26 lis 2025·8 min
Jak zbudować aplikację webową do śledzenia wąskich gardeł operacyjnych
Krok po kroku: jak zaplanować, zaprojektować i wdrożyć aplikację webową, która zbiera dane workflow, wykrywa wąskie gardła i pomaga zespołom usuwać opóźnienia.
Zacznij od problemu i decyzji
Aplikacja do śledzenia procesów pomaga tylko wtedy, gdy odpowiada na konkretne pytanie: „Gdzie utknęliśmy i co z tym zrobić?” Zanim zaprojektujesz ekrany lub wybierzesz architekturę aplikacji webowej, zdefiniuj, co znaczy „wąskie gardło” w Twojej operacji.
Zdefiniuj, co liczy się jako wąskie gardło
Wąskie gardło może być etapem (np. „przegląd QA”), zespołem (np. „realizacja”), systemem (np. „bramka płatności”) lub nawet dostawcą (np. „odbiór przez przewoźnika”). Wybierz definicje, którymi będziesz rzeczywiście zarządzać. Na przykład:
- Etap jest wąskim gardłem, gdy jego średni czas oczekiwania przekracza 24 godziny.
- Zespół jest wąskim gardłem, gdy praca w toku (WIP) utrzymuje się powyżej ustalonego progu przez 3 dni.
- System jest wąskim gardłem, gdy incydenty powodują skok czasu cyklu poza uzgodniony zakres.
Wypisz decyzje, które aplikacja musi umożliwić
Twój panel operacyjny powinien napędzać działania, nie tylko raportować. Zapisz decyzje, które chcesz podejmować szybciej i z większą pewnością, na przykład:
- Zasoby: „Czy przenosimy w tym tygodniu jedną osobę z Zespołu A do Zespołu B?”
- Priorytetyzacja: „Które zamówienia/tickety powinny przeskoczyć kolejkę, by chronić SLA?”
- Automatyzacja: „Który etap jest na tyle stabilny (i kosztowny), że warto go zautomatyzować jako pierwszy?”
Zidentyfikuj głównych użytkowników i ich potrzeby
Różni użytkownicy potrzebują różnych widoków:
- Menedżerowie operacyjni potrzebują jasnego widoku „gdzie interweniować dziś”.
- Liderzy zespołów potrzebują szczegółów do poziomu kolejek, blokad i przekazań.
- Analitycy potrzebują spójnych definicji i eksportów do analityki procesów.
Ustal metryki sukcesu dla samej aplikacji
Zdecyduj, po czym poznasz, że aplikacja działa. Dobre miary to adopcja (aktywni użytkownicy tygodniowo), czas zaoszczędzony na raportowaniu oraz szybsze rozwiązywanie (skrócony czas wykrycia i naprawy wąskich gardeł). Te metryki utrzymują fokus na wynikach, nie na funkcjach.
Wybierz workflow i napisz prostą mapę procesu
Zanim zaprojektujesz tabele, pulpity czy alerty, wybierz workflow, który potrafisz opisać jednym zdaniem. Celem jest śledzenie miejsc, gdzie praca czeka — więc zacznij od małego zakresu i wybierz jeden lub dwa procesy, które mają znaczenie i generują stały wolumen, np. realizacja zamówień, tickety wsparcia lub onboarding pracowników.
Wąski zakres utrzymuje definicję ukończenia jasną i zapobiega zastoju projektu, gdy różne zespoły nie zgadzają się, jak proces powinien działać.
Zacznij od 1–2 procesów o wysokim sygnale
Wybierz workflowy, które:
- Działają często (wystarczająco danych, by wychwycić wzorce)
- Przechodzą przez co najmniej jedno przekazanie (gdzie tworzą się kolejki)
- Mają wyraźny wpływ na klienta (czas, koszt, satysfakcja)
Na przykład „tickety wsparcia” często sprawdzają się lepiej niż „customer success”, bo mają oczywistą jednostkę pracy i znaczniki czasowe działań.
Zmapuj kroki i przekazania prostym językiem
Zapisz workflow jako prostą listę kroków, używając słów, których już używa zespół. Nie dokumentujesz polityki — identyfikujesz stany, przez które przechodzi element pracy.
