30 sie 2025·6 min
Nginx kontra HAProxy: wybór właściwego reverse proxy
Porównanie Nginx i HAProxy jako reverse proxy: wydajność, load balancing, TLS, obserwowalność, bezpieczeństwo i typowe konfiguracje, które pomogą wybrać najlepsze rozwiązanie.
Porównanie Nginx i HAProxy jako reverse proxy: wydajność, load balancing, TLS, obserwowalność, bezpieczeństwo i typowe konfiguracje, które pomogą wybrać najlepsze rozwiązanie.
Reverse proxy to serwer stojący przed Twoimi aplikacjami, który najpierw przyjmuje żądania od klientów. Przekazuje każde żądanie do odpowiedniego backendu (serwery aplikacyjne) i zwraca odpowiedź klientowi. Użytkownicy komunikują się z proxy; proxy komunikuje się z aplikacjami.
Forward proxy działa odwrotnie: stoi przed klientami (np. wewnątrz sieci firmowej) i przekazuje ich wychodzące żądania do internetu. Jego celem jest kontrola, filtrowanie lub ukrywanie ruchu klienckiego.
Load balancer często jest realizowany jako reverse proxy, ale z naciskiem na rozdzielanie ruchu między wiele instancji backendu. Wiele produktów (w tym Nginx i HAProxy) robi i proxy, i balancing, więc terminy bywają używane zamiennie.
Większość wdrożeń zaczyna się z jednego lub kilku powodów:
/api do usługi API, / do aplikacji webowej).Reverse proxy zwykle stoi przed stronami WWW, API i mikroserwisami — zarówno na krawędzi (internet publiczny), jak i wewnętrznie między usługami. W nowoczesnych stackach są też budulcem dla ingress gatewayów, blue/green deployów i rozwiązań high-availability.
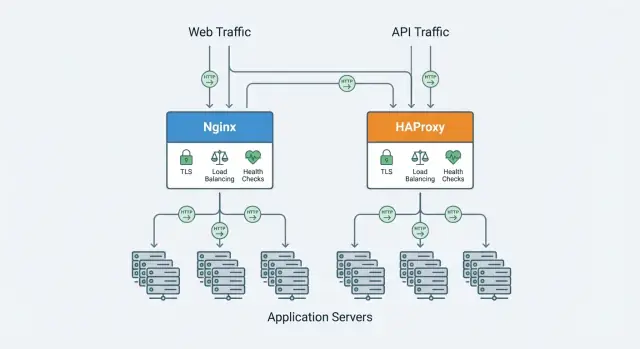
Nginx i HAProxy mają obszary wspólne, ale różnią się akcentami. Poniżej porównamy czynniki decyzyjne takie jak wydajność przy wielu połączeniach, load balancing i health checks, wsparcie protokołów (HTTP/2, TCP), funkcje TLS, obserwowalność i codzienna konfiguracja i operacje.
Nginx jest powszechnie używany zarówno jako serwer WWW, jak i reverse proxy. Wiele zespołów zaczyna od niego do obsługi publicznej strony, a potem rozszerza rolę o terminację TLS, routing i wygładzanie skoków ruchu.
Nginx błyszczy, gdy ruch jest głównie HTTP(S) i chcesz jednego „front door”, który potrafi trochę wszystkiego. Jest szczególnie dobry w:
X-Forwarded-For, nagłówki bezpieczeństwa)Ponieważ potrafi zarówno serwować treść, jak i proxy’ować, Nginx jest częstym wyborem w małych i średnich wdrożeniach, gdzie chce się mieć mniej elementów składowych.
Popularne możliwości to:
Nginx jest często wybierany, gdy potrzebujesz jednego punktu wejścia dla:
Jeśli priorytetem jest bogate przetwarzanie HTTP i chcesz łączyć serwowanie treści z proxy, Nginx często jest domyślnym wyborem.
HAProxy (High Availability Proxy) jest najczęściej używany jako reverse proxy i load balancer stojący przed jedną lub kilkoma aplikacjami. Akceptuje ruch, stosuje reguły routingu i przekazuje żądania do zdrowych backendów — często utrzymując stabilność czasów odpowiedzi przy dużej konkurencji połączeń.
Zespoły zwykle wdrażają HAProxy do zarządzania ruchem: rozkładania żądań między serwery, utrzymania dostępności przy awariach i wygładzania szczytów ruchu. To częsty wybór na krawędzi (ruch północ–południe) oraz między usługami wewnętrznymi (ruch wschód–zachód), zwłaszcza gdy potrzebujesz przewidywalnego zachowania i dużej kontroli nad połączeniami.
