05 paź 2025·8 min
Zbuduj aplikację webową do monitorowania SLA w czasie rzeczywistym i zapobiegania naruszeniom
Poznaj praktyczny plan budowy aplikacji webowej, która śledzi timery SLA, natychmiast wykrywa naruszenia, powiadamia zespół i wizualizuje zgodność w czasie rzeczywistym.
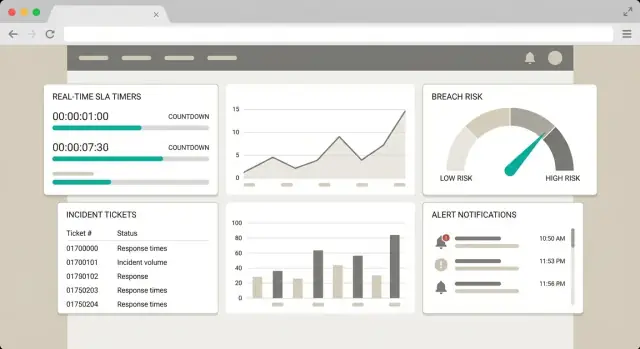
Zdefiniuj cel monitorowania SLA
Zanim zaprojektujesz ekrany czy napiszesz logikę wykrywania, ustal dokładnie, czego aplikacja ma zapobiegać. „Monitorowanie SLA” może oznaczać wszystko — od raportu dziennego po prognozowanie naruszeń co sekundę — to zupełnie inne produkty z odmiennymi potrzebami architektonicznymi.
Zdecyduj, co znaczy „w czasie rzeczywistym” (i dlaczego)
Zacznij od uzgodnienia okna reakcji, które zespół jest w stanie realistycznie wykonać.
Jeśli support działa w cyklach 5–10 minut (kolejki triage, rotacje dyżurów), „czas rzeczywisty” może oznaczać aktualizacje dashboardu co minutę i alerty w ciągu 2 minut. Jeśli obsługujesz incydenty wysokiej wagi, gdzie liczą się minuty, możesz potrzebować pętli wykrycia i powiadomienia 10–30 sekund.
Zapisz to jako mierzalny cel, np.: „Wykrywać potencjalne naruszenia w ciągu 60 sekund i powiadamiać osobę dyżurną w ciągu 2 minut.” To stanie się wytyczną przy późniejszych kompromisach dotyczących architektury i kosztów.
Wyjaśnij, które SLA musisz monitorować
Wypisz konkretne obietnice, które śledzisz, i zdefiniuj każdą prostym językiem:
- Czas pierwszej odpowiedzi (np. „odpowiedź w ciągu 1 godziny”)
- Czas rozwiązania (np. „rozwiązanie w ciągu 24 godzin”, często z zasadami pauzowania)
- Dostępność/uptime (np. „99,9% miesięcznie”)
Zwróć też uwagę, jak to się ma do definicji SLO i SLA w organizacji. Jeśli wewnętrzne SLO różni się od klientowi przedstawianego SLA, aplikacja może potrzebować śledzić oba: jeden do poprawy operacyjnej, drugi do ryzyka kontraktowego.
Zidentyfikuj interesariuszy i właścicieli decyzji
Nazwij grupy, które będą używać lub polegać na systemie: support, inżynieria, customer success, liderzy zespołów i response/on-call.
Dla każdej grupy zanotuj, jakie decyzje muszą podejmować tu i teraz: „Czy ten ticket jest zagrożony?”, „Kto nim zarządza?”, „Czy potrzebna jest eskalacja?” To ukształtuje dashboard, routowanie alertów i uprawnienia.
Zdefiniuj akcje, które aplikacja powinna wywoływać
Celem nie jest tylko widoczność — to terminowe działanie. Zdecyduj, co ma się wydarzyć, gdy ryzyko rośnie lub nastąpi naruszenie:
- Wysyłanie powiadomień w czasie rzeczywistym do Slack/email/pagera
- Eskalacja w zależności od powagi, poziomu klienta lub godzin pracy
- Auto-tworzenie zadania (Jira/Linear) i przypisanie właściciela
Dobre zdanie celu: „Zmniejszyć liczbę naruszeń SLA poprzez wykrywanie naruszeń i uruchamianie reakcji w naszym uzgodnionym oknie reakcji.”
Zmapuj reguły SLA i przypadki brzegowe
Zanim zbudujesz logikę wykrywania, zapisz dokładnie, co oznacza „dobrze” i „źle” dla twojej usługi. Większość problemów z monitorowaniem SLA to nie problemy techniczne, lecz problemy definicyjne.
SLA vs SLO vs KPI (prostym językiem)
SLA (Service Level Agreement) to obietnica wobec klienta, zwykle z konsekwencjami (kredyty, kary, warunki umowy). SLO (Service Level Objective) to wewnętrzny cel, który ma pomóc trzymać się powyżej SLA. KPI (Key Performance Indicator) to dowolna metryka, którą śledzisz (pomocna, ale nie zawsze związana z obietnicą).
