Wyjaśnij cele i dla kogo jest aplikacja
Zanim wybierzesz funkcje lub stos technologiczny, ustal, co w Twojej organizacji oznacza „runbook”. Niektóre zespoły używają runbooków jako playbooków do reagowania na incydenty (wysokie ciśnienie, krytyczny czas). Inne rozumieją je jako standardowe procedury operacyjne (powtarzalne zadania), zadania konserwacyjne lub workflow obsługi klienta. Jeśli nie zdefiniujesz zakresu na początku, aplikacja będzie próbowała obsługiwać każdy typ dokumentu — i ostatecznie nie spełni dobrze żadnego z nich.
Określ typy runbooków (i jak wygląda „dobry”)
Zapisz kategorie, które spodziewasz się przechowywać w aplikacji, z krótkim przykładem każdej:
- Playbooki incydentowe: kroki „skoków” przy wzroście latencji API, ścieżki eskalacji, instrukcje rollbacku
- SOP-y: „Provision a new customer”, „Rotate credentials”, „Weekly capacity check”
- Zadania konserwacyjne: „Patchowanie bazy danych”, „Odnawianie certyfikatów”
Zdefiniuj też minimalne standardy: pola wymagane (owner, dotknięte usługi, data ostatniego przeglądu), co oznacza „zrobione” (wszystkie kroki odhaczone, notatki zapisane) oraz czego unikać (długie akapity trudne do przeskanowania).
Zidentyfikuj docelowych użytkowników i ich ograniczenia
Wypisz głównych użytkowników i czego potrzebują w danym momencie:
- Inżynierowie na dyżurze: szybkość, jasność, minimalne tarcie przy wielozadaniowości
- Operacje/wsparcie: spójne procesy, mniej przekazań, jasne definicje
- Menedżerowie/liderzy: widoczność pokrycia, rytm przeglądów i własność
Różni użytkownicy optymalizują różne rzeczy. Projektowanie pod przypadek on-call zwykle wymusza, by interfejs był prosty i przewidywalny.
Ustal rezultaty i mierzalne wskaźniki sukcesu
Wybierz 2–4 główne cele, np. szybsze reagowanie, spójna realizacja i prostsze przeglądy. Następnie przypisz mierzalne wskaźniki, które możesz śledzić:
- Czas znalezienia właściwego runbooka (search-to-open)
- Wskaźnik ukończenia dla zadań cyklicznych
- Czas do złagodzenia incydentu, kiedy playbook istnieje vs. gdy go brak
- Rytm przeglądów: % runbooków zrewidowanych w ciągu ostatnich 90 dni
Te decyzje powinny kierować późniejszymi wyborami, od nawigacji po uprawnienia.
Zbierz wymagania z rzeczywistych przepływów operacyjnych
Zanim wybierzesz stack technologiczny lub naszkicujesz ekrany, obserwuj, jak operacje działają, gdy coś się psuje. Aplikacja do zarządzania runbookami odnosi sukces, gdy pasuje do prawdziwych nawyków: gdzie ludzie szukają odpowiedzi, co jest „wystarczająco dobre” podczas incydentu i co jest ignorowane, gdy wszyscy są przeciążeni.
Zacznij od problemu, który chcesz rozwiązać
Rozmawiaj z inżynierami na dyżurze, SRE, wsparciem i właścicielami usług. Proś o konkretne, niedawne przykłady, nie ogólne opinie. Typowe bolączki to rozproszone dokumenty w wielu narzędziach, przestarzałe kroki niezgodne z produkcją oraz niejasna własność (nikt nie wie, kto powinien zaktualizować runbook po zmianie).
Zapisz każde zagadnienie jako krótką historię: co się stało, co zespół próbował, co poszło nie tak i co by pomogło. Te historie staną się później kryteriami akceptacji.
