15 gru 2025·8 min
James Gosling, Java i wzrost idei „Pisz raz, uruchamiaj wszędzie”
Jak Java Jamesa Goslinga i „Pisz raz, uruchamiaj wszędzie” wpłynęły na systemy korporacyjne, narzędzia i współczesne praktyki backendowe — od JVM po chmurę.
Czego dotyczy ten wpis (i dlaczego to nadal ma znaczenie)
Najsłynniejsza obietnica Javy — „Pisz raz, uruchamiaj wszędzie” (WORA) — nie była marketingowym hasłem dla zespołów backendowych. To była praktyczna stawka: dało się zbudować poważny system raz, wdrożyć go na różnych systemach operacyjnych i sprzęcie oraz utrzymać w miarę rozwoju firmy.
Ten wpis wyjaśnia, jak ta stawka działała, dlaczego przedsiębiorstwa tak szybko przyjęły Javę i jak decyzje podjęte w latach 90. nadal kształtują współczesny rozwój backendu — frameworki, narzędzia budowania, wzorce wdrożeń i długo żyjące systemy produkcyjne, które wiele zespołów nadal obsługuje.
Co zyskasz dzięki tej historii
Zaczniemy od pierwotnych celów Jamesa Goslinga i od tego, jak język i runtime zaprojektowano, by zmniejszyć problemy z przenośnością, nie rezygnując przy tym całkowicie z wydajności.
Następnie prześledzimy historię adopcji w przedsiębiorstwach: dlaczego Java stała się bezpiecznym wyborem, jak pojawiły się serwery aplikacyjne i standardy korporacyjne oraz dlaczego narzędzia (IDE, automatyzacja budowania, testowanie) stały się siłą mnożącą efektywność.
Na koniec połączymy „klasyczny” świat Javy z dzisiejszą rzeczywistością — wzrostem Springa, wdrożeniami w chmurze, kontenerami, Kubernetesem i tym, co naprawdę znaczy „uruchamiaj wszędzie”, gdy w runtime działa dziesiątki usług i zależności zewnętrznych.
Kluczowe pojęcia (używane w całym wpisie)
Przenośność: Zdolność do uruchomienia tego samego programu w różnych środowiskach (Windows/Linux/macOS, różne typy CPU) przy minimalnych lub żadnych zmianach.
JVM (Java Virtual Machine): Runtime wykonujący programy Java. Zamiast kompilować bezpośrednio do kodu specyficznego dla maszyny, Java celuje w JVM.
Bytecode: Format pośredni produkowany przez kompilator Javy. Bytecode to to, co uruchamia JVM i jest centralnym mechanizmem stojącym za WORA.
WORA nadal ma znaczenie, ponieważ wiele zespołów backendowych dziś balansuje te same kompromisy: stabilne runtime’y, przewidywalne wdrożenia, produktywność zespołu i systemy, które muszą przetrwać dekadę lub dłużej.
James Gosling i pierwotne cele Javy
Javę często kojarzy się z Jamesem Goslingiem, ale to nigdy nie był projekt jednoosobowy. W Sun Microsystems na początku lat 90. Gosling pracował z małym zespołem (często nazywanym projektem „Green”), którego celem było stworzenie języka i runtime’u, które mogłyby działać na różnych urządzeniach i systemach operacyjnych bez konieczności przepisywania za każdym razem.
Efektem nie był tylko nowy składnik składniowy — to była pełna koncepcja „platformy”: język, kompilator i maszyna wirtualna zaprojektowane razem, tak by oprogramowanie dało się dystrybuować z mniejszą liczbą niespodzianek.
Cele: bezpieczeństwo, przenośność, produktywność
Kilka praktycznych celów kształtowało Javę od pierwszego dnia:
- Bezpieczeństwo i niezawodność: Java usunęła lub ograniczyła typowe źródła awarii znane z C/C++ — zwłaszcza bezpośrednią manipulację wskaźnikami — i dodała kontrole w czasie wykonywania, które faworyzowały przewidywalne awarie zamiast cichej korupcji.