Przykład: SLA = „odpowiedź w ciągu 1 godziny.” SLO = „odpowiedź w ciągu 30 minut.” KPI = „średni czas pierwszej odpowiedzi.”
Jasno zdefiniuj typy naruszeń
Wypisz każdy typ naruszenia, który musisz wykrywać, i zdarzenie uruchamiające licznik.
Typowe kategorie naruszeń:
- Przekroczony czas odpowiedzi: np. ticket utworzony o 10:00; pierwsza odpowiedź agenta musi mieć miejsce do 11:00.
- Przekroczony czas rozwiązania: np. ticket otwarty; musi być oznaczony jako rozwiązany w ciągu 24 godzin (z wyłączeniami pauz).
- Próg przerw w działaniu: np. dostępność usługi spada poniżej 99,9% miesięcznie, lub pojedynczy outage trwa dłużej niż 15 minut.
Bądź precyzyjny, co liczy się jako „odpowiedź” (publiczna odpowiedź vs notatka wewnętrzna) i „rozwiązanie” (resolved vs closed) oraz czy ponowne otwarcie resetuje zegar.
Godziny pracy, 24/7 i reguły stref czasowych
Wiele SLA liczy czas tylko w godzinach pracy. Zdefiniuj kalendarz: dni robocze, święta, godziny rozpoczęcia i zakończenia oraz strefę czasową używaną do obliczeń (klienta, kontraktu lub zespołu). Zdecyduj też, co się dzieje, gdy praca przechodzi przez granice (np. ticket przychodzi o 16:55 z SLA 30 minut).
Warunki pauzy i wykluczenia
Udokumentuj, kiedy zegar SLA się zatrzymuje, np.:
- Oczekiwanie na klienta (nieudostępnione dane)
- Okna planowanej konserwacji
- Wstrzymanie z powodu zależności zewnętrznej (jeśli umowa na to pozwala)
Zapisz je jako reguły, które aplikacja może stosować konsekwentnie i trzymaj przykłady trudnych przypadków do późniejszego testowania.
Wybierz źródła danych i zdarzenia do śledzenia
Monitor SLA jest tylko tak dobry, jak dane, które go zasilają. Zacznij od zidentyfikowania "systemów zapisu" dla każdego zegara SLA. Dla wielu zespołów ticketing jest źródłem prawdy dla znaczników czasu cyklu życia, a narzędzia monitorujące/logi tłumaczą, dlaczego coś się wydarzyło.
Wybierz systemy, które trzymają prawdę
Większość konfiguracji w czasie rzeczywistym pobiera dane z małego zestawu systemów:
- Ticketing/helpdesk (np. Zendesk, ServiceNow, Jira Service Management): priorytet, status, przypisany, klient, znaczniki czasowe
- Narzędzia monitorujące/incydentowe (np. Datadog, PagerDuty): incydent otwarty/zaakceptowany/rozwiązany, akcje on-call
- CRM/dane konta (np. Salesforce, HubSpot): poziom klienta, SLA z umowy, plan wsparcia
- Logi i ślady audytu (logi aplikacji, logi workflow): kontekst do dochodzeń i sporów
Jeśli dwa systemy nie zgadzają się, zdecyduj z góry, który wygrywa dla każdego pola (np. „status ticketu z ServiceNow, poziom klienta z CRM”).
Wypisz zdarzenia, które potrzebujesz (i te, które ludzie zapominają)
Minimum: śledź zdarzenia, które uruchamiają, zatrzymują lub zmieniają zegar SLA:
- Ticket created (SLA startuje)
- Status changed (w tym „waiting on customer”, „on hold” lub stany „paused”)
- Assigned / reassigned (często wpływa na reguły eskalacji)
- Priority or severity changed (może zmienić cel SLA w trakcie)
- First response sent i resolved/closed (SLA zatrzymuje się)
Rozważ też zdarzenia operacyjne: zmiany kalendarza godzin pracy, aktualizacje strefy czasowej klienta i zmiany w harmonogramie świąt.
Zdecyduj, jak pobierać dane
Preferuj webhooki dla aktualizacji bliskich czasu rzeczywistego. Używaj pollingu, gdy webhooki nie są dostępne lub nie są niezawodne. Zachowaj eksporty API/backfille do rekonsyliacji (np. zadania nocne wypełniające luki). Wiele zespołów tworzy hybrydę: webhook dla szybkości, okresowy polling dla bezpieczeństwa.
Zaplanuj problemy z jakością danych
Rzeczywiste systemy są nierówne. Spodziewaj się:
- Brakujących znaczników czasu (przechowuj „unknown” i oznacz do przeglądu)
- Zduplikowanych zdarzeń (używaj kluczy idempotencji i reguł deduplikacji)
- Dostarczania poza kolejnością i rozbieżności zegarów (sortuj po znaczniki czasu źródła + czasie ingest, wykrywaj ujemne trwania)
Traktuj to jako wymagania produktowe, nie „przypadki brzegowe” — wykrywanie naruszeń zależy od poprawnego obsłużenia tych sytuacji.
