13 gru 2025·8 min
Od startupu graficznego do giganta AI: historia Nvidia
Prześledź drogę Nvidia — od startupu graficznego z 1993 roku do globalnego potentata AI — analizując kluczowe produkty, przełomy, liderów i strategiczne zakłady.
Prześledź drogę Nvidia — od startupu graficznego z 1993 roku do globalnego potentata AI — analizując kluczowe produkty, przełomy, liderów i strategiczne zakłady.
Nvidia stała się nazwą powszechnie rozpoznawalną, choć z zupełnie różnych powodów — w zależności od tego, kogo zapytasz. Gracze komputerowi myślą o kartach GeForce i płynnych klatkach animacji. Badacze AI widzą GPU, które potrafią wyszkolić nowoczesne modele w dniach zamiast miesiącach. Inwestorzy widzą jednego z najcenniejszych producentów półprzewodników w historii — akcję, która stała się swego rodzaju proxy dla całego boomu AI.
Jednak nie było to nieuniknione. Gdy Nvidia powstała w 1993 roku, była maleńkim startupem stawiającym na niszową ideę: że układy graficzne zmienią komputery osobiste. Przez trzy dekady firma przekształciła się z producenta kart graficznych w centralnego dostawcę sprzętu i oprogramowania dla nowoczesnego AI, napędzając wszystko — od systemów rekomendacyjnych i prototypów autonomicznych po ogromne modele językowe.
Zrozumienie historii Nvidia to jedno z najjaśniejszych dróg do pojęcia współczesnego sprzętu dla AI i modeli biznesowych, które się wokół niego tworzą. Firma stoi na skrzyżowaniu kilku sił:
Po drodze Nvidia wielokrotnie podejmowała ryzykowne zakłady: wsparcie programowalnych GPU zanim rynek był oczywisty, budowa kompletnego stosu software'owego dla deep learningu oraz wydawanie miliardów na przejęcia jak Mellanox, aby kontrolować więcej elementów centrum danych.
Artykuł śledzi drogę Nvidia od 1993 roku do dziś, ze szczególnym uwzględnieniem:
Artykuł jest napisany dla czytelników z obszaru technologii, biznesu i inwestycji, którzy chcą zrozumieć narracyjnie, jak Nvidia stała się tytanem AI — i co może nastąpić dalej.
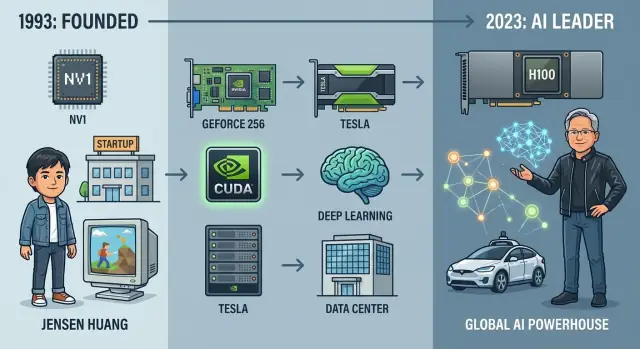
W 1993 roku trzech inżynierów o różnych osobowościach, ale wspólnej wierze w 3D, założyło Nvidia przy stoliku w typowym dinerze w Dolinie Krzemowej. Jensen Huang, tajwańsko‑amerykański inżynier i były projektant układów w LSI Logic, wniósł ambicję i talent do opowiadania historii klientom i inwestorom. Chris Malachowsky przyszedł ze Sun Microsystems z doświadczeniem w stacjach roboczych wysokiej wydajności. Curtis Priem, wcześniej w IBM i Sun, był architektem systemów z obsesją na punkcie dopasowania sprzętu i oprogramowania.
W tamtym czasie centrum ekosystemu stanowiły stacje robocze, minikomputery i wschodzący rynek PC. Grafika 3D była potężna, ale droga i głównie ograniczona do Silicon Graphics (SGI) oraz dostawców stacji roboczych obsługujących CAD, film i wizualizacje naukowe.
Założyciele Nvidia dostrzegli okazję: przenieść tę moc obliczeniową do przystępnych cenowo PC. Gdyby miliony osób mogły mieć wysokiej jakości grafikę 3D dla gier i multimediów, rynek byłby znacznie większy niż niszowy świat stacji roboczych.
Pomysł założycieli nie polegał na produkcji ogólnych półprzewodników, lecz na przyspieszonej grafice dla masowego rynku. Zamiast pozostawiać CPU wykonywanie wszystkiego, specjalny procesor graficzny miał przejmować ciężkie obliczenia matematyczne związane z renderowaniem scen 3D.
Zespół wierzył, że to wymaga:
Huang pozyskał kapitał początkowy od firm venture, takich jak Sequoia, ale pieniędzy nigdy nie było w nadmiarze. Pierwszy układ, NV1, był ambitny, lecz niezgodny z rosnącym standardem DirectX i dominującymi API dla gier. Sprzedaż była słaba i prawie zabiła firmę.
