Wyjaśnij cel i zakres aplikacji
Zanim zaprojektujesz ekrany lub wybierzesz stos technologiczny, ustal jasno, co „ryzyko operacyjne” oznacza w Twojej organizacji. Dla niektórych zespołów obejmuje to błędy procesowe i pomyłki ludzkie; inni włączają awarie IT, problemy z dostawcami, oszustwa lub zdarzenia zewnętrzne. Jeśli definicja będzie niejasna, aplikacja zamieni się w składowisko — a raportowanie stanie się niewiarygodne.
Określ, co będziesz śledzić
Zapisz jednoznaczne stwierdzenie, co kwalifikuje się jako ryzyko operacyjne, a co nie. Możesz podzielić to na cztery koszyki (procesy, ludzie, systemy, zdarzenia zewnętrzne) i dodać 3–5 przykładów dla każdego. Ten krok ograniczy późniejsze spory i utrzyma spójność danych.
Ustal oczekiwane rezultaty
Bądź konkretny, co aplikacja ma osiągnąć. Typowe cele to:
- Widoczność: jedno miejsce do przeglądu ryzyk, kontroli, incydentów i działań
- Odpowiedzialność: każdy element ma wskazanego właściciela i termin
- Śledzenie naprawcze: działania przechodzą od „otwarte” do „zweryfikowane” z dowodem
- Raportowanie i przygotowanie do audytu: możesz wyjaśnić, co zmieniono, kiedy i dlaczego
Jeśli nie potrafisz opisać rezultatu, prawdopodobnie to żądanie funkcji, a nie wymaganie.
Określ głównych użytkowników
Wypisz role, które będą korzystać z aplikacji i czego najbardziej potrzebują:
- Właściciele ryzyk (identyfikują i aktualizują ryzyka)
- Właściciele kontroli (potwierdzają kontrole, załączają dowody)
- Recenzenci (zatwierdzają zmiany, żądają aktualizacji)
- Audytorzy (dostęp tylko do odczytu, śledzalność)
- Administratorzy (dostęp użytkowników, konfiguracja)
To zapobiega budowaniu „dla wszystkich” i zadowalaniu nikogo.
Ustal realistyczny zakres v1
Praktyczne v1 dla śledzenia ryzyka operacyjnego zwykle koncentruje się na: rejestrze ryzyk, podstawowym ocenianiu ryzyka, śledzeniu działań i prostym raportowaniu. Głębsze możliwości (zaawansowane integracje, zarządzanie złożoną taksonomią, kreatory niestandardowych przepływów) odłóż do kolejnych etapów.
Zdefiniuj metryki sukcesu
Wybierz mierzalne wskaźniki, takie jak: odsetek ryzyk z przypisanymi właścicielami, kompletność rejestru ryzyk, czas zamknięcia działań, wskaźnik zaległych działań i terminowość przeglądów. Te metryki ułatwią ocenę, czy aplikacja działa i co poprawić dalej.
Zbieranie wymagań od interesariuszy
Aplikacja rejestru ryzyk działa tylko wtedy, gdy odzwierciedla sposób, w jaki ludzie identyfikują, oceniają i realizują działania związane z ryzykiem. Zanim zaczniesz rozmawiać o funkcjach, porozmawiaj z osobami, które będą korzystać (lub które będą oceniane na podstawie wyników).
Kogo zaangażować (i dlaczego)
Zacznij od małej, reprezentatywnej grupy:
- Business unit owners, którzy codziennie zgłaszają i zarządzają ryzykami
- Zespół ds. ryzyka/zgodności, który definiuje terminologię, oczekiwania dotyczące oceniania i potrzeby raportowe
- Audyt wewnętrzny, który dba o dowody, zatwierdzenia i kompletność śladu audytu
- IT/Security, które przejrzy kontrolę dostępu, retencję danych i integracje
- Przedstawiciele wykonawczy/komitetu, którzy konsumują podsumowania i trendy
Zmapuj obecny proces krok po kroku
Na warsztatach przejdź rzeczywisty przepływ: identyfikacja ryzyka → ocena → leczenie → monitorowanie → przegląd. Zapisz, gdzie zapadają decyzje (kto zatwierdza co), jak wygląda stan „ukończone” i co wyzwala przegląd (czasowo, po incydencie lub po przekroczeniu progu).