- Przenośność: Zamiast kompilować do kodu maszynowego konkretnego CPU, Java kompiluje do bytecode, który może być uruchomiony na zgodnej JVM. Ta decyzja przesunęła ciężar przenośności z warstwy kompilacji na spójną umowę runtime’u.
- Produktywność programisty: Java miała ułatwić codzienne programowanie przez standardową bibliotekę, spójne oczekiwania co do narzędzi i automatyczne zarządzanie pamięcią.
To nie były cele akademickie. Odpowiadały na realne koszty: debugowanie problemów z pamięcią, utrzymywanie wielu buildów specyficznych dla platform, i wdrażanie nowych osób do złożonych baz kodu.
Co dokładnie oznaczało „Pisz raz, uruchamiaj wszędzie” (a czego nie)
W praktyce WORA oznaczało:
- Jeśli celujesz w JVM, zwykle możesz wysłać ten sam bytecode na różne systemy operacyjne.
- Wciąż musisz zarządzać różnicami środowiskowymi: ścieżkami plików, zachowaniem lokalizacji, niuansami sieci, charakterystykami wydajności, integracjami natywnymi i pakowaniem wdrożeń.
Slogan nie był więc „magiczna przenośność”. Była to zmiana w tym, gdzie wykonuje się przenośność: nie w przepisywaniu kodu per-platforma, lecz w ustandaryzowanym runtime i bibliotekach.
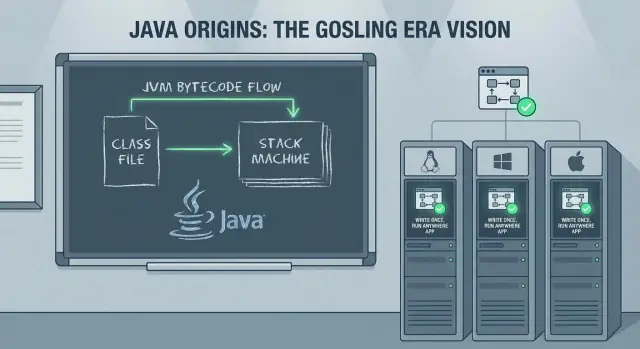
Jak działa WORA: bytecode i JVM
WORA to model kompilacji i runtime’u, który rozdziela budowanie oprogramowania od uruchamiania go.
Kod źródłowy → bytecode → wykonanie na JVM
Pliki źródłowe Javy (.java) są kompilowane przez javac do bytecode (.class). Bytecode to skompaktowany, ustandaryzowany zestaw instrukcji, taki sam niezależnie od tego, czy skompilowano go na Windows, Linux czy macOS.
W czasie wykonywania JVM ładuje ten bytecode, weryfikuje go i wykonuje. Wykonanie może być interpretowane, kompilowane „w locie” lub mieszanką obu, w zależności od implementacji JVM i obciążenia.
JVM jako „adapter” dla systemu operacyjnego/CPU
Zamiast generować kod maszynowy dla każdego docelowego CPU i systemu operacyjnego w czasie kompilacji, Java celuje w JVM. Każda platforma dostarcza swoją implementację JVM, która potrafi:
- tłumaczyć bytecode na natywne instrukcje dla lokalnego CPU
- współdziałać z lokalnym systemem operacyjnym (pliki, sieć, wątki)
Ta abstrakcja to sedno kompromisu: twoja aplikacja rozmawia ze spójnym runtime’em, a runtime rozmawia z maszyną.
Kontrole w czasie wykonywania i zarządzanie pamięcią
Przenośność zależy też od gwarancji wymuszanych w czasie wykonywania. JVM wykonuje weryfikację bytecode i inne kontrole, które pomagają zapobiegać niebezpiecznym operacjom.
Zamiast wymagać od programistów ręcznego przydzielania i zwalniania pamięci, JVM zapewnia automatyczne zarządzanie pamięcią (garbage collection), co redukuje kategorię błędów specyficznych dla platformy i problemów „działa na mojej maszynie”.
Dlaczego to upraszczało wdrożenia w dużych środowiskach
Dla przedsiębiorstw uruchamiających mieszany sprzęt i systemy operacyjne zysk był operacyjny: wysyłasz te same artefakty (JARy/WARy) na różne serwery, standaryzujesz się na wersji JVM i spodziewasz się w miarę spójnego zachowania. WORA nie wyeliminowała wszystkich problemów z przenośnością, ale zawęziła je — ułatwiając automatyzację i utrzymanie wdrożeń na dużą skalę.
Dlaczego przedsiębiorstwa tak szybko przyjęły Javę
Przedsiębiorstwa w końcu lat 90. i na początku 2000. miały konkretną listę życzeń: systemy, które mogłyby działać przez lata, przetrwać rotację personelu i być wdrażane w złożonym miksie serwerów UNIX, Windows i dostępnego wtedy sprzętu.
Java przyszła z historią przyjazną dla enterprise: zespoły mogły zbudować raz i oczekiwać przewidywalnego zachowania w heterogenicznych środowiskach, bez utrzymywania oddzielnych baz kodu dla każdego systemu.
Mniej przepisywania, mniej cykli QA
Przed Javą przeniesienie aplikacji między platformami często oznaczało przepisywanie części specyficznych dla platformy (wątki, sieć, ścieżki plików, toolkit GUI, różnice kompilatora). Każde przepisanie powiększało wysiłek testowy — a testy enterprise są kosztowne, bo obejmują regresję, zgodność i ostrożność „niech nie zepsuje się obsługa płac”.
Java zredukowała ten ciężar. Zamiast weryfikować wiele natywnych buildów, wiele organizacji mogło standaryzować się na jednym artefakcie builda i spójnym runtime, co obniżało koszty QA i ułatwiało planowanie długiego cyklu życia.
Standardowa biblioteka o spójnym zachowaniu
Przenośność to nie tylko uruchamianie tego samego kodu; to także poleganie na tym samym zachowaniu. Standardowe biblioteki Javy dawały spójne podstawy dla takich potrzeb jak:
- sieci i protokoły webowe
- łączność z bazą danych (przez JDBC i sterowniki vendorów)
- prymitywy bezpieczeństwa
- budulec do wątków i współbieżności
Ta spójność ułatwiała formowanie wspólnych praktyk między zespołami, wdrażanie programistów i używanie bibliotek zewnętrznych bez zaskoczeń.
Gdzie przenośność wciąż zawodziła
Historia „pisz raz” nie była idealna. Przenośność mogła się rozsypać, gdy zespoły polegały na:
- bibliotekach natywnych (JNI) do integracji ze sprzętem lub starego kodu
- specyfikach systemu plików, czcionek czy zachowania lokalizacji
- funkcjach specyficznych dla vendorów baz danych czy serwerów aplikacyjnych
Nawet wtedy Java często zawężała problem do małej, dobrze zdefiniowanej krawędzi — zamiast czynić całą aplikację specyficzną dla platformy.
Platformy korporacyjne: serwery aplikacyjne i Jakarta EE
W miarę jak Java przenikała z desktopów do centrów danych, zespoły potrzebowały więcej niż języka i JVM — potrzebowały przewidywalnego sposobu wdrażania i obsługi wspólnych funkcji backendu. To przyczyniło się do rozwoju serwerów aplikacyjnych takich jak WebLogic, WebSphere i JBoss (a na lżejszym końcu servlet containers jak Tomcat).
Ustandaryzowane pakowanie (WAR/EAR)
Jednym z powodów szybkiego rozpowszechnienia serwerów aplikacyjnych była obietnica ustandaryzowanego pakowania i wdrożenia. Zamiast dostarczać skrypt instalacyjny dla każdego środowiska, zespoły mogły spakować aplikację jako WAR (web archive) lub EAR (enterprise archive) i wdrożyć ją na serwerze z przewidywalnym modelem runtime.
Ten model miał znaczenie dla przedsiębiorstw, bo rozdzielał obowiązki: deweloperzy skupiali się na kodzie biznesowym, a operacje polegały na serwerze aplikacyjnym w kwestii konfiguracji, integracji bezpieczeństwa i zarządzania cyklem życia.
Wzorce enterprise, których każdy potrzebował
Serwery aplikacyjne spopularyzowały zbiór wzorców, które pojawiają się w niemal każdym poważnym systemie biznesowym:
- Transakcje: koordynowanie wieloetapowych operacji (często między bazami i usługami), by awarie nie zostawiały danych w połowie zapisanych.
- Messaging: asynchroniczna praca przez kolejki i topic’i, wygładzająca szczyty ruchu i odluźniająca powiązania między systemami.
- Pooling połączeń: ponowne użycie kosztownych połączeń do bazy zamiast otwierania jednego na żądanie.
To nie były „miłe dodatki” — to była infrastruktura wymagana do niezawodnego przetwarzania płatności, zamówień, aktualizacji zapasów i wewnętrznych procesów.
Od servletów/JSP do nowoczesnych backendów webowych
Era servletów/JSP była ważnym mostem. Servlety ustaliły standardowy model request/response, a JSP uczynił serwerowe generowanie HTML bardziej przystępnym.
Chociaż branża potem przeszła w stronę API i front-endowych frameworków, servlety położyły podwaliny pod współczesne backendy webowe: routing, filtry, sesje i spójne wdrożenie.
Jakarta EE jako wysiłek standaryzacyjny
Z czasem te funkcje sformalizowano jako J2EE, potem Java EE, a dziś Jakarta EE: zbiór specyfikacji dla enterprise Java API. Wartość Jakarta EE polega na ustandaryzowaniu interfejsów i zachowań między implementacjami, tak by zespoły mogły budować przeciwko znanym kontraktom, a nie przeciwko stackowi jednego dostawcy.
Wydajność: JIT, GC i koszt przenośności
Zaplanuj przed budową
Użyj trybu planowania, aby rozrysować endpointy, dane i zadania przed generowaniem kodu.
Przenośność Javy rodziła oczywiste pytanie: jeśli ten sam program może działać na bardzo różnych maszynach, jak może być też szybki? Odpowiedź to zestaw technologii runtime, które uczyniły przenośność praktyczną dla realnych obciążeń — zwłaszcza serwerowych.
Garbage Collection: mniej zarządzania pamięcią, mniej błędów produkcyjnych
Garbage collection (GC) miało znaczenie, bo duże aplikacje serwerowe tworzą i porzucają ogromne ilości obiektów: żądania, sesje, dane w cache’u, sparsowane payloady i więcej. W językach, gdzie pamięć zarządzana jest ręcznie, takie wzorce prowadziły często do wycieków, awarii lub trudnej do zdiagnozowania korupcji.
Dzięki GC zespoły mogły skupić się na logice biznesowej zamiast „kto zwalnia co i kiedy”. Dla wielu przedsiębiorstw ta przewaga niezawodności przeważała nad mikrooptymalizacjami.
Kompilacja JIT: most wydajności dla przenośności
Java uruchamia bytecode na JVM, a JVM używa Just-In-Time (JIT) compilation, by tłumaczyć gorące fragmenty programu na zoptymalizowany kod maszynowy dla bieżącego CPU.
To most: twój kod pozostaje przenośny, a runtime dostosowuje się do środowiska, w którym faktycznie działa — często poprawiając wydajność w miarę obserwacji, które metody są najczęściej używane.
Kompromisy: warm-up, tunning i wrażliwość na latencję
Te runtime’owe sprytne rozwiązania nie są darmowe. JIT wprowadza czas rozgrzewki, kiedy wydajność może być wolniejsza, dopóki JVM nie zaobserwuje wystarczającego ruchu, by zoptymalizować.
GC może też powodować pauzy. Nowoczesne kolektory znacząco je redukują, ale systemy wrażliwe na latencję nadal wymagają uważnych wyborów i strojenia (rozmiar heapu, wybór kolektora, wzorce alokacji).
Profilowanie jako normalna część pracy z Javą
Ponieważ dużo zależy od zachowania w czasie wykonania, profilowanie stało się rutyną. Zespoły Java powszechnie mierzą CPU, tempo alokacji i aktywność GC, by znaleźć wąskie gardła — traktując JVM jako coś, co obserwujesz i stroisz, a nie czarną skrzynkę.
Narzędzia, które zmieniły produktywność zespołów
Java nie przekonała zespołów tylko przenośnością. Przyszła też z historią narzędzi, które uczyniły duże bazy kodu przetrwalnymi — i sprawiły, że rozwój na poziomie enterprise przestał być hazardem.
IDE: od edycji plików do rozumienia systemów
Nowoczesne IDE dla Javy (i cechy języka, na których bazowały) zmieniły codzienną pracę: precyzyjne przechodzenie po pakietach, bezpieczne refaktoryzacje i ciągła analiza statyczna.
Zmień nazwę metody, wydziel interfejs lub przenieś klasę między modułami — a importy, miejsca wywołań i testy aktualizują się automatycznie. Dla zespołów oznaczało to mniej obszarów „nie ruszać tego”, szybsze code review i bardziej spójną strukturę w miarę wzrostu projektu.
Buildy i zależności: Ant → Maven/Gradle
Wczesne buildy Javy często opierały się na Ant: elastyczny, ale łatwo przekształcalny w skrypt znany tylko jednej osobie. Maven wprowadził podejście konwencja-nad-konfiguracją z ustandaryzowaną strukturą projektu i modelem zależności, który dało się odtworzyć na każdej maszynie. Gradle później przyniósł bardziej ekspresyjne buildy i szybsze iteracje, jednocześnie zachowując zarządzanie zależnościami w centrum uwagi.
Wielka zmiana to powtarzalność: ta sama komenda, ten sam rezultat, na laptopie dewelopera i w CI.
Dlaczego standardowe narzędzia pomagały skalować zespoły
Standardowe struktury projektów, współrzędne zależności i przewidywalne kroki budowania ograniczały wiedzę plemienną. Onboarding uprościł się, wydania stały się mniej manualne, a praktyczne egzekwowanie wspólnych zasad jakości (formatowanie, checki, bramki testowe) stało się możliwe w wielu serwisach.
Praktyczna lista kontrolna dla współczesnego projektu Java
- Używaj aktualnego LTS JDK (i przypnij go w CI).
- Wybierz Maven lub Gradle; utrzymuj build prosty i udokumentowany.
- Centralizuj wersje zależności (BOM lub katalog wersji).
- Dodaj formatowanie + statyczne checki (np. Checkstyle/SpotBugs) jako kroki builda.
- Wymagaj testów jednostkowych i generuj raporty pokrycia.
- Używaj odtwarzalnego pipeline’u CI, który uruchamia build + testy przy każdej zmianie.
- Udokumentuj „jak uruchomić lokalnie” w krótkim README.
Testowanie i dostarczanie: od JUnit do CI/CD
Wysyłaj narzędzia towarzyszące
Stwórz panel lub narzędzie migracyjne, które pasuje do twojego istniejącego ekosystemu Java.
Zespoły Java nie dostały tylko przenośnego runtime’u — nastąpiła zmiana kultury: testowanie i dostarczanie stały się czymś, co można ustandaryzować, zautomatyzować i powtarzać.
Jak JUnit uczynił testy jednostkowe „normalnymi”
Przed JUnit testy często były doraźne (lub manualne) i żyły poza głównym cyklem rozwoju. JUnit zmienił to, sprawiając, że testy stały się kodem pierwszej klasy: napisz małą klasę testową, uruchom ją w IDE i uzyskaj natychmiastową informację zwrotną.
Ten krótki cykl miał znaczenie w systemach enterprise, gdzie regresje są kosztowne. Z czasem „brak testów” przestał być dziwnym wyjątkiem, a zaczął wyglądać jak ryzyko.
Zalety CI: jeden build, wiele środowisk
Dużą przewagą dostarczania w Javie jest to, że buildy zwykle uruchamia się tymi samymi komendami wszędzie — na laptopach deweloperów, agentach budowania, serwerach Linux, runnerach Windows — bo JVM i narzędzia budujące zachowują się spójnie.
W praktyce ta spójność redukowała klasyczny problem „działa na mojej maszynie”. Jeśli twój serwer CI potrafi uruchomić mvn test lub gradle test, najczęściej otrzymujesz te same wyniki, które widzi cały zespół.
Narzędzia jakości kodu pasujące do pipeline’u
Ekosystem Javy ułatwił automatyzację „bramek jakości”:
- Formatowanie: Spotless lub wspólna konfiguracja IDE, by utrzymać czytelne diffy
- Linting/analiza statyczna: Checkstyle, PMD, SpotBugs do wykrywania typowych błędów
- Skan bezpieczeństwa: OWASP Dependency-Check (lub hosted tool jak Snyk) do wykrywania podatnych bibliotek
Te narzędzia działają najlepiej, gdy są przewidywalne: te same reguły dla każdego repo, egzekwowane w CI, z czytelnymi komunikatami o błędach.
Prosty pipeline CI dla serwisu Java
Utrzymuj go nudnym i powtarzalnym:
- Checkout + ustaw wersję Java (przypnij JDK)
- Build + testy jednostkowe (
mvn test/gradle test) - Statyczne checki (formatowanie, lint, skan bezpieczeństwa)
- Sporządź artefakt (JAR) i zapisz go
- Testy integracyjne (opcjonalnie, ale wartościowe)
- Wdróż na staging, potem produkcję z akceptacjami
Taka struktura skaluje od jednego serwisu do wielu — i powtarza temat: spójny runtime i spójne kroki przyspieszają zespoły.
Spring i przejście do współczesnego backendu
Java szybko zdobyła zaufanie w przedsiębiorstwach, ale budowanie rzeczywistych aplikacji biznesowych często oznaczało zmaganie się z ciężkimi serwerami aplikacyjnymi, rozbudowanym XML i konwencjami specyficznymi dla kontenerów. Spring zmienił codzienność, stawiając „zwykłą” Javę w centrum rozwoju backendu.
Inwersja kontroli: dlaczego pasowała do enterprise
Spring spopularyzował inwersję kontroli (IoC): zamiast samemu tworzyć i łączyć wszystko ręcznie, framework składa aplikację z powtarzalnych komponentów.
Dzięki wstrzykiwaniu zależności (DI) klasy deklarują, czego potrzebują, a Spring to dostarcza. To poprawia testowalność i ułatwia zamianę implementacji (np. realna bramka płatnicza vs. stub w testach) bez przepisywania logiki biznesowej.
Uproszczona konfiguracja i integracje
Spring zmniejszył tarcie, ustandaryzował integracje: JDBC template, wsparcie ORM, deklaratywne transakcje, harmonogramowanie i bezpieczeństwo. Konfiguracja przeszła z długiego, łamliwego XML w stronę adnotacji i zewnętrznych właściwości.
Ta zmiana dobrze współgrała z nowoczesnym dostarczaniem: ten sam build może działać lokalnie, na stagingu lub w produkcji, zmieniając jedynie konfigurację środowiskową zamiast kodu.
WORA, przenośność i współczesne wzorce usług
Usługi oparte na Springu utrzymywały obietnicę „uruchamiaj wszędzie”: REST API zbudowane ze Springa może działać bez zmian na laptopie dewelopera, VM czy w kontenerze — ponieważ bytecode celuje w JVM, a framework abstrahuje wiele szczegółów platformy.
Dziś powszechne wzorce — endpointy REST, wstrzykiwanie zależności i konfiguracja przez properties/env vars — są właściwie domyślnym modelem mentalnym Springa dla backendu. Aby dowiedzieć się więcej o realiach wdrożeń, zobacz wpis „Java w chmurze: kontenery, Kubernetes i rzeczywistość”.
Java w chmurze: kontenery, Kubernetes i rzeczywistość
Java nie potrzebowała „przepisu na chmurę”, by działać w kontenerach. Typowy serwis Java wciąż pakuje się jako JAR (lub WAR), uruchamia przez java -jar i trafia do obrazu kontenera. Kubernetes traktuje ten kontener jak każdy inny proces: uruchom go, obserwuj, restartuj i skaluj.
Co się zmienia w kontenerach (nawet jeśli kod nie)
Największa zmiana to środowisko wokół JVM. Kontenery wprowadzają ostrzejsze granice zasobów i szybsze cykle życia niż tradycyjne serwery.
Limity pamięci to pierwszy praktyczny problem. W Kubernetes ustawiasz limit pamięci i JVM musi go respektować — inaczej pod zostanie zabity. Nowoczesne JVM są świadome kontenerów, ale zespoły nadal stroją ustawienia heapu, by zostawić miejsce na metaspace, wątki i pamięć natywną. Usługa „działa na VM” może się zawiesić w kontenerze, jeśli heap jest ustawiony zbyt agresywnie.
Czas startu też zyskuje na znaczeniu. Orkiestratory skalują w górę i w dół często, a wolne zimne starty wpływają na autoskalowanie, wdrożenia i odzyskiwanie po incydentach. Rozmiar obrazu jest operacyjnym ciężarem: większe obrazy wolniej się ściągają, wydłużają deploy i zużywają pasmo/registry.
Jak sprawić, by Java lepiej pasowała: mniejsze, szybsze, przewidywalniejsze
Kilka podejść ułatwiło pracę Javy w chmurze:
- Lżejsze runtime’y: szczupłe obrazy bazowe i przycinanie runtime’u narzędziami typu
jlink(gdy to ma sens) redukują rozmiar obrazu. - Szybszy start: class data sharing (CDS) i dbałość o zależności mogą skrócić zimny start.
- Alternatywne pakowanie: kompilacja AOT (dla odpowiednich serwisów) może znacząco poprawić start i profil pamięci, kosztem innych kompromisów build/debug.
Dla praktycznego przewodnika po strojeniu zachowania JVM i zrozumieniu kompromisów wydajności, zobacz wpis „Java: podstawy wydajności”.
Wsteczna kompatybilność i systemy długo żyjące
Wciągnij innych
Zaproś współpracowników i zacznijcie budować aplikacje razem.
Jednym z powodów, dla których Java zdobyła zaufanie w przedsiębiorstwach, jest prosty fakt: kod często przeżywa zespoły, vendorów, a nawet strategie biznesowe. Kultura Javy nastawiona na stabilne API i wsteczną kompatybilność oznaczała, że aplikacja napisana lata temu często mogła dalej działać po aktualizacjach OS, wymianach sprzętu i nowych wydaniach JDK — bez totalnego przepisywania.
Dlaczego stabilne API są ważne w enterprise
Przedsiębiorstwa optymalizują pod przewidywalność. Gdy podstawowe API pozostają kompatybilne, koszt zmiany spada: materiały szkoleniowe pozostają użyteczne, instrukcje operacyjne nie wymagają ciągłych poprawek, a krytyczne systemy można ulepszać małymi krokami zamiast migracji typu big-bang.
Ta stabilność wpłynęła też na wybory architektoniczne. Zespoły czuły się komfortowo budując duże, współdzielone platformy i wewnętrzne biblioteki, bo oczekiwały, że będą działać długo.
Biblioteki, utrzymanie i oczekiwanie „na zawsze”
Ekosystem bibliotek Javy (od logowania po dostęp do baz) wzmacniał przekonanie, że zależności to długoterminowe zobowiązania. Rewers tej monety to utrzymanie: systemy długo żyjące gromadzą stare wersje, zależności przechodnie i „tymczasowe” obejścia, które stają się trwałe.
Aktualizacje bezpieczeństwa i higiena zależności to praca ciągła, a nie jednorazowy projekt. Regularne poprawianie JDK, aktualizowanie bibliotek i śledzenie CVE zmniejsza ryzyko bez destabilizacji produkcji — szczególnie gdy aktualizacje są inkrementalne.
Bezpieczne aktualizowanie starszych aplikacji Java
Praktyczne podejście to traktować aktualizacje jako pracę produktową:
- Zacznij od dodania lub ulepszenia zautomatyzowanych testów dla krytycznych ścieżek.
