Niezawodne integracje webhooków: podpisy, idempotencja, debugowanie
Naucz się tworzyć niezawodne integracje webhooków z podpisami, kluczami idempotencji, ochroną przed replay i szybkim procesem debugowania zgłoszeń klientów.
Dlaczego webhooki zawodzą w prawdziwym świecie
Kiedy ktoś mówi „webhooki nie działają”, zwykle ma na myśli jedno z trzech: zdarzenia nie dotarły, zdarzenia dotarły dwukrotnie, albo dotarły w mylącej kolejności. Z perspektywy klienta system „coś stracił”. Z twojej perspektywy dostawca wysłał zdarzenie, ale twój endpoint go nie przyjął, nie przetworzył albo nie zapisał zgodnie z oczekiwaniem.
Webhooki działają w publicznym internecie. Żądania się opóźniają, są ponawiane i czasem dostarczane nie w kolejności. Większość dostawców agresywnie ponawia próby przy timeoutach lub odpowiedziach nie-2xx. Mały zator (wolna baza, deploy, krótka przerwa) zamienia się w duplikaty i warunki wyścigu.
Słabe logi sprawiają, że to wygląda jak chaos. Jeśli nie możesz udowodnić, że żądanie było autentyczne, nie możesz bezpiecznie na nim działać. Jeśli nie możesz powiązać skargi klienta z konkretną próbą dostawy, zaczynasz zgadywać.
Większość realnych awarii trafia do kilku kategorii:
- „Zaginione” zdarzenia (timeout, błąd, albo błąd po potwierdzeniu)
- Duplikaty (retry + handler bez idempotencji)
- Zła kolejność (założyłeś, że kolejność dostarczeń równa się kolejności zdarzeń)
- Tajemnicze żądania (brak weryfikacji podpisu, więc nie możesz oddzielić prawdziwych od fałszywych)
Praktyczny cel jest prosty: zaakceptować prawdziwe zdarzenia raz, odrzucić fałszywe i zostawić czytelny ślad, żebyś mógł prześledzić skargę klienta w kilka minut.
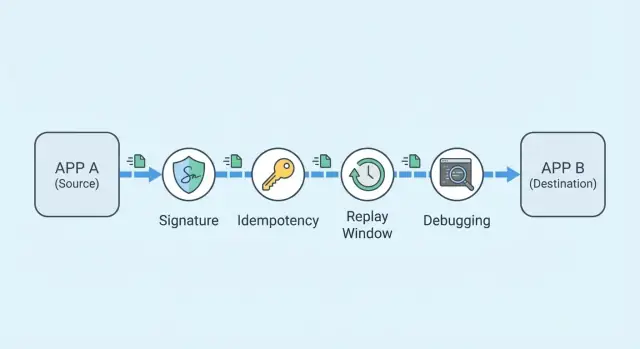
Jak webhooki faktycznie się zachowują
Webhook to po prostu żądanie HTTP, które dostawca wysyła na wystawiony przez ciebie endpoint. Nie pobierasz go jak zwykłe API. Nadawca wypycha go, gdy coś się dzieje, a twoim zadaniem jest przyjąć je, odpowiedzieć szybko i przetworzyć bezpiecznie.
Typowa dostawa zawiera ciało żądania (często JSON) oraz nagłówki, które pomagają Ci zweryfikować i zidentyfikować to, co otrzymałeś. Wielu dostawców dołącza timestamp, typ zdarzenia (np. invoice.paid) oraz unikalne ID zdarzenia, które możesz zapisać do wykrywania duplikatów.
Zaskakujące dla zespołów: dostawa niemal nigdy nie oznacza „dokładnie raz”. Większość dostawców celuje w „at least once”, co oznacza, że to samo zdarzenie może przyjść wielokrotnie, czasem z minutowym lub godzinowym odstępem.
Retry następują z nudnych powodów: twój serwer jest wolny lub timeoutuje, zwracasz 500, ich sieć nie widzi twojego 200, albo endpoint jest chwilowo niedostępny podczas deployu czy wzrostu ruchu.