Nvidia przetrwała, szybko pivotując do NV3 (RIVA 128), dostosowując architekturę do standardów branżowych i ucząc się ścisłej współpracy z deweloperami gier i Microsoftem. Lekcja była jasna: sama technologia nie wystarczy; przetrwanie zależało od zgodności z ekosystemem.
Od początku Nvidia pielęgnowała kulturę, w której inżynierowie mieli duży wpływ, a czas wejścia na rynek traktowano jako sprawę egzystencjalną. Zespoły działały szybko, iterowały projekty agresywnie i akceptowały, że niektóre zakłady się nie powiodą.
Ograniczenia gotówkowe kształtowały oszczędność: używane meble biurowe, długie godziny pracy i skłonność do zatrudniania niewielu, ale bardzo zdolnych inżynierów zamiast budowania dużych hierarchicznych zespołów. Ta wczesna kultura — intensywność techniczna, pilność i ostrożne wydatki — później ukształtowała sposób, w jaki Nvidia podchodziła do znacznie większych możliwości poza grafiką PC.
Na początku i w połowie lat 90. grafika PC była podstawowa i rozproszona. Wiele gier wciąż polegało na renderowaniu programowym, gdzie CPU wykonywało większość pracy. Istniały dedykowane akceleratory 2D dla Windows, a wczesne karty 3D, jak Voodoo firmy 3dfx, pomagały w grach, ale brakowało standardowego sposobu programowania sprzętu 3D. API takie jak Direct3D i OpenGL dopiero się rozwijały, a deweloperzy często musieli celować w konkretne karty.
To było środowisko, w które weszła Nvidia: szybkie, chaotyczne i pełne szans dla firmy, która połączy wydajność z czytelnym modelem programowania.
Pierwszy istotny produkt Nvidia, NV1, zadebiutował w 1995 roku. Próbował robić wszystko naraz: 2D, 3D, audio, a nawet wsparcie dla gamepada Sega Saturn na jednej karcie. Technicznie skupiał się na powierzchniach kwadratowych zamiast trójkątów, dokładnie w momencie, gdy Microsoft i większość branży standaryzowały API 3D wokół trójkątnych wielokątów.
Niedopasowanie do DirectX i ograniczone wsparcie programowe uczyniły NV1 komercyjną porażką. Jednak produkt ten nauczył Nvidia dwóch kluczowych rzeczy: podążaj za dominującym API (DirectX) i skoncentruj się na wydajności 3D zamiast egzotycznych funkcji.
Nvidia odbudowała się z RIVA 128 w 1997 roku. Firma przyjęła trójkąty i Direct3D, dostarczyła silną wydajność 3D i zintegrowała 2D i 3D w jednej karcie. Recenzenci zwrócili uwagę, a producenci OEM zaczęli postrzegać Nvidia jako poważnego partnera.
RIVA TNT i TNT2 dopracowały formułę: lepsza jakość obrazu, wyższe rozdzielczości i poprawione sterowniki. Choć 3dfx nadal dominował w świadomości graczy, Nvidia szybko się zbliżała, wysyłając częste aktualizacje sterowników i zbliżając się do deweloperów gier.
W 1999 roku Nvidia wprowadziła GeForce 256 i nazwała go „pierwszym na świecie GPU” — Graphics Processing Unit. To nie był tylko marketing. GeForce 256 zintegrował sprzętowe transformacje i oświetlenie (T&L), zrzucając obliczenia geometryczne z CPU na samą kartę graficzną.
Ten zwrot uwolnił CPU do logiki gry i fizyki, podczas gdy GPU radził sobie z coraz bardziej złożonymi scenami 3D. Gry mogły rysować więcej wielokątów, korzystać z bardziej realistycznego oświetlenia i działać płynniej przy wyższych rozdzielczościach.
Równolegle boom gier PC eksplodował, napędzany tytułami takimi jak Quake III Arena i Unreal Tournament oraz szybkim przyjęciem Windows i DirectX. Nvidia dopasowała się do tego wzrostu.
Firma zapewniła design‑winy z dużymi OEMami jak Dell i Compaq, co gwarantowało, że miliony mainstreamowych PC wysyłane były z grafiką Nvidia jako domyślną. Wspólne programy marketingowe ze studiami gier i kampania „The Way It’s Meant to Be Played” wzmocniły wizerunek Nvidia jako wyboru domyślnego dla zaawansowanych graczy.
Na początku XXI wieku Nvidia przekształciła się ze zmagającego się startupu z produktem niezgodnym ze standardami w dominującą siłę na rynku grafiki PC, torując drogę do tego, co później stało się obliczeniami na GPU, a w końcu AI.
Na początku GPU były głównie maszynami o stałej funkcji: sztywne potoki przetwarzania, które pobierały wierzchołki i tekstury i wypuszczały piksele. Były bardzo szybkie, ale prawie całkowicie nieelastyczne.
