Co obejmuje ten wpis (i dlaczego nadal ma znaczenie)
Joe Armstrong nie tylko współtworzył Erlanga — stał się jego najjaśniejszym i najbardziej przekonującym popularyzatorem. Przez wykłady, artykuły i pragmatyczne podejście spopularyzował prostą ideę: jeśli chcesz oprogramowania, które nie przestaje działać, projektujesz je pod kątem awarii, zamiast udawać, że można ich uniknąć.
Ten wpis to przewodnik po mentalności Erlanga i dlaczego ma ona dziś znaczenie przy budowie niezawodnych platform czasu rzeczywistego — takich jak systemy czatu, trasowanie połączeń, powiadomienia na żywo, koordynacja multiplayer i infrastruktura, która musi reagować szybko i konsekwentnie, nawet gdy części systemu zawodzą.
„Czas rzeczywisty” prostymi słowami
Czas rzeczywisty nie zawsze oznacza „mikrosekundy” czy „twarde terminy”. W wielu produktach oznacza to:
- szybkie odpowiedzi, które użytkownik odczuwa (bez tajemniczych zacięć)
- przewidywalne zachowanie pod obciążeniem (może zwalniać, ale nie powinno wpadać w spiralę)
- ciągłość usługi podczas częściowych awarii (zepsuty komponent nie powinien wyłączyć wszystkiego)
Erlang powstał dla systemów telekomunikacyjnych, gdzie te oczekiwania były niepodważalne — i to pod presją takich wymagań ukształtowało jego najbardziej wpływowe pomysły.
Trzy filary, na których się skoncentrujemy
Zamiast zanurzać się w składnię, skupimy się na koncepcjach, które uczyniły Erlanga sławnym i które wciąż pojawiają się w nowoczesnym projektowaniu systemów:
- Współbieżność jako domyślna: buduj oprogramowanie z wielu małych, odizolowanych workerów zamiast kilku gigantów.
- Odporność na błędy jako cel projektowy: zakładaj błędy, timeouty i awarie — i zaplanuj, co ma się stać dalej.
- „Let it crash”: nie bronić każdej linijki kodu nadmiernie; pozwól zawieść szybko i odzyskaj czysto przez strukturę (nie heroiczne naprawy).
Po drodze połączymy te idee z modelem aktora i przesyłaniem wiadomości, wyjaśnimy drzewa nadzorcze i OTP w przystępnych słowach oraz pokażemy, dlaczego BEAM VM sprawia, że podejście to jest praktyczne.
Nawet jeśli nie używasz Erlanga (i nigdy nie będziesz), istota pozostaje: ramy Armstronga dają potężną listę kontrolną do budowy systemów, które pozostają responsywne i dostępne, gdy rzeczywistość robi się bałagana.
Motywacja Joe Armstronga: budowanie systemów, które działają
Przełączniki telekomunikacyjne i platformy do trasowania połączeń nie mają luksusu „wyłączenia na konserwację” jak wiele stron. Oczekuje się od nich obsługi połączeń, zdarzeń billingowych i ruchu sygnalizacyjnego 24/7 — często z surowymi wymaganiami dostępności i przewidywalnych czasów odpowiedzi.
Erlang narodził się w Ericssonie pod koniec lat 80. jako próba sprostania tym realiom przy pomocy oprogramowania, nie tylko wyspecjalizowanego sprzętu. Joe Armstrong i jego koledzy nie gonili za elegancją dla samej elegancji; chcieli zbudować systemy, którym operatorzy mogliby ufać pod stałym obciążeniem, częściowymi awariami i nieidealnymi warunkami rzeczywistymi.
Co w praktyce znaczy „niezawodny”
Kluczowa zmiana myślenia polega na tym, że niezawodność nie równa się „nigdy się nie psuje”. W dużych, długotrwale działających systemach coś się zepsuje: proces dostanie nieoczekiwane dane, węzeł zrestartuje się, łącze sieciowe poszarpie się albo zależność przestanie odpowiadać.