Skompletuj inwentarz istniejących źródeł i potrzeb migracji
Wypisz, gdzie dziś żyją runbooki i SOP-y: wiki, Google Docs, repozytoria Markdown, PDF, komentarze w ticketach i postmortemy incydentów. Dla każdego źródła zanotuj:
- Format i strukturę (tabele, checklisty, zrzuty ekranu, linki)
- Wolumen i historię, którą trzeba zachować
- Wymagane metadane (usługa, środowisko, severity, właściciel)
To powie Ci, czy potrzebujesz masowego importera, prostego kopiuj-wklej migracji, czy obu.
Zmapuj end-to-end przepływ runbooka
Zapisz typowy cykl życia: create → review → use → update. Zwróć uwagę, kto uczestniczy przy każdym kroku, gdzie następują zatwierdzenia i co wywołuje aktualizacje (zmiany w usłudze, wnioski z incydentów, kwartalne przeglądy).
Zidentyfikuj oczekiwania dotyczące zgodności i audytu
Nawet jeśli nie jesteś w branży regulowanej, zespoły często potrzebują odpowiedzi na pytanie: „kto zmienił co, kiedy i dlaczego”. Określ minimalne wymagania śladu audytu wcześnie: podsumowania zmian, tożsamość zatwierdzającego, znaczniki czasu i możliwość porównania wersji podczas wykonania playbooka incydentowego.
Zaprojektuj model danych dla runbooków i wersji
Aplikacja runbookowa odnosi sukces lub porażkę w zależności od tego, czy model danych odzwierciedla sposób pracy zespołów operacyjnych: wiele runbooków, współdzielone elementy, częste edycje i wysoka ufność w „to, co było prawdą w danym momencie”. Zacznij od zdefiniowania podstawowych obiektów i ich relacji.
Obiekty podstawowe
Co najmniej zamodeluj:
- Runbook: tytuł, podsumowanie, status (draft/published/archived), flagi severity/use-case, last_reviewed_at.
- Step: uporządkowane elementy w runbooku (z opcjonalnymi gałęziami decyzyjnymi).
- Tag: lekkie etykietowanie do wyszukiwania i filtrowania.
- Service: do czego runbook się odnosi (payments, API, data pipeline).
- Owner: osoba/zespoł odpowiedzialny za poprawność.
- Version: niemodyfikowalna migawka runbooka w danym momencie.
- Execution: zarejestrowany „przebieg” runbooka podczas incydentu lub rutynowego zadania.
Relacje odzwierciedlające rzeczywistość operacji
Runbooki rzadko żyją samodzielnie. Zaplanuj linki, aby aplikacja mogła wyświetlać właściwy dokument pod presją:
- Runbook ↔ Service (wiele-do-wielu): jedna usługa może mieć wiele runbooków; runbook może dotyczyć wielu usług.
- Runbook ↔ Incident type / alert rule: przechowuj odniesienia do identyfikatorów alertów lub kategorii incydentów, by integracje mogły sugerować właściwy playbook.
- Runbook ↔ Tags: dla kwestii przekrojowych (database, customer-impacting, rollback).
Wersjonowanie: draft vs. published
Traktuj wersje jako append-only. Runbook wskazuje na current_draft_version_id i current_published_version_id.
- Edycja tworzy nowe wersje robocze.
- Publikacja „promuje” wersję roboczą do wersji publikowanej (tworząc nową niemodyfikowalną wersję publikowaną).
- Zachowuj stare wersje dla audytu i postmortem; rozważ politykę retencji tylko dla wersji roboczych, nie dla opublikowanych.
Przechowywanie bogatej treści i załączników
Dla kroków przechowuj treść jako Markdown (proste) lub jako strukturalne JSON blocks (lepsze dla checklist, calloutów i szablonów). Trzymaj załączniki poza bazą danych: przechowuj metadane (nazwa pliku, rozmiar, content_type, storage_key), a pliki w object storage.
Ta struktura ustawia Cię do wiarygodnych śladów audytu i płynnego trybu wykonania później.