Zanotuj problemy do naprawienia
Poproś interesariuszy o pokazanie bieżącego arkusza lub ścieżki emailowej. Udokumentuj konkretne problemy, takie jak:
- Brak przypisania właściciela (niejasność właściciela ryzyka vs. właściciela kontroli vs. właściciela działania)
- Niespójne ocenianie (zespoły rozumieją prawdopodobieństwo/ wpływ inaczej)
- Słabe ślady audytu (brak zapisu kto zmienił co i dlaczego)
- Zamieszanie wersji (wiele kopii „najnowszego” rejestru)
Udokumentuj wymagane przepływy i zdarzenia
Zapisz minimalne przepływy, które aplikacja musi wspierać:
- Utworzenie nowego ryzyka (z wymaganymi polami i regułami zatwierdzania)
- Aktualizacja ryzyka (ponowna ocena, zmiana statusu, dodanie notatek)
- Zalogowanie incydentu i powiązanie go z ryzykami/kontrolami
- Zarejestrowanie wyników testów kontroli i dowodów
- Tworzenie i śledzenie planów działań (terminy, przypomnienia, eskalacje)
Określ raporty, na których polegają ludzie
Uzgodnij outputy wcześnie, aby uniknąć przeróbek. Typowe potrzeby to podsumowania dla zarządu, widoki dla jednostek biznesowych, zaległe działania oraz najważniejsze ryzyka według wyniku lub trendu.
Zanotuj ograniczenia zgodności (bez obietnic certyfikacji)
Wypisz reguły, które kształtują wymagania — np. okresy retencji danych, ograniczenia prywatności dla danych incydentów, separacja obowiązków, dowody zatwierdzeń i ograniczenia dostępu według regionu lub podmiotu. Traktuj to jako zbieranie ograniczeń, nie deklarowanie zgodności domyślnie.
Zaprojektuj ramy ryzyka i terminologię
Zanim zbudujesz ekrany lub przepływy, ustal słownictwo, które aplikacja będzie egzekwować. Jasna terminologia zapobiega problemowi „to samo ryzyko, różne słowa” i sprawia, że raportowanie jest wiarygodne.
Zacznij od praktycznej taksonomii ryzyka
Określ, jak ryzyka będą grupowane i filtrowane w rejestrze. Utrzymaj to użyteczne zarówno dla codziennego przypisania, jak i dla dashboardów i raportów.
Typowe poziomy taksonomii to kategoria → podkategoria, mapowane do jednostek biznesowych i (gdzie pomocne) procesów, produktów lub lokalizacji. Unikaj tak szczegółowej taksonomii, że użytkownicy nie będą mogli wybierać konsekwentnie; możesz ją usprawniać, gdy pojawią się wzorce.
Ustandaryzuj opis ryzyka i pola obowiązkowe
Uzgodnij spójny format opisu ryzyka (np. „Z powodu przyczyny, może wystąpić zdarzenie, prowadząc do skutku”). Następnie zdecyduj, co jest obowiązkowe:
- Przyczyna, zdarzenie, skutek (dla sensownej analizy)
- Właściciel ryzyka i zespół odpowiedzialny (dla działań)
- Status (szkic, aktywne, w przeglądzie, wycofane)
- Daty (zidentyfikowane, ostatnio ocenione, następny przegląd)
Ta struktura łączy kontrole i incydenty z jedną narracją zamiast rozproszonych notatek.
Zdefiniuj wymiary oceny i skalę
Wybierz wymiary oceny, które będą używane w modelu punktacji. Minimum to prawdopodobieństwo i wpływ; prędkość wystąpienia i wykrywalność mogą dodać wartość, jeśli ludzie będą je oceniać spójnie.
Zdecyduj, jak poradzisz sobie z ryzykiem wrodzonym vs. ryzykiem resztkowym. Powszechne podejście: ryzyko wrodzone jest oceniane przed kontrolami; ryzyko resztkowe to ocena po kontrolach, z wyraźnym powiązaniem kontroli, aby logika była wyjaśnialna podczas przeglądów i audytów.
Na koniec uzgodnij prostą skalę ocen (zwykle 1–5) i opisz słownie każdy poziom. Jeśli „3 = średnie” znaczy coś innego w różnych zespołach, workflow oceny wygeneruje szum zamiast wniosków.
Stwórz model danych (rejestr ryzyk, kontrole, działania)
Jasny model danych przekształca arkusz w system, któremu można zaufać. Dąż do niewielkiego zestawu podstawowych rekordów, czystych relacji i spójnych list referencyjnych, aby raportowanie pozostało wiarygodne w miarę wzrostu użycia.
