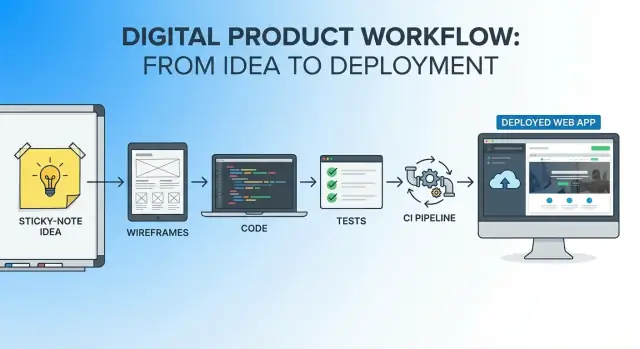
Cel: jedna ciągła ścieżka od pomysłu do działającej aplikacji
Wyobraź sobie prosty, użyteczny pomysł na aplikację: „Queue Buddy”, który pozwala pracownikowi kawiarni jednym przyciskiem dodać klienta do listy oczekujących i automatycznie wysłać mu SMS, gdy stolik będzie gotowy. Metrika sukcesu jest prosta i mierzalna: zmniejszyć liczbę telefonów z powodu niepewności dotyczącej czasu oczekiwania o 50% w ciągu dwóch tygodni, przy czasie wdrożenia dla pracowników poniżej 10 minut.
To sedno tego artykułu: wybierz jasny, ograniczony pomysł, określ, czym jest „dobrze”, a potem przejdź od koncepcji do live’owego wdrożenia bez ciągłego przełączania narzędzi, dokumentów i modeli mentalnych.
Co oznacza „jeden przepływ pracy”
Jeden przepływ pracy to jeden ciągły wątek od pierwszego zdania pomysłu do pierwszego wydania produkcyjnego:
- Jedno miejsce, gdzie zapisywane są decyzje (co budujemy i dlaczego)
- Jeden ewoluujący zestaw artefaktów (wymagania → ekrany → zadania → kod → testy → notatki wdrożeniowe)
- Jedno sprzężenie zwrotne (każdą zmianę można odnieść do celu i metryki)
Wciąż użyjesz wielu narzędzi (edytor, repo, CI, hosting), ale nie będziesz „restartować” projektu na każdym etapie. Ta sama narracja i ograniczenia idą dalej.
Rola AI: asystent, nie autopilot
AI jest najbardziej wartościowe, gdy:
- Szybko szkicuje opcje (sformułowania wymagań, przepływy użytkownika, kształty API)
- Generuje startowy kod i testy, które możesz przeglądać w małych fragmentach
- Wskazuje przypadki brzegowe, które możesz przeoczyć (walidacja, uprawnienia, logowanie)
Ale to nie AI podejmuje decyzje produktowe. Ty decydujesz. Przepływ jest zaprojektowany tak, byś zawsze weryfikował: Czy ta zmiana przesuwa metrykę? Czy można to bezpiecznie wypuścić?
Ścieżka end-to-end, którą przejdziemy
W kolejnych sekcjach przejdziesz krok po kroku:
- Wyjaśnij problem, użytkowników i „małe zwycięstwo”, które możesz wdrożyć.
- Zamień pomysł w lekki dokument wymagań.
- Szkicuj podróż użytkownika i kluczowe ekrany.
- Wybierz rozsądną architekturę wersji 1.
- Bootstrapuj działający szkielet repo.
- Buduj kluczowe funkcje w cienkich, przeglądalnych kawałkach.
- Dodaj podstawy bezpieczeństwa: walidacja, uprawnienia, logowanie.
- Dodaj testy chroniące happy path i ryzykowne obszary.
- Skonfiguruj buildy, CI i bramki jakości.
- Wdróż z jasnym, odwracalnym procesem.
- Monitoruj, ucz się i iteruj—bez przerywania wątku.
Na koniec powinieneś mieć powtarzalny sposób na przejście od „pomysłu” do „live app” przy jednoczesnym utrzymaniu zakresu, jakości i nauki ściśle powiązanych.
Zacznij od jasności: problem, użytkownicy i małe zwycięstwo
Zanim poprosisz AI o szkic ekranów, API lub tabeli bazy danych, potrzebujesz wyraźnego celu. Trochę jasności teraz oszczędza godziny „prawie dobrych” wyników później.