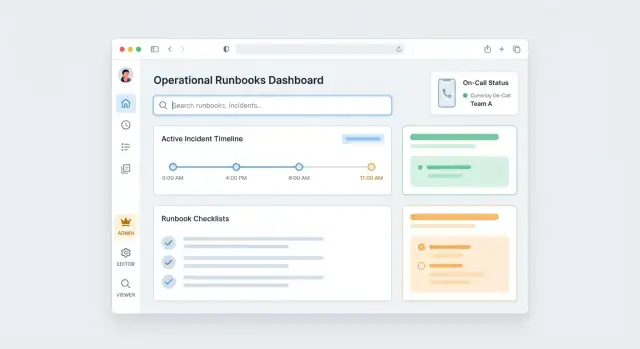
Zaplanuj zestaw funkcji i ścieżki użytkowników
Aplikacja runbookowa odnosi sukces, gdy pozostaje przewidywalna pod presją. Zacznij od zdefiniowania minimum przydatnego produktu (MVP), który obsługuje podstawową pętlę: napisz runbook, opublikuj go i niezawodnie używaj w pracy.
MVP: co jest minimalnie potrzebne
Utrzymaj pierwszy release ciasny:
- Lista / biblioteka: przeglądaj runbooki według usługi, zespołu i tagów.
- Widok: czysta strona tylko do odczytu, szybkie ładowanie i dobra do druku.
- Utwórz: zacznij od zera z tytułem, podsumowaniem i uporządkowanymi krokami.
- Edytuj: wprowadzaj zmiany w wersji roboczej bez wpływu na wersję publikowaną.
- Publikuj: wyraźna akcja, która czyni wersję „oficjalną”.
- Szukaj: pełnotekstowe wyszukiwanie w tytułach, podsumowaniach i tekstach kroków.
Jeśli nie potrafisz szybko dostarczyć tych sześciu rzeczy, dodatkowe funkcje nie będą miały znaczenia.
„Miłe do posiadania” później (nie blokuj pierwszego release'u)
Gdy podstawy będą stabilne, dodaj możliwości poprawiające kontrolę i wgląd:
- Szablony dla typowych incydentów i rutynowych zadań.
- Zatwierdzenia i recenzenci dla systemów wysokiego ryzyka.
- Executions (checklisty) do rejestrowania, co zostało zrobione i kiedy.
- Analityka jak najczęściej używane runbooki, przestarzała treść i zapytania bez wyników.
Układ: trzy główne przestrzenie pracy
Dopasuj UI do sposobu myślenia operatorów:
- Runbook Library: szybkie znajdowanie i filtrowanie.
- Editor: tworzenie, poprawki i podgląd widoku publikowanego.
- Execution View: skoncentrowany tryb „wykonaj kroki” z śledzeniem postępów.
Prosta mapa stron (przewidywalna nawigacja)
- /runbooks (biblioteka)
- /runbooks/new
- /runbooks/:id (widok publikowany)
- /runbooks/:id/edit (edytor wersji roboczej)
- /runbooks/:id/versions
- /runbooks/:id/execute (tryb wykonania)
- /search
Projektuj ścieżki użytkowników wokół ról: autor tworzący i publikujący, responder wyszukujący i wykonujący, oraz menedżer przeglądający, co jest aktualne, a co przestarzałe.
Zbuduj edytor runbooków, który utrzymuje kroki jasne i powtarzalne
Edytor powinien sprawiać, że „właściwy sposób” pisania procedur jest najprostszą drogą. Jeśli ludzie mogą szybko tworzyć czytelne, spójne kroki, runbooki pozostaną użyteczne w stresie i przy braku czasu.
Wybierz styl edytora dopasowany do użytkowników
Są trzy popularne podejścia:
- Edytor Markdown: szybki dla doświadczonych operatorów, świetny dla pracy głównie z klawiatury, ale łatwo wpaść w niejednolitą strukturę.
- Edytor blokowy: strukturalna treść (kroki, callouty, linki) z dobrą czytelnością; zwykle najlepszy balans dla zespołów mieszanych.
- Kroki jako formularze: każdy krok to formularz z określonymi polami (akcja, oczekiwany rezultat, właściciel, linki). To daje najbardziej spójny wynik i jest idealne, gdy potrzebujesz rygoru.
