez resellerów, dodaj dropdown „Gdzie kupiono?” i pokaż pole „Prześlij paragon” tylko gdy trzeba.
Załączniki, które pomagają technikom działać
Załączniki zmniejszają wymianę informacji, ale tylko jeśli ustawisz oczekiwania:
- Pozwalaj na zdjęcia, krótkie filmy i upload faktur/paragonów
- Ustal jasne limity typów plików i rozmiarów (np. JPG/PNG/PDF, oraz maks. rozmiar filmu)
- Pokaż wskazówki obok przycisku upload („Zdjęcie etykiety seryjnej”, „Film pokazujący problem”)
Treść zgody i prywatność, które klient zrozumie
Używaj prostych, konkretnych checkboxów zgody (bez prawniczego ściany tekstu). Na przykład: zgoda na przetwarzanie danych osobowych do obsługi zgłoszenia oraz zgoda na udostępnienie danych wysyłkowych przewoźnikom, jeśli konieczny jest zwrot.
Link to /privacy-policy for full details.
Reguły walidacji, które zapobiegają złym zgłoszeniom
Dobra walidacja sprawia, że portal wydaje się „inteligentny”, a nie restrykcyjny:
- Wymagaj pól tylko tam, gdzie to naprawdę konieczne
- Sprawdzaj formaty (e-mail, telefon, data zakupu)
- Sprawdzaj wzorce numeru seryjnego, gdzie to możliwe
Gdy coś jest nie tak, wyjaśnij to jednym zdaniem i zachowaj dane wprowadzone przez klienta.
Walidacja gwarancji i reguły decyzyjne
Reguły walidacji to moment, kiedy aplikacja przestaje być „formularzem” a zaczyna być narzędziem wspierającym decyzje. Dobre reguły zmniejszają wymianę informacji, przyspieszają zatwierdzenia i utrzymują spójność wyników między agentami i regionami.
Reguły uprawnień gwarancyjnych
Zacznij od jasnych kontroli uprawnień uruchamianych od razu po przesłaniu zgłoszenia:
- Okres ochrony: oblicz pokrycie na podstawie daty zakupu (lub daty wysyłki, jeśli taka jest polityka). Obsłuż przypadki brzegowe jak „90 dni od rejestracji” lub plany rozszerzone.
- Dowód zakupu: akceptuj upload paragonu, numer faktury lub ID zamówienia sprzedawcy. Jeśli dowód brak, skieruj sprawę do kolejki „Needs info” zamiast ją odrzucać.
- Format numeru seryjnego: waliduj długość/prefiks/cyfrę kontrolną i blokuj niemożliwe wartości. Jeśli masz wiele linii produktów, wykrywaj model z numeru seryjnego i podpowiadaj pola.
Logika pokrycia (co jest faktycznie objęte)
Oddziel „uprawniony” od „objętego gwarancją”. Klient może być w okresie ochrony, ale problem może być wyłączony.
Zdefiniuj reguły dla:
- Części vs robocizna: niektóre gwarancje pokrywają tylko części; robocizna może być usługą płatną.
- Wyłączenia: elementy zużywalne, uszkodzenia kosmetyczne, niewłaściwe użycie, nieautoryzowane naprawy.
- Uszkodzenia przypadkowe: często wymagają innego planu lub autoryzacji płatnej naprawy.
- Różnice regionalne: warunki gwarancji, adresy zwrotów i sformułowania prawne mogą się różnić.
Uczyń te reguły konfigurowalnymi (według produktu, regionu i planu), aby zmiany polityki nie wymagały wydania kodu.
Wykrywanie duplikatów
Uniemożliwiaj powstawanie duplikatów zanim staną się podwójnymi wysyłkami:
- Oznacz powtarzające się numery seryjne w danym przedziale czasowym.
- Wykrywaj powtarzające się zgłoszenia klientów używając e-mail/telefon + podobna kategoria problemu.
- Scalaj lub łącz sprawy automatycznie, zachowując ślad audytu.
Reguły eskalacji
Automatycznie eskaluj, gdy ryzyko jest wysokie:
- Zagrożenia bezpieczeństwa (dym, przegrzewanie, wstrząsy) powinny przejść do kolejki priorytetowej z przygotowanymi krokami.
