18 sie 2025·8 min
LLVM Chrisa Lattnera: cichy silnik współczesnych łańcuchów narzędzi
Dowiedz się, jak LLVM Chrisa Lattnera stało się modułową platformą kompilatora napędzającą języki i narzędzia — umożliwiając optymalizacje, lepsze diagnostyki i szybsze buildy.
Czym jest LLVM, prostym językiem
LLVM najlepiej wyobrazić sobie jako „silnik”, który dzielą ze sobą wiele kompilatorów i narzędzi developerskich.
Kiedy piszesz kod w języku takim jak C, Swift czy Rust, coś musi przetłumaczyć ten kod na instrukcje, które wykona procesor. Tradycyjny kompilator często budował każdy element tego pipeline'u samodzielnie. LLVM podchodzi do tego inaczej: dostarcza wysokiej jakości, wielokrotnego użytku rdzeń, który zajmuje się trudnymi i kosztownymi częściami — optymalizacją, analizą i generowaniem kodu maszynowego dla wielu typów procesorów.
Wspólna podstawa dla wielu języków
LLVM nie jest pojedynczym kompilatorem, którego „używasz bezpośrednio” w większości przypadków. To infrastruktura kompilatora: zestaw klocków, które zespoły tworzące języki mogą złożyć w pełny toolchain. Jedna grupa może skupić się na składni, semantyce i funkcjach widocznych dla dewelopera, a potem przekazać cięższą pracę LLVM.
Ta wspólna podstawa jest dużym powodem, dla którego nowoczesne języki mogą szybko dostarczać bezpieczne toolchainy bez odtwarzania na nowo dziesięcioleci pracy nad kompilatorami.
Dlaczego to ma znaczenie, nawet jeśli nie jesteś „osobą od kompilatorów”
LLVM pojawia się w codziennym doświadczeniu dewelopera:
- Szybkość: potrafi zamienić kod wysokiego poziomu w wydajny kod maszynowy na różnych platformach.
- Lepsze błędy i debugowanie: ekosystem wokół LLVM umożliwia bogatsze diagnostyki i lepsze narzędzia.
- Więcej niż „tylko kompilacja”: analiza statyczna, sanitizery, pokrycie kodu i inne pomocnicze narzędzia często budują się na tej samej reprezentacji i bibliotekach.
Co ten artykuł będzie (i czego nie będzie)
To przewodnik po ideach, które zapoczątkował Chris Lattner: jak zorganizowano LLVM, dlaczego środkowa warstwa ma znaczenie i jak pozwala ona na optymalizacje oraz wsparcie wielu platform. To nie jest podręcznik — skupimy się na intuicji i praktycznym wpływie zamiast formalnej teorii.
Pierwotna wizja Chrisa Lattnera
Chris Lattner to informatyk i inżynier, który będąc doktorantem na początku 2000-nych, zaczął pracę nad LLVM z praktycznej frustracji: technologia kompilatorów była potężna, ale trudna do ponownego użycia. Jeśli chciałeś nowy język programowania, lepsze optymalizacje lub wsparcie dla nowego CPU, często trzeba było grzebać w ściśle powiązanym „monolicznym” kompilatorze, gdzie każda zmiana miała efekty uboczne.
Problem, który chciał rozwiązać
W tamtych czasach wiele kompilatorów było budowanych jak jedna duża maszyna: część rozumiejąca język, część optymalizująca i część generująca kod maszynowy były głęboko splecione. To czyniło je skutecznymi dla ich pierwotnego zastosowania, ale kosztownymi w adaptacji.
Celem Lattnera nie był „kompilator dla jednego języka”. Chodziło o wspólną podstawę, która mogłaby zasilać wiele języków i narzędzi — bez konieczności, by każdy przepisywał te same skomplikowane elementy od nowa. Zakład był taki: jeśli uda się ustandaryzować środek pipeline'u, będzie można szybciej innowować na brzegach.
