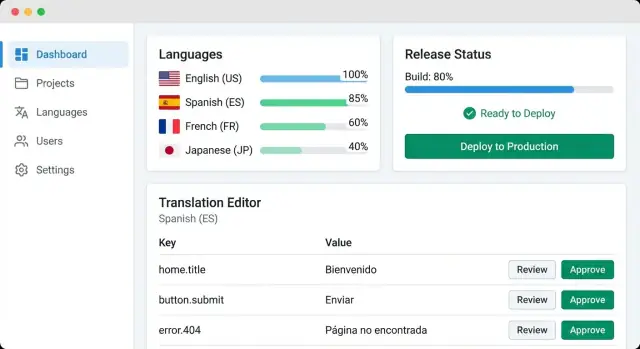
Co powinna rozwiązywać aplikacja webowa
Zarządzanie lokalizacją to codzienna praca nad tym, żeby teksty produktu (a czasem również obrazy, daty, waluty i reguły formatowania) zostały przetłumaczone, zrecenzowane, zatwierdzone i wypuszczone — bez psucia buildu lub dezorientowania użytkowników.
Dla zespołu produktowego celem nie jest „przetłumaczyć wszystko”. Chodzi o to, by każda wersja językowa była dokładna, spójna i aktualna wraz ze zmianami produktu.
Problemy, które rozwiązujesz
Większość zespołów zaczyna z dobrymi intencjami, a kończy w bałaganie:
- Rozproszone pliki locale w repozytoriach, folderach i arkuszach kalkulacyjnych, bez jednego źródła prawdy.
- Niespójne sformułowania (“Sign in” vs “Log in”), duplikaty stringów i różne tłumaczenia tego samego konceptu.
- Wolne cykle przeglądu, bo feedback pojawia się w mailach, komentarzach lub czatach.
- Niejasny status: nikt nie wie, co jest przetłumaczone, co przestarzałe, a co można bezpiecznie wypuścić.
- Ryzykowne kroki ręczne przy eksporcie/importcie plików prowadzą do brakujących kluczy, uszkodzonych placeholderów lub przypadkowych nadpisań.
Dla kogo jest ta aplikacja
Przydatna aplikacja do zarządzania lokalizacją wspiera wiele ról:
- Developerzy chcą wiarygodnych aktualizacji stringów, czytelnych diffów i mniej konfliktów merge.
- Tłumacze potrzebują kontekstu, wskazówek terminologicznych i skoncentrowanej kolejki zadań.
- Reviewerzy potrzebują przejrzystego procesu zatwierdzania i możliwości komentowania konkretnych stringów.
- PM-y i liderzy lokalizacji oczekują widoczności postępu i terminów, którym mogą zaufać.
Co zbudujesz na koniec
Zbudujesz MVP, które centralizuje stringi, śledzi status per locale i obsługuje podstawowy przegląd i eksport. Pełniejszy system doda automatyzacje (synchronizacja, QA checks), bogatszy kontekst oraz narzędzia takie jak glossary i pamięć tłumaczeń (TM).
Określ zakres i funkcje MVP
Zanim zaprojektujesz tabele czy ekrany, zdecyduj, za co faktycznie odpowiada twoja aplikacja do zarządzania lokalizacją. Wąski zakres sprawia, że pierwsza wersja jest użyteczna — i zapobiega późniejszym przebudowom.
Zacznij od listy typów treści
Tłumaczenia rzadko żyją w jednym miejscu. Wypisz, co potrzebujesz obsłużyć od pierwszego dnia:
- Stringi UI (etykiety, przyciski, komunikaty o błędach)
- E-maile transakcyjne (tematy i szablony)
- Fragmenty dokumentacji (krótkie bloki wielokrotnego użytku, nie całe strony dokumentacji)
- Strony marketingowe (często w rękach innego zespołu z innymi potrzebami przeglądu)
Ta lista pomoże uniknąć podejścia „jeden workflow dla wszystkiego”. Na przykład copy marketingowe może wymagać akceptacji, podczas gdy stringi UI potrzebują szybkiej iteracji.