Zaprojektuj prostą architekturę wysokiego poziomu
Dobra aplikacja do monitorowania SLA jest łatwiejsza do zbudowania (i utrzymania), gdy architektura jest jasna i celowo prosta. Na wysokim poziomie budujesz pipeline, który zamienia surowe sygnały operacyjne w „stan SLA”, a potem używa tego stanu do powiadomień i zasilania dashboardu.
Główne komponenty
Pomyśl o pięciu blokach:
- Ingest: zbieraj zdarzenia i metryki z systemów ticketing, monitoringu, logów lub aplikacji wewnętrznych.
- Process: normalizuj dane, powiąż je z klientami/usługami i oblicz timery SLA oraz progi.
- Store: przechowuj zarówno aktualny stan SLA (szybkie odczyty), jak i historię/audyt (śledzenie zmian).
- Alert: wywołuj powiadomienia i eskalacje, gdy naruszenie jest przewidywane lub wystąpi.
- Display: webowy dashboard „co jest teraz zagrożone” oraz szczegóły do dochodzenia.
To rozdzielenie utrzymuje odpowiedzialności czyste: ingest nie powinien zawierać logiki SLA, a dashboardy nie powinny wykonywać ciężkich obliczeń.
Streaming vs. częste przeliczanie
Zdecyduj wcześnie, jak bardzo „w czasie rzeczywistym” potrzebujesz być.
- Event streaming (zalecane dla szybkiej reakcji): gdy zdarzenia nadchodzą (incydent otwarty, status zmieniony, usługa nie działa), aktualizuj stan SLA natychmiast. To wspiera niskie opóźnienia i szybkie prognozowanie naruszeń.
- Częste przeliczanie (prostsze na start): uruchamiaj zaplanowane zadanie co N minut, które ponownie obliczy ryzyko SLA z danych z ostatniego okresu. To może działać dla SLA z oknami godzinowymi, ale może pominąć krótkie skoki lub tworzyć hałas wokół cykli odświeżania.
Pragmatyczne podejście: zacznij od częstego przeliczania dla jednej-dwóch reguł SLA, potem przenieś reguły o dużym wpływie do streaming.
Zaczynaj od prostego modelu wdrożenia
Na początku unikaj złożoności multi-region i wielu środowisk. Jeden region, jedno środowisko produkcyjne i minimalne staging zwykle wystarczą, dopóki nie zweryfikujesz jakości danych i użyteczności alertów. Zasada „skaluj później” powinna być projektem, nie wymaganiem budowy.
Jeśli chcesz przyspieszyć pierwszą wersję dashboardu i workflowów, platforma typu Koder.ai może pomóc w szybkim scaffoldowaniu UI React i backendu Go + PostgreSQL z chat-driven spec, a potem iterować ekrany i filtry w miarę weryfikacji potrzeb responderów.
Wymagania niefunkcjonalne do ustalenia teraz
Zapisz je przed implementacją:
- Cel dostępności dla systemu monitorującego (np. 99,9%).
- Opóźnienie end-to-end od zdarzenia do dashboardu/alertu (np. <60 seconds).
- Retencja historii i audytów (np. 13 miesięcy).
- Audytowalność: każda zmiana stanu SLA powinna być wytłumaczalna („które zdarzenie to spowodowało?”).
Zbuduj ingest zdarzeń i normalizację
Ingest zdarzeń to miejsce, w którym system monitorujący SLA staje się godny zaufania — albo hałaśliwy i mylący. Cel jest prosty: akceptować zdarzenia z wielu narzędzi, konwertować je do jednolitego formatu „prawdy” i przechowywać wystarczający kontekst, by wyjaśnić każdą decyzję SLA później.
Zdefiniuj jasny schemat zdarzenia
Ustandaryzuj, jak wygląda „zdarzenie istotne dla SLA”, nawet jeśli systemy źródłowe się różnią. Praktyczny podstawowy schemat zawiera:
ticket_id(lub case/work item ID)timestamp(kiedy nastąpiła zmiana, nie kiedy ją odebrano)status(opened, assigned, waiting_on_customer, resolved, itd.)priority(P1–P4 lub równoważne)customer(identyfikator konta/tenant)sla_plan(które reguły SLA mają zastosowanie)
Wersjonuj schemat (np. schema_version), żeby ewoluować pola bez łamania starszych producentów.