- Powtarzające się awarie (np. trzecie zgłoszenie dla tego samego numeru seryjnego/modelu) powinny wywołać przegląd inżynieryjny lub wyższą zgodę.
Decyzje te powinny być wytłumaczalne: każda akceptacja, odmowa czy eskalacja wymaga widocznego „dlaczego” dla agentów i klientów.
Role użytkowników, uprawnienia i wewnętrzne kolejki
Aplikacja udaje się lub nie w zależności od tego „kto co może” i jak praca przepływa przez zespół. Jasne role zapobiegają przypadkowym edycjom, chronią dane klientów i zapobiegają zatrzymaniu zgłoszeń.
Zdefiniuj role i uprawnienia
Zacznij od spisu minimalnych ról, jakie portal potrzebuje:
- Klient: tworzy roszczenia, przesyła dowody, widzi status, akceptuje kosztorysy i widzi szczegóły wysyłki/wizyty.
- Agent: przegląda zgłoszenia, prosi o brakujące informacje, stosuje wyniki walidacji gwarancji i komunikuje decyzje.
- Technik: ma dostęp do przypisanych zadań naprawczych, not diagnostycznych, użytych części i aktualizacji zakończenia (bez wrażliwych danych rozliczeniowych, jeśli niepotrzebne).
- Admin: zarządza regułami, dostępem użytkowników, szablonami, SLA i logami audytu.
- Partner/serwis zewnętrzny: ograniczony dostęp tylko do przypisanych RMA/napraw z zakresem widocznych danych klienta.
Używaj grup uprawnień zamiast jednorazowych wyjątków i domyślnie stosuj zasadę najmniejszych uprawnień.
Zaplanuj kolejkę agentów (filtry, przydział, priorytety, SLA)
Twój system ticketowy potrzebuje wewnętrznej kolejki wyglądającej jak panel kontrolny: filtry po linii produktowej, typie roszczenia, regionie, „czeka na klienta” i „ryzyko naruszenia SLA”.
Dodaj reguły priorytetu (np. kwestie bezpieczeństwa najpierw), automatyczny przydział (round-robin lub według umiejętności) oraz timery SLA, które pauzują, gdy czekasz na klienta.
Notatki wewnętrzne vs komentarze widoczne dla klienta
Oddziel notatki wewnętrzne (triage, sygnały fraudu, kompatybilność części, kontekst eskalacji) od aktualizacji widocznych dla klienta.
Zaznacz widoczność przed publikacją i loguj edycje.
Szablony odpowiedzi dla spójności
Stwórz szablony do typowych odpowiedzi: brak numeru seryjnego, odmowa z powodu braku gwarancji, zatwierdzenie autoryzacji naprawy, instrukcje wysyłkowe i potwierdzenie wizyty.
Pozwól agentom personalizować wiadomości, zachowując zgodność i spójność języka.
Śledzenie statusu dla klienta i powiadomienia
Zbuduj portal roszczeń szybko
Przekształć notatki o przepływie pracy w działający portal roszczeń za pomocą czatu Koder.ai.
Portal wydaje się prosty, gdy klienci nigdy nie muszą się zastanawiać, co się dzieje. Śledzenie statusu to nie tylko etykieta jak Open czy Closed — to jasna opowieść o tym, co będzie dalej, kto musi działać i kiedy.
Zbuduj stronę statusu, której można zaufać
Stwórz dedykowaną stronę statusu dla każdego zgłoszenia z prostą osi czasu.
Każdy krok powinien wyjaśniać, co oznacza w prostym języku (i co klient ma zrobić, jeśli cokolwiek).
Typowe etapy: zgłoszenie przesłane, przedmiot odebrany, weryfikacja w toku, zatwierdzone/odrzucone, umówiona naprawa, naprawa zakończona, wysłane/gotowe do odbioru, zamknięte.
Dodaj „co będzie dalej” pod każdym krokiem. Jeśli następny krok wymaga działania klienta (np. przesłanie dowodu zakupu), zrób to wyróżnionym przyciskiem — nie ukrytym notatką.