Wybierz 1–2 formaty dla MVP, a potem rozszerzaj. Popularne opcje to JSON, YAML, PO i CSV. Praktyczny wybór dla MVP to JSON lub YAML (dla stringów aplikacji), a CSV tylko jeśli już polegasz na importach z arkuszy.
Bądź konkretny co do wymagań typu formy mnogiej, zagnieżdżonych kluczy i komentarzy. Te szczegóły wpływają na zarządzanie plikami locale oraz przyszłą niezawodność import/eksportu.
Wybierz locale i reguły fallback
Zdefiniuj język źródłowy (często en) i ustaw zachowanie fallbacku:
- Brakujące stringi fallbackują do en
- Opcjonalnie fallback do parent locale (np. pt-BR → pt → en)
Zdecyduj też, co oznacza „zrobione” dla locale: 100% przetłumaczone, zrecenzowane czy wypuszczone.
MVP vs funkcje późniejsze
Na MVP skup się na procesie przeglądu tłumaczeń i podstawowym workflow i18n: tworzenie/edycja stringów, przydzielanie zadań, przegląd i eksport.
Zaplanuj dodatki na później — screenshots/kontekst, glossary, pamięć tłumaczeń, oraz integracja MT — ale nie buduj ich, dopóki nie zweryfikujesz podstawowego workflow na rzeczywistej treści.
Zaprojektuj model danych
Aplikacja do tłumaczeń odnosi sukces lub porażkę dzięki modelowi danych. Jeśli encje i pola są jasne, wszystko inne — UI, workflow, integracje — staje się prostsze.
Zacznij od najważniejszych encji
Większość zespołów zasłoni 80% potrzeb małym zbiorem tabel/kolekcji:
- Project: produkt/aplikacja lub konkretna przestrzeń stringów.
- Locale: języki i warianty regionalne (np.
en, en-GB, pt-BR).
- Key: stabilny identyfikator używany w kodzie (
checkout.pay_button).
- Source string: tekst odniesienia (zwykle język bazowy) przypisany do klucza.
- Translation: zlokalizowana wartość dla klucza + locale.
- Version: snapshot dla wydań, importów lub rewizji plików.
Modeluj relacje wyraźnie: Project ma wiele Locales; Key należy do Project; Translation należy do Key i Locale.
Zakoduj workflow za pomocą pól statusu
Dodaj status do każdego tłumaczenia, by system prowadził ludzi:
draft → in_review → approvedblocked dla stringów, które nie powinny trafić do produkcji (przegląd prawny, brak kontekstu itp.)
Przechowuj zmiany statusów jako zdarzenia (lub w tabeli historii), aby później móc odpowiedzieć: „kto i kiedy zatwierdził?”.
Tłumaczenia potrzebują więcej niż czysty tekst. Zapisz:
- Placeholders (np.
{name}, %d) i informację, czy muszą pasować do źródła
- Maksymalna długość (dla przycisków i ograniczeń UI)
- Notatki kontekstowe (gdzie się pojawia, znaczenie, ton)
- Tagi (obszar funkcji, platforma, pilność)
Nie pomijaj pól audytu
Przynajmniej zachowuj: created_by, updated_by, znaczniki czasu i krótkie change_reason. To przyspiesza przeglądy i buduje zaufanie, gdy zespoły porównują, co jest w aplikacji, a co wyszło do produkcji.
Zaplanuj przechowywanie i wersjonowanie
Decyzje dotyczące przechowywania wpłyną na wszystko: UX edycji, szybkość importu/eksportu, porównywanie zmian oraz pewność wypuszczania.
