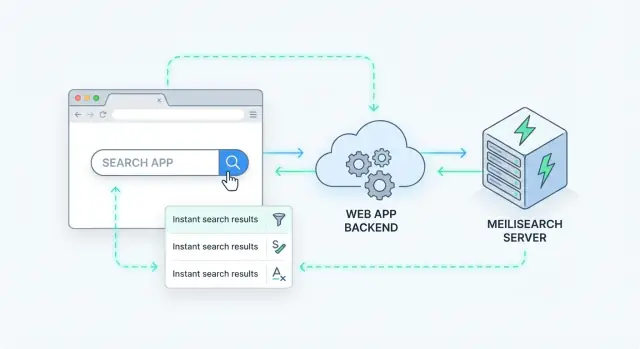
Co powinno zapewniać błyskawiczne wyszukiwanie po stronie serwera
Wyszukiwanie po stronie serwera oznacza, że zapytanie jest przetwarzane na Twoim serwerze (lub w dedykowanej usłudze wyszukiwania), a nie w przeglądarce. Twoja aplikacja wysyła żądanie wyszukiwania, serwer uruchamia je przeciwko indeksowi i zwraca posortowane wyniki.
To ma znaczenie, gdy Twoje dane są za duże, by wysyłać je do klienta, gdy potrzebujesz spójnej trafności na różnych platformach, albo gdy kontrola dostępu jest niezbędna (np. w narzędziach wewnętrznych, gdzie użytkownicy powinni widzieć tylko to, do czego mają dostęp). To też domyślny wybór, gdy chcesz mieć analitykę, logowanie i przewidywalną wydajność.
Czego użytkownicy oczekują (i zauważają od razu)
Ludzie nie myślą o silnikach wyszukiwania—oceniają doświadczenie. Dobry „błyskawiczny” przepływ zwykle oznacza:
- Szybka informacja zwrotna: wyniki aktualizują się szybko, gdy użytkownik wpisuje, bez niezręcznych przerw.
- Literówki nie psują wyszukiwania: błędy pisowni, zamienione litery i częściowe słowa nadal znajdują właściwe pozycje.
- Przydatne kontrolki: filtrowanie (kategoria, status, zakres cen), sortowanie (najnowsze, najtańsze) i fasety (liczniki przy filtrach) działają naturalnie.
- Istotne uporządkowanie: „najlepsze” wyniki pojawiają się pierwsze, nie tylko najnowsze czy najbardziej upakowane słowami kluczowymi.
Jeśli czegoś z tego brakuje, użytkownicy będą próbować innych zapytań, przewijać więcej albo porzucać wyszukiwanie.
Co pomoże Ci zrobić ten przewodnik
Ten artykuł to praktyczny przewodnik po budowie takiego doświadczenia z Meilisearch. Omówimy bezpieczną konfigurację, strukturę i synchronizację danych, strojenie trafności i reguł rankingowych, dodawanie filtrów/sortowania/faset, oraz kwestie bezpieczeństwa i skalowania, by wyszukiwanie pozostało szybkie wraz z rozwojem aplikacji.
Gdzie wyszukiwanie po stronie serwera świeci najlepiej
Meilisearch świetnie nadaje się do:
- Dokumentacji i baz wiedzy (szybkie znajdowanie stron, tolerancja literówek)
- Katalogów produktów i rynków (filtrowanie i sortowanie są kluczowe)
- Narzędzi wewnętrznych (wyszukiwanie z uwzględnieniem uprawnień)
- Serwisów treści (wyszukiwanie w artykułach, przewodnikach, FAQ)
Celem jest: wyniki, które wydają się natychmiastowe, dokładne i wiarygodne—bez przemiany wyszukiwania w dużą pracę inżynierską.
Meilisearch — przegląd prostym językiem
Meilisearch to silnik wyszukiwania, który uruchamiasz obok swojej aplikacji. Wysyłasz mu dokumenty (np. produkty, artykuły, użytkowników, zgłoszenia), a on buduje indeks zoptymalizowany pod szybkie wyszukiwanie. Twój backend (lub frontend) zapytuje Meilisearch przez prosty HTTP API i otrzymuje posortowane wyniki w milisekundach.
