Wyjaśnij przypadek użycia i metryki sukcesu
Zanim zaprojektujesz ekrany lub wybierzesz stack technologiczny, sprecyzuj problem, który rozwiązujesz. Aplikacja do zależności zawodzi, gdy staje się „kolejnym miejscem do aktualizacji”, a prawdziwy ból — niespodzianki i opóźnione przekazania między zespołami — pozostaje.
Zdefiniuj główny problem
Zacznij od prostego zdania, które możesz powtarzać na każdym spotkaniu:
Zależności międzyfunkcyjne powodują opóźnienia i ostatnie niespodzianki, ponieważ odpowiedzialność, terminy i status są niejasne.
Dopasuj je do swojej organizacji: które zespoły są najbardziej dotknięte, jakie typy pracy są blokowane i gdzie obecnie tracisz czas (przekazania, zatwierdzenia, dostawy, dostęp do danych itp.).
Określ docelowych użytkowników (i czego potrzebują)
Wypisz głównych użytkowników i jak będą korzystać z aplikacji:
- Kierownicy projektów: potrzebują wiarygodnego widoku nadchodzących blokad i tego, co eskalować.
- Liderzy zespołów: potrzebują jasności, co ich zespół ma dostarczyć, kiedy i jakie są kompromisy.
- Sponsorzy wykonawczy: potrzebują widoku ryzyka na wysokim poziomie i czytelności odpowiedzialności.
- Wykonawcy indywidualni (IC): potrzebują konkretnych próśb, kontekstu i terminów.
Zbierz najważniejsze zadania do wykonania
Utrzymaj „zadania” zwięzłe i testowalne:
- Wykrywać zależności wcześnie (podczas planowania, nie dopiero w trakcie realizacji).
- Tworzyć żądania zależności z jasnym zakresem i terminami.
- Weryfikować (zaakceptować/odrzucić) z wynegocjowanymi terminami.
- Śledzić postęp i zmiany w czasie.
- Eskalować gdy ryzyko rośnie lub zobowiązania zaczynają się obsuwać.
Zdecyduj, co tutaj oznacza „zależność”
Napisz jedną akapitową definicję. Przykłady: przekazanie (zespół A dostarcza dane), zatwierdzenie (podpis działu prawnego), albo dostawa (specyfikacja projektu). Ta definicja staje się Twoim modelem danych i kręgosłupem workflow.
Ustal metryki sukcesu
Wybierz mały zestaw mierzalnych rezultatów:
- Mniej aktywnych blokad na projekt (lub mniej „późno wykrytych” zależności).
- Szybszy średni czas od zgłoszenia → akceptacji → dostawy.
- Lepsza przewidywalność (mniej przesunięć terminów, wyższy odsetek dostaw na czas).
Jeśli nie możesz tego zmierzyć, nie udowodnisz, że aplikacja poprawia realizację.
Zmapuj interesariuszy i obecny workflow
Zanim zaprojektujesz ekrany lub bazy danych, wyjaśnij, kto uczestniczy w zależnościach i jak praca przepływa między nimi. Zarządzanie zależnościami międzyfunkcyjnymi bardziej zawodzi przez niezgodność oczekiwań niż przez złe narzędzie: „Kto za to odpowiada?”, „Co oznacza ukończenie?”, „Gdzie widzimy status?”
Znajdź, gdzie dziś żyją dane o zależnościach
Informacje o zależnościach są zwykle rozproszone. Zrób szybki przegląd i zachowaj przykłady (rzeczywiste zrzuty ekranu lub notatki) takich miejsc jak:
- Arkusze kalkulacyjne śledzące „prośby” i terminy
- Bilety i epiki w Jira/Asana/Trello
- Dokumenty i notatki ze spotkań (Google Docs/Notion/Confluence)
- Wątki w Slack/Teams, gdzie zapadają decyzje i składane są obietnice
To pokaże, na których polach ludzie już polegają (daty, linki, priorytet) i czego brakuje (jasny właściciel, kryteria akceptacji, status).