Zatem celem staje się:
- obsługiwać użytkowników nawet, gdy części systemu źle się zachowują
- wykrywać awarie szybko
- automatycznie odzyskiwać z minimalną interwencją ludzką
- izolować błędy, by jedna usterka nie wyłączała wszystkiego
To podejście sprawia, że idee takie jak drzewa nadzorcze i „let it crash” wydają się rozsądne: projektujesz na awarię jako normalne zdarzenie, nie jako katastrofę wyjątkową.
Mniej mitu, więcej rozwiązywania problemów
Łatwo jest opisać historię jako przełom jednej wizjonerskiej postaci. Bardziej użyteczne spojrzenie jest prostsze: ograniczenia telekomu wymusiły inne kompromisy. Erlang priorytetował współbieżność, izolację i odzyskiwanie, ponieważ były to praktyczne narzędzia potrzebne do utrzymania usług w działaniu, gdy świat wokół nich się zmieniał.
To problemowe podejście jest też powodem, dla którego lekcje Erlanga dobrze przekładają się dziś — wszędzie tam, gdzie dostępność i szybkie odzyskiwanie są ważniejsze niż perfekcyjne zapobieganie.
Współbieżność jako domyślność: wiele małych workerów
Jedną z podstawowych idei Erlanga jest to, że „robienie wielu rzeczy naraz” nie jest specjalną funkcją, którą doklejasz później — to normalny sposób strukturyzowania systemu.
Lekko wyjaśnione: lekkie procesy
W Erlangu praca jest podzielona na wiele malutkich „procesów”. Wyobraź je sobie jako małych workerów, z których każdy odpowiada za jedno zadanie: obsługę rozmowy telefonicznej, śledzenie sesji czatu, monitorowanie urządzenia, ponawianie płatności albo nadzorowanie kolejki.
Są lekkie — możesz mieć ich ogromne ilości bez potrzeby potężnego sprzętu. Zamiast jednego ciężkiego worker’a próbującego ogarnąć wszystko, masz tłum skupionych workerów, którzy szybko startują, szybko się zatrzymują i łatwo je wymienić.
Dlaczego „jeden wielki program” psuje się inaczej
Wiele systemów projektowanych jest jak jeden wielki program z wieloma ściśle powiązanymi częściami. Gdy taki system trafi na poważny błąd, problem z pamięcią lub operację blokującą, awaria może się rozlać — jak przepalenie jednego bezpiecznika i zgaszenie całego budynku.
Erlang promuje odwrotność: izolowanie odpowiedzialności. Jeśli jeden mały worker się popsuje, możesz go zatrzymać i zastąpić bez wyłączania niezwiązanych zadań.
Przekazywanie wiadomości — jak wysyłanie karteczek
Jak worker’y się ze sobą porozumiewają? Nie grzebią w stanie wewnętrznym innych. Wysyłają wiadomości — bardziej jak przekazywanie karteczek niż wspólna, zabałaganiona tablica.
Jeden worker może powiedzieć: „Nowe żądanie”, „Użytkownik się rozłączył” lub „Spróbuj ponownie za 5 sekund”. Odbiorca przeczyta karteczkę i zdecyduje, co robić dalej.
Kluczową korzyścią jest ograniczenie rozprzestrzeniania się awarii: ponieważ worker’y są izolowane i komunikują się wiadomościami, problemy rzadziej przenoszą się po całym systemie.
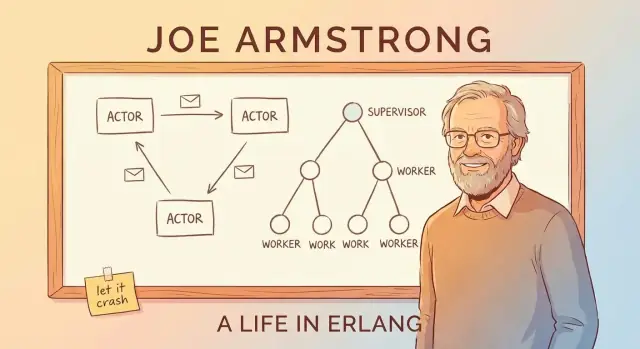
Przekazywanie wiadomości i model aktora (bez żargonu)
Prosty sposób zrozumienia „modelu aktora” Erlanga to wyobrazić system złożony z wielu małych, niezależnych workerów.