Co otrzymujesz od razu
Meilisearch koncentruje się na funkcjach, których oczekują użytkownicy nowoczesnego wyszukiwania:
- Tolerancja literówek, dzięki czemu „iphnoe” może znaleźć „iPhone”.
- Kontrola trafności (reguły rankingowe), żebyś mógł określić, co oznacza „najlepsze dopasowanie” dla Twojego biznesu.
- Filtry, sortowanie i fasety, by użytkownicy mogli zawęzić wyniki według kategorii, zakresu cen, dostępności czy tagów.
Został zaprojektowany tak, by być responsywnym i wyrozumiałym, nawet gdy zapytanie jest krótkie, nieprecyzyjne lub niejasne.
Czym Meilisearch nie jest
Meilisearch nie zastępuje Twojej bazy danych. Baza pozostaje źródłem prawdy dla zapisów, transakcji i ograniczeń. Meilisearch przechowuje kopię tych pól, które wybierzesz jako przeszukiwalne, filtrowalne lub wyświetlane.
Dobry model myślowy: baza danych do przechowywania i aktualizacji, Meilisearch do szybkiego odnajdywania.
Oczekiwania wydajności (co wpływa na szybkość)
Meilisearch może być bardzo szybki, ale wyniki zależą od kilku praktycznych czynników:
- Rozmiar i kształt danych (liczba dokumentów, liczba pól, ile tekstu indeksujesz)
- Sprzęt (CPU, RAM, dysk)
- Konfiguracja (które atrybuty są przeszukiwalne/filtrowalne/sortowalne i jak często reindeksujesz)
Dla małych i średnich zestawów danych często wystarczy jedna maszyna. Wraz ze wzrostem indeksu warto staranniej wybierać, co indeksować i jak utrzymywać synchronizację — tematy, które omówimy dalej.
Planowanie indeksów i modelu danych
Zanim cokolwiek zainstalujesz, zdecyduj, czego faktycznie będziesz szukać. Meilisearch będzie „błyskawiczny” tylko wtedy, gdy Twoje indeksy i dokumenty będą odpowiadać na sposób, w jaki użytkownicy przeglądają aplikację.
Mapowanie encji do indeksów
Zacznij od listy przeszukiwalnych encji — zwykle produkty, artykuły, użytkownicy, dokumentacja, lokalizacje itd. W wielu aplikacjach najczystszym podejściem jest jeden indeks na typ encji (np. products, articles). Utrzymuje to reguły rankingowe i filtry przewidywalne.
Jeśli UX wymaga „szukaj wszystkiego” w jednym polu, możesz trzymać osobne indeksy i scalać wyniki na backendzie albo stworzyć dedykowany indeks „globalny” później. Nie zmuszaj wszystkiego do jednego indeksu, jeśli pola i filtry nie są zgodne.
Wybierz klucz główny i kształt dokumentu
Każdy dokument potrzebuje stabilnego identyfikatora (klucz główny). Wybierz coś, co:
- nigdy się nie zmienia (lub bardzo rzadko)
- jest unikalne w indeksie
- już istnieje w bazie (np.
id, sku, slug)
Dla kształtu dokumentu preferuj pola płaskie. Są łatwiejsze do filtrowania i sortowania. Zagnieżdżone pola są ok, jeśli reprezentują zwartą, niezmienną paczkę (np. obiekt author), ale unikaj głębokiego zagnieżdżania, które odzwierciedla całą relacyjną strukturę bazy—dokumenty wyszukiwania powinny być optymalizowane pod odczyt, nie kształtem bazy.
Klasyfikacja pól: przeszukiwalne, filtrowalne, wyświetlane
Praktyczny sposób projektowania dokumentów to przypisanie roli każdemu polu:
- Przeszukiwalne: tekst, który wpisuje użytkownik (tytuł, nazwa, opis)
- Filtrowalne: atrybuty używane jako ograniczenia (kategoria, zakres cen, status, tagi)
- Wyświetlane: co zwracasz do UI (tytuł, URL miniaturki, krótki fragment)
To zapobiega powszechnemu błędowi: indeksowaniu pola „na wszelki wypadek” i późniejszemu zdziwieniu, dlaczego wyniki są hałaśliwe albo filtry wolne.
