15 maj 2025·8 min
Jak zbudować aplikację webową do wzbogacania danych klientów
Dowiedz się, jak zbudować aplikację webową wzbogacającą rekordy klientów: architektura, integracje, dopasowywanie, walidacja, prywatność, monitorowanie i wskazówki wdrożeniowe.
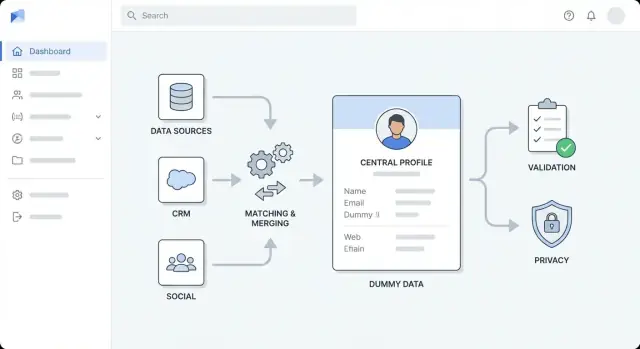
Określ cele, użytkowników i zakres wzbogacania
Zanim wybierzesz narzędzia lub narysujesz diagram architektury, dokładnie zdefiniuj, co dla was oznacza „wzbogacanie”. Zespoły często mieszają różne typy wzbogacania, a potem mają trudności z mierzeniem postępów — albo spierają się o to, co oznacza „zrobione”.
Co się liczy jako wzbogacanie?
Zacznij od nazwania kategorii pól, które chcesz poprawić, i od powodów:
- Firmograficzne: wielkość firmy, branża, lokalizacja siedziby, etap finansowania
- Kontaktowe: stanowisko, zweryfikowany e‑mail/telefon, stopień seniority, rola
- Behawioralne: sygnały użycia produktu, zamiar, wskaźniki zaangażowania
- Pola niestandardowe: wewnętrzne terytorium, poziom konta, ocena dopasowania do ICP
Zapisz, które pola są wymagane, które są mile widziane, a które nigdy nie powinny być wzbogacane (np. atrybuty wrażliwe).
Kto będzie korzystał z aplikacji — i w jakim celu?
Zidentyfikuj głównych użytkowników i ich najważniejsze zadania:
- Sales ops: redukcja duplikatów, standaryzacja kont, poprawa routingu
- Marketing ops: wzbogacanie leadów pod segmentację i precyzyjne targetowanie
- Support: szybki kontekst konta przy zgłoszeniach
- Analitycy: wiarygodne zbiory danych do raportów
Każda grupa użytkowników zazwyczaj potrzebuje innego przepływu pracy (przetwarzanie masowe vs. przegląd pojedynczych rekordów), więc zarejestruj te potrzeby wcześnie.
Określ rezultaty, granice zakresu i metryki sukcesu
Wypisz rezultaty w mierzalnych terminach: wyższy wskaźnik dopasowań, mniej duplikatów, szybszy routing leadów/kont albo lepsza jakość segmentacji.
Ustal jasne granice: które systemy są w zakresie (CRM, billing, analityka produktu, support) i które nie — przynajmniej dla pierwszego wydania.
Na koniec uzgodnij metryki sukcesu i akceptowalne wskaźniki błędów (np. pokrycie wzbogacania, współczynnik weryfikacji, wskaźnik duplikatów oraz reguły „bezpiecznej awarii”, gdy wzbogacanie jest niepewne). To będzie twoja latarnia podczas dalszej budowy.
Zmodeluj dane klienta i zidentyfikuj luki
Zanim czegokolwiek wzbogacisz, wyjaśnij, co w waszym systemie oznacza „klient” — i co już o nim wiecie. To zapobiega płaceniu za wzbogacanie danych, które nie mogą być zapisane, i uniknie mylących scaleni później.
Inwentaryzacja aktualnych pól i źródeł
Zacznij od prostego katalogu pól (np. imię, e‑mail, firma, domena, telefon, adres, stanowisko, branża). Dla każdego pola zanotuj, skąd pochodzi: wpis użytkownika, import do CRM, system rozliczeń, narzędzie supportowe, formularz rejestracji produktu lub dostawca wzbogacania.
Zanotuj też, jak jest zbierane (wymagane vs opcjonalne) i jak często się zmienia. Na przykład stanowisko i wielkość firmy zmieniają się w czasie, podczas gdy wewnętrzne ID klienta nie powinno się zmieniać.