Timeout jest szczególnie podstępny. Twój serwer może otrzymać żądanie i nawet zakończyć jego przetwarzanie, ale odpowiedź nie dotrze do nadawcy na czas. Z perspektywy dostawcy to zawiodło, więc ponawia. Bez ochrony przetwarzasz to samo zdarzenie dwa razy.
Dobry model myślowy: traktuj żądanie HTTP jako „próbę dostawy”, nie jako „zdarzenie”. Zdarzenie identyfikuje jego ID. Twoje przetwarzanie powinno opierać się na tym ID, a nie na tym, ile razy dostawca do ciebie dzwoni.
Podpisy webhooków prostym językiem
Podpis webhooka to sposób, w jaki nadawca udowadnia, że żądanie naprawdę pochodzi od niego i nie zostało zmienione w trakcie przesyłu. Bez podpisu każdy, kto zgadnie URL webhooka, może wysłać fałszywe „płatność udana” lub „użytkownik awansował”. Co gorsza, prawdziwe zdarzenie może zostać zmienione w tranzycie (kwota, ID klienta, typ zdarzenia) i dalej wyglądać wiarygodnie dla aplikacji.
Najczęstszy wzorzec to HMAC z tajnym kluczem. Obie strony znają tę samą wartość sekretu. Nadawca bierze dokładny payload (zwykle surowe ciało żądania), liczy HMAC przy użyciu tego sekretu i dołącza podpis razem z payloadem. Twoim zadaniem jest ponownie policzyć HMAC po tych samych bajtach i sprawdzić, czy podpisy się zgadzają.
Dane podpisu zwykle trafiają do nagłówka HTTP. Niektórzy dostawcy dołączają tam też timestamp, co pozwala dodać ochronę przed replay. Mniej powszechne jest osadzanie podpisu w samym JSON—jest to bardziej ryzykowne, bo parsery lub ponowna serializacja mogą zmienić format i zepsuć weryfikację.
Przy porównywaniu podpisów nie używaj zwykłego porównania stringów. Proste porównania mogą ujawniać różnice czasowe, które pomagają atakującemu odgadnąć poprawny podpis przez wiele prób. Używaj funkcji porównania w czasie stałym z biblioteki kryptograficznej lub języka i odrzucaj przy jakiejkolwiek niezgodności.
Jeśli klient zgłasza: „wasza aplikacja zaakceptowała zdarzenie, którego my nie wysyłaliśmy”, zacznij od sprawdzenia podpisów. Jeśli weryfikacja nie przechodzi, najprawdopodobniej masz niezgodny sekret lub haszujesz złe bajty (np. parsujesz JSON zamiast użyć surowego body). Jeśli przechodzi, możesz zaufać tożsamości nadawcy i przejść dalej do deduplikacji, kolejności i retry.
Krok po kroku: weryfikacja podpisu webhooka
Niezawodne obsługiwanie webhooków zaczyna się od jednej nudnej zasady: weryfikuj to, co otrzymałeś, a nie to, co chciałbyś otrzymać.
Bezpieczny sposób weryfikacji
Przechwyć surowe ciało żądania dokładnie tak, jak dotarło. Nie parsuj i nie serializuj JSON przed sprawdzeniem podpisu. Nawet drobne różnice (whitespace, kolejność kluczy, unicode) zmieniają bajty i mogą sprawić, że prawidłowy podpis wyda się nieprawidłowy.
Potem zbuduj dokładny ciąg, który dostawca spodziewa się, że podpiszesz. Wiele systemów podpisuje ciąg w stylu timestamp + "." + raw_body. Timestamp nie jest dekoracją — pozwala odrzucać stare żądania.
Oblicz HMAC używając tajnego klucza i wymaganego algorytmu (często SHA-256). Przechowuj sekret w bezpiecznym magazynie i traktuj go jak hasło.
Na koniec porównaj obliczoną wartość z nagłówkiem podpisu używając porównania w czasie stałym. Jeśli nie pasuje, zwróć 4xx i przerwij. Nie „akceptuj mimo wszystko”.
Krótka lista kontrolna implementacji:
- Odczytaj body jako bajty raz, zapisz je i użyj tych samych bajtów do weryfikacji.