Na początku lat 2000 programowalne shadery (Vertex i Pixel/Fragment Shaders w DirectX i OpenGL) zmieniły tę formułę. Z układami takimi jak GeForce 3, a później GeForce FX i GeForce 6, Nvidia zaczęła udostępniać niewielkie programowalne jednostki pozwalające deweloperom pisać efekty, zamiast polegać na sztywnym potoku.
Te shadery były dalej ukierunkowane na grafikę, ale zaszczepiły w Nvidii kluczową myśl: jeśli GPU można programować dla różnych efektów wizualnych, dlaczego nie można ich programować do ogólnych obliczeń?
Obliczenia ogólnego przeznaczenia na GPU (GPGPU) były zakładem kontrariańskim. Wewnątrz firmy wielu zastanawiało się, czy ma sens poświęcać ograniczone zasoby tranzystorowe, czas inżynieryjny i wysiłek programowy na obciążenia spoza gamingu. Zewnętrznie sceptycy traktowali GPU jak zabawkę graficzną, a wczesne hacki linearnych algebr do fragment shaderów były uciążliwe.
Odpowiedzią Nvidia była CUDA, ogłoszona w 2006 roku: model programowania przypominający C/C++, runtime i zestaw narzędzi zaprojektowany tak, by GPU zachowywało się jak masowo równoległy koprocesor. Zamiast zmuszać naukowców do myślenia w kategoriach trójkątów i pikseli, CUDA eksponowała wątki, bloki, siatki i jawne hierarchie pamięci.
To był ogromny strategiczny risk: Nvidia musiała zbudować kompilatory, debugery, biblioteki, dokumentację i programy szkoleniowe — inwestycje software’owe bardziej typowe dla firmy platformowej niż dostawcy chipów.
Pierwsze wygrane przyszły z high‑performance computing:
Badacze mogli nagle wykonywać symulacje trwające wcześniej tygodnie w dniach lub godzinach, często na jednej karcie GPU w stacji roboczej zamiast na całym klastrze CPU.
CUDA zrobiła więcej niż przyspieszyła kod; stworzyła ekosystem deweloperski wokół sprzętu Nvidia. Firma inwestowała w SDK, biblioteki matematyczne (jak cuBLAS i cuFFT), programy uniwersyteckie i własną konferencję (GTC), aby nauczyć programowania równoległego na GPU.
Każda aplikacja i biblioteka CUDA pogłębiały fosę: deweloperzy optymalizowali pod GPU Nvidia, narzędzia dojrzewały wokół CUDA, a nowe projekty zaczynały z Nvidia jako domyślnym akceleratorem. Długo przed tym, jak szkolenie AI zapełniło centra danych GPU, ten ekosystem już uczynił programowalność jednym z najpotężniejszych atutów Nvidia.
W połowie lat 2000 biznes gamingu Nvidia kwitł, ale Jensen Huang i zespół widzieli limit polegania wyłącznie na konsumenckich GPU. Ta sama równoległa moc, która wygładzała gry, mogła przyspieszać symulacje naukowe, finanse, a w końcu AI.
Nvidia zaczęła pozycjonować GPU jako akceleratory ogólnego przeznaczenia dla stacji roboczych i serwerów. Karty profesjonalne dla projektantów i inżynierów (linia Quadro) były wczesnym krokiem, ale większy zakład to wejście w serca centrów danych.
W 2007 Nvidia wprowadziła linię Tesla — pierwsze GPU zaprojektowane specjalnie dla HPC i obciążeń serwerowych, a nie wyświetlania obrazu.
Karty Tesla kładły nacisk na wydajność w podwójnej precyzji, pamięć z korekcją błędów (ECC) i efektywność energetyczną w gęstych szafach — cechy istotne dla centrów danych i ośrodków superkomputerowych, a nie dla liczby klatek na sekundę.
HPC i laboratoria narodowe stały się kluczowymi wczesnymi adoptersami. Systemy takie jak superkomputer „Titan” w Oak Ridge pokazały, że klastry programowalne przez CUDA mogą dostarczyć ogromnych przyspieszeń dla fizyki, modelowania klimatu i dynamiki molekularnej. Ta wiarygodność w HPC później pomogła przekonać przedsiębiorstwa i chmury, że GPU to poważna infrastruktura, a nie tylko sprzęt do gier.
Nvidia mocno inwestowała w relacje z uniwersytetami i instytutami badawczymi, dostarczając sprzęt i narzędzia CUDA do laboratoriów. Wielu badaczy, którzy eksperymentowali z obliczeniami GPU na uczelniach, później napędzało adaptację w firmach i startupach.
Równocześnie wczesne chmury zaczęły oferować instancje z GPU, czyniąc karty dostępnymi na żądanie. Amazon Web Services, a potem Microsoft Azure i Google Cloud, udostępniły GPU Tesla‑klasy każdemu z kartą kredytową, co okazało się kluczowe dla deep learningu na GPU.