Zdefiniuj model tożsamości: osoba, firma, konto
Większość przepływów wzbogacania obejmuje co najmniej dwie jednostki:
- Osoba (kontakt/lead): osoba z e‑mailami, telefonami, rolami
- Firma (organizacja): biznes z domeną, lokalizacją, danymi firmograficznymi
Zastanów się, czy potrzebujesz też Konta (relacji handlowej), które łączy wiele osób z jedną firmą i ma atrybuty jak plan, daty umowy i status.
Zapisz związki, które wspierasz (np. wiele osób → jedna firma; jedna osoba → wiele firm w czasie).
Udokumentuj typowe problemy z danymi
Wypisz powtarzające się kwestie: brakujące wartości, niespójne formaty ("US" vs "United States"), duplikaty powstałe przy importach, przeterminowane rekordy oraz sprzeczne źródła (adres billingowy vs adres w CRM).
Wybierz klucze wymagane i ustaw poziomy zaufania
Wybierz identyfikatory używane do dopasowań i aktualizacji — zwykle e‑mail, domena, telefon oraz wewnętrzne ID klienta.
Przypisz każdemu poziom zaufania: które klucze są autorytatywne, które są „najlepszym wysiłkiem”, a które nigdy nie powinny być nadpisywane.
Wyjaśnij własność i uprawnienia edycji
Uzgodnij, kto jest właścicielem których pól (Sales ops, Support, Marketing, Customer Success) i zdefiniuj reguły edycji: co może zmienić człowiek, co automatyzacja, a co wymaga zatwierdzenia.
To zarządzanie oszczędza czas, gdy wyniki wzbogacania konfliktują z istniejącymi danymi.
Wybierz źródła wzbogacania i kontrakty danych
Zanim zaczniesz pisać kod integracji, zdecyduj, skąd będą pochodzić dane wzbogacające i co możesz z nimi robić. To zapobiega częstemu błędowi: wdrożeniu funkcji, która działa technicznie, ale łamie oczekiwania kosztowe, niezawodnościowe lub zgodnościowe.
Typowe źródła wzbogacania
Zazwyczaj łączysz kilka wejść:
- Systemy wewnętrzne: CRM, billing, zgłoszenia support, analityka produktu, platforma e‑mail, hurtownia danych
- API zewnętrzne: firmografia firm, walidacja kontaktów, kody branżowe, technografia, sygnały ryzyka
- Przesłane listy: CSV od sprzedaży, wydarzeń, partnerów lub dostawców danych
- Webhooki: aktualizacje w czasie rzeczywistym z narzędzi obserwujących zmiany (np. weryfikacja e‑mail, dostawcy tożsamości)
Jak oceniać źródła
Dla każdego źródła oceń je pod kątem pokrycia (jak często zwraca przydatne informacje), świeżości (jak szybko się aktualizuje), kosztu (za wywołanie/rekord), limitów zapytań i warunków użytkowania (co możesz przechowywać, jak długo i w jakim celu).
Sprawdź też, czy dostawca zwraca oceny pewności i jasną proweniencję (skąd pochodzi pole).
Zdefiniuj kontrakt danych
Traktuj każde źródło jako kontrakt określający nazwy i formaty pól, pola wymagane vs opcjonalne, częstotliwość aktualizacji, oczekiwane opóźnienia, kody błędów i semantykę pewności.
Dołącz wyraźne mapowanie („pole dostawcy → twoje kanoniczne pole”) oraz reguły dla wartości null i konfliktów.
Fallback i decyzje o przechowywaniu
Zaplanuj, co się dzieje, gdy źródło jest niedostępne lub zwraca wyniki o niskiej pewności: ponów z backoffem, umieść w kolejce do późniejszego przetworzenia lub użyj źródła zapasowego.
Zdecyduj, co przechowujesz (atrybuty stabilne potrzebne do wyszukiwania/raportowania), a co obliczasz na żądanie (kosztowne lub czasowo wrażliwe zapytania).
Na koniec udokumentuj ograniczenia dotyczące przechowywania wrażliwych atrybutów (np. identyfikatory osobiste, wnioskowane demografie) i ustal reguły retencji.
Zaprojektuj architekturę wysokiego poziomu
Zanim wybierzesz narzędzia, zdecyduj, jak ma być zbudowana aplikacja. Jasna architektura na wysokim poziomie utrzymuje prace nad wzbogacaniem przewidywalne, zapobiega „quick fixom” zamieniającym się w trwały bałagan i pomaga zespołowi oszacować pracę.