Wysyłaj aktualizacje w momentach, które mają znaczenie
Automatyczne powiadomienia email/SMS zmniejszają telefony z pytaniem „czy są jakieś informacje?” i utrzymują oczekiwania.
Wyzwalaj wiadomości przy kluczowych zdarzeniach, takich jak:
- Otrzymaliśmy twoje zgłoszenie
- Otrzymaliśmy przedmiot
- Roszczenie zatwierdzone/odrzucone (z powodem i kolejnymi krokami)
- Serwis zaplanowany/przełożony
- Naprawa zakończona / wymiana zatwierdzona
- Zgłoszenie zamknięte (z podsumowaniem)
Pozwól klientom wybrać kanały i częstotliwość (np. SMS tylko do umawiania wizyt). Utrzymuj spójne szablony, dołącz numer sprawy i odwołanie do strony statusu.
Dodaj centrum wiadomości (z audytowalnością)
Dołącz centrum wiadomości, aby rozmowa była przyczepiona do sprawy.
Obsługuj załączniki (zdjęcia, rachunki, etykiety wysyłkowe) i prowadź ślad audytu: kto co wysłał, kiedy i które pliki dodano. To jest bezcenne przy sporach.
Zmniejsz wolumen zapytań dzięki kontekstowej pomocy
Używaj krótkich FAQ i podpowiedzi przy polach formularza, aby zapobiec złym zgłoszeniom: przykłady akceptowalnego dowodu zakupu, gdzie znaleźć numer seryjny, wskazówki pakowania i oczekiwany czas realizacji.
Link deeper guidance when needed (e.g., /help/warranty-requirements, /help/shipping).
Operacje serwisowe: umawianie, wysyłka i naprawy
Gdy roszczenie zostanie zatwierdzone (lub wstępnie zaakceptowane pod warunkiem inspekcji), aplikacja musi zamienić „ticket” na rzeczywistą pracę: wizytę, wysyłkę, zlecenie naprawy i jasne zamknięcie.
Tu wiele portali zawodzi — klienci utkną, a zespoły serwisowe wracają do arkuszy.
Umawianie usług zgodne z twoją rzeczywistością
Obsługuj zarówno wizyty u klienta, jak i naprawy w serwisie.
UI harmonogramu powinno pokazywać dostępne okna na podstawie kalendarzy techników, godzin pracy, limitów pojemności i regionu serwisowego.
Praktyczny flow: klient wybiera typ usługi → potwierdza adres/lokalizację → wybiera slot → otrzymuje potwierdzenie i instrukcje przygotowawcze (np. „przygotuj dowód zakupu”, „zrób kopię zapasową danych”, „usuń akcesoria”).
Jeśli używasz dispatchingu, pozwól użytkownikom wewnętrznym przemieszczać techników bez psucia terminu klienta.
Wysyłka i zwroty: RMA bez mailowego ping-ponga
Dla napraw w serwisie, traktuj wysyłkę jako funkcję pierwszorzędną:
- Generuj automatycznie numer RMA i pokazuj go wyraźnie.
- Udostępniaj do druku etykiety wysyłkowe (lub prośbę o odbiór) oraz jasne instrukcje pakowania.
- Pokazuj śledzenie przyjęcia/wysyłki, aby klient widział, gdzie jest przedmiot bez dzwonienia.
Wewnątrz aplikacji śledź kluczowe zdarzenia skanowania (etykieta utworzona, w tranzycie, odebrano, odesłano), aby zespół mógł odpowiedzieć „gdzie to jest?” w kilka sekund.
Części i zapasy (opcjonalne, ale przydatne)
Nawet jeśli nie budujesz pełnego systemu magazynowego, dodaj lekką obsługę części:
- „Zamów części” dla zlecenia (z wymogiem zatwierdzenia, jeśli potrzeba)
- Śledź części użyte na naprawę dla kalkulacji kosztów i odzysku gwarancyjnego
- Zaznacz opóźnienia i spodziewane terminy przybycia
Jeśli masz ERP, może to być proste zsynchronizowanie zamiast nowego modułu.