Dlaczego „modularna infrastruktura” była świeżym pomysłem
Kluczowa zmiana polegała na traktowaniu kompilacji jako zestawu oddzielnych bloków budowlanych z wyraźnymi granicami. W modularnym świecie:
- zespół języka może skupić się na parsowaniu i funkcjach dla dewelopera,
- zespół optymalizacyjny może poprawiać wydajność raz i dzielić się tym na szeroką skalę,
- wsparcie sprzętowe można dodać bez przeprojektowywania wszystkiego powyżej.
Ta separacja brzmi dziś oczywiście, ale wtedy przeczyła ewolucji wielu kompilatorów produkcyjnych.
Open source, stworzone do użycia przez innych
LLVM zostało szybko udostępnione jako open source, co miało znaczenie, ponieważ wspólna infrastruktura działa tylko wtedy, gdy wiele grup jej zaufa, może ją przejrzeć i rozszerzać. Z czasem uniwersytety, firmy i niezależni współpracownicy kształtowali projekt, dodając cele, poprawiając przypadki brzegowe, zwiększając wydajność i budując nowe narzędzia wokół niego.
Ten aspekt społeczności nie był tylko życzliwością — był częścią projektu: uczynić rdzeń szeroko użytecznym, a wtedy opłaca się go wspólnie utrzymywać.
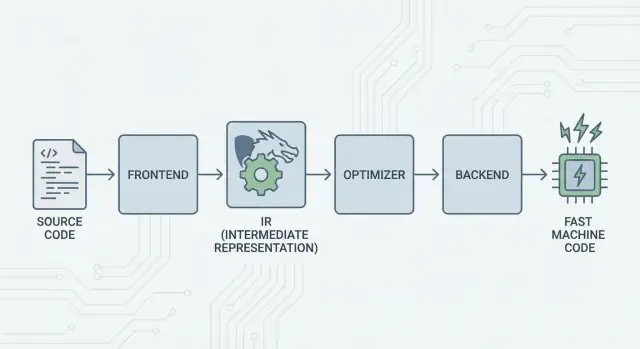
Wielka idea: frontendy, wspólny rdzeń i backendy
Główna myśl LLVM jest prosta: podziel kompilator na trzy główne części, aby wiele języków mogło współdzielić najtrudniejszą pracę.
1) Frontendy: „Co programista miał na myśli?”
Frontend rozumie konkretny język programowania. Czyta twój kod źródłowy, sprawdza reguły (składnię i typy) i zamienia go w uporządkowaną reprezentację.
Ważne: frontendy nie muszą znać wszystkich szczegółów procesora. Ich zadanie to przetłumaczyć koncepcje językowe — funkcje, pętle, zmienne — na coś bardziej uniwersalnego.
2) Wspólny środek: jeden rdzeń zamiast pracy N×M
Tradycyjnie budowa kompilatora oznaczała wykonywanie tej samej pracy wielokrotnie:
- Dla N języków i M celów sprzętowych kończysz z N×M kombinacjami do obsłużenia.
LLVM redukuje to do:
- N frontendów tłumaczących na wspólną formę
- M backendów tłumaczących tę formę na kod maszynowy
Ta „wspólna forma” to środek LLVM: wspólny pipeline, w którym żyją optymalizacje i analizy. To duże uproszczenie. Poprawki w środku (lepsze optymalizacje, lepsze informacje debugowania) mogą przynieść korzyść wielu językom naraz, zamiast być wdrażane w każdym kompilatorze osobno.
3) Backendy: „Jak sprawić, by to szybko działało na danym CPU?”
Backend bierze wspólną reprezentację i produkuje wynik specyficzny dla maszyny: instrukcje dla x86, ARM itd. Tutaj liczą się szczegóły takie jak rejestry, konwencje wywołań i wybór instrukcji.
Intuicyjny obraz pipeline'u
Pomyśl o kompilacji jak o trasie podróży:
- Kod źródłowy zaczyna w kraju specyficznym dla języka (frontend).