Wiele zespołów zaczyna od edytora blokowego i dodaje ograniczenia formularzowe dla krytycznych typów kroków.
Modeluj kroki jako obiekty pierwszej klasy
Zamiast jednego długiego dokumentu, przechowuj runbook jako uporządkowaną listę kroków o typach takich jak:
- Text (kontekst)
- Command (z przyciskiem kopiuj i opcjonalnym „expected output”)
- Link (do dashboardów, ticketów, dokumentów)
- Decision (gałęzie if/then)
- Checklist (wiele podpunktów)
- Caution note (ostrzeżenia o wysokiej widoczności)
Typowane kroki pozwalają na spójne renderowanie, wyszukiwanie, bezpieczne ponowne użycie i lepsze UX w trybie wykonania.
Dodaj zabezpieczenia, które zapobiegają „tajemniczym krokom”
Zabezpieczenia utrzymują treść czytelną i wykonalną:
- Pola obowiązkowe (np. każdy krok typu command musi mieć pole command i środowisko)
- Walidacja (zepsute linki, puste placeholdery, brakujące prerekwizyty)
- Podgląd zgodny z trybem wykonania, aby autor widział, co responder zobaczy
- Zasady formatowania (ograniczenie nagłówków, standaryzacja nazw jak „Verify…”, „Rollback…”, „Escalate…")
Ułatw ponowne użycie
Wspieraj szablony dla typowych wzorców (triage, rollback, post-incident checks) i akcję Duplicate runbook, która kopiuje strukturę, jednocześnie prosząc użytkownika o aktualizację kluczowych pól (nazwa usługi, kanał dyżurny, dashboardy). Ponowne użycie redukuje wariancję — a wariancja to źródło błędów.
Dodaj zatwierdzenia, właścicielstwo i przypomnienia o przeglądach
Wygeneruj szkielet aplikacji
Uruchom interfejs React z backendem Go + PostgreSQL bez pracy z boilerplate.
Runbooki są użyteczne tylko wtedy, gdy ludzie im ufają. Lekka warstwa governance — wyraźni właściciele, przewidywalne ścieżki zatwierdzeń i cykliczne przeglądy — utrzymuje treść aktualną bez zamieniania każdej zmiany w wąskie gardło.
Zaprojektuj prosty flow przeglądu
Zacznij od małego zestawu statusów dopasowanych do pracy zespołów:
- Draft: w trakcie pisania lub aktualizacji
- In review: oczekuje na opinie konkretnych recenzentów
- Approved: gotowe, ale niekoniecznie widoczne dla wszystkich (opcjonalna faza buforowa)
- Published: wersja używana podczas incydentów i rutynowej pracy
Uczyń przejścia widocznymi w UI (np. „Request review”, "Approve & publish"), i zapisuj, kto wykonał każdą akcję i kiedy.
Dodaj właścicieli i terminy przeglądów
Każdy runbook powinien mieć przynajmniej:
- Primary owner: odpowiada za poprawność
- Backup owner: zapewnia pokrycie podczas urlopów/rotacji
- Review due date (lub „review every X days”): aby runbooki nie gniły w ciszy
Traktuj własność jak koncepcję on-call: właściciele zmieniają się razem ze strukturą zespołów, a te zmiany powinny być widoczne.
Wymagaj podsumowań zmian przy edycjach
Gdy ktoś aktualizuje opublikowany runbook, poproś o krótkie change summary i (jeśli to istotne) wymagany komentarz typu „Dlaczego zmieniamy ten krok?”. To tworzy kontekst dla recenzentów i zmniejsza liczbę pętli zwrotnych przy zatwierdzaniu.
Planuj powiadomienia bez uzależniania od jednego dostawcy
Przypomnienia o przeglądach działają tylko wtedy, gdy ludzie je otrzymują. Wysyłaj powiadomienia „review requested” i „review due soon”, ale unikaj hardkodowania e-maila czy Slacka. Zdefiniuj prosty interfejs powiadomień (zdarzenia + odbiorcy), a potem podłącz dostawców — Slack dziś, Teams jutro — bez przepisywania logiki core.