Planowanie treści wielojęzycznych
„Język” może oznaczać różne rzeczy w Twoich danych:
- język dokumentu (np.
lang: "en")
- lokalizacja użytkownika (język UI)
- pola z mieszanymi językami (nazwy produktów w wielu językach)
Zdecyduj wcześniej, czy użyjesz osobnych indeksów per język (proste i przewidywalne) czy jednego indeksu z polami językowymi (mniej indeksów, więcej logiki). Wybór zależy od tego, czy użytkownicy szukają zazwyczaj w jednym języku naraz i jak przechowujesz tłumaczenia.
Instalacja i uruchomienie Meilisearch bezpiecznie
Uruchomienie Meilisearch jest proste, ale „bezpieczne domyślnie” wymaga kilku świadomych decyzji: gdzie go wdrożyć, jak przechowywać dane i jak obsługiwać master key.
Opcje wdrożenia (wybierz to, czym potraficie zarządzać)
- Docker (najpopularniejsze): szybkie uruchomienie, łatwa aktualizacja, spójne środowiska. Używaj z woluminem trwałym.
- VM lub bare metal: dobre, gdy macie standardowy pipeline wdrożeniowy Linux (systemd, rotacja logów, backupy).
- Hosting zarządzany: jeśli zespół nie chce utrzymywać serwerów, poszukaj dostawcy zarządzanego Meilisearch lub platformy oferującej go jako dodatek. Tracisz trochę elastyczności, ale ułatwiasz operacje.
Podstawy środowiska: przechowywanie, pamięć, backupy, monitoring
Storage: Meilisearch zapisuje indeks na dysku. Umieść katalog danych na niezawodnym, trwałym dysku (nie na efemerycznym storage kontenera). Planuj pojemność na wzrost: indeksy mogą szybko rosnąć przy dużych polach tekstowych i wielu atrybutach.
Pamięć: przydziel wystarczająco RAM, by wyszukiwanie było responsywne. Jeśli zauważysz swapowanie, wydajność spadnie.
Backupy: rób kopie katalogu danych Meilisearch (lub używaj snapshotów na poziomie storage). Przetestuj przywracanie przynajmniej raz; backup, którego nie da się przywrócić, to tylko plik.
Monitoring: monitoruj CPU, RAM, użycie dysku i I/O dysku. Również obserwuj zdrowie procesu i logi. Przynajmniej ustaw alerty na zatrzymanie usługi i niski wolny dysk.
Ustaw i przechowuj master key bezpiecznie
Zawsze uruchamiaj Meilisearch z master key poza lokalnym developmentem. Przechowuj go w managerze sekretów lub zaszyfrowanym magazynie środowiskowym (nie w Git, nie w jawnych .env w repozytorium).
Przykład (Docker):
docker run -d --name meilisearch \\
-p 7700:7700 \\
-v meili_data:/meili_data \\
-e MEILI_MASTER_KEY="$(openssl rand -hex 32)" \\
getmeili/meilisearch:latest
Rozważ też reguły sieciowe: binduj na prywatny interfejs lub ogranicz dostęp tak, aby tylko backend mógł łączyć się z Meilisearch.
Lista kontrolna przed startem
curl -s http://localhost:7700/version
Indeksowanie dokumentów i utrzymanie synchronizacji
Bring search to mobile
Generate a Flutter client that calls your backend search endpoint consistently.
Indeksowanie w Meilisearch jest asynchroniczne: wysyłasz dokumenty, Meilisearch dodaje zadanie do kolejki i dopiero po zakończeniu tego zadania dokumenty stają się przeszukiwalne. Traktuj indeksowanie jak system kolejkowy, nie pojedyncze żądanie.
Prosty flow indeksowania (dodaj → poczekaj → zweryfikuj)
- Dodaj dokumenty (upewnij się, że każdy ma stabilne, unikalne id, zwykle
id).
curl -X POST 'http://localhost:7700/indexes/products/documents?primaryKey=id' \\
-H 'Content-Type: application/json' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY' \\
--data-binary @products.json
- Poczekaj na zadanie. Odpowiedź API zawiera
taskUid. Polluj, aż będzie succeeded (lub failed).
curl -X GET 'http://localhost:7700/tasks/123' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY'
- Zweryfikuj liczniki i proste wyszukiwanie. Potwierdź, że indeks ma oczekiwaną liczbę dokumentów i że proste zapytanie zwraca wyniki.
curl -X GET 'http://localhost:7700/indexes/products/stats' \\
-H 'Authorization: Bearer YOUR_WRITE_KEY'
Jeśli liczby się nie zgadzają, nie zgaduj—sprawdź najpierw szczegóły błędu zadania.
