Transformer to sposób, by pomóc komputerom rozumieć sekwencje — rzeczy, w których liczy się porządek i kontekst, jak zdania, kod czy seria zapytań. Zamiast czytać tokeny po kolei i polegać na kruchej pamięci, Transformery patrzą na całą sekwencję i decydują, na co zwrócić uwagę przy interpretacji każdej części.
Ta prosta zmiana okazała się przełomowa. To jedna z głównych przyczyn, dla których współczesne duże modele językowe (LLM) potrafią utrzymać kontekst, wykonywać polecenia, pisać spójne akapity i generować kod odwołujący się do wcześniejszych funkcji i zmiennych.
Jeśli korzystałeś z chatbota, funkcji „podsumuj to”, wyszukiwania semantycznego czy asystenta do kodu, miałeś do czynienia z systemami opartymi na Transformerach. Ten sam podstawowy schemat napędza:
- narzędzia chatowe i wsparcia klienta, śledzące, co powiedziałeś wcześniej
- systemy wyszukiwania i rekomendacji, dopasowujące sens, nie tylko słowa kluczowe
- podsumowania, które ważą, co jest istotne, a co drugorzędne
- narzędzia programistyczne łączące definicje, użycie i intencję w różnych plikach
Czego nauczysz się z tego artykułu
Rozłożymy na części kluczowe elementy — self-attention, multi-head attention, kodowanie pozycyjne i podstawowy blok Transformera — i wytłumaczymy, dlaczego ta konstrukcja tak dobrze skalowalna wraz ze wzrostem modeli.
Omówimy też nowoczesne warianty, które zachowują tę samą ideę, ale dostosowują ją pod kątem szybkości, kosztów lub dłuższych okien kontekstowych.
Czego się spodziewać (i czego nie)
To przegląd na wysokim poziomie z wyjaśnieniami w prostym języku i minimalną matematyką. Celem jest budowanie intuicji: co robią poszczególne części, dlaczego współpracują i jak przekłada się to na rzeczywiste możliwości produktu.
Noam Shazeer jest badaczem i inżynierem AI najbardziej znanym jako jeden ze współautorów artykułu z 2017 r. “Attention Is All You Need.” Ten artykuł wprowadził architekturę Transformera, która stała się potem fundamentem wielu współczesnych LLM-ów. Wkład Shazeera był częścią pracy zespołowej: Transformer powstał w grupie badaczy w Google i warto przypisywać mu takie właśnie zespołowe autorstwo.
Co zmienił artykuł z 2017 r.
Przed Transformerem wiele systemów NLP opierało się na modelach rekurencyjnych, które przetwarzały tekst krok po kroku. Propozycja Transformera pokazała, że można modelować sekwencje skutecznie bez rekurencji, używając uwagi jako głównego mechanizmu łączenia informacji w zdaniu.
Ta zmiana miała znaczenie, bo ułatwiła równoleglenie trenowania (można przetwarzać dużo tokenów na raz) i otworzyła drogę do skalowania modeli i zbiorów danych w sposób praktyczny dla produktów.
Od idei badawczej do budulca produktu
Wkład Shazeera — obok pozostałych autorów — nie pozostał jedynie testem akademickim. Transformer stał się modułem wielokrotnego użytku, który zespoły mogły dostosowywać: wymieniać komponenty, zmieniać rozmiar, stroić pod zadania i później trenować na dużą skalę.
W ten sposób wiele przełomów trafia do praktyki: artykuł przedstawia czysty, ogólny przepis; inżynierowie go dopracowują; firmy operacjonalizują; w końcu staje się domyślnym wyborem do budowy funkcji językowych.
Dokładne przypisywanie zasług
Prawdziwe jest, że Shazeer był kluczowym współautorem artykułu Transformera. Nieprawdziwe byłoby przedstawianie go jako jedynego wynalazcy. Wpływ pochodzi z kolektywnego projektu i z wielu kolejnych ulepszeń, które społeczność zbudowała na oryginalnym szkicu.