Wybierz styl architektury dopasowany do zespołu
Dla większości zespołów zacznij od modularnego monolitu: jedna wdrażalna aplikacja, wewnętrznie podzielona na dobrze zdefiniowane moduły (ingest, dopasowanie, wzbogacanie, UI). Jest prościej budować, testować i debugować.
Przejdź do oddzielnych usług, gdy masz uzasadnienie — np. wysoka przepustowość wzbogacania, potrzeba niezależnego skalowania lub różne zespoły odpowiedzialne za różne części. Typowy podział:
- Usługa API (żądania synchroniczne, autoryzacja, CRUD rekordów)
- Serwis workerów (asynchroniczne wzbogacanie, ponawianie)
- UI (przegląd, zatwierdzenia, operacje masowe)
Rozdziel obawy na warstwy
Utrzymuj wyraźne granice, żeby zmiany nie rozchodziły się niekontrolowanie:
- Warstwa ingest: importy z CRM/plików i normalizacja wejścia
- Warstwa wzbogacania: wywołania dostawców/wewnętrznych źródeł i zapis wyników
- Warstwa walidacji: reguły jakości danych i flagowanie wyjątków
- Warstwa przechowywania: profile klientów, surowe ładunki źródłowe, historia audytu
- Warstwa prezentacji: widoki UI, kolejki przeglądu, zatwierdzenia
Projektuj od początku z myślą o asynchronicznym wzbogacaniu
Wzbogacanie jest wolne i podatne na awarie (limity, timeouty, częściowe dane). Traktuj wzbogacanie jako zadania:
- API tworzy zadanie i szybko odpowiada
- Workerzy przetwarzają zadania przez kolejkę (z ponawianiem i backoffem)
- UI pokazuje status zadania i pozwala na ponowne uruchomienie
Zaplanuj środowiska i konfigurację
Skonfiguruj dev/staging/prod wcześnie. Trzymaj klucze do dostawców, progi i flagi funkcji w konfiguracji (nie w kodzie) i ułatw możliwość podmiany dostawców w zależności od środowiska.
Zgraj się z prostym diagramem jednej strony
Szkicuj prosty diagram: UI → API → baza danych, plus kolejka → workerzy → dostawcy wzbogacania. Używaj go na spotkaniach, żeby wszyscy zgodzili się co do odpowiedzialności przed rozpoczęciem implementacji.
Prototypowanie szybkiej ścieżki (opcjonalne)
Jeśli celem jest walidacja przepływów i ekranów przeglądu przed pełnym cyklem inżynieryjnym, platforma vibe‑coding taka jak Koder.ai może pomóc szybko zrobić prototyp: UI w React, warstwa API w Go i storage na PostgreSQL.
To szczególnie przydatne, by przetestować model zadań (asynchroniczne wzbogacanie z ponawianiem), historię audytu i wzorce kontroli dostępu, a potem wyeksportować kod, gdy będziesz gotowy do produkcji.
Ustaw przechowywanie, kolejki i usługi wspierające
Zanim podłączysz dostawców wzbogacania, uporządkuj „instalację”. Decyzje o przechowywaniu i przetwarzaniu w tle trudno zmienić później — wpływają bezpośrednio na niezawodność, koszty i audytowalność.
Baza główna: profile + historia
Wybierz główną bazę dla profili klientów, która wspiera dane strukturalne i elastyczne atrybuty. Postgres to powszechny wybór, bo pozwala przechowywać pola podstawowe (imię, domena, branża) obok pół pół‑ustrukturalnych (JSON).
Równie ważne: przechowuj historię zmian. Zamiast cicho nadpisywać wartości, zapisuj kto/co zmieniło pole, kiedy i dlaczego (np. „vendor_refresh”, „manual_approval”). To ułatwia zatwierdzenia i chroni przy rollbackach.
Kolejka: wzbogacanie i ponawianie
Wzbogacanie jest z natury asynchroniczne: API limitują wywołania, sieć zawodzi, a niektórzy dostawcy odpowiadają wolno. Dodaj kolejkę zadań do pracy w tle:
- Żądania wzbogacania (pojedyncze i masowe)
- Ponawianie z backoffem
- Zaplanowane odświeżanie (np. co 30/90 dni)
- Obsługa dead‑letter dla zadań wielokrotnie nieudanych
To utrzymuje UI responsywnym i zapobiega awariom aplikacji z powodu problemów z dostawcami.