Normalizuj przed obliczeniem
Różne systemy nazywają to samo inaczej: „Solved” vs „Resolved”, „Urgent” vs „P1”, różnice stref czasowych czy brakujące priorytety. Zbuduj małą warstwę normalizacji, która:
- mapuje statusy do spójnego zestawu
- konwertuje znaczniki czasu do UTC
- wypełnia domyślne wartości (lub oznacza rekordy), gdy pola wymagane są brakujące
- dołącza pola pochodne (np.
is_customer_waitlubis_pause), które upraszczają późniejszą logikę naruszeń
Idempotencja: nie licz zdarzeń podwójnie
Integracje retry’ują. Ingest musi być idempotentny, by powtórki nie tworzyły duplikatów. Typowe podejścia:
- wymagać
event_idod producenta i odrzucać duplikaty - generować deterministyczny klucz (np.
ticket_id + timestamp + status) i upsertować
Trzymaj ślad audytowy, który da się wyjaśnić
Gdy ktoś zapyta „Dlaczego wysłaliśmy alert?”, potrzebujesz papierowego śladu. Przechowuj każde przyjęte surowe zdarzenie i każde zdarzenie po normalizacji, plus kto/co je zmieniło. Ta historia audytu jest niezbędna do rozmów z klientami i wewnętrznych przeglądów.
Dead-letter dla nieprzetwarzalnych zdarzeń
Niektóre zdarzenia nie przejdą parsowania lub walidacji. Nie porzucaj ich milcząco. Przekieruj je do dead-letter queue/tabeli z powodem błędu, oryginalnym payloadem i licznikiem retry, aby móc poprawić mapowania i bezpiecznie odtworzyć.
Wybierz storage dla stanu, historii i audytów
Prototype Your SLA Monitor Fast
Build an SLA dashboard and alerts from a chat spec, then iterate as your rules get clearer.
Aplikacja SLA potrzebuje dwóch „pamięci”: co jest prawdą teraz (by wywołać alerty) i co się wydarzyło w czasie (by wyjaśnić i udowodnić, dlaczego zaalarmowaliśmy).
Przechowuj stan bieżący dla szybkich decyzji
Stan bieżący to najnowszy znany status każdego elementu pracy (ticket/incydent/zamówienie) wraz z aktywnymi timerami SLA (czas startu, czas pauzy, termin, pozostałe minuty, obecny właściciel).
Wybierz magazyn zoptymalizowany pod szybkie odczyty/zapisy po ID i proste filtrowanie. Typowe opcje to relacyjna baza (Postgres/MySQL) lub key-value (Redis/DynamoDB). Dla wielu zespołów Postgres wystarcza i upraszcza raportowanie.
Utrzymuj model stanu mały i przyjazny zapytaniom. Będziesz go często czytać np. dla widoków „wkrótce przekroczy termin”.
Przechowuj historię jako append-only event log
Historia powinna rejestrować każdą zmianę jako niezmienny rekord: created, assigned, priority changed, status updated, customer replied, on-hold started/ended itd.
Tabela append-only (lub event store) umożliwia audyty i replay. Jeśli później odkryjesz błąd w logice naruszeń, możesz przetworzyć zdarzenia ponownie, odbudować stan i porównać wyniki.
Praktyczny wzorzec: tabela stanu + tabela zdarzeń w tej samej bazie na start; przejdź do osobnego magazynu analitycznego, gdy wolumen urośnie.
Decyzje o retencji i archiwizacji
Zdefiniuj retencję według celu:
- Widoki operacyjne: trzymaj ostatni stan i krótki window historii szybko (np. 30–90 dni).
- Audyt/zgodność: przechowuj zdarzenia dłużej (np. 1–7 lat), potem archiwizuj do tańszego storage.
Używaj partycjonowania (miesiąc/kwartał), by archiwizacja i usuwanie były przewidywalne.
Indeksy i zapytania dla kluczowych ekranów
Zaplanuj odpowiedzi na pytania, które dashboard będzie zadawać najczęściej:
- „Breaching soon”: indeksuj po
due_atistatus(i ewentualniequeue/team). - „Breached today”: indeksuj po
breached_at(lub flagę naruszenia) i dacie. - Widoki per-customer lub per-service: indeksy złożone jak
(customer_id, due_at).
Tu wygrywa wydajność: strukturuj storage wokół 3–5 najważniejszych widoków, nie wszystkich możliwych raportów.
Zaimplementuj logikę wykrywania naruszeń w czasie rzeczywistym
Wykrywanie naruszeń w czasie rzeczywistym to głównie jedno: zamiana nieuporządkowanych, ludzkich workflowów (przypisane, oczekiwanie na klienta, ponowne otwarcie, transfer) w jasne timery SLA, którym można ufać.
Zbuduj timery SLA: start, stop, pause, resume
Zacznij od zdefiniowania, które zdarzenia kontrolują zegar SLA dla każdego typu ticketu lub żądania. Typowe wzorce:
- Start: gdy ticket jest utworzony, lub gdy po raz pierwszy wchodzi w status „support active”.
- Pause: gdy przechodzi do „Waiting for customer” lub „On hold.”
- Resume: gdy klient odpowiada lub ticket wraca do aktywnej kolejki.
- Stop: gdy jest resolved/closed (lub gdy spełnione jest SLA pierwszej odpowiedzi).
Na podstawie tych zdarzeń oblicz due time. Dla ścisłych SLA może to być „created_at + 2 hours”. Dla SLA liczonych w godzinach pracy to „2 business hours”, co wymaga kalendarza.