Aktorzy: mali workerzy, którzy rozmawiają tylko przez wiadomości
Aktor to samodzielna jednostka z własnym prywatnym stanem i skrzynką pocztową. Robi trzy podstawowe rzeczy:
- odbiera wiadomości (pojedynczo) ze swojej skrzynki
- aktualizuje swój wewnętrzny stan
- wysyła wiadomości do innych aktorów
To wszystko. Brak ukrytych współdzielonych zmiennych, brak „wejścia w pamięć innego worker’a”. Jeśli aktor potrzebuje czegoś od innego, prosi, wysyłając wiadomość.
Dlaczego unikanie współdzielonego stanu usuwa całe klasy błędów
Gdy wiele wątków współdzieli dane, pojawiają się race condition: dwie akcje zmieniają tę samą wartość niemal jednocześnie, a wynik zależy od dokładnego momentu. To są błędy przerywane i trudne do odtworzenia.
Przy przekazywaniu wiadomości każdy aktor jest właścicielem swoich danych. Inni nie mogą ich bezpośrednio zmieniać. To nie eliminuje wszystkich błędów, ale znacząco redukuje problemy wynikające z jednoczesnego dostępu do tej samej części stanu.
Back-pressure wyjaśnione jak kolejka w kawiarni
Wiadomości nie przychodzą „za darmo”. Jeśli aktor dostaje wiadomości szybciej niż potrafi je obsłużyć, jego skrzynka rośnie. To jest back-pressure: system mówi ci pośrednio „ta część jest przeciążona”.
W praktyce monitorujesz rozmiary skrzynek i wprowadzasz limity: odrzucanie obciążenia, batching, sampling albo przenoszenie pracy do większej liczby workerów zamiast pozwolić kolejkom rosnąć w nieskończoność.
Przykład praktyczny: powiadomienia w czacie
Wyobraź sobie aplikację czatową. Każdy użytkownik mógłby mieć aktora odpowiedzialnego za dostarczanie powiadomień. Gdy użytkownik jest offline, wiadomości nadal przychodzą — więc skrzynka rośnie. Dobrze zaprojektowany system może ograniczać kolejkę, odrzucać niekrytyczne powiadomienia albo przełączać na tryb zbiorczy (digest), zamiast pozwalać jednemu wolnemu użytkownikowi degradacji całej usługi.
„Let It Crash” wyjaśnione: zawieś się szybko, odzyskaj szybciej
„Let it crash” to nie hasło dla bylejakości. To strategia niezawodności: gdy komponent wpada w zły lub nieoczekiwany stan, powinien się szybko i głośno zatrzymać zamiast kulać dalej.
Co to naprawdę oznacza
Zamiast pisać kod, który próbuje obsłużyć każdy możliwy edge case w jednym procesie, Erlang zachęca do utrzymywania workerów małych i skoncentrowanych. Jeśli worker napotka coś, czego naprawdę nie potrafi obsłużyć (uszkodzony stan, złamane założenie, nieoczekiwane dane), wychodzi. Inna część systemu odpowiada za jego przywrócenie.
To przesuwa główne pytanie z „Jak zapobiec awarii?” na „Jak czyściutko się odzyskać, gdy awaria nastąpi?”.
Kompromis: mniej defensywnych sprawdzeń, czytelniejsza logika
Obrona w każdej funkcji może zamienić prosty przepływ w labirynt warunków, retry i częściowych stanów. „Let it crash” zamienia część tej złożoności wewnątrz procesu na:
- prostsze, bardziej czytelne ścieżki kodu
- szybsze wykrywanie złamanych założeń
- odzyskiwanie, które jest przewidywalne (bo scentralizowane)
Ważne jest, by odzyskiwanie było przewidywalne i powtarzalne, a nie improwizowane w każdym miejscu kodu.