Cache: szybkie odczyty i śledzenie limitów
Mały cache (np. Redis) pomaga przy częstych zapytaniach (np. „firma po domenie”) i śledzeniu limitów dostawców i okien cooldown. Przydaje się też do idempotency keys, żeby powtarzające się importy nie uruchamiały podwójnego wzbogacania.
Przechowywanie plików i retencja
Zaplanuj storage obiektowy dla importów CSV/eksportów, raportów błędów i plików „diff” używanych w przepływach przeglądu.
Zdefiniuj reguły retencji: trzymaj surowe payloady dostawców tylko tak długo, jak potrzebne do debugowania i audytu, i usuwaj logi zgodnie z polityką zgodności.
Zbuduj pipeline ingest i normalizacji
Umieść aplikację przed użytkownikami
Wdróż i hostuj nową aplikację, a gdy będzie produkcyjna, dodaj własną domenę.
Twoja aplikacja wzbogacająca jest tak dobra, jak dane, które do niej trafiają. Ingest to krok, w którym decydujesz, jak informacja wchodzi do systemu, a normalizacja to miejsce, gdzie ujednolica się formaty, by móc dopasowywać, wzbogacać i raportować.
Zdecyduj, jak dane wchodzą
Większość zespołów potrzebuje mieszanki punktów wejścia:
- Endpointy API dla produktu lub narzędzi wewnętrznych do przesyłania nowych/zmienionych klientów
- Webhooki z CRM lub systemów billingowych dla near‑real‑time zmian
- Zapotrzebowane pobrania (synchronizacje nocne) dla systemów bez push
- Importy CSV dla backfilli i jednorazowych uploadów
Cokolwiek obsługujesz, trzymaj etap „raw ingest” lekki: akceptuj dane, uwierzytelniaj, loguj metadane i wstawiaj zadanie do przetworzenia.
Normalizuj i standaryzuj wcześnie
Stwórz warstwę normalizacji, która zamienia nieuporządkowane wejścia w spójny wewnętrzny kształt:
- Imiona: przytnij spacje, próbuj rozdzielić pełne imię, poprawiaj wielkość liter
- Telefony: konwertuj do formatu E.164 i zapisz założenia dotyczące kraju
- Adresy: standaryzuj pola (ulica, miejscowość, region, kod pocztowy) i zachowaj oryginalny tekst
- Domeny/e‑maile: lowercase, usuń parametry śledzące z URL, waliduj składnię
Waliduj, kwarantannuj i zachowaj idempotentność
Zdefiniuj pola wymagane według typu rekordu i odrzucaj lub kwarantannuj rekordy, które nie przejdą kontroli (np. brak e‑maila/domeny do dopasowania firmy). Kwarantanna powinna być widoczna i możliwa do naprawy w UI.
Dodaj klucze idempotencji, aby zapobiec podwójnemu przetwarzaniu przy ponowieniach (częste przy webhookach i niestabilnych sieciach). Prosty sposób to hasz (source_system, external_id, event_type, event_timestamp).
Śledź linię pochodzenia per pole
Przechowuj proweniencję dla każdego rekordu, a jeśli to możliwe — dla każdego pola: źródło, czas ingestu i wersja transformacji. Dzięki temu łatwiej odpowiesz na pytania typu: „Dlaczego ten numer telefonu się zmienił?” lub „Który import wprowadził tę wartość?”.
Zaimplementuj dopasowywanie, deduplikację i scalanie
Skuteczne wzbogacanie zależy od niezawodnego rozpoznawania, kto jest kim. Aplikacja potrzebuje jasnych reguł dopasowań, przewidywalnego zachowania przy scalaniu i zabezpieczeń, gdy system nie jest pewny.