Przechowywanie stringów: wiersz-na-klucz vs dokument-na-plik
Row-per-key (jeden wiersz DB na string na locale) świetnie nadaje się do dashboardów i workflow. Łatwo filtrować „brakujące po polsku” lub „do przeglądu”, przypisywać właścicieli i liczyć postęp. Minusem jest to, że odtworzenie pliku locale do eksportu wymaga grupowania i zachowania porządku oraz dodatkowych pól na ścieżkę pliku i namespace.
Document-per-file (przechowuj każdy plik locale jako dokument JSON/YAML) odwzorowuje sposób pracy z repozytorium. Eksport jest szybszy i łatwiej utrzymać formatowanie. Jednak wyszukiwanie i filtrowanie staje się trudniejsze, chyba że utrzymujesz też indeks kluczy, statusów i metadanych.
Wiele zespołów stosuje hybrydę: row-per-key jako źródło prawdy i generowane snapshoty plików do eksportu.
Wersjonowanie: rewizje per tłumaczenie i per wydanie
Zachowuj historię rewizji na poziomie jednostki tłumaczenia (klucz + locale). Każda zmiana powinna zapisać: poprzednią wartość, nową wartość, autora, znacznik czasu i komentarz. To ułatwia przeglądy i rollbacki.
Osobno śledź snapshoty wydania: „co dokładnie wyszło w v1.8”. Snapshot może być tagiem wskazującym spójny zestaw zatwierdzonych rewizji we wszystkich locale. To zapobiega późnym edycjom, które potajemnie zmieniają wypuszczoną wersję.
Plural i reguły dotyczące rodzaju
Nie traktuj „plurala” jako pojedynczego booleanu. Użyj ICU MessageFormat lub kategorii CLDR (np. one, few, many, other), aby języki takie jak polski czy arabski nie były dopasowywane do reguł angielskich.
Dla rodzaju i innych wariantów modeluj je jako warianty tej samej wiadomości zamiast oddzielnych, ad-hoc kluczy, by tłumacze widzieli pełen kontekst.
Wyszukiwanie i filtry, które skalują
Wdrożysz pełnotekstowe wyszukiwanie po kluczu, source text, tłumaczeniu i notatkach deweloperskich. Połącz to z filtrami odpowiadającymi realnej pracy: status (new/translated/reviewed), tagi, plik/namespace i missing/empty.
Indeksuj te pola wcześnie — wyszukiwanie to funkcja, z której ludzie korzystają setki razy dziennie.
Wybierz architekturę, która skaluje
Aplikacja do zarządzania lokalizacją zwykle zaczyna prosto — wrzuć plik, edytuj stringi, pobierz go z powrotem. Komplikuje się, gdy dodasz wiele produktów, locale, częste wydania i stały strumień automatyzacji (sync, QA, MT, przeglądy).
Najłatwiej pozostać elastycznym, separując odpowiedzialności od początku.
Praktyczny stack
Typowa, skalowalna konfiguracja to API + web UI + zadania w tle + baza danych:
- Web UI: edytor tłumaczeń, ekrany przeglądu i ustawienia projektu.
- API: pojedyncze źródło prawdy używane przez UI, narzędzia CLI i integracje.
- Zadania w tle: długotrwałe operacje (import/eksport, skany QA, sync), które nie powinny blokować UI.
- Baza danych: przechowuje projekty, klucze, tłumaczenia, historię i uprawnienia.
Takie rozdzielenie ułatwia dodanie workerów do cięższych zadań bez przebudowy całej aplikacji.
Jeśli chcesz szybciej osiągnąć działającą wersję, platformy do szybkiego prototypowania jak Koder.ai mogą pomóc w wygenerowaniu szkieletu UI (React), API (Go) i schematu PostgreSQL z uporządkowanej specyfikacji — a potem wyeksportować kod, gdy będziesz gotów przejąć repo i deployment.
Jak strukturujesz API
Trzymaj API wokół kilku głównych zasobów:
- Projects: pojemnik dla aplikacji/produktu.
- Locales: języki/regiony aktywowane per project.