Dowód wykonania i czyste zakończenie
Naprawa nie jest „zrobiona”, dopóki nie będzie udokumentowana.
Zapisz:
- Notatki technika (co znaleziono, co wymieniono)
- Zdjęcia (przed/po) jako załączniki
- Potwierdzenie klienta: podpis na miejscu lub w portalu „usługa zakończona”
Zakończ jasnym podsumowaniem i dalszymi krokami (np. pozostała gwarancja, faktura jeśli poza gwarancją, oraz informacja o możliwości ponownego otwarcia zgłoszenia jeśli problem wróci).
Integracje: CRM, ERP, płatności i logistyka
Uczyń aktualizacje statusu jasnymi
Utwórz statusy i powiadomienia, które zmniejszą liczbę maili i telefonów z pytaniem o status.
Integracje zamieniają portal w system, którym rzeczywiście można zarządzać. Cel jest prosty: wyeliminować podwójne wprowadzanie, zmniejszyć błędy i utrzymać klientów w procesie RMA z mniejszą liczbą przekazań.
CRM / helpdesk: jeden klient, jedna rozmowa
Wiele firm już śledzi interakcje w CRM lub helpdesku. Twój portal powinien synchronizować podstawowe dane, aby agenci nie pracowali w dwóch systemach:
- Twórz lub aktualizuj ticket przy złożeniu roszczenia (wraz z załącznikami, nr seryjnym i żądanym wynikiem).
- Synchronizuj zmiany statusu w obie strony (np. „Czeka na zdjęcia”, „Zatwierdzone”, „Wysłane”, „Naprawione”, „Zamknięte”).
- Powiąż roszczenie z profilem klienta, by historia wsparcia była widoczna podczas follow-upów.
Jeśli już używasz workflowów/makropoleceń w helpdesku, mapuj swoje wewnętrzne kolejki do tych stanów zamiast tworzyć równoległy proces.
ERP / dane zamówień: weryfikacja zakupów i katalog produktów
Walidacja gwarancji zależy od rzetelnych danych zakupowych i produktowych. Lekka integracja z ERP może:
- Weryfikować dowód zakupu używając numeru zamówienia, e-maila klienta lub ID faktury
- Pobierać SKU produktu, warunki gwarancji i dostępne opcje serwisu
- Zapobiegać niezgodnościom (błędnie wybrany model, nieprawidłowy format numeru seryjnego, duplikaty zgłoszeń)
Nawet jeśli ERP jest chaotyczny, zacznij od integracji tylko do odczytu — potem rozszerz do zapisu (numery RMA, koszty serwisu) gdy przepływ się ustabilizuje.
Płatności za pracę poza gwarancją
Dla usług poza gwarancją podłącz dostawcę płatności do ofert, faktur i linków do płatności.
Kluczowe elementy:
- Powiąż płatności z ID zgłoszenia i przechowuj referencję transakcji
- Wspieraj „zapłać przed umówieniem” lub „zatwierdź kosztorys, potem płać”, zależnie od polityki
- Uczynij zwroty/adjustacje widocznymi na osi czasu sprawy
Logistyka: etykiety wysyłkowe, śledzenie i wyjątki
Integracje wysyłkowe redukują ręczne tworzenie etykiet i dają klientom automatyczne aktualizacje śledzenia.
Zbieraj zdarzenia śledzenia (dostarczono, nieudane doręczenie, zwrot do nadawcy) i kieruj wyjątki do wewnętrznej kolejki.
Zaplanuj API i udokumentuj dane, które wystawiasz
Nawet jeśli zaczynasz tylko z kilkoma integracjami, zdefiniuj webhooks/API wcześnie:
- Webhooki dla zdarzeń jak claim.created, claim.approved, shipment.created, payment.received
- API do odczytu statusu zgłoszenia i zapisu notatek/aktualizacji statusu
- Jasne definicje pól (ID, timestampy, enumy statusów), by przyszłe systemy integrowały się bez domysłów
Mała specyfikacja integracji teraz zapobiegnie drogim przeróbkom później.
Bezpieczeństwo, prywatność i audytowalność
Bezpieczeństwo nie jest funkcją „na później” w aplikacji gwarancyjnej — kształtuje jak zbierasz dane, jak je przechowujesz i kto ma do nich dostęp.
