Z prototypu do SaaS: gdzie zaczyna się zamieszanie
Prototyp dowodzi pomysłu. SaaS musi przetrwać prawdziwe użycie: szczytowy ruch, nieporządne dane, retry i klientów, którzy zauważają każdy potknięcie. Wtedy robi się niejasno, bo pytanie zmienia się z „czy to działa?” na „czy będzie działać dalej?”.
Przy prawdziwych użytkownikach „działało wczoraj” zawodzą z nudnych powodów. Zadanie backgroundowe uruchamia się później niż zwykle. Jeden klient przesyła plik 10x większy niż testowe dane. Dostawca płatności zaciąga się na 30 sekund. To nic egzotycznego, ale efekty domina stają się głośne, gdy części systemu zależą od siebie.
Większość złożoności pojawia się w czterech miejscach: dane (ten sam fakt istnieje w wielu miejscach i dryfuje), opóźnienia (wywołania po 50 ms czasem trwają 5 sekund), awarie (timeouty, częściowe aktualizacje, retry) i zespoły (różni ludzie wdrażają różne usługi w różnych terminach).
Prosty model mentalny pomaga: komponenty, komunikaty i stan.
Komponenty wykonują pracę (web, API, worker, baza). Komunikaty przenoszą pracę między komponentami (żądania, zdarzenia, zadania). Stan to to, co zapamiętujesz (zamówienia, ustawienia użytkownika, status rozliczeń). Ból skalowania to zazwyczaj niedopasowanie: wysyłasz komunikaty szybciej niż komponent nadąża albo aktualizujesz stan w dwóch miejscach bez jasnego źródła prawdy.
Klasyczny przykład to rozliczenia. Prototyp może tworzyć fakturę, wysyłać e‑mail i zmieniać plan użytkownika w jednym żądaniu. Pod obciążeniem e‑mail zwalnia, żądanie time‑outuje, klient próbuje ponownie i masz dwie faktury i jedną zmianę planu. Praca nad niezawodnością to głównie zapobieganie temu, by codzienne awarie stawały się bugami widocznymi dla klientów.
Przekuj koncepcje w zapisane decyzje
Większość systemów robi się trudniejsza, bo rosną bez porozumienia o tym, co musi być poprawne, co ma być szybkie, a co powinno się dziać przy awarii.
Zacznij od narysowania granicy tego, co obiecujesz użytkownikom. Wewnątrz tej granicy wymień działania, które muszą być poprawne za każdym razem (przenoszenie pieniędzy, kontrola dostępu, własność konta). Potem wymień obszary, gdzie „ostateczna poprawność” jest wystarczająca (liczniki analityki, indeksy wyszukiwania, rekomendacje). Ten podział zmienia mglistą teorię w priorytety.
Następnie zapisz źródło prawdy. To miejsce, gdzie fakty zapisuje się raz, trwale, z jasnymi regułami. Wszystko inne to dane pochodne zbudowane dla szybkości lub wygody. Jeśli widok pochodny jest uszkodzony, powinieneś być w stanie odbudować go z źródła prawdy.
Gdy zespoły utkną, zwykle pojawiają się te pytania, które ujawniają, co ważne:
- Jakich danych nie można nigdy stracić, nawet jeśli to je spowolni?
- Co da się odtworzyć z innych danych, nawet jeśli zajmie to godziny?
- Co może być nieaktualne i jak długo z punktu widzenia użytkownika?
- Która awaria jest dla was gorsza: duplikaty, brakujące zdarzenia czy opóźnienia?
Jeśli użytkownik zaktualizuje plan rozliczeniowy, dashboard może się opóźnić. Ale nie możesz tolerować rozbieżności między statusem płatności a faktycznym dostępem.