Co było wcześniej: RNN-y, LSTM-y i ich ograniczenia
Zanim pojawiły się Transformery, większość problemów sekwencyjnych (tłumaczenie, mowa, generowanie tekstu) była zdominowana przez Recurrent Neural Networks (RNN), a później LSTM (Long Short-Term Memory). Główny pomysł był prosty: czytaj tekst po jednym tokenie, utrzymuj „pamięć” (stan ukryty) i używaj go do przewidywania kolejnych tokenów.
Krótkie wyobrażenie, jak to działało
RNN przetwarza zdanie jak łańcuch. Każdy krok aktualizuje stan ukryty na podstawie bieżącego słowa i poprzedniego stanu. LSTM poprawiły to, dodając bramki decydujące, co zachować, zapomnieć lub wyprowadzić — dzięki czemu łatwiej było utrzymać przydatne sygnały na dłużej.
Dlaczego zależności na długim dystansie były trudne
W praktyce pamięć sekwencyjna ma wąskie gardło: wiele informacji trzeba upchać w jednym stanie, gdy zdanie się wydłuża. Nawet w LSTM sygnały z dalekich słów mogą zanikać lub zostać nadpisane.
To utrudniało naukę pewnych zależności — np. przypisanie zaimka do poprawnej nazwy pojawiającej się wiele słów wcześniej, albo śledzenie tematu przez kilka zdań.
Wyzwania trenowania i skalowania
RNN-y i LSTM-y są też wolne w trenowaniu, ponieważ nie można w pełni równolegle liczyć po czasie. Można grupować różne zdania w batchu, ale wewnątrz jednego zdania krok 50 zależy od 49, który zależy od 48, i tak dalej.
Takie krokowe obliczenia stają się poważnym ograniczeniem, gdy chcesz większych modeli, więcej danych i szybszych eksperymentów.
Motywacja do podejścia przyjaznego równolegleniu
Badacze potrzebowali projektu, który pozwoli łączyć słowa ze sobą bez ścisłego przetwarzania lewo‑do‑prawo podczas treningu — sposobu modelowania zależności na długim dystansie bez przepychania informacji przez sekwencję. Ten nacisk przygotował grunt pod podejście oparte na uwadze zaprezentowane w Attention Is All You Need.
Uwaga, wytłumaczona bez matematyki
Uwaga to sposób modelu na zadanie: „Na które inne słowa powinienem teraz spojrzeć, żeby zrozumieć to słowo?” Zamiast czytać zdanie ściśle lewo‑do‑prawo i liczyć na pamięć, uwaga pozwala modelowi zerknąć na najbardziej istotne fragmenty zdania w chwili, gdy ich potrzebuje.
Pomysł „szukaj i pobierz”
Pomocny model mentalny to mała wyszukiwarka działająca w ramach zdania.
- Query: czego szuka bieżące słowo (pytanie)
- Keys: co każde inne słowo oferuje (etykiety potencjalnych trafień)
- Values: informacje, które zostaną pobrane, jeśli jest trafienie (zawartość)
Model tworzy zapytanie dla bieżącej pozycji, porównuje je z kluczami wszystkich pozycji, a następnie pobiera mieszankę wartości.
Wyniki istotności → wagi uwagi
Porównania dają wyniki istotności: przybliżone sygnały „jak bardzo to jest powiązane?”. Model zamienia je potem na wagi uwagi, które sumują się do 1.
Jeśli jedno słowo jest bardzo istotne, dostaje większy udział uwagi. Jeśli ważnych jest kilka, uwaga rozkłada się między nie.
Prosty przykład (zaimki i gramatyka)
Weź zdanie: „Maria powiedziała Jennie, że ona zadzwoni później.”
Aby zinterpretować ona, model powinien spojrzeć na kandydatki takie jak „Maria” i „Jennie”. Uwaga przypisze większą wagę do imienia, które najlepiej pasuje do kontekstu.
Albo rozważ: „Klucze do szafki są zaginione.” Uwaga pomaga połączyć „są” z „klucze” (prawdziwy podmiot), a nie z „szafka”, chociaż „szafka” jest bliżej. To sedno: uwaga łączy znaczenie na odległość, na żądanie.