Celem jest ochrona klientów i zespołu bez uprzykrzania korzystania z portalu.
Zbieraj tylko to, co potrzebne
Każde dodatkowe pole zwiększa ryzyko i tarcie. Proś tylko o minimalne informacje potrzebne do walidacji gwarancji i skierowania zgłoszenia (np. model produktu, numer seryjny, data zakupu, dowód zakupu).
Gdy prosisz o wrażliwe lub „dodatkowe” dane, wytłumacz to prostym językiem („Używamy numeru seryjnego do potwierdzenia pokrycia gwarancyjnego” lub „Potrzebujemy zdjęć do oceny uszkodzeń przy wysyłce”). To zmniejsza porzucenia i zapytania do supportu.
Kontrola dostępu i bezpieczne przechowywanie
Stosuj dostęp oparty na rolach, aby ludzie widzieli tylko to, co muszą:
- Klienci: tylko własne sprawy i załączniki
- Agenci: przypisane kolejki; ograniczony dostęp do danych płatniczych
- Technicy: szczegóły napraw i zdjęcia, bez danych rozliczeniowych
- Admini: konfiguracja i raportowanie, z podwyższonymi akcjami zapisywanymi w logach
Szyfruj dane w tranzycie (HTTPS) i w spoczynku (baza danych i backupy).
Przechowuj uploady (rachunki, zdjęcia) w bezpiecznym obiekcie storage z prywatnym dostępem i czasowo ograniczonymi linkami do pobrania — nie publicznymi URL-ami.
Zaufane logi audytu
Decyzje gwarancyjne wymagają śledzenia. Prowadź log audytu kto co zmienił, kiedy i skąd:
- Zmiany statusów (Submitted → In Review → Approved/Denied)
- Wyniki walidacji i wersje reguł
- Autoryzacje naprawy (utworzono RMA, wydano etykiety)
- Edycje notatek i działania na załącznikach
Uczyń logi append-only i przeszukiwalne, by szybko rozwiązywać spory.
Zasady przechowywania i usuwania danych
Zdefiniuj, jak długo przechowujesz dane klientów i załączniki oraz jak działa usuwanie (w tym backupy).
Na przykład: rachunki przechowywane X lat dla zgodności; zdjęcia usuwane po Y miesiącach od zamknięcia sprawy. Zapewnij jasną ścieżkę realizacji żądań usunięcia tam, gdzie to stosowne.
Architektura i wybory technologiczne (bez overengineerowania)
Aplikacja do roszczeń nie potrzebuje skomplikowanego mikroserwisowego stacku, żeby działać dobrze.
Zacznij od najprostszej architektury, która wspiera twój przepływ, utrzymuje spójność danych i łatwo pozwala zmieniać polityki lub produkty.
Wybierz podejście do budowy pasujące do realiów
Zwykle są trzy ścieżki:
- Rozszerzenie istniejącego helpdesku/ticketingu jeśli potrzebujesz głównie portalu zgłoszeń, kolejek wewnętrznych i mailowych aktualizacji. To często najszybsze, ale może się skomplikować gdy dodasz walidację gwarancji, kroki RMA lub logikę autoryzacji napraw.
- Low-code jeśli zespół potrafi szybko skonfigurować formularze, statusy i automatyzacje — dobre na wczesne wersje, ale trzeba pilnować ograniczeń integracji i raportowania.
- Budowa custom gdy reguły decyzyjne, integracje (CRM/ERP/logistyka) i własność danych są kluczowe. Prosty monolit z czystą bazą danych zwykle jest najlepszym początkiem.
Jeśli chcesz szybko wypuścić prototyp (formularz → przepływ → strona statusu) i iterować ze stakeholderami, platforma typu Koder.ai może pomóc wygenerować portal React + backend Go/PostgreSQL z chatowego specu — a następnie wyeksportować kod do produkcji.