- Odtwórz podpisany ciąg dokładnie, włączając separatory i formatowanie timestampa.
- Oblicz HMAC z właściwym sekretem i algorytmem.
- Porównaj podpisy bezpiecznie i odrzuć niezgodności.
- Loguj powód niepowodzenia weryfikacji (brak nagłówka, zły timestamp, niezgodność) bez logowania sekretu ani pełnego podpisu.
Krótki przykład
Klient zgłasza: „webhooki przestały działać” po dodaniu middleware parsującego JSON. W logach widzisz niezgodności podpisów, głównie przy większych payloadach. Naprawa zwykle polega na weryfikacji surowego body przed jakimkolwiek parsowaniem i logowaniu, który krok zawiódł (np. „brak nagłówka podpisu” vs „timestamp poza dozwolonym oknem”). Ten szczegół często skraca debug z godzin do kilku minut.
Klucze idempotencji: zaakceptuj raz, bezpiecznie
Dostawcy ponawiają wysyłki, bo dostawa nie jest gwarantowana. Twój serwer może być niedostępny przez minutę, hop sieciowy może zgubić pakiet, albo handler może timeoutować. Dostawca zakłada „może zadziałało” i wysyła to samo zdarzenie ponownie.
Idempotency key to numer potwierdzenia, którego używasz, żeby rozpoznać zdarzenie, które już przetworzyłeś. To nie jest funkcja bezpieczeństwa i nie zastępuje weryfikacji podpisu. Nie rozwiąże też warunków wyścigu, jeśli nie zapisujesz i nie sprawdzasz go bezpiecznie przy współbieżności.
Wybór klucza zależy od tego, co daje dostawca. Preferuj wartość, która jest stabilna przy retry:
- Event ID (najlepsze, gdy jedno zdarzenie odpowiada jednej zmianie biznesowej)
- Delivery ID lub message ID (najlepsze, gdy retry zachowują ten sam identyfikator dostawy)
- Hash stabilnych pól (ostateczność, jeśli brak identyfikatora)
Gdy otrzymasz webhook, najpierw zapisz klucz w magazynie z regułą unikalności, tak żeby tylko jedno żądanie „wygrało”. Potem przetwórz zdarzenie. Jeśli zobaczysz ten sam klucz ponownie, zwróć sukces bez powtarzania pracy.
Przechowuj „paragon” krótki, ale użyteczny: klucz, status przetwarzania (received/processed/failed), timestampy (pierwsze wykrycie/ostatnie wykrycie) i minimalne podsumowanie (typ zdarzenia i powiązane ID obiektu). Wiele zespołów przechowuje klucze 7–30 dni, aby objąć późne retry i większość zgłoszeń klientów.
Ochrona przed powtórnym odtwarzaniem bez blokowania prawdziwego ruchu
Replay polega na tym, że ktoś złapie prawdziwe żądanie webhook (z ważnym podpisem) i wyśle je ponownie później. Jeśli handler traktuje każdą dostawę jako nową, taki replay może spowodować podwójne zwroty, duplikaty zaproszeń użytkowników lub powtarzające się zmiany statusów.
Popularne podejście to podpisanie nie tylko payloadu, ale też timestampa. Twój webhook ma nagłówki typu X-Signature i X-Timestamp. Po otrzymaniu: zweryfikuj podpis i sprawdź, czy timestamp jest świeży w krótkim oknie czasowym.
Dryft zegara jest źródłem fałszywych odrzuceń. Twoje serwery i serwery nadawcy mogą różnić się o minutę lub dwie, a sieć może opóźnić dostawę. Daj bufor i loguj powód odrzucenia.
Praktyczne reguły:
- Akceptuj tylko jeśli
abs(now - timestamp) <= window(np. 5 minut plus drobna tolerancja). - Polegaj na idempotencji jako rzeczywistym zabezpieczeniu. Nawet w oknie retry nie powinny podwójnie zastosować zmian.
- Jeśli odrzucisz z powodu czasu, zwróć czytelne 4xx i zaloguj otrzymany timestamp oraz czas serwera.