Self-Attention: podstawowy mechanizm
Self-attention to pomysł, że każdy token w sekwencji może spojrzeć na inne tokeny w tej samej sekwencji, żeby zdecydować, co jest teraz ważne. Zamiast przetwarzać słowa ściśle lewo‑do‑prawo (jak starsze modele rekurencyjne), Transformer pozwala każdemu tokenowi zbierać wskazówki z dowolnego miejsca wejścia.
Tokeny zwracają uwagę na tokeny
Wyobraź sobie zdanie: „Wlałem wodę do kubka, ponieważ on był pusty.” Słowo „on” powinno połączyć się z „kubek”, a nie z „woda”. Dzięki self-attention token „on” przypisuje większą wagę tokenom, które pomagają rozwiązać jego znaczenie („kubek”, „pusty”) i mniejszą wagę tym nieistotnym.
Jak budowany jest kontekst
Po self-attention każdy token przestaje być tylko sobą. Staje się wersją świadomą kontekstu — ważoną mieszanką informacji z innych tokenów. Można to traktować jak spersonalizowane streszczenie całego zdania, dopasowane do potrzeb danego tokena.
W praktyce reprezentacja „kubka” może zawierać sygnały z „wlałem”, „woda” i „pusty”, podczas gdy „pusty” może pobrać to, co opisuje.
Dlaczego trening może być równoległy
Ponieważ każdy token może jednocześnie obliczyć swoją uwagę nad całą sekwencją, trening nie musi czekać na przetworzenie poprzednich tokenów krok po kroku. To równoległe przetwarzanie jest główną przyczyną, dlaczego Transformery trenują efektywnie na dużych zbiorach danych i skalują się do ogromnych modeli.
Dlaczego są silne w relacjach na długim dystansie
Self-attention ułatwia łączenie odległych fragmentów tekstu. Token może bezpośrednio skupić się na istotnym słowie daleko wstecz—bez przekazywania informacji przez długi łańcuch pośredników.
Ta bezpośrednia ścieżka pomaga w zadaniach takich jak koreferencja („ona”, „to”, „oni”), śledzenie tematów przez akapity i obsługa instrukcji zależnych od wcześniejszych szczegółów.
Multi-Head Attention: wiele spojrzeń na to samo zdanie
Szybko zbuduj funkcję LLM
Przekształć pomysły z Transformera w działającą funkcję LLM, opisując aplikację w czacie.
Pojedynczy mechanizm uwagi jest potężny, ale nadal można go porównać do oglądania rozmowy tylko z jednego kąta kamery. Zdania często zawierają jednocześnie kilka relacji: kto co zrobił, do czego odnosi się „to”, które słowa nadają ton, jaki jest temat.
Dlaczego jedno spojrzenie nie wystarcza
Gdy czytasz „Trofeum nie zmieściło się w walizce, bo ona była za mała”, musisz śledzić kilka wskazówek naraz (gramatyka, sens, kontekst świata rzeczywistego). Jedna głowa uwagi może skupić się na najbliższym rzeczowniku; inna na frazie czasownikowej, aby rozstrzygnąć, do czego odnosi się „ona”.
Co robi wiele głów
Multi-head attention uruchamia kilka obliczeń uwagi równolegle. Każda „głowa” patrzy na zdanie z innej perspektywy — często opisywanej jako inne podprzestrzenie. W praktyce głowy mogą specjalizować się w różnych wzorcach, np.:
- lokalna składnia (np. przymiotnik → rzeczownik)
- łącza na dużą odległość (np. podmiot ↔ orzeczenie przez całe zdanie)
- koreferencja (np. zaimek → encja)
- sygnały tematyczne (słowa ustawiające przedmiot lub sentyment)
Jak łączy się wyjścia głów
Po tym, jak każda głowa daje własne wnioski, model nie wybiera jednej z nich. Konkatenacja wyników głów (ułożenie obok siebie) jest następnie rzutowana z powrotem do głównej przestrzeni roboczej modelu za pomocą nauczonej warstwy liniowej.
To jak scalanie kilku notatek w jedno czyste podsumowanie, którego może użyć następna warstwa. Efekt to reprezentacja uchwytująca wiele relacji naraz — jeden z powodów, dla których Transformery działają tak dobrze przy skalowaniu.
