Określ cele i zakres śledzenia niezawodności
Zanim wybierzesz metryki lub zbudujesz dashboardy, zdecyduj, za co Twoja aplikacja do niezawodności odpowiada — i za co nie odpowiada. Jasny zakres zapobiega temu, by narzędzie stało się łapankowym „portalem ops”, któremu nikt nie ufa.
Zdefiniuj, co będziesz śledzić
Zacznij od wypisania narzędzi wewnętrznych, które aplikacja obejmie (np. system ticketowy, płace, integracje CRM, pipeline’y danych) oraz zespołów, które je posiadają lub zależą od nich. Bądź konkretny co do granic: „strona klienta” może być poza zakresem, a „konsola administracyjna wewnętrzna” — w zakresie.
Uzgodnij, co oznacza „niezawodność” tutaj
Różne organizacje używają tego słowa w inny sposób. Spisz roboczą definicję prostym językiem — zwykle to mieszanka:
- Dostępność: czy można się do tego dostać, gdy potrzeba?
- Opóźnienie: czy jest wystarczająco szybkie, by było użyteczne?
- Błędy: czy zawodzi w sposób zauważalny dla użytkowników (timeouty, awarie zadań, złe odpowiedzi)?
Jeśli zespoły się nie dogadają, aplikacja zacznie porównywać gruszki z jabłkami.
Zdecyduj o oczekiwanych rezultatach
Wybierz 1–3 główne rezultaty, np.:
- Szybsze wykrywanie problemów (krótszy „time to notice”)
- Czytelniejsze raporty dla menedżerów i interesariuszy
- Mniej powtarzających się incydentów dzięki lepszemu follow-upowi
Te cele będą później kierować tym, co mierzysz i jak to prezentujesz.
Zidentyfikuj użytkowników i role
Wypisz, kto będzie korzystać z aplikacji i jakie decyzje będzie podejmować: inżynierowie badający incydenty, support eskalujący kwestie, menedżerowie przeglądający trendy i interesariusze potrzebujący aktualizacji statusu. To ukształtuje terminologię, uprawnienia i poziom szczegółowości widoków.
Wybierz metryki niezawodności, które się liczą (SLI/SLO)
Śledzenie niezawodności działa tylko wtedy, gdy wszyscy zgadzają się, co oznacza „dobrze”. Zacznij od rozdzielenia trzech podobnie brzmiących terminów.
SLI vs SLO vs SLA (prosto)
SLI (Service Level Indicator) to miara: „Jaki procent żądań się powiódł?” albo „Jak długo ładowały się strony?”.
SLO (Service Level Objective) to cel dla tej miary: „99,9% sukcesu w ciągu 30 dni”.
SLA (Service Level Agreement) to obietnica z konsekwencjami, zwykle zewnętrzna (kredyty, kary). Dla narzędzi wewnętrznych często ustawia się SLO bez formalnych SLA — wystarczająco, by wyrównać oczekiwania bez zamieniania niezawodności w prawo kontraktowe.
Wybierz mały, spójny zestaw SLI dla każdego narzędzia
Utrzymuj porównywalność między narzędziami i prostotę wyjaśnień. Praktyczny baseline to:
- Uptime/dostępność: czy narzędzie było osiągalne?
- Czas odpowiedzi: jak szybko odpowiadały kluczowe strony lub endpointy?
- Wskaźnik błędów: jaka część checków lub żądań zawiodła (5xx, timeouty, znane stany błędów)?
Nie dodawaj więcej, zanim nie będziesz mógł odpowiedzieć: „Jaką decyzję pchnie ta metryka?”
Wybierz okna czasowe zgodne z myśleniem ludzi
Używaj okien kroczących, tak aby scorecardy aktualizowały się ciągle:
- 7 dni: szybko łapie regresje
- 30 dni: raportowanie miesięczne i trendy
- 90 dni: stabilność kwartalna
Zdefiniuj incydenty z jasnymi poziomami ciężkości
Aplikacja powinna zamieniać metryki w działania. Zdefiniuj poziomy severity (np. Sev1–Sev3) i eksplicytne triggery, takie jak:
- Sev1: narzędzie niedostępne lub krytyczny workflow zablokowany przez X minut
- Sev2: poważne pogorszenie (np. wskaźnik błędów powyżej Y% przez Z minut)
- Sev3: drobne problemy lub sporadyczne awarie
Te definicje sprawiają, że alertowanie, timeline incydentów i śledzenie budżetu błędów będą spójne między zespołami.