Obsłuż uwierzytelnianie i uprawnienia bezpiecznie
Runbooki często zawierają informacje, które nie powinny być szeroko udostępniane: wewnętrzne URL-e, kontakty eskalacyjne, polecenia odzyskiwania i czasem wrażliwe dane konfiguracyjne. Traktuj auth i autoryzację jako kluczową funkcję, nie jako późniejsze utwardzanie.
Zacznij od prostego RBAC
Przynajmniej wdroż role:
- Viewer: może czytać runbooki i używać trybu wykonania.
- Editor: może tworzyć i aktualizować runbooki, do których ma dostęp.
- Admin: zarządza uprawnieniami, zespołami/usługami i ustawieniami globalnymi.
Utrzymuj spójność ról w całym UI (przyciski, dostęp do edytora, zatwierdzenia), aby użytkownicy nie musieli zgadywać, co im wolno.
Zakresuj dostęp według zespołu lub usługi (opcjonalnie według runbooka)
Większość organizacji porządkuje operacje według zespołu lub usługi, a uprawnienia powinny iść tym tropem. Praktyczny model:
- Użytkownicy należą do jednego lub więcej zespołów.
- Runbooki są oznaczone tagiem usługi (własność zespołu).
- Uprawnienia nadawane są na poziomie zespołu/usługi.
Dla treści wysokiego ryzyka dodaj opcjonalne przesłonięcie na poziomie runbooka (np. „tylko Database SREs mogą edytować ten runbook”). To utrzymuje system znośnym, wspierając wyjątki.
Chroń wrażliwe kroki
Niektóre kroki powinny być widoczne tylko dla mniejszej grupy. Wspieraj sekcje ograniczone, jak „Szczegóły wrażliwe”, które wymagają podwyższonych uprawnień do odsłonięcia. Preferuj redakcję („ukryte dla viewerów”) zamiast usuwania treści, aby runbook pozostał spójny pod presją.
Utrzymuj elastyczność uwierzytelniania
Nawet jeśli zaczynasz od email/hasła, projektuj warstwę auth tak, by móc dodać SSO później (OAuth, SAML). Użyj podejścia pluginowego dla dostawców tożsamości i przechowuj stabilne identyfikatory użytkowników, żeby przełączenie na SSO nie złamało własności, zatwierdzeń ani śladu audytu.
Ułatw odnajdywanie runbooków pod presją
Szybkie szkielety integracji
Określ kontrakty webhooków w czacie i wygeneruj punkt końcowy integracji dla alertów i incydentów.
Gdy coś jest zepsute, nikt nie chce przeglądać dokumentacji. Chcą właściwy runbook w kilka sekund, nawet jeśli pamiętają tylko mgliste określenie z alertu lub wiadomości od kolegi. Znajdowalność to funkcja produktu, nie dodatek.
Zbuduj wyszukiwanie, które zachowuje się jak mózg on-call
Zaimplementuj jedno pole wyszukiwania, które skanuje więcej niż tytuły. Indeksuj tytuły, tagi, usługę oraz treść kroków (w tym komendy, URL-e i fragmenty logów). Ludzie często wklejają fragment logu lub tekst alertu — wyszukiwanie na poziomie kroków zamienia to w trafienie.
Wspieraj tolerancyjne dopasowania: częściowe słowa, literówki i zapytania z prefiksem. Zwracaj wyniki z wyróżnionymi fragmentami, aby użytkownicy mogli potwierdzić trafność bez otwierania wielu kart.
Dodaj filtry, które natychmiast odcinają szum
Wyszukiwanie jest najszybsze, gdy użytkownicy mogą zawęzić kontekst. Zapewnij filtry odzwierciedlające sposób myślenia zespołów operacyjnych:
- Service (lub komponent)
- Severity (poziomy SEV, priorytet)
- Environment (prod/stage/dev, region)
- Team/owner
- Data ostatniego przeglądu (lub „review overdue”)
Uczyń filtry trwałymi między sesjami dla użytkowników on-call i pokaż aktywne filtry wyraźnie, by było jasne, dlaczego wyniki są ograniczone.