Moduł biznesowego kalendarza wielokrotnego użytku
Stwórz mały moduł kalendarza, który odpowiada spójnie na dwa pytania:
- „Ile czasu roboczego upłynęło między A i B?”
- „Jaka jest data/godzina N roboczych minut po A?”
Trzymaj święta, godziny pracy i strefy czasowe w jednym miejscu, aby każda reguła SLA korzystała z tej samej logiki.
Pozostały czas i ryzyko naruszenia
Gdy masz już due time, obliczenie pozostałego czasu jest proste: due_time - now (w minutach roboczych, jeśli dotyczy). Następnie zdefiniuj progi ryzyka naruszenia, np. „do terminu 15 minut” lub „mniej niż 10% SLA pozostało”. To zasila odznaki pilności i routowanie alertów.
Ciągłe przeliczanie vs zaplanowane ticki
Możesz:
- Przeliczać ciągle (na każde istotne zdarzenie + przy odczycie): najprostsze konceptualnie, ale może być kosztowne w skali.
- Używać zaplanowanych ticków (np. co minutę): aktualizuj pozostały czas i wywołuj przejścia ryzyka zbiorczo.
Praktyczna hybryda: aktualizacje event-driven dla dokładności oraz minutowy tick, by wyłapywać przejścia progowe nawet gdy brak nowych zdarzeń.
Skonfiguruj alertowanie, eskalacje i powiadomienia
Add an On Call Mobile View
Create a Flutter companion view for on call triage when you are away from your desk.
Alerty to moment, w którym monitoring SLA staje się operacyjny. Celem nie jest „więcej powiadomień”, lecz trafienie do właściwej osoby, która wykona właściwą akcję przed upływem terminu.
Zdefiniuj typy alertów (i co oznaczają)
Użyj kilku typów alertów z jasnym przeznaczeniem:
- Ostrzeżenie o ryzyku: SLA jest nadal bezpieczne, ale zmierza ku przekroczeniu (np. „prawdopodobne naruszenie za 30 minut”).
- Potwierdzone naruszenie: SLA zostało oficjalnie złamane, z czasem naruszenia i zakresem wpływu.
- Krok eskalacji: zaplanowane follow-upy, gdy problem nie został uznany lub rozwiązany.
Dopasuj każdy typ do innego kanału i stopnia pilności (np. chat dla ostrzeżeń, paging dla potwierdzonych naruszeń).
Kieruj alerty wg zespołu, usługi, priorytetu i poziomu klienta
Routowanie powinno być oparte na danych, nie hardkodowane. Użyj prostej tabeli reguł: service → owning team, a potem zastosuj modyfikatory:
- Priorytet/Severity (P0–P3)
- Poziom klienta (enterprise vs standard)
- Godziny pracy vs poza godzinami dyżur
To zapobiega „broadcastowaniu do wszystkich” i ujawnia właściciela sprawy.
Dodaj deduplikację, aby zapobiec spamowi alertów
Status SLA może szybko się zmieniać podczas reakcji. Deduplicuj po stabilnym kluczu jak (ticket_id, sla_rule_id, alert_type) i stosuj:
- krótkie okno cooldown (np. 5–15 minut)
- wysyłanie bazujące na stanie (notify tylko przy przejściach)
Rozważ też grupowanie wielu ostrzeżeń w jedną periodyczną paczkę.
Dołącz jasny kontekst do każdego alertu
Każde powiadomienie powinno odpowiadać na „co, kiedy, kto, co dalej”:
- Właściciel/zespół i cel on-call
- Due time i pozostały czas
- Następna akcja (acknowledge, assign, respond)
- Bezpośredni link do elementu pracy (np. /tickets/123) i widoku SLA (np. /sla/tickets/123)
Jeśli ktoś nie może wykonać akcji w 30 sekund po przeczytaniu powiadomienia, alert wymaga lepszego kontekstu.
Zaprojektuj dashboard i workflowy użytkowników
Dobry dashboard SLA to mniej wykresów, a więcej pomocy w podjęciu decyzji w mniej niż minutę. Projektuj UI wokół trzech pytań: Co jest zagrożone? Dlaczego? Jaką akcję mam podjąć?
Podstawowe widoki zgodne z pracą zespołów
Zacznij od czterech prostych widoków, każdy z jasnym celem:
- Overview: migawka obciążenia i ryzyka (otwarte, wkrótce terminy, naruszone, najważniejsi klienci dotknięci).
- Breaching soon: operacyjna skrzynka na dziś — elementy o najwyższej pilności.
- Breached: co wymaga reakcji incydentowej, eskalacji lub aktualizacji klienta.
- Compliance trends: raporty tygodniowe/miesięczne, żeby menedżerowie mogli zauważyć powtarzające się problemy (wg zespołu, klienta, planu SLA).
Domyślny widok trzymaj skoncentrowany na breaching soon, bo tam odbywa się zapobieganie.