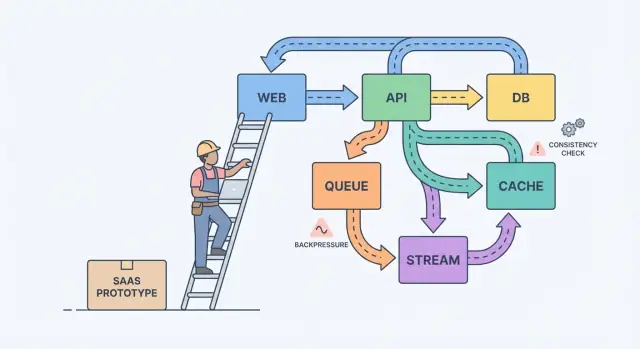
Strumienie, kolejki i logi: wybór kształtu pracy
Jeśli użytkownik klika przycisk i musi od razu zobaczyć rezultat (zapisz profil, załaduj dashboard, sprawdź uprawnienia), normalne API request‑response zwykle wystarcza. Trzymaj to bezpośrednio.
Gdy tylko praca może się odbyć później, przenieś ją do async. Pomyśl o wysyłaniu e‑maili, obciążaniu kart, generowaniu raportów, zmniejszaniu rozmiaru przesłanych plików, synchronizacji z wyszukiwarką. Użytkownik nie powinien czekać na to, a twoje API nie powinno być zajęte, dopóki to działa.
Kolejka to lista rzeczy do zrobienia: każde zadanie powinien obsłużyć jeden worker. Strumień (lub log) to zapis: zdarzenia są utrzymywane w kolejności, więc wielu czytelników może je replayować, nadrabiać zaległości lub budować nowe funkcje bez zmiany producenta.
Praktyczny sposób wyboru:
- Używaj request‑response, gdy użytkownik potrzebuje natychmiastowej odpowiedzi i praca jest mała.
- Użyj kolejki dla pracy w tle z retry, gdy tylko jeden worker powinien wykonać każde zadanie.
- Użyj strumienia/logu, gdy potrzebujesz replayu, śladu audytu lub wielu konsumentów, którzy nie powinni być powiązani z jedną usługą.
Przykład: w Twoim SaaS jest przycisk „Utwórz fakturę”. API waliduje dane i zapisuje fakturę w Postgres. Potem kolejka obsługuje „wyślij e‑mail z fakturą” i „obciąż kartę”. Jeśli później dodasz analitykę, powiadomienia i sprawdzanie fraudu, strumień InvoiceCreated pozwala każdej funkcji zasubskrybować zdarzenia bez zamieniania serwisu rdzeniowego w labirynt.
Projektowanie zdarzeń: co publikujesz i co przechowujesz
W miarę rozwoju produktu zdarzenia przestają być „miłe do posiadania” i stają się siatką bezpieczeństwa. Dobry projekt zdarzeń sprowadza się do dwóch pytań: jakie fakty zapisujesz i jak inne części produktu mogą reagować bez zgadywania?
Zacznij od małego zestawu zdarzeń biznesowych. Wybierz momenty, które mają znaczenie dla użytkowników i pieniędzy: UserSignedUp, EmailVerified, SubscriptionStarted, PaymentSucceeded, PasswordResetRequested.
Nazwy przeżywają kod. Używaj czasu przeszłego dla faktów zakończonych, bądź konkretny i unikaj nazewnictwa z UI. PaymentSucceeded pozostaje zrozumiałe, nawet jeśli później dodasz kupony, retry czy wielu dostawców płatności.
Traktuj zdarzenia jak kontrakty. Unikaj worka wszystkiego typu „UserUpdated” z polami zmieniającymi się co sprint. Wybieraj najmniejszy fakt, za który możesz ręczyć przez lata.
Aby bezpiecznie ewoluować, faworyzuj zmiany addytywne (nowe opcjonalne pola). Jeśli potrzebujesz zmiany łamiącej, opublikuj nową nazwę zdarzenia (lub explicite wersję) i uruchamiaj obie, dopóki starzy konsumenci nie znikną.
Co powinieneś przechowywać? Jeśli trzymasz tylko ostatnie wiersze w bazie danych, tracisz historię, jak do tego doszło.
Surowe zdarzenia są świetne do audytu, replayu i debugowania. Snapshorty są dobre do szybkich odczytów i szybkiego przywracania. Wiele produktów SaaS używa obu podejść: przechowuj surowe zdarzenia dla kluczowych workflow (rozliczenia, uprawnienia) i utrzymuj snapshoty do ekranów skierowanych do użytkownika.