Lekka mapa procesu może wyglądać tak:
- Ticket utworzony → ztriage'owany → przypisany → agent pracuje → oczekiwanie na klienta → rozwiązany
Na tym etapie wyraźnie zaznacz przekazania (triage → przypisany, agent → specjalista itp.). To w przekazaniach zwykle kryje się czas w kolejce i to one będą momentami, które chcesz mierzyć później.
Zdefiniuj zdarzenia startu/końca i „zrobione” dla każdego kroku
Dla każdego kroku zapisz dwie rzeczy:
- Zdarzenie rozpoczęcia (co udowadnia, że krok się rozpoczął?)
- Zdarzenie zakończenia (co udowadnia, że krok się zakończył?)
Trzymaj to obserwowalne. „Agent zaczyna analizę” jest subiektywne; „status zmieniono na In Progress” lub „dodano pierwszą notatkę wewnętrzną” jest mierzalne.
Zdefiniuj też, co znaczy „zrobione”, aby aplikacja nie myliła częściowego ukończenia z faktycznym zakończeniem. Na przykład „resolved” może znaczyć „wiadomość o rozwiązaniu wysłana i ticket oznaczony jako Resolved”, a nie tylko „praca wewnętrznie ukończona”.
Zanotuj typowe wyjątki do śledzenia później
Prawdziwe operacje mają złożone ścieżki: poprawki, eskalacje, brakujące informacje i ponowne otwarcia. Nie próbuj modelować wszystkiego od razu — po prostu zapisz wyjątki, aby dodać je świadomie później.
Prosta notatka typu „10–15% ticketów jest eskalowanych do Tier 2” wystarczy. Użyjesz tych notatek, by zdecydować, czy wyjątki staną się oddzielnymi krokami, tagami lub odrębnymi ścieżkami przy rozszerzaniu systemu.
Zdefiniuj metryki, które naprawdę ujawnią wąskie gardła
Wąskie gardło to nie odczucie — to mierzalne spowolnienie w konkretnym kroku. Zanim zbudujesz wykresy, zdecyduj, które liczby udowodnią, gdzie praca się gromadzi i dlaczego.
Wybierz mały zestaw podstawowych miar
Zacznij od czterech metryk, które działają w większości workflowów:
- Czas cyklu (Cycle time): ile trwa element pracy od startu do zakończenia.
- Czas oczekiwania/kolejki: ile czasu element stoi nieaktywny między krokami.
- Przepustowość (Throughput): ile elementów jest ukończonych w okresie.
- WIP (work in progress): ile elementów jest obecnie „w systemie”.
To pokrywa prędkość (cykl), bezczynność (kolejka), output (przepustowość) i obciążenie (WIP). Większość „tajemniczych opóźnień” objawia się jako rosnący czas oczekiwania i WIP w konkretnym kroku.
Zdefiniuj obliczenia (wraz z przypadkami brzegowymi)
Zapisz definicje, na które zgodzi się cały zespół, a potem zaimplementuj dokładnie to.
- Cycle time =
done_timestamp − start_timestamp.- Przypadki brzegowe: elementy ponownie otwarte (traktować jako nowy cykl vs. wydłużyć oryginalny), elementy nigdy nie rozpoczęte (wykluczyć z czasu cyklu, ale policzyć w WIP), brakujące znaczniki czasu (oznaczyć jako problem z jakością danych).
- Queue time = suma luk między krokami, gdy status to „waiting”.
- Przypadki brzegowe: noce/weekendy (czas kalendarzowy vs. godziny pracy), stany zablokowane (liczyć oddzielnie od normalnego oczekiwania, jeśli chcesz czytelniejszych przyczyn).
- Throughput = liczba elementów z
done_timestampw oknie czasowym.- Przypadki brzegowe: anulowania (wykluczyć lub śledzić oddzielnie), częściowe ukończenia.
- WIP = liczba elementów niebędących w stanie terminalnym w danym momencie.
- Przypadki brzegowe: elementy wstrzymane (wciąż WIP, ale możesz chcieć mieć oddzielny „zablokowany WIP”).
Wybierz podziały, które napędzają decyzje
Wybierz cięcia, których menedżerowie faktycznie używają: zespół, kanał, linia produktów, region i priorytet. Celem jest odpowiedzieć: „Gdzie jest wolno, dla kogo i w jakich warunkach?”