- Przekracza granicę do wspólnego, ustandaryzowanego „języka pośredniego” (rdzeń LLVM i jego przejścia).
- Potem jedzie lokalnym pociągiem do konkretnego miasta docelowego (backend dla docelowej maszyny).
W efekcie dostajesz modułowy toolchain: języki mogą skupić się na wyrażaniu pomysłów, a wspólny rdzeń LLVM — na ich efektywnym uruchomieniu na wielu platformach.
LLVM IR: środkowa warstwa, która umożliwia ponowne użycie
LLVM IR (Intermediate Representation) to „wspólny język” siedzący pomiędzy językiem programowania a kodem maszynowym, który wykonuje CPU.
Frontend kompilatora (jak Clang dla C/C++) tłumaczy twój kod źródłowy na tę wspólną formę. Potem optymalizatory i generatory kodu LLVM pracują na IR, a backend w końcu przekształca IR w instrukcje dla konkretnego celu (x86, ARM itd.).
Wspólny język między narzędziami a CPU
Pomyśl o LLVM IR jak o starannie zaprojektowanym moście:
- Nad nim: wiele języków może się podłączyć (C, C++, Rust, Swift, Julia itd.).
- Pod nim: można celować w wiele CPU.
- W środku: te same narzędzia analizy i optymalizacji mogą być użyte ponownie.
Dlatego często mówi się o LLVM jako o „infrastrukturze kompilatora”, a nie o „kompilatorze”. IR jest wspólnym kontraktem, który sprawia, że ta infrastruktura jest użyteczna wielokrotnie.
Dlaczego IR umożliwia ponowne użycie (i oszczędza pracę)
Po przetłumaczeniu kodu na LLVM IR większość przejść optymalizacyjnych nie musi wiedzieć, czy kod pochodzi z szablonów C++, iteratorów Rust czy generyków Swift. Zajmują się uniwersalnymi koncepcjami, takimi jak:
- „Ta wartość jest stała.”
- „To obliczenie się powtarza; czy możemy użyć wyniku ponownie?”
- „To odczytywanie pamięci można przesunąć lub usunąć bezpiecznie.”
Dzięki temu zespoły językowe nie muszą budować (i utrzymywać) własnego kompletnego stosu optymalizacyjnego. Mogą skupić się na frontendzie — parsowaniu, sprawdzaniu typów, regułach specyficznych dla języka — a potem przekazać resztę LLVM.
Jak to „wygląda” konceptualnie
LLVM IR jest wystarczająco niskopoziomowy, by mapować się czysto na kod maszynowy, ale wciąż na tyle uporządkowany, by go analizować. Koncepcyjnie składa się z prostych instrukcji (add, compare, load/store), jawnego przepływu sterowania (branch) i silnie typowanych wartości — bardziej przypomina uporządkowany język asembleropodobny zaprojektowany dla kompilatorów niż coś, co ludzie zwykle piszą ręcznie.
Jak działają optymalizacje (bez matematyki)
Gdy ludzie słyszą „optymalizacje kompilatora”, często wyobrażają sobie tajemnicze sztuczki. W LLVM większość optymalizacji lepiej rozumieć jako bezpieczne, mechaniczne przekształcenia programu — transformacje, które zachowują zachowanie programu, ale mają na celu szybsze lub mniejsze wykonanie.
Pomyśl o tym jak o edycji, nie wynajdywaniu na nowo
LLVM bierze twój kod (w LLVM IR) i wielokrotnie stosuje małe ulepszenia, trochę jak polerowanie szkicu:
- Usuwanie duplikatów pracy: jeśli jakaś wartość jest obliczana dwa razy i nic się między tym nie zmienia, LLVM może wykonać obliczenie raz i użyć wyniku.
- Uproszczenie oczywistej logiki: stałe wyrażenia można złożyć wcześniej (np. zamienić
3 * 4na12), więc CPU robi mniej w czasie wykonywania. - Usprawnianie pętli: przejścia związane z pętlami mogą zredukować powtarzane sprawdzenia, wyciągnąć stałe obliczenia poza pętlę lub rozpoznać wzorce, które można wykonać wydajniej.