Zdefiniuj reguły dopasowań (i progi pewności)
Zacznij od deterministycznych identyfikatorów:
- Dokładne klucze: e‑mail (znormalizowany na lowercase), ID klienta, numer podatkowy, lub zweryfikowana domena
Następnie dodaj dopasowania probabilistyczne tam, gdzie brakuje dokładnych kluczy:
- Dopasowania przybliżone: imię + domena firmy, imię + lokalizacja, podobieństwo numerów telefonów
Przypisz wynik dopasowania i ustaw progi, np.:
- Auto‑scalaj tylko powyżej wysokiego progu
- Kolejkuj do przeglądu w zakresie „może”
- Odrzuć poniżej dolnego progu
Zaplanuj logikę deduplikacji i scalania
Gdy dwa rekordy reprezentują tego samego klienta, zdecyduj jak wybiera się pola:
- Priorytety pól: „zweryfikowany e‑mail ma pierwszeństwo przed nieweryfikowanym”, „nowszy timestamp wygrywa”, „CRM nadpisuje wzbogacanie dla właściciela kontaktu”
- Oceny źródeł: ustal ranking źródeł (CRM, billing, dostawcy wzbogacania) do rozstrzygania konfliktów
- Obsługa konfliktów: zachowuj obie wartości gdy to możliwe (np. wiele numerów telefonów) lub zapisuj przegraną wartość w historii
Ślad audytowy i przepływ przeglądu
Każe scalanie powinno tworzyć zdarzenie audytowe: kto/co je wywołało, wartości przed/po, kiedy, wynik dopasowania i zaangażowane ID rekordów.
Dla niejednoznacznych dopasowań zapewnij ekran przeglądu z porównaniem bok‑w‑bok i opcjami „scal / nie scal / poproś o więcej danych”.
Zabezpieczenia przed przypadkowymi masowymi scaleniami
Wymagaj dodatkowego potwierdzenia przy scalaniach masowych, limituj liczbę scalonych rekordów na zadanie i wspieraj podgląd „suchy przebieg”.
Dodaj też ścieżkę cofania (undo) lub możliwość odwrócenia scalenia za pomocą historii audytu, aby pomyłki nie były trwałe.
Zintegruj API wzbogacające i zadbaj o niezawodność
Wzbogacanie to punkt styku zewnętrzny — wielu dostawców, niespójne odpowiedzi i nieprzewidywalna dostępność. Traktuj każdego dostawcę jako wtyczkę, dzięki czemu możesz dodawać, wymieniać lub wyłączać źródła bez ingerencji w resztę pipeline'u.
Buduj konektory do dostawców (autoryzacja, ponawianie, mapowanie błędów)
Stwórz jeden konektor na dostawcę z jednolitym interfejsem (np. enrichPerson(), enrichCompany()). Trzymaj logikę specyficzną dla dostawcy w konektorze:
- Autoryzacja (klucze API, tokeny OAuth, odświeżanie tokenów)
- Standardowe ponawianie dla błędów przejściowych
- Mapowanie błędów (przekształć błędy dostawcy na kategorie jak
invalid_request,not_found,rate_limited,provider_down)
Dzięki temu downstream obsługuje twoje kategorie błędów, a nie każde dziwactwo dostawcy.
Obsługuj limity zapytań przez throttling i backoff
Większość API narzuca limity. Dodaj throttling per dostawca (czasem nawet per endpoint), by trzymać się limitów.
Gdy osiągniesz limit, używaj wykładniczego backoffu z jitterem i respektuj nagłówki Retry‑After.
Planuj też „powolne awarie”: timeouty i częściowe odpowiedzi traktuj jako zdarzenia do ponowienia, a nie ciche odrzucenia.
Przechowuj pewność i dowody (zgodnie z polityką)
Wyniki wzbogacania rzadko są absolutne. Przechowuj oceny pewności od dostawcy, gdy są dostępne, oraz własny wynik oparty na jakości dopasowania i kompletności pól.
Tam, gdzie umowa i polityka prywatności na to pozwalają, zapisuj surowe dowody (URL źródła, identyfikatory, znaczniki czasu) dla audytu i budowania zaufania użytkownika.
Strategia multi‑dostawcza: wybór „najlepszego dostępnego”
Wspieraj wielu dostawców, definiując reguły wyboru: najtańszy‑pierwszy, najwyższa pewność lub pole‑po‑polu „najlepsze dostępne”.
Zapisuj, który dostawca dostarczył każde atrybut, aby móc wyjaśnić zmiany i ewentualnie cofnąć poprawki.
Zasady odświeżania
Dane się starzeją. Wdróż polityki odświeżania, np. „ponowne wzbogacanie co 90 dni”, „odśwież po zmianie kluczowego pola” lub „odśwież tylko gdy spadnie pewność”.
Umożliwiaj konfigurację harmonogramów per klient i per typ danych, by kontrolować koszty i hałas.
Dodaj reguły jakości danych i walidację
Przejdź od schematu do UI
Przekształć model danych i kontrakty w działające ekrany CRUD i API, nad którymi możesz iterować.
Wzbogacanie pomaga tylko wtedy, gdy nowe wartości są godne zaufania. Traktuj walidację jako funkcję pierwszorzędną: chroni użytkowników przed chaosem importów, zawodnymi odpowiedziami zewnętrznych dostawców i przypadkowymi uszkodzeniami przy scalaniu.