Kodowanie pozycyjne: uczenie modelu porządku słów
Self-attention świetnie wychwytuje relacje — ale samo w sobie nie wie, kto był pierwszy. Jeśli przemieszczasz słowa w zdaniu, zwykła warstwa self-attention może potraktować przemieszczoną wersję jak równoważną, bo porównuje tokeny bez wbudowanego poczucia pozycji.
Kodowanie pozycyjne rozwiązuje to, wstrzykując informację „gdzie jestem w sekwencji?” do reprezentacji tokenów. Gdy pozycja jest dołączona, uwaga może uczyć się wzorców np. „słowo zaraz po nie ma dużą wagę” albo „podmiot zwykle stoi przed orzeczeniem”, bez potrzeby wnioskowania kolejności od zera.
Jak kodowania pozycyjne dodają porządek
Główna idea jest prosta: osadzenie tokenu łączy się z sygnałem pozycji przed wprowadzeniem do bloku Transformera. Ten sygnał pozycji można traktować jako dodatkowy zestaw cech oznaczających, że token jest 1., 2., 3.… w wejściu.
Istnieją popularne podejścia:
- Pozycje absolutne (stałe): klasyczne Transformery używały deterministycznych, sinusoidalnych wzorców. Nie zwiększają one liczby parametrów i częściowo uogólniają na długości poza tymi widzianymi podczas treningu.
- Uczone pozycje absolutne: model uczy wektora dla „pozycji 1”, „pozycji 2” itd. To działa dobrze, ale zwykle wiąże model z maksymalnym oknem kontekstu, na którym był trenowany.
- Pozycje względne: zamiast kodować „to token 57”, model skupia się na odległościach, np. „ten token jest 3 kroki przed tamtym”. Nowoczesne warianty (w tym rotary) często należą do tej rodziny.
Dlaczego to ma znaczenie przy długim kontekście
Wybory dotyczące pozycji mają zauważalny wpływ na modelowanie długiego kontekstu — np. podsumowywanie długiego raportu, śledzenie encji przez wiele akapitów czy wyszukiwanie informacji wspomnianej tysiące tokenów wcześniej.
Przy długich wejściach model nie tylko uczy się języka — uczy się, gdzie patrzeć. Metody względne i rotary zwykle ułatwiają porównywanie odległych tokenów i zachowanie wzorców w miarę wzrostu kontekstu, podczas gdy pewne schematy absolutne mogą szybciej pogarszać się poza oknem treningowym.
W praktyce kodowanie pozycyjne to jedno z tych cichych decyzji projektowych, które mogą zadecydować, czy LLM jest ostry i spójny przy 2 000 tokenów — i czy wciąż ma sens przy 100 000.
Przenieś na mobile
Przekształć przepływ LLM w aplikację mobilną Flutter z tego samego procesu budowy opartego na czacie.
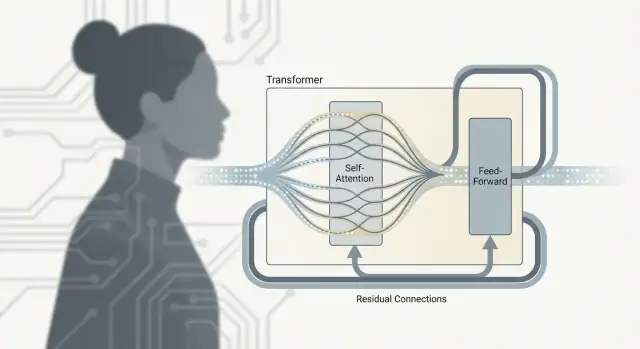
Transformer to nie tylko „uwaga”. Rzeczywista praca dzieje się w powtarzającym się module — często zwanym blokiem Transformera — który miesza informacje między tokenami i potem je udoskonala. Zestakuj wiele takich bloków, a uzyskasz głębię, która daje dużym modelom językowym ich możliwości.
Po uwadze: co robi FFN/MLP
Self-attention to krok komunikacji: każdy token zbiera kontekst od innych tokenów.