W miarę jak rósł segment centrów danych i profesjonalny, baza przychodów Nvidia się poszerzała. Gaming pozostał filarem, ale nowe segmenty — HPC, enterprise AI i chmura — stały się drugim silnikiem wzrostu, tworząc ekonomiczną podstawę dominacji firmy w AI.
Punkt zwrotny nastąpił w 2012 roku, gdy sieć neuronowa AlexNet zaskoczyła społeczność wizji komputerowej, rozbijając benchmark ImageNet. Kluczowe było to, że uruchomiono ją na paru GPU Nvidia. To, co wcześniej było niszową ideą — trenowanie dużych sieci neuronowych na kartach graficznych — nagle zaczęło wyglądać jak przyszłość AI.
Sieci głębokie składają się z ogromnej liczby identycznych operacji: mnożeń macierzy i splotów wykonywanych na milionach wag i aktywacji. GPU zostały zaprojektowane do uruchamiania tysięcy prostych, równoległych wątków do shadingu grafiki. Ta równoległość pasowała niemal idealnie do sieci neuronowych.
Zamiast renderować piksele, GPU mogły przetwarzać neurony. Obciążenia intensywne obliczeniowo, które na CPU działałyby powoli, mogły być przyspieszone o rzędy wielkości. Czas trenowania, który kiedyś trwał tygodnie, skrócił się do dni lub godzin, umożliwiając szybkie iteracje i skalowanie modeli.
Nvidia działała szybko, aby przekształcić ciekawostkę badawczą w platformę. CUDA już dawała sposób programowania GPU, ale deep learning potrzebował narzędzi wyższego poziomu.
Nvidia stworzyła cuDNN, bibliotekę zoptymalizowaną pod GPU dla prymitywów sieci neuronowych — splotów, poolingów, funkcji aktywacji. Frameworki takie jak Caffe, Theano, Torch, a potem TensorFlow i PyTorch zintegrowały cuDNN, więc badacze mogli uzyskać przyspieszenie GPU bez ręcznego strojenia kerneli.
Równocześnie Nvidia dopracowywała sprzęt: dodając wsparcie mieszanej precyzji, pamięć o dużej przepustowości i potem Tensor Cores w architekturach Volta i późniejszych, zaprojektowanych specjalnie do mnożeń macierzy w deep learningu.
Nvidia pielęgnowała bliskie relacje z czołowymi laboratoriami AI i badaczami na uniwersytetach takich jak Toronto, Stanford, z Google, Facebook i startupami typu DeepMind. Firma oferowała wczesny sprzęt, pomoc inżynieryjną i niestandardowe sterowniki, otrzymując w zamian bezpośrednią informację zwrotną, czego obciążenia AI będą potrzebować dalej.
Aby uczynić superkomputery do AI bardziej dostępnymi, Nvidia wprowadziła systemy DGX — zintegrowane serwery AI wypełnione wydajnymi GPU, szybkim interconnectem i dopracowanym oprogramowaniem. DGX‑1 i kolejne wersje stały się domyślną „aplikacją” dla wielu laboratoriów i przedsiębiorstw budujących poważne możliwości deep learningu.
Z GPU takimi jak Tesla K80, P100, V100, a w końcu A100 i H100, Nvidia przestała być „firmą od gier, która także robi obliczenia” i stała się domyślnym silnikiem do trenowania i serwowania nowoczesnych modeli deep learningowych. Moment AlexNet otworzył nową erę, a Nvidia ustawiła się w jej centrum.
Nvidia nie wygrała w AI sprzedając tylko szybsze układy. Zbudowała kompletny ekosystem, który upraszcza budowanie, wdrażanie i skalowanie AI na sprzęcie Nvidia bardziej niż gdzie indziej.
Podstawą jest CUDA — model programowania równoległego wprowadzony w 2006 roku. CUDA pozwala traktować GPU jako akcelerator, z dobrze znanymi narzędziami C/C++ i Python.
Na CUDA Nvidia nakłada wyspecjalizowane biblioteki i SDK:
Dzięki temu badacz lub inżynier rzadko pisze niskopoziomowy kod GPU — wywołuje biblioteki Nvidia, które są dostrojone dla każdej generacji GPU.
Lata inwestycji w narzędzia CUDA, dokumentację i szkolenia stworzyły potężną fosę. Miliony linii kodu produkcyjnego, projekty akademickie i open source są zoptymalizowane pod GPU Nvidia.
Przejście na konkurencyjną architekturę często oznacza konieczność przepisywania kerneli, ponownego walidowania modeli i przeszkolenia inżynierów. Te koszty zmiany przywiązują deweloperów, startupy i duże przedsiębiorstwa do Nvidia.
Nvidia ściśle współpracuje z hyperscalami, dostarczając referencyjne platformy HGX i DGX, sterowniki i dopracowane stosy oprogramowania, aby klienci mogli wynająć GPU bez większych trudności.