Te zmiany są celowo zachowawcze. Przejście dokonuje przepisania tylko wtedy, gdy może udowodnić, że nie zmieni to znaczenia programu.
Przykłady z życia
Jeśli twój program robi w praktyce:
- Odczytuje tę samą wartość konfiguracyjną przy każdej iteracji pętli
- Wykonuje to samo obliczenie na tych samych danych w wielu miejscach
- Sprawdza warunek, który w danym kontekście jest zawsze prawdziwy/fałszywy
…LLVM stara się zamienić to w „zrób ustawienie raz”, „użyj wyniku ponownie” i „usuń martwe gałęzie”. To mniej magia, a więcej sprzątanie.
Rzeczywisty kompromis: czas kompilacji kontra czas działania
Optymalizacja nie jest darmowa: więcej analiz i więcej przejść zwykle oznacza wolniejszą kompilację, nawet jeśli finalny program działa szybciej. Dlatego toolchainy oferują poziomy takie jak „trochę optymalizuj” kontra „optymalizuj agresywnie”.
Profile mogą pomóc. Dzięki profile-guided optimization (PGO) uruchamiasz program, zbierasz dane o użyciu, a potem rekompilujesz, aby LLVM skupił wysiłek na ścieżkach, które naprawdę się liczą — czyniąc kompromis bardziej przewidywalnym.
Backendy: obsługa wielu CPU bez przepisywania wszystkiego
Posiadaj źródła
Zachowaj pełną kontrolę, eksportując kod źródłowy, gdy będziesz gotowy przejąć repozytorium.
Kompilator ma dwa bardzo różne zadania. Po pierwsze, musi zrozumieć twój kod źródłowy. Po drugie, musi wyprodukować kod maszynowy, który konkretny CPU może wykonać. Backendy LLVM skupiają się na tym drugim zadaniu.
Co backend właściwie robi
Traktuj LLVM IR jako „uniwersalny przepis” na to, co program ma robić. Backend zamienia ten przepis na dokładne instrukcje dla danej rodziny procesorów — x86-64 dla większości desktopów i serwerów, ARM64 dla wielu telefonów i nowszych laptopów, lub cele specjalizowane jak WebAssembly.
Konkretnie backend odpowiada za:
- Wybór instrukcji: mapowanie operacji IR na rzeczywiste instrukcje CPU
- Alokację rejestrów: wybór, które wartości żyją w szybkich rejestrach CPU, a które w pamięci
- Harmonogram: uporządkowanie instrukcji tak, by CPU mogło je wykonywać wydajnie
- Wyjście do asemblera/obiektu: emisję kodu, który rozumie linker i system operacyjny
Dlaczego współdzielona infrastruktura ułatwia wsparcie nowego sprzętu
Bez wspólnego rdzenia każdy język musiałby ponownie implementować to wszystko dla każdego CPU — ogrom pracy i stały koszt utrzymania.
LLVM odwraca to: frontend (np. Clang) produkuje LLVM IR raz, a backendy zajmują się „ostatnią milą” dla każdego celu. Dodanie wsparcia dla nowego CPU zwykle oznacza napisanie jednego backendu (lub rozszerzenie istniejącego), a nie przepisywanie każdego kompilatora.
Przenośność dla zespołów wypuszczających na wiele platform
Dla projektów, które muszą działać na Windows/macOS/Linux, na x86 i ARM, a nawet w przeglądarce, model backendów LLVM to praktyczna korzyść. Możesz trzymać jedną bazę kodu i w dużej mierze jeden pipeline budowania, a potem targetować różne platformy, wybierając inny backend (lub cross-kompilując).
Ta przenośność to powód, dla którego LLVM pojawia się wszędzie: nie chodzi tylko o szybkość — chodzi też o unikanie powtarzalnej, specyficznej dla platformy pracy przy kompilatorze, która spowalnia zespoły.