Sieć feed-forward (FFN), zwana też MLP, to krok przetwarzania: bierze zaktualizowaną reprezentację tokenu i uruchamia ten sam mały sieciowy transformator niezależnie dla każdego tokenu.
Mówiąc prosto, FFN przekształca i modeluje to, co każdy token teraz wie, pomagając budować bogatsze cechy (składniowe, faktyczne, stylowe) po zebraniu odpowiedniego kontekstu.
Dlaczego bloki przeplatają uwagę i FFN
Przeplatanie ma sens, bo obie części robią różne rzeczy:
- Uwaga przenosi informacje pomiędzy tokenami (kto ma wpływ na kogo)
- FFN przetwarza informacje w obrębie tokena (jak przekuć kontekst w użyteczne cechy)
Powtarzanie tego wzorca pozwala modelowi stopniowo budować wyższe poziomy znaczenia: komunikuj, oblicz, komunikuj, oblicz.
Połączenia rezydualne: „pasy omijające”
Każda podwarstwa (uwaga lub FFN) owinięta jest połączeniem rezydualnym: wejście jest dodawane z powrotem do wyjścia. Pomaga to w trenowaniu głębokich modeli, bo gradienty mogą płynąć przez „pas omijający”, nawet jeśli dana warstwa wciąż się uczy. Pozwala też warstwie wprowadzać drobne korekty zamiast uczyć wszystkiego od zera.
Normalizacja warstwy: stabilizator sygnałów
Layer normalization stabilizuje aktywacje, żeby nie narastały ani nie malały zbytnio w miarę przechodzenia przez wiele warstw. Można to traktować jak utrzymywanie stałego poziomu głośności, by kolejne warstwy nie były przytłoczone lub pozbawione sygnału — co sprawia, że trening jest gładszy i bardziej niezawodny, zwłaszcza w LLM-ach.
Enkoder–dekoder kontra tylko-dekoder: co napędza LLM-y?
Oryginalny Transformer w Attention Is All You Need był zbudowany do tłumaczeń maszynowych, gdzie zamienia się jedną sekwencję (np. francuski) na inną (np. angielski). To zadanie naturalnie dzieli się na dwie role: dobrze przeczytać wejście i płynnie napisać wyjście.
Enkoder–dekoder: „Najpierw czytaj, potem pisz”
W enkoder–dekoderze enkoder przetwarza całe wejście naraz i produkuje bogaty zestaw reprezentacji. Dekoder potem generuje wyjście token po tokenie.
Dekoder nie polega tylko na swoich wcześniejszych tokenach: używa też cross-attention, by zerkać na wyjście enkodera i utrzymywać się w źródle tekstu.
To ustawienie nadal sprawdza się, gdy musisz mocno warunkować odpowiedź na konkretnym wejściu — tłumaczenie, streszczenie czy odpowiadanie na pytanie z określonego fragmentu tekstu.
Tylko-dekoder: jeden model, który ciągle przewiduje
Większość nowoczesnych LLM-ów to tylko-dekoder. Trenują się do prostego, potężnego zadania: przewidywania następnego tokena.
Aby to zadziałało, używają maskowanej self-attention (tzw. causal attention). Każda pozycja może zwracać uwagę tylko na wcześniejsze tokeny, nie na przyszłe, dzięki czemu generacja przebiega lewo‑do‑prawo i jest spójna.
To podejście dominuje w LLM-ach, bo jest proste do trenowania na ogromnych korpusach tekstowych i dobrze odpowiada przypadkom użycia generacji.
Gdzie pasują modele enkoderowe
Modele enkoderowe (jak BERT) nie generują tekstu; czytają całe wejście dwukierunkowo. Sprawdzają się świetnie do klasyfikacji, wyszukiwania i embeddingów — wszędzie tam, gdzie ważniejsze jest rozumienie tekstu niż tworzenie długiego ciągu wyjściowego.
Transformery okazały się wyjątkowo przyjazne skali: jeśli dasz im więcej tekstu, więcej mocy obliczeniowej i większe modele, mają tendencję do przewidywalnej poprawy.