Zdefiniuj reguły walidacji per pole
Zacznij od prostego „katalogu reguł” dla każdego pola, współdzielonego między formularzami UI, pipeline'ami ingest i publicznymi API.
Typowe reguły to walidacja formatu (e‑mail, telefon, kod pocztowy), dozwolone wartości (kody krajów, listy branż), zakresy (liczba pracowników, przedziały przychodów) i zależności (jeśli country = US, to state jest wymagane).
Wersjonuj reguły, aby móc je bezpiecznie zmieniać w czasie.
Dodaj kontrole jakości odpowiadające realnemu użyciu
Poza podstawową walidacją uruchamiaj kontrole jakości odpowiadające biznesowym pytaniom:
- Kompletność: Czy mamy minimalne pola do użycia rekordu?
- Unikalność: Czy „unikalne” identyfikatory (domena, NIP) są zdublowane?
- Spójność: Czy powiązane pola zgadzają się ze sobą (kraj vs. prefiks telefonu)?
- Aktualność: Jak stare jest pole i czy należy je odświeżyć?
Oceniaj rekordy i źródła
Przekształć kontrole w kartę wyników: per rekord (ogólny stan) i per źródło (jak często dostarcza poprawne, aktualne wartości).
Użyj wyniku do kierowania automatyzacją — np. auto‑stosuj wzbogacenia tylko powyżej progu.
Przewoź błędy przewidywalnie
Gdy rekord nie przejdzie walidacji, nie usuwaj go.
Wyślij go do kolejki „data‑quality” do ponowienia (problemy przejściowe) lub do ręcznego przeglądu (błędne dane). Przechowuj payload, naruszenia reguł i sugerowane poprawki.
Uczyń błędy zrozumiałymi
Zwracaj jasne, wykonalne komunikaty dla importów i klientów API: jakie pole nie przeszło, dlaczego i przykład poprawnej wartości.
To zmniejsza obciążenie wsparcia i przyspiesza czyszczenie danych.
Stwórz UI do przeglądu, zatwierdzeń i pracy masowej
Pipeline wzbogacania przynosi wartość, gdy ludzie mogą przejrzeć zmiany i pewnie wprowadzić aktualizacje do systemów downstream. UI powinien odpowiadać na pytanie: „co się stało, dlaczego i co robię dalej?” w sposób oczywisty.
Ekrany podstawowe do zaprojektowania
Profil klienta to baza. Pokaż kluczowe identyfikatory (e‑mail, domena, nazwa firmy), bieżące wartości pól i odznakę statusu wzbogacania (np. Nie wzbogacone, W toku, Wymaga przeglądu, Zatwierdzone, Odrzucone).
Dodaj oś historii zmian, która opisuje aktualizacje prostym językiem: „Wielkość firmy zaktualizowana z 11–50 na 51–200.” Każdy wpis powinien być klikalny, żeby zobaczyć szczegóły.
Dostarczaj sugestie scalenia przy wykryciu duplikatów. Wyświetl kandydatów obok siebie z rekomendowanym rekordem „zwycięzcą” i podglądem rezultatu scalenia.
Praca masowa odpowiadająca rzeczywistym operacjom
Większość zespołów działa w partiach. Włącz operacje masowe takie jak:
- Wzbogacanie wybranych rekordów (albo enqueue do nocnego przetworzenia)
- Zatwierdzanie/odrzucanie sugerowanych scaleni
- Eksport wyników (CSV) do audytów lub przeglądu offline
Używaj jasnego kroku potwierdzenia przy destrukcyjnych akcjach (scalanie, nadpisanie) z możliwością „undo”, jeśli to możliwe.
Szybkie wyszukiwanie, filtry i pochodzenie per pole
Dodaj globalne wyszukiwanie i filtry po e‑mailu, domenie, firmie, statusie i ocenie jakości.
Pozwól użytkownikom zapisywać widoki jak „Wymaga przeglądu” lub „Niskie zaufanie”.
Dla każdego wzbogaconego pola pokaż proweniencję: źródło, znacznik czasu i pewność.
Prosty panel „Dlaczego ta wartość?” buduje zaufanie i redukuje wymianę wiadomości.