- Aktualizuj małymi krokami (np. jedna linia LTS naraz) i mierz wydajność oraz pamięć, nie tylko kompilację.
- Uruchamiaj stare i nowe wersje równolegle na stagingu i trzymaj jawne plany rollbacku.
- Wczesna inwentaryzacja zależności; wiele „aktualizacji Javy” kończy się niepowodzeniem, bo kluczowa biblioteka została porzucona.
Wsteczna kompatybilność nie jest gwarancją braku bólu, ale tworzy fundament do ostrożnej, niskoryzykownej modernizacji.
Kluczowe lekcje dla zespołów backendowych dziś
Co WORA naprawdę dostarczyła (a czego nie)
WORA działała najlepiej na poziomie, który Java obiecywała: ten sam skompilowany bytecode mógł działać na dowolnej platformie z kompatybilnym JVM. To ułatwiło wdrożenia serwerowe i niezależne od dostawcy pakowanie bardziej niż w wielu natywnych ekosystemach.
Gdzie zawodziła, to wszystko wokół granicy JVM. Różnice w systemach operacyjnych, systemach plików, domyślnych ustawieniach sieci, architekturach CPU, flagach JVM i natywnych zależnościach wciąż miały znaczenie. I przenośność wydajności nigdy nie była automatyczna — możesz uruchomić wszędzie, ale musisz obserwować i stroić, jak to działa.
Praktyczne wnioski dla zespołów wybierających Javę dziś
Największą zaletą Javy nie jest jedna funkcja; to połączenie stabilnych runtime’ów, dojrzałych narzędzi i ogromnego rynku pracy.
Kilka lekcji zespołowych, które warto zabrać dalej:
- Traktuj JVM jak platformę: wybierz wspierany dystrybucję JDK, standaryzuj wersje i aktualizuj celowo.
- Preferuj nudne domyślne ustawienia: utrzymuj buildy, logowanie, metryki i zarządzanie zależnościami spójne między serwisami.
- Projektuj pod kątem operacyjności: zainwestuj wcześnie w monitoring, bezpieczną konfigurację i przewidywalne zachowanie pamięci/GC.
- Wykorzystuj ekosystem: frameworki i biblioteki oszczędzają czas, ale audytuj rozrost zależności i aktualizacje bezpieczeństwa.
Czynniki decyzyjne: kiedy Java jest dobrym wyborem
Wybierz Javę, gdy twój zespół ceni długoterminowe utrzymanie, mocne wsparcie bibliotek i przewidywalne operacje produkcyjne.
Sprawdź te czynniki:
- Umiejętności zespołu: Czy macie doświadczenie z Java/Spring, czy będziecie szkolić od zera?
- Ograniczenia runtime’u: Czy czas uruchomienia i pamięć są krytyczne (niektóre obciążenia wolą Go/Node), czy priorytetem jest przepustowość i stabilność?
- Potrzeby ekosystemu: Czy potrzebujesz dojrzałego messagingu, sterowników baz danych, obserwowalności lub integracji enterprise?
- Długość życia: Czy system będzie żył latami z minimalnymi przepisaniami?
Następne kroki
Jeśli oceniasz Javę dla nowego backendu lub modernizacji, zacznij od małego pilota, zdefiniuj politykę aktualizacji/patchowania i uzgodnij bazę frameworków. Jeśli chcesz pomocy w określeniu tych wyborów, skontaktuj się.
Jeśli eksperymentujesz też z szybszymi sposobami stawiania usług towarzyszących lub narzędzi wewnętrznych wokół istniejącego estate’u Java, platformy takie jak Koder.ai mogą pomóc przejść od pomysłu do działającej aplikacji web/serwer/mobilnej przez chat — przydatne do prototypowania usług pomocniczych, dashboardów czy narzędzi migracyjnych. Koder.ai wspiera eksport kodu, wdrożenie/hosting, własne domeny oraz snapshoty/rollback, co dobrze łączy się z tym samym podejściem operacyjnym, które cenią zespoły Java: powtarzalne buildy, przewidywalne środowiska i bezpieczna iteracja.