Ustal okna czasowe i cele
Zdecyduj, jak często raportujesz (codziennie i tygodniowo są typowe) i zdefiniuj cele, takie jak progi SLA/SLO (np. „80% elementów wysokiego priorytetu ukończonych w ciągu 2 dni”). Cele sprawiają, że pulpit staje się użyteczny, a nie ozdobny.
Zaplanuj źródła danych i metodę zbierania
Najszybszym sposobem zablokowania projektu jest założenie, że dane „po prostu będą”. Zanim zaprojektujesz tabele czy wykresy, zapisz, skąd pochodzi każde zdarzenie i znacznik czasu — i jak utrzymasz ich spójność w czasie.
Zrób inwentaryzację źródeł, które już masz
Większość zespołów operacyjnych już śledzi pracę w kilku miejscach. Typowe punkty startowe to:
- Arkusze kalkulacyjne używane do przekazań, dziennych logów lub zliczeń produkcji
- Systemy ERP/CRM (zamówienia, klienci, kroki realizacji)
- Narzędzia ticketowe (kolejki wsparcia, zgłoszenia zmian, zadania konserwacyjne)
- Bazy wewnętrzne (skany magazynowe, tabele harmonogramów zadań, dane MES)
Dla każdego źródła zanotuj, co może dostarczyć: stabilny identyfikator rekordu, historię statusu (nie tylko aktualny status) i przynajmniej dwa znaczniki czasu (wejście do kroku, wyjście z kroku). Bez tego monitorowanie czasu w kolejce i śledzenie czasu cyklu będzie zgadywanką.
Wybierz metodę przechwytywania pasującą do źródła
Zazwyczaj masz trzy opcje i wiele aplikacji używa mieszanki:
- API pull: zaplanowany sync z ERP/CRM/narzędziami ticketowymi. Proste do rozumienia, ale trzeba obsłużyć paginację, limity i przyrostowe aktualizacje.
- Webhooki: push aktualizacji gdy praca się zmienia. Świetne do niemal rzeczywistych alertów, ale trzeba projektować retry i obsługę zdarzeń przychodzących poza kolejnością.
- Ręczne wpisy / import CSV: użyteczne dla zespołów startujących z arkuszami lub przypadków brzegowych. Uczyń to bezpiecznym poprzez szablony, walidację i czytelne komunikaty o błędach.
Zaplanuj jakość danych (bo się pojawią problemy)
Spodziewaj się brakujących znaczników czasu, duplikatów i niespójnych statusów („In Progress” vs „Working”). Zbuduj reguły wcześnie:
- Preferuj niezmienny log zdarzeń zamiast nadpisywania rekordów
- Deduplicate według source ID + event time + status
- Normalizuj statusy do kanonicznych kroków w aplikacji
- Oznacz rekordy, które nie pozwalają na wiarygodne śledzenie czasu cyklu
Zdecyduj o częstotliwości odświeżania
Nie każdy proces wymaga aktualizacji w czasie rzeczywistym. Wybierz na podstawie decyzji:
- Rzeczywisty czas: dyspozycja, triage wsparcia, ryzyko SLA
- Co godzinę: przepustowość magazynu, monitorowanie czasu w kolejce
- Codziennie: raportowanie tygodniowe, przeglądy ciągłego usprawniania
Zapisz to teraz; wpływa to na strategię synchronizacji, koszty i oczekiwania wobec pulpitu operacyjnego.
Zaprojektuj model danych pod analizę czasową
Aplikacja do śledzenia wąskich gardeł żyje lub umiera w zależności od tego, jak dobrze odpowiada na pytania czasowe: „Ile to trwało?”, „Gdzie czekało?” i „Co zmieniło się tuż przed spowolnieniem?” Najłatwiejszym sposobem, by wspierać te pytania później, jest modelowanie danych wokół zdarzeń i znaczników czasu od dnia zero.
Zacznij od podstawowych encji
Utrzymuj model małym i oczywistym:
- Process: ogólny workflow (np. „Realizacja zamówienia”).
- Step: etap w procesie (np. „Pick”, „Pack”, „Ship”).
- Work item: jednostka, która przechodzi przez kroki (ticket, zamówienie, roszczenie).
- Event: zarejestrowana zmiana stanu (wejście do kroku, przypisanie, zablokowanie, ukończenie).
- User/Team i Assignment: kto był właścicielem pracy w danym czasie.