Naucz system synonimów i języka incydentów
Zespoły nie używają jednego słownika. „DB”, „database”, „postgres”, „RDS” i wewnętrzny skrót mogą znaczyć to samo. Dodaj lekki słownik synonimów, który można aktualizować bez redeployu (UI admina lub konfiguracja). Używaj go w czasie zapytania (rozszerzanie terminów) i opcjonalnie przy indeksowaniu.
Również zbieraj powszechne terminy z tytułów incydentów i etykiet alertów, aby synonimy były zgodne z rzeczywistością.
Projektuj widok runbooka pod kątem skanowania, nie czytania
Strona runbooka powinna być skondensowana i łatwa do przeskanowania: jasne podsumowanie, prerekwizyty i spis treści kroków. Pokaż kluczowe metadane na górze (usługa, zastosowanie środowiskowe, data ostatniego przeglądu, właściciel) i trzymaj kroki krótkie, numerowane i zwijalne.
Dodaj przycisk „kopiuj” dla komend i URL-i oraz kompaktowy obszar „powiązane runbooki” do szybkiego przejścia do typowych następnych kroków (np. rollback, weryfikacja, eskalacja).
Zaimplementuj tryb wykonania dla incydentów i rutynowych zadań
Tryb wykonania to miejsce, gdzie runbooki przestają być „dokumentacją” i stają się narzędziem, na którym można polegać pod presją czasu. Traktuj go jako skoncentrowany, wolny od rozproszeń widok prowadzący od pierwszego do ostatniego kroku, jednocześnie rejestrując, co faktycznie się wydarzyło.
Skoncentrowane UI: kroki, status i czas
Każdy krok powinien mieć jasny status i prosty zestaw kontroli:
- Checkbox lub Oznacz jako wykonane (plus Pomiń, gdy stosowne)
- Stany kroków: Not started / In progress / Blocked / Done
- Opcjonalne timery: licznik przebiegu (od startu) i timery na poziomie kroku (czas spędzony)
Małe udogodnienia pomagają: przypinanie bieżącego kroku, pokazanie „następny”, trzymanie długich kroków czytelnymi dzięki zwijanym szczegółom.
Notatki, linki i dowody — uchwycone w trakcie
Podczas wykonywania operatorzy potrzebują dodawać kontekst bez opuszczania strony. Pozwól na dodawanie per-krok:
- Notatek wolnego tekstu (co widziałeś, co próbowałeś, dlaczego wybrałeś ścieżkę)
- Linków do dashboardów, ticketów lub wątków czatu
- Załączników dowodowych (zrzuty ekranu, logi, output z komend)
Te dodatki powinny być automatycznie opatrzone znacznikiem czasu i zachowane nawet, jeśli przebieg zostanie wstrzymany i wznowiony.
Gałęzie i ścieżki eskalacji
Rzeczywiste procedury nie są zawsze liniowe. Wspieraj kroki rozgałęziające (if/then), aby runbook mógł dostosować się do warunków (np. „Jeśli error rate > 5%, to…”). Dodaj też explicite akcje Stop and escalate, które:
- Oznaczają przebieg jako eskalowany/zablokowany
- Pytają, kogo powiadomiono i dlaczego
- Opcjonalnie generują podsumowanie przekazania dla następnego respondenta
Przechowuj historię wykonania do nauki
Każdy przebieg powinien tworzyć niemodyfikowalny rekord wykonania: użyta wersja runbooka, znaczniki czasu kroków, notatki, dowody i ostateczny wynik. To staje się źródłem prawdy dla post-incident review i ulepszeń runbooka bez polegania na pamięci.