Filtry proste, ale użyteczne
Daj użytkownikom niewielki zestaw filtrów odpowiadających rzeczywistej własności i decyzjom triage:
- Team/queue (kto za to odpowiada)
- Priority (wpływ)
- Customer (skupienie na koncie)
- SLA plan (warunki kontraktu)
- Zakres czasowy (ostatnie 24h, 7d, 30d dla trendów)
Uczyń filtry „sticky” per użytkownik, by nie musieli ich ustawiać za każdym razem.
Wyjaśnij, dlaczego ticket jest zagrożony
Każdy wiersz w „breaching soon” powinien zawierać krótkie, prostoliniowe wyjaśnienie, np.:
- Zegar SLA: 2h 10m pozostało (cel 4h)
- Czas pauzy: 1h 30m wykluczone (oczekiwanie na klienta)
- Zastosowana reguła: „P1 Business Hours (Mon–Fri)”
- Następny termin: 15:40 czasu lokalnego
Dodaj „Szczegóły” z timeline’em zmian stanu SLA (start, pause, resume, breach), żeby użytkownik ufał obliczeniom bez konieczności ręcznych kalkulacji.
Workflow i przyciski akcji
Zaprojektuj domyślny workflow: review → open → act → confirm.
Każdy element powinien mieć przyciski akcji prowadzące do źródła prawdy:
- Open ticket: /tickets/{id}
- View customer: /customers/{id}
- Escalation policy: /oncall/{team}
Jeśli wspierasz szybkie akcje (assign, change priority, add note), pokazuj je tylko tam, gdzie można je stosować konsekwentnie i audytuj zmianę.
Dodaj bezpieczeństwo, uprawnienia i rządzenie danymi
Aplikacja do monitorowania SLA szybko staje się systemem zapisu dla wydajności, incydentów i wpływu na klienta. Traktuj ją jak produkcyjne oprogramowanie od pierwszego dnia: ogranicz kto i co może robić, chroń dane klientów i udokumentuj, jak dane są przechowywane i usuwane.
Zdefiniuj role i uprawnienia
Zacznij od małego, jasnego modelu uprawnień i rozbudowuj tylko gdy potrzeba. Typowa konfiguracja:
- Viewer: dostęp tylko do odczytu do dashboardów i raportów.
- Operator: może potwierdzać alerty, dodawać notatki, tworzyć incydenty i uruchamiać eskalacje.
- Admin: zarządza definicjami SLA, integracjami, regułami routingu, użytkownikami i politykami danych.
Utrzymuj uprawnienia spójne z workflowami. Na przykład operator może aktualizować status incydentu, ale tylko admin może zmieniać timery SLA lub reguły eskalacji.
Chroń pola wrażliwe i audytuj dostęp
Monitor SLA często zawiera identyfikatory klientów, poziomy kontraktów i treść ticketów. Minimalizuj ekspozycję:
- Maskuj lub redaguj dane klienta domyślnie (pełne wartości zobaczą tylko osoby z autoryzacją).
- Oddziel „display name” od „unikalnego ID”, aby dashboardy były użyteczne bez ujawniania prywatnych danych.
- Loguj dostęp do wrażliwych widoków i eksportów (kto, kiedy i skąd uzyskał dostęp).
Zabezpiecz integracje end-to-end
Integracje to częsty słaby punkt:
- Używaj zakresów najmniejszego uprzywilejowania: tylko uprawnień potrzebnych do czytania zdarzeń lub wysyłania powiadomień.
- Przechowuj tokeny w secrets managerze (nie w kodzie ani ustawieniach dashboardu).
- Rotuj tokeny regularnie i natychmiast po zmianach personelu lub podejrzeniu wycieku.
- Preferuj webhooki z weryfikacją sygnatury lub krótkotrwałe poświadczenia.
Ustal zasady przetwarzania danych wcześnie
Zdefiniuj polityki zanim zgromadzisz miesiące historii:
- Retencja: jak długo trzymać surowe zdarzenia, obliczone stany SLA i logi audytu.
- Usuwanie: jak usunąć dane klienta na żądanie (i co nie może być usunięte ze względów zgodności).
- Eksporty: kto może eksportować raporty, w jakich formatach i z jakimi redakcjami.
Zapisz te reguły i odzwierciedl je w UI, żeby zespół wiedział, co system przechowuje — i jak długo.
Testuj, waliduj i monitoruj system
Lock Down SLA Rules Early
Use planning mode to write down timers, pauses, and edge cases before you implement logic.
Testowanie aplikacji SLA to mniej „czy UI się załadował”, a więcej „czy timery, pauzy i progi są obliczane dokładnie tak, jak oczekuje umowa — za każdym razem”. Mały błąd (strefy czasowe, godziny pracy, brakujące zdarzenia) może powodować hałas alertów lub, co gorsza, missed breaches.
Waliduj reguły realistycznymi scenariuszami
Zamień reguły SLA w konkretne scenariusze, które możesz symulować end-to-end. Uwzględnij normalne przepływy i trudne przypadki:
- Tickety tworzone tuż przed końcem godzin pracy
- Zmiany priorytetu w trakcie incydentu (czy zegar się resetuje?)