Zmapuj workflow end-to-end
Opisz obecny przepływ prostym językiem, zwykle:
request → accept → deliver → verify
Dla każdego kroku zanotuj:
- Kto to wywołuje (rola/zespół, nie osoba)
- Jakie informacje są potrzebne, by przejść dalej
- Gdzie jest to dziś zapisywane
- Co oznacza „ukończone” (i kto to zatwierdza)
Wypunktuj punkty awarii i oceń ból
Szukaj wzorców, jak niejasni właściciele, brak terminów, „cichy” status lub późno wykryte zależności. Poproś interesariuszy o ocenę najboleśniejszych scenariuszy (np. „zaakceptowane, ale nigdy nie dostarczone” vs. „dostarczone, ale niezweryfikowane”). Optymalizuj najpierw top 1–2.
Zakotwicz budowę w historiach użytkownika
Napisz 5–8 historii użytkownika odzwierciedlających rzeczywistość, np.:
- “Jako PM zgłaszający zależność mogę przesłać żądanie z datą potrzebną i kontekstem, żeby zespół odpowiedzialny mógł je ocenić.”
- “Jako lider zespołu mogę zaakceptować/odrzucić z zobowiązanym terminem, aby oczekiwania były jasne.”
- “Jako interesariusz mogę zobaczyć status na pierwszy rzut oka, żeby nie ścigać aktualizacji na spotkaniach.”
Te historie będą strażnikiem zakresu, gdy pojawi się fala nowych żądań funkcji.
Zaprojektuj model danych dla zależności
Aplikacja do zależności odniesie sukces lub porażkę w zależności od tego, czy wszyscy ufają danym. Celem modelu danych jest uchwycenie kto potrzebuje czego, od kogo, do kiedy oraz prowadzenie czystego zapisu zmian zobowiązań w czasie.
Główny rekord zależności
Zacznij od pojedynczej encji „Dependency”, która jest czytelna sama w sobie:
- Tytuł: krótki, konkretny (np. „Zapewnić przegląd prawny zaktualizowanego tekstu kasy”)
- Opis: kontekst, kryteria akceptacji, linki
- Typ: kontrolowana lista (np. przegląd, dostawa, zatwierdzenie, dostęp do danych)
- Zespół odpowiedzialny: zespół, który ma dostarczyć
- Zgłaszający: osoba lub zespół zgłaszający
Uczyń te pola obowiązkowymi tam, gdzie to możliwe; pola opcjonalne mają tendencję do pozostawania pustymi.
Daty i zobowiązania
Zależności dotyczą czasu, więc przechowuj daty explicite i oddzielnie:
- Requested by (data, której potrzebuje zgłaszający)
- Committed by (termin obiecany przez zespół realizujący)
- Delivered on (rzeczywista data ukończenia)
- Review window (zakres start/koniec dla weryfikacji lub zatwierdzenia)
Takie oddzielenie zapobiega sporom później („poproszono” ≠ „zobowiązano się”).
Status i relacje
Użyj prostego, wspólnego modelu statusów: proposed → pending → accepted → delivered, z wyjątkami jak at risk i rejected.
Modeluj relacje jako powiązania jeden-do-wielu, aby każda zależność mogła łączyć się z:
- Projektami (jedna zależność może wpływać na wiele inicjatyw)
- Kamieniami milowymi (powiąż z konkretnym checkpointem dostawy)
- Biletami (np. zadania w Jira dla wykonania)
Audytowalność i zaufanie
Śledź zmiany za pomocą:
- Kto utworzył/zmodyfikował
- Historia zmian (zmiany na poziomie pola w czasie)
- Komentarze (notatki decyzyjne, wyjaśnienia, zatwierdzenia)
Jeśli dobrze zaplanujesz ślad audytu, unikniesz debat „kto co powiedział” i ułatwisz przekazania.