Zacznij od jasnego, nudnego modelu danych
Większość projektów udaje się, gdy podstawowe encje są oczywiste:
- Klienci (i kontakty)
- Produkty (z numerami seryjnymi, datami zakupu, plikami dowodu)
- Roszczenia (samo zgłoszenie: powód, zdjęcia, notatki, status)
- Zlecenia serwisowe (wydarzenia naprawcze, użyte części, notatki technika)
- Wiadomości (wątki komunikacji i załączniki)
Zaprojektuj je tak, by odpowiadały na podstawowe pytania: „Co się stało?”, „Jaka była decyzja?” i „Jakie prace wykonano?”.
UI mobile-first i lekki panel admina
Zakładaj, że wielu użytkowników złoży zgłoszenie z telefonu. Priorytetyzuj szybkie strony, duże kontrolki formularza i łatwy upload zdjęć.
Trzymaj konfigurację poza kodem, budując mały panel admina dla statusów, kodów przyczyn, szablonów i SLA.
Jeśli zmiana etykiety statusu wymaga developera, proces szybko stanie się powolny.
Testy, szkolenia i lista kontrolna uruchomienia
Wysyłaj i poprawiaj co tydzień
Wdrażaj, hostuj oraz używaj snapshotów i rollbacków, by aktualizacje były bezpieczniejsze.
Wypuszczenie aplikacji to nie tylko „niech działa”. To upewnienie się, że prawdziwy klient złoży zgłoszenie w 2 minuty, zespół obsłuży je bez domysłów, a nic nie zepsuje się przy dużym ruchu.
Krótka, praktyczna lista kontrolna zaoszczędzi tygodnie sprzątania po starcie.
Najpierw prototypuj formularz i stronę statusu
Zanim zbudujesz wszystkie integracje, zaprototypuj dwa ekrany:
- formularz zgłoszenia/serwisu
- stronę statusu zgłoszenia (co widzi klient po wysłaniu)
Postaw prototyp przed prawdziwymi użytkownikami (klientami i personelem) i przeprowadź 30-minutowy test. Obserwuj, gdzie się wahają: pole numeru seryjnego? krok uploadu? „data zakupu”? To miejsca, gdzie formularze zwykle zawodzą.
Testuj przypadki brzegowe, które generują tickety
Większość awarii dzieje się w „złych rzeczywistościach”, nie na ścieżkach idealnych.
Testuj wprost:
- Brak dowodu zakupu (jakie opcje ma klient?)
- Błędne formaty numerów seryjnych (walidacja i pomoc)
- Duże załączniki i wolne łącza
- Spam i powtarzające się zgłoszenia (rate limiting, CAPTCHA, weryfikacja e-mail)
Testuj też punkty decyzyjne: reguły walidacji, autoryzację naprawy (RMA) i co się dzieje przy odrzuceniu — czy klient dostaje jasne powody i kolejne kroki?
Stwórz środowisko staging i checklistę release
Użyj środowiska staging, które odzwierciedla produkcję (wysyłka maili, storage plików, uprawnienia) bez dotykania realnych danych klientów.
Dla każdego wydania wykonaj checklistę:
- wysłanie formularza, email potwierdzający i utworzenie ticketu
- aktualizacje statusu i powiadomienia do klienta
- kolejki wewnętrzne i dostęp według ról (support vs technicy)
- obsługa załączników i skanowanie wirusów (jeśli włączone)
- wpisy w logu audytu dla kluczowych działań (zatwierdzenie/odmowa, wydanie RMA, przetworzenie zwrotu)
To zamienia każdą deployę z loterii w rutynę.
Szkolenie supportu i techników (i ułatw je)
Szkolenie powinno skupiać się na przepływie roszczeń, nie na UI.
Dostarcz:
- Jednostronicowy szybki przewodnik dla każdej roli (support, magazyn, technik)
- Małą bibliotekę gotowych odpowiedzi na typowe scenariusze (brak dowodu, poza gwarancją, instrukcje wysyłki)
- Jasną „definicję zakończenia” dla każdego stanu kolejki
Jeśli zespół nie potrafi wytłumaczyć etykiet statusu klientowi, etykiety są problemem. Napraw je przed startem.
Analityka, raportowanie i ciągłe ulepszanie
Analityka to nie tylko „miłe do posiadania” — to sposób, by portal był szybki dla klientów i przewidywalny dla twojego zespołu.