Podstawowe byty (minimalne schema)
Zacznij od kilku tabel odwzorowujących sposób pracy ludzi:
- Users i Roles: kto jest w systemie i co może robić
- Risks: wpis w rejestrze ryzyk (tytuł, opis, właściciel, obszar biznesowy, oceny wrodzone/resztkowe, status)
- Assessments: oceny punktowe (data, oceniający, dane wejściowe do oceny, notatki). Trzymanie ocen osobno zapobiega nadpisywaniu „bieżącego widoku”.
- Controls: zabezpieczenia powiązane z ryzykami (projekt/skuteczność działania, częstotliwość testów, właściciel kontroli)
- Incidents/Events: co się wydarzyło (data, wpływ, przyczyna źródłowa, powiązane ryzyko(i), powiązane awarie kontroli)
- Actions: zadania naprawcze powiązane z ryzykiem, kontrolą lub incydentem
- Comments: dyskusje i decyzje, najlepiej z @wzmiankami i znacznikami czasu
Relacje istotne dla śledzalności
Modeluj istotne relacje wiele-do-wielu jawnie:
- Risk ↔ Controls (przez tabelę łączącą), aby pokazać, które kontrole łagodzą które ryzyka
- Risk ↔ Incidents, by powiązać realne straty/bliskie zdarzenia z rejestrem
- Actions → Risk/Control/Incident (link polimorficzny lub trzy NULLowalne klucze obce), aby remediation była zawsze osadzona
Taka struktura pozwala odpowiadać na pytania typu „Które kontrole zmniejszają nasze największe ryzyka?” i „Które incydenty spowodowały zmianę oceny ryzyka?”.
Tabele historii i „dlaczego to się zmieniło?”
Śledzenie zmian jest często wymagane. Dodaj tabele historii/audytu dla Risks, Controls, Assessments, Incidents i Actions z:
- kto zmienił, kiedy i jakie pola się zmieniły
- opcjonalne powód zmiany (tekst wolny lub kody do wyboru)
Unikaj przechowywania tylko „ostatnio zaktualizowano”, jeśli oczekujesz zatwierdzeń i audytów.
Tabele referencyjne dla spójności
Używaj tabel referencyjnych (nie literówek w ciągach tekstowych) dla taksonomii, statusów, skal prawdopodobieństwa/ciężkości, typów kontroli i stanów działań. To zapobiega rozbiciu raportów przez literówki („High” vs. „HIGH”).
Załączniki (dowody) z myślą o retencji
Traktuj dowody jako dane pierwszorzędne: tabela Attachments z metadanymi plików (nazwa, typ, rozmiar, uploader, powiązany rekord, data uploadu) oraz polami dla daty retencji/usunięcia i klasyfikacji dostępu. Pliki przechowuj w object storage, a zasady zarządzania w bazie danych.
Zaplanuj przepływy, zatwierdzenia i odpowiedzialność
Aplikacja upada szybko, gdy „kto co robi” jest niejasne. Zanim zbudujesz ekrany, zdefiniuj stany workflow, kto może przesuwać elementy między stanami i co musi być zarejestrowane na każdym etapie.
Role i uprawnienia (utrzymaj proste)
Zacznij od niewielkiej liczby ról i rozwijaj je tylko gdy to konieczne:
- Creator: może tworzyć szkice nowych ryzyk, kontroli, incydentów i działań
- Risk owner: odpowiada za poprawność i przeglądy
- Approver: zatwierdza wpisy i może oznaczyć je jako „oficjalne”
- Auditor / read-only: może przeglądać, eksportować i (opcjonalnie) komentować, ale nie edytować
- Admin: zarządza konfiguracją, użytkownikami i uprawnieniami
Uczyń uprawnienia jawne dla każdego typu obiektu (ryzyko, kontrola, działanie) i dla każdej zdolności (tworzenie, edycja, zatwierdzanie, zamykanie, ponowne otwieranie).
Przepływ zatwierdzania: szkic → przegląd → zatwierdzone → przegląd ponowny
Użyj jasnego cyklu życia z przewidywalnymi bramkami:
- Szkic: edytowalne; dozwolone brakujące pola
- W przeglądzie: zmiany ograniczone; wymagane komentarze recenzenta
- Zatwierdzone: zablokuj pola kluczowe; zmiany wymagają formalnego żądania aktualizacji
- Okresowy przegląd: zaplanowane punkty kontrolne (np. kwartalne) w celu potwierdzenia, że nic się nie zmieniło
SLA, przypomnienia i logika przeterminowania
Przypisz SLA do cykli przeglądu, testów kontroli i terminów działań. Wysyłaj przypomnienia przed terminem, eskaluj po przekroczeniu SLA i wyróżniaj przeterminowane elementy w widoku właściciela i menedżera.