HAProxy jest znane z efektywnej obsługi dużej liczby jednoczesnych połączeń. Ma to znaczenie, gdy wiele klientów łączy się jednocześnie (obciążone API, długo żyjące połączenia, czat) i chcesz, aby proxy pozostawało responsywne.
Jego możliwości load balancingowe są kluczowym powodem wyboru. Poza prostym round-robin wspiera wiele algorytmów i strategii routingu, które pomagają:
Health checki to kolejny silny punkt. HAProxy potrafi aktywnie weryfikować stan backendów i automatycznie usuwać z rotacji niezdrowe instancje, a potem ponownie dodawać je po odzyskaniu. W praktyce zmniejsza to przestoje i zapobiega wpływowi „półzepsutych” wdrożeń na wszystkich użytkowników.
HAProxy może działać na Layer 4 (TCP) i Layer 7 (HTTP).
W praktyce: L4 jest zazwyczaj prostsze i bardzo szybkie do przekazywania TCP, natomiast L7 daje bogatsze możliwości routingu, gdy są potrzebne.
HAProxy często wybierają zespoły, gdy celem jest niezawodne, wysokowydajne równoważenie obciążenia z mocnymi health checkami — np. rozkładanie ruchu API między wieloma serwerami aplikacyjnymi, zarządzanie failover między strefami dostępności lub frontowanie usług, gdzie liczba połączeń i przewidywalność zachowania mają większe znaczenie niż funkcje serwera WWW.
Porównania wydajności często zawodzą, bo ludzie patrzą na jedną liczbę (np. „maks. RPS”) i ignorują to, co odczuwa użytkownik.
Proxy może zwiększyć przepustowość, a jednocześnie pogorszyć tail latency, jeśli pod obciążeniem zbyt dużo pracy jest kolejkowane.
Pomyśl o „kształcie” Twojej aplikacji:
Jeśli benchmarkujesz pod jednym wzorcem, a wdrażasz inny, wyniki nie będą przenośne.
Buforowanie może pomóc, gdy klienci są wolni lub ruch jest burstowy — proxy może odczytać całe żądanie (lub odpowiedź) i karmić aplikację równomierniej.
Buforowanie może zaszkodzić, gdy aplikacja korzysta ze streamingu (SSE, duże pobierania, realtime). Dodatkowe buforowanie zwiększa pamięć i może wydłużać tail latency.
Mierz więcej niż „maks. RPS”:
Jeśli p95 rośnie gwałtownie zanim pojawią się błędy, to wczesny sygnał nasycenia — nie „wolne zasoby”.
Zarówno Nginx, jak i HAProxy mogą stać przed wieloma instancjami aplikacji i rozdzielać ruch, ale różnią się głębokością funkcji load-balancingowych dostępnych od razu.
Round-robin to domyślny, „wystarczająco dobry” wybór, gdy backendy są podobne. Jest prosty, przewidywalny i sprawdza się dla bezstanowych aplikacji.
Least connections przydaje się, gdy żądania różnią się długością (pobierania plików, długie wywołania API, połączenia podobne do websocketów). Faworyzuje backendy obsługujące mniej aktywnych połączeń.
Weighted balancing (round-robin z wagami, albo weighted least connections) jest praktyczne, gdy serwery nie są identyczne — mieszane stare i nowe węzły, różne rozmiary instancji lub stopniowe przesuwanie ruchu.
Ogólnie HAProxy oferuje więcej algorytmów i drobiazgowej kontroli na L4/L7, podczas gdy Nginx pokrywa typowe przypadki czytelnie (można rozszerzać w zależności od edycji/modułów).
Stickiness sprawia, że użytkownik jest kierowany do tego samego backendu w kolejnych żądaniach.
Używaj stickiness tylko gdy musisz; aplikacje bezstanowe lepiej się skalują i odzyskują.
Aktywne health checki okresowo sondają backendy (endpoint HTTP, połączenie TCP, oczekiwany status). Wykrywają awarie nawet przy niskim ruchu.
Pasywne health checki reagują na rzeczywisty ruch: timeouty, błędy połączenia lub złe odpowiedzi oznaczają serwer jako niezdrowy. Są lekkie, ale wykrywanie problemów może zająć więcej czasu.
HAProxy jest szeroko znane z bogatych kontroli health-check (progi, liczniki rise/fall, szczegółowe sprawdzenia). Nginx również wspiera solidne checki, zależnie od builda i edycji.