Clang: gdzie wielu deweloperów spotyka LLVM po raz pierwszy
Clang to frontend dla C, C++ i Objective-C, który podłącza się do LLVM. Jeśli LLVM jest wspólnym silnikiem, który może optymalizować i generować kod maszynowy, Clang jest częścią, która czyta pliki źródłowe, rozumie reguły języka i zamienia to, co napisałeś, w formę, z którą LLVM może pracować.
Dlaczego Clang został zauważony
Wielu deweloperów nie odkryło LLVM przez lekturę prac naukowych — spotkali się z nim, gdy zmienili kompilator i nagle feedback stał się czytelniejszy.
Diagnostyka Clang jest znana z tego, że jest bardziej czytelna i szczegółowa. Zamiast mglistych błędów, często wskazuje dokładny token, który spowodował problem, pokazuje odpowiedni wiersz i wyjaśnia, czego oczekiwał. To ma znaczenie na co dzień, bo pętla „kompiluj, popraw, powtórz” staje się mniej frustrująca.
Clang udostępnia też czytelne, dobrze udokumentowane interfejsy (m.in. przez libclang i szerszy ekosystem narzędzi Clang). Ułatwiło to edytorom, IDE i innym narzędziom głęboką integrację z rozumieniem języka bez odtwarzania parsera C/C++.
Jak to wpływa na codzienne przepływy pracy
Kiedy narzędzie potrafi niezawodnie parsować i analizować twój kod, zaczynasz dostawać funkcje, które mniej przypominają edycję tekstu, a bardziej pracę z uporządkowanym programem:
- Dokładna nawigacja po kodzie („przejdź do definicji”, „znajdź odwołania”) nawet w dużych projektach C++ z makrami
- Refaktoryzacje rozumiejące symbole i zakresy, a nie tylko wyszukaj-i-zamień
- Podpowiedzi inline i szybkie poprawki oparte na rzeczywistej składni i informacjach typów
Dlatego Clang jest często pierwszym punktem styku z LLVM: to stąd pochodzą praktyczne poprawy doświadczenia dewelopera. Nawet jeśli nigdy nie myślisz o LLVM IR czy backendach, korzystasz z ulepszeń, gdy autouzupełnianie jest mądrzejsze, statyczne kontrole dokładniejsze, a błędy kompilacji łatwiejsze do naprawienia.
Dlaczego wiele nowoczesnych języków buduje na LLVM
LLVM atrakcyjne jest dla zespołów językowych z prostego powodu: pozwala im skupić się na języku, zamiast spędzać lata na odtwarzaniu pełnego optymalizującego kompilatora.
Szybsze wprowadzenie na rynek
Budowa nowego języka już sama w sobie obejmuje parsowanie, sprawdzanie typów, diagnostykę, narzędzia pakietowe, dokumentację i wsparcie społeczności. Jeśli dodatkowo trzeba stworzyć produkcyjnej klasy optymalizator, generator kodu i wsparcie platform — wypuszczenie zajmuje dużo dłużej.
LLVM dostarcza gotowy rdzeń kompilacji: alokację rejestrów, wybór instrukcji, dojrzałe przejścia optymalizacyjne i cele dla popularnych CPU. Zespoły mogą podłączyć frontend, który obniży ich język do LLVM IR, a potem polegać na istniejącym pipeline, by wygenerować natywny kod dla macOS, Linuxa i Windows.
Wysoka wydajność (bez heroicznych wysiłków)
Optymalizatory i backendy LLVM to wynik długotrwałej inżynierii i ciągłych testów w realnym świecie. To przekłada się na solidną bazową wydajność dla języków, które go adoptują — często wystarczająco dobrą od początku i możliwą do poprawiania w miarę rozwoju LLVM.
Dlatego kilka znanych języków zbudowało się wokół LLVM:
- Swift używa LLVM do wygenerowania wysoko zoptymalizowanych binarek natywnych na platformy Apple.