Modeluj projekty, kamienie milowe i własność zespołów
Aplikacja zadziała tylko, jeśli wszyscy zgodzą się, co to znaczy „projekt”, „kamień milowy” i kto ponosi odpowiedzialność, gdy coś się obsuwa. Utrzymaj model na tyle prosty, by zespoły faktycznie go utrzymywały.
Projekty i kamienie milowe: dobierz odpowiednią szczegółowość
Śledź projekty na poziomie, na którym ludzie planują i raportują—zwykle inicjatywa trwająca od tygodni do miesięcy z jasnym rezultatem. Unikaj tworzenia projektu dla każdego biletu; to należy do narzędzi wykonawczych.
Kamienie milowe powinny być nieliczne i znaczące, które mogą odblokować innych (np. „Zatwierdzony kontrakt API”, „Uruchomienie beta”, „Zakończona weryfikacja bezpieczeństwa”). Jeśli kamieni milowych będzie za dużo, aktualizacje staną się uciążliwe, a jakość danych spadnie.
Praktyczna zasada: projekt powinien mieć 3–8 kamieni milowych, każdy z właścicielem, datą docelową i statusem. Jeśli potrzebujesz więcej, rozważ podział projektu.
Katalog zespołów: udostępnij właścicielstwo
Zależności zawodzą, gdy ludzie nie wiedzą, z kim rozmawiać. Dodaj lekki katalog zespołów zawierający:
- Nazwę zespołu i funkcję (np. Payments, Data Platform, Legal)
- Kontakt główny (osoba) i backup/on-call
- Preferowany kanał (email, Slack handle, kolejka biletów)
Katalog powinien być użyteczny dla partnerów nietechnicznych, więc utrzymuj pola czytelne i przeszukiwalne.
Zasady własności: odpowiedzialność bez zamieszania
Zdecyduj wcześniej, czy dopuszczasz współwłasność. Najczystsza zasada dla zależności to:
- Jeden odpowiedzialny właściciel na kamień milowy/zależność (jedna osoba)
- Opcjonalni współpracownicy (wiele osób)
Jeśli dwa zespoły naprawdę współdzielą odpowiedzialność, modeluj to jako dwa kamienie milowe (lub dwie zależności) z jasnym przekazaniem, zamiast „współwłasności”, której nikt nie napędza.
Zależności międzyprojektowe i zbiory programowe
Reprezentuj zależności jako linki między projektem/ kamieniem milowym zgłaszającym a projektem/kamieniem milowym realizującym, z określoną kierunkiem („A potrzebuje B”). To pozwala na widoki programowe: agregację po inicjatywie, kwartale lub portfelu bez zmiany codziennej pracy zespołów.
Strategia tagowania, która pozostanie użyteczna
Tagi pomagają w raportowaniu bez wymuszania nowej hierarchii. Zacznij od małego, kontrolowanego zestawu:
- Obszar produktu
- Kwartał (lub okno wydania)
- Nazwa inicjatywy/programu
- Priorytet (np. P0–P3)
Preferuj dropdowny zamiast wolnego tekstu dla kluczowych tagów, aby uniknąć „Payments”, „payments” i „Paymnts” jako trzech różnych kategorii.
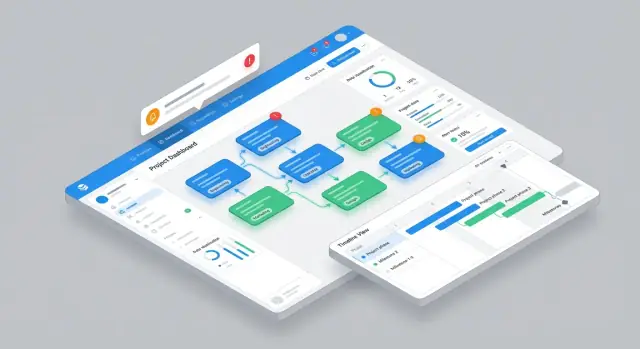
Zaplanuj główny interfejs i nawigację
Make Risk Visible Fast
Get meeting-ready views for overdue, at risk, and missing owner items.