Dodaj ślady audytu i historię zmian, którym można ufać
Kiedy runbook się zmienia, pytanie podczas incydentu nie brzmi „co jest najnowsze?” — tylko „czy możemy temu zaufać i jak do tego doszło?”. Jasny ślad audytu zamienia runbooki w wiarygodne zapisy operacyjne, a nie edytowalne notatki.
Co logować (i dlaczego to ważne)
Przynajmniej loguj każdą znaczącą zmianę z kto, co i kiedy. Zrób krok dalej i przechowuj snapshots before/after treści (lub strukturalny diff), aby recenzenci mogli zobaczyć dokładnie, co zmieniono.
Rejestruj też zdarzenia poza edycją:
- Publikacje: draft → published, published → archived, rollbacky
- Decyzje zatwierdzające: kto zatwierdził/odrzucił, znacznik czasu, opcjonalny komentarz
- Zmiany własności: przekazanie właściciela lub zespołu
To tworzy linię czasu, na której możesz polegać podczas przeglądów pokontrolnych i kontroli zgodności.
Widoki audytu, które działają pod presją
Daj użytkownikom zakładkę Audit przy każdym runbooku pokazującą chronologiczny strumień zmian z filtrami (edytor, zakres dat, typ zdarzenia). Dodaj akcje „zobacz tę wersję” i „porównaj z aktualną”, aby respondenci mogli szybko potwierdzić, czy wykonują właściwą procedurę.
Jeśli organizacja tego wymaga, dodaj opcje eksportu jak CSV/JSON dla audytów. Pilnuj uprawnień do eksportów i ich zakresu (pojedynczy runbook lub okno czasowe).
Zasady retencji i odporność na manipulacje
Zdefiniuj zasady retencji zgodne z wymaganiami: np. pełne migawki przez 90 dni, następnie przechowywanie diffów i metadanych przez 1–7 lat. Przechowuj zapisy audytu append-only, ogranicz usuwanie i rejestruj każde administracyjne obejście jako audytowalne zdarzenie.
Połącz aplikację z alertami, incydentami i narzędziami czatu
Użyj własnej domeny
Umieść bibliotekę runbooków pod zapamiętywalną domeną dla zespołu podczas pracy pod presją.
Twoje runbooki stają się znacznie przydatniejsze, gdy są o jeden klik od alertu, który uruchomił działanie. Integracje zmniejszają też przełączanie kontekstu podczas incydentów, gdy ludzie mają podwyższone napięcie i brak czasu.
Zacznij od prostego kontraktu integracyjnego (webhooki + API)
Większość zespołów pokryje 80% potrzeb przy dwóch wzorcach:
- Incoming webhooks z narzędzi alertujących/incydentowych do Twojej aplikacji (utwórz lub zaktualizuj „incident context”, zasugeruj runbooki).
- Outgoing webhooks lub wywołania API z aplikacji do tych narzędzi (opublikuj link do wybranego runbooka, aktualizacje statusu i kluczowe decyzje).
Minimalny przychodzący payload może wyglądać tak:
{
"service": "payments-api",
"event_type": "5xx_rate_high",
"severity": "critical",
"incident_id": "INC-1842",
"source_url": "https://…"
}
Deep linki: prowadź responderów prosto do właściwego runbooka
Projektuj schemat URL tak, aby alert mógł wskazać najlepsze dopasowanie, zwykle przez service + event type (lub tagi takie jak database, latency, deploy). Na przykład:
- Link do konkretnego runbooka:
/runbooks/123
- Link do trybu wykonania z kontekstem:
/runbooks/123/execute?incident=INC-1842
- Link do presetów wyszukiwania:
/runbooks?service=payments-api&event=5xx_rate_high
To ułatwia systemom alertującym dołączenie URL-a do powiadomień i pozwala ludziom wylądować na właściwej checkliście bez dodatkowego szukania.