Pakiet Nvidia AI Enterprise, katalog oprogramowania NGC i wstępnie wytrenowane modele dają przedsiębiorstwom ścieżkę od pilotażu do produkcji, zarówno on‑premises, jak i w chmurze.
Nvidia rozszerza platformę na kompletne rozwiązania pionowe:
Te platformy pionowe łączą GPU, SDK, aplikacje referencyjne i integracje partnerów, dostarczając klientom niemal rozwiązania „turnkey”.
Poprzez pielęgnowanie ISV, partnerów chmurowych, laboratoriów badawczych i integratorów systemów wokół swojego stosu software'owego, Nvidia uczyniła GPU domyślnym sprzętem dla AI.
Każdy nowy framework zoptymalizowany pod CUDA, każdy startup wysyłający produkt na Nvidia i każda usługa chmurowa dostosowana do jej GPU wzmacniają sprzężenie zwrotne: więcej oprogramowania na Nvidia przyciąga więcej użytkowników, co uzasadnia kolejne inwestycje i powiększa dystans do konkurentów.
Wzrost Nvidia w AI to nie tylko sprawa GPU, lecz także strategicznych zakładów poza samym układem.
Przejęcie Mellanox w 2019 było punktem zwrotnym. Mellanox wniósł InfiniBand i wysokiej klasy Ethernet oraz wiedzę o łączności niskiego opóźnienia i dużej przepustowości.
Szkolenie dużych modeli wymaga scalania tysięcy GPU w jedną logiczną maszynę. Bez szybkiej sieci GPU będą stały bezczynnie, czekając na dane lub synchronizację gradientów. Technologie takie jak InfiniBand, RDMA, NVLink i NVSwitch zmniejszają narzut komunikacyjny i pozwalają efektywnie skalować ogromne klastry. Mellanox dał Nvidia krytyczną kontrolę nad tą „tkaniną”.
W 2020 Nvidia ogłosiła plan przejęcia Arm, z zamiarem połączenia swojej wiedzy w akceleracji AI z powszechnie licencjonowaną architekturą CPU używaną w telefonach, urządzeniach wbudowanych i coraz częściej w serwerach.
Regulatorzy w USA, UK, UE i Chinach podnieśli silne obawy antymonopolowe: Arm jest neutralnym dostawcą IP dla wielu rywali Nvidia, a konsolidacja zagroziłaby tej neutralności. Po długim przeglądzie i presji branży Nvidia porzuciła ten plan w 2022.
Nawet bez Arm Nvidia posunęła się naprzód z własnym CPU Grace, pokazując, że nadal chce kształtować pełny węzeł centrum danych, nie tylko akcelerator.
Omniverse rozszerza Nvidia w symulacje, digital twins i współpracę 3D. Łączy narzędzia i dane wokół OpenUSD, pozwalając firmom symulować fabryki, miasta i roboty przed wdrożeniem w świecie fizycznym. Omniverse to zarówno ciężkie obciążenia GPU, jak i platforma programowa, która przywiązuje deweloperów.
W motoryzacji platforma DRIVE celuje w scentralizowaną obliczeniowo architekturę pokładową, autonomię i zaawansowane systemy wspomagania kierowcy. Dostarczając sprzęt, SDK i narzędzia walidacyjne producentom samochodów i dostawcom tier‑1, Nvidia wplata się w długie cykle produktowe i przychód z oprogramowania.
Na brzegu sieci moduły Jetson i powiązane stosy oprogramowania zasilają robotykę, inteligentne kamery i AI przemysłowy. Produkty te przenoszą platformę Nvidia do handlu, logistyki, opieki zdrowotnej i miast — obsługując obciążenia, które nie mogą żyć wyłącznie w chmurze.
Dzięki Mellanox i sieciom, nieudanym, ale pouczającym próbom jak Arm, oraz ekspansji w Omniverse, automotive i edge AI, Nvidia celowo przekształciła się z „dostawcy GPU” w firmę platformową.
Sprzedaje teraz:
Te zakłady utrudniają wyparcie Nvidia: konkurenci muszą dorównać nie tylko chipowi, ale ścisle zintegrowanemu stosowi obejmującemu obliczenia, sieć, oprogramowanie i rozwiązania dedykowane branżom.
Wzrost Nvidia przyciągnął potężnych rywali, baczniejszych regulatorów i nowe ryzyka geopolityczne, które kształtują każdy ruch strategiczny firmy.
AMD pozostaje najbliższym rywalem Nvidia w GPU, często konkurując bezpośrednio w gamingu i akceleratorach do centrów danych. Układy AMD MI serii celują w tych samych klientów chmurowych i hiperskalowych, co H100 i następcy Nvidia.
Intel atakuje z kilku stron: przez swoje CPU x86 dominujące w serwerach, własne dyskretne GPU i dedykowane akceleratory AI. Równocześnie hyperscale'owi gracze jak Google (TPU), Amazon (Trainium/Inferentia) i fala startupów (Graphcore, Cerebras) projektują własne układy, aby zmniejszyć zależność od Nvidia.
