21 wrz 2025·8 min
Myślenie Erica Brewera o CAP: dlaczego systemy rozproszone dokonują kompromisów
Poznaj twierdzenie CAP Erica Brewera jako praktyczny model myślowy: jak spójność, dostępność i partycje wpływają na decyzje w systemach rozproszonych.
Poznaj twierdzenie CAP Erica Brewera jako praktyczny model myślowy: jak spójność, dostępność i partycje wpływają na decyzje w systemach rozproszonych.
Kiedy przechowujesz te same dane na więcej niż jednej maszynie, zyskujesz szybkość i odporność na awarie — ale pojawia się nowy problem: niezgodność. Dwa serwery mogą otrzymać różne aktualizacje, wiadomości mogą przyjść z opóźnieniem albo wcale, a użytkownicy mogą odczytywać różne odpowiedzi zależnie od tego, z której repliki trafili. CAP stał się popularny, bo daje inżynierom jasny sposób mówienia o tej chaotycznej rzeczywistości bez pustych słów.
Eric Brewer, naukowiec komputerowy i współzałożyciel Inktomi, przedstawił główną ideę w 2000 roku jako praktyczne stwierdzenie o systemach replikowanych w warunkach awarii. Rozprzestrzeniła się szybko, bo odpowiadała temu, co zespoły obserwowały w produkcji: systemy rozproszone nie tylko „padzą”; one się dzielą.
CAP jest najbardziej użyteczny, gdy coś idzie nie tak — zwłaszcza gdy sieć nie zachowuje się poprawnie. W zdrowy dzień wiele systemów może wyglądać zarówno spójnie, jak i wystarczająco dostępnie. Prawdziwy test to moment, gdy maszyny nie mogą się niezawodnie komunikować i musisz zdecydować, co robić z odczytami i zapisami, dopóki system jest podzielony.
To ujęcie tłumaczy, dlaczego CAP stał się modelem: nie dyskutuje najlepszych praktyk; wymusza konkretne pytanie — co poświęcimy podczas podziału?
Na końcu tego artykułu powinieneś umieć:\n
CAP przetrwał, bo zamienia mglistą myśl „systemy rozproszone są trudne” w decyzję, którą można podjąć — i obronić.
System rozproszony to, prosto mówiąc, wiele komputerów próbujących zachować się jak jeden. Możesz mieć kilka serwerów w różnych szafach, regionach czy strefach chmurowych, ale dla użytkownika to „aplikacja” albo „baza danych”.
Aby taki wspólny system działał w skali rzeczywistej, zwykle replikujemy: trzymamy wiele kopii tych samych danych na różnych maszynach.
Replikacja jest popularna z trzech praktycznych powodów:
Na papierze replikacja wygląda jak wygrana. Haczyk polega na tym, że replikacja tworzy nowe zadanie: utrzymanie wszystkich kopii w zgodzie.
Gdyby każda replika mogła zawsze natychmiast rozmawiać z każdą inną, mogłyby koordynować aktualizacje i pozostawać zsynchronizowane. Ale prawdziwe sieci nie są perfekcyjne. Wiadomości mogą być opóźnione, zgubione lub przekierowane przez awarie.
Gdy komunikacja jest zdrowa, repliki zwykle wymieniają aktualizacje i zbieżają do tego samego stanu. Ale gdy komunikacja zawodzi (nawet tymczasowo), możesz skończyć z dwoma pozornie prawidłowymi wersjami „prawdy”.
Na przykład: użytkownik zmienia adres wysyłki. Replika A przyjmuje aktualizację, replika B nie. Teraz system musi odpowiedzieć na proste pytanie: jaki jest bieżący adres?
To różnica między:
Myślenie w kategoriach CAP zaczyna się właśnie tutaj: kiedy replikacja istnieje, niezgodność przy awarii komunikacji nie jest skrajnym przypadkiem — to centralny problem projektowy.