Duży powód to strukturalna prostota. Transformer składa się z powtarzanych bloków (self-attention + niewielkie FFN + normalizacja), a te bloki zachowują się podobnie, czy trenujesz na milionie słów, czy na bilionie.
Równoległy trening to ukryta supermoc
Wcześniejsze modele sekwencyjne (jak RNN) musiały przetwarzać tokeny jeden po drugim, co ograniczało skalowanie. Transformery zaś mogą w trakcie treningu przetwarzać wszystkie tokeny sekwencji jednocześnie.
To sprawia, że świetnie pasują do GPU/TPU i dużych środowisk rozproszonych — dokładnie tego, co potrzeba przy trenowaniu nowoczesnych LLM-ów.
„Okno kontekstu” i dlaczego jest ważne
Okno kontekstu to fragment tekstu, który model może „widzieć” jednocześnie — twój prompt plus ostatnia rozmowa lub tekst dokumentu. Większe okno pozwala łączyć pomysły przez więcej zdań lub stron, śledzić ograniczenia i odpowiadać na pytania zależne od wcześniejszych szczegółów.
Ale kontekst nie jest darmowy.
Kluczowe ograniczenie: koszt uwagi rośnie z długością
Self-attention porównuje tokeny między sobą. W miarę wydłużania sekwencji liczba porównań szybko rośnie (w przybliżeniu kwadratowo względem długości). Dlatego bardzo długie okna kontekstowe są kosztowne pod względem pamięci i obliczeń, i stąd wiele współczesnych prac koncentruje się na efektywniejszej uwadze.
Skalowanie odblokowało zachowania ogólnego przeznaczenia
Gdy Transformery są trenowane na dużą skalę, nie tylko poprawiają się w jednym wąskim zadaniu. Często zaczynają wykazywać szerokie, elastyczne zdolności — streszczanie, tłumaczenie, pisanie, kodowanie i rozumowanie — ponieważ ta sama ogólna maszyna ucząca się jest stosowana na ogromnych, zróżnicowanych danych.
Współczesne warianty zbudowane na tej samej bazie
Eksportuj źródła w dowolnym momencie
Zachowaj własność, eksportując kod źródłowy, gdy będziesz gotowy.
Oryginalny projekt Transformera nadal jest punktem odniesienia, ale większość produkcyjnych LLM-ów to „Transformer plus”: drobne, praktyczne poprawki, które zachowują rdzeń (uwaga + MLP), a poprawiają szybkość, stabilność lub długość kontekstu.
Typowe usprawnienia, które zobaczysz
Wiele ulepszeń to raczej optymalizacje trenowania i uruchamiania niż zmiana istoty modelu:
- Lepsze metody pozycyjne: alternatywy dla klasycznych sinusoid (często rotary lub podejścia względne) poprawiają obsługę długiego kontekstu.
- Optymalizacje uwagi: implementacje zmniejszające użycie pamięci i zwiększające przepustowość (np. zintegrowane kernele lub efektywniejsze obliczenia uwagi).
- Modyfikacje normalizacji: zmiany w miejscu i sposobie stosowania normalizacji mogą poprawić stabilność treningu i zmniejszyć wrażliwość na hiperparametry.
Te zmiany zwykle nie zmieniają fundamentalnej „transformerowości” modelu — go udoskonalają.
Podejścia do długiego kontekstu (na wysokim poziomie)
Rozszerzanie kontekstu z kilku tysięcy tokenów do dziesiątek lub setek tysięcy często opiera się na rzadkiej uwadze (attend tylko do wybranych tokenów) lub efektywnych wariantach uwagi (przybliżenia lub restrukturyzacja uwagi, by obciąć obliczenia).
Koszt to zwykle kompromis między dokładnością, pamięcią i złożonością inżynieryjną.
Mixture-of-Experts (MoE): więcej pojemności bez liniowego kosztu
Modele MoE dodają wiele „ekspertów” — pod‑sieci — i kierują każdy token tylko przez podzbiór z nich. Koncepcyjnie: masz większy mózg, ale nie aktywujesz go w całości za każdym razem.
To może obniżyć obciążenie obliczeniowe na token dla danej liczby parametrów, ale zwiększa złożoność systemu (routing, balansowanie ekspertów, serwowanie).