Jeśli timestampów brakuje, nie możesz przeprowadzić prawdziwej ochrony przed replay opierając się tylko na czasie. W takim przypadku bardziej polegaj na idempotencji (przechowuj i odrzucaj duplikaty po event ID) i rozważ wymaganie timestampów w następnej wersji webhooka.
Rotacja sekretów również ma znaczenie. Jeśli rotujesz sekrety podpisów, trzymaj kilka aktywnych sekretów przez krótki okres nakładania się. Weryfikuj najpierw względem najnowszego, potem przywracaj się do starszych. To zapobiega problemom klientów podczas rolloutów. Jeśli twój zespół szybko wdraża endpointy (np. generując kod z Koder.ai i używając snapshotów oraz rollbacku), okno nakładania się pomaga, bo starsze wersje mogą być wciąż aktywne krótko po deployu.
Zaprojektuj handler tak, żeby retryy nie szkodziły
Retryy są normalne. Zakładaj, że każda dostawa może być zduplikowana, opóźniona lub w złej kolejności. Twój handler powinien zachowywać się tak samo, czy widzi zdarzenie raz, czy pięć razy.
Utrzymuj ścieżkę żądania krótką. Rób tylko to, co konieczne do zaakceptowania zdarzenia, a cięższą pracę przerzuć do zadania w tle.
Prosty, sprawdzony wzorzec produkcyjny:
- Waliduj podstawy (metoda, content-type, wymagane nagłówki).
- Zweryfikuj autentyczność (podpis) i odrzuć wszystko, co nie przejdzie.
- Parsuj i waliduj payload.
- Deduplikuj używając event ID (lub klucza idempotencji) w tabeli z unikalnym ograniczeniem.
- Enqueue'uj pracę z event ID, a potem odpowiedz.
Zwróć 2xx tylko po tym, jak zweryfikujesz podpis i zapiszesz zdarzenie (lub umieścisz je w kolejce). Jeśli odpowiesz 200 przed zapisaniem czegokolwiek, możesz stracić zdarzenia przy awarii. Jeśli wykonasz ciężką pracę przed odpowiedzią, timeouty wywołają retry i możesz powtórzyć efekty uboczne.
Wolne systemy downstream to główny powód, dla którego retryy bolą. Jeśli dostawca e-mail, CRM lub baza jest wolna, pozwól kolejce wchłonąć opóźnienie. Worker może retryować z backoffem i możesz mieć alerty na zablokowane zadania, bez blokowania nadawcy.
Zdarzenia poza kolejnością też występują. Na przykład subscription.updated może przyjść przed subscription.created. Buduj tolerancję: sprawdzaj aktualny stan przed zastosowaniem zmian, pozwalaj na upserty i traktuj „nie znaleziono” jako sygnał do ponowienia później (gdy to ma sens), zamiast jako błąd trwały.
Typowe błędy prowadzące do trudnych do zdiagnozowania problemów
Wiele „losowych” problemów z webhookami jest wywołanych przez nas samych. Wyglądają jak niestabilne sieci, ale powtarzają się w wzorcach, zazwyczaj po deployu, rotacji sekretów lub małej zmianie w parsowaniu.
Najczęstszy błąd z podpisami to haszowanie złych bajtów. Jeśli najpierw parsujesz JSON, serwer może go przeformatować (whitespace, kolejność kluczy, format liczb). Potem weryfikujesz podpis względem innego body niż to, które podpisał nadawca i weryfikacja zawodzi, mimo że payload jest prawdziwy. Zawsze weryfikuj względem surowych bajtów dokładnie takim, jak dotarły.
Kolejne źródło zamieszania to sekrety. Zespoły testują w stagingu, ale przypadkowo weryfikują produkcyjnym sekretem, albo zostawiają stary sekret po rotacji. Gdy klient zgłasza awarie „tylko w jednym środowisku”, zacznij od sprawdzenia sekretu lub konfiguracji.
Kilka błędów prowadzących do długich śledztw:
- Logowanie całego body do debugu i wyciek tokenów, e-maili lub danych płatniczych do logów.
- Zwracanie 500 podczas wykonywania efektów ubocznych (wysyłanie maili, aktualizacja zamówień). Retry powtórzy te efekty.