Aplikacja do zarządzania zależnościami działa, gdy ludzie mogą w ciągu kilku sekund odpowiedzieć na dwa pytania: „Co ja muszę zrobić?” i „Co mnie blokuje?”. Projektuj nawigację wokół tych zadań, a nie obiektów bazy danych.
Główne widoki odpowiadające rzeczywistej pracy
Zacznij od czterech kluczowych widoków, z których każdy jest zoptymalizowany pod inny moment tygodnia:
- Lista zależności do triage i sortowania (najlepsza na codzienne check-iny)
- Graf zależności by zrozumieć wpływ upstream/downstream na pierwszy rzut oka
- Oś czasu by wykrywać kolizje terminów i opóźniające się przekazania
- Skrzynka zespołowa (inbox) jako domyślna strona dla wykonawców („prośby czekające na mnie”)
Utrzymaj globalną nawigację minimalistyczną (np. Inbox, Dependencies, Timeline, Reports) i pozwól użytkownikom przechodzić między widokami bez utraty filtrów.
Szybkie tworzenie bez utraty jasności
Utworzenie zależności powinno być równie szybkie jak wysłanie wiadomości. Zapewnij szablony (np. „Kontrakt API”, „Przegląd projektu”, „Eksport danych”) i wysuwane okno Quick Add.
Wymagaj tylko tego, co niezbędne do prawidłowego skierowania pracy: zgłaszający zespół, zespół realizujący, data, krótki opis i status. Reszta może być opcjonalna lub stopniowo odkrywana.
Filtry, wyszukiwanie i zapisane widoki
Ludzie będą żyć w filtrach. Wspieraj wyszukiwanie i filtry po zespole, zakresie dat, ryzyku, statusie, projekcie, plus „przypisane do mnie”. Pozwól zapisywać popularne kombinacje („Moje premiery Q1”, „Wysokie ryzyko w tym miesiącu”).
Dostępność i wskazówki dla pustych stanów
Użyj wskaźników ryzyka bezpiecznych kolorystycznie (ikona + etykieta, nie tylko kolor) i zapewnij pełną nawigację klawiaturową przy tworzeniu, filtrowaniu i aktualizacji statusów.
Puste stany uczą. Gdy lista jest pusta, pokaż krótki przykład mocnej zależności:
“Payments team: provide sandbox API keys for Checkout v2 by Mar 14; needed for mobile QA start.”
Taka wskazówka poprawia jakość danych bez dodawania procesu.
Zbuduj workflow: Request, Accept, Deliver, Close
Narzędzie do zależności odnosi sukces, gdy odzwierciedla sposób współpracy zespołów—bez zmuszania ich do długich spotkań statusowych. Projektuj workflow wokół niewielkiego zestawu rozpoznawalnych stanów i spraw, by każda zmiana odpowiadała na pytanie: „Co dalej i kto za to odpowiada?”
Przepływ zgłoszenia zależności: create → route → acceptance
Zacznij od prowadzonego formularza „Create dependency”, który zbiera minimum potrzebne do działania: projekt zgłaszający, oczekiwany wynik, docelowa data i wpływ przy braku dostawy. Następnie automatycznie skieruj to do zespołu odpowiedzialnego na podstawie prostej reguły (właściciel usługi/komponentu, katalog zespołów lub ręcznie wybrany właściciel).
Akceptacja powinna być jawna: zespół realizujący akceptuje, odrzuca lub prosi o doprecyzowanie. Unikaj „miękkiej” akceptacji—zrób to przyciskiem, który tworzy odpowiedzialność i zapisuje znacznik czasu.