Taka struktura pozwala mierzyć czas cyklu po kroku, czas oczekiwania między krokami i przepustowość w całym procesie bez wymyślania wyjątków.
Wybierz log zdarzeń zamiast pól „aktualny status”
Traktuj każdą zmianę statusu jako niezmienny rekord zdarzenia. Zamiast nadpisywać current_step i tracić historię, dopisz zdarzenie takie jak:
- work_item_id
- from_step → to_step (lub „entered_step”)
- event_type (assigned, started, blocked, completed)
- event_time
Możesz nadal przechowywać snapshot „current state” dla wydajności, ale analityka powinna opierać się na logu zdarzeń.
Uczyń czas i śledzenie niepodważalnymi
Przechowuj znaczniki czasu konsekwentnie w UTC. Zachowaj też oryginalne identyfikatory źródeł (np. klucz issue w Jira, ID zamówienia w ERP) na work itemach i zdarzeniach, aby każdy wykres dało się odtworzyć do rzeczywistego rekordu.
Rejestruj wyjątki bez tworzenia nadmiernej biurokracji
Zaplanuj lekkie pola na momenty, które wyjaśniają opóźnienia:
- reason_code (opcje standardowe, np. „Waiting on customer”)
- comment (opcjonalny tekst)
- blocked_flag lub severity
Uczyń je opcjonalnymi i łatwymi do uzupełnienia, żeby uczyć się na wyjątkach, nie zamieniając aplikacji w formularz do wypełniania.
Wybierz architekturę dopasowaną do zespołu
Spraw, by opóźnienia prowadziły do działań
Generuj ekrany drill-down z kafelków KPI do dokładnych zaległych elementów.
„Najlepsza” architektura to ta, którą Twój zespół potrafi zbudować, zrozumieć i obsługiwać przez lata. Zacznij od stosu odpowiadającego puli rekrutacyjnej i istniejącym umiejętnościom — popularne, dobrze wspierane wybory to React + Node.js, Django lub Rails. Spójność bije nowinkarstwo, gdy uruchamiasz pulpit operacyjny, od którego ludzie zależą codziennie.
Rozdziel obszary odpowiedzialności, aby system pozostał edytowalny
Aplikacja do śledzenia wąskich gardeł zwykle działa lepiej, gdy rozdzielisz ją na czytelne warstwy:
- Ingestia: odbiór zdarzeń (zmiany statusu, znaczniki czasu, przekazania) z formularzy, integracji lub importów.
- Storage: baza transakcyjna dla niezawodnych zapisów i historii audytu.
- Zapytania analityczne: widoki zoptymalizowane do odczytu, obliczające czas cyklu, czas oczekiwania i przepustowość.
- UI/API: endpointy i ekrany, które utrzymują pulpity szybkie i przewidywalne.
Ten podział pozwala zmieniać jedną część (np. dodać nowe źródło danych) bez przepisywania wszystkiego.
Zdecyduj, gdzie powinny być obliczenia
Niektóre metryki są wystarczająco proste, by liczyć je w zapytaniach bazodanowych (np. „średni czas oczekiwania po kroku za ostatnie 7 dni”). Inne są kosztowne lub wymagają wstępnego przetwarzania (np. percentyle, detekcja anomalii, kohorty tygodniowe). Praktyczna zasada:
- Filtry i podziały w czasie rzeczywistym rób w bazie.
- Użyj zadań tła do precompute cięższych agregatów i przechowuj je, by pulpit ładował się szybko.
- Dodaj warstwę analityczną tylko jeśli zespół będzie ją utrzymywać z pewnością.
Zaplanuj wydajność wcześnie
Pulpity operacyjne zawodzą, gdy są powolne. Używaj indeksów na znacznikach czasu, ID kroków workflow i tenant/team ID. Dodaj paginację dla logów zdarzeń. Cache’uj popularne widoki (np. „dzisiaj” i „ostatnie 7 dni”) i unieważniaj cache, gdy przychodzą nowe zdarzenia.
Jeśli chcesz głębszej dyskusji o kompromisach, trzymaj krótki zapis decyzji w repo, aby przyszłe zmiany nie dryfowały.
Szybsza droga dla zespołów chcących szybko wdrożyć
Jeśli celem jest zweryfikować analitykę workflow i alertowanie przed pełnym budowaniem, platforma vibe-codingowa jak Koder.ai może pomóc szybciej wystawić pierwszą wersję: opisujesz workflow, encje i pulpity w czacie, a następnie iterujesz wygenerowany interfejs React i backend Go + PostgreSQL, dopracowując instrumentację KPI.