Buduj raporty wokół realnego przepływu: co klienci próbują zrobić, gdzie utkną i co się dzieje po złożeniu zgłoszenia.
Metryki lejka: zmniejsz porzucenia zgłoszeń
Zacznij od śledzenia, czy ludzie kończą formularz:
- Rozpoczęte vs przesłane zgłoszenia (całkowicie i wg urządzeń)
- Krok porzucenia (np. „numer seryjny”, „dowód zakupu”, „zdjęcia”)
- Powody porzucenia poprzez krótkie podpowiedzi „Co blokowało?” (brak info, niejasna polityka, za dużo pól)
Jeśli dużo porzucają na mobilu, potrzebujesz mniej wymaganych pól, lepszego uploadu zdjęć lub jaśniejszych przykładów.
Metryki operacyjne: popraw wydajność serwisu
Raporty operacyjne pomagają zarządzać ticketami:
- Czas do pierwszej odpowiedzi (wg kolejki, linii produktowej, priorytetu)
- Czas do rozwiązania (wliczając autoryzację/RMA)
- Wskaźnik ponownego otwarcia (sygnał, że wynik lub instrukcje nie były jasne)
Udostępniaj te dane liderom tygodniowo, nie tylko kwartalnie.
Tagi i kody przyczyn: wykrywaj problemy produktowe wcześnie
Dodaj strukturalne tagi/kody przyczyny do każdego roszczenia (np. „spuchnięcie baterii”, „usterka ekranu”, „uszkodzenie przy transporcie”).
Z czasem pokażą wzorce: partie produktów, regiony lub typy awarii. Te informacje pomagają zapobiegać przyszłym roszczeniom poprzez zmiany w opakowaniu, aktualizacje firmware lub lepsze instrukcje setupu.
Pętla ciągłego ulepszania (i dzielenie się nią)
Traktuj portal jak produkt. Prowadź małe eksperymenty (kolejność pól, treść, wymagania załączników), mierz wpływ i miej changelog.
Rozważ publiczną stronę zmian lub roadmapę (np. /blog), aby informować klientów o usprawnieniach — klienci to doceniają i to zmniejsza powtarzające się pytania.
Często zadawane pytania
Jaka jest różnica między aplikacją do roszczeń gwarancyjnych a portalem zgłoszeń serwisowych?
Zacznij od rozdzielenia dwóch ścieżek:
- Roszczenie gwarancyjne: walidacja uprawnień (okres, dowód zakupu, wyłączenia) i wydanie decyzji (zaakceptowane/odrzucone).
- Zgłoszenie serwisowe: diagnoza, umawianie wizyty i pobranie opłaty, jeśli konieczne.
Następnie buduj wokół rezultatów takich jak mniej niekompletnych zgłoszeń, szybsza pierwsza odpowiedź i krótszy czas rozwiązania.
Kto jest głównym użytkownikiem aplikacji do roszczeń i serwisu?
Typowy portal obsługuje:
- Klienci: składają zgłoszenia, przesyłają rachunki/zdjęcia, śledzą status.
- Agenci wsparcia: triage, proszą o brakujące informacje, zatwierdzają/odrzucają, komunikują decyzje.
- Technicy/partnerzy: zapisują diagnostykę, części/robociznę, zakończenia prac.
- Managerowie/admini: konfigurują reguły, monitorują SLA, przeglądają koszty i wyjątki.
Projektuj oddzielne widoki, aby każda rola widziała tylko to, czego potrzebuje.
Jak zmapować przepływ roszczenia gwarancyjnego przed zbudowaniem aplikacji?
Utrzymaj czytelność i pełny przebieg. Typowy szablon to:
- Złożenie zgłoszenia
- Przegląd/triage
- Walidacja gwarancji / decyzja
- Umówienie serwisu lub utworzenie RMA/wysyłki
- Naprawa/wymiana
- Zakończenie z dokumentacją
Jeśli proces nie mieści się na jednej stronie, uprość go zanim dodasz funkcje.
Jakie statusy widoczne dla klienta powinien zawierać portal roszczeń?