Kryteria akceptacji: definicja ukończenia i zatwierdzenie
Przy akceptacji wymagaj lekkiej definicji ukończenia: deliverables (np. endpoint API, przegląd specyfikacji, eksport danych), test akceptacyjny lub krok weryfikacji oraz właściciel zatwierdzenia po stronie zgłaszającej. To zapobiega sytuacji, w której zależność jest „dostarczona”, ale nieużyteczna.
Zarządzanie zmianami: daty, zakres, przekazania
Zmiany są normalne; niespodzianki nie. Każda zmiana powinna:
- zapisać co się zmieniło (data, zakres, właściciel)
- wymagać krótkiego powodu
- powiadomić oba zespoły
- trzymać widoczną historię, by nikt nie debatował „kto co powiedział”
Ścieżka eskalacji: flagi at-risk i SLA
Daj użytkownikom wyraźną flagę at-risk z poziomami eskalacji (np. Team Lead → Program Lead → Exec Sponsor) i opcjonalne oczekiwania SLA (odpowiedź w X dni, aktualizacja co Y dni). Eskalacja powinna być akcją workflow, nie agresywnym wątkiem wiadomości.
Zamknięcie: dowody, weryfikacja, notatki retrospektywne
Zamknij zależność dopiero po dwóch krokach: dowód dostawy (link, załącznik lub notatka) i weryfikacja przez zgłaszającego (lub autouzupelnienie po określonym oknie). Zapisz krótkie pole retrospektywne („co nas blokowało?”), by poprawiać planowanie bez pełnego postmortemu.
Dodaj role, uprawnienia i audytowalność
Zarządzanie zależnościami psuje się szybko, gdy ludzie nie wiedzą, kto może się zobowiązywać, kto może edytować i kto zmienił co. Jasny model uprawnień zapobiega przypadkowym zmianom dat, chroni poufną pracę i buduje zaufanie między zespołami.
Zdefiniuj typy ról odpowiadające rzeczywistej pracy
Zacznij od małego zestawu ról i rozszerzaj tylko wtedy, gdy pojawi się rzeczywista potrzeba:
- Admin: zarządza ustawieniami workspace, integracjami i globalnymi uprawnieniami
- Program manager: nadzoruje portfele, ustala zasady governance i rozstrzyga spory
- Team lead: odpowiada za zobowiązania zespołu i zatwierdza przychodzące żądania
- Contributor: tworzy i aktualizuje zależności, w których uczestniczy, dodaje notatki, proponuje zmiany
- Viewer: dostęp tylko do odczytu dla interesariuszy, którzy potrzebują widoczności bez możliwości edycji
Uprawnienia wg obiektu (i akcji)
Wdrażaj uprawnienia na poziomie obiektu — dependencies, projects, milestones, comments/notes — a następnie wg akcji:
- Tworzenie/edycja zależności
- Zmiana statusu zależności (np. Proposed → Accepted → Delivered → Closed)
- Edycja dat zobowiązań vs. sugerowanych dat
- Usuwanie (zwykle ograniczone do Admin/Program manager)
Dobrym domyśłem jest zasada najmniejszych uprawnień: nowi użytkownicy nie powinni móc usuwać rekordów ani nadpisywać zobowiązań.
Widoczność danych i prace wrażliwe
Nie wszystkie projekty powinny być jednakowo widoczne. Dodaj zakresy widoczności takie jak:
- Internal (domyślnie): widoczne dla uwierzytelnionych użytkowników w workspace
- Sensitive: ograniczone do konkretnych zespołów lub grupy bezpieczeństwa
- Team-private notes: utrzymuj szczere notatki widoczne tylko dla zespołu realizującego, podczas gdy status zależności pozostaje widoczny dla interesariuszy
Kontrole zatwierdzeń i audytowalność
Zdefiniuj, kto może akceptować/odrzucać żądania i kto może zmieniać daty zobowiązań — zazwyczaj lider zespołu realizującego (lub delegat). Pokaż tę regułę w UI: „Tylko zespół realizujący może zobowiązywać terminy.”