Batching, który nie zaskoczy Cię później
Batching polega na utrzymaniu zadań przewidywalnych i możliwych do odzyskania.
- Zacznij od 1,000–10,000 dokumentów na batch, lub ograniczaj rozmiar payloadu (dla wielu aplikacji 5–15 MB na żądanie to komfortowy zakres).
- Preferuj wiele mniejszych batchy zamiast jednego ogromnego; łatwiej je powtórzyć i łatwiej zlokalizować złe dane.
- Jeśli masz częste zmiany, indeksuj ciągle w batchach (np. co minutę) zamiast przebudowywać wszystko.
Aktualizacje vs pełny reindex
addDocuments działa jak upsert: dokumenty z tym samym kluczem głównym są aktualizowane, nowe wstawiane. Używaj tego do normalnych aktualizacji.
Przeprowadź pełny reindex gdy:
- znacznie zmieniłeś kształt dokumentów,
- musisz przeliczyć pola pochodne,
- synchronizacja zboczyła i chcesz czyste reset.
Aby usuwać, wywołaj deleteDocument(s); w przeciwnym razie stare rekordy mogą się utrzymywać.
Idempotencja: bezpieczne powtórki gdy zadania zawodzą
Indeksowanie powinno być możliwe do powtórzenia. Kluczem są stabilne id dokumentów.
- Jeśli przesyłanie batcha wygaśnie, możesz wysłać ten sam batch ponownie: upsert + stabilne id zapobiega duplikatom.
- Przechowuj zwrócone
taskUid razem z id batcha/jobu i wykonuj retry na podstawie statusu zadania.
- Jeśli masz kolejkę, zrób worker „at-least-once” bezpieczny: duplikaty nie powinny szkodzić.
Dane początkowe do szybkiego testu przed produkcją
Przed danymi produkcyjnymi zaindeksuj mały zestaw (200–500 elementów) odpowiadający prawdziwym polom. Przykład: zestaw products z id, name, description, category, brand, price, inStock, createdAt. To wystarczy, by zweryfikować flow zadań, liczniki i zachowanie update/delete—bez czekania na masowy import.
Trafność i reguły rankingowe, nad którymi masz kontrolę
„Trafność” wyszukiwania to po prostu: co pojawia się pierwsze i dlaczego. Meilisearch pozwala to regulować bez konieczności tworzenia własnego systemu punktacji.
Zacznij od właściwych atrybutów
Dwa ustawienia określają, co Meilisearch może zrobić z Twoimi treściami:
searchableAttributes: pola, w których Meilisearch szuka, gdy użytkownik wpisuje zapytanie (np. title, summary, tags). Kolejność ma znaczenie: wcześniejsze pola są traktowane jako ważniejsze.displayedAttributes: pola zwracane w odpowiedzi. Ma to znaczenie dla prywatności i rozmiaru payloadu—jeśli pole nie jest wyświetlane, nie zostanie odesłane.
Praktyczna baza to kilka pól o wysokim sygnale jako przeszukiwalne (tytuł, kluczowy tekst) i ograniczenie wyświetlanych pól do tego, czego UI potrzebuje.
Jak reguły rankingowe wpływają na kolejność wyników
Meilisearch sortuje pasujące dokumenty używając reguł rankingowych—potoku „rozstrzygaczy”. W uproszczeniu preferuje:
- wyniki dobrze pasujące do zapytania (w tym tolerancję literówek), następnie
- wyniki, gdzie dopasowania są silniejsze (bliżej, w ważniejszych atrybutach), potem
- wyniki pasujące do logiki biznesowej (sortowanie po świeżości, popularności).
Nie musisz zapamiętywać szczegółów implementacji, by skutecznie je stroić; głównie wybierasz które pola są ważne i kiedy zastosować własne sortowanie.