- Rust polega na LLVM przy generowaniu kodu i wsparciu wielu architektur.
- Julia wykorzystuje LLVM, by umożliwić szybki kod numeryczny, w tym kompilację w czasie wykonywania dla wyspecjalizowanych zadań.
Nie każdy język potrzebuje LLVM
Wybór LLVM to kompromis, nie nakaz. Niektóre języki priorytetyzują bardzo małe binarki, ultra-szybką kompilację lub pełną kontrolę nad całym toolchainem. Inne mają już ugruntowane kompilatory (np. ekosystemy oparte na GCC) albo wolą prostsze backendy.
LLVM jest popularne, bo to silny domyślny wybór — nie dlatego, że to jedyna słuszna droga.
JIT i kompilacja w czasie wykonywania: szybkie pętle informacji zwrotnej
Skaluj w swoim tempie
Wybierz Free, Pro, Business lub Enterprise w zależności od tego, jak daleko chcesz zajść.
„Just-in-time” (JIT) kompilacja najłatwiej rozumieć jako kompilowanie w trakcie uruchamiania. Zamiast tłumaczyć cały kod z góry na finalny binarny plik, silnik JIT czeka, aż fragment kodu będzie potrzebny, a potem kompiluje tę część na gorąco — często korzystając z rzeczywistych informacji runtime (np. dokładnych typów i rozmiarów danych) do podejmowania lepszych decyzji.
Dlaczego JIT może wydawać się szybki
Skoro nie trzeba kompilować wszystkiego od razu, systemy JIT mogą dostarczyć szybkie sprzężenie zwrotne w pracy interaktywnej. Piszesz lub generujesz fragment kodu, uruchamiasz go natychmiast, a system kompiluje tylko to, co teraz potrzebne. Jeśli ten sam kod jest wykonywany wielokrotnie, JIT może zapamiętać skompilowany wynik lub przebudować „gorące” sekcje bardziej agresywnie.
Gdzie kompilacja w czasie wykonywania pomaga w praktyce
JIT sprawdza się, gdy obciążenia są dynamiczne lub interaktywne:
- REPL-e i notebooki: natychmiastowa ewaluacja fragmentów z zachowaniem prędkości natywnej dla ciężkich pętli.
- Pluginy i rozszerzenia: aplikacje mogą ładować kod użytkownika w czasie działania i kompilować go dla docelowego CPU.
- Dynamiczne obciążenia: profilowanie w czasie wykonywania może wskazać, które ścieżki warto optymalizować.
- Obliczenia naukowe: generowane jądra (dla konkretnego rozmiaru macierzy, kształtu modelu lub cechy sprzętowej) można kompilować na żądanie.
Rola LLVM (bez nadmiernego szumu)
LLVM nie sprawia magicznie, że każdy program jest szybszy, i samo w sobie nie jest kompletnym JIT-em. Dostarcza jednak zestaw narzędzi: dobrze zdefiniowany IR, dużą liczbę przejść optymalizacyjnych i generację kodu dla wielu CPU. Projekty mogą budować silniki JIT na tych blokach, wybierając kompromis między czasem startu, maksymalną wydajnością i złożonością.
Wydajność, przewidywalność i realne kompromisy
Toolchainy oparte na LLVM mogą generować bardzo szybki kod — ale „szybki” nie jest jedną, stałą właściwością. Zależy od wersji kompilatora, docelowego CPU, ustawień optymalizacji, a nawet od założeń, które kompilator może zrobić o programie.
Dlaczego „ten sam kod, różne wyniki” się zdarzają
Dwa kompilatory mogą czytać ten sam kod źródłowy (C/C++/Rust/Swift) i dalej generować zauważalnie różny kod maszynowy. Część z tego jest zamierzona: każdy kompilator ma zestaw przejść optymalizacyjnych, heurystyk i domyślnych ustawień. Nawet w ramach LLVM, Clang 15 i Clang 18 mogą podejmować inne decyzje dotyczące inline'owania, wektoryzacji pętli czy harmonogramowania instrukcji.