Delegacja, przekazywanie i odpowiedzialność
Każdy element powinien mieć jednego właściciela odpowiedzialnego oraz opcjonalnych współpracowników. Wspieraj delegowanie i przypisywanie na nowo, ale wymagaj powodu (i opcjonalnie daty skuteczności), aby czytelnicy rozumieli, kiedy i dlaczego zmieniła się odpowiedzialność.
Zaprojektuj doświadczenie użytkownika i kluczowe ekrany
Obniż koszty budowy
Obniż koszty budowy, zdobywając dodatkowy czas przez tworzenie treści o Koder.ai lub zapraszanie współpracowników przez referral.
Aplikacja ryzyk odniesie sukces, gdy ludzie będą jej rzeczywiście używać. Dla nietechnicznych użytkowników najlepsze UX jest przewidywalne, niskiego tarcia i spójne: jasne etykiety, minimalne żargon i wystarczające wskazówki, by unikać niejasnych wpisów typu „różne”.
1) Intake ryzyka: ułatwiaj wprowadzanie dobrych danych
Formularz powinien przypominać prowadzone rozmowy. Dodaj krótkie podpowiedzi pod polami (nie długie instrukcje) i oznacz naprawdę wymagane pola.
Umieść podstawy: tytuł, kategoria, proces/obszar, właściciel, status, początkowa ocena i „dlaczego to ważne” (narracja wpływu). Jeśli używasz oceniania, osadź dymki z podpowiedziami przy każdym czynniku, aby użytkownicy rozumieli definicje bez opuszczania strony.
2) Widok listy ryzyk: triage i follow-up w jednym miejscu
Większość użytkowników będzie pracować w widoku listy, więc ułatw odpowiedź na pytanie: „Co wymaga uwagi?”
Daj filtry i sortowanie po statusie, właścicielu, kategorii, wyniku, dacie ostatniego przeglądu i zaległych działaniach. Wyróżniaj wyjątki (przeglądy zaległe, przeterminowane działania) subtelnymi odznakami — niewszystko krzyczy alarmem — żeby uwaga skupiła się na właściwych elementach.
3) Strona szczegółów ryzyka: jedna historia, powiązane rekordy
Ekran szczegółów powinien najpierw przedstawiać podsumowanie, potem szczegóły wspierające. Utrzymaj górną część skupioną: opis, bieżący wynik, ostatni przegląd, data następnego przeglądu i właściciel.
Poniżej pokaż powiązane kontrole, incydenty i działania jako oddzielne sekcje. Dodaj komentarze dla kontekstu („dlaczego zmieniliśmy ocenę”) i załączniki jako dowody.
4) Śledzenie działań: zamień decyzje w zakończenia
Działania muszą mieć przypisanie, terminy, postęp, upload dowodów i jasne kryteria zamknięcia. Uczyń zamknięcie eksplicytnym: kto zatwierdza zamknięcie i jaki dowód jest wymagany.
Jeśli potrzebujesz układu referencyjnego, utrzymaj prostą i spójną nawigację między ekranami (np. /risks, /risks/new, /risks/{id}, /actions).
Zaimplementuj ocenianie ryzyka i logikę przeglądu
Ocena ryzyka to moment, w którym aplikacja staje się użyteczna. Celem nie jest „ocenianie” zespołów, lecz standaryzacja porównywania ryzyk, ustalanie priorytetów i zapobieganie przestarzałym wpisom.
Wybierz (i udokumentuj) model oceniania
Zacznij od prostego, wyjaśnialnego modelu, który działa w większości zespołów. Powszechny domyślny model to skala 1–5 dla Prawdopodobieństwa i Wpływu, z obliczeniem:
- Wynik = Prawdopodobieństwo × Wpływ
Zapisz jasne definicje dla każdej wartości (co oznacza „3”, nie tylko liczba). Umieść tę dokumentację obok pól w UI (dymki lub „Jak działa ocenianie”), aby użytkownicy nie musieli jej szukać.
Uczyń progi znaczącymi i powiąż je z działaniami
Same liczby nie wywołują działań — robią to progi. Określ granice dla Niskie / Średnie / Wysokie (i ewentualnie Krytyczne) i zdecyduj, co każdy poziom wyzwala.
Przykłady:
- Wysokie: wymaga właściciela, daty docelowej i zatwierdzenia zarządu przed zamknięciem
- Średnie: wymaga planu łagodzenia, ale niekoniecznie zatwierdzenia
- Niskie: monitorować i przeglądać; brak natychmiastowych działań
Utrzymuj progi konfigurowalne, bo to, co jest „Wysokie”, różni się między jednostkami biznesowymi.