Kiedy to pasuje — a kiedy nie
Dobrze się sprawdza, gdy awarie są odzyskiwalne i izolowane: tymczasowy problem sieciowy, złe żądanie, zawieszony worker, timeout zależności.
Nie pasuje tam, gdzie restart może spowodować nieodwracalną szkodę, na przykład:
- utrata danych bez trwałego źródła prawdy
- operacje krytyczne dla bezpieczeństwa, gdzie „spróbuj ponownie” jest niedopuszczalne
Szybkie restarty i znany, dobry stan
Crash pomaga tylko, jeśli ponowne uruchomienie jest szybkie i bezpieczne. W praktyce oznacza to restart workerów w znanym, dobrym stanie — często przez ponowne wczytanie konfiguracji, odbudowanie pamięci podręcznej z trwałego magazynu i wznowienie pracy bez udawania, że popsuty stan nigdy nie istniał.
Drzewa nadzorcze: projektowanie awarii z premedytacją
Pomysł „let it crash” działa tylko dlatego, że awarie nie są pozostawione przypadkowi. Kluczowym wzorcem jest drzewo nadzorcze: hierarchia, gdzie supervisorzy są jak menedżerowie, a worker’y wykonują faktyczną pracę (obsługa połączenia, sesji, konsumowanie kolejki itd.). Gdy worker źle się zachowuje, menedżer to zauważa i restartuje.
Menedżerowie, którzy restartują worker’y
Supervisor nie próbuje „naprawić” popsutego processu na miejscu. Zamiast tego stosuje prostą, spójną zasadę: jeśli worker umiera, uruchom nowego. To sprawia, że ścieżka odzyskiwania jest przewidywalna i zmniejsza potrzebę posypywania kodu ad-hoc obsługą błędów.
Równie ważne jest, że supervisor może zdecydować, kiedy nie restartować — jeśli coś się zbyt często wywala, może to oznaczać głębszy problem, a ciągłe restarty mogą wszystko pogorszyć.
Strategie restartu (wysoki poziom)
Nadzór nie jest uniwersalny. Powszechne strategie to:
- One-for-one: restartuje się tylko zawiedziony worker. Pasuje do niezależnych zadań, gdzie jedna awaria nie powinna zaburzyć innych.
- Restarty grupowe: gdy jeden worker upada, restartuje się powiązany zestaw. Pasuje do ściśle powiązanych komponentów, które muszą być zsynchronizowane.
Zależności: część, nad którą trzeba się zastanowić
Dobre projektowanie nadzoru zaczyna się od mapy zależności: które komponenty polegają na których innych i co oznacza „świeży start” dla nich.
Jeśli handler sesji zależy od procesu cache, restart tylko handlera może pozostawić go w złym stanie. Grupa ich pod właściwym supervisorem (lub restart razem) przekształca chaotyczne tryby awaryjne w spójne, powtarzalne zachowania odzyskiwania.
OTP: gotowe elementy do budowy niezawodnych usług
Jeśli Erlang to język, OTP (Open Telecom Platform) to zestaw części, które przemieniają „let it crash” w coś, co możesz uruchomić w produkcji przez lata.
OTP jako skrzynka narzędzi sprawdzonych wzorców
OTP to nie jedna biblioteka — to zestaw konwencji i gotowych komponentów (zwanych behaviours), które rozwiązują nudne, ale krytyczne części budowy usług:
gen_server dla długotrwałego workera, który utrzymuje stan i obsługuje żądania pojedynczosupervisor do automatycznego restartowania workerów według jasnych regułapplication do definiowania, jak cała usługa się uruchamia, zatrzymuje i wchodzi w release
To nie magia — to szablony z dobrze zdefiniowanymi callbackami, dzięki czemu twój kod dopina się do znanego kształtu zamiast wynajdywać nowy w każdym projekcie.
Dlaczego standardowe wzorce biją niestandardowe frameworki
Zespoły często tworzą ad-hoc worker’y w tle, domowe haki monitorujące i jednorazowe logiki restartu. Działa — aż nie działa. OTP zmniejsza to ryzyko, kierując wszystkich ku tej samej terminologii i cyklowi życia. Nowy inżynier nie musi uczyć się twojego custom frameworku; może polegać na wspólnych wzorcach znanych w ekosystemie Erlanga.
Jak OTP kieruje architekturą na co dzień
OTP zachęca do myślenia w kategoriach ról procesów i odpowiedzialności: co jest workerem, co koordynatorem, co ma restartować co, a co nigdy nie powinno być restartowane automatycznie.
Wymusza też dobrą higienę: jasne nazwy, eksplicytna kolejność startu, przewidywalne zamykanie i wbudowane sygnały monitorowania. Efekt to oprogramowanie zaprojektowane do ciągłego działania — usługi, które potrafią odzyskiwać z błędów, ewoluować i nadal wykonywać swoją pracę bez ciągłej opieki ludzkiej.
BEAM VM: środowisko wykonawcze, które sprawia, że model jest praktyczny
Wielkie idee Erlanga — malutkie procesy, przesyłanie wiadomości i „let it crash” — byłyby znacznie trudniejsze do praktycznego zastosowania bez maszyny wirtualnej BEAM. BEAM to runtime, który sprawia, że te wzorce działają naturalnie, a nie kruche.
Harmonogramowanie: uczciwość zamiast „jednego wielkiego wątku”
BEAM jest zbudowany do uruchamiania ogromnej liczby lekkich procesów. Zamiast polegać na garstce wątków systemu operacyjnego i modlić się, że aplikacja będzie się dobrze zachowywać, BEAM sam planuje procesy Erlanga.
Praktyczna korzyść to responsywność pod obciążeniem: praca jest krojona na małe kawałki i rotowana sprawiedliwie, więc żaden pojedynczy zajęty worker nie dominuje systemu przez długi czas. To idealnie pasuje do usługi złożonej z wielu niezależnych zadań — każdy robi trochę pracy, potem ustępuje innym.
Izolacja i „pamięć per-proces” z własnym GC
Każdy proces Erlanga ma własny heap i własne odśmiecanie pamięci. To kluczowy detal: czyszczenie pamięci w jednym procesie nie wymaga zatrzymywania całego programu.
Co ważniejsze, procesy są izolowane. Jeśli jeden się wywala, nie psuje pamięci innych, a VM pozostaje przy życiu. Ta izolacja to fundament, który czyni drzewa nadzorcze realistycznymi: awaria jest ograniczana, a potem obsługiwana przez restart złej części zamiast rozbicia wszystkiego.
Dystrybucja: wiele węzłów, jeden system
BEAM wspiera też dystrybucję w prosty sposób: możesz uruchomić wiele węzłów Erlanga (oddzielnych instancji VM) i pozwolić im komunikować się przez wysyłanie wiadomości. Jeśli rozumiesz, że „procesy rozmawiają przez messaging”, dystrybucja to przedłużenie tej samej idei — niektóre procesy po prostu mieszkają na innym węźle.
BEAM nie obiecuje surowej szybkości w każdym scenariuszu. Chodzi o to, by uczynić współbieżność, izolację błędów i odzyskiwanie domyślnością, dzięki czemu historia niezawodności staje się praktyczna, nie tylko teoretyczna.
Aktualizacje bez zatrzymywania systemu (hot code, z ostrożnością)
Jednym z najbardziej omawianych trików Erlanga jest hot code swapping: aktualizowanie części działającego systemu przy minimalnym przestoju (gdy runtime i narzędzia to wspierają). Obietnica praktyczna to nie „nigdy więcej restartów”, lecz „wdrażaj poprawki bez zamieniania krótkiego błędu w długi przestój”.