Kompromisy spójności, które odczuwają użytkownicy
Buduj SaaS, nie slajdy
Przekształć decyzje skalowania w działającą aplikację React + Go + Postgres w jednym miejscu.
Spójność objawia się w momentach typu: „Zmieniłem plan, dlaczego nadal pokazuje Free?” albo „Wysłałem zaproszenie, dlaczego mój współpracownik nie może się zalogować?”
Silna spójność oznacza, że po otrzymaniu komunikatu o sukcesie każdy ekran powinien od razu pokazywać nowy stan. Ostateczna spójność oznacza, że zmiana rozprzestrzenia się w czasie i przez krótki okres różne części aplikacji mogą się nie zgadzać. Żadne z podejść nie jest „lepsze”. Wybierasz w oparciu o szkody, jakie może wyrządzić rozbieżność.
Silna spójność zwykle pasuje do pieniędzy, dostępu i bezpieczeństwa: obciążenie karty, zmiana hasła, unieważnianie kluczy API, egzekwowanie limitów miejsc. Ostateczna spójność często pasuje do kanałów aktywności, wyszukiwania, raportów analitycznych, „ostatnio widziany” i powiadomień.
Jeśli akceptujesz nieświeżość, projektuj to zamiast ją ukrywać. Uczciwie informuj UI: pokazuj stan „Aktualizuję…” po zapisie, aż przyjdzie potwierdzenie, oferuj ręczne odświeżenie list i używaj optymistycznego UI tylko wtedy, gdy możesz łatwo się wycofać.
Retry to miejsce, gdzie spójność robi się podstępna. Sieci zrywają się, klienci klikają dwa razy, workery restartują się. Dla ważnych operacji spraw, by żądania były idempotentne, aby powtórzenie tej samej akcji nie tworzyło dwóch faktur, dwóch zaproszeń czy dwóch zwrotów. Częstym podejściem jest idempotency key per action plus reguła po stronie serwera, aby zwracać oryginalny wynik dla powtórzeń.
Backpressure: jak nie dopuścić, by system się rozpuścił
Backpressure potrzebujesz, gdy żądania lub zdarzenia przychodzą szybciej, niż system jest w stanie przetworzyć. Bez niego praca gromadzi się w pamięci, kolejki rosną, a najwolniejsza zależność (często baza danych) decyduje, kiedy wszystko padnie.
Mówiąc prościej: producent gada dalej, a konsument się topi. Jeśli nadal przyjmujesz więcej pracy, nie tylko robi się wolniej. Uruchamiasz reakcję łańcuchową timeoutów i retry, która mnoży obciążenie.
Znaki ostrzegawcze zwykle widać zanim wystąpi outage: backlog rośnie, opóźnienia skaczą po skokach ruchu lub wdrożeniach, retry rosną razem z timeoutami, niepowiązane endpointy padają, gdy jedna zależność zwalnia, a połączenia do bazy siedzą na limicie.
Gdy osiągniesz ten punkt, wybierz jasną regułę, co się stanie, gdy będziesz pełny. Cel nie polega na przetwarzaniu wszystkiego za wszelką cenę. Chodzi o przetrwanie i szybkie odzyskanie. Zespoły zwykle zaczynają od jednego lub dwóch mechanizmów: rate limit (na użytkownika lub klucz API), ograniczone kolejki z jasną polityką odrzutu/opóźnienia, circuit breaker dla zawodzących zależności oraz priorytety, by żądania interaktywne wygrywały z zadaniami tła.
Chroń bazę danych w pierwszej kolejności. Trzymaj pule połączeń małe i przewidywalne, ustaw time‑outy zapytań i nałóż twarde limity na kosztowne endpointy jak ad‑hoc raporty.
Krok po kroku do niezawodności (bez przepisywania wszystkiego)
Niezawodność rzadko wymaga dużego przepisania. Zwykle wynika z kilku decyzji, które sprawiają, że awarie są widoczne, ograniczone i możliwe do odzyskania.