Może to też wynikać z niezdefiniowanego zachowania i zachowania nieokreślonego w języku. Jeśli program przypadkowo polega na czymś, czego standard nie gwarantuje (np. przepełnienie liczby całkowitej ze znakiem w C), różne kompilatory — lub różne flagi — mogą „optymalizować” w sposób zmieniający wyniki.
Determinizm, buildy debugowe i release
Ludzie często oczekują, że kompilacja będzie deterministyczna: te same wejścia, te same wyjścia. W praktyce zbliżysz się do tego, ale nie zawsze otrzymasz identyczne binaria między środowiskami. Ścieżki builda, sygnatury czasowe, kolejność linkowania, dane z profile-guided, oraz wybory LTO mogą wpłynąć na finalny artefakt.
Bardziej praktyczny rozróżnik to debug vs. release. Buildy debugowe zwykle wyłączają wiele optymalizacji, aby zachować możliwość krokowego debugowania i czytelne ślady stosu. Buildy release włączają agresywne transformacje, które mogą zmieniać kolejność kodu, inline'ować funkcje i usuwać zmienne — świetne dla wydajności, ale czasem trudniejsze do debugowania.
Praktyczna rada: mierz, nie zgaduj
Traktuj wydajność jako problem pomiarowy:
- Benchmarkuj na reprezentatywnym sprzęcie i na realistycznych danych.
- Rozgrzewaj cache i uruchamiaj wiele iteracji.
- Porównuj buildy z jawnie ustawionymi flagami (np. zmieniając
-O2vs-O3, włączając/wyłączając LTO, lub wybierając-march).
Małe zmiany flag mogą przesunąć wydajność w obu kierunkach. Najbezpieczniejszy workflow to: postaw hipotezę, zmierz ją i trzymaj benchmarki blisko tego, co robią twoi użytkownicy.
Narzędzia poza kompilacją: analiza, debugowanie i bezpieczeństwo
Zaplanuj przed kodowaniem
Najpierw zaplanuj funkcje i zadania, a potem pozwól Koder.ai wygenerować szkielet.
LLVM często opisuje się jako zestaw narzędzi kompilacyjnych, ale wielu deweloperów odczuwa jego wpływ przez narzędzia, które „siedzą wokół” procesu kompilacji: analizatory, debugery i mechanizmy wykrywania błędów, które można włączać podczas buildów i testów.
Analiza i instrumentacja jako „dodatki”
Ponieważ LLVM eksponuje dobrze zdefiniowaną reprezentację pośrednią (IR) i pipeline przejść, naturalne jest budowanie dodatkowych kroków, które inspekcjonują lub przepisują kod w celu innym niż szybkość. Przejście może wstawić liczniki do profilowania, oznaczyć podejrzane operacje pamięci albo zebrać dane o pokryciu kodu.
Kluczowe jest to, że te funkcje można zintegrować bez tego, żeby każdy zespół językowy odtwarzał tę samą infrastrukturę.
Sanitizery: łapanie błędów blisko źródła
Clang i LLVM spopularyzowały rodzinę runtime'owych „sanitizerów”, które instrumentują programy, aby wykrywać typowe klasy błędów podczas testów — pomyśl o odczytach poza granicami pamięci, use-after-free, wyścigach danych i wzorcach niezdefiniowanego zachowania. To nie są magiczne tarcze i zwykle spowalniają programy, więc używa się ich głównie w CI i przed wydaniem. Jednak gdy się uruchomią, często wskazują precyzyjne miejsce w źródle i czytelne wyjaśnienie — dokładnie to, czego zespoły potrzebują przy ściganiu przerywalnych crashy.
Lepsza diagnostyka = szybsze wdrożenie nowych osób
Jakość narzędzi to także jakość komunikacji. Jasne ostrzeżenia, konkretne komunikaty o błędach i spójne informacje debugowania zmniejszają „czynnik tajemnicy” dla nowych osób. Gdy toolchain wyjaśnia co się stało i jak to naprawić, deweloperzy spędzają mniej czasu na zapamiętywaniu dziwactw kompilatora, a więcej na nauce kodu bazy.