- Odpowiedź klienta pauzująca zegar (i prawidłowe wznowienie)
- Duplikaty zdarzeń, zdarzenia poza kolejnością i brakujące „resolved”
Udowodnij, że logika wykrywania naruszeń jest stabilna wobec realnego bałaganu operacyjnego, nie tylko czystych danych demo.
Używaj odtwarzalnych fixture’ów zdarzeń
Stwórz bibliotekę odtwarzalnych fixture’ów: mały zbiór „timeline’ów incydentów”, które możesz przepuścić przez ingest i obliczenia za każdym razem, gdy zmieniasz logikę. To pomaga weryfikować obliczenia w czasie i zapobiega regresjom.
Trzymaj fixture’y w wersjonowanym repo (np. Git) i dołącz oczekiwane wyjścia: obliczony czas pozostały, moment naruszenia, okna pauz i wywołane alerty.
Monitoruj sam monitoring
Traktuj monitor SLA jak każdy system produkcyjny i dodaj własne sygnały zdrowia:
- Opóźnienie ingest (jak bardzo jesteś za czasem rzeczywistym)
- Liczba błędów przetwarzania / dead-letterów
- Błędy obliczeń timerów (wg typu SLA)
- Współczynnik dostarczania alertów i czas do dostarczenia
Jeśli dashboard pokazuje „zielono”, podczas gdy zdarzenia utknęły, szybko stracisz zaufanie.
Runbooki dla zablokowanych pipeline’ów i recalculation
Napisz krótki, jasny runbook dla typowych trybów awarii: zablokowane konsumery, zmiany schematu, awarie upstream i backfill’e. Zawieraj kroki pozwalające bezpiecznie odtworzyć zdarzenia i przeliczyć timery (jaki okres, których tenantów, jak uniknąć podwójnych alertów). Podlinkuj go w wewnętrznej dokumentacji lub prostej stronie jak /runbooks/sla-monitoring.
Wdrażaj inkrementalnie i planuj iteracje
Wysyłanie aplikacji SLA jest najprostsze, gdy traktujesz ją jak produkt, a nie jednorazowy projekt. Zacznij od minimalnego wydania, które udowadnia pętlę end-to-end: ingest → evaluate → alert → potwierdzenie, że pomogło komuś zareagować.
Zacznij od minimalnego releasu wartościowego
Wybierz jedno źródło danych, jeden typ SLA i podstawowe alerty. Na przykład monitoruj „czas pierwszej odpowiedzi” z jednego kanału ticketowego i wyślij alert, gdy zegar zbliża się do terminu (nie tylko po naruszeniu). To zawęża zakres, jednocześnie weryfikując trudne elementy: znaczniki czasu, okna czasu i własność.
Po ustabilizowaniu MVP rozszerzaj małymi krokami: dodaj drugi typ SLA (np. resolution), potem drugie źródło danych, następnie bogatsze workflowy.
Zaplanuj środowiska i bezpieczne roll-outy
Skonfiguruj dev, staging i production wcześnie. Staging powinien odzwierciedlać konfiguracje produkcyjne (integracje, harmonogramy, ścieżki eskalacji) bez powiadamiania rzeczywistych responderów.
Używaj feature flagów do wdrożeń:
- Nowe reguły naruszeń dla pilota
- Nowe integracje w trybie „observe-only” (loguj wykrycia, bez alertów)
- Zmiany UI za toggle’m, żeby można było szybko cofnąć
Jeśli budujesz szybko z platformą jak Koder.ai, snapshoty i rollback są przydatne: wdrażaj UI i zmiany reguł do pilota, potem szybko revertuj, jeśli alerty będą za hałaśliwe.
Dokumentuj onboarding, żeby zespoły rzeczywiście to przyjęły
Napisz krótkie, praktyczne instrukcje: „Podłącz źródło danych”, „Utwórz SLA”, „Przetestuj alert”, „Co robić po otrzymaniu powiadomienia”. Trzymaj je blisko produktu, np. stronę wewnętrzną /docs/sla-monitoring.
Buduj backlog iteracji
Po początkowym wdrożeniu priorytetyzuj ulepszenia zwiększające zaufanie i redukujące hałas:
- Proste wykrywanie anomalii dla niespodziewanych wolumenów lub nagłych wzrostów ryzyka SLA
- Publiczne strony statusu dla kluczowych usług (opcjonalnie)
- Zaplanowane raporty operacyjne (tygodniowe podsumowanie SLA, główne przyczyny naruszeń, linie trendów)
Iteruj w oparciu o realne incydenty: każdy alert powinien nauczyć cię, co zautomatyzować, wyjaśnić lub usunąć.
Często zadawane pytania
What is an “SLA monitoring goal,” and how do I define it?