- Używanie klucza idempotencji, który nie jest naprawdę unikalny (np. typ zdarzenia + minuta). Prawdziwe zdarzenia są odrzucane jako „duplikaty”.
- Traktowanie 2xx jako „przetworzone”, podczas gdy kod tylko umieścił pracę w kolejce, która potem nie powiodła się.
Przykład: klient mówi „order.paid nie dotarło”. W logach widzisz niezgodności podpisu pojawiające się po refaktorze, który zmienił middleware parsujące request. Middleware odczytuje i re-koduje JSON, więc weryfikacja podpisu używa teraz zmienionego body. Naprawa jest prosta, ale tylko jeśli wiesz, gdzie szukać.
Szybkie debugowanie zgłoszeń od klientów
Gdy klient mówi „wasz webhook nie zadziałał”, traktuj to jako problem śledzenia, nie zgadywania. Ustal jedną konkretną próbę dostawy od dostawcy i prześledź ją przez system.
Zacznij od pobrania identyfikatora dostawy od dostawcy: request ID, delivery ID lub event ID dla nieudanego przykładu. Z tym jednym identyfikatorem powinieneś szybko znaleźć pasujący wpis w logach.
Następnie sprawdź trzy rzeczy w kolejności:
- Czy weryfikacja podpisu przeszła?
- Czy check timestampa/przedziału replay przeszedł (jeśli używasz)?
- Czy idempotencja potraktowała to jako nowe czy jako duplikat?
Potem potwierdź, co zwróciłeś dostawcy. Wolne 200 może być równie złe jak 500, jeśli dostawca timeoutuje i retryuje. Sprawdź kod odpowiedzi, czas odpowiedzi i czy handler potwierdził przed wykonaniem ciężkiej pracy.
Jeśli musisz odtworzyć, rób to bezpiecznie: przechowaj zanonimizowany surowy przykład żądania (kluczowe nagłówki + surowe body) i odtwórz go w środowisku testowym używając tego samego sekretu i kodu weryfikującego.
Szybka lista kontrolna do wykonania w 10 minut
Gdy integracja webhooków zaczyna „losowo” zawodzić, szybkie działanie jest ważniejsze niż perfekcja. Ten plan łapie zwykłe przyczyny.
Najpierw weź jeden konkretny przykład: nazwa dostawcy, typ zdarzenia, przybliżony timestamp (z strefą czasową) i dowolne event ID, które klient widzi.
Potem zweryfikuj:
- Czy weryfikacja podpisu używa surowych bajtów body (przed parsowaniem JSON) i właściwego sekretu dla tego środowiska.
- Czy reguły replay mają sens dla prawdziwych retryów (i czy zegar serwera jest poprawny).
- Czy idempotencja naprawdę deduplikuje (unikalny indeks, zapis przed przetwarzaniem, sensowny okres przechowywania).
- Czy handler potwierdza dopiero po walidacji i trwałym zapisaniu/umieszczeniu w kolejce.
- Czy logi zawierają minimalny, przeszukiwalny paragon: provider, event_id, signature_ok, replay_ok, idempotency_status, response_code, latency_ms.
Jeśli dostawca mówi „ponawialiśmy 20 razy”, sprawdź najpierw wzorce: zły sekret (signature fails), dryft zegara (replay window), limity rozmiaru payloadu (413), timeouty (brak odpowiedzi) i nagłe 5xx od zależności.
Przykład: śledzenie zgłoszenia "zaginionego zdarzenia" od początku do końca
Klient pisze: „Przegapiliśmy zdarzenie invoice.paid wczoraj. Nasz system nie zaktualizował stanu.” Oto szybki sposób śledzenia.
Najpierw potwierdź, czy dostawca próbował dostarczyć. Pobierz event ID, timestamp, docelowy URL i dokładny kod odpowiedzi, który zwrócił wasz endpoint. Jeśli były retry, zanotuj powód pierwszej niepowodzenia i czy późniejszy retry się powiódł.
Następnie sprawdź, co twój kod zobaczył na brzegu: potwierdź sekret podpisu skonfigurowany dla tego endpointu, przelicz weryfikację podpisu używając surowego ciała żądania i porównaj request timestamp z dozwolonym oknem.
Bądź ostrożny z oknami replay podczas retryów. Jeśli okno to 5 minut, a dostawca retryował 30 minut później, możesz odrzucić prawidłowy retry. Jeśli taka jest twoja polityka, upewnij się, że jest to zamierzone i udokumentowane. Jeśli nie, poszerz okno lub zmień logikę tak, żeby idempotencja była główną linią obrony.
Jeśli podpis i timestamp wyglądają dobrze, prześledź event ID przez system i odpowiedz: czy przetworzyliście, zdeduplikowaliście, czy odrzuciliście?
Typowe wyniki:
- Zdeduplikowane: klucz idempotencji już istnieje, więc zwróciłeś 200 bez ponownego wykonania logiki biznesowej.
- Odrzucone: walidacja nie przeszła (niezgodność podpisu, za stary timestamp, brak nagłówków).
- Timeout: handler trwał za długo, dostawca oznaczył jako nieudane i retryował.
W odpowiedzi do klienta bądź zwięzły i konkretny: „Otrzymaliśmy próby dostawy o 10:03 i 10:33 UTC. Pierwsza zakończyła się timeoutem po 10s; retry został odrzucony, bo timestamp był poza naszym 5-min oknem. Zwiększyliśmy okno i przyspieszyliśmy potwierdzenie. Prosimy o ponowne wysłanie event ID X, jeśli potrzeba.”
Następne kroki: spraw, żeby było powtarzalne
Najszybszy sposób, żeby zatrzymać pożary z webhookami, to sprawić, by każda integracja przestrzegała jednego playbooka. Spisz kontrakt, na który się ty i nadawca umawiacie: wymagane nagłówki, dokładna metoda podpisywania, który timestamp jest używany i które ID traktujecie jako unikalne.
Ustandaryzuj też to, co zapisujecie dla każdej próby dostawy. Mały log potwierdzeń zwykle wystarcza: received_at, event_id, delivery_id, signature_valid, idempotency_result (new/duplicate), handler_version i response status.
Przydatny workflow wraz ze skalą:
- Miej dedykowany endpoint testowy, który weryfikuje podpisy i zwraca 2xx bez wykonywania akcji biznesowych.
- Przechowuj surowe ciało żądania i kluczowe nagłówki przez krótki czas, tylko na potrzeby debugu i replayu.
- Zbuduj job bezpieczny dla replayów, który przepuści zapisane zdarzenia przez ten sam kod handlera.
- Miej jedną wewnętrzną checklistę, której trzymają się support, QA i inżynieria.
Jeśli budujesz aplikacje na Koder.ai (Koder.ai), Planning Mode to dobry sposób na najpierw zdefiniowanie kontraktu webhooka (nagłówki, podpisy, ID, zachowanie retry), a potem wygenerowanie spójnego endpointu i zapisu potwierdzeń w różnych projektach. To spójność właśnie sprawia, że debugowanie jest szybkie zamiast heroiczne.
Często zadawane pytania
Dlaczego webhooki wydają się „losowo” zawodzić albo się duplikować w produkcji?
Ponieważ dostarczanie webhooków jest zwykle at-least-once, a nie dokładnie raz. Dostawcy ponawiają wysyłki przy timeoutach, odpowiedziach 5xx i czasem gdy nie zobaczą Twojego 2xx na czas, więc możesz otrzymać duplikaty, opóźnienia i wydarzenia w złej kolejności nawet gdy wszystko działa.
Jaki jest najbezpieczniejszy podstawowy przepływ obsługi żądania webhook?
Domyślny porządek działania: najpierw zweryfikuj podpis, potem zapisz/zde-duplikuj zdarzenie, odpowiedz 2xx, a ciężką pracę wykonaj asynchronicznie.
Jeśli wykonasz ciężką pracę przed odpowiedzią, trafisz na timeouty i wywołasz retry; jeśli odpowiesz zanim zapiszesz cokolwiek, możesz stracić zdarzenia przy awarii.
Jak uniknąć niezgodności podpisu przy weryfikacji webhooków?