Dla rolling deployów szukaj:
Paruj draining z krótkimi, jednoznacznymi timeoutami i jasnym endpointem "ready/unready", by ruch płynnie przesuwał się podczas wdrożeń.
Reverse proxy stoi na krawędzi systemu, więc wybory protokołów i TLS wpływają na wszystko — od wydajności w przeglądarce po to, jak bezpiecznie komunikują się usługi.
Zarówno Nginx, jak i HAProxy mogą terminować TLS: przyjmują zaszyfrowane połączenia od klientów, odszyfrowują ruch i przekazują żądania do aplikacji po HTTP albo ponownie szyfrują połączenie do upstreamu.
W praktyce operacyjnej istotne jest zarządzanie certyfikatami. Trzeba mieć plan na:
Nginx często wybierany jest, gdy terminacja TLS idzie w parze z funkcjami serwera WWW (pliki statyczne, przekierowania). HAProxy jest wybierane, gdy TLS jest częścią warstwy zarządzania ruchem (load balancing, obsługa połączeń).
HTTP/2 może skrócić czasy ładowania stron w przeglądarce poprzez multipleksowanie wielu żądań po jednym połączeniu. Oba narzędzia wspierają HTTP/2 po stronie klienta.
Kluczowe rozważenia:
Jeśli musisz kierować ruch nie-HTTP (bazy danych, SMTP, Redis, niestandardowe protokoły), potrzebujesz proxy TCP zamiast routingu HTTP. HAProxy jest szeroko stosowane jako wysokowydajne rozwiązanie TCP z drobiazgową kontrolą połączeń. Nginx też potrafi proxy TCP (przez stream), co może wystarczyć do prostych przypadków pass-through.
mTLS weryfikuje obie strony: klient prezentuje certyfikat, nie tylko serwer. Sprawdza się w komunikacji między usługami, integracjach z partnerami oraz w projektach zero-trust. Oba proxy potrafią wymusić walidację certyfikatów klientów na krawędzi, a wiele zespołów stosuje mTLS również wewnętrznie między proxy a upstreamami, by zmniejszyć założenia o „zaufanej sieci”.
Reverse proxy pośredniczy w każdym żądaniu, więc często jest najlepszym miejscem, by odpowiedzieć "co się stało?" Dobra obserwowalność to spójne logi, niewielki zestaw wartościowych metryk i powtarzalny sposób debugowania timeoutów i błędów bramkowych.
Przynajmniej trzymaj w produkcji access logs i error logs. W access logach uwzględnij timingi upstreamu, by wiedzieć, czy opóźnienie leży po stronie proxy, czy aplikacji.
W Nginx często używa się pól czasu żądania i czasu upstream (np. $request_time, $upstream_response_time, $upstream_status). W HAProxy włącz tryb logowania HTTP i zbieraj pola timingowe (queue/connect/response), by oddzielić „czekanie na slot backendu” od „backend był wolny”.
Trzymaj logi w formacie ustrukturyzowanym (JSON, jeśli to możliwe) i dodaj request ID (z nagłówka przychodzącego lub wygenerowane), by powiązać logi proxy z logami aplikacji.
Niezależnie czy scrappujesz Prometheus czy wysyłasz metryki gdzie indziej, eksportuj spójny zestaw:
Nginx często korzysta ze stub status lub eksportera Prometheus; HAProxy ma wbudowany endpoint statystyk, z którego czytają eksportery.
Wystaw lekki /health (proces żyje) i /ready (może osiągnąć zależności). Używaj obu w automatyzacji: health checki load balancerów, deployy i decyzje autoskalowania.
Przy debugowaniu porównaj timing proxy (connect/queue) z czasem odpowiedzi upstreamu. Jeśli connect/queue jest wysokie — dodaj pojemność lub dostosuj load balancing; jeśli upstream jest wolny — skup się na aplikacji i bazie danych.
Obsługa reverse proxy to nie tylko szczytowa przepustowość — to też to, jak szybko zespół może bezpiecznie wprowadzić zmianę o 14:00 (albo o 2:00 rano).
Konfiguracja Nginx jest oparta na dyrektywach i hierarchii. Czyta się ją jak „bloki w blokach” (http → server → location), co wielu osobom wydaje się przystępne, gdy myślą kategoriami witryn i ścieżek.
Konfiguracja HAProxy jest bardziej „pipeline’owa”: definiujesz frontendy (co akceptujesz), backendy (gdzie wysyłasz ruch) i dodajesz reguły (ACL), które je łączą. Może być bardziej jawna i przewidywalna, gdy przyswoisz model, zwłaszcza dla logiki routingu ruchu.
Nginx zwykle przeładowuje konfigurację, uruchamiając nowe workers i graceful draining starych. To przyjazne podejście dla częstych aktualizacji tras i odnowień certyfikatów.
HAProxy potrafi też robic seamless reloady, ale zespoły często traktują go bardziej jak “appliance”: ściślejsza kontrola zmian, wersjonowana konfiguracja i ostrożna koordynacja poleceń reload.
Oba narzędzia wspierają test konfiguracji przed reloadem (konieczność dla CI/CD). W praktyce konfiguracje utrzymuje się DRY generując je:
Kluczowa praktyka operacyjna: traktuj konfigurację proxy jak kod — review, testy i deploy jak zmiany aplikacyjne.
W miarę wzrostu liczby usług, to rozrost certyfikatów i routingu staje się głównym bólem. Zaplanuj:
Jeśli spodziewasz się setek hostów, rozważ centralizowanie wzorców i generowanie konfiguracji z metadanych usług zamiast ręcznego edytowania plików.
Jeśli budujesz i iterujesz wiele usług, reverse proxy to tylko część pipeline’u dostarczania — nadal potrzebujesz powtarzalnego scaffoldu aplikacji, zgodności środowisk i bezpiecznych rolloutów.
Koder.ai może pomóc zespołom szybciej przejść od „pomysłu” do działających usług, generując React web apps, Go + PostgreSQL backendy i Flutter mobilne aplikacje przez interfejs czatu, a następnie wspierać eksport źródeł, wdrożenie/hosting, własne domeny oraz snapshoty z rollbackiem. W praktyce możesz prototypować API + frontend, wdrożyć je i dopiero na podstawie realnego ruchu zdecydować, czy lepszym frontem będzie Nginx czy HAProxy.
Reverse proxy stoi przed Twoimi aplikacjami: klienci łączą się z proxy, a ono przekazuje żądania do odpowiednich backendów i zwraca odpowiedź.
Forward proxy stoi przed klientami i kontroluje wychodzący ruch do internetu (często używane w sieciach korporacyjnych).
Load balancer skupia się na rozdzielaniu ruchu między wiele instancji backendu. Wiele load balancerów jest implementowanych jako reverse proxy, dlatego terminy te często zachodzą na siebie.
W praktyce często użyjesz jednego narzędzia (np. Nginx lub HAProxy) zarówno do reverse proxy, jak i do load balancing.
Umieść go tam, gdzie chcesz mieć pojedynczy punkt kontroli:
Kluczowe jest, by klienci nie łączyli się bezpośrednio z backendami — proxy powinno pozostać punktem kontrolnym dla polityk i obserwowalności.
TLS termination oznacza, że proxy obsługuje HTTPS: przyjmuje zaszyfrowane połączenia od klientów, odszyfrowuje je i przekazuje ruch do upstreamów po HTTP lub ponownie szyfruje go TLS.
Operacyjnie trzeba zaplanować:
Wybierz Nginx, gdy proxy jest też „frontem” dla ruchu webowego:
Wybierz HAProxy, gdy priorytetem jest zarządzanie ruchem i przewidywalność pod obciążeniem:
Użyj round-robin dla podobnych backendów i jednolitych kosztów żądań.
Użyj least connections gdy czas trwania żądań się różni (pobieranie, długie wywołania API, połączenia długożyjące), by nie przeciążać wolniejszych instancji.
Użyj weighted gdy backendy się różnią (różne rozmiary instancji, mieszane środowiska, migracje) — pozwala to kontrolować przesunięcie ruchu.
Stickiness utrzymuje użytkownika przy tym samym backendzie pomiędzy żądaniami.
Unikaj przyklejania sesji, jeśli to możliwe — usługi bezstanowe lepiej skalują i łatwiej je aktualizować.
Buffering może pomagać, wygładzając ruch z wolnych lub burstujących klientów, dzięki czemu backend otrzymuje stabilniejszy strumień żądań.
Może jednak szkodzić przy potrzebie streamingu (SSE, WebSockety, duże pobierania): dodatkowe buforowanie zwiększa zużycie pamięci i może pogorszyć tail latency.
Jeśli aplikacja opiera się na streamingu, testuj i dostosowuj buforowanie zamiast polegać na domyślnych ustawieniach.
Rozpocznij od rozdzielenia opóźnienia proxy od opóźnienia backendu używając logów i metryk.
Typowe znaczenia:
Sygnały do sprawdzenia:
Naprawy zwykle obejmują regulację timeoutów, zwiększenie pojemności backendu lub poprawę health checks/readiness.