Praktyczną zaletą dla aplikacji śledzącej wąskie gardła jest szybkość informacji zwrotnej: możesz pilotażować ingest (API pull, webhooki lub import CSV), dodać ekrany drill-down i poprawiać definicje metryk bez tygodni stawiania infrastruktury. Gdy będziesz gotowy, Koder.ai wspiera eksport kodu źródłowego i deployment/hosting, co ułatwia przejście z prototypu do narzędzia utrzymywanego na stałe.
Zaprojektuj pulpit i doświadczenie drill-down
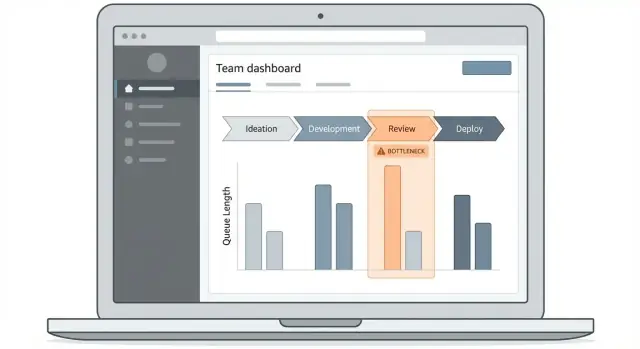
Aplikacja do śledzenia wąskich gardeł odnosi sukces tylko wtedy, gdy ludzie szybko odpowiadają na pytanie: „Gdzie praca teraz utknęła i które elementy są tego przyczyną?” Twój pulpit powinien sprawić, że ta ścieżka będzie oczywista, nawet dla osoby odwiedzającej raz w tygodniu.
Zacznij od 2–3 kluczowych ekranów
Utrzymaj pierwsze wydanie zwarte:
- Dashboard przeglądowy: „tablica statusu” dla czasu cyklu, czasu oczekiwania i najważniejszych zablokowanych etapów.
- Lista elementów pracy: przeszukiwalna, filtrowalna tabela elementów dotkniętych opóźnieniami.
- Szczegóły workflow: widok krok po kroku pokazujący czas na każdym etapie i punkty przekazań.
Te ekrany tworzą naturalny flow drill-down bez konieczności uczenia się skomplikowanego UI.
Używaj wizualizacji, które tłumaczą czas i przepływ
Wybieraj typy wykresów odpowiadające pytaniom operacyjnym:
- Funnel etapowy: pokazuje, gdzie akumuluje się wolumen (dobry do wykrywania kolejek).
- Słupki czasu w etapie: porównują etapy po medianie i percentylach, nie tylko po średnich.
- Linie trendu: odpowiadają na pytanie „czy to się poprawia czy pogarsza?” w tygodniach.
- Heatmapy: ujawniają wzorce, np. „poniedziałki w Review” lub „przekazania nocnej zmiany”.
Używaj prostych etykiet: „Czas oczekiwania” zamiast „Queue latency”.
Uczyń filtry spójnymi i łatwo dostrzegalnymi
Użyj jednego wspólnego paska filtrów na wszystkich ekranach (to samo rozmieszczenie, te same domyślne ustawienia): zakres dat, zespół, priorytet i krok. Pokaż aktywne filtry jako chipy, żeby użytkownicy nie błędnie odczytywali liczby.
Zaprojektuj czytelne ścieżki drill-down
Każdy kafelek KPI powinien być klikalny i prowadzić w użyteczne miejsce:
KPI → etap → lista dotkniętych elementów
Przykład: kliknięcie „Najdłuższy czas w kolejce” otwiera szczegóły etapu, a pojedyncze kliknięcie pokazuje dokładne elementy aktualnie tam czekające — posortowane według wieku, priorytetu i właściciela. To zamienia ciekawość w konkretną listę zadań, co sprawia, że pulpit jest używany, a nie ignorowany.
Dodaj alerty i sygnały wczesnego ostrzegania
Buduj na prostej mapie procesu
Zamień mapę procesu w kroki, zdarzenia i pulpity bez tygodni konfiguracji.