Typowe cele strojenia (z przykładami)
Cel: „Dopasowania w tytule powinny wygrywać.” Umieść title jako pierwsze:
{
"searchableAttributes": ["title", "subtitle", "description", "tags"]
}
Cel: „Nowsza treść powinna być pierwsza.” Dodaj pole do sortowania i sortuj przy zapytaniu (lub ustaw custom ranking):
{
"sortableAttributes": ["publishedAt"],
"rankingRules": ["sort", "typo", "words", "proximity", "attribute", "exactness"]
}
Następnie wykonaj zapytanie:
{ "q": "release notes", "sort": ["publishedAt:desc"] }
Cel: „Promuj popularne pozycje.” Uczyń popularity sortowalnym i sortuj według niego, gdy to właściwe.
Oceń zmiany prostym testem before/after
Wybierz 5–10 rzeczywistych zapytań użytkowników. Zapisz top wyniki przed zmianami, potem porównaj po.
Przykład:
- Przed: zapytanie
"apple" → Apple Watch band, Pineapple slicer, Apple iPhone case
- Po (tytuł-przede wszystkim + exactness): zapytanie
"apple" → Apple iPhone case, Apple Watch band, Pineapple slicer
Jeśli lista „po” lepiej odzwierciedla intencję użytkownika, zachowaj ustawienia. Jeśli psuje przypadki brzegowe, zmieniaj jedną rzecz naraz (kolejność atrybutów, potem reguły sortowania), żeby wiedzieć, co spowodowało poprawę.
Filtry, sortowanie i fasety dla wyszukiwania w realnym świecie
Dobre pole wyszukiwania to nie tylko „wpisz słowa, dostaniesz dopasowania”. Ludzie chcą też zawęzić wyniki („tylko dostępne”) i ustawić porządek („najtańsze najpierw”). W Meilisearch robisz to za pomocą filtrów, sortowania i faset.
Filtry i fasety (ten sam pomysł, różny UI)
Filtr to reguła, którą stosujesz do zbioru wyników. Faseta to to, co pokazujesz w UI, by pomóc użytkownikom budować te reguły (zwykle checkboxy lub liczniki).
Przykłady niefachowe:
- Kategoria: „Buty”, „Kurtki”, „Akcesoria”
- Cena: „Do 50$”, „50–100$”
- Status: „Dostępne”, „Na zamówienie”, „Archiwalne”
Użytkownik może wyszukać „running”, a potem przefiltrować do category = Shoes i status = in_stock. Fasety pokażą liczniki jak „Shoes (128)”, „Jackets (42)”, by użytkownik wiedział, co jest dostępne.
Konfiguracja pól filtrowalnych i sortowalnych (inaczej nie zadziałają)
Meilisearch wymaga, by pola używane do filtrowania i sortowania były jawnie udostępnione.
- Oznacz pola jako filterable jeśli będą używane w filtrach:
category, status, brand, price, created_at, tenant_id.
- Oznacz pola jako sortable jeśli będziesz sortować po nich:
price, rating, created_at, popularity.
Utrzymaj tę listę zwartą. Uczynienie wszystkiego filtrowalnym/sortowalnym może zwiększyć rozmiar indeksu i spowolnić aktualizacje.
Paginacja i limity, żeby wyszukiwania były szybkie
Nawet przy 50,000 dopasowań użytkownik widzi tylko pierwszą stronę. Używaj małych stron (często 20–50 wyników), ustaw sensowny limit i paginuj z offset (lub nowsze mechanizmy paginacji, jeśli wolisz). Ogranicz też maksymalną głębokość stron w aplikacji, by zapobiec kosztownym „strona 400”.
Synonimy i stop words (opcjonalnie, używaj ostrożnie)
- Synonimy pomagają, gdy różne słowa znaczą to samo (np. „hoodie” ↔ „sweatshirt”). Dodawaj je stopniowo i przeglądaj analitykę—zbyt wiele synonimów może prowadzić do zaskakujących dopasowań.
- Stop words usuwają powszechne słowa („the”, „and”). Mogą zmniejszyć szum, ale też zaszkodzić precyzyjnym zapytaniom (np. „The Who”, „A Team”). Modyfikuj listę stop words tylko przy realnym problemie.
Integracja Meilisearch z backendem aplikacji
Go from local to live
Deploy and host your app, then iterate on relevance without risky manual changes.
Czysty sposób dodania wyszukiwania po stronie serwera to traktować Meilisearch jako wyspecjalizowaną usługę danych za Twoim API. Aplikacja otrzymuje zapytanie wyszukiwania, wywołuje Meilisearch, a następnie zwraca klientowi przygotowaną odpowiedź.