Powiadomienia czatowe i udostępnianie podczas incydentu
Podłącz Slack lub Microsoft Teams, aby responderzy mogli:
- Opublikować wybrany runbook do kanału incydentu
- Udostępnić krótkie podsumowanie („Co wykonujemy, kto jest właścicielem, aktualny krok”)
- Utrzymać runbook widoczny, gdy podejmowane są decyzje
Jeśli masz już dokumentację integracji, odnoś ją z UI (np. "/docs/integrations") i eksponuj konfigurację tam, gdzie zespoły jej oczekują (strona ustawień plus przycisk testowy).
Wdróż, zabezpiecz i iteruj bez spowalniania operacji
System runbooków jest częścią Twojej siatki bezpieczeństwa operacyjnego. Traktuj go jak usługę produkcyjną: wdróż przewidywalnie, chroń przed typowymi awariami i ulepszaj w małych, niskoryzykownych krokach.
Hosting, backupy i odzyskiwanie po awarii
Zacznij od modelu hostingu, którym zespół ops potrafi zarządzać (platforma zarządzana, Kubernetes lub proste VM). Cokolwiek wybierzesz, udokumentuj to w osobnym runbooku.
Backupy powinny być automatyczne i testowane. Nie wystarczy „robić snapshoty” — musisz mieć pewność, że przywrócisz:
- Regularne backupy bazy danych (i przed dużymi aktualizacjami)
- Zaszyfrowane kopie z ograniczonym dostępem
- Rutynowy test przywracania (np. miesięczny) w osobnym środowisku
Dla DR określ cele wcześniej: ile danych możesz stracić (RPO) i jak szybko aplikacja ma wrócić (RTO). Trzymaj lekki checklist DR obejmujący DNS, sekrety i zweryfikowaną procedurę przywracania.
Podstawy wydajności zapobiegające tarciu
Runbooki są najbardziej wartościowe pod presją, więc dąż do szybkich ładowań i przewidywalnego zachowania:
- Cache dla punktów końcowych do odczytu (listy runbooków, szablony)
- Paginacja i filtrowanie dla wyników wyszukiwania i widoków audytu
- Ograniczenia zapytań (rate limiting) na uwierzytelnianie i akcje zapisu, by zmniejszyć nadużycia i przypadkowe przeciążenie
Również loguj wolne zapytania wcześnie; to łatwiejsze niż zgadywanie później.
Strategia testów, która chroni zaufanie
Skoncentruj testy na funkcjach, których awaria powoduje ryzyko:
- Sprawdzenia uprawnień (RBAC, własność, zatwierdzenia)
- Zachowanie edytora (kolejność kroków, szablony, walidacje)
- Wersjonowanie (diffy, flow publikacji, rollback)
Dodaj też ograniczony zestaw testów end-to-end dla „opublikuj runbook” i „wykonaj runbook”, aby wykryć problemy integracyjne.
Wdrażaj iteracyjnie, nie od razu wszystko
Pilotuj z jednym zespołem — najlepiej tym, który ma dużo on-callowego doświadczenia. Zbieraj feedback w narzędziu (szybkie komentarze) i na krótkich cotygodniowych przeglądach. Rozszerzaj stopniowo: dodaj następny zespół, migruj kolejne SOP-y i dopracowuj szablony na podstawie rzeczywistego użycia, a nie założeń.
Przyspiesz dostarczenie z pomocą Koder.ai (bez zmiany modelu własności)
Jeśli chcesz szybko przejść od koncepcji do działającego narzędzia wewnętrznego, platforma vibe-codingowa taka jak Koder.ai może pomóc prototypować aplikację runbookową end-to-end z poziomu czatu. Możesz iterować nad kluczowymi przepływami (library → editor → execution mode), a potem eksportować kod źródłowy, gdy będziesz gotowy na przegląd, wzmocnienie i obsługę w standardowych procesach inżynieryjnych.
Koder.ai jest praktyczny dla tego typu produktu, ponieważ pasuje do powszechnych wyborów implementacyjnych (React dla UI; Go + PostgreSQL dla backendu) i wspiera tryb planowania, snapshoty i rollback — przydatne podczas iteracji nad krytycznymi operacyjnie funkcjami jak wersjonowanie, RBAC i ślady audytu.