Użyj niewielkiego zestawu statusów, które potrafisz niezawodnie utrzymać, np.:
- Submitted
- In review
- Waiting on customer
- Approved / Denied
- Scheduled / Shipping label created
- Item received
- Repair in progress
- Shipped / Ready for pickup
Jakie informacje powinien wymagać formularz zgłoszenia?
Zbieraj tylko to, co niezbędne do walidacji i skierowania sprawy:
- Dane kontaktowe (adres tylko jeśli wysyłka/serwis u klienta)
- Model produktu + numer seryjny
- Data zakupu (lub data wysyłki, w zależności od polityki)
- Opis problemu z podpowiedziami (kody błędów, kiedy się pojawił)
Wyświetl pole do przesłania dowodu zakupu tylko wtedy, gdy jest to wymagane (np. sprzedaż przez resellerów).
Jak aplikacja powinna obsługiwać zdjęcia, filmy i dowody zakupu?
Uczyń przesyłanie plików przewidywalnym:
- Akceptuj zdjęcia, krótkie filmy i PDF-y (rachunki/faktury)
- Ustal jasne limity (formaty plików i maks. rozmiar)
- Dodaj podpowiedzi przy przycisku upload („Zdjęcie etykiety seryjnej”, „Film pokazujący problem”)
Jeśli upload zawiedzie, zachowaj wprowadzone dane i wytłumacz błąd w jednym zdaniu.
Jak aplikacja może zautomatyzować sprawdzanie uprawnień gwarancyjnych?
Zautomatyzuj pierwszy etap od razu po złożeniu zgłoszenia:
- Oblicz okres ochrony od daty zakupu/wysyłki (uwzględnij przypadki typu rejestracja/rozszerzone plany)
- Waliduj format numeru seryjnego (i wykrywaj linię produktową z numeru, jeśli możliwe)
- Weryfikuj dowód zakupu (upload rachunku, numer faktury, ID zamówienia sprzedawcy)
Jeśli brak dowodu, skieruj zgłoszenie do kolejki „Needs info” zamiast odrzucać.
Jakie funkcje bezpieczeństwa i prywatności są niezbędne dla aplikacji gwarancyjnej?
Stosuj dostęp oparty na rolach i zasadę najmniejszych uprawnień:
- Klienci widzą tylko swoje zgłoszenia i pliki
- Agenci widzą przypisane kolejki; ogranicz dostęp do danych płatniczych
- Technicy widzą zadania napraw, zdjęcia, ale nie szczegóły rozliczeń
- Admini mają dostęp konfiguracyjny; akcje podnoszące uprawnienia są logowane
Przechowuj załączniki w prywatnym storage z czasowo ograniczonymi linkami do pobrania, szyfruj dane w tranzycie i spoczynku oraz prowadź append-only logi audytu.
Które integracje są najważniejsze (CRM, ERP, płatności, logistyka)?
Integruj tam, gdzie zmniejsza to podwójną pracę:
- CRM/helpdesk: tworzenie/aktualizacja ticketów, synchronizacja statusów, historia rozmów
- ERP/dane zamówień: weryfikacja zakupu, pobieranie SKU/warunków gwarancji
- Płatności: oferty/faktury powiązane z ID zgłoszenia; zwroty zapisywane w osi czasu
- Logistyka: tworzenie etykiet, śledzenie przyjęć/wysyłek, obsługa wyjątków
Zaplanuj webhooks jak , , , wcześnie, aby uniknąć przebudowy później.
Co powinno się przetestować przed uruchomieniem aplikacji do roszczeń gwarancyjnych?
Testuj realne, problematyczne przypadki, nie tylko ścieżki idealne:
- Brak rachunku, błędne formaty numerów seryjnych, niekompletne pola
- Duże pliki i wolne łącza
- Duplikaty zgłoszeń, spam, ograniczenia (rate limiting, CAPTCHA)
- Odrzucenia/odmowy (czy klient dostaje jasne powody i dalsze kroki?)
Użyj środowiska staging, które odzwierciedla produkcję (wysyłka maili, storage, uprawnienia) i weryfikuj wpisy w logu audytu dla kluczowych działań jak zatwierdzenia, RMA i zwroty.