Co naprawdę znaczy „hot code”
W Erlang/OTP runtime może trzymać jednocześnie dwie wersje modułu. Istniejące procesy mogą dokończyć pracę używając starej wersji, podczas gdy nowe wywołania zaczynają korzystać z nowej. To daje przestrzeń na załatanie błędu, wprowadzenie funkcji lub zmianę zachowania bez wyrzucania wszystkich z systemu.
Robione dobrze, to wspiera cele niezawodności bezpośrednio: mniej pełnych restartów, krótsze okna konserwacyjne i szybsze naprawianie, gdy coś przecieknie do produkcji.
Ograniczenia, których nie warto ignorować
Nie każda zmiana jest bezpieczna do wymiany na żywo. Przykłady zmian wymagających ostrożności lub restartu:
- zmiany kształtu stanu (proces oczekuje danych w jednym formacie, a nowy kod w innym)
- zmiany protokołu lub formatu wiadomości, które muszą być zgodne po obu stronach
- migracje schematu, które trwają lub wymagają koordynacji
Erlang daje mechanizmy do kontrolowanych przejść, ale nadal trzeba zaprojektować ścieżkę aktualizacji.
Mentalność: aktualizacje i rollbacki jako normalna rzecz
Hot upgrade działa najlepiej, gdy aktualizacje i rollbacki traktowane są rutynowo, a nie jako rzadkie awaryjne działania. To oznacza planowanie wersjonowania, kompatybilności i jasnej ścieżki „cofnij” od początku. W praktyce zespoły łączą techniki live-upgrade z etapowymi rolloutami, health checkami i odzyskiwaniem opartym na nadzorach.
Nawet jeśli nigdy nie użyjesz Erlanga, lekcja jest uniwersalna: zaprojektuj systemy tak, by bezpieczna zmiana była wymogiem, a nie dodatkiem.
Platformy czasu rzeczywistego mniej polegają na idealnym czasie, a bardziej na pozostawaniu responsywnym, gdy wszystko ciągle się psuje: sieci chwiejne, zależności spowolnione, ruch skacze. Projekt Erlanga — promowany przez Joe Armstronga — pasuje do tej rzeczywistości, bo zakłada awarię i traktuje współbieżność jako coś normalnego.
Typowe przypadki użycia „w czasie rzeczywistym”
Zastosowania, gdzie myślenie w stylu Erlanga sprawdza się najlepiej:
- Messaging i czat: miliony małych rozmów, każda z własnym stanem i mechanizmem ponawiania.
- Komunikacja na żywo: sygnalizacja głosu/wideo, aktualizacje obecności, koordynacja sesji.
- Koordynacja IoT: floty urządzeń łączących się, znikających i ponownie się pojawiających.
- Przepływy płatności: wieloetapowe procesy, gdzie niektóre kroki są wolne, niedostępne lub wymagają kompensujących działań.
Co zwykle znaczy „soft real-time”
Większość produktów nie potrzebuje twardych gwarancji typu „każde działanie w 10 ms”. Potrzebują soft real-time: konsekwentnie niskich opóźnień dla typowych żądań, szybkiego odzyskiwania po awarii i wysokiej dostępności, by użytkownicy rzadko zauważali incydenty.
Awarie są normalne: projektuj na nie
Prawdziwe systemy doświadczają problemów takich jak:
- Zerwane połączenia (sieci mobilne, przełączenia Wi‑Fi)
- Timeouty gdy downstream jest wolny
- Częściowe przestoje w regionie lub zależności
Model Erlanga zachęca do izolowania każdej aktywności (sesja użytkownika, urządzenie, próba płatności), by awaria nie rozprzestrzeniała się. Zamiast jednego wielkiego komponentu „próbuj obsłużyć wszystko”, zespoły myślą w mniejszych jednostkach: każdy worker robi jedno zadanie, komunikuje się przez wiadomości i jeśli się psuje, zostaje czysto zrestartowany.
Ta zmiana perspektywy — z „zapobiegaj każdej awarii” na „ograniczaj i odzyskuj szybko” — często sprawia, że platformy czasu rzeczywistego zachowują stabilność pod presją.