Jednozdaniowe określenie problemu
Budujesz aplikację, bo konkretna grupa ludzi napotyka powtarzalne tarcie: nie mogą wykonać ważnego zadania szybko, niezawodnie lub z pewnością przy użyciu dostępnych narzędzi. Cel wersji 1 to usunąć jeden bolesny krok w tym przepływie—bez próby automatyzowania wszystkiego—tak, by użytkownik mógł przejść od „muszę zrobić X” do „X jest zrobione” w kilka minut, z jasnym zapisem co się stało.
Docelowi użytkownicy i ich 3 główne zadania do wykonania
Wybierz jednego głównego użytkownika. Użytkownicy drugorzędni mogą poczekać.
- Główny użytkownik: zapracowani operatorzy/właściciele, którzy zarządzają procesem end-to-end (nie specjaliści).
- Główne zadania do wykonania:
- Szybkie przechwycenie żądania (lub wpisu) bez pominięcia kluczowych danych.
- Śledzenie statusu na pierwszy rzut oka i wiedza co zrobić dalej.
- Udostępnienie wyniku (potwierdzenie, podsumowanie lub eksport), któremu inni mogą zaufać.
Założenia (co musi być prawdą)
Założenia to miejsce, gdzie dobre pomysły cicho upadają—ujawnij je.
- Użytkownicy zgodzą się poświęcić trochę czasu na konfigurację dla powtarzalnego przepływu.
- Potrzebne dane istnieją (lub można je wprowadzić) z rozsądną dokładnością.
- Lekki ślad audytu wystarczy; pełne funkcje zgodności nie są potrzebne w v1.
- „Pomoc AI” przyspiesza pracę, ale użytkownicy nadal chcą ostatecznej kontroli.
Definicja ukończenia dla pierwszego wydania
Wersja 1 powinna być małym zwycięstwem, które możesz wysłać.
- Użytkownik może ukończyć podstawowy przepływ w mniej niż 3 minuty.
- Dane są walidowane i przechowywane, z podstawowymi uprawnieniami i logiem aktywności.
- Istnieje jeden udostępnialny wynik (email, PDF lub link) i jest spójny.
- Możesz wdrożyć, cofnąć i odpowiedzieć na pytanie: „Czy to działa?”
Zamień pomysł w lekki dokument wymagań
Lekki dokument wymagań (pomyśl: jedna strona) to most między „fajnym pomysłem” a „planem do zbudowania”. Trzyma fokus, daje AI właściwy kontekst i zapobiega pęcznieniu v1 do wielomiesięcznego projektu.
Szkicuj jednostronicowy PRD (części, które mają znaczenie)
Utrzymaj zwięzłość i czytelność. Prosty szablon:
- Problem: Jaki ból rozwiązujemy, w jednym zdaniu?
- Docelowi użytkownicy: Kto najczęściej doświadcza tego problemu?
- Zakres (Wersja 1): Co zbudujemy teraz.
- Non-goals: Czego explicitnie nie zbudujemy jeszcze (tu ginie scope creep).
- Ograniczenia: Budżet, harmonogram, ograniczenia technologiczne, zgodność, urządzenia, źródła danych.
- Metryka sukcesu: Jak wygląda „udanе” (nawet prosty proxy jest OK).
Zdefiniuj i uporządkuj 5–10 kluczowych funkcji
Napisz maksymalnie 5–10 funkcji, sformułowanych jako rezultaty. Potem je uporządkuj:
- Must-have (aplikacja bez tego nie zadziała)
- Should-have (wysoka wartość, ale może poczekać)
- Nice-to-have (odłóż na później)
To też wskazówka dla AI: „Zaimplementuj tylko must-have na początek.”
Dodaj kryteria akceptacji dla top funkcji
Dla 3–5 najważniejszych funkcji dodaj 2–4 kryteria akceptacji każda. Używaj prostego języka i testowalnych stwierdzeń.
Przykład:
- Funkcja: Załóż konto
- Użytkownik może zarejestrować się e-mailem i hasłem
- Hasło musi mieć co najmniej 12 znaków
- Po rejestracji użytkownik ląduje na pulpicie
- Duplikat e-maila pokazuje jasny komunikat o błędzie
Zapisz otwarte pytania do szybkiej walidacji
Zakończ krótką listą „Otwarte pytania” — rzeczy, na które możesz odpowiedzieć jedną rozmową, szybkim call’em z klientem lub szybkim wyszukaniem.