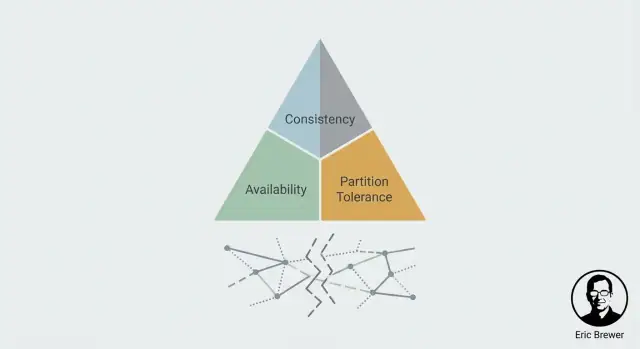
CAP to model myślowy opisujący to, co użytkownicy faktycznie odczuwają, gdy system jest rozproszony po wielu maszynach (często w wielu lokalizacjach). Nie ocenia systemów jako „dobrych” lub „złych” — opisuje napięcie, którym trzeba zarządzać.
Spójność dotyczy zgody. Jeśli coś zaktualizujesz, czy następny odczyt (z dowolnego miejsca) pokaże tę aktualizację?
Z perspektywy użytkownika to różnica między „właśnie to zmieniłem i wszyscy widzą nową wartość” a „niektórzy przez chwilę widzą starą wartość”.
Dostępność oznacza, że system odpowiada na żądania — odczyty i zapisy — z rezultatem sukcesu. Nie „najszybciej jak się da”, ale „nie odmawia obsługi”.
W czasie problemów (serwer padł, chwilowy błąd sieci) dostępny system nadal przyjmuje żądania, nawet jeśli odpowiada danymi lekko nieaktualnymi.
Partycja to sytuacja, gdy sieć się dzieli: maszyny działają, ale wiadomości między niektórymi z nich nie docierają (albo przychodzą zbyt późno, by miały wartość). W systemach rozproszonych nie można traktować tego jako niemożliwości — trzeba zdefiniować zachowanie, gdy do niej dojdzie.
Wyobraź sobie dwa sklepy sprzedające ten sam produkt i dzielące się „1 stanem magazynowym”. Klient kupuje ostatni egzemplarz w Sklepie A, więc Sklep A zapisuje inventory = 0. W tym samym czasie partycja sieciowa uniemożliwia Sklepowi B otrzymanie tej informacji.
Jeśli Sklep B zostanie dostępny, może sprzedać produkt, którego już nie ma (zaakceptować sprzedaż podczas podziału). Jeśli Sklep B wymusi spójność, może odmówić sprzedaży, dopóki nie potwierdzi najnowszego stanu (odmowa obsługi w czasie podziału).
„Partycja” to nie tylko „internet padł”. To każda sytuacja, w której części systemu nie mogą ze sobą wiarygodnie rozmawiać — choć każda część może nadal działać poprawnie.
W systemie replikowanym węzły nieustannie wymieniają wiadomości: zapisy, potwierdzenia, heartbeaty, wybory lidera, żądania odczytu. Partycja to moment, gdy te wiadomości przestają docierać (albo docierają zbyt późno), tworząc niezgodność co do rzeczywistości: „Czy zapis się wykonał?” „Kto jest liderem?” „Czy węzeł B jest żywy?”
Komunikacja może zawodzić w złożony, częściowy sposób:\n
Ważne: partycje to często degradacja, a nie czysty stan on/off. Z punktu widzenia aplikacji „wystarczająco wolno” może być nie do odróżnienia od „nie działa”.
Im więcej maszyn, sieci i regionów dodajesz, tym więcej okazji do tymczasowego złamania komunikacji. Nawet jeśli pojedyncze komponenty są niezawodne, cały system doświadcza awarii, bo ma więcej zależności i koordynacji między węzłami.
Nie musisz zakładać konkretnej częstości awarii, żeby przyjąć prostą prawdę: jeśli system działa długo i obejmuje dużo infrastruktury, podziały wystąpią.
Tolerancja podziału oznacza, że system jest zaprojektowany tak, by działać podczas podziału — nawet gdy węzły nie mogą się zgodzić ani potwierdzić, co druga strona widziała. To wymusza wybór: albo nadal obsługiwać żądania (ryzykując niespójność), albo zatrzymać/odrzucić część żądań (zachowując spójność).
Gdy masz replikację, partycja to po prostu przerwa w komunikacji: dwie części systemu nie mogą się przez pewien czas niezawodnie porozmawiać. Repliki dalej działają, użytkownicy klikają, a twoja usługa dalej otrzymuje żądania — ale repliki nie mogą zgodzić się co do najnowszej prawdy.