Główną obroną Nvidia pozostaje kombinacja przywództwa wydajnościowego i oprogramowania. CUDA, cuDNN, TensorRT i głęboki stos SDK przywiązują deweloperów i przedsiębiorstwa. Sam sprzęt to nie wszystko; przenoszenie modeli i narzędzi poza ekosystem Nvidia wiąże się z rzeczywistymi kosztami przejścia.
Rządy traktują dziś zaawansowane GPU jako zasoby strategiczne. Kontrole eksportowe USA wielokrotnie zaostrzały limit wysyłki najwyższej klasy chipów AI do Chin i innych obszarów wrażliwych, zmuszając Nvidia do projektowania „zgodnych z eksportem” wariantów o ograniczonej wydajności. Te ograniczenia chronią bezpieczeństwo narodowe, ale ograniczają dostęp do dużego rynku wzrostu.
Regulatorzy również obserwują siłę rynkową Nvidia. Zablokowane przejęcie Arm pokazało obawy przed koncentracją kontroli nad fundamentalnym IP. Wraz ze wzrostem udziału Nvidia w akceleratorach AI, regulatorzy w USA, UE i innych miejscach chętniej badają praktyki związane z wyłącznością, bundlingiem i ewentualną dyskryminacją w dostępie do sprzętu i oprogramowania.
Nvidia jest firmą fabless, mocno zależną od TSMC dla najlepszych procesów technologicznych. Każde zakłócenie na Tajwanie — od katastrofy naturalnej po napięcia polityczne — uderzyłoby bezpośrednio w zdolność Nvidia do dostarczania najwyższej klasy GPU.
Globalne niedobory zaawansowanej pojemności pakowania (CoWoS, integracja HBM) już tworzą wąskie gardła, dając Nvidia mniej elastyczności w odpowiedzi na gwałtowny popyt. Firma musi negocjować moce produkcyjne, poruszać się w kwestiach napięć technologicznych USA–Chiny i zabezpieczać się przed regułami eksportowymi, które mogą zmieniać się szybciej niż roadmapy półprzewodników.
Godzenie tych presji z utrzymaniem przewagi technologicznej stało się dziś zadaniem równie geopolitycznym i regulacyjnym, co inżynieryjnym.
Jensen Huang to założyciel‑CEO, który w praktyce zachowuje się jak zaangażowany inżynier. Bierze czynny udział w strategii produktowej, uczestnicząc w przeglądach technicznych i sesjach przy tablicy, a nie tylko w rozmowach z inwestorami.
Jego publiczny wizerunek łączy pokazowość z klarownością. Skórzana kurtka na prezentacjach to celowy zabieg: używa prostych metafor, by wytłumaczyć skomplikowane architektury, pozycjonując Nvidia jako firmę, która rozumie zarówno fizykę, jak i biznes. W środku firmy znany jest z bezpośredniego feedbacku, wysokich oczekiwań i gotowości do podejmowania trudnych decyzji, gdy technologia lub rynki się zmieniają.
Kultura Nvidia opiera się na kilku powtarzających się motywach:
Taka mieszanka tworzy środowisko, gdzie długie pętle sprzętowe współistnieją z szybkimi pętlami software'owymi i researchowymi, a zespoły hardware, software i badawcze współpracują ściśle.
Nvidia rutynowo inwestuje w wieloletnie platformy — nowe architektury GPU, interkonekty i frameworki — jednocześnie zarządzając krótkoterminowymi oczekiwaniami rynkowymi.
Organizacyjnie oznacza to:
Huang często w raportach kwartalnych odwołuje się do długoterminowych trendów (AI, przyspieszone obliczenia), aby utrzymać inwestorów w zgodzie z czasowym horyzontem firmy, nawet gdy krótkoterminowe popytowe wahania występują.
Nvidia traktuje deweloperów jako kluczowego klienta. CUDA, cuDNN, TensorRT i dziesiątki SDK pionowych wspierane są przez:
Ekosystem partnerów — OEM, chmury, integratorzy systemów — pielęgnowany jest przez projekty referencyjne, wspólny marketing i wczesny dostęp do roadmapów. To ściśle powiązane otoczenie czyni platformę Nvidia przyczepną i trudną do wypchnięcia.
W miarę jak Nvidia przekształcała się z dostawcy kart graficznych w globalną platformę AI, jej kultura ewoluowała:
Mimo skali Nvidia starała się zachować mentalność prowadzoną przez założyciela i pierwszeństwo inżynierii, gdzie zachęca się do ambitnych zakładów technicznych, a zespoły mają oczekiwanie szybkiego działania w dążeniu do przełomów.
Arc finansowy Nvidia to jedna z najbardziej spektakularnych opowieści w technologii: od skromnego dostawcy grafiki do firmy o wartości rynkowej w centrum boomu AI.