Przykłady: „Czy użytkownicy potrzebują logowania przez Google?” „Jakie minimalne dane musimy przechowywać?” „Czy potrzebna jest aprobata admina?”
Ten dokument nie jest papierologią; to wspólne źródło prawdy, które będziesz aktualizować w miarę postępów budowy.
Szkicuj podróż użytkownika i kluczowe ekrany
Zanim poprosisz AI o generowanie ekranów, ustaw opowieść produktu. Szybki szkic podróży trzyma wszystkich w zgodzie: co użytkownik próbuje zrobić, co oznacza sukces i gdzie coś może pójść źle.
Mapuj główne przepływy użytkownika (happy path + kluczowe przypadki brzegowe)
Zacznij od happy path: najprostszej sekwencji dostarczającej główną wartość.
Przykładowy przepływ (ogólny):
- Użytkownik rejestruje się / loguje
- Użytkownik tworzy nowy Projekt
- Użytkownik dodaje Zadania
- Użytkownik oznacza Zadanie jako ukończone
- Użytkownik widzi postęp / potwierdzenie
Potem dodaj kilka przypadków brzegowych, które są prawdopodobne i kosztowne, jeśli zostaną zaniedbane:
- Użytkownik porzuca rejestrację w połowie (co z częściowymi danymi?)
- Użytkownik traci dostęp (wygasła sesja, cofnięte uprawnienia)
- Stan pusty (jeszcze brak projektów)
- Nieudane zapisy (błąd sieci) i zachowanie ponawiania
Nie potrzebujesz dużego diagramu. Numerowana lista i krótkie notatki wystarczą do kierowania prototypowaniem i generowaniem kodu.
Wypisz kluczowe ekrany/strony i co każdy musi osiągnąć
Napisz krótką „pracę do wykonania” dla każdego ekranu. Skoncentruj się na rezultatach, nie UI.
- Login / Rejestracja: wprowadź użytkownika; wyjaśnij błędy; pozwól zresetować hasło
- Pulpit: pokaż bieżące elementy i kolejną akcję; ładnie obsłuż stan pusty
- Szczegóły projektu: pokaż info o projekcie; pozwól dodawać/edytować zadania; pokaż status
- Edytor zadania (modal/strona): utwórz lub zaktualizuj zadanie; waliduj wymagane pola
- Ustawienia / Konto: zarządzaj profilem; wyloguj; obsłuż usuwanie konta jeśli potrzebne
Jeśli pracujesz z AI, ta lista świetnie nadaje się jako materiał do prompta: „Wygeneruj pulpit wspierający X, Y, Z i uwzględnij stany pusty/wczytywanie/błąd.”
Zdefiniuj encje danych na poziomie „serwetki”
Trzymaj się „napkin schema” — wystarczająco, by obsłużyć ekrany i przepływy.
- User: id, email, name, role
- Project: id, ownerId, title, createdAt
- Task: id, projectId, title, status, dueDate
Zanotuj relacje (User → Projects → Tasks) i wszystko, co wpływa na uprawnienia.
Wskaż punkty, gdzie zaufanie i bezpieczeństwo mają znaczenie
Oznacz miejsca, gdzie błędy łamią zaufanie:
- Autoryzacja i obsługa sesji
- Uprawnienia (kto może przeglądać/edytować projekt?)
- Operacje niszczące (usunięcie projektu/zadania) i potwierdzenia
- Audytowalność (podstawowe logowanie edycji i usunięć)
Tu nie chodzi o nadmierne inżynierowanie — chodzi o zapobieganie niespodziankom, które z demo robią się problemy wsparcia po uruchomieniu.
Wybierz rozsądną architekturę dla wersji 1
Architektura v1 powinna robić jedną rzecz dobrze: pozwolić wysłać najmniejszy użyteczny produkt bez potrzeby malowania się w kącie. Dobra zasada: „jedno repo, jeden wdrażalny backend, jeden wdrażalny frontend, jedna baza danych” — i dodawaj elementy tylko gdy wyraźny wymóg tego wymusi.
Wybierz najprostszy stos, który pasuje
Dla typowej aplikacji webowej sensowny domyślny wybór to:
- Frontend: React (lub Next.js jeśli chcesz routing + podstawowy server rendering)
- Backend: Node.js + lekki framework (Express/Fastify) lub Next.js API routes jeśli API jest małe
- Baza danych: Postgres (solidny, elastyczny i szeroko wspierany)
Trzymaj liczbę usług niską. Dla v1 „modularny monolit” (dobrze zorganizowany kod, ale jeden backend) jest zwykle łatwiejszy niż mikroserwisy.
Jeśli wolisz środowisko AI-first, gdzie architektura, zadania i generowany kod są ściśle powiązane, platformy takie jak Koder.ai mogą pasować: opisujesz zakres v1 w czacie, iterujesz w „trybie planowania”, a następnie generujesz frontend React z backendem Go + PostgreSQL — przy zachowaniu kontroli i możliwości przeglądu.
Zarysuj API jak kontrakt
Zanim wygenerujesz kod, napisz małą tabelę API, żebyś ty i AI mieli ten sam cel. Przykładowy kształt:
GET /api/projects → { items: Project[] }POST /api/projects → { project: Project }GET /api/projects/:id → { project: Project, tasks: Task[] }POST /api/projects/:id/tasks → { task: Task }
Dodaj notatki o kodach statusu, formacie błędu (np. { error: { code, message } }) i paginacji jeśli potrzebna.
Zdecyduj o autoryzacji (lub jej uniknij)
Jeśli v1 może być publiczny lub single-user, pomiń auth i wypuść szybciej. Jeśli potrzebujesz kont, użyj zarządzanego providera (magic link e-mail lub OAuth) i trzymaj uprawnienia proste: „użytkownik jest właścicielem swoich rekordów.” Unikaj złożonych ról, dopóki realne użycie ich nie wymusi.
Ustal pierwsze cele wydajności i niezawodności
Udokumentuj kilka praktycznych ograniczeń:
- Oczekiwany ruch (nawet przybliżony)
- Cel czasów odpowiedzi (np. „większość żądań poniżej 300ms”)
- Minimalne logowanie (żądania, błędy i kluczowe wydarzenia biznesowe)
- Kopie zapasowe i plan rollbacku
Te notatki kierują generowany kod AI ku temu, by był wdrażalny, a nie tylko funkcjonalny.
Bootstrap repo: od pustego folderu do działającego szkieletu
Szybko wystartuj działający repozytorium
Wygeneruj minimalny szkielet web + API z jednej rozmowy w Koder.ai.
Najszybszy sposób na zabicie momentum to tydzień kłótni o narzędzia i brak uruchamialnego kodu. Cel: dostać się do „hello app”, który startuje lokalnie, pokazuje ekran i akceptuje żądanie — przy jednoczesnym zachowaniu prostoty, by każda zmiana była łatwo przeglądalna.
Poproś AI o praktyczny szkielet (nie skończony produkt)
Daj AI ścisły prompt: wybór frameworka, podstawowe strony, stub API i pliki, których oczekujesz. Szukasz przewidywalnych konwencji, nie wymyślnych rozwiązań.
Dobry pierwszy szkic to struktura jak:
/README.md
/.env.example
/apps/web/
/apps/api/
/package.json
Jeśli używasz jednego repo, poproś o podstawowe trasy (np. / i /settings) i jeden endpoint API (np. GET /health lub GET /api/status). To wystarczy, by udowodnić, że rurociąg działa.
Jeśli korzystasz z Koder.ai, to naturalne miejsce startu: poproś o minimalny „web + api + database-ready” skeleton, a potem eksportuj źródła, gdy struktura i konwencje będą satysfakcjonujące.
Wygeneruj minimalne UI połączone z stub backendem
Trzymaj UI celowo nudne: jedna strona, jeden przycisk, jedno wywołanie.
Przykładowe zachowanie:
- Strona główna renderuje „App is running.”
- Przycisk wywołuje endpoint backendu.
- Odpowiedź jest wyświetlana na stronie.
Daje to natychmiastową pętlę informacji zwrotnej: jeśli UI się ładuje, ale wywołanie zawodzi, wiesz dokładnie gdzie szukać (CORS, port, routing, błędy sieci). Powstrzymaj się od dodawania auth, bazy czy skomplikowanego stanu — to zrobisz, gdy szkielet jest stabilny.
Dodaj zmienne środowiskowe i instrukcje lokalnego dewelopu
Utwórz .env.example pierwszego dnia. Zapobiega to problemom „działa u mnie” i ułatwia onboarding.
Przykład:
WEB_PORT=3000
API_PORT=4000
API_URL=http://localhost:4000
Następnie napisz README uruchamialne w mniej niż minutę:
- zainstaluj zależności
- skopiuj
.env.example → .env
- uruchom web + api
- otwórz adres w przeglądarce
Trzymaj zmiany małe i commituj wcześnie
Traktuj ten etap jak położenie czystych fundamentów. Commituj po każdym małym sukcesie: „init repo”, „add web shell”, „add api health endpoint”, „wire web to api.” Małe commity ułatwiają iterację z AI: jeśli wygenerowana zmiana pójdzie nie tak, możesz cofnąć bez utraty dnia pracy.
Buduj kluczowe funkcje w cienkich, przeglądalnych kawałkach
Gdy szkielet działa end-to-end, powstrzymaj potrzebę „dokończenia wszystkiego”. Buduj wąski, pionowy fragment, który dotyka bazy, API i UI (jeśli dotyczy), potem powtarzaj. Cienkie kawałki utrzymują review szybkie, błędy małe, a współpracę z AI łatwiejszą do weryfikacji.
Zacznij od głównego modelu danych (i migracji)
Wybierz model, bez którego aplikacja nie będzie działać — często „rzecz”, którą użytkownicy tworzą lub zarządzają. Zdefiniuj go jasno (pola, wymagane vs opcjonalne, domyślne), a potem dodaj migracje jeśli używasz relacyjnej bazy. Pierwsza wersja niech będzie nudna: unikaj sprytnych normalizacji i przedwczesnej elastyczności.
Jeśli używasz AI do szkicowania modelu, poproś o uzasadnienie każdego pola i domyślnej wartości. Jeśli nie potrafi tego wyjaśnić w jednym zdaniu, prawdopodobnie nie powinno być w v1.
Zbuduj podstawowe endpointy z regułami walidacji
Stwórz tylko endpointy potrzebne dla pierwszej podróży użytkownika: zwykle create, read i minimalny update. Umieść walidację blisko granicy (request DTO/schema) i zrób reguły jawne:
- Pola wymagane, formaty i dozwolone zakresy
- Sprawdzenia własności/uprawnień („czy ten użytkownik ma dostęp do rekordu?”)
- Spójne kształty odpowiedzi (sukces i błąd)
Walidacja to część funkcji, nie tylko wygładzenie — zapobiega brudnym danym, które spowalniają później.
Obsługa błędów, która pomaga ludziom
Traktuj komunikaty o błędach jako UX dla debugowania i wsparcia. Zwracaj jasne, możliwe do wykonania komunikaty (co nie zadziałało i jak to naprawić), unikając ujawniania wrażliwych szczegółów po stronie klienta. Loguj kontekst techniczny po stronie serwera z request ID, żeby śledzić incydenty bez zgadywania.
Korzystaj z sugestii AI—potem przeglądaj każdą zmianę
Proś AI o propozycje zmian wielkości PR: jedna migracja + jeden endpoint + jeden test naraz. Przeglądaj dify jak od współpracownika: sprawdź nazewnictwo, przypadki brzegowe, założenia bezpieczeństwa i czy zmiana rzeczywiście wspiera „małe zwycięstwo”. Jeśli dodaje funkcje ekstra, wytnij je i idź dalej.
Uczyń to wystarczająco bezpiecznym: walidacja, uprawnienia i logowanie
Dodaj aplikację mobilną później
Rozszerz przepływ pracy na Flutter, gdy v1 potrzebuje towarzyszącej aplikacji mobilnej.
Wersja 1 nie musi mieć klasy bezpieczeństwa enterprise — ale musi unikać przewidywalnych porażek, które zmieniają obiecującą aplikację w koszmar wsparcia. Cel: „wystarczająco bezpieczne”: zapobiegać złym danym, domyślnie odmawiać dostępu i zostawiać ślad, który pomaga przy debugowaniu.
Walidacja wejścia + podstawowa ochrona przed nadużyciami
Traktuj każdą granicę jako nieufną: pola formularzy, payloady API, parametry query, a nawet wewnętrzne webhooki. Waliduj typ, długość i dozwolone wartości; normalizuj dane (przytnij ciągi, zmień wielkość liter) przed zapisem.
Kilka praktycznych domyślnych zasad:
- Walidacja po stronie serwera (zawsze), nawet jeśli walidujesz w UI.
- Ograniczenia częstości dla logowania, resetu hasła i kosztownych endpointów.
- Sprawdzanie uploadów plików: limity rozmiaru, dozwolone MIME i skanowanie antywirusowe jeśli akceptujesz publiczne uploady.
- Bezpieczne komunikaty o błędach: mów użytkownikom co poprawić, ale nie wyciekaj stack trace’ów ani identyfikatorów wewnętrznych.
Jeśli AI generuje handlery, proś, by explicite dodało reguły walidacji (np. „max 140 znaków” lub „musi być jednym z: …”) zamiast „zwaliduj input”.
Uprawnienia: zacznij mało, domyślnie odmawiaj
Prosty model uprawnień zwykle wystarczy dla v1:
- Anonimowy: dostęp tylko do publicznych stron.
- Zalogowany użytkownik: może tworzyć i przeglądać własne dane.
- Właściciel/edytor (opcjonalnie): może edytować współdzielone rekordy.
Centralizuj sprawdzenia własności (middleware/policy functions), żeby nie rozsypywać if userId == … po kodzie.
Logowanie, które pomaga w szybkim debugowaniu
Dobre logi odpowiadają: co się stało, komu i gdzie? Zawieraj:
- Request ID (propaguj przez usługi)
- User ID (gdy uwierzytelniony)
- Akcja + zasób (np.
update_project, project_id)
- Czas (czas trwania dla wolnych żądań)
Loguj wydarzenia, nie sekrety: nigdy nie zapisuj haseł, tokenów ani pełnych danych płatniczych.
Krótka lista „typowych błędów”
Zanim oznaczysz aplikację jako „wystarczająco bezpieczną”, sprawdź:
- Auth wymagany na wszystkich niepublicznych trasach
- Sprawdzenia autoryzacji (nie tylko uwierzytelnienie)
- Ograniczenia częstości na auth i endpointach zapisu
- Walidacja po stronie serwera dla wszystkich inputów
- Sekrety przechowywane w env/secret manager (nie w repo)
- Spójne, niejawne logowanie z request ID
Dodaj testy, które chronią happy path i ryzyko
Testowanie to nie pogoń za idealnym wynikiem — to zapobieganie awariom, które ranią użytkowników, łamią zaufanie lub generują kosztowne pożary. W przepływie wspomaganym AI testy są też „kontraktem”, który trzyma generowany kod w ramach tego, co naprawdę miałeś na myśli.
Zacznij od logiki o najwyższym ryzyku
Zanim dodasz dużo coverage, zidentyfikuj, gdzie błędy byłyby kosztowne. Typowe obszary wysokiego ryzyka: pieniądze/kredyty, uprawnienia, transformacje danych i walidacja brzegowa. Napisz testy jednostkowe dla tych części najpierw. Trzymaj je małe i konkretne: dla wejścia X oczekujesz wyjścia Y (lub błędu). Jeśli funkcja ma zbyt wiele gałęzi, by ją łatwo testować, to znak, że należy ją uprościć.
Dodaj 1–2 testy integracyjne dla głównego przepływu
Testy jednostkowe łapią błędy logiki; integracyjne łapią błędy „okablowania”—trasy, wywołania bazy, sprawdzenia auth i działanie UI razem.
Wybierz główną podróż (happy path) i zautomatyzuj ją end-to-end:
- Utwórz konto / zaloguj się
- Wykonaj główną akcję, dla której powstała aplikacja
- Potwierdź, że wynik pojawia się tam, gdzie użytkownik oczekuje (ekran, e-mail, pulpit)
Kilka solidnych testów integracyjnych często zapobiega więcej incydentom niż dziesiątki drobnych testów.
Użyj AI do szkicowania testów—potem je uczyń sensownymi
AI świetnie szkicuje struktury testów i wypunktowuje przypadki brzegowe, które możesz przeoczyć. Poproś o:
- przypadki brzegowe (puste wartości, maksymalne długości, strefy czasowe)
- przypadki negatywne (nieautoryzowany dostęp, nieprawidłowe stany)
- realistyczne przykłady danych (nie tylko „foo/bar”)
Potem sprawdź każdą asercję. Testy powinny weryfikować zachowanie, nie szczegóły implementacji. Jeśli test przejdzie mimo istnienia błędu, to nie chroni.
Ustal mały cel pokrycia i optymalizuj niezawodność
Wybierz umiarkowany target (np. 60–70% na kluczowych modułach) i traktuj go jako ogranicznik, nie trofeum. Skup się na stabilnych, powtarzalnych testach, które szybko uruchamiają się w CI i zawodzą z właściwych powodów. Flakiery erodują zaufanie—gdy zespół przestaje ufać suite’owi, przestaje on chronić.
Przygotuj automatyzację: buildy, CI i bramki jakości
Automatyzacja to moment, w którym przepływ wspomagany AI przestaje być „projektem działającym na mojej maszynie” i staje się czymś, czym możesz pewnie wysyłać. Cel to powtarzalność, nie wyszukane narzędzia.
Zacznij od jednej powtarzalnej komendy build
Wybierz jedną komendę, która daje ten sam wynik lokalnie i w CI. Dla Node to może być npm run build; dla Pythona make build; dla mobile konkretny krok Gradle/Xcode.
Oddziel konfiguracje dev i production wcześnie. Prosta zasada: dev domyślnie wygodne; production domyślnie bezpieczne.
{
"scripts": {
"lint": "eslint .",
"format": "prettier -w .",
"test": "vitest run",
"build": "vite build"
}
}
Linter łapie ryzykowne wzorce (nieużywane zmienne, niebezpieczne async). Formatter eliminuje „debaty o styl” w diffach. Utrzymuj zasady skromne dla v1, ale egzekwuj je konsekwentnie.
Praktyczna kolej bramek:
- format → 2) lint → 3) testy → 4) build
Skonfiguruj podstawowe CI: uruchamiaj testy na każdy push
Pierwszy workflow CI może być mały: zainstaluj zależności, uruchom bramki i fail fast. To samo w sobie zapobiega cichym awariom w main.
name: ci
on: [push, pull_request]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 20
- run: npm ci
- run: npm run format -- --check
- run: npm run lint
- run: npm test
- run: npm run build
Określ sposób przechowywania sekretów (i utrudnij pomyłki)
Zdecyduj, gdzie będą sekrety: store sekretów CI, manager haseł lub ustawienia środowiska platformy deploymentowej. Nigdy nie commituj ich do gita—dodaj .env do .gitignore i umieść .env.example z bezpiecznymi placeholderami.
Jeśli chcesz następnego kroku, połącz te bramki z procesem wdrożenia, żeby „zielone CI” było jedyną ścieżką do produkcji.
Wdróż do produkcji z jasnym, odwracalnym procesem
Zachowaj własność kodu
Eksportuj źródła w dowolnym momencie, zachowując pełną kontrolę nad projektem.
Wysyłanie to nie pojedyncze kliknięcie—to powtarzalna rutyna. Cel v1: wybierz target wdrożenia pasujący do stosu, wdrażaj małymi krokami i zawsze miej drogę powrotną.
Wybierz właściwy target wdrożenia (nie przepłacaj)
Wybierz platformę dopasowaną do sposobu działania aplikacji:
- Static site + serverless API: Vercel / Netlify
- Aplikacja Dockerowa: Render / Fly.io
- Tradycyjne VM: mały VPS (tylko jeśli naprawdę potrzebujesz)
Optymalizacja pod „łatwość redeploy” zwykle przewyższa optymalizację „maksymalnej kontroli” na tym etapie.
Jeśli priorytetem jest minimalne przełączanie narzędzi, rozważ platformy, które łączą build + hosting + rollback. Na przykład Koder.ai wspiera deployment i hosting wraz ze snapshotsami i rollbackiem, więc możesz traktować wydania jako odwracalne kroki, a nie drzwi jednokierunkowe.
Używaj checklisty wdrożeniowej za każdym razem
Napisz checklistę raz i używaj jej przy każdym wydaniu. Trzymaj ją krótką, by ludzie faktycznie ją stosowali:
- Potwierdź, że zmienne środowiskowe i sekrety są ustawione
- Uruchom migracje bazy (lub potwierdź, że nie są potrzebne)
- Zbuduj i uruchom aplikację w konfiguracji produkcyjnej
- Wykonaj smoke test głównego przepływu użytkownika
- Zweryfikuj, że logi płyną i błędy są widoczne
Jeśli przechowujesz ją w repo (np. w /docs/deploy.md), naturalnie zostanie blisko kodu.
Dodaj
Dodaj health checki i endpoint statusu
Utwórz lekki endpoint odpowiadający: „Czy apka jest up i może dotrzeć do zależności?” Typowe wzorce:
GET /health dla load balancerów i monitorów uptimeGET /status zwracający wersję aplikacji + sprawdzenia zależności
Odpowiedzi trzymaj szybkie, bez cache i bez szczegółów wrażliwych.
Zaplanuj rollback zanim będzie potrzebny
Plan rollbacku powinien być jawny:
- Jak ponownie wdrożyć poprzednią wersję (tag, release lub obraz)
- Co zrobić z migracjami (najpierw kompatybilne wstecz; odwracalne tylko gdy to konieczne)
- Kto decyduje o rollbacku i jakie sygnały go wywołują (wzrost błędów, nieudane health checki)
Gdy deployment jest odwracalny, wydawanie staje się rutyną—możesz częściej wypuszczać zmiany z mniejszym stresem.
Zamknij pętlę: monitoruj, ucz się i iteruj w tym samym przepływie pracy
Uruchomienie to początek najcenniejszej fazy: nauki, co robią prawdziwi użytkownicy, gdzie aplikacja pęka i które małe zmiany przesuwają metrykę sukcesu. Cel: utrzymać ten sam przepływ wspomagany AI, którego użyłeś do budowy—teraz skierowany na dane, nie założenia.
Skonfiguruj podstawowy monitoring (uptime, błędy, wydajność)
Zacznij od minimalnego stosu monitoringu odpowiadającego na trzy pytania: Czy jest online? Czy się wywala? Czy jest wolne?
Uptime możesz robić prostymi checkami (okresowe uderzenie w health endpoint). Śledzenie błędów powinno zbierać stack trace’y i kontekst żądań (bez danych wrażliwych). Monitoring wydajności może zacząć się od czasów odpowiedzi kluczowych endpointów i metryk ładowania front-endu.
Poproś AI o wygenerowanie:
- formatu logowania i korelacji ID, żeby jedna akcja użytkownika była śledzona end-to-end
- progów alertów (początkowo konserwatywnych) i checklisty on-call co robić najpierw
Dodaj analitykę produktową powiązaną z metryką sukcesu
Nie śledź wszystkiego—śledź to, co udowadnia, że apka działa. Zdefiniuj jedną główną metrykę sukcesu (np. „zakończone zamówienie”, „utworzony pierwszy projekt”, „zaproszony współpracownik”). Instrumentuj mały lejek: wejście → kluczowa akcja → sukces.
Poproś AI o propozycję nazw eventów i właściwości, potem sprawdź je pod kątem prywatności i przejrzystości. Utrzymuj eventy stabilne; zmiany nazw co tydzień czynią trendy bezużytecznymi.
Zamień feedback użytkowników w plan iteracji
Stwórz prosty intake: przycisk feedback w aplikacji, krótki alias e-mail i lekki template zgłoszenia błędu. Triage co tydzień: grupuj feedback w tematy, powiąż tematy z analityką i wybierz 1–2 poprawki do następnej iteracji.
Utrzymuj ciągłość przepływu po starcie
Traktuj alerty monitoringu, spadki w analityce i tematy feedbacku jak nowe „wymagania”. Wrzucaj je do tego samego procesu: zaktualizuj dokument, wygeneruj małą propozycję zmiany, zaimplementuj cienki kawałek, dodaj test celowany i wdrażaj tą samą odwracalną procedurą wydania. Dla zespołów, współdzielona strona „Learning Log” (linkowana z /blog lub wewnętrznych docs) utrzymuje decyzje widoczne i powtarzalne.