Częste nieporozumienia i rzeczywiste ograniczenia
Reputacja Erlanga może brzmieć jak obietnica: systemy, które nigdy nie padają, bo po prostu się restartują. Rzeczywistość jest bardziej praktyczna — i użyteczna. „Let it crash” to narzędzie do budowy zależnych usług, nie pozwolenie na ignorowanie trudnych problemów.
Restarty to nie plaster na wszystko
Częsty błąd to traktowanie nadzoru jako sposobu ukrycia głębokich błędów. Jeśli proces pada natychmiast po starcie, supervisor może go stale restartować, doprowadzając do pętli crashów — spalania CPU, zalewu logów i większego przestoju niż pierwotny błąd.
Dobre systemy dodają backoff, limity intensywności restartów i jasne zachowanie „poddaj się i eskaluj”. Restarty powinny przywracać zdrowe działanie, a nie maskować złamaną inwariantę.
Stan to trudna część
Restart procesu jest często prosty; odzyskanie poprawnego stanu — nie. Jeśli stan istnieje tylko w pamięci, musisz zdecydować, co znaczy „poprawne” po crashu:
- Odbudować z trwałego magazynu?
- Odtworzyć zdarzenia (idempotentnie)?
- Co z pracą w toku lub częściowymi aktualizacjami?
Odporność nie zastępuje starannego projektowania danych. Zmusza do jawnego podejścia.
Nadal potrzebujesz obserwowalności
Crashes pomagają tylko, jeśli je wczesne zobaczysz i zrozumiesz. To oznacza inwestycję w logowanie, metryki i tracing — nie tylko „zrestartowano, więc OK”. Chcesz zauważyć narastające wskaźniki restartów, rosnące kolejki i wolne zależności zanim użytkownicy to poczują.
Istnieją realne limity operacyjne
Nawet przy zaletach BEAM, systemy mogą zawodzić zwykłymi sposobami:
- Wzrost pamięci spowodowany wyciekami, cache’ami lub dużymi heapami
- Zaleganie mailboxów gdy producenci przewyższają konsumentów (spadki i timeouty)
- Awaria zależności (bazy danych, API zewnętrzne, DNS), której restart kodu nie naprawi
Model Erlanga pomaga ograniczać i odzyskiwać awarie — nie eliminuje ich całkowicie.
Jak zastosować te lekcje dziś (nawet jeśli nie używasz Erlanga)
Największy dar Erlanga to nie składnia, lecz zestaw nawyków do budowy usług, które działają gdy części nieuchronnie zawodzą. Możesz zastosować te nawyki w niemal każdym stacku.
Przełóż idee na konkretne działania
Zacznij od jawnego określenia granic awarii. Podziel system na komponenty, które mogą zawieść niezależnie, i upewnij się, że każdy ma jasny kontrakt (wejścia, wyjścia i jak wygląda „źle”).
Następnie automatyzuj odzyskiwanie zamiast próbować zapobiec każdemu błędowi:
- Izoluj komponenty: uruchamiaj ryzykowną pracę w osobnych procesach/kontenerach/wątkach, by jeden crash nie zatruł wszystkiego.
- Zdefiniuj granice: timeouty, retry z backoffem, circuit-breakery i bulkhead’y, by zatrzymać kaskadowe awarie.
- Uczyń odzyskiwanie rutyną: health checki, auto-restarty i bezpieczne domyślne ustawienia, by system szybko wracał do znanego dobrego stanu.
Jednym praktycznym sposobem wdrożenia tych nawyków jest wbudowanie ich w narzędzia i cykl życia, nie tylko w kod. Na przykład workflowy w Koder.ai przy vibecodowaniu web, backendu czy aplikacji mobilnych przez chat naturalnie zachęcają do jawnego planowania (Planning Mode), powtarzalnych deploymentów i bezpiecznej iteracji ze snapshotami i rollbackami — koncepcje zgodne z operacyjnym mindsetem, który spopularyzował Erlang: zakładaj zmiany i awarie, i spraw, by odzyskiwanie było nudne.