Po IPO w 1999 roku Nvidia przez długie lata była wyceniana w pojedynczych miliardach, powiązana głównie z cyklicznym rynkiem PC i gamingu. W latach 2000 przychody rosły, ale firma nadal była postrzegana jako wyspecjalizowany producent chipów, nie jako lider platformowy.
Przełom nastąpił w połowie dekady 2010, gdy przychody z centrów danych i AI zaczęły rosnąć skumulowanie. Około 2017 r. kapitalizacja Nvidia przekroczyła 100 mld USD; w 2021 r. była jedną z najcenniejszych firm półprzewodnikowych na świecie. W 2023 krótkotrwale dołączyła do klubu firm o wartości biliona dolarów, a do 2024 r. często handlowano nią znacznie powyżej tej granicy, odzwierciedlając przekonanie inwestorów, że Nvidia jest fundamentem infrastruktury AI.
Przez większość historii gaming był rdzeniem biznesu. Karty konsumenckie oraz profesjonalne wizualizacje generowały większość przychodów i zysków.
Ten miks odwrócił się wraz z eksplozją AI i obliczeń przyspieszonych w chmurze:
Ekonomia sprzętu AI zmieniła profil finansowy Nvidia. Platformy high‑end i sieć oraz oprogramowanie mają premię cenową i wysokie marże. Wraz z rosnącymi przychodami z centrów danych, marże ogólne rozszerzyły się, czyniąc z Nvidia maszynę generującą gotówkę z niezwykłą dźwignią operacyjną.
Popyt na AI nie tylko dodał kolejnej linii produktowej — zmienił sposób, w jaki inwestorzy wyceniają Nvidia. Firma przestała być modelowana jako cykliczny producent półprzewodników, a zaczęto ją traktować bardziej jak krytyczną infrastrukturę i platformę software'ową.
Marże brutto, wspierane przez akceleratory AI i platformowe oprogramowanie, znalazły się na solidnym poziomie — często sięgającym wysokich wartości. Koszty stałe rosły wolniej niż przychody, więc przyrostowe marże przy wzroście AI były bardzo wysokie, co napędzało gwałtowny wzrost zysku na akcję. To wywołało kilka fal podwyższeń prognoz analityków i repricing akcji.
Historia kursu Nvidia pełna jest spektakularnych rajdów i ostrych spadków.
Firma przeprowadziła wiele podziałów akcji, by utrzymać przystępną cenę za sztukę: kilka splitów 2‑for‑1 w wczesnych latach 2000, split 4‑for‑1 w 2021 i 10‑for‑1 w 2024. Długoterminowi akcjonariusze, którzy trzymali papiery przez te wydarzenia, doświadczyli niezwykłych skumulowanych zwrotów.
Zmienność była równie zauważalna. Kurs mocno spadał podczas:
Za każdym razem obawy o cykliczność czy korekty popytu silnie uderzały w kurs. Jednak kolejne fale boomu AI wielokrotnie pchały Nvidia na nowe szczyty, gdy konsensus przewartościowywał oczekiwania.
Mimo sukcesu Nvidia nie jest pozbawiona ryzyka. Inwestorzy dyskutują o kilku kluczowych kwestiach:
Równocześnie długoterminowy bull case zakłada, że przyspieszone obliczenia i AI staną się standardem w centrach danych, przedsiębiorstwach i urządzeniach brzegowych przez dekady. W tym scenariuszu połączenie GPU, sieci, oprogramowania i przywiązania ekosystemowego Nvidia może uzasadniać lata wysokiego wzrostu i silne marże, wspierając transformację firmy w trwałego rynkowego giganta.
Następny rozdział Nvidia polega na przekształceniu GPU z narzędzia trenowania modeli w podstawę inteligentnych systemów: generatywne AI, autonomiczne maszyny i symulowane światy.
Generatywne AI to natychmiastowy priorytet. Nvidia chce, aby każdy istotny model — tekstowy, obrazowy, wideo czy kodowy — był trenowany, dostrajany i serwowany na jej platformie. To oznacza silniejsze GPU centrów danych, szybsze sieci i stosy oprogramowania ułatwiające przedsiębiorstwom budowę własnych copilotov i modeli domenowych.
Poza chmurą Nvidia rozwija systemy autonomiczne: samochody, roboty dostawcze, ramiona fabryczne i drony. Celem jest ponowne użycie tego samego stosu CUDA, AI i symulacji w automotive (Drive), robotyce (Isaac) i platformach wbudowanych (Jetson).
Digital twins łączą to wszystko. Z Omniverse i powiązanymi narzędziami Nvidia stawia, że firmy będą symulować fabryki, miasta, sieci 5G — nawet elektrownie — zanim je zbudują lub przebudują. To tworzy długotrwałe przychody z oprogramowania i usług na sprzęcie.