To napięcie CAP w jednym zdaniu: podczas partycji musisz wybrać, czy priorytetem będzie Spójność (C) czy Dostępność (A). Nie możesz mieć obu naraz.
Mówisz: „Wolę być poprawny niż responsywny.” Gdy system nie może potwierdzić, że żądanie utrzyma wszystkie repliki w synchronizacji, musi zawieść lub poczekać.
Efekt praktyczny: część użytkowników zobaczy błędy, timeouty albo komunikaty „spróbuj ponownie” — zwłaszcza przy operacjach zmieniających dane. To powszechne, gdy wolisz odmówić płatności niż ryzykować podwójne obciążenie, albo zablokować rezerwację miejsca, niż sprzedać ponad stan.
Mówisz: „Wolę odpowiadać niż blokować.” Każda strona podziału będzie dalej przyjmować żądania, nawet jeśli nie może się skoordynować.
Efekt praktyczny: użytkownicy dostają sukcesy, ale dane mogą być przeterminowane, a równoległe aktualizacje mogą wchodzić w konflikt. Polegasz wtedy na późniejszej rekonsyliacji (reguły scalania, last-write-wins, przegląd ręczny itp.).
To nie zawsze jest jedna globalna zasada. Wiele produktów miesza strategie:\n
Kluczowy moment to decyzja — per operacja — co jest gorsze: zablokowanie użytkownika teraz, czy naprawianie sprzecznej prawdy później.
Hasło „wybierz dwa” jest chwytliwe, ale często wprowadza w błąd, sugerując, że CAP to lista trzech cech, z których możesz na zawsze zachować tylko dwie. CAP dotyczy tego, co się dzieje gdy sieć przestaje współpracować: podczas partycji system rozproszony musi wybrać między zwracaniem spójnych odpowiedzi a byciem dostępnym dla każdego żądania.
W rzeczywistych systemach rozproszonych partycje nie są ustawieniem, które możesz wyłączyć. Jeśli system obejmuje maszyny, szafy, strefy lub regiony, wiadomości mogą być opóźniane, zgubione, przestawiane w kolejności lub dziwnie routowane. To jest partycja z punktu widzenia oprogramowania: węzły nie mogą się wiarygodnie zgodzić, co się dzieje.
Nawet gdy fizyczna sieć działa, awarie gdzie indziej dają ten sam efekt — GC pauses, noisy neighbors, DNS hiccups, wadliwy load balancer. Efekt jest taki sam: niektóre części systemu nie mówią do innych wystarczająco dobrze, by się skoordynować.
Aplikacje nie doświadczają „partycji” jako ładnego, binarnego zdarzenia. Doświadczają skoków opóźnień i timeoutów. Jeśli żądanie timeoutuje po 200 ms, nie ma znaczenia, czy pakiet dotarł po 201 ms czy wcale: aplikacja musi zdecydować, co dalej. Z perspektywy aplikacji wolna komunikacja często jest nierozróżnialna od jej całkowitego braku.
Wiele rzeczywistych systemów jest głównie spójnych lub głównie dostępnych, zależnie od konfiguracji i warunków. Timeouty, polityki retry, rozmiary kworum i opcje typu „read your writes” mogą przesuwać zachowanie.
W normalnych warunkach baza może wyglądać na silnie spójną; pod obciążeniem lub przy problemach międzyregionowych może zacząć odrzucać żądania (faworyzując spójność) albo zwracać starsze dane (faworyzując dostępność). CAP mniej etykietuje produkty, a bardziej wyjaśnia wybór, który robisz, gdy pojawia się niezgodność — zwłaszcza gdy powoduje ją zwykłe spowolnienie.
Dyskusje CAP często czynią spójność binarną: „idealna” albo „cokolwiek”. Rzeczywiste systemy oferują menu gwarancji, z różnymi doświadczeniami użytkownika, gdy repliki się nie zgadzają lub łącze sieciowe pęka.
Silna spójność (często „linearizowalność”) oznacza, że gdy zapis został potwierdzony, każdy późniejszy odczyt — niezależnie od repliki — zwróci ten zapis.
Cena: podczas partycji lub gdy mniejszość replik jest niedostępna, system może opóźniać lub odrzucać odczyty/zapisy, aby uniknąć sprzecznych stanów. Użytkownicy zauważą to jako timeouty, „spróbuj ponownie” lub tymczasowy tryb tylko do odczytu.