Na koniec dodaj log audytu dla kluczowych zdarzeń: zmiany statusu, edycje dat, zmiany właścicieli, aktualizacje uprawnień i usunięcia (z informacją kto, kiedy i co zmienił). Jeśli obsługujesz SSO, powiąż je z logiem audytu, by dostęp i odpowiedzialność były jasne.
Wdroż powiadomienia i alerty
Iterate Without Fear
Use snapshots and rollback when you test new status rules or data fields.
Alerty to moment, w którym narzędzie do zależności staje się naprawdę pomocne — albo zamienia się w hałas, którego wszyscy zaczynają unikać. Cel jest prosty: płynność pracy między zespołami poprzez powiadamianie właściwych osób we właściwym czasie z odpowiednim poziomem pilności.
Zacznij od klarownych wyzwalaczy powiadomień
Zdefiniuj zdarzenia, które mają największe znaczenie dla zależności międzyfunkcyjnych:
- Nowe zgłoszenie (zespół realizujący musi to potwierdzić)
- Zgłoszenie zaakceptowane/odrzucone (zgłaszający potrzebuje jasności)
- Zbliżający się termin (zapobiega niespodziankom na ostatnią chwilę)
- Status zmienia się na “at risk” lub “blocked” (wymaga działania i wsparcia)
Powiąż każdy wyzwalacz z właścicielem i „następnym krokiem”, żeby powiadomienie nie było tylko informacją — było działaniem.
Oferuj kanały bez przymusu
Wspieraj wiele kanałów:
- Powiadomienia w aplikacji dla czystego śladu audytu i łatwego triage
- Email dla osób żyjących w skrzynce odbiorczej
- Slack/Teams (jeśli stosowalne) dla szybkiej widoczności zespołowej
Umożliwiaj konfigurację na poziomie użytkownika i zespołu. Lider zależności może chcieć pingów w Slacku; sponsor wykonawczy może preferować codzienne podsumowanie e-mailem.
Zrównoważ alerty w czasie rzeczywistym i digesty
Wiadomości w czasie rzeczywistym są najlepsze dla decyzji (akceptacja/odrzucenie) i eskalacji. Digesty lepsze dla świadomości (nadchodzące terminy, elementy „czekające”).
Dodaj ustawienia typu: „natychmiast dla przypisań”, „codzienny digest dla terminów” i „cotygodniowe podsumowanie zdrowia”. To zmniejsza zmęczenie powiadomieniami, zachowując widoczność zależności.
Ustaw logiczne przypomnienia i eskalacje
Przypomnienia powinny respektować dni robocze, strefy czasowe i godziny ciszy. Na przykład: przypomnij 3 dni robocze przed terminem i nie wysyłaj poza 9–18 czasu lokalnego.
Eskalacje uruchamiaj, gdy:
- Żądanie pozostaje nieodpowiedziane po ustalonym SLA (np. 48 godzin)
- Termin się obsunął lub zależność oznaczono jako at risk
Eskaluj do następnej odpowiedzialnej warstwy (lider zespołu, program manager) i dołącz kontekst: co jest blokowane, przez kogo i jaka decyzja jest potrzebna.
Zaplanuj integracje i synchronizację danych
Integracje sprawiają, że aplikacja do zależności jest użyteczna od pierwszego dnia, ponieważ większość zespołów już śledzi pracę gdzie indziej. Celem nie jest „zastąpienie Jira” (lub Linear, GitHub, Slack) — chodzi o połączenie decyzji zależności z systemami, w których dzieje się realizacja.
Integracje warte priorytetu
Zacznij od narzędzi, które reprezentują pracę, czas i komunikację:
- Jira / Linear dla issue'ów, statusów, przypisań i kontekstu sprintu/iteracji
- GitHub dla pull requestów, wydań i sygnałów wdrożeń
- Google Calendar dla dat kamieni milowych, okien zmian i kluczowych spotkań
- Slack dla powiadomień i lekkich zatwierdzeń
Wybierz 1–2 do pilota. Zbyt wiele integracji na początku może zamienić debugowanie w główne zadanie.
Strategia importu: najpierw CSV, potem sync
Użyj jednorazowego importu CSV do zasilenia istniejących zależności, projektów i właścicieli. Trzymaj format zdyscyplinowany (np. tytuł zależności, zespół zgłaszający, zespół dostarczający, termin, status).
Potem dodaj ciągłą synchronizację tylko dla pól, które muszą być spójne (np. status issue lub termin). To ogranicza niespodziewane zmiany i ułatwia rozwiązywanie problemów.
Linkowanie vs. synchronizacja (kiedy co stosować)
Nie każde pole zewnętrzne powinno być kopiowane do Twojej bazy.
- Linkowanie: przechowuj ID zewnętrznego systemu (np. klucz Jira) i deep-link do niego. Dobre, gdy narzędzie zewnętrzne jest źródłem prawdy.
- Synchronizacja: przechowuj lokalną kopię wybranych pól (status, termin, przypisany) by wspierać raportowanie, alerty i historię audytu — szczególnie gdy potrzebujesz "co się zmieniło kiedy".
Praktyczny wzorzec: zawsze przechowuj zewnętrzne ID, synchronizuj mały zestaw pól i pozwól na ręczne nadpisania tylko tam, gdzie Twoja aplikacja jest źródłem prawdy.
Webhooki + API: synchronizacja zdarzeniowa
Polling jest prosty, ale kosztowny. Preferuj webhooki gdzie to możliwe:
- Nasłuchuj zmian statusu (np. “In Progress” → “Done”)
- Nasłuchuj zmian terminów (często najważniejszy wyzwalacz ryzyka)
Gdy przyjdzie zdarzenie, umieść zadanie w kolejce, by pobrać najnowszy rekord przez API i zaktualizować obiekt zależności.
Zdefiniuj granice własności danych
Spisz, który system jest właścicielem każdego pola:
- Jira/Linear ma status issue i assignee
- Twoja aplikacja ma zależności, daty zobowiązań i decyzje accept/decline
- Slack ma kanał komunikacji i historię wiadomości (nie próbuj jej replikować)
Jasne reguły źródła prawdy zapobiegają „wojnom synchronizacji” i upraszczają governance oraz audyty.
Stwórz raportowanie i dashboardy zdrowia
Plan the Data Model
Map entities, roles, and success metrics first, then generate the app from the plan.
Dashboardy to miejsce, gdzie aplikacja do zależności zdobywa zaufanie: liderzy przestają prosić o „jeszcze jeden slajd statusowy”, a zespoły przestają ścigać aktualizacje w wątkach czatu. Celem nie jest ściana wykresów — to szybka odpowiedź na pytanie: „Co jest zagrożone, dlaczego i kto wykona następny krok?”
Zdefiniuj jasne sygnały zdrowia
Zacznij od małego zestawu flag ryzyka, które można obliczyć spójnie:
- Overdue: obiecana data minęła i nie dostarczono
- Blocked: oznaczone jako zablokowane lub brak wymaganych danych
- Missing owner: brak przypisanego właściciela/zespołu
- Conflicting dates: zgłaszający potrzebuje po dacie planowanej dostawy dostawcy (lub odwrotnie)
Te sygnały powinny być widoczne na poziomie zależności i agregowane do zdrowia projektu/programu.
Zbuduj widoki gotowe na spotkania
Stwórz widoki pasujące do spotkań sterujących:
- Nadchodzące krytyczne zależności: następne 2–4 tygodnie, posortowane po ryzyku i terminie
- Wpływ na przepustowość zespołu: gdzie przychodzące żądania przekraczają dostępność zespołu (nawet prosty wskaźnik “niska/średnia/wysoka” pomaga)
- Rollupy programowe: grupuj zależności według inicjatywy, kwartału lub release train, by liderzy mogli porównywać strumienie pracy bez ręcznej agregacji
Dobrym domyślnym widokiem jest jedna strona odpowiadająca na pytanie: „Co się zmieniło od zeszłego tygodnia?” (nowe ryzyka, rozwiązane blokady, przesunięcia dat).