Pulpity świetnie nadają się do przeglądów, ale wąskie gardła zwykle najbardziej szkodzą między spotkaniami. Alerty zamieniają aplikację w system wczesnego ostrzegania: znajdujesz problemy, gdy się formują, a nie po stracie tygodnia.
Zacznij od prostych, przewidywalnych reguł
Rozpocznij od małego zestawu typów alertów, które zespół już uznaje za „złe”:
- Przekroczenia progów: czas cyklu lub czas oczekiwania powyżej znanego limitu (np. „etap Review > 24 godziny”).
- Nietypowe wzrosty: mediana czasu cyklu dziś wyższa o 30% vs tydzień temu.
- Utknięte elementy: brak zmiany statusu przez N godzin/dni lub elementy przekraczające maksymalny wiek.
Trzymaj pierwszą wersję prostą. Kilka deterministycznych reguł wyłapie większość problemów i jest łatwiejsze do zaufania niż skomplikowane modele.
Dodaj lekkie kontrole anomalii
Gdy progi się ustabilizują, dodaj podstawowe sygnały „czy to dziwne?”:
- Zmiana procentowa vs tydzień temu (porównanie tego samego dnia tygodnia zmniejsza fałszywe alarmy).
- Dryf średniej ruchomej (np. 7-dniowa średnia rosnąca stopniowo).
- Niezgodności wolumenu (wejście rośnie szybciej niż wyjście na danym etapie).
Traktuj anomalie jako sugestie, nie alarmy: oznaczaj je „Heads up”, dopóki użytkownicy nie potwierdzą ich przydatności.
Dostarczaj alerty tam, gdzie ludzie pracują
Obsługuj wiele kanałów, aby zespoły mogły wybrać sposób komunikacji:
- Email dla menedżerów i podsumowań dziennych
- Slack/Microsoft Teams do natychmiastowego triage
- Powiadomienia w aplikacji dla właścicieli wewnątrz narzędzia
Uczyń każdy alert wykonalnym
Alert powinien odpowiadać na „co, gdzie i co dalej”:
- Który etap jest dotknięty i w jakim okresie czasu
- Główne przyczyny (np. zespół, kategoria, priorytet)
- Bezpośredni odnośnik do śledzenia, np.
/dashboard?step=review&range=7d&filter=stuck
Jeśli alerty nie prowadzą do konkretnej dalszej akcji, ludzie je wyciszą — traktuj jakość alertów jak funkcję produktu, nie dodatek.
Zadbaj o uprawnienia, bezpieczeństwo i audytowalność
Aplikacja do śledzenia wąskich gardeł szybko staje się „źródłem prawdy”. To świetnie — dopóki niewłaściwa osoba nie zmieni definicji, nie wyeksportuje wrażliwych danych lub nie udostępni pulpitu poza swoim zespołem. Uprawnienia i ślady audytu to nie biurokracja; to ochrona zaufania do liczb.
Zdefiniuj role i zasady dostępu
Zacznij od prostego, jasnego modelu ról i rozszerzaj go tylko wtedy, gdy potrzeba:
- Viewer: dostęp tylko do odczytu do pulpitów i raportów.
- Manager: może filtrować po zespole, tworzyć zapisane widoki, potwierdzać alerty i dodawać notatki (ale nie może zmieniać globalnych ustawień).
- Admin: zarządza definicjami procesów, formułami KPI, integracjami i dostępem użytkowników.
Bądź jawny co do uprawnień: przeglądanie surowych zdarzeń vs agregatów, eksport danych, edycja progów i zarządzanie integracjami.
Oddziel dane według zespołu lub jednostki biznesowej
Jeśli aplikację używa wiele zespołów, egzekwuj separację na poziomie danych — nie tylko w UI. Typowe opcje:
- Multi-tenant: każdy rekord ma
tenant_id, a każde zapytanie jest do niego ograniczone. - Partycje/projekty: oddzielne „workspaces” dla jednostek biznesowych z niezależnymi ustawieniami i pulpitami.
Zdecyduj wcześnie, czy menedżerowie mogą widzieć dane innych zespołów. Uczyń widoczność międzyzespołową uprawnieniem, a nie domyślną.
Bezpieczne logowanie (SSO lub gotowość do MFA)
Jeśli organizacja ma SSO (SAML/OIDC), użyj go, aby centralizować offboarding i kontrolę dostępu. Jeśli nie, zaimplementuj logowanie gotowe na MFA (TOTP lub passkeys), obsługujące bezpieczne resetowanie haseł i wymuszające timeouty sesji.