Prosty wzorzec backendowy
Większość zespołów kończy z takim flow:
- Klient wywołuje endpoint (np.
GET /api/search?q=wireless+headphones&limit=20).
- Backend waliduje wejście, nakłada reguły biznesowe i decyduje, którego indeksu użyć.
- Backend wysyła zapytanie do Meilisearch Search API z zapytaniem użytkownika plus filtrami/sortowaniem.
- Backend post-processuje wyniki (ukrywa prywatne pola, łączy z danymi z DB, stosuje uprawnienia).
- Backend zwraca stabilny kształt odpowiedzi do klienta.
Ten wzorzec utrzymuje Meilisearch wymienialnym i zapobiega zależności frontendu od wewnętrznej struktury indeksu.
Jeśli budujesz nową aplikację (lub przebudowujesz narzędzie wewnętrzne) i chcesz szybko wdrożyć ten wzorzec, platforma vibe-coding jak Koder.ai może pomóc przygotować cały flow—React UI, backend w Go i PostgreSQL—a następnie zintegrować Meilisearch za jednym endpointem /api/search, by klient był prosty, a uprawnienia trzymane po stronie serwera.
Zapytania z frontendu kontra backendu (i dlaczego backend jest bezpieczniejszy)
Meilisearch obsługuje zapytania z klienta, ale zwykle bezpieczniej jest używać backendu, bo:
- Sekrety pozostają prywatne: nie narażasz się na ujawnienie uprzywilejowanych kluczy.
- Autoryzacja jest spójna: backend może wymusić, co dany użytkownik może zobaczyć.
- Kontrolujesz złożoność zapytań: ograniczaj filtry, opcje sortowania i paginację, by chronić wydajność.
Zapytania z frontendu działają dla publicznych danych z ograniczonymi kluczami, ale jeśli masz reguły widoczności specyficzne dla użytkownika, kieruj wyszukiwanie przez serwer.
Cache'owanie popularnych zapytań bez łamania trafności
Ruch wyszukiwania często się powtarza („iphone case”, „return policy”). Dodaj cache na warstwie API:
- Cache'uj pełną odpowiedź na krótkie okresy (np. 10–60 sekund) dla anonimowego ruchu.
- Normalizuj klucze cache (usuń spacje, lowercase, uwzględnij filtry/sortowanie).
- Inwaliduj ostrożnie: przy szybko zmieniających się indeksach trzymaj TTL krótki zamiast próbować agresywnie czyścić cache.
Ograniczenia rate i kontrola nadużyć
Traktuj wyszukiwanie jako endpoint publiczny:
- Stosuj limitowanie per IP lub per użytkownik.
- Narzuć maksymalny
limit i maksymalną długość zapytania.
- Rozważ łagodne blokowanie oczywistych botów, pozostawiając dostęp prawdziwym użytkownikom.
Podstawy bezpieczeństwa: klucze, kontrola dostępu, multi-tenancy
Meilisearch często znajduje się „za” Twoją aplikacją, bo może zwracać wrażliwe dane szybko. Traktuj go jak bazę danych: zabezpiecz i udostępniaj tylko to, co powinno być widoczne dla danego klienta.
Klucze API: master vs scoped (zasada najmniejszego przywileju)
Meilisearch ma master key, który może wszystko: tworzyć/usuwać indeksy, zmieniać ustawienia i czytać/zapisywać dokumenty. Trzymaj go tylko po stronie serwera.
Dla aplikacji generuj klucze API z ograniczonymi uprawnieniami i indeksami. Częsty wzorzec:
- Zadania backendowe: klucz, który może pisać dokumenty i aktualizować ustawienia, ale tylko dla konkretnych indeksów.
- Serwer aplikacji: klucz read-only dla wyszukiwania.
- Klient (jeśli konieczne): mocno ograniczony klucz tylko do wyszukiwania z narzuconymi filtrami.
Zasada najmniejszego przywileju sprawia, że wyciek klucza nie pozwoli na usunięcie danych ani odczyt z niezwiązanych indeksów.
Multi-tenancy: oddzielne indeksy czy filtr po tenantId
Jeśli obsługujesz wielu klientów (tenantów), masz dwie główne opcje:
1) Jeden indeks na tenant.