Ułatwiaj udostępnianie
Dashboardy często muszą opuścić aplikację. Dodaj eksporty, które zachowują kontekst:
- CSV do analizy i filtrowania
- PDF na spotkania sterujące i zatwierdzenia
Przy eksporcie dołącz właściciela, daty, status i ostatni komentarz, aby plik miał samodzielny kontekst. To sposób, by dashboardy zastąpiły ręczne slajdy statusowe, zamiast tworzyć kolejne zadanie raportowe.
Wybierz praktyczny stack technologiczny i architekturę
Celem nie jest wybór „idealnej” technologii — chodzi o stack, który zespół potrafi zbudować i utrzymać, a jednocześnie zapewni szybkie i wiarygodne widoki zależności.
Zacznij od prostego, sprawdzonego kształtu
Praktyczny baseline to:
- Aplikacja webowa (server-rendered lub SPA) do codziennego użytku
- Jedno API (REST lub GraphQL) napędzające UI i integracje
- Relacyjna baza danych
- Zadania w tle dla powiadomień, harmonogramów sync i generowania raportów
Takie podejście utrzymuje system prostym do zrozumienia: akcje użytkownika obsługiwane są synchronicznie, a wolne zadania (wysyłka alertów, obliczenia zdrowia) działają asynchronicznie.
Baza danych: modeluj powiązania świadomie
Zarządzanie zależnościami generuje dużo zapytań typu „znajdź wszystkie elementy blokowane przez X”. Model relacyjny sprawdza się dobrze, szczególnie z odpowiednimi indeksami.
Przynajmniej zaplanuj tabele Projects, Milestones/Deliverables i Dependencies (from_id, to_id, type, status, daty, właściciele). Dodaj indeksy dla typowych filtrów (zespół, status, data, projekt) i dla traversali (from_id, to_id). To zapobiegnie spowolnieniu aplikacji wraz ze wzrostem liczby powiązań.
Grafy i osie czasu: wybierz biblioteki z myślą o wydajności
Grafy zależności i wykresy typu Gantt mogą być kosztowne. Wybierz biblioteki renderujące z wirtualizacją (renderują tylko to, co widać) i wspierające aktualizacje inkrementalne. Traktuj widoki „pokaż wszystko” jako tryby zaawansowane; domyślnie pokazuj zakresy (projekt, zespół, zakres dat).
Utrzymuj szybkość widoków: cache i paginacja
Paginuj listy domyślnie i cache’uj często obliczane wyniki (np. „ile blokad na projekt”). Dla grafów ładuj sąsiedztwo wybranego węzła, a następnie rozszerzaj na żądanie.
Podstawy wdrożeniowe, za które będziesz wdzięczny
Używaj oddzielnych środowisk (dev/staging/prod), dodaj monitoring i śledzenie błędów oraz loguj zdarzenia ważne dla audytu. Aplikacja do zależności szybko staje się źródłem prawdy — przestoje i ciche awarie kosztują realny czas koordynacji.
Szybka ścieżka przy prototypowaniu
Jeśli celem jest szybkie zweryfikowanie workflow i UI (inbox, akceptacja, eskalacja, dashboardy) zanim zaangażujesz full engineering, możesz prototypować aplikację w platformie vibe-coding takiej jak Koder.ai. Pozwala iterować model danych, role/uprawnienia i kluczowe ekrany przez chat, a potem eksportować kod źródłowy przy gotowości do produkcji (często React na froncie, Go + PostgreSQL na backendzie). To dobre rozwiązanie dla pilota z 2–3 zespołami, gdzie szybkość iteracji jest ważniejsza niż idealna architektura na dzień pierwszy.