Uczyń zmiany audytowalnymi
Loguj akcje, które mogą zmienić wyniki lub ujawnić dane: eksporty, zmiany progów, edycje workflow, aktualizacje uprawnień i ustawienia integracji. Zapisz kto to zrobił, kiedy, co się zmieniło (przed/po) i gdzie (workspace/tenant). Udostępnij widok „Audit Log”, aby szybko badać problemy.
Przekształć insighty w działania i usprawnienia procesów
Pulpit o wąskich gardłach ma znaczenie tylko wtedy, gdy zmienia zachowanie zespołów. Celem tej sekcji jest przekształcenie „interesujących wykresów” w powtarzalny rytm operacyjny: decyduj, działaj, mierz i zachowuj to, co działa.
Stwórz lekki przegląd wąskich gardeł
Ustal prosty cotygodniowy rytm (30–45 minut) z jasnymi właścicielami. Zacznij od 1–3 największych wąskich gardeł według wpływu (np. najwyższy czas oczekiwania lub największy spadek przepustowości), a następnie uzgodnij jedną akcję na każde wąskie gardło.
Utrzymuj workflow mały:
- Właściciel: jedna osoba odpowiedzialna za akcję
- Termin: domyślnie następny przegląd
- Definicja ukończenia: mierzalna zmiana (nie „zbadamy dalej”)
Zapisuj decyzje bezpośrednio w aplikacji, aby pulpit i log działań były powiązane.
Śledź ulepszenia jako eksperymenty
Traktuj poprawki jak eksperymenty, by szybko się uczyć i unikać „losowych działań optymalizacyjnych”. Dla każdej zmiany zapisz:
- Hipotezę (co jest powodem opóźnień i dlaczego)
- Zmianę (co zrobicie)
- Oczekiwany wpływ (która metryka ma się zmienić i o ile)
- Wynik (co naprawdę się wydarzyło)
Z czasem to stanie się playbookiem: co zmniejsza czas cyklu, co redukuje poprawki, a co nie pomaga.
Dodaj kontekst za pomocą adnotacji
Wykresy mogą wprowadzać w błąd bez kontekstu. Dodawaj proste adnotacje na osi czasu (np. onboard nowej osoby, awaria systemu, zmiana polityki), aby widzowie poprawnie interpretowali przesunięcia w czasie oczekiwania lub przepustowości.
Ułatwiaj dzielenie się
Daj opcje eksportu do analizy i raportowania — CSV i zaplanowane raporty — aby zespoły mogły dołączać wyniki do aktualizacji operacyjnych i przeglądów kierownictwa. Jeśli masz już stronę raportową, linkuj do niej z pulpitu (np. /reports).
Wdróż, monitoruj i utrzymuj świeżość danych
Szybko wdroż pilota
Użyj hostingu Koder.ai, aby pilotażować narzędzie i iterować z użytkownikami.
Aplikacja do śledzenia wąskich gardeł ma sens tylko wtedy, gdy jest dostępna i liczby pozostają wiarygodne. Traktuj wdrożenie i świeżość danych jako część produktu, nie dodatek.
Używaj oddzielnych środowisk i powtarzalnych wdrożeń
Skonfiguruj dev / staging / prod wcześnie. Staging powinien odzwierciedlać produkcję (ten sam silnik bazy, podobny wolumen danych, te same zadania tła), aby wykryć wolne zapytania i błędne migracje przed użytkownikami.
Automatyzuj deploy z jednym pipeline: uruchom testy, zastosuj migracje, wdroż, a następnie wykonaj krótki smoke check (logowanie, załadowanie pulpitu, weryfikacja ingestii). Utrzymuj małe i częste wdrożenia; zmniejsza to ryzyko i ułatwia rollback.
Monitoruj aplikację i pipeline
Monitorowanie powinno obejmować dwa fronty:
- Zdrowie aplikacji: wskaźniki błędów, opóźnienia, wolne endpointy i zapytania.
- Zdrowie danych: błędy ingestii, wielkość backlogu i „czas od ostatniego zdarzenia”.