Automotive, automatyzacja przemysłowa i edge computing to ogromne szanse. Samochody stają się mobilnymi centrami danych, fabryki — systemami napędzanymi AI, a szpitale i sklepy — środowiskami bogatymi w sensory. Każde z nich potrzebuje niskoczasowej inferencji, oprogramowania krytycznego dla bezpieczeństwa i silnych ekosystemów deweloperskich — obszarów, w które Nvidia intensywnie inwestuje.
Ale ryzyka są realne:
Dla założycieli i inżynierów historia Nvidia pokazuje moc posiadania pełnego stosu: sprzęt, systemowe oprogramowanie i narzędzia deweloperskie, a także ciągłe obstawianie następnego wąskiego gardła obliczeniowego zanim stanie się oczywiste.
Dla polityków to studium przypadku, jak krytyczne platformy obliczeniowe stają się infrastrukturą strategiczną. Decyzje w kwestii kontroli eksportowych, polityki konkurencji i finansowania otwartych alternatyw będą kształtować, czy Nvidia pozostanie dominującą bramą do AI, czy jednym z kilku ważnych graczy w bardziej zróżnicowanym ekosystemie.
Nvidia powstała wokół bardzo konkretnego zakładu: że grafika 3D przejdzie z drogich stacji roboczych do masowych PC, i że ta zmiana będzie wymagać dedykowanego procesora graficznego ściśle powiązanego z oprogramowaniem.
Zamiast próbować być ogólną firmą półprzewodnikową, Nvidia:
To wąskie, ale dogłębne skupienie na jednym problemie — renderowaniu w czasie rzeczywistym — stworzyło podstawę techniczną i kulturową, która później przełożyła się na obliczenia na GPU i akcelerację AI.
CUDA przekształciła GPU Nvidia z układów o stałej funkcji graficznej w ogólnego przeznaczenia równoległą platformę obliczeniową.
Kluczowe sposoby, w jakie przyczyniła się do dominacji w AI:
Mellanox dał Nvidia kontrolę nad fabułą sieciową, która łączy tysiące GPU w superkomputerach AI.
Dla dużych modeli wydajność zależy nie tylko od szybkich chipów, ale także od tego, jak szybko mogą wymieniać dane i gradienty. Mellanox wniosło:
Przychody Nvidia przeszły z dominacji gamingu do dominacji centrów danych.
W skrócie:
Platformy AI klasy high‑end i sieciowanie mają premie cenowe i marżowe, dlatego wzrost centrów danych znacząco przekształcił rentowność Nvidia.
Nvidia stoi wobec nacisku zarówno ze strony tradycyjnych rywali, jak i układów specjalizowanych:
Zaawansowane GPU są dziś traktowane jako technologia strategiczna, szczególnie w kontekście AI.
Wpływ na biznes Nvidia obejmuje:
Stos AI Nvidia to warstwowy zestaw narzędzi, który ukrywa złożoność GPU przed większością deweloperów:
Autonomiczne prowadzenie i robotyka to rozszerzenia rdzenia platformy AI i symulacji Nvidia na systemy fizyczne.
Z strategicznego punktu widzenia:
Ewolucja Nvidia daje kilka lekcji:
Jeśli przyszłe obciążenia AI odejdą od wzorców przyjaznych GPU, Nvidia będzie musiała szybko dostosować swoje architektury i oprogramowanie.
Możliwe zmiany to:
Prawdopodobna odpowiedź Nvidia to:
Kiedy głęboka nauka eksplodowała, narzędzia, dokumentacja i nawyki wokół CUDA były już dojrzałe, co dało firmie ogromną przewagę.
Dzięki temu Nvidia mogła sprzedawać zintegrowane platformy (DGX, HGX, pełne projekty centrów danych), w których GPU, sieć i oprogramowanie są współoptymalizowane, zamiast jedynie sprzedawać pojedyncze karty akceleracyjne.
Głównymi obronami Nvidia są przewaga wydajności, ekosystem CUDA i zintegrowane systemy. Jednak jeśli alternatywy staną się „wystarczająco dobre” i łatwiejsze do programowania, udział i siła cenowa Nvidia mogą zostać pod presją.
W efekcie strategia Nvidia musi uwzględniać nie tylko inżynierię i rynki, ale też politykę, reguły handlu i regionalne plany przemysłowe.
Większość zespołów wywołuje te biblioteki poprzez frameworki takie jak PyTorch czy TensorFlow, więc rzadko piszą niskopoziomowy kod GPU bezpośrednio.
Te rynki mogą być dziś mniejsze od chmurowego AI, ale oferują trwałe, wysokomarżowe przychody i pogłębiają ekosystem Nvidia w różnych branżach.
Dla twórców kluczowe jest łączenie głębokiego wglądu technicznego z myśleniem o ekosystemie, a nie tylko skupianie się na surowej wydajności.
Historia firmy sugeruje, że potrafi się pivotować, ale takie zmiany będą testem jej elastyczności.