Śledź ryzyko wrodzone vs. resztkowe
Dyskusje często zacinają się, gdy strony mówią o różnych rzeczach. Rozwiąż to, rozdzielając:
- Ryzyko wrodzone: przed kontrolami
- Ryzyko resztkowe: po uwzględnieniu istniejących kontroli
W UI pokaż oba wyniki obok siebie i zobrazuj, jak kontrole wpływają na ryzyko resztkowe (np. kontrola może zmniejszyć Prawdopodobieństwo o 1 lub Wpływ o 1). Unikaj ukrytej logiki za automatycznymi korektami, których użytkownicy nie potrafią wytłumaczyć.
Buduj konfigurowalne reguły przeglądu
Dodaj reguły przeglądu oparte na czasie, żeby ryzyka nie stały się przestarzałe. Praktyczne domyślne ustawienia:
- Wysokie: przegląd kwartalny
- Średnie: przegląd półroczny
- Niskie: przegląd roczny
Umożliw konfigurację częstotliwości według jednostki biznesowej i nadpisywanie per ryzyko. Zautomatyzuj przypomnienia i status „przegląd zaległy” na podstawie daty ostatniego przeglądu.
Unikaj czarnej skrzynki oceniania
Uczyń obliczenia widocznymi: pokaż Prawdopodobieństwo, Wpływ, ewentualne korekty przez kontrole oraz końcowy wynik resztkowy. Użytkownik powinien móc odpowiedzieć na pytanie „Dlaczego to jest Wysokie?” na pierwszy rzut oka.
Zbuduj ślad audytu, wersjonowanie i obsługę dowodów
Zgromadź interesariuszy w jednym miejscu
Zgromadź właścicieli ryzyk, recenzentów i audytorów w jednym miejscu, aby testować uprawnienia i przepływy.
Narzędzie do ryzyka jest wiarygodne tylko wtedy, gdy ma historię. Jeśli wynik się zmienia, kontrola zostanie oznaczona jako „przetestowana” albo incydent przeklasyfikowany, potrzebujesz zapisu odpowiadającego na pytanie: kto co zrobił, kiedy i dlaczego.
Zdecyduj, co śledzić (i bądź konkretny)
Zacznij od listy zdarzeń, aby nie pominąć ważnych akcji ani nie zalać loga hałasem. Typowe zdarzenia audytowe:
- Tworzenie/aktualizacja/usunięcie kluczowych obiektów (ryzyka, kontrole, incydenty, działania)
- Decyzje zatwierdzające (przesłano, zatwierdzono, odrzucono) i zmiany właściciela
- Eksporty (CSV/PDF), zwłaszcza dla zespołów regulowanych
- Zdarzenia uwierzytelniania (logowania, reset haseł) i zmiany uprawnień
Zbieraj „kto/kiedy/co” plus kontekst
Przynajmniej przechowuj aktora, znacznik czasu, typ/ID obiektu i pola, które się zmieniły (stara wartość → nowa wartość). Dodaj opcjonalne pole „powód zmiany” — zapobiega to późniejszym niejasnościom („zmieniono wynik resztkowy po przeglądzie kwartalnym”).
Utrzymuj log audytu jako append-only. Unikaj możliwości edycji, nawet przez administratorów; jeśli trzeba poprawić, stwórz nowe zdarzenie odnoszące się do poprzedniego.
Udostępnij widok audytu tylko do odczytu
Audytorzy i administratorzy zwykle potrzebują dedykowanego, filtrowalnego widoku: po zakresie dat, obiekcie, użytkowniku i typie zdarzenia. Umożliw łatwy eksport z tego ekranu, ale rejestruj także samo zdarzenie eksportu. Jeśli masz panel admina, podlinkuj go z /admin/audit-log.
Wersjonuj dowody i zapobiegaj cichym nadpisaniom
Pliki dowodowe (zrzuty ekranu, wyniki testów, polityki) powinny mieć wersje. Traktuj każdy upload jako nową wersję z własnym znacznikiem czasu i uploaderem, zachowując wcześniejsze pliki. Jeśli zastąpienie jest dozwolone, wymagaj notatki z powodem i zachowaj obie wersje.
Zdefiniuj retencję i dostęp dla wrażliwych dowodów
Ustal reguły retencji (np. przechowuj zdarzenia audytu przez X lat; usuwaj dowody po Y, chyba że są objęte zatrzymaniem prawnym). Ogranicz dostęp do dowodów surowiej niż do samego rekordu, gdy zawierają dane osobowe lub szczegóły bezpieczeństwa.
Podejdź do bezpieczeństwa, prywatności i kontroli dostępu
Bezpieczeństwo i prywatność nie są „dodatkami” — kształtują komfort zgłaszania incydentów, załączania dowodów i przypisywania odpowiedzialności. Zacznij od mapowania, kto potrzebuje dostępu, co powinien widzieć i co trzeba ograniczyć.
Uwierzytelnianie: SSO vs. email/hasło
Jeśli organizacja używa dostawcy tożsamości (Okta, Azure AD, Google Workspace), priorytetowo traktuj Single Sign-On przez SAML lub OIDC. Zmniejsza to ryzyko haseł, upraszcza onboarding/offboarding i pasuje do korporacyjnych zasad.
Jeżeli budujesz dla mniejszych zespołów lub zewnętrznych użytkowników, email/hasło też może działać — ale zawsze z silnymi zasadami haseł, bezpiecznym odzyskiwaniem konta i (gdzie możliwe) MFA.
RBAC dopasowany do rzeczywistej pracy
Zdefiniuj role odzwierciedlające rzeczywiste obowiązki: admin, właściciel ryzyka, recenzent/zatwierdzający, współtwórca, tylko do odczytu, audytor.
Ryzyko operacyjne często wymaga ostrzejszych granic niż zwykłe narzędzie wewnętrzne. Rozważ RBAC, które może ograniczać dostęp:
- Według jednostki biznesowej (np. Finanse nie widzi incydentów HR)
- Na poziomie rekordu (np. tylko zespół śledczy widzi wrażliwy incydent)
Utrzymuj uprawnienia zrozumiałe — użytkownicy powinni szybko wiedzieć, dlaczego widzą lub nie widzą rekordu.
Podstawy ochrony danych, które są niepodważalne
Stosuj szyfrowanie w tranzycie (HTTPS/TLS) wszędzie i zasadę least privilege dla usług aplikacji i baz danych. Sesje zabezpieczaj ciasteczkami z flagami secure, krótkimi timeoutami bezczynności i unieważnianiem po stronie serwera przy wylogowaniu.
Wrażliwe pola i redakcja
Nie każde pole ma takie samo ryzyko. Narracje incydentów, notatki o wpływie na klienta czy dane pracownika mogą wymagać ostrzejszych ograniczeń. Wspieraj widoczność na poziomie pola (lub przynajmniej redakcję), aby użytkownicy mogli współpracować bez szerokiego ujawniania treści.
Środki administracyjne
Dodaj praktyczne zabezpieczenia:
- Logi aktywności adminów (kto zmienił uprawnienia, eksporty, konfigurację)
- Opcjonalne białe listy IP dla środowisk wysokiego ryzyka
- MFA dla administratorów (nawet jeśli inni użytkownicy jej nie używają)
Wykonane dobrze, te zabezpieczenia chronią dane i jednocześnie utrzymują płynność raportowania i naprawy.
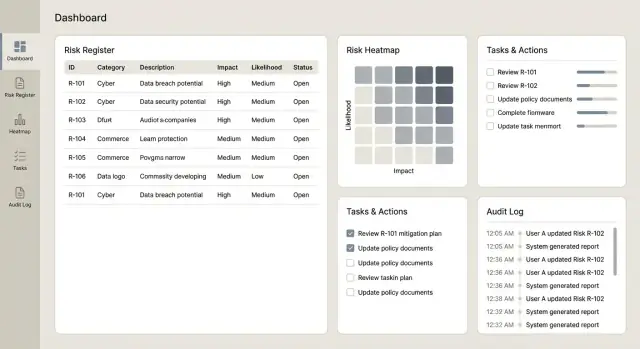
Dostarcz dashboardy, raporty i eksporty
Dashboardy i raporty to moment, w którym aplikacja udowadnia wartość: zmienia długi rejestr w przejrzyste decyzje dla właścicieli, menedżerów i komitetów. Kluczowe jest, aby liczby dało się powiązać z regułami oceniania i rekordami źródłowymi.
Dashboardy, których ludzie rzeczywiście użyją
Zacznij od niewielkiej liczby widoków o wysokim sygnale, które szybko odpowiadają na typowe pytania:
- Najważniejsze ryzyka według wyniku resztkowego (z możliwością przełączenia na wrodzone)
- Trendy w czasie (np. trend resztkowego ryzyka według miesiąca/kwartału)
- Rozkład resztkowe vs. wrodzone, w tym prosty widok „przed vs. po kontrolach”
- Mapa ryzyka (prawdopodobieństwo × wpływ) z możliwością kliknięcia w komórkę i przejścia do listy ryzyk
Uczyń każdy kafelek klikalny, aby użytkownicy mogli przejść do dokładnej listy ryzyk, kontroli, incydentów i działań stojących za wykresem.