Jak oceniać twierdzenia o wariantach
Gdy model chwali się nowym wariantem Transformera, warto poprosić o:
- Benchmarki istotne dla twoich zadań (nie tylko nagłówkowe wyniki)
- Opóźnienia (czas do pierwszego tokena i tokeny/sek)
- Koszty (trening i inferencja), wliczając pamięć i wymagania sprzętowe
Większość ulepszeń jest realna — ale rzadko są one darmowe.
Co to oznacza dla zespołów budujących na LLM-ach
Pomysły Transformera, jak self-attention i skalowanie, są fascynujące — ale zespoły produktowe odczuwają je głównie jako kompromisy: ile tekstu możesz wrzucić, jak szybko dostaniesz odpowiedź i ile to kosztuje za żądanie.
Wybór modelu lub dostawcy: cztery kompromisy
Długość kontekstu: Większy kontekst pozwala dołączać więcej dokumentów, historii czatu i instrukcji, ale zwiększa zużycie tokenów i może spowolnić odpowiedzi. Jeśli funkcja wymaga „przeczytaj 30 stron i odpowiedz”, priorytetem jest długość kontekstu.
Opóźnienia: Interaktywne doświadczenia chatowe i copiloty zależą od czasu odpowiedzi. Strumieniowanie wyjścia pomaga, ale wybór modelu, region i batching też mają znaczenie.
Koszt: Ceny zwykle naliczane są za token (wejście + wyjście). Model o 10% „lepszy” może kosztować 2–5× więcej. Porównuj w kategoriach cenowych, by zdecydować, na jaką jakość warto wydać pieniądze.
Jakość: Zdefiniuj ją dla swojego przypadku użycia: dokładność faktograficzna, wykonywanie poleceń, ton, użycie narzędzi czy generowanie kodu. Oceń na rzeczywistych przykładach z twojej domeny, nie tylko na ogólnych benchmarkach.
Gdy embeddingi przewyższają generację
Jeśli głównie potrzebujesz wyszukiwania, deduplikacji, klastrowania, rekomendacji lub „znajdź podobne”, to embeddingi (często modele enkoderowe) są zwykle tańsze, szybsze i bardziej stabilne niż wywoływanie modelu do generowania. Używaj generacji tylko jako kroku końcowego (podsumowania, wyjaśnienia, szkicu) po pobraniu odpowiednich fragmentów.
Dla głębszego omówienia skieruj zespół do technicznego opracowania o temacie embeddings vs generation.
Gdzie to pojawia się w realnych cyklach dostarczania
Gdy przekształcasz możliwości Transformera w produkt, trudność zwykle dotyczy mniej architektury, a bardziej przepływu pracy: iteracji promptów, ugruntowania odpowiedzi w danych, ewaluacji i bezpiecznego wdrożenia.
Jedną praktyczną drogą jest użycie platformy vibe-coding takiej jak Koder.ai, by prototypować i wdrażać funkcje oparte na LLM szybciej: możesz opisać aplikację webową, endpointy backendu i model danych w czacie, iterować w trybie planowania, a następnie eksportować kod źródłowy lub wdrożyć z hostingiem, niestandardowymi domenami i rollbackiem przez snapshoty. To szczególnie przydatne podczas eksperymentów z retrievalem, embeddingami czy pętlami wywołań narzędzi, gdy chcesz szybkie iteracje bez budowania od zera tej samej podstawy.
Praktyczna lista kontrolna adoptowania
- Napisz jedną stronę specyfikacji: cel użytkownika, tryby awarii i kryteria sukcesu.
- Zdecyduj, co musi być ugruntowane w waszych danych (RAG, cytowania lub wywołania narzędzi).
- Ustal budżety na tokeny, opóźnienia i miesięczne wydatki; mierz je na środowisku staging.
- Dodaj zabezpieczenia: odmowy, redakcję i zachowanie „nie wiem”.
- Buduj ewaluację wcześnie: golden prompts, testy regresji i przeglądy ludzkie.
- Planuj możliwość zamiany modelu: trzymaj prompty i reguły routingu konfigurowalne.