Proste do rozumienia i zmniejsza ryzyko dostępu między tenantami. Minusy: więcej indeksów do zarządzania i konieczność stosowania ustawień konsekwentnie.
2) Wspólny indeks + filter po tenantId.
Przechowuj pole tenantId w każdym dokumencie i wymuszaj filtr tenantId = "t_123" dla wszystkich zapytań. To może skalować dobrze, ale tylko jeśli zapewnisz, że każde żądanie zawsze stosuje filtr (najlepiej poprzez scoped key, żeby wykluczyć jego usunięcie przez klienta).
Zapobieganie wyciekom danych: kontrola, co można zwrócić
Nawet jeśli wyszukiwanie jest poprawne, wyniki mogą ujawnić pola, których nie chciałeś pokazać (maile, notatki wewnętrzne, ceny kosztowe). Skonfiguruj, co można zwrócić:
- Ogranicz displayed/retrievable attributes do bezpiecznej allowlisty.
- Trzymaj pola wrażliwe w indeksie tylko wtedy, gdy to konieczne—i unikaj ich zwracania w wynikach.
Zrób szybki test „najgorszego scenariusza”: wyszukaj popularny termin i upewnij się, że żadne prywatne pola się nie pojawiają.
Podstawowe zasady operacyjne bezpieczeństwa
- Ogranicz dostęp sieciowy: binduj na localhost lub prywatną sieć i zezwól na ruch tylko z serwerów aplikacji.
- Postaw Meilisearch za reverse proxy, jeśli potrzebujesz TLS i rate limiting.
- Przechowuj klucze w managerze sekretów (nie w repozytorium czy paczkach frontendowych) i rotuj je okresowo.
Jeśli nie jesteś pewien, czy klucz powinien być po stronie klienta—zakładaj „nie” i trzymaj wyszukiwanie po stronie serwera.
Wydajność i skalowanie bez zgadywania
Add filters and facets fast
Build a product catalog search with facets, filters, and sorting from one chat.
Meilisearch jest szybki, kiedy masz na uwadze dwa rodzaje obciążenia: indeksowanie (zapisy) i zapytania (odczyty). Większość „tajemniczych” spowolnień to po prostu konkurencja tych obciążeń o CPU, RAM lub dysk.
Gdzie zwykle pojawiają się wąskie gardła
Obciążenie indeksowania może skakać przy dużych importach, częstych aktualizacjach lub wielu przeszukiwalnych polach. Indeksowanie jest zadaniem w tle, ale zużywa CPU i przepustowość dysku. Jeśli kolejka zadań rośnie, wyszukiwania mogą zacząć się wydawać wolniejsze, nawet jeśli ruch zapytań się nie zmienił.
Obciążenie zapytań rośnie wraz z ruchem, ale też wraz z funkcjami: więcej filtrów, więcej faset, większe zbiory wyników i większa tolerancja literówek zwiększają pracę na żądanie.
I/O dysku jest cichym winowajcą. Wolne dyski (lub „hałaśliwi sąsiedzi” na współdzielonych woluminach) mogą zmienić „błyskawiczne” w „w końcu”. NVMe/SSD to zwykle minimum dla produkcji.
Praktyczne kroki skalowania
Zacznij od prostego rozmiarowania: daj Meilisearch wystarczająco RAM, by indeksy były “hot” i CPU, by obsłużyć piki QPS. Potem oddziel obciążenia:
- Jeśli indeksowanie przeszkadza w odczytach, planuj importy poza szczytem i preferuj większe batchy zamiast wielu małych.
- Dodaj repliki dla wysokiej dostępności i przepustowości odczytu (aplikacja może load-balansować zapytania po replikach).
- Sharding: Meilisearch nie ma automatycznego rozproszonego sharding. Jeśli pojedynczy węzeł przestaje wystarczać, partycjonuj dane na poziomie aplikacji (np. per tenant, region lub zakres czasowy) do wielu indeksów lub klastrów.