- Keys: stabilne identyfikatory (np.
checkout.button.pay).
- Translations: tekst per key+locale, wraz ze statusem (draft/approved), autorem i znacznikami czasu.
Projektuj endpointy tak, by obsługiwały zarówno edycję przez ludzi, jak i automatyzację. Na przykład listowanie kluczy powinno akceptować filtry takie jak „missing in locale”, „changed since” lub „needs review”.
Zadania w tle, których będziesz potrzebować
Traktuj automatyzację jako pracę asynchroniczną. Kolejka zwykle obsługuje:
- Importy (parsowanie plików locale, walidacja, tworzenie/aktualizacja kluczy)
- Eksporty (budowanie pakietów locale do wydania)
- QA checks (placeholders, długość, HTML, zabronione terminy)
- Sync jobs (pull/push do Git, CI lub innych systemów)
Spraw, by zadania były idempotentne (bezpieczne do ponowienia) i zapisuj logi zadań per projekt, aby zespoły mogły samodzielnie diagnozować niepowodzenia.
Podstawy wydajności ważne na początku
Nawet małe zespoły mogą wygenerować duże zbiory danych. Dodaj paginację dla list (klucze, historia, zadania), cache’uj popularne odczyty (statystyki projektu i locale) i stosuj rate limiting, aby chronić endpointy import/eksport i publiczne tokeny.
To są nudne szczegóły, które zapobiegają spowolnieniu systemu właśnie wtedy, gdy adopcja rośnie.
Dodaj uwierzytelnianie, role i uprawnienia
Jeśli twoja aplikacja przechowuje source strings i historię tłumaczeń, kontrola dostępu nie jest opcjonalna — to sposób, by zapobiec przypadkowym edycjom i zachować rozliczalność decyzji.
Wybierz role odpowiadające rzeczywistej pracy
Prosty zestaw ról pokrywa większość zespołów:
- Admin: zarządza ustawieniami organizacji, locale, integracjami i dostępem użytkowników.
- Developer: edytuje source strings, tworzy klucze, uruchamia importy/eksporty.
- Translator: edytuje tłumaczenia w przypisanych locale.
- Reviewer: zatwierdza lub odrzuca tłumaczenia i blokuje ostateczne brzmienie.
- Viewer: dostęp tylko do odczytu dla interesariuszy.
Zdefiniuj uprawnienia (nie tylko tytuły)
Traktuj każdą akcję jako osobne uprawnienie, by móc ewoluować system później. Typowe reguły:
- Edit source: Admin, Developer tylko (zapobiega tłumaczom zmieniać znaczenia).
- Approve: Reviewer (opcjonalnie Admin) by wymusić jasny proces zatwierdzania.
- Export: Developer/Admin lub Reviewer, jeśli to on zarządza wydaniami.
- Manage locales: tylko Admin (dodanie locale wpływa na workflow i budżety).
- Edit translations: Translator/Reviewer w przypisanych locale i projektach.
To dobrze mapuje się do systemu zarządzania tłumaczeniami, a jednocześnie pozostaje elastyczne dla wykonawców zewnętrznych.
Logowanie: SSO vs email
Jeśli firma używa Google Workspace, Azure AD lub Okta, SSO zmniejsza ryzyko haseł i upraszcza offboarding. Logowanie e-mail/hasło działa dla małych zespołów — wymagaj silnych haseł i flow resetu.
Podstawy bezpieczeństwa sesji
Używaj bezpiecznych, krótkotrwałych sesji (HTTP-only cookies), ochrony CSRF, limitów żądań i 2FA tam, gdzie to możliwe.
Logi aktywności dla rozliczalności
Zapisuj, kto zmienił co i kiedy: edycje, zatwierdzenia, zmiany locale, eksporty i aktualizacje uprawnień. Połącz log z możliwością „undo” przez historię wersji, aby rollbacki były bezpieczne i szybkie.