Spójność ostateczna obiecuje, że jeśli nie nastąpią nowe aktualizacje, wszystkie repliki zbiegną do tego samego stanu. Nie obiecuje, że dwaj użytkownicy czytający teraz zobaczą to samo.
Co użytkownicy mogą zauważyć: niedawno zaktualizowane zdjęcie profilowe, które „cofa się”, liczniki opóźniające się, albo wysłana wiadomość, która na innym urządzeniu pojawia się z opóźnieniem.
Często możesz uzyskać lepsze doświadczenie bez wymagania pełnej silnej spójności:\n
Te gwarancje pasują do ludzkiego rozumienia („nie pokazuj mi moich zmian jakby zniknęły”) i bywają łatwiejsze do utrzymania podczas częściowych awarii.
Zacznij od obietnic dla użytkownika, nie od żargonu:\n
Spójność to wybór produktowy: opisz, co dla użytkownika znaczy „zły wynik”, a potem wybierz najsłabszą gwarancję, która temu zapobiegnie.
Dostępność w kontekście CAP to nie chwalenie się „pięcioma dziewiątkami” — to obietnica wobec użytkowników o tym, co się stanie, gdy system nie może być pewny.
Gdy repliki nie mogą się zgodzić, często wybierasz między:\n
Użytkownicy odbierają to jako „aplikacja działa” kontra „aplikacja jest poprawna”. Ani jedno, ani drugie nie jest uniwersalnie lepsze; właściwy wybór zależy od tego, co znaczy „błąd” w twoim produkcie. Nieco przeterminowany feed jest irytujący. Przeterminowane saldo konta może być szkodliwe.
Dwa typowe zachowania podczas niepewności:\n
To nie jest czysto techniczna decyzja; to polityka. Produkt musi zdefiniować, co można pokazać, a co nigdy nie może być zgadywane.
Dostępność rzadko jest „wszystko albo nic”. Podczas podziału możesz mieć częściową dostępność: niektóre regiony, sieci lub grupy użytkowników odnoszą sukces, inne nie. To może być zamierzony projekt (obsługuj tam, gdzie lokalna replika jest zdrowa) albo przypadkowy (nierównomierne trasy, nierówny dostęp do kworum).
Praktycznym kompromisem jest tryb degradacji: dalej obsługuj bezpieczne akcje, ograniczając ryzykowne. Na przykład pozwól na przeglądanie i wyszukiwanie, ale tymczasowo wyłącz „przelej środki”, „zmień hasło” czy inne operacje, gdzie poprawność i unikalność są kluczowe.
CAP wydaje się abstrakcyjne, dopóki nie przypiszesz go do tego, co użytkownik zobaczy podczas podziału sieci: wolisz, żeby system dalej odpowiadał, czy żeby przestać przyjmować lub zwracać sprzeczne dane?
Wyobraź sobie dwa centra danych, oba przyjmujące zamówienia, gdy nie mogą się porozumieć.
Jeśli zachowasz dostępność w procesie checkout, każda strona może sprzedać „ostatni egzemplarz” i dojść do oversellu. To może być akceptowalne dla nieskomplikowanych produktów (backorder, przeprosiny), ale bolesne przy limitowanych wypuszczeniach.
Jeśli wybierzesz spójność, możesz zablokować nowe zamówienia, gdy nie możesz potwierdzić globalnego stanu. Użytkownicy zobaczą „spróbuj ponownie później”, ale unikniesz sprzedaży rzeczy, których nie możesz dostarczyć.
Pieniądze to klasyczna domena, gdzie bycie w błędzie jest kosztowne. Jeśli dwie repliki niezależnie zaakceptują wypłaty podczas podziału, konto może pójść na minus.
Systemy często preferują spójność przy krytycznych zapisach: odrzucają lub opóźniają akcje, jeśli nie mogą potwierdzić bieżącego salda. Kosztem jest dostępność (tymczasowe błędy płatności) na rzecz poprawności, audytowalności i zaufania.
W czatach i feedach społecznościowych użytkownicy zwykle tolerują niewielkie niespójności: wiadomość przychodzi z kilkusekundowym opóźnieniem, licznik lajków się różni, metryki widoków aktualizują się później.
Tu projektowanie pod dostępność może być dobrym wyborem produktowym, o ile jasne jest, które elementy są „ostatecznie poprawne” i potrafisz dobrze scalać aktualizacje.
„Właściwy” wybór CAP zależy od kosztu bycia w błędzie: zwrotów, ryzyka prawnego, utraty zaufania użytkowników czy chaosu operacyjnego. Zdecyduj, gdzie możesz dopuścić tymczasową niespójność — a gdzie musisz zamknąć system.
Gdy już zdecydujesz, jak zachować się podczas podziału, potrzebujesz mechanizmów, które te decyzje wprowadzą w życie. Wzorce te pojawiają się w bazach danych, systemach kolejkowych i API — nawet jeśli produkt nigdy nie wspomina „CAP”.
Kworum to po prostu „większość replik się zgadza”. Jeśli masz 5 kopii danych, większość to 3.
Wymagając, żeby odczyty i/lub zapisy kontaktowały większość, zmniejszasz szansę na zwrócenie przeterminowanych lub sprzecznych danych. Na przykład, jeśli zapis musi być potwierdzony przez 3 repliki, trudniej jest, aby dwie izolowane grupy zaakceptowały różne „prawdy”.
Kosztem jest prędkość i zasięg: jeśli nie możesz osiągnąć większości (z powodu partycji lub awarii), system może odmówić operacji — wybierając spójność nad dostępnością.
Wiele problemów z dostępnością to nie totalne awarie, lecz wolne odpowiedzi. Krótki timeout sprawia, że system wydaje się szybki, ale też zwiększa ryzyko, że potraktujesz wolne sukcesy jako porażki.
Retry potrafi uratować chwilowe błędy, ale agresywne ponawianie może przeciążyć już nadwyrężony serwis. Backoff (wydłużanie przerw między ponowieniami) i jitter (losowość) pomagają uniknąć, żeby retry nie stały się falą ruchu.
Klucz: ustawienia muszą odpowiadać twojej obietnicy: „zawsze odpowiadać” zwykle oznacza więcej retry i fallbacków; „nigdy nie kłamać” — ostrzejsze limity i czytelne błędy.
Jeśli w trakcie partycji pozwalasz na różne aktualizacje, musisz je później pogodzić. Typowe podejścia to:\n
Retry mogą powodować duplikaty: podwójne obciążenie karty albo złożenie zamówienia dwa razy. Idempotencja temu zapobiega.
Popularny wzorzec to klucz idempotencji (ID żądania) wysyłany z każdym żądaniem. Serwer zapisuje pierwszy wynik i zwraca ten sam wynik dla powtórzeń — więc retry poprawiają dostępność bez psucia danych.
Większość zespołów „wybiera” postawę CAP na tablicy — a potem odkrywa w produkcji, że system zachowuje się inaczej pod obciążeniem. Weryfikacja znaczy: celowo wywołać warunki, w których kompromisy CAP staną się widoczne, i sprawdzić, czy system reaguje jak zaplanowano.
Nie musisz mieć naprawdę przeciętego kabla, żeby czegoś się nauczyć. Użyj kontrolowanego wstrzykiwania błędów w stagingu (i ostrożnie w produkcji), aby symulować partycje:\n
Cel to odpowiedzieć na konkretne pytania: Czy zapisy są odrzucane czy akceptowane? Czy odczyty pokazują stare dane? Czy system automatycznie się odzyskuje i ile trwa rekonsyliacja?
Jeśli chcesz zweryfikować te zachowania wcześnie (zanim spędzisz tygodnie na scalaniu usług), warto szybko postawić realistyczny prototyp. Na przykład zespoły używające Koder.ai często zaczynają od wygenerowania małej usługi (zwykle backend w Go z PostgreSQL i React UI) i iterują nad mechanikami jak retry, klucze idempotencji czy przepływy trybu degradacji w piaskownicy.
Tradycyjne checki uptime nie wykryją „dostępne, ale niepoprawne”. Śledź:\n
Operatorzy potrzebują wcześniej ustalonych działań na wypadek partycji: kiedy zamrozić zapisy, kiedy przeprowadzić failover, kiedy degradować funkcje i jak zweryfikować bezpieczeństwo ponownego scalania.
Zaplanuj też komunikację do użytkowników. Jeśli wybierasz spójność, komunikat może brzmieć: „Nie możemy teraz potwierdzić twojej aktualizacji — spróbuj ponownie.” Jeśli wybierasz dostępność, bądź jasny: „Twoja aktualizacja może pojawić się z opóźnieniem.” Jasne słowa redukują obciążenie supportu i chronią zaufanie.
Gdy podejmujesz decyzję systemową, CAP jest najprzydatniejszy jako szybki audyt „co się psuje podczas podziału?” — nie teoretyczna dyskusja. Użyj tego checklistu przed wyborem funkcji bazy danych, strategii cache’owania lub trybu replikacji.
Zadaj te pytania w kolejności:\n
Jeśli dojdzie do partycji, decydujesz, które z tych rzeczy chronisz najpierw.
Unikaj jednego globalnego ustawienia typu „jesteśmy AP”. Zamiast tego ustal decyzje per:\n
Przykład: podczas podziału możesz zablokować zapisy do payments (faworyzując spójność), ale utrzymać odczyty katalogu produktów z cache.
Zapisz, co możesz tolerować, z przykładami:\n
Jeśli nie potrafisz opisać niespójności prostymi przykładami, trudno będzie ją przetestować i wytłumaczyć przy incydencie.
Kolejne tematy warte lektury: konsensus, modele spójności oraz SLO i budżety błędów.
CAP to model myślowy dla systemów replikowanych podczas awarii komunikacji. Jest najbardziej przydatny, gdy sieć jest wolna, traci pakiety lub się dzieli — bo wtedy repliki nie mogą się wiarygodnie zgodzić i musisz zdecydować między:
Pomaga to zamienić „systemy rozproszone są trudne” na konkretne decyzje produktowe i inżynieryjne.
Prawdziwy scenariusz CAP wymaga obu warunków:
Jeśli twój system to pojedynczy węzeł albo nie replikujesz stanu, kompromisy CAP nie są głównym problemem.
Partycja to każda sytuacja, w której części systemu nie mogą komunikować się wiarygodnie lub w wymaganym czasie — nawet jeśli wszystkie maszyny nadal działają.
Praktycznie „partycja” często objawia się jako:
Z perspektywy aplikacji „za wolno” może być tym samym co „nie działa”.
Spójność (C) oznacza, że odczyty odzwierciedlają najnowszy potwierdzony zapis z dowolnego miejsca. Użytkownicy doświadczają tego jako „zmieniłem to i wszyscy to widzą.”
Dostępność (A) oznacza, że każde żądanie otrzymuje odpowiedź uznawaną za sukces (niekoniecznie najnowsze dane). Użytkownicy odbierają to jako „aplikacja działa dalej”, choć wyniki mogą być przeterminowane.
Podczas partycji zwykle nie da się zagwarantować obu tych właściwości jednocześnie dla wszystkich operacji.
Bo partycje są nieuniknione w systemach rozproszonych obejmujących wiele maszyn, szaf, stref lub regionów. Jeśli replikujesz, musisz określić zachowanie, gdy węzły nie mogą się skoordynować.
„Tolerować partycje” zwykle oznacza: gdy komunikacja zawodzi, system nadal ma zdefiniowany sposób działania — albo odrzuca/wstrzymuje pewne akcje (faworyzując spójność), albo zwraca najlepsze możliwe wyniki (faworyzując dostępność).
Jeśli faworyzujesz spójność, zwykle:
To jest powszechne w domenach takich jak transfery pieniędzy, rezerwacje czy zmiany uprawnień — gdzie bycie w błędzie jest gorsze niż krótkotrwała niedostępność.
Jeśli faworyzujesz dostępność, zwykle:
Użytkownicy widzą mniej twardych błędów, ale mogą zobaczyć przeterminowane dane, zduplikowane efekty bez idempotencji lub konflikty wymagające sprzątania.
Możesz wybierać inaczej dla różnych endpointów/typów danych. Typowe strategie mieszane to:
To pozwala uniknąć jednego globalnego etykietowania „jesteśmy AP/CP”, które rzadko pasuje do rzeczywistych potrzeb produktu.
Przydatne opcje poza „mocną” i „ostateczną” spójnością to:
Weryfikuj, tworząc warunki, w których różnice stają się widoczne:
Wybierz najsłabszą gwarancję, która zapobiega użytkownikowo widocznym „błedom”, których tolerować nie możesz.
Przygotuj też runbooki i komunikaty dla użytkowników, które odzwierciedlają wybrane zachowanie (fail closed vs fail open).