Widoki operacyjne do zarządzania codziennego
Dashboardy decyzyjne różnią się od widoków operacyjnych. Dodaj ekrany skoncentrowane na tym, co wymaga uwagi w tym tygodniu:
- Przeterminowane działania (według właściciela/zespołu, z dniami zaległości)
- Nadchodzące przeglądy (ryzyka lub kontrole do przeglądu)
- Niepowodzenia testów kontroli (ostatnie niepowodzenia, ich waga i otwarte działania)
- Częstotliwość incydentów (liczby i wskaźniki w czasie, z filtrami według procesu/kategorii)
Te widoki dobrze współgrają z przypomnieniami i własnością zadań, dzięki czemu aplikacja działa jak narzędzie przepływu pracy, a nie tylko baza danych.
Eksporty dla komitetów i audytów
Zaprojektuj eksporty wcześnie — komitety często polegają na pakietach offline. Wspieraj CSV do analizy i PDF do dystrybucji tylko do odczytu, z:
- Filtrami (jednostka biznesowa, kategoria, właściciel, status)
- Zakresem dat (incydenty w okresie, działania utworzone/zamknięte w okresie)
- Jasnymi etykietami (wrodzone vs. resztkowe, daty wersji i zastosowane filtry)
Jeśli masz już szablon pakietu governance, odwzoruj go, aby ułatwić adopcję.
Spójność i wydajność w skali
Upewnij się, że definicja raportu odpowiada zasadom oceniania. Na przykład, jeśli dashboard ranguje „najważniejsze ryzyka” według wyniku resztkowego, musi to być zgodne z obliczeniem używanym na rekordzie i w eksportach.
Dla dużych rejestrów projektuj pod kątem wydajności: paginacja na listach, cache dla popularnych agregatów i asynchroniczne generowanie raportów (generuj w tle i powiadom użytkownika, gdy będą gotowe). Jeśli dodasz harmonogram raportów, trzymaj odnośniki wewnętrzne (np. zapisz konfigurację raportu, która może być otwarta z /reports).
Zaplanuj integracje i migrację danych
Iteruj bez utraty zaufania
Eksperymentuj z taksonomią i zasadami oceniania, a potem szybko przywróć poprzednią wersję, jeśli trzeba.
Integracje i migracja decydują, czy aplikacja stanie się systemem zapisu — czy kolejnym miejscem, które ludzie zapomną aktualizować. Planuj je wcześnie, ale wdrażaj stopniowo, aby utrzymać stabilność rdzenia produktu.
Zacznij od przepływów, których ludzie już używają
Większość zespołów nie chce „kolejnej listy zadań”. Chcą, by aplikacja łączyła się z miejscami, gdzie praca się odbywa:
- Jira lub ServiceNow do tworzenia i śledzenia działań naprawczych (i synchronizacji statusu)
- Slack lub Microsoft Teams do alertów, gdy ryzyko jest eskalowane, przegląd jest due lub żądane są dowody
- Email do przypomnień o przeglądach i zatwierdzeniach (przydatne dla okazjonalnych użytkowników)
Praktyczne podejście: trzymać rejestr ryzyk jako źródło prawdy, podczas gdy narzędzia zewnętrzne zarządzają szczegółami wykonania (ticketami, przypisaniami, terminami) i raportują postęp z powrotem.
Bezpiecznie zasiej rejestr ryzyk z arkuszy
Wiele organizacji zaczyna od Excela. Zapewnij import, który akceptuje popularne formaty, ale z zabezpieczeniami:
- Reguły walidacji (pola wymagane, formaty dat, zakresy liczbowe)
- Wykrywanie duplikatów (np. ten sam tytuł ryzyka + proces + właściciel) z opcją „połącz/pomiń”
- Egzekwowanie taksonomii (jednostka biznesowa, proces, kategoria), aby zapobiec bałaganowi w raportach
Pokaż podgląd tego, co zostanie utworzone, odrzucone i dlaczego — to jedno okno może zaoszczędzić godziny.