Alertuj o symptomach odczuwalnych przez użytkowników (pulpity timeoutują) i o wczesnych sygnałach (kolejka rośnie przez 30 minut). Śledź też nieudane obliczenia metryk — brakujące czasy cyklu mogą wyglądać jak „poprawa”.
Utrzymuj świeżość danych: opóźnione zdarzenia, korekty i backfille
Dane operacyjne przychodzą późno, poza kolejnością lub są korygowane. Zaplanuj:
- Idempotentną ingestę (ponowne przetworzenie tego samego zdarzenia nie zdubluje go).
- Backfille na zakresy dat, gdy źródło było niedostępne.
- Recompute'y gdy zmieniają się dane referencyjne (np. zaktualizowane kalendarze zmian).
Zdefiniuj, co znaczy „świeże” (np. 95% zdarzeń w ciągu 5 minut) i pokaż informację o świeżości w UI.
Pisz runbooki, by naprawy nie były zgadywanką
Udokumentuj kroki: jak zrestartować sync, zweryfikować KPI z wczoraj i potwierdzić, że backfill nie zmienił historycznych liczb w niespodziewany sposób. Przechowuj runbooki z projektem i linkuj je z /docs, żeby zespół mógł szybko reagować.
Iteruj z użytkownikami i rozszerzaj zasięg
Aplikacja do śledzenia wąskich gardeł odnosi sukces, gdy ludzie jej ufają i regularnie z niej korzystają. To dzieje się po tym, jak obserwujesz użytkowników odpowiadających na rzeczywiste pytania („Dlaczego zatwierdzenia są wolne w tym tygodniu?”) i wtedy dopracujesz produkt wokół tych workflowów.
Zacznij od pilota i ucz się, co się psuje
Zacznij od jednego zespołu pilota i małej liczby workflowów. Utrzymaj zakres na tyle wąski, by obserwować użycie i szybko reagować.
W pierwszym tygodniu lub dwóch skup się na tym, co myli lub brakuje:
- Których wykresów użytkownicy źle odczytują?
- Gdzie się zawieszają podczas drążenia danych?
- Jakich danych oczekują, a nie znajdują?
- Które wąskie gardła wydają się oczywiste użytkownikom, ale nie są odzwierciedlone w aplikacji?
Zbieraj feedback w samym narzędziu (proste pytanie „Czy to było użyteczne?” na kluczowych ekranach działa dobrze), zamiast polegać na pamięci ze spotkań.
Waliduj metryki, by uniknąć „kłótni o dashboard”
Zanim rozszerzysz aplikację na kolejne zespoły, uzgodnij definicje z osobami, które będą rozliczane. Wiele wdrożeń kończy się niepowodzeniem, bo zespoły nie zgadzają się, co metryka oznacza.
Dla każdego KPI (czas cyklu, czas oczekiwania, wskaźnik poprawek, naruszenia SLA) udokumentuj:
- Dokładne zdarzenia startu i końca
- Obsługę pauz, weekendów i brakujących znaczników czasu
- Jak liczone są wyjątki (anulowania, eskalacje, ponowne otwarcia)
Następnie przejrzyj te definicje z użytkownikami i dodaj krótkie dymki wyjaśniające w UI. Jeśli zmieniasz definicję, pokaż wyraźny changelog, aby ludzie rozumieli, dlaczego liczby się przesunęły.
Rozszerzaj zasięg bez zamieniania aplikacji w chaos
Dodawaj funkcje ostrożnie i tylko wtedy, gdy analiza workflow pilota jest stabilna. Typowe rozszerzenia to niestandardowe kroki (różne zespoły nazywają etapy inaczej), dodatkowe źródła (tickety + CRM + arkusze) i zaawansowana segmentacja (linia produktów, region, priorytet, segment klienta).
Użyteczna zasada: dodawaj jedną nową zmienną naraz i weryfikuj, czy poprawia decyzje, a nie tylko raportowanie.
Uprość onboarding i uczyn go powtarzalnym
W miarę rozwoju deploymentu do kolejnych zespołów potrzebujesz spójności. Stwórz krótkiego przewodnika onboardingowego: jak podłączyć dane, jak interpretować pulpit operacyjny i jak reagować na alerty o wąskich gardłach.
Linkuj użytkowników do odpowiednich stron w produkcie i materiałów, takich jak /pricing i /blog, aby nowi użytkownicy mogli samodzielnie znaleźć odpowiedzi zamiast czekać na szkolenie.