Co monitorować (żeby nie zgadywać)
Śledź niewielki zestaw sygnałów:
- Latency wyszukiwania (p50/p95) i przepustowość
- Długość kolejki zadań / czas przetwarzania zadań (rosnąca kolejka oznacza, że indeksowanie nie nadąża)
- CPU, RAM, użycie dysku i I/O wait
- Wskaźniki błędów (timeouts, 4xx/5xx, nieudane zadania)
Backupy i planowanie aktualizacji
Backupy powinny być rutyną, nie heroicznym wysiłkiem. Używaj funkcji snapshot Meilisearch w harmonogramie, przechowuj snapshoty poza serwerem i okresowo testuj przywracanie. Przy aktualizacjach czytaj release notes, testuj upgrade w środowisku nieprodukcyjnym i planuj czas na reindeksowanie, jeśli nowa wersja wpływa na indeksowanie.
Jeśli już używasz snapshotów środowisk i rollbacku w platformie aplikacyjnej (np. przez Koder.ai), zsynchronizuj rollout wyszukiwania z tym samym podejściem: snapshot przed zmianami, sprawdź health checks i miej szybki powrót do znanego stanu.
Rozwiązywanie problemów i praktyczna lista kontrolna wdrożenia
Nawet przy czystej integracji problemy z wyszukiwaniem zwykle wpadają w kilka powtarzalnych kategorii. Dobrą wiadomością jest to, że Meilisearch daje wystarczającą widoczność (zadania, logi, deterministyczne ustawienia), by szybko debugować—jeśli podejdziesz do tego systematycznie.
Częste problemy (i co zwykle oznaczają)
- „Moje filtry nie działają”: pole nie zostało dodane do
filterableAttributes, albo dokumenty mają inne kształty pól (string vs array vs nested object).
- „Wyniki są dziwnie posortowane”: reguły rankingowe, synonimy, stop words lub brak
sortableAttributes/rankingRules mogą wypychać „złe” elementy na górę.
- „Wyszukiwanie pokazuje stare dane”: zadania indeksowania nadal się przetwarzają, zapisujesz do innego indeksu niż ten, z którego czytasz, albo pipeline synchronizacji upuścił aktualizacje/usunięcia.
Workflow debugowania, który pozostaje sensowny
Zacznij od sprawdzenia, czy Meilisearch pomyślnie zastosował ostatnią zmianę.
- Sprawdź status zadania: każda zmiana ustawień i aktualizacja dokumentów tworzy asynchroniczne zadanie. Jeśli zadanie nie powiodło się, napraw to najpierw (błędne payloady, nieprawidłowe typy pól, za duże dokumenty).
- Używaj logów z jednym pytaniem w głowie: „Czy serwer przyjął moje żądanie?” potem „Czy zakończył przetwarzanie?” Unikaj jednoczesnego skanowania wszystkiego.
- Stwórz minimalne powtarzalne zapytanie:
- Wybierz jeden indeks.
- Użyj zapytania, które zwraca niewielki, stabilny zestaw.
- Dodawaj ograniczenia krok po kroku:
filter, potem sort, potem facets.
Jeśli nie potrafisz wyjaśnić wyniku, tymczasowo uprość konfigurację: usuń synonimy, zredukować zmiany w regułach rankingowych i testuj na małym zbiorze. Złożone problemy trafności są łatwiejsze do zdiagnozowania na 50 dokumentach niż na 5 milionach.
Strategia rollout: zmniejsz radius błędu
- Najpierw testowy indeks: zbuduj
your_index_v2 równolegle, zastosuj ustawienia i odtwórz próbkę zapytań produkcyjnych.
- Canary rollout: skieruj mały procent ruchu do nowego indeksu lub nowych ustawień, porównaj CTR i wskaźniki „bez wyników”.
- Fallback: zdecyduj, co widzi użytkownik, gdy wyszukiwanie jest wolne lub niedostępne—zbuforowane wyniki, uproszczone zapytanie lub przyjazny komunikat „spróbuj ponownie”. Nie pozwól, by awaria wyszukiwania psuła całą stronę.
Lista rzeczy do zrobienia teraz
- Zweryfikuj, że
filterableAttributes i sortableAttributes odpowiadają wymaganiom UI.
- Potwierdź, że zadania indeksowania kończą się sukcesem po każdej deploymencie.
- Dodaj mały „monitor zdrowia wyszukiwania” (latency + nieudane zadania).
- Poćwicz rollback: przełącz ruch z powrotem na poprzedni indeks.
Related guides: /blog (search reliability, indexing patterns, and production rollout tips).