Używaj surowych bajtów ciała żądania dokładnie tak, jak dotarły. Nie parsuj JSON i nie serializuj ponownie przed weryfikacją—białe znaki, kolejność kluczy i formatowanie liczb mogą złamać podpis.
Upewnij się też, że odtwarzasz dokładnie podpisany ciąg (często timestamp + "." + raw_body).
Co powinien zrobić mój endpoint, gdy weryfikacja podpisu nie przejdzie?
Zwróć 4xx (np. 400 lub 401) i nie przetwarzaj payloadu.
Zaloguj krótki powód (brak nagłówka z podpisem, niezgodność, niewłaściwy przedział czasowy), ale nie loguj sekretów ani pełnych wrażliwych danych.
Czym jest klucz idempotencji dla webhooków i jakiej wartości powinienem użyć?
Klucz idempotencji to stabilny, unikalny identyfikator, który zapisujesz, żeby retry nie powielały efektów ubocznych.
Najlepsze opcje:
- Event ID (idealne, gdy pojedyncze zdarzenie odpowiada jednej zmianie biznesowej)
- Delivery/message ID (jeśli ten sam identyfikator jest zachowany przy retry)
- Hash stabilnych pól (ostateczność)
Wymuszaj go przez unikalny indeks, żeby tylko jedno żądanie „wygrało” przy konkurencji.
Jak deduplikować webhooki bez warunków wyścigu?
Zapisz klucz idempotencji przed wykonaniem efektów ubocznych, z regułą unikalności. Następnie:
- Oznacz go jako przetworzony po powodzeniu, lub
- Zarejestruj status błędu, żeby móc bezpiecznie retryować
Jeśli wstawienie się nie powiedzie, bo klucz już istnieje, zwróć 2xx i pomiń ponowne wykonanie akcji biznesowej.
Jak dodać ochronę przed replay bez odrzucania prawdziwego ruchu?
Podpisuj nie tylko payload, ale też znacznik czasu. Nagłówki typu X-Signature i X-Timestamp pozwalają sprawdzić, czy żądanie jest świeże.
Aby nie odrzucać prawidłowych retry:
- Pozwól na pewien dryft zegara
- Zaloguj czas serwera i otrzymany timestamp przy odrzuceniu
- Traktuj idempotencję jako główną ochronę przeciw duplikatom; okno czasowe służy głównie blokowaniu replayów
Jak obsługiwać zdarzenia webhooków przychodzące w złej kolejności?
Nie zakładaj, że kolejność dostarczeń odpowiada kolejności zdarzeń. Zrób handler odporny:
- Stosuj upserty tam, gdzie to możliwe
- Sprawdzaj aktualny stan przed zastosowaniem zmian
- Jeśli obiekt nie istnieje, rozważ ponowne przetworzenie później (przez kolejkę) zamiast trwałego błędu
Zapisuj event_id i typ zdarzenia, żeby móc analizować przebieg nawet przy dziwnej kolejności.
Co powinienem logować, żeby debugowanie webhooków nie zamieniło się w zgadywankę?
Zaloguj mały „paragon” dla każdej próby dostawy, żeby prześledzić zdarzenie end-to-end:
- provider, event_id, delivery_id
- signature_ok, replay_ok
- wynik idempotencji (nowy/duplikat)
- response_code, latency_ms
- timestampy (received/first_seen/last_seen)
Upewnij się, że logi są przeszukiwalne po event_id, żeby wsparcie mogło szybko odpowiadać klientom.
Jaki jest szybki sposób zbadania zgłoszenia klienta, że „webhook nigdy nie dotarł”?
Poproś o jeden konkretny identyfikator: event ID lub delivery ID i przybliżony timestamp.
Następnie sprawdź w tej kolejności:
- Wynik weryfikacji podpisu
- Wynik sprawdzenia timestampu/okna replay (jeśli używasz)
- Wynik idempotencji (nowy vs duplikat)
- Co zwróciliście (status + czas odpowiedzi)
Jeśli budujesz endpointy z Koder.ai, utrzymuj spójny wzorzec (verify → record/dedupe → queue → respond). Spójność przyspiesza analizę incydentów.