Zacznij od przepływów, które budują albo tracą zaufanie, a potem dodaj zabezpieczenia zanim dołożysz funkcje:
-
Zmapuj krytyczne ścieżki. Zapisz dokładne kroki dla signupu, logowania, resetu hasła i każdego flow płatności. Dla każdego kroku wypisz zależności (baza, provider e‑mail, worker). To wymusza jasność, co musi być natychmiastowe, a co może być naprawione „ostatecznie”.
-
Dodaj podstawy obserwowalności. Nadaj każdemu żądaniu ID, które pojawia się w logach. Śledź mały zestaw metryk odpowiadających bólowi użytkownika: wskaźnik błędów, opóźnienia, głębokość kolejek i wolne zapytania. Dodaj trace'y tylko tam, gdzie żądania przechodzą między usługami.
-
Izoluj wolną lub zawodną pracę. Wszystko, co rozmawia z zewnętrzną usługą lub regularnie trwa dłużej niż sekundę, powinno iść do jobów i workerów.
-
Projektuj pod retry i częściowe awarie. Zakładaj, że time‑outy się zdarzają. Rób operacje idempotentne, używaj backoff, ustawiaj limity czasowe i utrzymuj krótkie akcje widoczne dla użytkownika.
-
Ćwicz odzyskiwanie. Backupy mają znaczenie tylko wtedy, gdy potrafisz je przywrócić. Wydawaj małe releasy i trzymaj szybką ścieżkę rollbacku.
Jeśli twoje narzędzia wspierają snapshoty i rollback (Koder.ai to robi), wbuduj to w normalne nawyki wydawnicze zamiast traktować jako sztuczkę awaryjną.
Przykład: jak mały SaaS stał się wiarygodny
Buduj i zdobywaj kredyty
Dziel się tym, co zbudujesz, lub polecaj innych i zdobywaj kredyty na dalsze iteracje.
Wyobraź sobie mały SaaS pomagający zespołom onboardować nowych klientów. Przepływ jest prosty: użytkownik się rejestruje, wybiera plan, płaci i otrzymuje e‑mail powitalny oraz kilka kroków „jak zacząć”.
W prototypie wszystko dzieje się w jednym żądaniu: utwórz konto, obciąż kartę, ustaw flaga "paid" dla użytkownika, wyślij e‑mail. Działa, dopóki ruch nie urośnie, nie pojawią się retry i zewnętrzne usługi nie zaczną zwalniać.
Aby uczynić system niezawodnym, zespół rozbija kluczowe akcje na zdarzenia i trzyma append‑only historię. Wprowadzają kilka zdarzeń: UserSignedUp, PaymentSucceeded, EntitlementGranted, WelcomeEmailRequested. To daje ślad audytu, ułatwia analitykę i pozwala na wykonywanie wolnej pracy w tle bez blokowania rejestracji.
Kilka decyzji robi większość pracy:
- Traktuj płatności jako źródło prawdy dla dostępu, nie pojedynczy flagowy „paid”.
- Nadaj uprawnienia na podstawie
PaymentSucceeded z jasnym idempotency key, żeby retry nie dublowały przyznania.
- Wysyłaj e‑maile z kolejki/workerów, nie w żądaniu checkoutu.
- Rejestruj zdarzenia nawet jeśli handler zawiedzie, żeby móc replayować i odzyskać.
- Dodaj time‑outy i circuit breaker wokół providerów zewnętrznych.
Jeśli płatność powiedzie się, ale dostęp nie zostanie przyznany od razu, użytkownik czuje się oszukany. Naprawa to nie „perfekcyjna spójność wszędzie”. To decyzja, co musi być spójne teraz, i odzwierciedlenie tego w UI stanem takim jak „Aktywacja twojego planu” aż EntitlementGranted zostanie zapisane.
W złe dni backpressure robi różnicę. Jeśli API e‑maili zamarza podczas kampanii marketingowej, stary projekt timeoutuje checkouty i użytkownicy retryują, tworząc duplikaty opłat i e‑maile. W lepszym projekcie checkout przechodzi, żądania e‑maili trafiają do kolejki, a job replayujący opróżnia backlog, gdy provider wróci do zdrowia.