LLVM nie gwarantuje sam z siebie idealnych diagnostyk czy bezpieczeństwa, ale daje wspólną podstawę, która sprawia, że narzędzia skierowane do deweloperów są praktyczne do budowy, utrzymania i współdzielenia.
Kiedy użyć LLVM (a kiedy nie)
LLVM najlepiej myśleć jako „zbuduj-własny-kompilator i zestaw narzędzi”. Ta elastyczność to właśnie powód, dla którego zasila tak wiele nowoczesnych toolchainów — ale też powoduje, że nie jest to odpowiedź na każde zadanie.
Kiedy LLVM jest dobrym wyborem
LLVM błyszczy, gdy chcesz ponownie użyć poważnej inżynierii kompilatora zamiast odtwarzać ją od zera.
Jeśli budujesz nowy język programowania, LLVM może dać sprawdzony pipeline optymalizacyjny, dojrzałą generację kodu dla wielu CPU i drogę do dobrego debugowania.
Jeśli wypuszczasz aplikacje wieloplatformowe, ekosystem backendów LLVM redukuje pracę potrzebną do targetowania różnych architektur. Skupiasz się na języku lub logice produktu, zamiast pisać oddzielne generatory kodu.
Jeśli twoim celem są narzędzia developerskie — linters, analiza statyczna, nawigacja po kodzie, refaktoryzacje — LLVM (i szerszy ekosystem) to mocna podstawa, ponieważ kompilator już „rozumie” strukturę kodu i typy.
Kiedy może być overkill
LLVM może być „ciężkie”, jeśli pracujesz nad malutkimi systemami wbudowanymi, gdzie rozmiar builda, pamięć i czas kompilacji są ściśle ograniczone.
Może też nie pasować do bardzo wyspecjalizowanych pipeline'ów, gdzie nie chcesz uniwersalnych optymalizacji albo gdy twój „język” jest bliższy prostemu DSL z bezpośrednim mapowaniem na kod maszynowy.
Prosta lista kontrolna
Zadaj sobie trzy pytania:
- Czy musimy targetować wiele platform/CPU teraz lub w niedalekiej przyszłości?
- Czy skorzystamy z istniejących optymalizacji i informacji debugowania, zamiast budować je od zera?
- Czy cenimy ścieżkę ekosystemową (narzędzia, integracje, łatwość rekrutacji) bardziej niż minimalny, dedykowany kompilator?
Jeśli odpowiedziałeś „tak” na większość, LLVM zwykle jest praktycznym wyborem. Jeśli głównie chcesz najmniejszy, najprostszy kompilator rozwiązujący wąski problem, lżejsze podejście może wygrać.
Uwaga praktyczna dla zespołów produktowych: korzyści LLVM bez zostawania ekspertami od kompilatorów
Większość zespołów nie chce „przyjąć LLVM” jako projektu. Chcą rezultatów: buildów na wielu platformach, szybkich binarek, dobrej diagnostyki i niezawodnych narzędzi.
To jeden z powodów, dla których platformy takie jak Koder.ai są interesujące w tym kontekście. Jeśli twój workflow coraz bardziej opiera się na automatyzacji wysokiego poziomu (planowanie, generowanie szkieletów, iteracje w krótkiej pętli), nadal czerpiesz korzyści z LLVM pośrednio przez toolchainy pod spodem — niezależnie od tego, czy budujesz aplikację React, backend w Go z PostgreSQL, czy mobilny klient we Flutter. Podejście chat-driven do „vibe-coding” Koder.ai skupia się na szybszym dostarczaniu produktu, podczas gdy nowoczesna infrastruktura kompilatorów (LLVM/Clang i towarzysze, gdy mają zastosowanie) dalej wykonuje mało efektowną pracę optymalizacji, diagnostyki i przenośności w tle.