Prowadzone przepływy dla nietechnicznych użytkowników
Utrzymuj decyzje proste i prowadzone: „Zaakceptuj sugerowaną wartość”, „Zachowaj obecną”, „Edytuj ręcznie”. Głębsze opcje trzymaj za przełącznikiem „Zaawansowane”, a nie jako domyślne.
Podstawy bezpieczeństwa, prywatności i zgodności
Wdróż czysty pipeline
Szkicuj procesy importu, normalizacji i walidacji w jednym projekcie i rozwijaj je krok po kroku.
Aplikacje wzbogacające dotykają wrażliwych identyfikatorów (e‑maile, telefony, dane firmowe) i często pobierają dane od stron trzecich. Traktuj bezpieczeństwo i prywatność jako cechy pierwszorzędne, nie jako coś „na później”.
Kontrola dostępu oparta na rolach (RBAC)
Zacznij od jasnych ról i domyślnych uprawnień najmniejszych:
- Admin: zarządzanie użytkownikami, rolami, konektorami, politykami retencji
- Ops: uruchamianie zadań wzbogacania, rozwiązywanie konfliktów, zatwierdzanie scalen
- Viewer: dostęp tylko do odczytu do raportów i wsparcia
Trzymaj uprawnienia szczegółowe (np. „eksport danych”, „widok PII”, „zatwierdź scalenia”) i oddziel środowiska, aby dane produkcyjne nie były dostępne w dev.
Chroń dane wrażliwe
Używaj TLS dla całego ruchu i szyfrowania w spoczynku dla baz i object storage.
Przechowuj klucze API w managerze sekretów (nie w plikach env w repozytorium), rotuj je regularnie i nadaj zakres per środowisko.
Jeśli wyświetlasz PII w UI, ustaw bezpieczne domy jak maskowanie pól (np. pokaż ostatnie 2–4 cyfry) i wymagaj wyraźnego uprawnienia do odkrycia pełnych wartości.
Zgoda i ograniczenia użycia danych
Jeśli wzbogacanie zależy od zgody lub warunków umownych, zakoduj te ograniczenia w przepływie pracy:
- Śledź źródło danych, cel i dozwolone użycia dla każdego pola
- Udokumentuj co przechowujesz i dlaczego (krótka wewnętrzna polityka jak /privacy lub /docs/data-handling pomaga)
- Unikaj zbierania pól, których nie potrzebujesz — mniej danych to mniejsze ryzyko
Audyt, retencja i usuwanie
Twórz ślad audytowy zarówno dla dostępu, jak i zmian:
- Loguj kto wyświetlił/wyeksportował rekordy
- Loguj kto zmienił co i kiedy (wartości przed/po, ID zadania, dostawca wzbogacania)
Wreszcie, wspieraj żądania prywatności narzędziami praktycznymi: polityki retencji, usuwanie rekordów i workflow „zapomnij”, które też usuwa kopie w logach, cache'ach i backupach tam, gdzie to możliwe (lub oznacza je do wygaśnięcia).
Monitorowanie, analityka i kontrolki operacyjne
Monitorowanie to nie tylko uptime — to sposób, w jaki utrzymujesz zaufanie do wzbogacania w miarę zmiany wolumenów, dostawców i reguł.
Traktuj każde uruchomienie wzbogacania jako mierzalne zadanie z sygnałami, które możesz śledzić w czasie.
Metryki, które naprawdę pomagają
Zacznij od małego zestawu metryk operacyjnych powiązanych z rezultatami:
- Przepustowość zadań (rekordy/min) i czas do ukończenia na uruchomienie
- Wskaźnik sukcesu vs współczynnik błędów, rozdzielony według typu błędu (walidacja, dopasowanie, dostawca)
- Latencja dostawcy (p50/p95) i timeouty per źródło
- Wskaźnik dopasowań (jak często pewnie przypisujemy wzbogacenie)
- Liczba zapobiegniętych duplikatów (ile scaleni uniknęłoby się bez zabezpieczeń)
Te liczby szybko odpowiadają: „Czy poprawiamy dane, czy tylko je przesuwamy?”.
Alerty i zabezpieczenia
Dodaj alerty, które reagują na zmiany, nie na hałas:
- Skoki w liczbie błędów lub rekordów w kwarantannie
- Zaległości w kolejce lub wolni konsumenci (sygnał zablokowanego pipeline'u)
- Wybuch błędów u dostawcy (429/5xx), podniesiona latencja lub zwiększona liczba timeoutów
Powiąż alerty z konkretnymi akcjami, jak pauzowanie dostawcy, obniżenie współbieżności lub przełączenie na dane z cache'u.