Typowe pułapki przy skalowaniu
Większość outage'ów nie jest wynikiem jednego heroicznego buga. Pojawiają się przez małe decyzje, które miały sens w prototypie, a potem stały się nawykiem.
Jedna pułapka to dzielenie na mikrousługi za wcześnie. Kończysz z usługami, które głównie się nawzajem wywołują, niejasną własnością i zmianami wymagającymi pięciu wdrożeń zamiast jednego.
Inna pułapka to traktowanie „ostatecznej spójności” jak darmowego przywileju. Użytkownicy nie dbają o terminologię. Chcą, żeby po kliknięciu Zapisz strona nie pokazywała później starych danych albo żeby status faktury nie skakał w przód i w tył. Jeśli akceptujesz opóźnienie, nadal potrzebujesz feedbacku dla użytkownika, timeoutów i definicji „wystarczająco dobrze” na każdym ekranie.
Inni powtarzający się winowajcy: publikowanie zdarzeń bez planu reprocessingu, nieograniczone retry mnożące obciążenie w czasie incydentu oraz pozwalanie każdemu serwisowi na bezpośredni dostęp do tego samego schematu bazy danych, tak że jedna zmiana łamie wiele zespołów.
Szybkie kontrole zanim nazwiesz to "gotowe do produkcji"
Wydawaj z pewnością
Wysyłaj małe zmiany z snapshotami i możliwością rollbacku, gdy ruch w produkcji zaskoczy.
„Gotowe do produkcji” to zestaw decyzji, które potrafisz wskazać o 2 w nocy. Jasność bije spryt.
Zacznij od nazwania źródeł prawdy. Dla każdego kluczowego typu danych (klienci, subskrypcje, faktury, uprawnienia) zdecyduj, gdzie znajduje się ostateczny rekord. Jeśli aplikacja czyta „prawdę” z dwóch miejsc, w końcu pokażesz różne odpowiedzi różnym użytkownikom.
Potem spójrz na retry. Zakładaj, że każda ważna akcja odpali się dwukrotnie w pewnym momencie. Jeśli to samo żądanie trafi dwa razy, czy możesz uniknąć podwójnego obciążenia, podwójnego wysłania czy podwójnego utworzenia?
Mała lista kontrolna, która łapie większość bolesnych awarii:
- Dla każdego typu danych potrafisz wskazać źródło prawdy i nazwać co jest pochodne.
- Każdy ważny zapis jest bezpieczny do powtórzenia (idempotency key lub unikatowe ograniczenie).
- Twoja praca asynchroniczna nie może rosnąć bez ograniczeń (monitorujesz lag, wiek najstarszej wiadomości i alertujesz zanim użytkownicy to zauważą).
- Masz plan zmiany (odwracalne migracje, wersjonowanie zdarzeń).
- Potrafisz cofnąć i przywrócić z pewnością, bo to ćwiczyłeś.
Następne kroki: podejmuj po jednej decyzji naraz
Skalowanie staje się prostsze, gdy traktujesz projekt systemu jako krótką listę decyzji, a nie stos teorii.
Zapisz 3–5 decyzji, których spodziewasz się w nadchodzącym miesiącu, prostym językiem: „Przenieść wysyłanie e‑maili do pracy w tle?” „Akceptujemy lekko nieaktualne dane analityczne?” „Które akcje muszą być natychmiastowo spójne?” Użyj tej listy, by zgrać produkt i inżynierię.
Następnie wybierz jeden workflow, który jest obecnie synchroniczny i skonwertuj tylko ten na async. Paragony, powiadomienia, raporty i przetwarzanie plików to częste pierwsze ruchy. Mierz dwie rzeczy przed i po: opóźnienie widoczne dla użytkownika (czy strona była szybsza?) i zachowanie przy awariach (czy retryy tworzyły duplikaty lub zamieszanie?).
Jeśli chcesz szybko prototypować te zmiany, Koder.ai (koder.ai) może być pomocne do iterowania nad React + Go + PostgreSQL SaaS, trzymając snapshoty i rollback w zasięgu ręki. Kryterium jest proste: wypuść jedno ulepszenie, naucz się z realnego ruchu, potem podejmij kolejną decyzję.