Podstawy API, które zmniejszają ból w przyszłości
Nawet jeśli zaczynasz od jednej integracji, projektuj API tak, jakby miało ich być kilka:
- Zachowuj spójne endpointy i nazewnictwo (np. /risks, /controls, /actions)
- Zapewnij logowanie audytu dla zapisów (kto zmienił co, kiedy i skąd)
- Dodaj rate limiting i czytelne kody błędów, by integracje awaryjnie odpadały przewidywalnie
Obsługuj awarie z retry i widocznym statusem
Integracje zawodzą z normalnych powodów: zmiany uprawnień, timeouty sieci, usunięte tickety. Projektuj na to:
- Kolejkowanie żądań wychodzących i retry z backoffem
- Rejestruj status integracji przy każdym powiązanym elemencie („Synced”, „Pending”, „Failed”)
- Dostarczaj komunikaty operacyjne („token ServiceNow wygasł — ponownie połącz”) i przycisk „Retry teraz”
To podtrzymuje zaufanie i zapobiega cichej różnicy między rejestrem a narzędziami wykonawczymi.
Testuj, uruchom i ulepszaj z czasem
Aplikacja zyska wartość, gdy ludzie jej zaufają i będą jej konsekwentnie używać. Traktuj testowanie i rollout jako część produktu, a nie końcowy checkbox.
Zbuduj praktyczną strategię testów
Zacznij od testów automatycznych dla elementów, które muszą zachowywać się zawsze tak samo — szczególnie ocenianie i uprawnienia:
- Testy jednostkowe dla oceniania: weryfikuj obliczenia prawdopodobieństwo/wpływ, progi, zaokrąglanie i przypadki brzegowe (np. „N/A”, brak pól, nadpisania)
- Testy workflow dla zatwierdzeń: upewnij się, że zmiany stanów podążają za regułami (szkic → przesłano → zatwierdzone), włączając ścieżki reassignment i odrzucenia
- Testy uprawnień: potwierdź, że widzowie nie mogą edytować, właściciele nie mogą zatwierdzać własnych wpisów (jeśli taka polityka) i admini mogą audytować bez łamania separacji obowiązków
Przeprowadź UAT z realnymi scenariuszami
UAT działa najlepiej, gdy odzwierciedla rzeczywistą pracę. Poproś każdą jednostkę biznesową o kilka przykładowych ryzyk, kontroli, incydentów i działań, a następnie przeprowadź typowe scenariusze:
- utwórz ryzyko, powiąż kontrole i prześlij do zatwierdzenia
- zaktualizuj po incydencie i dołącz dowody
- zakończ działanie i zweryfikuj zmiany w raportowaniu
Zbieraj nie tylko błędy, ale też mylące etykiety, brakujące statusy i pola niepasujące do języka zespołów.
Pilotaż przed skalowaniem
Uruchom pilotaż w jednym zespole lub regionie na 2–4 tygodnie. Ogranicz zakres: jeden workflow, mała liczba pól i jasna metryka sukcesu (np. % ryzyk przeglądniętych na czas). Użyj feedbacku, aby dopracować:
- nazwy pól i wymagania
- kroki zatwierdzania i zasady własności
- timing przypomnień i eskalacji
Szkolenia, dokumentacja i adopcja
Dostarcz krótkie przewodniki i jednostronicowy glosariusz: co oznacza każdy wynik, kiedy używać każdego statusu i jak dołączać dowody. 30-minutowe szkolenie na żywo plus nagrania krótkich klipów zwykle przewyższa długi podręcznik.
Przyspiesz rozwój z Koder.ai (opcjonalnie)
Jeśli chcesz szybko osiągnąć wiarygodne v1, platforma vibe-codingowa taka jak Koder.ai może pomóc prototypować i iterować przepływy bez długiego cyklu setupu. Możesz opisać ekrany i zasady (intake ryzyka, zatwierdzenia, ocenianie, przypomnienia, widoki audytu) w czacie, a następnie dopracować wygenerowaną aplikację na podstawie reakcji interesariuszy.
Koder.ai jest zaprojektowany na dostawę end-to-end: wspiera budowę aplikacji webowych (często React), serwisów backendowych (Go + PostgreSQL) i zawiera praktyczne funkcje jak eksport źródeł, deployment/hosting, domeny niestandardowe oraz snapshoty z możliwością rollbacku — przydatne przy zmianach taksonomii, skal oceniania czy przepływów zatwierdzania. Zespoły mogą zacząć na darmowym planie i przejść na pro, business lub enterprise, gdy wymagania governance i skali wzrosną.
Utrzymanie aplikacji po starcie
Zaplanuj operacje po starcie: automatyczne backupy, podstawowy monitoring dostępności/błędów i lekki proces zmian dla taksonomii i skal oceniania, aby aktualizacje pozostały spójne i audytowalne w czasie.