Zaplanuj źródła danych i sposób ingestii
Aplikacja do śledzenia niezawodności jest tak wiarygodna, jak dane za nią stojące. Zanim zbudujesz pipeline’y ingestii, zmapuj każdy sygnał, który będziesz traktować jako „prawdę”, i zapisz, na jakie pytanie odpowiada (dostępność, opóźnienie, błędy, wpływ deployu, reakcja na incydent).
Zmapuj istniejące źródła danych
Większość zespołów może pokryć podstawy mieszanką:
- Status checks / synthetic probes (uptime i podstawowy czas odpowiedzi)
- Metryki (percentyle latency, wskaźniki błędów, saturacja)
- Logi (liczba błędów, najczęściej zawodne endpointy)
- Trace’y (gdzie spędzany jest czas w zależnościach)
- Narzędzia ticketowe/incydentowe (start/koniec incydentu, severity, właściciel, linki do postmortem)
Bądź jasny, które systemy są autorytatywne. Na przykład Twój „uptime SLI” może pochodzić tylko z synthetic probes, a nie z logów serwera.
Zdecyduj push vs pull (i jak często)
- Pull działa dobrze dla API (Prometheus, monitoring cloudowy, ticketing): aplikacja polluje w harmonogramie.
- Push jest lepszy dla zdarzeń o dużej objętości (deployy, incydenty, alerty): systemy wysyłają webhooki/wydarzenia do Twojej aplikacji.
Ustaw częstotliwość aktualizacji wg przypadku użycia: dashboardy mogą odświeżać się co 1–5 minut, scorecardy liczyć godzinowo/dziennie.
Normalizuj identyfikatory i właścicielstwo
Utwórz spójne ID dla narzędzi/usług, środowisk (prod/stage) i właścicieli. Uzgodnij reguły nazewnictwa wcześnie, aby „Payments-API”, „payments_api” i „payments” nie stały się trzema różnymi encjami.
Retencja i prywatność
Zaplanuj, co przechowywać i jak długo (np. surowe zdarzenia 30–90 dni, agregaty dzienne 12–24 miesiące). Unikaj ingestowania wrażliwych payloadów; przechowuj tylko metadane potrzebne do analizy niezawodności (znaczniki czasu, kody statusu, wiadra latencji, tagi incydentów).
Zaprojektuj model danych i schemat bazy
Twój schemat powinien ułatwiać dwie rzeczy: odpowiedzi na codzienne pytania („czy to narzędzie jest zdrowe?”) i odtworzenie, co się stało podczas incydentu („kiedy zaczęły się symptomy, kto co zmienił, jakie alerty zadziałały?”). Zacznij od małego zestawu core encji i jawnie przedstaw relacje.
Kluczowe encje (zacznij od minimum)
- Tool/Service: śledzone narzędzie wewnętrzne (nazwa, opis, środowisko, krytyczność).
- Check: konkretny check uptime lub synthetic powiązany z narzędziem (typ, target URL, harmonogram, enabled).
- Metric: punkty szeregów czasowych (latency, success rate, error count) powiązane z narzędziem lub checkiem.
- SLO: cel i okno ewaluacji (np. 99.9% w 30 dni) oraz ustawienia budżetu błędów.
- Incident: zdarzenie wpływające na niezawodność (severity, status, start/koniec, podsumowanie).
- Event: rekord osi czasu dla incydentów (zmiany stanu, notatki, alert odebrany, zastosowane mitigacje).
- Owner: zespół lub osoba odpowiedzialna za narzędzie.
Relacje upraszczające zapytania
Praktyczny baseline:
- Tool ma wiele Checks (i może mieć wiele SLO).
- Check ma wiele Metrics (lub strumieni metryk).
- Incident należy do Tool, a Incident ma wiele Events dla osi czasu.
- Tool należy do Owner (lub relacja wiele-do-wielu, jeśli współdzielone właścicielstwo jest częste).
Taka struktura obsługuje dashboardy („tool → aktualny status → ostatnie incydenty”) i drill-down („incydent → zdarzenia → powiązane checki i metryki”).
Pola audytu i tagowanie
Dodaj pola audytu tam, gdzie potrzebujesz odpowiedzialności i historii:
created_by, created_at, updated_atstatus plus śledzenie zmian statusu (albo w tabeli Event, albo dedykowana tabela historii)
Na koniec dodaj elastyczne tagi do filtrowania i raportowania (np. zespół, krytyczność, system, compliance). Tabela łącząca tool_tags (tool_id, key, value) utrzymuje spójność tagowania i ułatwia scorecardy oraz rollupy.
Wybierz stack technologiczny i model wdrożenia
Twój tracker niezawodności powinien być „nudny” w najlepszym sensie: łatwy do uruchomienia, łatwy do zmiany i łatwy do wsparcia. „Właściwy” stack to zwykle ten, który Twój zespół potrafi utrzymać bez bohaterstwa.
Zacznij od tego, co zespół już zna
Wybierz mainstreamowy web framework, który zespół zna dobrze — Node/Express, Django lub Rails to solidne opcje. Priorytetyzuj:
- Jasne konwencje (by nowi współpracownicy się nie gubili)
- Dobre biblioteki do auth, background jobs i wykresów
- Przewidywalne ścieżki aktualizacji
Jeśli integrujesz się z systemami wewnętrznymi (SSO, ticketing, chat), wybierz ekosystem, w którym te integracje są najprostsze.
Jeżeli chcesz przyspieszyć pierwszą iterację, platforma vibe-codingowa taka jak Koder.ai może być praktycznym punktem startu: opisujesz encje (tools, checks, SLO, incidents), workflowy (alert → incident → postmortem) i dashboardy w czacie, a następnie generujesz działający szkielet aplikacji. Ponieważ Koder.ai często celuje w React na frontendzie i Go + PostgreSQL na backendzie, dobrze mapuje się na domyślny „nudny, utrzymywalny” stack — i możesz wyeksportować kod źródłowy, jeśli później przejdziesz na w pełni ręczny pipeline.
Najpierw baza danych, potem komponenty wspierające
Dla większości wewnętrznych aplikacji niezawodności PostgreSQL jest domyślnym wyborem: radzi sobie z raportowaniem relacyjnym, zapytaniami czasowymi i audytem.
Dodawaj komponenty tylko wtedy, gdy rozwiązują realny problem:
- Cache (np. Redis), jeśli dashboardy są wolne lub jesteś limitowany przez upstream API
- Kolejka/background jobs (Redis + worker, Sidekiq, Celery, BullMQ) do pollowania uptime, wysyłania powiadomień i generowania raportów
Hosting i model wdrożenia
Zdecyduj między:
- Chmurą wewnętrzną / Kubernetes, gdy potrzebujesz szerszego dostępu sieciowego do usług wewnętrznych
- PaaS, gdy chcesz prostszych operacji i szybkiego iterowania
Cokolwiek wybierzesz, ustandaryzuj dev/staging/prod i zautomatyzuj wdrożenia (CI/CD), aby zmiany nie wpływały cicho na liczby niezawodności. Jeśli używasz podejścia platformowego (w tym Koder.ai), szukaj funkcji takich jak separacja środowisk, hosting/wdrożenia i szybki rollback (snapshoty), aby iterować bez łamania samego trackera.
Zarządzanie konfiguracją, któremu można ufać
Udokumentuj konfigurację w jednym miejscu: zmienne środowiskowe, sekrety i feature flagi. Zachowaj jasny „jak uruchomić lokalnie” przewodnik i minimalny runbook (co zrobić, gdy ingestia zatrzyma się, kolejka się zapełni lub baza dojdzie do limitów). Krótka strona w /docs zwykle wystarczy.
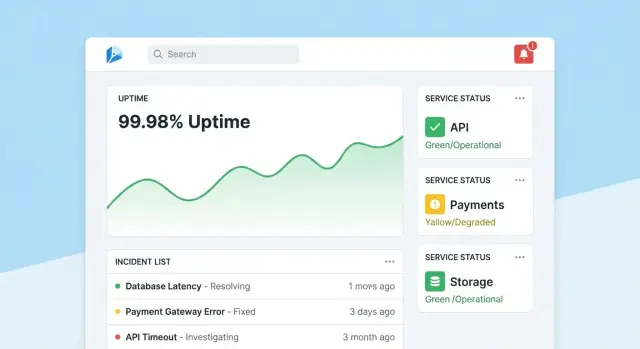
Zaprojektuj UX: dashboardy, drill-downy i workflowy
Przekształć SLO w dashboardy
Zbuduj widoki React dla scorecardów i drill-downów, generując backend w Go i PostgreSQL.
Aplikacja do śledzenia niezawodności odnosi sukces, gdy ludzie mogą w kilka sekund odpowiedzieć na dwa pytania: „Czy wszystko w porządku?” i „Co mam zrobić dalej?”. Projektuj ekrany wokół tych decyzji, z jasną nawigacją overview → konkretne narzędzie → konkretny incydent.
Strona główna: szybki odczyt zdrowia
Uczyń stronę główną kompaktowym centrum dowodzenia. Zacznij od ogólnego podsumowania zdrowia (np. liczba narzędzi spełniających SLO, aktywne incydenty, największe aktualne ryzyka), a potem pokaż ostatnie incydenty i alerty z odznakami statusu.
Utrzymaj domyślny widok spokojny: podkreślaj tylko to, co wymaga uwagi. Każda kafelka powinna mieć bezpośredni drill-down do dotkniętego narzędzia lub incydentu.
Strona narzędzia: od statusu do działania
Każda strona narzędzia powinna odpowiadać na pytanie „Czy to narzędzie jest wystarczająco niezawodne?” i „Dlaczego tak/nie?”. Załaduj:
- Aktualny status SLO z prostym pass/fail i pozostałym budżetem błędów
- Wykresy uptime, latencji lub wskaźnika błędów dla wybieralnych zakresów czasowych
- Ostatnie zmiany (deployy, edycje konfiguracji, aktualizacje checków), aby wzorce były oczywiste
- Runbooki i właściciele: wyraźna sekcja „Co robić” z linkami i kontaktami
Projektuj wykresy dla nie‑ekspertów: opisuj jednostki, oznacz progi SLO i dodaj małe wyjaśnienia (tooltips) zamiast gęstych, technicznych kontrolerów.
Strona incydentu: wspólny kontekst i oś czasu
Strona incydentu to żywy dokument. Zawrzyj oś czasu (automatycznie zapisywane zdarzenia jak alert uruchomiony, potwierdzony, złagodzony), aktualizacje od ludzi, dotknięci użytkownicy i podjęte działania.
Ułatw publikowanie aktualizacji: jedno pole tekstowe, predefined status (Investigating/Identified/Monitoring/Resolved) i opcjonalne notatki wewnętrzne. Po zamknięciu incydentu akcja „Start postmortem” powinna prefiltrować fakty z osi czasu.
Strony administracyjne: właścicielstwo i spójność
Administratorzy potrzebują prostych ekranów do zarządzania narzędziami, checkami, celami SLO i właścicielami. Optymalizuj pod kątem poprawności: sensowne domyślne ustawienia, walidacja i ostrzeżenia przy zmianach wpływających na raportowanie. Dodaj widoczne „ostatnio edytowane”, by ludzie ufali liczbom.
Wdróż uwierzytelnianie, uprawnienia i ślady audytu
Dane niezawodności pozostają użyteczne tylko wtedy, gdy ludzie im ufają. To znaczy: powiązać każdą zmianę z tożsamością, ograniczyć, kto może wykonać duże zmiany, i zachować jasną historię, do której można wrócić podczas przeglądów.
Uwierzytelnianie: użyj tego, co już stosuje firma
Dla narzędzia wewnętrznego domyślnie korzystaj z SSO (SAML) lub OAuth/OIDC przez Twojego dostawcę tożsamości (Okta, Azure AD, Google Workspace). To redukuje zarządzanie hasłami i automatyzuje onboard/offboard.
Praktyczne wskazówki:
- Wymuszaj MFA przez IdP (nie implementuj go ponownie)
- Mapuj grupy IdP na role aplikacyjne przy logowaniu
- Ustaw krótkie sesje i wspieraj ręczne wylogowanie
Uprawnienia: RBAC z „chronionymi akcjami”
Zacznij od prostych ról i dodawaj drobnoziarniste reguły tylko wtedy, gdy zajdzie potrzeba:
- Viewer: tylko odczyt dashboardów i scorecardów dla interesariuszy
- Editor: tworzenie/aktualizacja checków, incydentów i notatek
- Admin: zarządzanie definicjami SLO, progami, integracjami i mapowaniem użytkowników/rol
Chroń akcje, które mogą zmienić wyniki niezawodności lub narrację raportowania:
- Tylko Admini mogą zmieniać cele SLO, progi alertów i mapowania źródeł danych
- Ogranicz, kto może zamykać incydenty lub oznaczać je jako „resolved”, i wymagaj podsumowania rozwiązania
Ślady audytu: niemutowalna historia zmian
Loguj każdą edycję SLO, checków i pól incydentów z:
- kto to zrobił (użytkownik + rola)
- kiedy to się stało (timestamp)
- co się zmieniło (wartości przed/po)
- skąd to pochodziło (UI, API, automatyzacja)
Uczyń logi audytu przeszukiwalnymi i widocznymi na odpowiednich stronach (np. strona incydentu pokazuje pełną historię zmian). To utrzymuje przeglądy w faktach i ogranicza wymianę zdań w postmortemach.
Zbuduj checki monitorujące i zbieranie uptime
Monitoring to „warstwa sensorów” Twojej aplikacji niezawodności: zamienia rzeczywiste zachowanie w dane, którym można ufać. Dla narzędzi wewnętrznych syntetyczne checki często są najszybszą drogą, bo sam decydujesz, co znaczy „zdrowe”.
Zdefiniuj syntetyczne checki dla każdego narzędzia
Zacznij od małego zestawu typów checków, które pokryją większość aplikacji wewnętrznych:
- HTTP ping: potwierdź, że usługa odpowiada (kod statusu, TLS, podstawowe nagłówki).
- Walidacja endpointu: uderz w znany URL i sprawdź coś znaczącego (oczekiwana shape JSON, kluczowy tekst w HTML lub payload endpointu health).
- Ścieżka „smoke” bez logowania: jeśli to możliwe, przetestuj jeden read-only flow odzwierciedlający UX (np. załaduj stronę dashboardu i weryfikuj, że renderuje).
Utrzymuj checki deterministyczne. Jeśli walidacja może zawieść z powodu zmiennej treści, stworzysz szum i zmniejszysz zaufanie.
Zbieraj uptime i latencję (i przechowuj rozsądnie)
Dla każdego uruchomienia checka zapisuj:
- Timestamp (start i koniec)
- Wynik: up/down/unknown
- Latency: całkowity czas trwania (i opcjonalnie DNS/connect/TTFB, jeśli to mierzysz)
- Powód: kod błędu, timeout, niepowodzenie walidacji lub komunikat wyjątku
Przechowuj dane jako zdarzenia szeregów czasowych (po jednym wierszu na uruchomienie checka) lub jako zagregowane interwały (np. rollupy minutowe z licznikami i p95 latencji). Surowe zdarzenia są świetne do debugowania; rollupy — do szybkich dashboardów. Wiele zespołów przechowuje i jedno, i drugie: surowe wydarzenia 7–30 dni i rollupy na dłużej.
Traktuj przerwy w danych inaczej niż outage
Brak wyniku checka nie powinien automatycznie oznaczać „down”. Dodaj wyraźny stan unknown dla przypadków jak:
- worker checkujący został zatrzymany
- partycja sieci między checkerem a celem
- konfiguracja została usunięta w trakcie uruchomienia
To zapobiega zawyżaniu czasu przestojów i sprawia, że „luki w monitoringu” są widoczne same w sobie.
Uruchamiaj checki w harmonogramie z użyciem background jobs
Używaj workerów (harmonogram podobny do cron, kolejki), aby uruchamiać checki w stałych interwałach (np. co 30–60 sekund dla krytycznych narzędzi). Dodaj timeouty, retry z backoffem i limity współbieżności, by Twój checker nie przeciążył wewnętrznych usług. Zapisuj wynik każdego uruchomienia — nawet błędy — aby dashboard uptime pokazywał zarówno aktualny status, jak i wiarygodną historię.
Stwórz przepływy alertów i powiadomień
Zaplanuj zakres zanim zbudujesz
Wykorzystaj Tryb Planowania, aby zaprojektować narzędzia, role i granice, dzięki czemu pierwsza wersja pozostanie skupiona.
Alerty to moment, w którym śledzenie niezawodności zamienia się w działanie. Cel jest prosty: powiadomić odpowiednie osoby, z odpowiednim kontekstem, we właściwym czasie — bez zalewania wszystkich powiadomieniami.
Powiąż alerty z SLO (nie tylko progami)
Zacznij od definiowania reguł alertów, które mapują się bezpośrednio na Twoje SLI/SLO. Dwa praktyczne wzorce:
- Burn-rate alerts: page, gdy budżet błędów jest spalany na tyle szybko, że przegapisz SLO, jeśli nic się nie zmieni.
- Przełamania progów: ostrzegaj, gdy metryka przekroczy jasną granicę (np. dostępność spada poniżej 99.5% przez 15 minut).
Dla każdej reguły przechowuj obok „co” też „dlaczego”: które SLO jest dotknięte, okno ewaluacji i zamierzony severity.
Uczyń powiadomienia wykonalnymi
Wysyłaj powiadomienia do kanałów, w których zespoły już żyją (email, Slack, Microsoft Teams). Każda wiadomość powinna zawierać:
- Jednolinijkowe podsumowanie (serwis + symptom + severity)
- Bezpośredni link do odpowiedniego widoku dashboardu (np. /services/payments?window=1h)
- Link do strony incydentu, jeśli został utworzony (np. /incidents/123)
Unikaj zrzucania surowych metryk. Podaj krótki „kolejny krok” typu „Sprawdź ostatnie deployy” lub „Otwórz logi”.
Zmniejsz szum dzięki dedupe, grupowaniu i godzinom ciszy
Wdroż:
- Deduplikację (ten sam fingerprint alertu → aktualizuj istniejący wątek)
- Grupowanie (jeden incydent może zebrać wiele powiązanych alertów)
- Godziny ciszy i reguły routingu, żeby niskoseverity nie budziły on-call
Wspieraj eskalację i rotację on-call
Nawet w narzędziu wewnętrznym ludzie potrzebują kontroli. Dodaj ręczną eskalację (przycisk na stronie alertu/incydentu) i integruj z narzędziami on-call, jeśli są dostępne (PagerDuty/Opsgenie), albo przynajmniej konfigurowalną listę rotacyjną przechowywaną w aplikacji.
Dodaj zarządzanie incydentami i funkcje postmortem
Zarządzanie incydentami zamienia „mieliśmy alert” w skoordynowaną, śledzoną odpowiedź. Zbuduj to w trackerze, aby ludzie mogli przejść od sygnału do koordynacji bez przeskakiwania między narzędziami.
Jednoklikowe tworzenie incydentu
Umożliw tworzenie incydentu bezpośrednio z alertu, strony serwisu lub wykresu uptime. Wstępnie uzupełniaj kluczowe pola (service, environment, źródło alertu, pierwszy zaobserwowany czas) i przypisuj unikalne ID incydentu.
Lekki zestaw pól domyślnych wystarczy: severity, wpływ na użytkowników (zespół/zespoły wewnętrzne), obecny owner i linki do wyzwalającego alertu.
Cykl życia statusu i współpraca
Używaj prostego cyklu życia odpowiadającego praktyce zespołów:
- Open → Investigating → Mitigated → Resolved
Każda zmiana statusu powinna rejestrować, kto i kiedy ją wykonał. Dodaj krótkie aktualizacje na osi czasu (timestampowane), wsparcie załączników i linków do runbooków i ticketów (np. /runbooks/payments-retries czy /tickets/INC-1234). To staje się pojedynczym wątkiem „co się stało i co zrobiliśmy”.
Postmortemy z punktami akcji
Postmortemy powinny być szybkie do rozpoczęcia i spójne do przeglądu. Dostarcz szablony z:
- Podsumowaniem, wpływem, detekcją i root cause
- Czynnikami przyczyniającymi się (w tym luki procesowe)
- Co zadziałało / co nie zadziałało
- Follow-upami z właścicielami i terminami
Powiąż punkty akcji z incydentem, śledź ich zakończenie i eksponuj zaległe elementy na dashboardach zespołów. Jeśli wspierasz „learning reviews”, udostępnij tryb „bez obwiniania”, koncentrujący się na zmianach systemowych i procesowych zamiast na błędach pojedynczych osób.
Raportowanie i scorecardy niezawodności
Dodaj mobilne widoki statusu
Stwórz web app teraz i rozwiń do ekranów mobilnych Flutter, gdy zespoły będą potrzebować statusów w terenie.
Raportowanie to moment, w którym śledzenie niezawodności staje się podejmowaniem decyzji. Dashboardy pomagają operatorom; scorecardy pomagają liderom zrozumieć, czy narzędzia wewnętrzne się poprawiają, gdzie inwestować i jak wygląda „dobrze”.
Co umieścić w scorecardzie
Zbuduj spójny, powtarzalny widok per narzędzie (i opcjonalnie per zespół), który szybko odpowiada na kilka pytań:
- Zgodność z SLO w czasie: pokaż bieżący okres (tydzień/miesiąc/kwartał) i linię trendu względem celu SLO.
- Najbardziej zawodna grupa narzędzi: ranking wg przekroczeń SLO, najdłuższych minut downtime lub najszybszego spalania budżetu błędów.
- MTTR: medianę i p90 czasu przywrócenia, żeby pojedynczy długi incydent nie ukrył wzorca.
- Liczba incydentów: suma incydentów z rozbiciem severity (np. Sev1–Sev3) i porównanie z poprzednim okresem.
Gdzie to możliwe, dodaj lekki kontekst: „SLO missed z powodu 2 deployów” lub „Większa część downtime przez zależność X”, bez zamieniania raportu w pełne postmortem.
Filtry, które czynią raporty użytecznymi dla liderów
Liderzy rzadko chcą „wszystko”. Dodaj filtry na zespół, krytyczność narzędzia (np. Tier 0–3) i okres czasu. Upewnij się, że to samo narzędzie może pojawiać się w wielu rollupach (platform team jest właścicielem, a finance na nim polega).
Podsumowania i eksporty
Udostępnij cotygodniowe i comiesięczne podsumowania do dzielenia się poza aplikacją:
- Jednoklikowy eksport CSV do arkuszy
- Czysty eksport PDF do przeglądów statusu
Utrzymuj narrację spójną („Co się zmieniło od ostatniego okresu?” „Gdzie przekraczamy budżet?”). Jeśli potrzebujesz przewodnika dla interesariuszy, odwołaj się do krótkiego przewodnika typu /blog/sli-slo-basics.
Bezpieczeństwo, jakość danych i twardnienie operacyjne
Tracker niezawodności szybko staje się źródłem prawdy. Traktuj go jak system produkcyjny: domyślnie bezpieczny, odporny na złe dane i łatwy do odzyskania, gdy coś pójdzie nie tak.
Chroń powierzchnię aplikacji
Zablokuj każdy endpoint — nawet „tylko wewnętrzne”.
- Waliduj wejścia na granicy (typy, zakresy, dozwolone enumy, max rozmiary payloadu) i odrzucaj nieznane pola.
- Dodaj rate limiting per użytkownik/token usługi, by zapobiec przeciążeniu ingestii lub dashboardów przez hałaśliwych klientów.
- Używaj parametrized queries i bezpiecznych wzorców ORM, by unikać injection.
Sekrety i kontrola dostępu
Trzymaj poświadczenia poza kodem i poza logami.
Przechowuj sekrety w managerze sekretów i rotuj je. Daj aplikacji najmniejsze możliwe uprawnienia do bazy: oddziel role read/write, ogranicz dostęp tylko do potrzebnych tabel i używaj krótkotrwałych poświadczeń tam, gdzie to możliwe. Szyfruj dane w tranzycie (TLS) między przeglądarką↔aplikacją i aplikacją↔bazą.
Strażniki jakości danych
Metryki są przydatne tylko wtedy, gdy zdarzenia są wiarygodne.
Dodaj serwerowe walidacje timestampów (strefa czasowa/rozjazd zegara), wymaganych pól i kluczy idempotencyjnych do deduplikacji retryów. Śledź błędy ingestii w dead-letter queue lub tabeli „kwarantanny”, żeby złe zdarzenia nie zatruwały dashboardów.
Podstawy operacyjne (nie pomijaj)
Automatyzuj migracje bazy i testuj rollbacki. Harmonogramuj backupy, regularnie przywracaj testowo i udokumentuj minimalny plan DR (kto, co, ile czasu). Na koniec: spraw, by sam tracker był niezawodny — dodaj health checki, podstawowy monitoring lagów kolejek i latencji DB oraz alertuj, gdy ingestia spada do zera.
Plan wdrożenia i roadmapa iteracji
Tracker odnosi sukces, gdy ludzie mu ufają i faktycznie go używają. Traktuj pierwsze wdrożenie jako pętlę uczenia się, a nie „big bang”.
Zacznij od skoncentrowanego pilota
Wybierz 2–3 narzędzia wewnętrzne szeroko używane i z jasnymi właścicielami. Implementuj mały zestaw checków (np. dostępność strony głównej, sukces logowania i kluczowy endpoint API) i opublikuj jeden dashboard odpowiadający: „Czy jest dostępne? Jeśli nie, co się zmieniło i kto za to odpowiada?”
Utrzymaj pilota widocznym, ale ograniczonym: jeden zespół lub mała grupa power userów wystarczy, by zweryfikować flow.
Zbieraj krytyczny feedback
W pierwszych 1–2 tygodniach aktywnie zbieraj feedback na temat:
- Co jest mylące (nazwy metryk, wykresy, filtry, definicje)
- Co jest hałaśliwe (alerty, które nie odpowiadają wpływowi użytkownika)
- Czego brakuje (właściciele, runbooki, linki do incydentów)
Przekształcaj feedback w konkretne backlog items. Prosty przycisk „Zgłoś problem z tą metryką” na każdym wykresie często ujawnia najszybsze wnioski.
Iteruj z integracjami i automatyzacją
Dodawaj wartość warstwami: połącz z narzędziem chat do powiadomień, potem z narzędziem incydentowym do automatycznego tworzenia ticketów, następnie z CI/CD do znaczników deployów. Każda integracja powinna redukować ręczną pracę lub skracać time-to-diagnosis — inaczej to tylko dodatkowa złożoność.
Jeśli prototypujesz szybko, rozważ użycie trybu planowania Koder.ai, by zmapować początkowy zakres (encje, role, workflowy) zanim wygenerujesz pierwsze buildy. To prosty sposób na utrzymanie MVP zwartego — i ponieważ możesz robić snapshoty i rollbacky, bezpiecznie iterujesz dashboardy i ingestię w miarę doprecyzowywania definicji przez zespoły.
Zdefiniuj metryki sukcesu i rozszerzaj
Zanim rozszerzysz tracker na więcej zespołów, zdefiniuj metryki sukcesu takie jak tygodniowi aktywni użytkownicy dashboardu, skrócony time-to-detect, mniej zduplikowanych alertów czy regularne przeglądy SLO. Opublikuj lekką roadmapę w /blog/reliability-tracking-roadmap i rozszerzaj narzędzie narzędzie po narzędziu z jasnymi właścicielami i sesjami szkoleniowymi.