Panel administracyjny dla operatorów
Daj widok administracyjny dla ostatnich uruchomień: status, liczniki, ponowienia i listę kwarantannowanych rekordów z powodami.
Dołącz kontrolki „replay” i bezpieczne operacje masowe (ponów wszystkie timeouty dostawcy, uruchom ponownie tylko dopasowania).
Śledzenie z logami
Używaj strukturalnych logów i correlation ID, które śledzą pojedynczy rekord od początku do końca (ingest → dopasowanie → wzbogacanie → scalanie).
To znacznie przyspiesza support i debugowanie incydentów.
Playbooki incydentów i rollback
Napisz krótkie playbooki: co robić, gdy dostawca degraduje usługę, gdy spada wskaźnik dopasowań lub gdy duplikaty przebijają się przez mechanizmy.
Miej opcję rollbacku (np. cofnięcie scalenia przez pewien przedział czasowy) i udokumentuj to w /runbooks.
Testy, wdrożenie i plan iteracji
Testy i rollout to momenty, w których aplikacja wzbogacająca staje się bezpieczna do zaufania. Celem nie jest „więcej testów”, lecz pewność, że reguły dopasowań, scalania i walidacji zachowują się przewidywalnie przy brudnych, rzeczywistych danych.
Testuj najpierw ryzykowne elementy
Priorytetyzuj testy wokół logiki, która może cicho uszkodzić rekordy:
- Reguły dopasowań: testy jednostkowe dla dopasowań dokładnych, przybliżonych i złożonych (np. e‑mail + domena). Uwzględnij niemal‑duplikaty i zamienione pola.
- Wyniki scalenia: testuj priorytety pól (ranking źródeł), obsługę konfliktów i reguły „nie nadpisuj”.
- Walidacja skrajnych przypadków: źle sformatowane e‑maile, międzynarodowe formaty telefonów, brak kraju, zduplikowane identyfikatory, wartości „nieznane”.
Używaj syntetycznych zestawów danych (generowane imiona, domeny, adresy), aby walidować dokładność bez narażania prawdziwych danych klientów.
Trzymaj wersjonowany „golden set” z oczekiwanymi wynikami dopasowań/scalenia, by regresje były oczywiste.
Stopniowe wdrożenie, by zmniejszyć zakres szkód
Zacznij od małego zakresu, a potem rozszerzaj:
- Pilot: jeden zespół lub segment (np. tylko SMB leads)
- Ograniczone akcje: zacznij od „sugerowanych aktualizacji”, które wymagają zatwierdzenia przed zapisaniem do CRM
- Skalowanie: zwiększ wolumen rekordów, a potem włącz automatyczne zapisy dla niskiego ryzyka pól
Zdefiniuj metryki sukcesu przed startem (precyzja dopasowań, współczynnik zatwierdzeń, spadek ręcznych poprawek, czas wzbogacania).
Dokumentacja przepływów i checklista integracji
Stwórz krótkie dokumenty dla użytkowników i integratorów (udostępnione w produkcie lub w /pricing, jeśli funkcje są ograniczone). Zawieraj checklistę integracyjną:
- Metoda autoryzacji API, limity, i zachowanie ponawiania
- Pola wymagane dla żądań wzbogacania
- Webhooky/payloady zdarzeń (i wersjonowanie)
- Kody błędów i reguły „częściowego wzbogacenia”
- Oczekiwania co do logów audytu i retencji danych
Dla ciągłego ulepszania zaplanuj lekki rytm przeglądów: analizuj nieudane walidacje, częste ręczne nadpisania i niezgodności, aktualizuj reguły i dodawaj testy.
Praktyczne odniesienie do zacieśniania reguł: /blog/data-quality-checklist.
Budować czy przyspieszyć: praktyczna uwaga
Jeśli znasz już swoje przepływy, ale chcesz skrócić czas od specyfikacji do działającej aplikacji, rozważ użycie Koder.ai do wygenerowania wstępnej implementacji (React UI, serwisy Go, PostgreSQL). Zespoły często używają tego, aby szybko postawić UI przeglądu, przetwarzanie zadań i historię audytu — potem iterują z trybem planowania, snapshotami i rollbackami. Gdy potrzebujesz pełnej kontroli, możesz wyeksportować kod źródłowy i kontynuować w istniejącym pipeline'ie. Koder.ai oferuje plany free, pro, business i enterprise, co pozwala dopasować eksperymenty do wymagań produkcyjnych.