Cel monitorowania SLA to mierzalne stwierdzenie definiujące:
- Co próbujesz zapobiec (np. naruszenia czasu pierwszej odpowiedzi, naruszenia czasu rozwiązania, spadki dostępności)
- Jak szybko musisz wykryć ryzyko (np. w ciągu 60 sekund)
- Jak szybko musisz powiadomić kogoś, kto może zareagować (np. w ciągu 2 minut)
Sformułuj to jako cel, który można przetestować: „Wykryj potencjalne naruszenia w ciągu X sekund i powiadom osobę dyżurną w ciągu Y minut.”
How do I decide what “real time” should mean for SLA monitoring?
Zdefiniuj „czas rzeczywisty” w oparciu o zdolność zespołu do reakcji, a nie tylko możliwości techniczne.
- Jeśli pracujecie w cyklach triage 5–10 minut, celuj w aktualizacje co minutę i powiadomienia w ~2 minuty.
- Jeśli liczą się sekundy (wysoki priorytet), może być potrzebna pętla wykrycia i powiadomienia 10–30 sekund.
Najważniejsze jest określenie docelowego (zdarzenie → obliczenie → alert/dashboard) i zaprojektowanie systemu wokół tego celu.
Which SLA types should my app monitor first?
Monitoruj obietnice skierowane do klientów, które faktycznie mogą skutkować naruszeniem (i ewentualnymi kredytami), np.:
- Czas pierwszej odpowiedzi (wyraźnie zdefiniuj, co liczy się jako odpowiedź)
- Czas rozwiązania (wraz z zasadami pauzowania)
- Dostępność/uptime (procent miesięczny i/lub progi pojedynczych awarii)
Wiele zespołów śledzi też wewnętrzne ostrzejsze niż SLA. Jeśli masz oba, przechowuj i pokazuj oba, żeby operatorzy mogli działać wcześniej, a jednocześnie raportować zgodność kontraktową dokładnie.
What are the most important SLA edge cases to document before building?
Błędy w SLA to często błędy definicji. Wyjaśnij:
- Zdarzenie startowe (utworzenie zgłoszenia? wejście w status „aktywne”?)
- Zdarzenie stop (pierwsza publiczna odpowiedź? resolved vs closed?)
- Warunki pauzy (oczekiwanie na klienta, on hold, maintenance)
- Zachowanie przy przywróceniu (czy ponowne otwarcie resetuje zegar czy wznawia?)
Zakoduj te zasady deterministycznie i utrzymuj bibliotekę przykładów timeline’ów do testów.
How should I handle business hours and time zones in SLA calculations?
Zdefiniuj spójny zestaw reguł kalendarza:
- Dni robocze, godziny rozpoczęcia/końca, święta
- Strefa czasowa używana do obliczeń (klienta, kontraktu lub zespołu)
- Zachowanie na granicach dni (np. zgłoszenie 5 minut przed zamknięciem)
Zaimplementuj moduł kalendarza, który potrafi odpowiedzieć na pytania:
- „Ile czasu roboczego upłynęło między A i B?”
What data sources should I integrate, and which one is the source of truth?
Wybierz „system zapisu” dla każdego pola i udokumentuj, który system przeważa w przypadku rozbieżności.
Typowe źródła:
- Ticketing/helpdesk: status, przypisany, znaczki czasowe
- Narzędzia monitorujące/incydentowe: lifecycle incydentu, akcje on-call
- CRM: poziom klienta, plan SLA
- Logi/ślady audytu: kontekst
Dla zachowania bliskości rzeczywistości używaj ; dodaj do rekonsyliacji i uzupełniania braków.
Which events do I need to track to compute SLA timers correctly?
Minimumn zdarzeń, które zaczynają, zatrzymują lub modyfikują zegar SLA:
- Created
- Status changes (w tym waiting/paused states)
- Assigned/reassigned
- Priority/severity changes (może zmienić cel w trakcie)
- First response sent
- Resolved/closed
Planuj też „zapominane” zdarzenia: aktualizacje kalendarza, zmiany stref czasowych i święta — mogą one zmienić terminy bez aktywności ticketu.
What’s a practical architecture for a real-time SLA monitoring web app?
Użyj prostego pięcioblokowego pipeline’u:
- Ingest zdarzeń
- Process normalizacja + obliczenia SLA
- Store stan bieżący + niezmienną historię
- Alert na przejścia ryzyko/naruszenie
- Display dashboardy do triage i śledztwa
Should I compute SLA state with streaming events or scheduled recalculation?
W zależności od pilności używaj obu podejść:
- Event-driven streaming aktualizuje stan SLA natychmiast po nadejściu zdarzeń. Najlepsze dla niskich opóźnień.
- Scheduled recalculation (ticks) przelicza timery okresowo. Prostsze, ale może przegapić krótkie okna.
Silne rozwiązanie hybrydowe: event-driven dla poprawności plus minutowy tick, który wyłapuje przejścia progowe, gdy brak nowych zdarzeń (np. „do terminu 15 minut”).
How do I prevent alert spam while still catching SLA risk early?
Traktuj alertowanie jako workflow, nie jako strumień powiadomień: